Ответ на «Нейросеть от Microsoft для транскрипции видео, которая понимает кто говорит: VibeVoice ASR — обзор и портативная версия»
Не обязательно устанавливать на свой комп. Более того, это не гарантирует работу.
лучше дистанционные методы
WhisperDesktop, Google Colab и три часа терпения при транскрипции видео
Зачем вообще понадобился транскрипт
Мы провели рабочую встречу по нашей симуляционной модели здоровья работников — запись осталась на YouTube. Нужно было извлечь из неё планы и идеи, которые обсуждались, и оформить в документ. Задача простая: получить текст из видео.
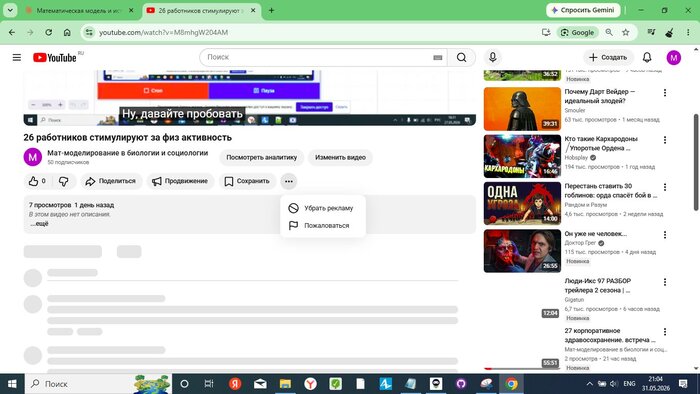
Первая попытка — попросить YouTube сделать это за нас. Нажимаем три точки под видео, ищем «Открыть транскрипцию»…
Почему то картинки не вставляются,воспользуюсь онлайн сервисом.
YouTube, три точки под видео — пункта «Открыть транскрипцию» нет. Видео загружено несколько часов назад, субтитры ещё не сгенерированы.
Пусто. Видео только что загружено, YouTube ещё не успел обработать аудио. Ждать не вариант.
Скриншот до текста.
Попытка первая: WhisperDesktop
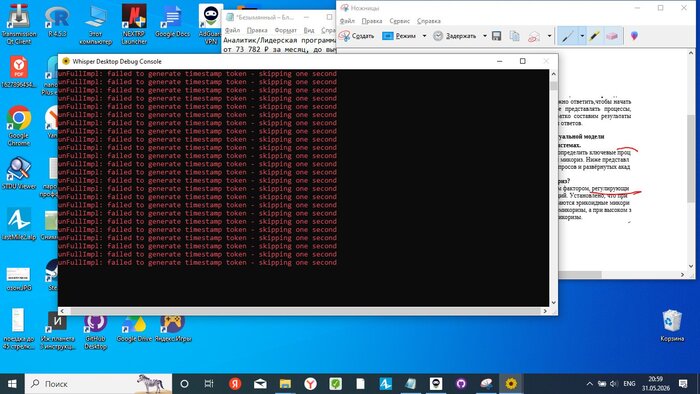
Скачали WhisperDesktop (GUI для whisper.cpp) и модель ggml-medium.bin (~1.5 ГБ). Запустили. Первые секунды — тишина. Потом консоль начала выдавать что-то очень неприятное:
🖼 Скриншот 2 после текста— WhisperDesktop с ошибкой
WhisperDesktop Debug Console: бесконечный поток «unFullImpl: failed to generate timestamp token - skipping one second». Программа не падает, но и не работает.
Строчки сыпятся одна за другой, транскрипт пустой. Это известная проблема с GPU через DirectCompute — программа пропускает каждую секунду аудио. Лечится отключением GPU в настройках, но тогда 55-минутное видео будет обрабатываться несколько часов. Ищем быстрее.
Попытка вторая: Google Colab
Google Colab даёт бесплатный GPU в браузере без установки чего-либо. Создали новый notebook, три ячейки.
Ячейка 1 — установка зависимостей:
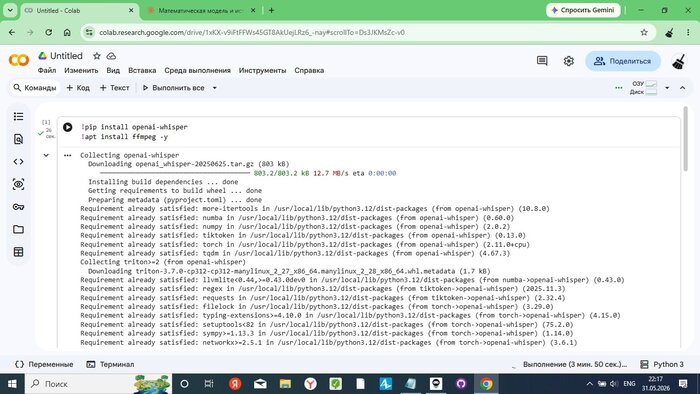
!pip install openai-whisper
!apt install ffmpeg -y
🖼 Скриншот 3 и тут и после текста— Colab установка
Colab устанавливает openai-whisper и зависимости. Процесс занял ~3 минуты.
Ячейка 2 — загрузка файла прямо с компьютера:
from google.colab import files
uploaded = files.upload()
filename = list(uploaded.keys())[0]
🖼 Скриншот 4 — загрузка файла 100%
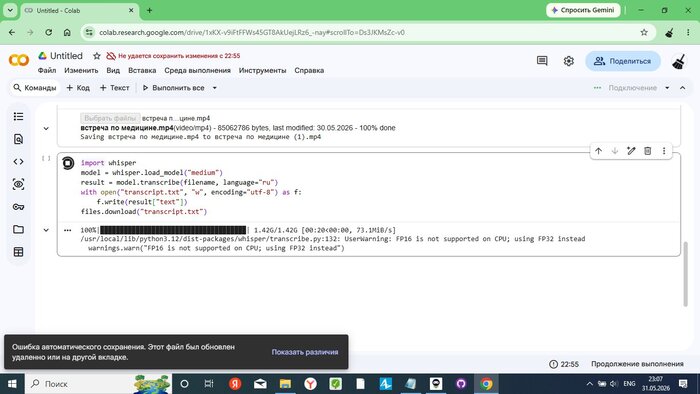
Файл «встреча по медицине.mp4» (85 МБ) загружен на сервер Colab — 100% done. Загрузка ~5 минут.
Ячейка 3 — транскрипция:
import whisper
model = whisper.load_model("medium")
result = model.transcribe(filename, language="ru")
with open("transcript.txt", "w", encoding="utf-8") as f:
f.write(result["text"])
files.download("transcript.txt")
Процесс: час ожидания
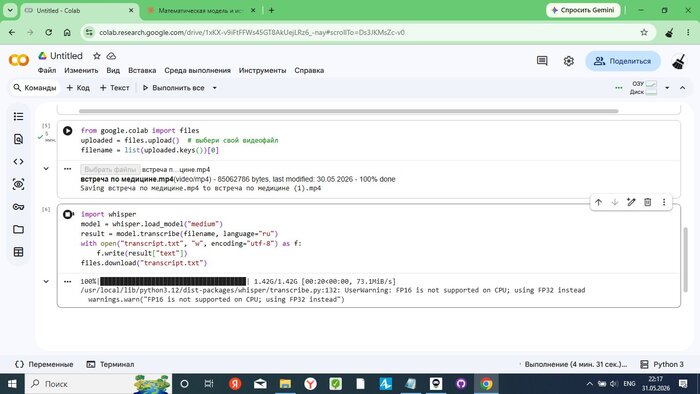
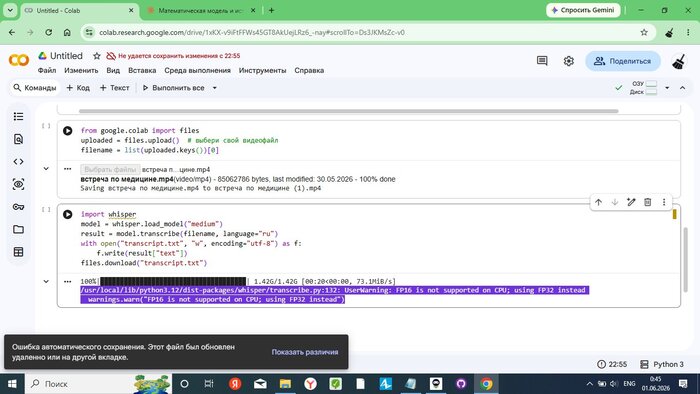
Colab сразу предупредил: «FP16 is not supported on CPU; using FP32 instead» — GPU не выделился, работаем на процессоре. Примерно вдвое медленнее, но всё равно быстрее локальной машины с проблемным GPU.
🖼 Скриншот 5 — транскрипция стартует
Whisper загрузил модель medium (1.42 ГБ) и начал транскрипцию. Таймер: 4 минуты 31 секунда — только начало.
Оставляем вкладку открытой. Через 38 минут заглядываем — всё ещё работает:
🖼 Скриншот 6 — 38 минут ожидания
Всё ещё работает. Таймер: 22:55. Colab параллельно выдаёт диалог про несохранённые изменения — нажимаем «Отмена», транскрипция продолжается.
Ещё через ~20 минут — готово:
🖼 Скриншот 7 — готово, галочка ✓
В правом верхнем углу — галочка ✓: ячейка выполнена. Суммарное время ~1 час. Браузер автоматически скачал transcript.txt.
Качество результата
Модель medium на русском языке работает хорошо. Типичные проблемы:
Имена собственные — расшифровывает фонетически: «AnyLogic» → «Энилоджик»
Технические аббревиатуры — угадывает через раз
Слова-паразиты и оговорки — транскрибирует честно, всё подряд
Перекрёстный разговор — склеивает в кашу
Для извлечения смысла и структурирования идей — вполне достаточно.
Что использовать когда
YouTube субтитры — если можете подождать несколько часов/дней
WhisperDesktop локально — если GPU без проблем с DirectCompute
Google Colab — быстро, без установки, ~1 час на CPU или ~15 мин на GPU
openai-whisper локально через pip — если есть RTX 30xx+: whisper video.mp4 --language Russian --model medium
Транскрипт нам нужен был для анализа рабочей встречи по математической модели здоровья сотрудников. О самой модели — в других постах.1