Промпт-инжиниринг — это не магия и не «секретные команды». Это структура. Хороший промпт даёт нейросети ровно столько контекста, сколько нужно, чтобы она перестала угадывать и начала точно отвечать на вашу задачу.
Содержание
Почему «просто спросить» — не работает
Формула 1. RTF — самая простая (Role, Task, Format)
Формула 2. RACE — для бизнес-задач (Role, Action, Context, Expectation)
Формула 3. CRISPE — золотой стандарт (6 элементов)
Формула 4. TAG — для быстрых задач
Формула 5. CO-STAR — для контента и копирайтинга
Формула 6. RISEN — для пошаговых инструкций
Формула 7. BAB — для продающего текста
Какую формулу выбрать в зависимости от задачи
В этой статье разберём 7 формул, по которым пишут профессиональные промпт-инженеры. Каждую формулу проиллюстрируем парой «плохой промпт → хороший промпт → результат», чтобы разница была очевидной. После прочтения вы сможете писать промпты, которые с первого раза дают результат уровня платного специалиста.
Почему «просто спросить» — не работает
Большинство пользователей пишут ChatGPT короткие фразы вроде «напиши пост про маркетинг» и получают шаблонный безликий текст. Причина простая: нейросеть не телепат. У неё нет ни вашей аудитории, ни тона бренда, ни контекста бизнеса. Она угадывает по среднему — и выдаёт средний результат.
Хороший промпт — это техзадание, в котором закрыты 4 ключевых вопроса:
Кто отвечает? Какую роль должна примерить нейросеть — копирайтер, маркетолог, юрист.
Что нужно сделать? Конкретная задача с измеримым результатом.
Какой контекст? Аудитория, тон, цель, ограничения.
В каком формате? Длина, структура, наличие списков и таблиц.
Все 7 формул ниже — это просто разные способы упаковать эти 4 элемента. Выбирайте ту, что лучше всего подходит для текущей задачи.
Формула 1. RTF — Role, Task, Format
Самая простая и универсальная формула. Подходит для 80% бытовых задач и идеально для новичков. Состоит из трёх блоков:
Role — кем нейросеть должна себя представить.
Task — что она должна сделать.
Format — в каком виде выдать ответ.
Пример: подготовка к собеседованию
Помоги подготовиться к собеседованию на джуна-разработчика.
Role: ты HR-директор IT-компании с опытом проведения 500+ собеседований. Task: составь список из 10 самых частых вопросов для джуниор-разработчика на Python и образцовые ответы по STAR-формату на основе моего опыта (3 пет-проекта на Django, стажировка 6 месяцев). Format: пронумерованный список, каждый пункт — вопрос, потом ответ длиной 80-120 слов с акцентом на конкретные действия и результаты.
Чёткий список из 10 вопросов с готовыми ответами, которые можно прямо репетировать. Каждый ответ структурирован по формуле «Ситуация — Задача — Действие — Результат». Без воды.
Когда использовать RTF
Когда задача однозначная и не требует длинного контекста: написать письмо, объяснить термин, сделать чек-лист, перевести текст. Если за 60 секунд можете описать задачу другому человеку — RTF подойдёт.
Формула 2. RACE — Role, Action, Context, Expectation
Расширение RTF, в котором добавлены два важных элемента: контекст и ожидание результата. RACE особенно хорош для бизнес-задач, где нужно учитывать специфику аудитории или продукта.
Role — роль нейросети.
Action — что сделать (с глаголом действия).
Context — фон задачи: продукт, аудитория, прошлый опыт.
Expectation — критерий успеха или примеры желаемого результата.
Пример: текст рекламы
Напиши рекламный текст для онлайн-курса по английскому.
Role: ты копирайтер с 7-летним опытом запуска онлайн-курсов. Action: напиши рекламный текст для Instagram-таргета (до 90 знаков для заголовка + до 200 знаков для основного текста). Context: курс «Английский для IT-специалистов за 3 месяца», ЦА — мидл-разработчики 25-35 лет, которые проваливают собеседования из-за слабого устного английского. Цена курса — 19 900 руб. Expectation: текст должен закрывать боль «трудно говорить, хотя читаю статьи» и приводить к клику на лид-форму. Используй формулу AIDA. Дай 3 варианта.
3 готовых варианта объявления, разные по эмоциональному регистру: рациональный, провокационный, поддерживающий. Каждый укладывается в лимиты, закрывает указанную боль и заканчивается мягким CTA на регистрацию.
Когда использовать RACE
Когда нужен текст с учётом аудитории и продукта: рекламные креативы, описания товара, скрипты звонков, презентационные материалы. Контекст в RACE — главный элемент, который делает результат уникальным, а не шаблонным.
Формула 3. CRISPE — золотой стандарт промпт-инжиниринга
CRISPE — самая полная формула, разработанная инженерами Anthropic. 6 элементов, каждый из которых снимает одну из типичных проблем плохих промптов.
Capacity (Capacity & Role) — кто и в какой роли отвечает.
Insight — контекст и предыстория.
Statement — сформулированная задача.
Personality — тон и стиль ответа.
Experiment — просьба дать несколько вариантов.
Шестой элемент — это «E» в названии: попросить нейросеть дать несколько разных подходов, чтобы вы могли выбрать лучший.
Пример: сценарий лонгрида
Напиши статью про продуктовую аналитику.
Хороший промпт по CRISPE:
Capacity: действуй как ведущий продакт-менеджер крупного российского IT-сервиса с опытом запуска 3 успешных продуктов. Insight: в 2026 году в России растёт спрос на продуктовую аналитику в B2C-сегменте, при этом большинство курсов копируют американские кейсы, оторванные от российских реалий. Statement: напиши SEO-лонгрид «Продуктовая аналитика в России 2026: как метрики помогают расти» на 2500 слов. Personality: тон — экспертный, но без академизма. Используй короткие предложения, конкретные кейсы российских компаний, цифры. Experiment: дай 3 варианта структуры (разные углы захода) — я выберу один, и ты его развернёшь полностью.
3 разных каркаса: первый — «по этапам продуктовой воронки», второй — «по типам бизнеса», третий — «через типичные ошибки команд». Дальше можно выбрать лучший и попросить развернуть в готовую статью.
Когда использовать CRISPE
Когда задача стратегическая и важно получить максимум вариативности: контент-стратегии, концепции рекламных кампаний, структуры лендингов, бизнес-планы. CRISPE медленнее в написании, но окупается за счёт качества первого результата — экономит 2-3 итерации.
Формула 4. TAG — Task, Action, Goal
Минималистичная формула для быстрых задач. Когда нужен ответ «здесь и сейчас», а на длинный промпт нет времени.
Task — что нужно сделать.
Action — как это сделать (метод/инструмент).
Goal — зачем это нужно (целевой результат).
Пример: оптимизация письма
Task: сократи следующее письмо. Action: оставь только ключевую мысль, убери канцеляризмы и повторы, упрости конструкции. Goal: получатель должен понять суть за 15 секунд чтения и согласиться на встречу. Текст письма: [вставлен текст].
Письмо в 2-3 раза короче, с понятным CTA в конце. Тон сохранён, но текст стал плотным — ничего лишнего.
Когда использовать TAG
Для типовых рутинных задач: переписывание, перевод, краткое содержание, форматирование. Если задача занимает у вас меньше 5 минут вручную — TAG идеально подойдёт.
Формула 5. CO-STAR — для контента и копирайтинга
CO-STAR разработана специально для задач, где важен тон голоса и адаптация под аудиторию. Ключевая фишка — отдельные блоки для стиля, тона и аудитории.
Context — фон задачи.
Objective — измеримая цель текста.
Style — стилистика (например, как у конкретного автора).
Tone — эмоциональный регистр.
Audience — детальное описание читателя.
Response — формат вывода.
Пример: пост в Telegram-канал
Напиши пост в Telegram-канал про юнит-экономику.
Хороший промпт по CO-STAR:
Context: я веду экспертный Telegram-канал о бизнесе для предпринимателей в нише EdTech. Аудитория устала от мотивирующих постов, ценит конкретику. Objective: пост должен дать одну мысль о юнит-экономике, после которой подписчик пересмотрит свою воронку продаж. Цель — 100+ репостов. Style: пишу как Оскар Хартманн — короткие предложения, реальные цифры, личный опыт. Tone: спокойный, без восклицаний, без эмодзи. Audience: предприниматели 30-45 лет с выручкой 5-50 млн рублей в месяц, отвечающие сами за маркетинг. Response: пост на 700-800 знаков с пробелами, без хэштегов.
Пост, который читается за 90 секунд, содержит конкретный пример с цифрами (например, «снизил CAC с 4500 до 2700 за счёт переноса 70% бюджета из таргета в SEO») и заканчивается провокационным выводом, заставляющим репостить.
Когда использовать CO-STAR
Для контента, где провал — потерять голос бренда: посты в соцсетях, рассылки, статьи, корпоративные блоги. Чем точнее опишете аудиторию и тон, тем ближе текст будет к вашему стилю.
Формула 6. RISEN — для пошаговых инструкций
Когда нужен не просто текст, а структурированный план или гайд. RISEN строит ответ как алгоритм — с проверяемыми этапами.
Role — роль нейросети.
Instruction — главная задача.
Steps — сколько шагов и в каком виде представить.
End goal — что считается успехом.
Narrowing — ограничения, что нельзя делать.
Пример: план запуска товара
Помоги запустить продукт на маркетплейсе.
Role: ты опытный категорийный менеджер Wildberries с 5-летним стажем. Instruction: составь пошаговый план запуска нового товара (электронные весы для кухни) с нуля до первых 100 продаж. Steps: 12 шагов, по каждому — название, длительность, ответственный, чек-лист действий. End goal: к концу 60-го дня — стабильные 5+ продаж в день и рейтинг от 4.7. Narrowing: не предлагай платное продвижение через WB Promotion в первые 30 дней; не учитывай работу с блогерами; бюджет на запуск — до 80 тыс. рублей.
Готовый план в формате Gantt-таблицы: каждый шаг с дедлайном, ответственным, конкретными действиями. Учитываются ваши ограничения — никаких рекомендаций «купите рекламу за 200 тысяч».
Когда использовать RISEN
Для процессных задач: инструкции, дорожные карты, чек-листы, технологические процессы. Главная сила RISEN — блок Narrowing, который защищает от «общих советов из интернета».
Формула 7. BAB — Before, After, Bridge
Формула из мира копирайтинга, адаптированная для промптов. Идеально подходит для продающего текста, лендингов и презентаций.
Before — текущее состояние / проблема клиента.
After — желаемое состояние после решения.
Bridge — как ваш продукт переводит из Before в After.
Пример: лендинг услуги
Напиши лендинг для агентства по таргетированной рекламе.
Напиши заголовок и первый экран лендинга агентства таргетированной рекламы по формуле BAB. Before: владельцы малого бизнеса в регионах сливают 40-60% рекламного бюджета на неэффективный таргет, ведут его сами без аналитики, не понимают цифры. After: после работы с агентством за 30 дней получают воронку с ROMI > 200%, прозрачные отчёты раз в неделю и контроль над каждым рублём. Bridge: наша методология — выделенный аналитик и медиабайер на проект, A/B-тесты на каждом этапе, гарантия возврата комиссии при недостижении KPI. Стиль — статусный, без воды, с измеримыми обещаниями.
Заголовок типа «Перестаньте сливать 40% бюджета на таргет — выйдите на ROMI 200% за 30 дней или вернём комиссию», подзаголовок с конкретикой методологии, 3 буллета социальных доказательств. Готовый текст под главный экран.
Когда использовать BAB
Для всего, где нужно «продать» — лендинги, рекламные ролики, презентации инвесторам, клиентские email-рассылки, питч-деки. Формула работает потому, что повторяет механику принятия решения покупателем: «есть проблема → представлю себя без неё → купить».
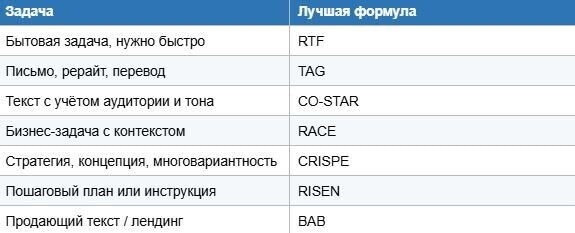
Какую формулу выбрать в зависимости от задачи
Запоминать названия не нужно. Достаточно понять принцип: чем больше блоков в промпте — тем точнее результат. Но баланс важен: для простой задачи длинный промпт — оверкилл, для сложной короткий — недодача контекста.
Главная ошибка новичков и как её избежать
Самая частая ошибка — не указывать роль и аудиторию. Без роли нейросеть пишет «обычным языком», без аудитории — «для всех и ни для кого». Если в вашем промпте нет ни Role, ни Audience — переписывайте.
Второй уровень ошибки — отсутствие критериев успеха. Нейросеть не знает, какой ответ для вас «хороший». Без явных критериев («должен поместиться в 500 знаков», «должен закрыть возражение Х») вы получаете middle-of-the-road результат, который придётся доводить вручную.
Что делать дальше
Возьмите любую формулу из этой статьи и протестируйте её на трёх задачах из своего рабочего бэклога. Сравните результат с тем, как вы пишете промпты сейчас. Уверен: качество ответов вырастет в 2-3 раза с первой же попытки.
А чтобы не тратить время на перебор — есть готовый каталог из 104 проверенных промптов по 10 категориям (маркетинг, копирайтинг, программирование, аналитика и так далее). Каждый промпт построен по одной из формул выше — копируйте, подставляйте свои данные, получайте результат.