ИИ научился вскрывать чужой код быстрее любого хакера — и индустрия наконец испугалась этого по-настоящему. На этой неделе Linux Foundation вместе с двумя десятками крупнейших корпораций объявила Akrites — коалицию, которая будет латать дыры в открытом софте раньше, чем до них доберутся злоумышленники с ИИ. И это уже не первый такой «общий сбор».
Что такое Akrites. Это единый, конфиденциальный штаб по устранению уязвимостей в том самом open-source, на котором держится критическая инфраструктура всего мира. Среди отцов-основателей — AWS, Google, Microsoft, OpenAI, Anthropic, NVIDIA, IBM, Cisco, Red Hat, Rust Foundation, JPMorgan, Citi и другие. Запуск состоялся 26 июня, финансирование идёт через фонд Alpha-Omega под крылом Linux Foundation.
Как это работает. Вместо десятков разрозненных багрепортов, которые сыплются на измотанных мейнтейнеров, Akrites даёт единую команду реагирования (SIRT) и стандартный процесс координированного раскрытия — с CVE, оценкой по CVSS и протоколом конфиденциальности TLP (всё стартует на уровне TLP:RED). Отдельная фишка — роль «мейнтейнера последней надежды»: если критичный, но заброшенный пакет некому чинить, патч выпустит сам Akrites.
Почему именно сейчас. Как формулируют сами авторы, «современные ИI-модели сканируют большой проект за минуты вместо недель». Это меняет баланс: уязвимости вскрываются быстрее, чем их успевают чинить, а сложные эксплойты становятся доступны даже непрофессионалам. Значит, и оборона обязана стать ИИ-скоростной — иначе атакующие всегда будут на шаг впереди.
Akrites не одинок. Ещё в апреле Anthropic запустила Project Glasswing: её фронтир-модель Claude Mythos в превью уже нашла тысячи серьёзных уязвимостей — в том числе в каждой крупной операционной системе и браузере. Доступ к ней получили Apple, Google, Microsoft, NVIDIA, AWS, CrowdStrike, Palo Alto Networks и Linux Foundation, а охват расширили до 150 критических организаций. Google параллельно поставила охоту за багами на ИИ-конвейер и публично предупредила: хакеры уже атакуют с помощью ИИ.
Парадокс эпохи. Та же сверхспособность, что напугала регуляторов до экспортных запретов (вспомните недавний бан на иностранный доступ к Anthropic Fable 5 и Mythos 5), теперь становится главным щитом. Вечная гонка брони и снаряда окончательно переехала в исходный код — и от того, кто в ней быстрее, зависит безопасность всего, что работает на open-source. То есть практически всего.
Все началось с того, что outline у меня перестал нормально работать в последнем ubuntu. Ну и плюс у меня в локальной сети куча разных устройств со своими протоколами и хотелось использовать прокси. Hiddify меня всем устраивал, но не понимал ssconf. Перевел его на go 1.26 и flutter SDK 3.44.4. Помимо http теперь почти полностью понимает ssconf:// - можно использовать кучу VPN.
Использую как системный прокси. Для тех, у кого XFCE (lxQt и т.д.) - в них chrome, code и т.п. не умеют правильно читать системный прокси. Надо использовать командную строку типа: all_proxy=socks5://127.0.0.1:12334 google-chrome-stable
Удобно работать на чужих машинах. Только конфиги надо не забывать чистить. Поддерживать его я конечно же не буду - но если надо что-то небольшое добавить - пишите.
Почитал каменты, ощущаю острую необходимость густо надушнить.
1. Для чего нужна SteamOS, если есть Венда?
Тут ответ неоднозначный, потому что номинально Венда делает абсолютно всё то же самое что и SteamOS, только может ещё больше, например одновременно быть и рабочей станцией, и мультимедиа-комбайном для просмотра фильмов, прослушивания и записи музыки и т.д.
И именно поэтому концепция Венды как jack of all trades проигрывает концепции операционки, заточенной под игры. И проигрывает пока что только концептуально, потому что на данный момент шанс того что игры будут болие лудьше идти под Венду - гораздо выше. Поэтому на данный момент в этом вопросе ответ однозначный: на домашних игровых ПК SteamOS это пока лишь удачный эксперимент и возможность громко послать Майкрософт нахуй. Если возникает вопрос "зачем громко посылать Майкрософт нахуй?" то это значит что ты недостаточно опытный пользователь Венды.
2. "Линукс для игр все равно дно, сколько бы протон не пилили."
Буквально лет пять назад я бы ответил точно так же, но сейчас соотношение сил уже начинает меняться. Почему? Проблемы с любыми дистрибутивами линуксов всегда возникали исключительно из-за того что занимаются этими дистрибутивами три с половиной красноглазых линуксоида, а у этих людей очень специфическое понимание того как должна работать операционка. И что важнее - специфическое понимание приоритетов разработки. Если коротко, то можно сказать что у красноглазых недостаточно ресурсов для развития, потому что всё сообщество (и так небольшое) разбито на кучки противоборствующих лагерей, каждый из которых пилит свою систему чуть ли не в одиночку.
В этом смысле поддержка серьёзной компании это огромный плюс, а заточенность SteamOS именно под игры это сам по себе ускоряющий пинок под жопу невероятной силы (в смысле развития платформы). Напомню, что Венда в своё время выехала в том числе на отличной поддержке первого Doom.
3. "Пффф, видеокарта от AMD."
С одной стороны я как геймер солидарен, с другой стороны... тут всё очень сложно. Попробую кратко насколько возможно.
Nvidia сейчас в приоритете, потому что сколько бы ни рассказывали о невероятной мощи видеокарт AMD, по факту алгоритм сглаживания (апскейлер FSR) у них - полное говно. Можно говорить что AMD выдаёт больше фпс на рубль, но по факту все современные игры рассчитаны на использование вместе с апскейлерами. Раньше казалось что вот-вот сейчас заживём и повысим все фопесы во всех играх с навороченной графикой, но потом разработчики вероломно включили апскейлеры в парадигму разработки, и какая-нибудь Gothic 1 Remake нещадно тормозит без DLSS, при этом имея уровень графики десятилетней примерно давности (утрирую, но в целом так).
Здесь ещё был запрятан ответ на вопрос о том, как человечество заживёт после открытия бесконечного источника бесплатной энергии, но этот ответ где-то потерялся.
Далее, в наше время недостаточно иметь объективно лучшие технические характеристики, важно ещё участвовать в большой политике. И тут возникает вопрос на стороне какого лагеря вы выступите? Номинально AMD это свободный софт и поддержка всяких энтузиастов вроде нашей SteamOS - эдакий "свободный Телеграм" где царит неразбериха и беспорядок, глюки и тормоза, но все чувствуют себя "свободными". Nvidia - это "МАХ", т.е. анально огороженные корпораты с закрытым софтом и бездушными проприетарными технологиями, которыми они не хотят делиться. С часто ненужными свистоперделками для прогрева гоев, кои выбрасываются на свалку истории сразу после того как из них были выдоены все деньги (PhysX, Hairworks, Flow, Turbulence, про технологию RTX даже начинать не хочу, тут нужен сайт по-болбше).
Осложняет это всё то что CEO AMD Лиза Су это двоюродная племянница CEO Nvidia Дженсена Хуанга, если вдруг не знали. Подозреваю что у них там всё очень плотно схвачено и AMD нужны как второй игрок в этой монопольной игре в одни ворота. Да, я в курсе что уже есть китайцы и Intel, это новые игроки на рынке GPU, но на данный момент они незначительны.
4. 60 фпс достаточно, 120 для задротов.
Последнее время приколистов, рассказывающих про то что человеческий глаз не видит больше 24 кадров в секунду, стало меньше, ведь появились нейросети, которые могут скомпоновать всю важную информацию так, что читать удобно даже дегенератам.
Уже много писал об этом, но повторюсь: такие разговоры возникают только у тех, кто не пробовал играть на высокой герцовке с большим фпс, на большом экране. Если вы видите человека, который утверждает что 60 фпс достаточно и больше не нужно - он просто никогда не пробовал по-другому. И варианты "да я включал, разницы не заметил" это примерно то же самое, что "да я ездил на вашем Бентли/Феррари/Ламборгини, разницы с ВАЗом не заметил".
К хорошему быстро привыкаешь. Вы готовы вот прямо сейчас играть в 15-20 фпс? Неверное, нет. Точно так же ощущается переход с каких-нибудь 180-240 фпс обратно на 60 - как лютые тормоза. Я спокойно могу ощутить разницу между 60 и 100 фпс, между 100 и 180 фпс.
И если вы вдруг подумали "да ну нафиг, вот ещё привыкну к высокой герцовке и не смогу вернуться обратно и придётся покупать сверхдорогое железо" то я вас поздравляю, вы не зря беспокоитесь, потому что именно так и происходит.
Тут есть парочка нюансов, о которых обычно никто не вспоминает: инпут лаг (отзывчивость управления) и фреймген (генерация кадров).
Не буду разводить сейчас математику, но при тридцати кадрах в секунду об отзывчивости управления не идёт речи вообще никакой. Даже 60 фпс по сравнению с 30 - уже гигантский прирост, и я напомню что до выхода PS5 у консольщиков считалось нормой иметь в ААА-игре 30 кадров. Я думаю, можно легко откопать треды, где они кричат о том что только пека-задротам нужно больше 30 кадров =) Так вот, я помню замечательный момент когда эмулировал The Legend of Zelda: Breath of the Wild на ПК, и в процессе перешёл с 30 кадров на 90-120. Божечки, какой это был славный глоток свежего воздуха! С пальцев как будто сняли кандалы и парировать всяких левров, делать бекфлипы и просто бегать по игровому миру стало в разы приятнее. Это был замечательный пример того, чего можно добиться, просто увеличив герцовку в игре с приличной экшен-составляющей.
Далее, фреймген. Фактически это ещё одна "инновация" от Nvidia, которую подхватили другие, хотя в целом технология не нова. Проблема тут в том, что раскукожив свою игру с нативных 30 кадров в 120+ ты всё равно не получишь такое же приятное и гладкое как попка младенца управление, как при нативных 120+ кадрах. Но разработчики взяли фреймген и прямо сейчас, на наших глазах, встраивают его в парадигму разработки. Поэтому условная Gothic 1 Remake прямо-таки ТРЕБУЕТ, чтобы ты включил DLSS, включил фреймген, взял флаг в руки, повесил барабан на шею... кхем, короче, начинает тебя прогревать. А изначально фреймген должен был генерировать тебе 240 кадров из твоих нативных 120, а не вот это вот всё.
Итого, как выглядит игровой процесс здорового человека: имея мощную видеокарту от Nvidia, он запускает графически тяжёлую игру, играется с настройками так, чтобы не использовать слишком жирные настройки которые почти никак не улучшают картинку, и добивается ХОТЯ БЫ 60 нативных кадров. После чего DLSS скукоживает картинку до более низких разрешений без потери качества картинки и фпс вырастает ещё. И вот теперь уже поверх этого можно намазать фреймген, который даст тебе минимум 120 кадров, которые хотя бы будут радовать твои глаза, даже если желейное управление при нативных 60 фпс не.
Важно помнить что существуют игры, где количество фопесов действительно не так важно. Например, пошаговые стратегии, медленные хорроры без стрельбы, спокойные сюжетно-ориентированные игры и множество инди-проектов. Если это не экшен с быстрым геймплеем, то 60 фпс обычно вполне достаточно и нет смысла как-то уж сильно стараться чтобы выжать больше.
Суммируя всё вышесказанное:
1. SteamOS это рабочий, многообещающий задел на будущее, но на данный момент нужен только энтузиастам.
2. Линкус вполне подходит для игр, и в данный момент боеспособен как никогда раньше, пусть и работает неидеально. Но если ты счастлив, играя на Венде, переходить на SteamOS пока нет смысла.
3. AMD или Nvidia? Решать только тебе. Лично я выбираю Nvidia, чтобы видеть лучшую картинку и иметь доступ к cutting-edge технологиям, которыми я иногда пользуюсь. Это не означает что AMD это нерабочий кусок железа.
4. Чем больше фпс - тем лучше. Но гонясь за кадрами, не забывай что фопесы это результат слаженной работы кучи разных софтово-железных механизмов под капотом твоего ПК и не единственное мерило приятного геймплея.
Телеграм, ВКонтакте, Дзен, Макс — площадок становится все больше, а вот внимание аудитории по-прежнему ограничено. Что делать? Продвигать!
На Пикабу можно рекламировать свои каналы прямо в лентах сайта. Находите новую аудиторию и получайте живые переходы без сложных рекламных кабинетов.
Подойдет для:
авторских и экспертных блогов
бизнеса
медиа и новостных каналов
мемных и развлекательных сообществ
Запускается просто: добавляете ссылку, пишете заголовок и краткое описание и выбираете географию для показов. А дальше о вашем канале узнают тысячи пользователей Пикабу!
Подробное руководство по ускорению любимого браузера подручными средствами. В помощь домохозяюшкам, студентам и высшему руководству — всем у кого нет под рукой топового железа с 64Гб памяти для работы в современном интернете.
В качестве демонстрации. FreeBSD и ноутбук 2007 года, но ниже будет и про ваши любимые Windows c Linux
❯ Хром
Браузер Chrome, созданный и разрабатываемый корпорацией Google давно стал главным инструментом для большинства пользователей компьютерной техники:
в вашем телефоне, планшете, телевизоре, ноутбуке и стационарном компьютере в подавляющем большинстве случаев будет установлен именно этот браузер, либо что-то на его основе.
Два вечных конкурента в виде браузеров Opera и Internet Explorer сдались в попытке угнаться за прогрессом и ныне используют под капотом движок от Chrome.
Так что Google это мировой монополист в области браузеростроения, Chrome — его самый популярный продукт и фактически главное приложение для большинства современных пользователей.
Даже эта статья создавалась с помощью браузера Chrome:
❯ Скорость
Конечно высокооплачиваемые разработчики самого популярного браузера на планете, щедро финансируемые «корпорацией добра» — не полные идиоты и разбираются в вопросах производительности собственного продукта гораздо лучше автора.
Но только проблемы производительности на дешевом, устаревшем и тем более неподдерживаемом оборудовании сотрудников Google... мягко говоря не очень волнуют.
Поэтому в очередной раз простому пользователю, не желающему продавать почку ради современного компьютера, придется заботиться о себе самостоятельно. Чем мы сейчас и займемся.
Применимость
Описываемые ниже инструкции — для десктопной версии браузера Chrome и с учетом специфики трех разных операционных систем: Windows, Linux и FreeBSD.
Мобильная версия браузера довольно сильно отличается, но также поддается подобной настройке. Однако чтобы не раздувать статью — про тюнинг мобильной версии расскажу в следующий раз.
Замечу также, что эта статья — далеко не самый возможный максимум оптимизации и если Господь наградил вас знанием языка С++, дав в руки компилятор, то сотворить с браузером можно гораздо больше.
Но тут все же для обычных людей, не обезображенных высшим техническим образованием и навыками системного программирования.
Производительность
Я использую браузер Chrome на ноутбуках с момента его появления и часто работаю «в поле» — от батареи и без подключения к розетке. Помимо браузера на машине постоянно присутствуют еще несколько тяжелых приложений — в первую очередь среды разработки и разнообразные редакторы.
Все это в итоге формирует следующий набор требований:
браузер не должен нападать на человека забирать на себя все доступные ресурсы;
браузер не должен «сжирать» батарею ноутбука;
браузер должен продолжать работать с современными сайтами, сохраняя отзывчивость интерфейса.
Время «холодного запуска» и скорость отрисовки страниц при таких вводных разумеется могут пострадать, но будут оставаться в пределах разумного.
Версии и названия
Чтобы не было путаницы, стоит сразу прояснить ряд нюансов с названиями продуктов и используемыми терминами.
Официально браузер от Google называется «Chrome» и поставляется (даже для Linux) в виде готовой сборки с инсталлятором, т.е. это закрытый коммерческий продукт, хотя и бесплатный для пользователя.
Именно эта версия доступна для скачивания с официального сайта и имеет максимальную интеграцию с сервисами и другими продуктами Google.
Открытая часть браузера Chrome называется «Chromium» и с точки зрения обычного пользователя никак не поставляется, поскольку Chromium предназначен в первую очередь для технических специалистов, участвующих в процессе разработки и тестирования.
Именно Chromium а не Chrome чаще всего установлен по-умолчанию в различных дистрибутивах Linux, в виде сборки от ментейнеров дистрибутива.
Наконец существует проект «Ungoogled Chromium», авторы которого постарались удалить из Chromium абсолютно все интеграции с сервисами Google и все закрытые инструменты сборки.
Ungoogled Chromium за последние годы набрал популярность, поэтому активно используется в BSD-системах и дистрибутивах Linux, ориентированных на безопасность.
Поскольку использование сервисов Google в наше непростое время может приводить к непредсказуемым проблемам и сбоям подключения, я буду использовать для всех описываемых оптимизаций Ungoogled Chromium либо просто Chromium, но не официальный Google Chrome.
Тем не менее для простоты повествования, в статье используется термин «Chrome» в качестве обозначения браузера, поскольку описываемые методы оптимизации полностью совпадают и частично применимы и к другим браузерам на основе Chromium.
Тестовая среда
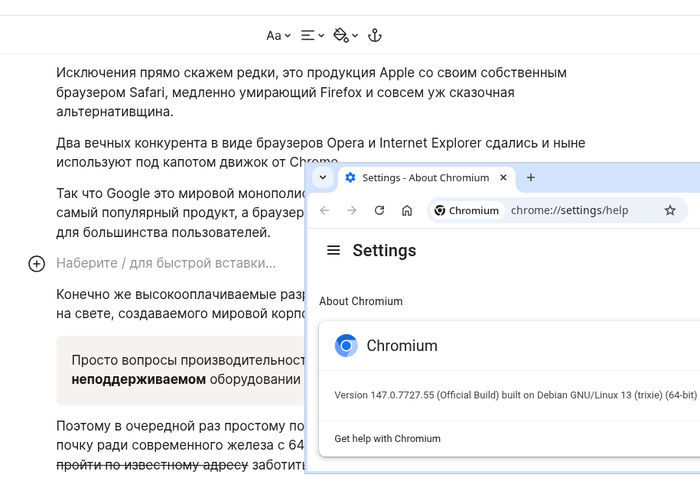
Для статьи использовались современные 64-битные сборки браузера, с версиями начиная с 147 и выше:
147.0.7727.101 (Official Build) (64-bit)
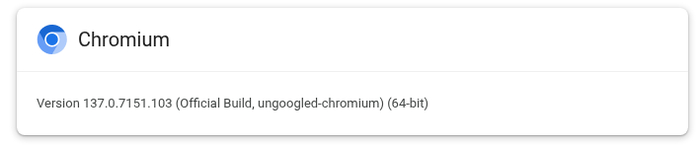
Ungoogled Chromium имеет свою собственную нумерацию версий, отличную от оригинальной, для этой статьи использовались версии 137 и выше:
Под различными операционными системами использовались разные версии браузера, но во всех случаях — самые последние из доступных на момент написания статьи. Замечу также, что описанные оптимизации постоянно используются на всех моих ноутбуках, как мощных и современных, так и откровенно.. винтажных.
Поскольку разницу лучше всего видно на устаревшем оборудовании, в качестве тестовой среды будут использованы два настоящих «боевых пенсионера»:
Эти весьма устаревшие по любым меркам (особенно второй) машины станут отличным тестовым полигоном для демонстрации результатов всех описываемых вивисекций оптимизаций.
❯ Оптимизация
Поскольку целевая аудитория статьи — обычные пользователи, не владеющие с пеленок компилятором и отладчиком, ограничусь тремя вариантами оптимизации браузера, доступными без залезания непосредственно в код:
хитрые настройки, хитрые плагины и хитрое окружение.
Все ради того чтобы крутить ленту каких-нибудь Reddit/LinkedIn без зависания браузера и 100% загрузки процессора.
Так выглядит работа браузера со всеми оптимизациями на Ubuntu Linux и ноутбуке 2012 года
❯ Chrome и Linux
Так исторически сложилось, что я использую много разных Linux-дистрибутивов в своей непростой деятельности:
Сразу уточню, что Calculate Linux (на базе Gentoo) использует OpenRC вместо systemd, поэтому трюк с systemd-run тут не используется, но все остальные инструкции отлично работают на всем этом зоопарке и по своей сути применимы для любого окружения на базе Linux, везде где есть браузер Chrome.
Начнем со скрипта запуска браузера, в котором специальными параметрами включаются или отключаются разные хитрые опции, а также используется специальное окружение:
Сохраняете текст выше в какой-нибудь /opt/own/bin/chrom, выставляете бит запуска:
chmod +x /opt/own/bin/chrom
И используете этот скрипт для первого запуска браузера.
Стоит напомнить, что символ \ отвечает за перенос строк, т.е. для программы весь набор параметров выше это одна длинная строка.
Если при копировании текста что‑то сломается — просто удалите все \ и сведите все в одну длинную строку — так тоже запустится.
Переназначать обработку всех HTML-страниц в рабочем окружении на этот скрипт не стоит, поскольку процессы браузера Chrome умеют общаться между собой и пока есть хоть один работающий процесс — его настройки будут использоваться для запуска новых копий.
Теперь рассказываю страшную сказку про «прожорливый» Chrome и пропавшую память, точнее про эту интересную строку:
Дело в том, что у браузера Chrome есть дурная привычка считать весь компьютер своей собственностью и захватывать максимум доступных ресурсов — всю свободную память и все доступные процессоры и ядра.
Пока вы работаете на сервере современной машине с кучей памяти, не держите открытыми сотни вкладок с графикой а конкуренцию браузеру за доступные ресурсы составляет только офисный пакет — проблемы нет.
Но стоит лишь немного просесть по мощности используемого оборудования или доступным ресурсам для более прожорливых программ (привет Davinci Resolve) и любимый браузер от «корпорации добра» немедленно показывает звериный оскал свое истинное лицо.
В случае ноутбука (тем более мощного) немедленно проявляется еще один дурной эффект:
скачки бесконтрольной нагрузки, создаваемой браузером очень быстро разряжают батарею.
Так что становится жизненно необходимым сажать браузер на ресурсную диету с помощью systemd и функционала cgroups.
Делается это в современных Linux-дистрибутивах довольно просто, для начала создаем файл ~/.config/systemd/user/chromium.slice со следующим содержимым:
Помимо очевидных лимитов на объем используемой памяти (MemoryHigh и MemoryMax), тут еще задается квота на загрузку процессора (CPUQuota), что не дает поднять ее выше заданного лимита — 100% загрузку CPU от процессов Chrome вы больше не увидите.
Теперь самое важное:
все указанные лимиты применяются ко всем дочерним процессам, которые запускает Chrome во время работы.
По сути этим создается специально ограниченный по ресурсам контейнер, внутри которого запускается браузер.
Ну и сам запуск с помощью черной магии systemd-run и указания слайса:
Аналогичным образом можно ограничивать по ресурсам любые другие «жирные» приложения, например Telegram, который в последних версиях повадился генерировать 100% загрузку процессора по любому поводу.
Замечу, что сей хитрый трюк работает и с приложениями, работающими внутри AppImage или snapd-пакетов, так что с его помощью замечательно урезаются аппетиты версий Chrome/Chromium в Ubuntu/Manjaro, управляемые snapd.
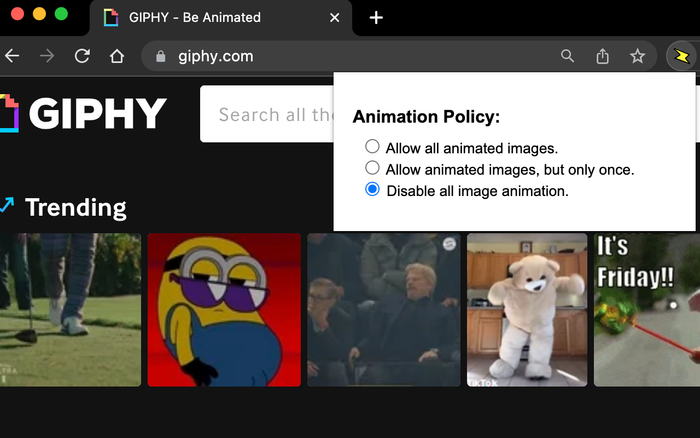
Отключение анимации в действии
❯ Отключение анимации
Существует одно интересное расширение для Chrome, позволяющее отключать анимированные картинки на всех страницах:
вместо мигающей хтони анимации будет отображаться один статичный кадр.
Нетрудно догадаться, что этим сильно снижается нагрузка на CPU/GPU (особенно в случае устаревшего оборудования), с чего происходит серьезная экономия заряда батареи.
Так что очень рекомендую к использованию.
Ungoogled Chromium и установка расширений
К сожалению для установки расширений из официального магазина для «левого» Ungoogled Chromium необходимо специальное расширение, без которого вас обрадуют ошибкой:
CRX_REQUIRED_PROOF_MISSING
А кнопка установки в интерфейсе магазина окажется скрытой.
В качестве альтернативного варианта можно использовать специальный сайт от авторов расширения, который позволяет скачать пакет с расширением .crx и установить его локально в вашем браузере.
Теперь переходим к самому интересному — к параметрам запуска.
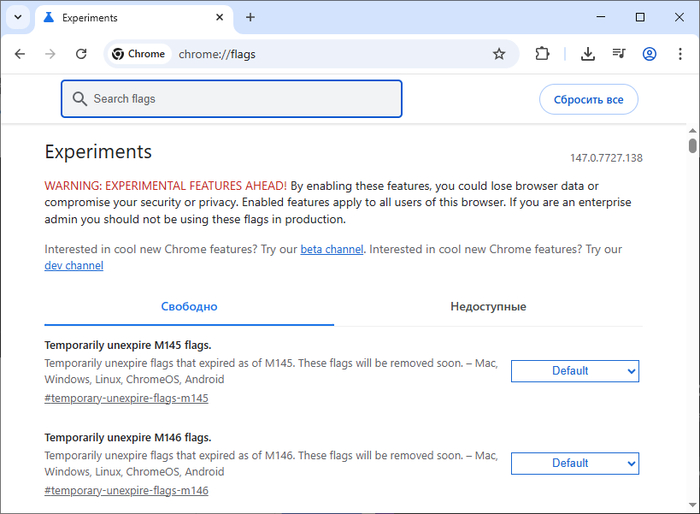
❯ Параметры Chrome
У браузера Chrome есть огромное количество разнообразных параметров запуска, как документированных так и не очень. Часть из них дублируется во внутреннем служебном интерфейсе chrome://flags/, часть — нет.
Так выглядит служебный интерфейс с настройками браузера Chrome
Поскольку прямого соответствия именований между параметром запуска и названием опции нет, не стал описывать в статье вариант настройки через переключение опций.
Тем более что ряд опций, доступных через служебный интерфейс не имеют отдельного параметра запуска.
Этих самых параметров настолько много, что был создан отдельный сайт, посвященный только лишь их описанию, регулярно выгружаемому непосредственно из исходного кода браузера.
Так выглядит небольшая часть параметров в динамике:
Тут показано менее 1% всех параметров запуска браузера
С учетом постоянного устаревания и регулярных ломающих изменений в функционале браузера, нет ни возможности ни особого смысла описывать абсолютно все, поэтому ниже только те параметры, которые постоянно используются на моих машинах в целях оптимизации.
Параметр --enable-features= как нетрудно догадаться из названия используется для принудительного включения опций браузера.
В данном случае принудительно включаются кодеки для аппаратного декодирования видео, работающие на базе Video Acceleration API (VAAPI).
По-умолчанию, если библиотека VAAPI в системе не установлена либо работает неправильно, браузер автоматически переключится на медленный программный кодек, с чего будет сильно нагружаться процессор при проигрывании видео.
С данной настройкой, при проблемах с VAAPI браузер либо перестанет запускаться совсем, либо покажет явную заглушку вместо видео — таким образом появится однозначный сигнал о серьезной проблеме.
Комфортно смотреть видео даже на современном железе без работающего VAAPI вряд ли получится из-за сильной загрузки процессора, поэтому настройка актуальна для всех пользователей.
Chrome 37 introduced a GPU rasterizer. When enabled, some paint workloads can go from 100ms/frame to 4-5ms/frame.
Несмотря на то что опция является «экспериментальной» и вроде как работает не во всех случаях — ее включение это единственный вариант комфортного использования современного браузера на устаревшем железе.
Запрещает браузеру использовать фоновые сетевые запросы, например проверку обновлений для установленных расширений.
--disable-client-side-phishing-detection
Отключает фоновую проверку сайтов на фишинг.
Этот параметр вроде как удален в новых версиях браузера, но все еще часто встречается в различных руководствах и материалах.
Фоновое обновление этих баз отнимает ресурсы а сама проверка плохо работает в современных реалиях разделенного интернета, поэтому отключаем.
--disable-prompt-on-repost
Отключает дурацкое предупреждение о повторной отправке формы:
--disable-sync
Отключает облачную синхронизацию учетной записи Google.
Актуально только для обычного Chromium, для ungoogled-версии не используется, поскольку функционал глобальной учетной записи там вырезан.
--metrics-recording-only
Указывает браузеру только записывать отчеты с метриками производительности, но запрещает отправлять их на сервера Google. Отчеты сохраняются в текущем профиле, актуальны при поиске проблем с медленной работой браузера или отдельных сайтов.
--no-first-run
Отключает приветственный диалог при первом запуске браузера.
--safebrowsing-disable-auto-update
Отключает автоматическое фоновое обновление баз для «Safe Browsing» — специального сервиса Google для защиты от фишинга и подозрительных сайтов. Актуально для обычного Chromium, поскольку в ungoogled‑версии функционал «Safe Browsing» удален.
--ignore-gpu-blocklist
Натурально заставляет браузер «работать на дровах» — использовать неподдерживаемое и устаревшее оборудование для аппаратного ускорения.
Очень важная опция, без указания которой браузер тихо и цинично включит программную отрисовку ничего не сказав пользователю, с чего скорость отображения страниц сильно упадет.
--renderer-process-limit=2
Еще один «магический» параметр, критически влияющий на производительность браузера и потребляемые ресурсы:
именно с его помощью переопределяется лимит на количество запущенных процессов отрисовки страниц — самых тяжелых процессов браузера, создающих основную нагрузку на систему.
Количество таких процессов напрямую влияет на потребляемые ресурсы, поэтому в случае ограниченных ресурсов стоит выставить какое-то небольшое число.
--disable-smooth-scrolling
Просто «имба» за которую вы потом будете благодарить — параметр отключает плавную прокрутку в браузере, которая очень сильно влияет на скорость при работе на слабом или устаревшем оборудовании.
Влияет настолько сильно, что разницу становится видно визуально после перезапуска.
--wm-window-animations-disabled
Отключает практически всю анимацию во внутренних интерфейсах браузера — там где опции настроек, закладки и расширения.
--animation-duration-scale=0
Переопределяет длительность воспроизведения CSS-анимации, значение 0 означает полное отключение, но работает к сожалению только для элементов интерфейса самого браузера, не для страниц.
--disable-spell-checking
Отключает фоновую проверку правописания, которая серьезно влияет на скорость работы браузера (вплоть до подвисания страниц).
--enable-unsafe-swiftshader
Еще один важный параметр, который разрешает использование «небезопасного» программного рендера WebGL, что позволяет использовать 3D-графику в браузере даже на устаревшем оборудовании, которое не поддерживает современное Vulkan API.
Данный параметр по прямой аналогии с описанным в самом начале --enable-features= переопределяет опции браузера, которые необходимо отключить.
В данном случае отключаем встроенную рекламу новых фич браузера, которые вылезают при обновлениях и очень сильно бесят отвлекают.
Актуально только для обычного Chromium, поскольку в ungoogled-версии все эти радости вырезаны целиком.
Теперь рассказываю для самой широкой аудитории — про оптимизацию браузера под Windows.
Прокрутка ленты Reddit в качестве демонстрации, поскольку Reddit — один из самых «тяжелых» популярных сайтов, известных автору
❯ Хром и Windows
Я использую Windows 11, 10 и 7 на рабочих станциях а также множество разных виртуальных машин с серверными версиями Windows.
Поскольку оптимизации актуальны только при использовании браузера на рабочей станции (мало кому интересно работать из браузера прямо с сервера, правда?), поэтому в качестве тестовой среды будут выступать только три пользовательских версии Windows: 11, 10 и 7.
Технические характеристики машины из ролика с лентой Reddit
Сохраняете текст выше в файле run.cmd, кладете в каталог рядом с chrome.exe и используете для первого запуска.
Используемые параметры браузера и их логика полностью совпадают с описанными выше для Linux, шаги по установке расширения для отключения анимации также полностью аналогичны.
Замечу, что символ ^ — аналог \ в UNIX-мире и используется для переноса длинных строк в командных скриптах под Windows.
Если что‑то перенесется неправильно — просто удаляете символы ^ и сводите все в одну длинную строку.
Также добавлю, что в последние версии и Chrome (и даже Chromium) под Windows авторы напихали AI-фич под завязку, поэтому на моих рабочих станциях с Windows ныне используются только и исключительно Ungoogled-сборки.
Ungoogled Chromium на Windows 7 со всем тюнингом. Справа менеджер задач и загрузка памяти
Chrome и старые Windows
Официально Google перестала поддерживать Windows 7 для Chrome/Сhromium еще в 2023 году, поэтому если у вас осталась живая «семерка» и есть необходимость использовать современный браузер — будут определенные сложности.
Обратите внимание на версию браузера и дату сборки
Цитируя одну известную шутку: чем бы вы ни занимались — обязательно найдется азиат, который сделает еще круче. В случае с портированием Chrome на устаревшие версии Windows именно так и произошло:
стоило только начать изучать вопрос и доступные варианты — немедленно нашелся репозиторий со сборками последних версий Chrome... под Windows XP!
Windows XP вышла в далеком 2001м году и процесс портирования под настолько старую ОС был весьма непростым занятием. Вот тут выложены готовые сборки браузера под Windows XP с поддержкой аппаратного ускорения (!) — невероятный хардкор.
Теперь переходим к разделу для самых ярых фанатов своего дела.
Да, это современная сборка браузера Chrome, летающая на антикварном оборудовании. Без записи с экрана все работает еще быстрее
❯ Chrome и FreeBSD
Наконец последним разделом описываю то, с чего началась эта статья в далеком 2023-м году:
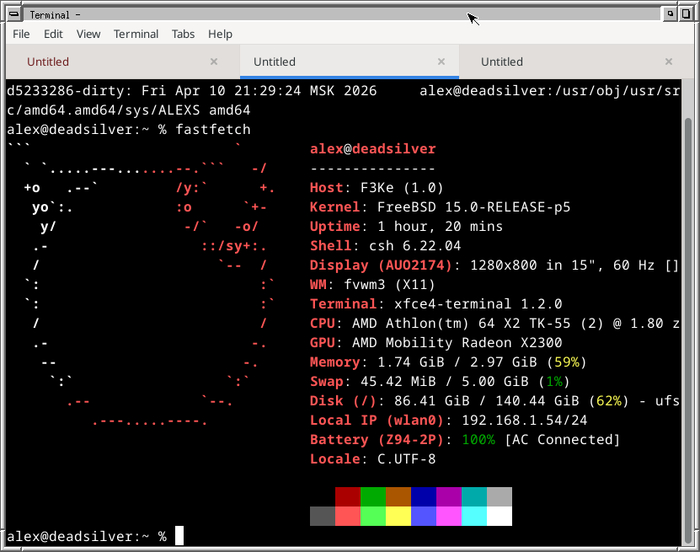
оптимизация работы браузера Chrome под FreeBSD на очень сильно устаревшем оборудовании.
«Очень сильно устаревший» — про тот самый Asus F3KE из 2007 года, спасенный автором от достойного погребения за долгую службу.
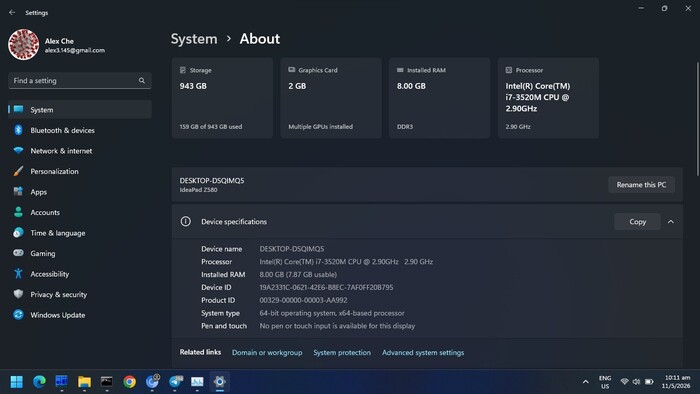
Так выглядит вывод fastfetch с описанием оборудования:
Конечно же для столь мощного колдунства пришлось провести немало нечистых ритуалов оптимизаций (начиная с кастомного ядра), но как минимум половина производительности — результат подбора правильных параметров браузера.
на самом деле скрывает портал в ад отдельный механизм повторного использования сессии DBus, подключаемый тут файл ~/.exports.sh создается вот таким специальным скриптом:
#!/usr/local/bin/bash
FF=0
if [[ -z $DBUS_SESSION_BUS_ADDRESS ]]; then lines=$(pgrep "dbus-daemon" -u "$USER" | (while read -r line do echo $line exp=`procstat -h -e $line` if [[ "$exp" == *"DBUS_SESSION_BUS_ADDRESS="* ]]; then echo "DBus session found" exp2=`echo $exp |sed 's/.*DBUS_SESSION_BUS_ADDRESS=\([^ ]*\).*/\1/'` echo export DBUS_SESSION_BUS_ADDRESS="$exp2" > ~/.exports.sh FF=1 break fi done; echo $lines) ) echo $FF if [[ "$FF" = 8 ]]; then echo "DBus session not found, starting.." dbus_out=`dbus-launch` echo $dbus_out > ~/.exports.sh fi if [[ -f ~/.exports.sh ]]; then source ~/.exports.sh fi fi
Этот скрипт натуральным образом ворует сессию работы с DBus, забираясь в окружение другого запущенного процесса (да, так можно было) — все ради того чтобы не запускать процесс dbus-launch повторно.
Помимо приседаний с параметрами, в версии для FreeBSD также используется описанное выше расширение браузера для отключения анимации, но вместо изоляции через cgroups используется более простой вариант со сниженным лимитом на количество запущенных процессов рендера:
--renderer-process-limit=2
Чего вполне достаточно для комфортной работы.
❯ За кадром
В качестве небольшого бонуса, ряд дополнительных параметров запуска браузера Chrome, которые остались за кадром. Они также применимы ко всем версиям и вариациям браузера и работают на всех операционных системах.
Актуально в первую очередь для тестов, но может влиять на системы защиты от ботов, поскольку данный ключ часто используют системы автоматизации, работающие поверх браузера.
--single-process
Заклинание чудовищной силы, которое заставляет браузер работать в одном единственном процессе:
Браузер Chrome, работающий целиком в одном процессе. Шок-контент
Этот весьма опасный (во всех смыслах) параметр переключает Chrome в нестандартный режим работы, при котором браузер не порождает отдельные процессы на каждую вкладку.
К сожалению такой режим работы является весьма нестабильным и браузер будет падать, особенно на сложном контенте и с большими расширениями вроде AdBlock.
Тем не менее, это единственный известный мне способ заставить Chrome работать без порождения дополнительных процессов.
--disable-features=UseSkiaRenderer
Отключает бекэнд Skia Renderer, используемый для отрисовки практически всей графики:
Chrome uses Skia for nearly all graphics operations, including text rendering. GDI is for the most part only used for native theme rendering; new code should use Skia.
К сожалению этот параметр является обязательным если вы собираетесь использовать --single-process, думаю очевидно что скорость отрисовки страниц при этом упадет.
❯ Эпилог
Мой опыт оптимизации браузера весьма специфичный и далеко не глобальный, поскольку решаемая задача касается производительности на устаревшем оборудовании и не самых популярных операционных системах.
Поэтому с радостью почитаю про ваш опыт и применяемые практики.
В копилку стабильности — и с конкретным обновлением под капотом.
Во время работы с высокопроизводительными серверами на Ryzen 7950X нашли причину редких зависаний нод. На старом ядре Ubuntu 22.04 эти процессоры могли работать нестабильно.
Это могло обернуться внезапной недоступностью виртуальных машин, хотя с самими проектами все было в порядке.
Чтобы устранить проблему, обновили ОС и ядро на всех Ryzen-серверах в московской локации.
Переезд выполнили поэтапно: сначала подняли резервные серверы, перенесли на них проекты и только потом приступили к обновлению основных хостов. Поэтому пользователи не столкнулись с простоем.
Теперь гипервизоры работают на новом ядре, а риски возможных зависаний нод осталась в прошлом.
Если вам нужны мощные серверы в Москве, есть еще одна новость — расширили парк Ryzen 7950X, чтобы было больше доступных конфигураций под ваши проекты.
Вынос со скандалом Bcachefs из mainline-ядра Linux в конце 2025 года (начиная с релиза 6.18) проект не похоронил. Напротив, это явно подстегнуло мейнтейнера к жесткой дисциплине. Спустя 7 месяцев проект перешел на DKMS-модель и официально снял статус experimental.
Развернул тестовую ВМ в Proxmox, чтобы посмотреть на эксплуатационный UX: как ставится, как ведет себя при отказе дисков и стоит ли тащить в homelab или прод.
Дисклеймер. Это синтетические тесты, а не академический бенчмарк (на виртуалке поверх ZFS тестировать скорость - такое себе). Цель - проверить работу базовых функций, диагностику и поведение при аварии.
1. Установка и DKMS-нюансы
Тест проводился на Ubuntu 26.04 с ядром 7.0.0-22-generic. Штатного модуля в ядре дистрибутива нет, так что идем в официальный репозиторий за DKMS:
# Добавляем репозиторий apt.bcachefs.org (unstable / bcachefs-tools-release) и затем ставим всю обвязку
По итогу получаем собранный модуль (bcachefs.ko.zst версии 1.38.6), и dmesg ожидаемо сыплющий ворнингами про tainting kernel и verification failed. Ну это просто надо иметь ввиду - теперь вы живете на внешнем модуле, и при каждом обновлении ядра нужно будет пристально следить за DKMS.
bcachefs: filldir64 fastpath disabled: struct layout unverified for this kernel
2. Базовый single-disk сценарий
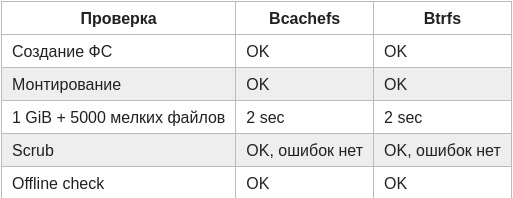
Первый тест был максимально тупой и прямолинейный:
Создать ФС на одном диске.
Смонтировать.
Записать файл 1 GiB и 5000 мелких файлов.
Запустить usage/scrub.
Размонтировать и выполнить offline check.
Для Bcachefs:
sudo bcachefs format -f -L bcf_single /dev/sdb
sudo mount -t bcachefs -o noatime /dev/sdb /mnt/bcf
sudo bcachefs fs usage -h -a /mnt/bcf
sudo bcachefs scrub /mnt/bcf
sudo bcachefs fsck -n -f /dev/sdb
Для Btrfs:
sudo mkfs.btrfs -f -L btr_single /dev/sdc
sudo mount -t btrfs -o noatime /dev/sdc /mnt/btr
sudo btrfs filesystem usage -T /mnt/btr
sudo btrfs scrub start -B /mnt/btr
sudo btrfs check --readonly /dev/sdc
На этом этапе всё скучно, единственная практическая ценность тут - набор команд для создания ФС, может кому пригодится как шпаргалка.
Можно еще отдельно сказать про команды Bcachefs. Они непривычны, но в целом на удивление логичны: вместо mkfs.bcachefs используется bcachefs format, диагностика идёт через bcachefs fs usage, проверка через bcachefs fsck.
3. Сжатие
Для проверки сжатия использовал простой набор:
zero-512m.bin, 512 MiB нулей.
random-256m.bin, 256 MiB случайных данных.
Bcachefs создавалась сразу с zstd:
sudo bcachefs format -f -L bcf_zstd --compression=zstd /dev/sdb
Btrfs монтировалась с compress=zstd:
sudo mount -t btrfs -o noatime,compress=zstd /dev/sdc /mnt/btr
У Bcachefs понравилась отдельная секция в fs usage:
Итоговое использование места:
Bcachefs - около 283 MiB
Btrfs - около 274 MiB
Обе ФС отработали отлично (нули сжали, рандом пропустили). Разница в несколько мегабайт тут не имеет особого смысла.
Из интересного - у Bcachefs утилита fs usage выдает шикарную и очень наглядную статистику по сжатым/несжимаемым данным прямо в консоль.
Здесь ноль сюрпризов. Снапшоты работают так, как от CoW-ФС и ожидаешь.
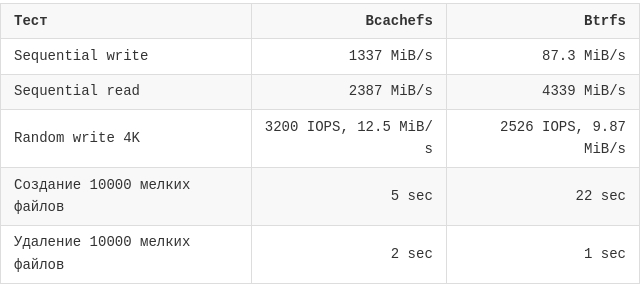
5. Производительность fio и мелкие файлы
Теперь к цифрам. Ещё раз: это синтетические тесты внутри одного сомнительного стенда.
Параметры fio:
single disk
без сжатия
sequential read/write: bs=1M, size=2G
random write: bs=4k, numjobs=4, iodepth=16, runtime=30
Первые три строки ниже - это fio. Создание и удаление 10000 мелких файлов замерялись отдельно обычным shell-сценарием: создание дерева файлов и последующий rm -rf этого дерева.
Результаты:
На этом стенде Bcachefs заметно быстрее на последовательной записи, random write 4K и создании мелких файлов. Btrfs, наоборот, быстрее на последовательном чтении и чуть быстрее удаляет дерево мелких файлов.
Само собой всё это автоматически не приводит нас к выводу, что Bcachefs быстрее Btrfs. Всё таки подложка в виде Proxmox/ZFS может сильно влиять на такие цифры. Но как лабораторный результат - как минимум любопытно.
Отдельный нюанс: во время нагрузки у Bcachefs в dmesg появилась строка:
bcachefs (sdb): bch2_journal_flush_seq stuck? Waited 10s for seq 32
После этого ФС нормально размонтировалась и прошла проверки. Но при эксплуатации это сообщение нельзя просто игнорировать. Его стоит отдельно разбирать при повторных тестах.
6. Multi-device
Одна из причин вообще смотреть на Bcachefs - обещание функциональности уровня современных CoW-ФС с более гибкой моделью устройств.
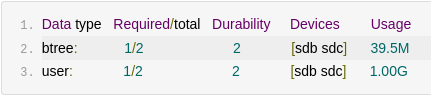
Bcachefs с двумя копиями данных и метаданных создаётся так:
bcachefs format -f -L bcf_raid1 --replicas=2 /dev/sdb /dev/sdc
После записи 512 MiB полезной нагрузки bcachefs fs usage показал ожидаемую репликацию:
У него всё ожидаемо отображается через Data ratio: 2.00 и Metadata ratio: 2.00.
Нюанс в терминологии: у Bcachefs модель --replicas=2 читается проще. Мы описываем желаемое количество копий, а не выбираем отдельные RAID-профили для data и metadata. Для админа это вполне приятная деталь.
7. Потеря диска на живую
Ну и само собой важная часть для любой multi-device ФС нифига не красивая таблица fio, а поведение при отказе.
Сначала пробовал имитировать отказ изнутри гостевой ОС через /sys/block/*/device/delete и device/state=offline. В этой ВМ метод оказался ненадёжным: устройство либо оставалось видимым, либо состояние быстро возвращалось в running.
Поэтому финальный тест делал через QMP hot-unplug на уровне Proxmox/QEMU. Постоянную конфигурацию ВМ не менял, удалял только live-устройство.
Bcachefs
Сценарий:
Bcachefs на /dev/sdb и /dev/sdc.
Форматирование с --replicas=2.
Запись 256 MiB payload.
QMP device_del scsi2, то есть удаление второго диска.
Проверка чтения старого файла и запись нового файла.
После hot-unplug /dev/sdc исчез из lsblk. Чтение и запись продолжили работать:
/mnt/bcf/payload.bin: OK
-rw-rw-r-- 1 user user 20 ... /mnt/bcf/after-qmp-hotunplug.txt
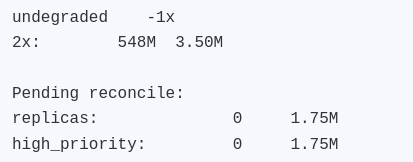
Диагностика Bcachefs показала, что часть метаданных уже требует восстановления реплик:
В dmesg появились ожидаемые ошибки по удалённому устройству:
Практический вывод: ФС осталась рабочей, данные читались, новая запись прошла. При этом состояние явно деградировало и требует дальнейшего reconcile/восстановления. Собственно, именно это и хотелось увидеть от теста.
Btrfs
Для Btrfs аналогичный сценарий делал на другой паре дисков:
Btrfs RAID1 на /dev/sdd и /dev/sde.
Так же запись 256 MiB payload.
QMP device_del scsi4.
Проверка чтения и запись нового файла.
После удаления /dev/sde ФС тоже продолжила работать:
/mnt/btr/payload.bin: OK
-rw-rw-r-- 1 user user 20 ... /mnt/btr/after-qmp-hotunplug.txt
btrfs filesystem usage -T показал missing device:
WARNING: failed to get device size for /dev/sde: No such file or directory
Device missing: 20.00GiB
В dmesg появились ошибки записи на удалённое устройство:
BTRFS warning (device sdd): lost super block write due to IO error on /dev/sde (-5)
BTRFS error (device sdd): error writing primary super block to device 2
В этом конкретном сценарии обе ФС повели себя адекватно: RAID1-подобная конфигурация пережила потерю одного диска на живую, данные остались читаемыми, запись продолжилась.
8. Что там по UX
Понравилось в Bcachefs:
bcachefs fs usage -h -a очень информативен.
Хорошо видно data/metadata, compression, btree и состояние устройств.
Модель --replicas=2 читается проще, чем отдельные профили -d raid1 -m raid1.
Снапшоты и subvolume-команды выглядят логично.
Потерю одного устройства при репликации ФС пережила.
Минусы:
Вместо нормальной поставки в составе ядра - поставляется как DKMS-модуль со всеми вытекающими (вообще надо было постараться настолько сильно выбесить мейнтейнеров ядра своим стилем разработки, чтоб тебя со скандалом вып*здили из mainline)
В dmesg был warning про bch2_journal_flush_seq stuck.
Сценарий возврата или замены диска после hot-unplug надо тестировать отдельно.
У Btrfs главный плюс скучный, но весомый: он давно есть в дистрибутивах, хорошо документирован, привычен и в принципе практически стабилен.
Итоги
Bcachefs после снятия experimental уже имеет смысл тестировать в homelab.
На этом стенде Bcachefs хорошо выступила на записи и мелких файлах, но это синтетические тесты.
Потерю одного диска при --replicas=2 Bcachefs пережила: данные читались, запись продолжалась, диагностика показала деградацию.
Если резюмировать, то основные вопросы пока не столько к самой ФС, сколько к эксплуатационной обвязке: DKMS, обновления ядра, загрузка модуля и восстановление после отказов.
ИМХО, для лаборатории, тестового NAS, домашнего стенда и удовлетворения инженерного любопытства - да, Bcachefs уже интересно гонять. Для продакшена или единственной копии важных данных - только после собственных аварийных тестов и с нормальными бэкапами.
Возникла необходимость перенести Kaspersky Security Center 16 с Windows на Ubuntu, и возникли проблемы. Инструкции на сайте Каспера — кривой, бесполезный кусок говна. Нейронки тоже не справились с помощью. На данный момент развернут сервер Ubuntu 24.04, введен в домен AD, установлен сервер KAC и Web Console. Веб-морда грузится, даже нафиг ненужное нововведение в виде обязательной двойной авторизации работает.
Проблема в том, что сервер Каспера не опрашивает домен (только через точки распространения). Нет пункта «Единый вход», чтобы настроить авторизацию под доменными учетками. Может, у кого-то есть нормальная, собранная инструкция, или кто-то сталкивался с такой проблемой — помогите, пожалуйста, уже голова кипит.