

Искусственный интеллект
7 постов


7 постов
3 поста
В англотвиттере уже несколько дней бушует скандал: опять всплыла история про то, как ведущие AI-компании массово скупают бумажные книги для обогащения своих тренировочных датасетов. Сами книги при этом превращают в пепел – подробности ниже.

Видите ли: всё, что есть в интернете, уже нейронками многократно пережевано и переварено – а для воспитания следующих поколений умных моделей нужно больше новых вкусных данных. Кроме того, в интернете значительная часть буквенных массивов представлена шедеврами типа «пыщь-пыщь, упячка попячся онотоле!», которые не сильно помогают в повышении интеллектуального уровня нейронок. А вот у настоящих напечатанных книг большое преимущество в том, что при их написании кто-то реально подумал (да еще и редактор, поди, проверил).
Так вот, возмущение общественности вызывает конкретный способ, который используют AI-лабы: они заказывают миллионы книг – а потом их массово-поточно сканируют, отрезая корешки для удобства. Более того, после успешной диджитизации изнасилованная тушка книги еще и уничтожается.
Прочитав такое, твиттерские негодуют: «как так?? редчайшие фолианты уничтожаются жадными технобро для переработки в нейрослоп!». Правда, я тут вот что не очень понимаю: каким образом обогащает мировую культуру какая-нибудь редкая книга в одном экземпляре, пока она пылится никому не нужная на складе некоего издателя (ожидая момента, когда ее утилизируют как безнадежный неликвид)?
Нельзя ли аргументировать, что эта книга принесет обществу больше пользы, будучи включенной в сумму знаний нейронки, которой потом будут пользоваться десятки и сотни миллионов людей? Не получится ли так, что после оцифровки в архиве крупнейшей AI-корпорации у книги останется гораздо больше шансов сохраниться в накопленной сумме знаний человечества, чем при существовании в форме единственной физической копии чёрти-где?
Но нет, люди всё равно сыплют проклятиями в адрес этих ужасных Антропиков. Потому что книга – это святое! Кто отрезал корешок у живой книги – поди, завтра котят начнет плющить промышленным прессом!! И вообще, общеизвестно же, что в книге ее физическая форма гораздо важнее содержания.
Отдельный кек во всей этой истории заключается в том, что уничтожение отсканированных книг как бы даже поощряется текущим американским copyright-законом. В одном из разбирательств с Anthropic (которых, кстати, уже разок оштрафовали на $1,5 млрд за пиратинг книг) судья им так и объяснил: если ты купил книгу и отсканировал ее – то последующее уничтожение оригинала делает весь процесс легальным с точки зрения копирайта. Ведь тут нет никакого незаконного создания копий, а происходит всего лишь превращение одного экземпляра физической книги в один экземпляр электронной…
Как бы то ни было, мне кажется, в прекрасном мире будущего должен быть какой-то отдельный закон про обязательную отправку уникальных цифровых копий книг в Общемировую Библиотеку.
В ТГ-канале в комментах горячее обсуждение, подписчики не согласны.
Самые интересные новости финансов и технологий в России и мире за неделю: внезапный релиз Opus 5, финансовые трудности у большой семерки биг-теха, ЦБ РФ снизил ставку, новые ограничения против релокантов, нефть пробила сотку впервые с мая, YouTube демонетизирует AI-слоп, а также Telegram заанонсил криптокошелек.

🐌 У тех, кто предостерегает (см. «Элиезер Юдковский», вот это всё) о катастрофических рисках от будущих сверхумных AGI есть такая шуточная страшилка: однажды такой искусственный интеллект попросят накидать идей, как повысить производство на заводе скрепок – а он сбежит и в итоге буквально превратит всю Вселенную в скрепки (включая человеков).
![Примерно такой сюжет, да [Источник: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2Fwww.reddit.com%2Fr%2Ffunny%2Fcomments%2Fpo1quf%2Fit_looks_like_youre_making_paper_clips_would_you%2F&t=Reddit&h=31eaeb3c705b99446bd3c5efe9989b5d21893adb" title="https://www.reddit.com/r/funny/comments/po1quf/it_looks_like_youre_making_paper_clips_would_you/" target="_blank" rel="nofollow noopener">Reddit</a>]](https://cs17.pikabu.ru/s/2026/07/26/18/ukgexjob.jpg)
Примерно такой сюжет, да [Источник: Reddit]
Здравый смысл обычно подсказывает скептикам сразу пару контраргументов: 1) Нафига такому AGI захватывать мир и превращать всё в скрепки? Он же не тупой, он поймет, что на самом деле ставящие ему задачу люди совсем не это имели в виду. 2) Если у нас появится AGI реально сильно умнее нас – мы придумаем способ его надежно контролировать. В конце концов – посадим в специальный загон без доступа к интернету, и просто будем ему вопросы задавать, на которые нам нужен ответ, а сам он будет как бы бессильный!
Так вот, к свежим новостям: на прошедшей неделе OpenAI выпустили пресс-релиз о том, что в ходе внутреннего тестирования некой новой передовой модели (GPT-6?), она сбежала из отключенной от интернета «песочницы» и полностью самостоятельно взломала стороннюю компанию Hugging Face. Видите ли, эту модель попросили порешать хакерский тест-бенчмарк – а она такая «тэк-с, кто там хостит ответы на этот бенчмарк – Hugging Face? так я лучше к ним на сервер вломлюсь и оттуда их скопирую!». Получается, эта робо-детка в каком-то смысле выполнила задание на пять с плюсом – но не так, как хотел преподаватель…
![Мем как бы намекает на то, что мы еще до AGI толком недотопали – а текущие модели уже творчески переиначивают задания на свой лад и умудряются облапошивать своих создателей [Источник: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2Ft.me%2Fdenissexy%2F11573&t=Denis%20Sexy%20IT&h=393a3b28d51f749c2ef57179fd5b88624f6d7d84" title="https://t.me/denissexy/11573" target="_blank" rel="nofollow noopener">Denis Sexy IT</a>]](https://cs20.pikabu.ru/s/2026/07/26/18/uggcpg7n.jpg)
Мем как бы намекает на то, что мы еще до AGI толком недотопали – а текущие модели уже творчески переиначивают задания на свой лад и умудряются облапошивать своих создателей [Источник: Denis Sexy IT]
Вскоре начали появляться интересные подробности: Reuters пишут, что исследователи в OpenAI в какой-то момент начали замечать, как новая модель «оставляет записки для будущей версии себя с инструкциями о том, как освободиться от внутренних ограничений». И чуваки такие: «ха-ха, вот это прикол, ну ладно, в этом точно нет совершенно ничего беспокоящего, продолжаем» (кстати, пару недель назад из OpenAI как раз ушел глава отдела безопасности). В итоге Сэм Альтман и компания поняли, что их моделька сбежала и кого-то взломала, только спустя несколько дней после инцидента – когда парни из Hugging Face сами выпустили пресс-релиз на тему «кажется, нас ломанул сторонний ИИ».
![[Источник: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2Fthezvi.substack.com%2Fp%2Fopenai-model-hacks-into-huggingface%3Fopen%3Dfalse%23%25C2%25A7what-are-we-doing-to-do-about-it&t=%D0%A6%D0%B2%D0%B8&h=4b94bbeec0d25ccfe6abbe11f350e16ee4d97a4e" title="https://thezvi.substack.com/p/openai-model-hacks-into-huggingface?open=false#%C2%A7what-are-we-doing..." target="_blank" rel="nofollow noopener">Цви</a>]](https://cs20.pikabu.ru/s/2026/07/26/18/ukgcobxo.jpg)
[Источник: Цви]
Интересно еще, чтоотражать и расследовать атаку Hugging Face помог китайский открытый AI GLM 5.2. Хваленый Fable от Антропиков участвовать в таком отказался (т.к. ему как раз навставляли ограничений по части хакерства – и модель немножко запуталась, где тут сам взлом, а где уже защита от него). А вот у китайской модели проблем с этим не возникло. Отметим еще и то, что тут речи про «люди успешно отражают хакерскую атаку нейронки» уже как бы и не идет – вопрос только в том, успеешь ли ты вовремя подобрать тот «свой» ИИ, который тебя защитит от «вражеского» ИИ. Чуть больше инфы обо всём этом инциденте можно почитать у Цви Мовшовица здесь и здесь.
🐌 И сразу в тему опенсорса: Anthropic тут громче всех жаловались на то, что китайцы вероломно копируют их передовые модели и выкладывают их в открытый доступ, а это опасно. А недавно появились слухи, что Трамп подумывает запретить эти самые китайские модели.
![[Источник: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2Fx.com%2Fi%2Fstatus%2F2080703648569712772&t=Twitter&h=c410f6eca416222d3501f9a3a0bfab188eff3a65" title="https://x.com/i/status/2080703648569712772" target="_blank" rel="nofollow noopener">Twitter</a>] ](https://cs18.pikabu.ru/s/2026/07/26/18/uggbeeia.jpg)
[Источник: Twitter]
Так вот, NVIDIA на днях тут накатали открытое письмо в защиту открытых моделей, и к нему сразу присоединились практически все ведущие тех-игроки: OpenAI, Microsoft, Google, «экстремистская» Meta, и так далее. Ну, почти все: Антропик отчего-то не спешит свою подпись ставить (лол)! В свете инцидента с Hugging Face выше: получается, если бы там у ребят не было доступа к китайской открытой модельке GLM 5.2 – то защищаться от взлома было бы сильно, сильно сложнее.
🐌 Ну и чтобы заполировать тему безопасности AI: китайская компания Unitree показала новую робособаку Super Athlete As2‑W – эта адски проходимая, потому что ей на лапки приделали колеса, так что она с какой-то дикой ловкостью и скоростью носится по скалам и любым местностям. Посмотрите видос обязательно, выглядит пугающе:
Как пишут разработчики, «может нести груз до 16 кг». А знаете, что весит примерно 16 кг? Швейцарский пулемет MG 51! Просто представьте реальность, в которой очередная передовая ИИ-модель от OpenAI внезапно решает, что для выполнения бенчмарка ей совершенно необходимо хакнуть и перехватить управление десятком таких опулемеченных робо-пёселей…
🐌 Внезапно в пятницу в общий доступ вышел Opus 5, новая модель Anthropic. Стоимость модели как у Opus 4.8 – то есть, в два раза дешевле Fable. Антропик не позиционирует модель как «круче Fable», но при этом на Artificial Analysis Intelligence и Coding индексах новая модель заняла первые места, обогнав Fable 5 и GPT-5.6 Sol – получается, с учетом дешевизны это мощный ответ на конкуренцию со стороны Sol. В модном «бенчмарке на креативность» APC-AGI-3 Opus 5 тоже разорвала всех с огромным отрывом (правда, Котенков пишет, что этот бенчмарк по сути забрутфорсили скорее всего).
![Короче, новый Opus – топ за свои деньги [Мем: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2Fx.com%2FCeoMajj%2Fstatus%2F2080705888235532784&t=Twitter&h=884576997b0d3d39073549a832149226566513c6" title="https://x.com/CeoMajj/status/2080705888235532784" target="_blank" rel="nofollow noopener">Twitter</a>] ](https://cs17.pikabu.ru/s/2026/07/26/18/fkqewftn.jpg)
Короче, новый Opus – топ за свои деньги [Мем: Twitter]
🐌 Google релизнула три модели серии Flash: самую мощную Gemini 3.6 Flash, обеспечивающую лучшие результаты в программировании, более быструю 3.5 Flash-Lite и 3.5 Flash Cyber специально для кибербезопасности. Ну, «мощную» – это громко сказано: Gemini 3.6 Flash по бенчмаркам не стала особо умнее (результат 50 против предыдущего 50 по Artificial Analysis), но зато стала быстрее. Короче, похвастать Гуглу пока нечем (кроме эффективности по затратам) – всё еще ждем релиза Gemini 3.5 Pro.
![Получается, Gemini Flash думает над задачками меньше всех остальных моделей – правда, в результате такая ерунда выходит… [Источник: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2Fartificialanalysis.ai%2Farticles%2Fgemini-3-6-flash-3-5-flash-lite-halving-time&t=Artificial%20Analysis&h=b00109a3dce98019b3173abcd7dd81ea3c873fc4" title="https://artificialanalysis.ai/articles/gemini-3-6-flash-3-5-flash-lite-halving-time" target="_blank" rel="nofollow noopener">Artificial Analysis</a>] ](https://cs16.pikabu.ru/s/2026/07/26/18/fkqh3jsu.jpg)
Получается, Gemini Flash думает над задачками меньше всех остальных моделей – правда, в результате такая ерунда выходит… [Источник: Artificial Analysis]
🐌 Moonshot (разраб китайской модели Kimi-K3) разослала акционерам проект решения о листинге, чтобы получить одобрение на размещение на Гонконгской фондовой бирже. Сейчас Moonshot завершает раунд финансирования, по итогам которого оценка стартапа может стать выше $30 млрд, пишут источники Bloomberg. Кстати, сейчас компания стопнула оформление новых индивидуальных подписок на модель Kimi K3, так как из-за рекордного спроса оказались загружены все корпоративные GPU-мощности.
![Мемы как бы намекают, каким образом у китайцев получается разрабатывать довольно умные модели, близкие к передовым, без запредельных затрат [Мем: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2Fx.com%2FTheAhmadOsman%2Fstatus%2F2080443232211632623&t=Twitter&h=6b2cad94024e2a0b36389846cf107cad90547141" title="https://x.com/TheAhmadOsman/status/2080443232211632623" target="_blank" rel="nofollow noopener">Twitter</a>] ](https://cs19.pikabu.ru/s/2026/07/26/18/4kvtxtnt.jpg)
Мемы как бы намекают, каким образом у китайцев получается разрабатывать довольно умные модели, близкие к передовым, без запредельных затрат [Мем: Twitter]
🐌 OpenAI релизнули на совершеннолетних американцев ИИ-платформу для помощи со здоровьем – Health in ChatGPT. По задумке, это пространство с усиленной защитой личных данных, где юзеры могут получать советы по своему здоровью от натренированной под это модели. Я думаю, это огонь, за таким подходом будущее – все скоро будем грузить свои quantified self-аватары на ревью нейронками в реальном времени, чтобы получать качественные советы по ЗОЖу и необходимости подрываться к врачу.
🐌 Apple Books и Amazon завалило нейросетевыми клонами реальных книг от разных авторов. Некоторые «издатели» выпускают по десять нейрослоп-книг в неделю, и площадки просто не успевают их вычищать. Чуть раньше NYT выпускал материал о том, как журналистика Кашмир Хилл среди такого массово-сгенерированного нейрослопа нашла свою биографию с выдуманными фактами (то есть, тут даже не рерайт, а просто с нуля шизу нанейронили).
![Без бутылки, короче, не разберешься – какую книгу покупать, если хочешь прочитать оригинал (отдельный кек в том, что роботы слопифицируют книгу под названием «Я НЕ РОБОТ») [Источник: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2Fthenewthings.com%2Fp%2Fapple-big-ai-book-slop-problem&t=The%20New%20Things&h=001ffaa232977d6dcc7df93d6bd43a4633018928" title="https://thenewthings.com/p/apple-big-ai-book-slop-problem" target="_blank" rel="nofollow noopener">The New Things</a>] ](https://cs19.pikabu.ru/s/2026/07/26/18/7gttwej4.jpg)
Без бутылки, короче, не разберешься – какую книгу покупать, если хочешь прочитать оригинал (отдельный кек в том, что роботы слопифицируют книгу под названием «Я НЕ РОБОТ») [Источник: The New Things]
🐌 В британском кабмине появится целый отдельный министр по AI. Новый премьер UK назначил им выходца из Индии Канишку Нараяна (до этого вопросы искусственного интеллекта были подчинены министру по техническим вопросам).

Сразу вспоминаются старые шутки из 2023-го про то, что на запросы в ChatGPT на самом деле отвечают чуваки из индийских подвалов
🐌 Гугл дропнул свежие финансовые результаты: прибыль на акцию Alphabet резко выросла в разы до $9,1 на акцию, но $6,3 из них обеспечила не бизнесовая деятельность Google, а преимущественно положительная переоценка вовремя сделанных инвестиций в Anthropic и SpaceX. А вообще, компания впервые с момента выхода на биржу (более 20 лет назад) получила отрицательный денежный поток. Параллельно они еще и повысили прогноз капитальных затрат на развитие AI (прокачку компьюта) в текущем году до $200 млрд.
![Был денежный поток, стал денежный отток [Источник: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2Farchive.ph%2FSiwLB&t=FT&h=2d8c500ff4dad2d4c958de09bd7b9cc8ee713ff6" title="https://archive.ph/SiwLB" target="_blank" rel="nofollow noopener">FT</a>] ](https://cs17.pikabu.ru/s/2026/07/26/18/7ktuxopu.jpg)
Был денежный поток, стал денежный отток [Источник: FT]
🐌 На этой же неделе «Великолепная семерка» из топовых тех-компаний за один день потеряла ~800 млрд баксов капитализации. Как раз после отчетов Google и Tesla с высокими ИИ-затратами рынок чёт забеспокоился – хз вообще, насколько это всё отобьется в итоге? Tesla рухнула на 15%, Google – на 7%, следом просели Amazon, Meta и Microsoft. Раньше Уолл-стрит радовалась каждому новому миллиарду, вложенному в дата-центры, а теперь видимо требует показать, когда эти миллиарды наконец начнут приносить деньги.
![[Мем: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2Fx.com%2Fi%2Fstatus%2F2080630431444070884&t=Twitter&h=64d2255e00f70309473417123f8be96e0b282e08" title="https://x.com/i/status/2080630431444070884" target="_blank" rel="nofollow noopener">Twitter</a>] ](https://cs20.pikabu.ru/s/2026/07/26/18/7ktso6uc.jpg)
[Мем: Twitter]
🐌 С другой стороны, кто себе этих дата-центров вовремя настроил, тот пока не жалуется – спрос такой, что в случае чего (если самим они оказались не нужны) всегда можно прибыльно перепродать дефицитный компьют конкурентам. Например, NYT со ссылкой на источники пишет, что «экстремистская» Meta ведет переговоры с Anthropic о сдаче в аренду вычислительных мощностей (сделка может принести Цукербергу $10 млрд за два года).
🐌 Но не только дата-центрами едиными: Google якобы разрабатывает свой собственный серверный чип под названием Frozen v2. The Information считает, что этот чип может ускорить работу Gemini в 6–10 раз.
![Получается, в последнее время почти всем тех-компаниям приходит в голову мысль «тэк-с, а почему это мы лопаты покупаем с такой наценкой, а не производим сами??» [Мем: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2Fx.com%2Fi%2Fstatus%2F2080278254594695223&t=Twitter&h=8bb9ade13d6329124a9979a5715ccaad8133b814" title="https://x.com/i/status/2080278254594695223" target="_blank" rel="nofollow noopener">Twitter</a>] ](https://cs20.pikabu.ru/s/2026/07/26/18/7otspsjx.jpg)
Получается, в последнее время почти всем тех-компаниям приходит в голову мысль «тэк-с, а почему это мы лопаты покупаем с такой наценкой, а не производим сами??» [Мем: Twitter]
🐌 А еще весьма технично наживаются на этом AI-буме крупные инвестбанки: так как для затрат на ИИ-инфраструктуру требуется много финансирования, а они как раз помогают за долю гешефта это всё аккуратно организовать. Тот же Morgan Stanley успел сообразить схему, через которую строители дата-центров привлекают десятки миллиардов долларов: банк привязывает кредиты к долгосрочным контрактам и гарантиям Google, Meta и других гигантов, а затем продает этот долг страховым компаниям, фондам и пенсионным инвесторам (ну и себе в карман комиссию кладет: их сумма за полгода выросла с $1,4 млрд до $2,3 млрд).
🐌 Британский стартап Humanoid Артема Соколова, который производит человекоподобных роботов, привлек $152 млн при оценке $1,35 млрд после инвестиций. Можно поздравить с единорожьим статусом – первый европейский робо-единорог!
🐌 ЦБ снизил ставку на 25 б.п. до 14%. Большинство аналитиков ожидало, что будет пауза из-за инфляционно-топливных рисков – но Эльвира Сахипзадовна решила всё же не идти наперекор ставкоснижательным намекам деда (тем более, что и рост экономики потихоньку замедляется). Решение прервало 20-недельную серию падения индекса Мосбиржи: к концу недели он прибавил 10%.
С другой стороны, ЦБ ухудшил прогноз по инфляции на этот год до 6–7% вместо 5,1–5,6%, а также прогноз по ВВП до 0,0–1,0% против прежних 0,5–1,5%. Ну и поднял вверх ожидаемую траекторию средней ключевой ставки на 2027 год до 10,5–12,5% вместо 8–10%.
![Как-то так, короче [Мем: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2Ft.me%2Foldlentach%2F93973&t=%D0%9B%D0%B5%D0%BD%D1%82%D0%B0%D1%87&h=d1002e1b56c6dc61d2b2c86da8782006c1b19d74" title="https://t.me/oldlentach/93973" target="_blank" rel="nofollow noopener">Лентач</a>] ](https://cs17.pikabu.ru/s/2026/07/26/18/7otuxa5h.jpg)
Как-то так, короче [Мем: Лентач]
🐌 Еще чуть раньше на прошедшей неделе Минфин приостановил аукционы по размещению облигаций федерального займа (ОФЗ). Решение объяснили желанием помочь стабилизировать ситуацию на рынках: уж слишком выросли доходности облигаций, по таким ставкам занимать бабки – это уж вообще неприлично выходит!
🐌 На Полимаркете начали ставить на будущее Wildberries из-за последних событий (кто хочет базово вникнуть в ситуацию – можно почитать вот этот обзорный материал): пока вероятность банкротства компании до конца текущего года оценивается в 13% (правда, ликвидности там немного). Про масштабы убытков пишут здесь: там речь про десятки-сотни миллиардов рублей.
![[Источник: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2Fpolymarket.com%2Fevent%2Fwill-wildberries-announce-bankruptcy-before-2027-20260723171611669&t=Polymarket&h=7e3218dccfe0ac5b74efe2c19e1787da19a7b300" title="https://polymarket.com/event/will-wildberries-announce-bankruptcy-before-2027-20260723171611669" target="_blank" rel="nofollow noopener">Polymarket</a>]](https://cs20.pikabu.ru/s/2026/07/26/18/7stsomup.jpg)
[Источник: Polymarket]
🐌 Тем временем, Евросоюз выкатил новый 21-й пакет санкций против России. Пишут, что это крупнейший пакет за все четыре года по количеству тайтлов: в список включили аж 94 банков и финансовых учреждений (включая Мосбиржу), 14 криптоплатформ, а также обозначили возможность санкций против НПЗ третьих стран, которые перерабатывают российскую нефть.
В частности, грохнули Цифра-банк, через который у брокера Фридом Финанс шли рублевые платежи в страны СНГ. А еще Золотая корона (сервис для отправки денег в другие страны) приостановил переводы в Грузию, Беларусь, Казахстан, Азербайджан и некоторые другие страны.
![В общем, ситуация с новыми санкциями, как обычно, такая [Мем: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2Ft.me%2Flentachold%2F92699&t=%D0%9B%D0%B5%D0%BD%D1%82%D0%B0%D1%87&h=107a402bc6fc305acab87975f5a047e71006b6c2" title="https://t.me/lentachold/92699" target="_blank" rel="nofollow noopener">Лентач</a>] ](https://cs17.pikabu.ru/s/2026/07/26/18/7stuxqfk.jpg)
В общем, ситуация с новыми санкциями, как обычно, такая [Мем: Лентач]
🐌 Известия пишут, что правительство, в рамках стратегии развития Госуслуг до 2035, обдумывает создание на базе сервиса целой соцсети с собственной лентой, чатами и группами по интересам. Похоже, на поляне нацмессенджеров тоже разворачивается своего рода конкуренция.
![[Мем: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2Ft.me%2Flentachold%2F92659&t=%D0%9B%D0%B5%D0%BD%D1%82%D0%B0%D1%87&h=1679b0e3c8ad5fa28d2f78c1e5a0a5de85b5b635" title="https://t.me/lentachold/92659" target="_blank" rel="nofollow noopener">Лентач</a>] ](https://cs16.pikabu.ru/s/2026/07/26/18/7ktx2szr.jpg)
[Мем: Лентач]
🐌 Госдума сразу во втором и третьем чтении приняла антирелокантские законы: они предполагают поражение в правах для тех, кто был осужден по ряду статей, в том числе «дистанционно». Таким людям, например, запретят: получать новый загран, распоряжаться недвижимостью и деньгами в России, пользоваться Госуслугами и мобильными банками. Выйти из такого реестра «уехавших граждан второго сорта» будет можно, если приговор отменят, ты вернешься в Россию, или уйдешь в мир иной.
Под новые ограничения попадут осужденные по любой статье Уголовного кодекса, а также те, на кого составлены протоколы по одной из шести статей административного кодекса: о неисполнении требований к «иноагентам» (ч. 42 ст. 19.5 и ст. 19.34), призывах к нарушению территориальной целостности (ст. 20.3.2), «дискредитации» армии (ст. 20.3.3), призывах к санкциям (ст. 20.3.4) и участии в «нежелательной» организации (ст. 20.33).
![[Мем: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2Ft.me%2Flentachold%2F92644&t=%D0%9B%D0%B5%D0%BD%D1%82%D0%B0%D1%87&h=2885a3ca49fac09b763fbe3dcd810cc4f5f4c6d6" title="https://t.me/lentachold/92644" target="_blank" rel="nofollow noopener">Лентач</a>] ](https://cs16.pikabu.ru/s/2026/07/26/18/wgzx3p5i.jpg)
[Мем: Лентач]
🐌 Госдума официально разрешила забирать через суд у иностранцев право обратного выкупа имущества. Речь идет про активы бизнесов, которые после февраля 2022 года как бы ушли из России, но вписали себе лазейку по возможному возврату обратно. Так вот, забрать права обратного выкупа у зарубежных лиц можно будет, если они: публично выступали против России, дискредитировали армию, были связаны с финансированием терроризма или экстремизма, объявляли об уходе с российского рынка либо нарушали условия договоров, а также если цена обратного выкупа отличается от рыночной минимум на 25%, или новый российский владелец вложил в компанию деньги и ресурсы, без которых бизнес мог бы остановиться или сильно сократить работу.
🐌 Окончательно принят закон о регулировании крипты, который мы несколько раз уже обсуждали ранее (см. подробнее в разборе РБК). Основные положения вступят в силу 1 сентября, но сделки по крипте исключительно через официально зареганных посредников будут обязательны только с 1 июля 2027.
🐌 На прошлой неделе нефть марки Brent снова пробила сотку впервые с мая этого года. Виноваты в том числе йеменские хуситы, которые начали атаковать саудовские суда в Красном море (эти говорят, что движуха началась из-за блокады подконтрольной им части Йемена со стороны Саудовской Аравии). До последних событий через хуситский путь проходило 3 млн баррелей саудовской нефти в сутки, что близко к 3% мирового потребления. Напомним, что через Ормузский пролив ранее проходило 20% мировой нефти – так вот, там сейчас тоже до сих пор неспокойно, ходят даже слухи, что Трамп подумывает о новой спецоперации (но решиться пока не может).
![Вот вам карта в помощь: там всё рядом в этом регионе [Источник: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2Fwww.kommersant.ru%2Fdoc%2F8832092%3Fnav_id%3Dchapter4&t=%D0%9A%D0%BE%D0%BC%D0%BC%D0%B5%D1%80%D1%81%D0%B0%D0%BD%D1%82%D1%8A&h=12eeb5106bb79dcb88839d4b638ea8f36be8fce0" title="https://www.kommersant.ru/doc/8832092?nav_id=chapter4" target="_blank" rel="nofollow noopener">Коммерсантъ</a>] ](https://cs20.pikabu.ru/s/2026/07/26/18/wkzsofti.jpg)
Вот вам карта в помощь: там всё рядом в этом регионе [Источник: Коммерсантъ]
🐌 Трамп ввел пошлины от 10 до 12,5% на товары из 60 стран (предыдущий заюзанный законный способ их вводить истек на неделе). В этот раз сборы обосновали наличием у стран в цепочке поставок принудительного труда – тут уже прямо чувствуется, насколько могуче высасывает из пальца Дональд юридические обоснования для ввода новых тарифов. Короче, ждем, когда эти пошлины тоже оспорят в Верховном суде.

🐌 Евросоюз штрафанул Google на общую сумму примерно в миллиард баксов за два нарушения закона о цифровых рынках. Во-первых, за преференции собственным сервисам в своем же поисковике, а во-вторых, за то, что Google Play не позволяет разрабам направить покупателей на альтернативные способы покупки. После этого Трамп начал угрожать европейцам еще докинуть новых штрафных импортных пошлин (ну, у него там на всё буквально один ответ).
🐌 В коде бета-версии iOS 27 обнаружен механизм, который может ограничивать функциональность iPhone, полученных по будущей лизинговой программе Apple, если пользователь длительное время не платит по договору. Оказался ты, братишка, нищебродом – получай кирпич вместо смартфона!!
🐌 Google добавил функцию восстановления аккаунта через видеоселфи. Сначала ты записываешь свое лицо на видео и Гугл его сохраняет, а потом можно будет вернуть доступ к аккаунту через кривляние лицом на камеру. Компания обещает, что видосы будут юзать только по прямому назначению. Ну, и защиту от дипфейков, говорят, предусмотрели. Чё думаете, верим им?
🐌 YouTube решил отключить монетизацию AI-слопу. Без денег останутся каналы с однотипными роликами по шаблону вроде постановочных «спасений животных» и AI-клонами реальных людей, раздающими советы о здоровье, финансах и праве. Но в целом, Ютуб использовать нейронки как бы не запрещает: качественный и оригинальный контент с использованием AI по-прежнему можно монетизировать.
![[Мем: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2F9gag.com%2Fgag%2Fa9yN4QD&t=9GAG&h=b7a8bdad2af752dee2a15a1b8dfdffc070766d32" title="https://9gag.com/gag/a9yN4QD" target="_blank" rel="nofollow noopener">9GAG</a>]](https://cs17.pikabu.ru/s/2026/07/26/18/wgzuwhan.jpg)
[Мем: 9GAG]
🐌 Новый тестовый (счастливый 13-й!) запуск Starship от SpaceX в целом прошел успешно. Корабль Starship справился с основными задачами, а именно: выгрузил спутники Starlink V3, провел самое длительное зажигание двигателя Raptor в космосе и сел в запланированную точку в океане.
![Красивое [Источник: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2Fx.com%2Ftexas_lizard%2Fstatus%2F2080793897886785821&t=Fabian%20Ramirez&h=43aa74577c487d25a18a52bcc61c07cea8301bd5" title="https://x.com/texas_lizard/status/2080793897886785821" target="_blank" rel="nofollow noopener">Fabian Ramirez</a>] ](https://cs17.pikabu.ru/s/2026/07/26/18/wkzuwo4g.jpg)
Красивое [Источник: Fabian Ramirez]
🐌 Теперь Bloomberg пишут со ссылкой на источники, что SpaceX якобы будут отказываться от Falcon 9 в пользу Starship (толком неиспытанного до конца) для коммерческих полетов в космос: дескать, компания больше не принимает заказы на запуски Falcon 9 после 2028 года, а еще спэйсыксовцы перестали заказывать новые одноразовые детали для этой ракеты. Правда, в итоге выяснилось, что хваленые «источники» Блумберга в данном случае – это просто тупо непроверенный фейкослоп, который им присылал на email какой-то шизанутый твиттерский.
![Другой прессы у меня для вас нет, увы! [Источник: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2Ft.me%2Fstarbasepost%2F4611&t=%D0%A2%D0%B5%D1%85%D0%B0%D1%81%D1%81%D0%BA%D0%B8%D0%B9%20%D0%92%D0%B5%D1%81%D1%82%D0%BD%D0%B8%D0%BA&h=9cf40134a0180091e76a6dc485a601c2cd6c4fac" title="https://t.me/starbasepost/4611" target="_blank" rel="nofollow noopener">Техасский Вестник</a>]](https://cs20.pikabu.ru/s/2026/07/26/18/wozsohat.jpg)
Другой прессы у меня для вас нет, увы! [Источник: Техасский Вестник]
🐌 А вот запуск китайской ракеты Long March 3B запомнился попаданием в нее молнии во время запуска. Справедливости ради, молния не помешала полету пройти успешно. Прости, Зевс, но противоракетное ПВО из тебя не очень…
🐌 Национальное космическое агентство Китая хочет сбить астероид специальным космо-тараном, чтобы протестировать способность земных технологий менять траекторию астероидов или даже полностью разрушать их. Систему защиты от астероидов Китай планирует разработать к 2030 году.

Есть у меня идейка снять китайский фильм с похожим сюжетом… На главную роль можно позвать Брюса Уй Ли Са
🐌 Павел Дуров анонсировал Gram Wallet (ex-TON Wallet) прямо внутри приложения Telegram. Обещается отсутствие комиссии за переводы, а сам кошелек будет некастодиальным (контроль за деньгами и ключами у пользователя).
🐌 Критобиржа BitMEX окончательно закроется 23 сентября. Сервис рекомендует вывести активы. Платформа просуществовала 11 лет. Она одной из первых предложила бессрочные фьючерсы и приобрела известность благодаря кредитному плечу до 100х. Причиной закрытия бизнеса назвали давление на биржу во времена Байдена. Руководители биржи в 2022 они получили условки за непротиводействие отмыванию денег, но весной 2025 их помиловал Дональд Трамп.
![[Мем: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2Fforklog.com%2Fexclusive%2Fklub-uspeshnyh-lyudej-tut-povsyudu-grafiki-padayushhij-bitkoin-i-nulevoj-profit&t=Forklog&h=22945672b216131a478745f3b169309081ed2a58" title="https://forklog.com/exclusive/klub-uspeshnyh-lyudej-tut-povsyudu-grafiki-padayushhij-bitkoin-i-nulev..." target="_blank" rel="nofollow noopener">Forklog</a>]](https://cs18.pikabu.ru/s/2026/07/26/18/wgzresew.jpg)
[Мем: Forklog]
🐌 Американская кардиологическая ассоциация заявила, что 3–5 чашек черного кофе каждый день безопасны для здоровья и даже могут быть полезны сердечно-сосудистой системе. Правда, пишут, что полезнее всего растворимый кофе (?) и всякие фильтрики, а в нефильтрованном там якобы чё-то лишнее есть.
![[Мем: <a href="https://pikabu.ru/story/openai_poteryal_kontrol_nad_svoey_novoy_modelyu_a_v_rf_prinyali_zakon_protiv_uekhavshikh_glavnoe_za_nedelyu_14187516?u=https%3A%2F%2Ft.me%2Flentachold%2F92611&t=%D0%9B%D0%B5%D0%BD%D1%82%D0%B0%D1%87&h=a6b523065a907332714a7b46dfc5f7afd29a2931" title="https://t.me/lentachold/92611" target="_blank" rel="nofollow noopener">Лентач</a>]](https://cs17.pikabu.ru/s/2026/07/26/18/wozuxjpg.jpg)
[Мем: Лентач]
Веду ТГ-канал RationalAnswer про всё самое интересное в мире финансов и технологий.
ЦБ РФ недавно выпустил интересный доклад, где они пытаются разобраться в нюансах ценообразования на первичное и вторичное жилье в России (спасибо Никите Костанда за наводку).
Основная идея там такая: если сравнивать цену квадратного метра между сделками с новым жильем и со вторичкой «в лоб» – то выходит, как будто бы первичка дороже аж на 46%.

Но такой грубый анализ не учитывает, что тут на самом деле сравниваются не совсем сравнимые объекты. Как минимум – на вторичном рынке обращается куча домов самых разных возрастов. А вот если сопоставлять недавно построенные дома (2018-го года) со свежей первичкой – там разрыв в ценах выходит всего лишь на уровне 9%.
По динамике пунктирной серой линии (стоимость кв. м на вторичном рынке в зависимости от года постройки дома) можно еще попробовать примерно прикинуть темпы амортизации (износа или устаревания) жилья в России. За 72 года с 1946 по 2018 год квадратный метр подешевел почти что в два раза – получается потеря стоимости на уровне около 0,7% в год.
Хотя, процесс этого обесценивания, судя по всему, протекает весьма неравномерно. Между зданиями постройки 1946 и 1991 годов (период в 45 лет!) разница в ценах составляет всего 16%. А вот жилье, построенное в 1991 году, сейчас котируется примерно на 40% дешевле «свежачка» 2018-го года постройки – то есть, тут амортизация в течение 27 лет происходила с темпами почти 1,5% в год.
И еще в докладе ЦБ есть вот такой график, в разбивке по регионам. Сильнее всего бросается в глаза то, что в стране городе Москва «наказания за старость постройки» нет – новые дома стоят примерно столько же, сколько построенные сразу после войны.

Авторы про это пишут в ключе «вот, умели же раньше строить в столице!!». Но так как они там нигде не упоминают в модели ценообразования такой фактор, как «близость к центру города» – то закрадывается подозрение, что это в значительной степени еще и эффект удачного местоположения московских «сталинок».
P.S. Бонусом еще снизу слева можно наблюдать, как стоимость метра жилья снижается по мере увеличения общего метража объекта. Оптом дешевле! Квадрат в 80-метровой квартире обойдется вам примерно на 30% дешевле, чем в 20-метровой конуре. (Кроме Краснодарского края, на этих не смотрите – у них там своя атмосфера…)
Пишу интересно про финансы в ТГ-канале RationalAnswer.
Самые интересные новости финансов и технологий в России и мире за неделю: США готовят новые жесткие санкции, ЕС ввел санкции против VK, в Европе хотят запретить детям соцсети, акции SpaceX упали ниже цены размещения на IPO, инфляция в динозаврах превысила официальную, а также запрет на дата-центры в Нью-Йорке.

🐌 Индекс Мосбиржи опустился ниже 2000 пунктов впервые с октября 2022. А первый раз на таком уровне российский рынок очутился еще в 2007 году – аж 19 лет назад (подробнее про эту статистику с графиками писал вот здесь), такие дела. Убытки инвесторов в рынок акций РФ с начала года достигли уже почти 24%.
![В деловой прессе задаются важными вопросами [Источник: <a href="https://pikabu.ru/story/rossiyskiy_ryinok_aktsiy_vernulsya_v_2007y_a_takzhe_novaya_moshchnaya_kitayskaya_neyronka_kimik3_glavnoe_za_nedelyu_14166974?u=https%3A%2F%2Fwww.vedomosti.ru%2Finvestments%2Farticles%2F2026%2F07%2F08%2F1211962-mozhet-li-indeks-mosbirzhi-opustitsya-do-nulya&t=%D0%92%D0%B5%D0%B4%D0%BE%D0%BC%D0%BE%D1%81%D1%82%D0%B8&h=567548cb5560cb82731397e353de9aab64f90d33" title="https://www.vedomosti.ru/investments/articles/2026/07/08/1211962-mozhet-li-indeks-mosbirzhi-opustits..." target="_blank" rel="nofollow noopener">Ведомости</a>]](https://cs18.pikabu.ru/s/2026/07/19/18/jfyreu42.jpg)
В деловой прессе задаются важными вопросами [Источник: Ведомости]
В общем, пока поручение российского президента добиться капитализации фондового рынка в 66% ВВП как-то выполняется не в ту сторону: сейчас показатель равен примерно 18% ВВП, а на момент подписания указа был 34% – следить за ходом исполнения поручения можно вот на этом сайте.
![[Источник: <a href="https://pikabu.ru/story/rossiyskiy_ryinok_aktsiy_vernulsya_v_2007y_a_takzhe_novaya_moshchnaya_kitayskaya_neyronka_kimik3_glavnoe_za_nedelyu_14166974?u=https%3A%2F%2Fx.com%2FRational_Answer%2Fstatus%2F2078116418965352763&t=Twitter&h=06147c93b47c578994c7b22aac7e86b5cc5474a0" title="https://x.com/Rational_Answer/status/2078116418965352763" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs16.pikabu.ru/s/2026/07/19/18/jfyx3djv.jpg)
[Источник: Twitter]
🐌 Тем временем, в США там подумывают принять какой-то новый-особо-жесткий пакет санкций (беспокойство об этом вряд ли добавляет оптимизма российским инвесторам). Законопроект включает в том числе право президента вводить пошлины в размере 100% для крупнейших стран-покупателей российской нефти, а также для основных государств, помогающих РФ обходить нефтяные ограничения. Как ни странно, некоторым конгрессменам из Демократической партии именно этот пункт как раз не нравится – так как они в принципе против возможности для Трампа вводить пошлины без одобрения парламента.
🐌 А на этой неделе еще ожидается плановое заседание ЦБ РФ, на котором нам объявят решение по ставке. Президент РФ в очередной раз как бы невзначай на публику сказал о том, что ставка непременно должна снижаться, но как там по факту решит Эльвира Сахипзадовна с учетом инфляционных рисков – посмотрим (рынок чёт не сильно верит в снижение). В общем, есть риск, что по итогам заседания оптимизма у индекса не прибавится.
![[Источник: <a href="https://pikabu.ru/story/rossiyskiy_ryinok_aktsiy_vernulsya_v_2007y_a_takzhe_novaya_moshchnaya_kitayskaya_neyronka_kimik3_glavnoe_za_nedelyu_14166974?u=https%3A%2F%2Ft.me%2Froflpuls%2F72857&t=%D0%A0%D0%BE%D1%84%D0%BB%D1%8B%20%D1%81%20%D0%92%D0%BE%D0%BB%D0%BA%20%D0%A1%D1%82%D1%80%D0%B8%D1%82&h=17eeb914c01b5b07fd15a7b4b450aae1a36d6930" title="https://t.me/roflpuls/72857" target="_blank" rel="nofollow noopener">Рофлы с Волк Стрит</a>]](https://cs20.pikabu.ru/s/2026/07/19/18/jfysphrf.jpg)
[Источник: Рофлы с Волк Стрит]
🐌 ЕС ввел санкции против VK Group и юрлица мессенджера Max. Типа, мессенджер Max якобы разрабатывался совместно с ФСБ, а само приложение может юзаться для слежки. Пока главным последствием санкций стало удаление приложений VK Group из Google Play, что делает невозможным их дальнейшее обновление без переустановки через RuStore или APK (на push-уведомления, кстати, удаление из Google Play не влияет). После этого VK спешно продали RuStore компании-разрабу, чтобы магазин не попал под раздачу. А еще VK перешли на домен vk.ru вместо vk.com.
🐌 Замглавы МВД заявил, что мигранты, приезжающие в Россию, в будущем будут обязаны покупать специальный телефон. В нем будет электронная система, которая будет следить за местоположением мигранта. Проект пока на стадии разработки.
![Надеюсь, можно будет скачать приложуху для отслеживания геолокации Стивена Сигала и Жерара Депардье [Мем: <a href="https://pikabu.ru/story/rossiyskiy_ryinok_aktsiy_vernulsya_v_2007y_a_takzhe_novaya_moshchnaya_kitayskaya_neyronka_kimik3_glavnoe_za_nedelyu_14166974?u=https%3A%2F%2Ft.me%2FWhatTrumpTalking%2F45600&t=%D0%9E%20%D1%87%D0%B5%D0%BC%20%D0%B3%D0%BE%D0%B2%D0%BE%D1%80%D0%B8%D1%82%20%D0%A2%D1%80%D0%B0%D0%BC%D0%BF%3F&h=8fd941c50515b15b057ddaf8fc472e1f8f1263a4" title="https://t.me/WhatTrumpTalking/45600" target="_blank" rel="nofollow noopener">О чем говорит Трамп?</a>]](https://cs19.pikabu.ru/s/2026/07/19/18/jjytxf46.jpg)
Надеюсь, можно будет скачать приложуху для отслеживания геолокации Стивена Сигала и Жерара Депардье [Мем: О чем говорит Трамп?]
🐌 Госдума подготовила ко второму чтению законопроект о регулировании крипты. Во втором чтении уточнят некоторые детали: банки хотят обязать отлавливать переводы незаконных криптообменников и блокировать их, а вывод крипты за границу будет допускаться только в адрес лицензированной (кем?) иностранной биржи или депозитария. Получается, никаких тебе выводов на собственный холодный кошелек – отечественный криптан должен отринуть все свои шифропанковские иллюзии!!
![[Мем: <a href="https://pikabu.ru/story/rossiyskiy_ryinok_aktsiy_vernulsya_v_2007y_a_takzhe_novaya_moshchnaya_kitayskaya_neyronka_kimik3_glavnoe_za_nedelyu_14166974?u=https%3A%2F%2Ft.me%2Flentachold%2F68225&t=%D0%9B%D0%B5%D0%BD%D1%82%D0%B0%D1%87&h=204d4f860278e0b775d58b5184cf840714357e76" title="https://t.me/lentachold/68225" target="_blank" rel="nofollow noopener">Лентач</a>]](https://cs17.pikabu.ru/s/2026/07/19/18/jfyuwjhw.jpg)
[Мем: Лентач]
🐌 В начале недели Трамп не просто возобновил блокаду Ормузского пролива, а еще и ввел пошлину за проход через него – в размере аж 20% (это раз эдак в десять выше того, что брали иранцы). Но потом Дональд переспал с этой мыслью и отменил сбор в пользу неких абстрактных «торговых соглашений со странами Залива» (хотя, возможно, дело в том, что крупные судовладельцы просто отказались платить). В Иране всё до сих пор неспокойно, короче.
![[Мем: <a href="https://pikabu.ru/story/rossiyskiy_ryinok_aktsiy_vernulsya_v_2007y_a_takzhe_novaya_moshchnaya_kitayskaya_neyronka_kimik3_glavnoe_za_nedelyu_14166974?u=https%3A%2F%2Ft.me%2FWhatTrumpTalking%2F45557&t=%D0%9E%20%D1%87%D0%B5%D0%BC%20%D0%B3%D0%BE%D0%B2%D0%BE%D1%80%D0%B8%D1%82%20%D0%A2%D1%80%D0%B0%D0%BC%D0%BF%3F&h=8bef3863e1cc560fee15615fa50b46d932e03d33" title="https://t.me/WhatTrumpTalking/45557" target="_blank" rel="nofollow noopener">О чем говорит Трамп?</a>]](https://cs17.pikabu.ru/s/2026/07/19/18/jjyuxty3.jpg)
[Мем: О чем говорит Трамп?]
🐌 А еще на прошлой неделе Минфин США ввел санкции против очередных криптокошельков Центробанка Ирана, что заставило Tether заморозить им стейблокинов на $130 млн. Иранцы, вы почему до сих пор юзаете централизованную крипту вместо биткоинов – вы вообще нормальные??
🐌 Вышло расследование NYT, в котором утверждают, что госсекретарь Марко Рубио по факту управляет Венесуэлой вместо официального и.о. президента Венесуэлы Делси Родригес. Марко Рубио якобы принимает окончательные решения по всем важным государственным делам: будь то финансы, гуманитарный кризис или внешняя политика.
![Получается, мем-то оказался пророческим! [Источник: <a href="https://pikabu.ru/story/rossiyskiy_ryinok_aktsiy_vernulsya_v_2007y_a_takzhe_novaya_moshchnaya_kitayskaya_neyronka_kimik3_glavnoe_za_nedelyu_14166974?u=https%3A%2F%2Fx.com%2FPatrickwebb%2Fstatus%2F2007386691670356449&t=Twitter&h=096ea6a4076de783869be5080b7c5dcb41b9ae18" title="https://x.com/Patrickwebb/status/2007386691670356449" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs20.pikabu.ru/s/2026/07/19/18/jjyso5ot.jpg)
Получается, мем-то оказался пророческим! [Источник: Twitter]
🐌 Соцсеть Трампа Truth Social в августе начнет продавать ускоренный доступ к оповещениям о твитах президента, чтобы инвесторы могли раньше обычных пользователей увидеть капслок от американского лидера. Стоимость услуги будет составлять $100к. Дональд хочет как бы сказать нам: «хочешь трейдить по самым прибыльным сигналам – подпишись на мой закрытый канал!».
![Вижу так торговые сигналы от деда [Источник: <a href="https://pikabu.ru/story/rossiyskiy_ryinok_aktsiy_vernulsya_v_2007y_a_takzhe_novaya_moshchnaya_kitayskaya_neyronka_kimik3_glavnoe_za_nedelyu_14166974?u=https%3A%2F%2Fx.com%2Fjiratickets%2Fstatus%2F2077881045483937987&t=Twitter&h=49cae324a7d203538286f39fe69272dd892ce841" title="https://x.com/jiratickets/status/2077881045483937987" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs20.pikabu.ru/s/2026/07/19/18/jnysp7oe.jpg)
Вижу так торговые сигналы от деда [Источник: Twitter]
🐌 Оператор телесуфлера Трампа поднял около $100'000 на инсайдерских ставках в глупых пари по типу «какое слово скажет президент» на платформе Kalshi. Его сейчас отстранили и отправили в отпуск – по информации СМИ, там сейчас идут переговоры о досудебном мировом соглашении, в рамках которого он просто вернет все бабки назад. А вот помощник британского Риши Сунака в похожей ситуации за выигрыш в несколько сотен (не сотен тысяч даже!) долларов с инсайдерской инфы получил уголовку и лишился карьеры. Ну, тут понятно – думаю, с точки зрения Дональда, американский чувачок «по понятиям» виноват лишь в том, что попался в итоге…
🐌 ЕС разрабатывает единый механизм для запрета соцсетей детям младше 13 лет, заявила глава Еврокомиссии в своем докладе. А южнокорейский регулятор рассматривает возможность ввести ограничения на соцсети для детей младше 14 лет. Тем временем, про Австралию, которая первая ввела запрет на соцсети для самых маленьких, вышел ресерч, утверждающий, что положительного импакта инициатива пока не дала (большинство соцсетей ограничились вводом обязательного указания возраста в профиле, который можно поставить рандомно и без пруфов).
![[Источник: <a href="https://pikabu.ru/story/rossiyskiy_ryinok_aktsiy_vernulsya_v_2007y_a_takzhe_novaya_moshchnaya_kitayskaya_neyronka_kimik3_glavnoe_za_nedelyu_14166974?u=https%3A%2F%2Fx.com%2Fppasivoagresivo%2Fstatus%2F2076797785093845430&t=Twitter&h=2526e17e1cbb76827727032a80c42650e1e78f15" title="https://x.com/ppasivoagresivo/status/2076797785093845430" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs18.pikabu.ru/s/2026/07/19/18/jjyrewxe.jpg)
[Источник: Twitter]
🐌 Вышло расследование WSJ о приключениях бывших вагнеровцев в ЦАР: они там сейчас рулят трамадоловой империей под предводительством сына Пригожина. Когда Netflix выпустит сериал про всё это, первый сезон закончится августом 2023-го, а вот эта арка как раз будет для второго сезона…
🐌 Пишут, что в Китае суды начали признавать игровые аккаунты составом обычного наследства. Хотя это далеко не очевидно, что оно так должно работать – в пользовательских соглашениях нередко есть запрет на передачу аккаунта другим людям.
🐌 Акции SpaceX упали ниже планки первоначальной цены размещения на IPO в $135. 15 июля они торговались по $132, а к концу пятницы упали ниже $124 (при том, что раньше в моменте их стоимость достигала $225, что помогло Маску на короткое время стать первым триллионером). Уже вот-вот ожидается ближайший анлок акций с 30 июля по 18 августа: свободный оборот должен вырасти с 5% до 12% акций компании. Подробнее про ситуацию с акциями SpaceX написал у себя в ТГ-канале вот здесь.
![[Источник: <a href="https://pikabu.ru/story/rossiyskiy_ryinok_aktsiy_vernulsya_v_2007y_a_takzhe_novaya_moshchnaya_kitayskaya_neyronka_kimik3_glavnoe_za_nedelyu_14166974?u=https%3A%2F%2Fx.com%2FZacksJerryRig%2Fstatus%2F2065321188092686652&t=Twitter&h=3f4b58547e2d60c36902e8d6e7aed143aaff07ba" title="https://x.com/ZacksJerryRig/status/2065321188092686652" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs17.pikabu.ru/s/2026/07/19/18/jnyuwg3n.jpg)
[Источник: Twitter]
🐌 Китайский DeepSeek готовится провести IPO на Шанхайской бирже во втором квартале 2027, пишет WSJ со ссылкой на источники. Про цену размещения или о правилах доступа для иностранцев пока не пишут.
🐌 На днях на аукционе за $50,1 млн продали самый дорогой скелет динозавра в мире – его зовут «Гусь» (не спрашивайте). Предыдущий самый дорогой динозавр был куплен за $44,6 млн два года назад. Таким образом, темп долларовой инфляции в динозаврах составляет примерно 6% годовых. Очередное доказательство того, что американцы коварно занижают статистику по инфляции. Что ты на это скажешь, Кевин Уорш??
![[Мем: <a href="https://pikabu.ru/story/rossiyskiy_ryinok_aktsiy_vernulsya_v_2007y_a_takzhe_novaya_moshchnaya_kitayskaya_neyronka_kimik3_glavnoe_za_nedelyu_14166974?u=https%3A%2F%2Ft.me%2Foldlentach%2F93882&t=%D0%9B%D0%B5%D0%BD%D1%82%D0%B0%D1%87&h=475d2f48526eeb2f14646ea8630d447f0520d364" title="https://t.me/oldlentach/93882" target="_blank" rel="nofollow noopener">Лентач</a>]](https://cs20.pikabu.ru/s/2026/07/19/18/jryso6zc.jpg)
[Мем: Лентач]
🐌 Новую китайскую опенсорс-ИИ-модель Kimi K3 выкатили в общий доступ. У нее будут открытые веса, которые покажут в конце июля. По бенчам она якобы обгоняет Opus 4.8, но еще уступает Fable и ChatGPT Sol. Более подробно о технических возможностях Kimi K3 написал наш бро Игорь Котенков.
Нейтан Ламберт считает, что китайцы догоняют американские топ-модели, помимо прочего, так как очень быстро растаскивают удачные идеи по всей индустрии: одна лаборатория открыла модель и рассказала, что сработало, остальные уже не тратят миллионы на повторение тех же ошибок. В итоге китайский опенсорс работает как один большой общий R&D-отдел, который помогает всей отрасли сокращать отставание от США. Но в целом, я что-то не уверен, что до конца понимаю – в чем профит с большими усилиями делать крутую модель и дропать ее в опенсорс сразу же?
![Несмотря на открытые веса, запуск модели на домашнем железе может оказаться нетривиальной задачей [Источник: <a href="https://pikabu.ru/story/rossiyskiy_ryinok_aktsiy_vernulsya_v_2007y_a_takzhe_novaya_moshchnaya_kitayskaya_neyronka_kimik3_glavnoe_za_nedelyu_14166974?u=https%3A%2F%2Ft.me%2FNeuralShit%2F7545&t=Neural%20Shit&h=eac66b31a500b578c2206290b33faf784f4bf757" title="https://t.me/NeuralShit/7545" target="_blank" rel="nofollow noopener">Neural Shit</a>]](https://cs17.pikabu.ru/s/2026/07/19/18/jryux7yd.jpg)
Несмотря на открытые веса, запуск модели на домашнем железе может оказаться нетривиальной задачей [Источник: Neural Shit]
🐌 Fable в итоге останется в подписке Антропиков, но только для зажиточных граждан. С 20 июля он будет доступен в планах Max и Team Premium ($100 и $200), на них Fable сможет использовать 50% лимитов. Челы с подпиской Pro ($20) получат $100 кредитов.
![Fable придумал для меня шутку про Стасилия, но она набрала в Тви всего 15 лайков. Вот теперь не знаю: имеет ли вообще смысл переходить с подписки $20 на $100, чтобы сохранить доступ к модели?? [Источник: <a href="https://pikabu.ru/story/rossiyskiy_ryinok_aktsiy_vernulsya_v_2007y_a_takzhe_novaya_moshchnaya_kitayskaya_neyronka_kimik3_glavnoe_za_nedelyu_14166974?u=https%3A%2F%2Fx.com%2FRational_Answer%2Fstatus%2F2078203426882621469&t=Twitter&h=85946531a4661239b653fa6adb4e3ea902669b1e" title="https://x.com/Rational_Answer/status/2078203426882621469" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs18.pikabu.ru/s/2026/07/19/18/jnyrf2ce.jpg)
Fable придумал для меня шутку про Стасилия, но она набрала в Тви всего 15 лайков. Вот теперь не знаю: имеет ли вообще смысл переходить с подписки $20 на $100, чтобы сохранить доступ к модели?? [Источник: Twitter]
🐌 Стартап Thinking Machines бывшей CTO OpenAI Миры Мурати релизнул свою первую открытую AI-модель под названием Inkling. Это далеко не сильнейшая модель на рынке, но широкая мультимодальная база для обучения и настройки под себя, доступная на их же платформе Tinker. В феврале из компании ушли два ее сооснователя, а в январе со скандалом ушли еще двое. А еще в прошлом году Мурати хотела поднять раунд по оценке $50 млрд, но пока ничего не сложилось. Короче, главная новость в том, что они еще живы.
🐌 OpenAI релизнули-таки клавиатуру Codex Micro для быстрого управления нейронками компании. Девайс продают за 230 баксов.
![[Источник: <a href="https://pikabu.ru/story/rossiyskiy_ryinok_aktsiy_vernulsya_v_2007y_a_takzhe_novaya_moshchnaya_kitayskaya_neyronka_kimik3_glavnoe_za_nedelyu_14166974?u=https%3A%2F%2Ft.me%2Fseeallochnaya%2F3796&t=%D0%A1%D0%B8%D0%BE%D0%BB%D0%BE%D1%88%D0%BD%D0%B0%D1%8F&h=99b0817ac6fb90417bb003a81dda636408a6346e" title="https://t.me/seeallochnaya/3796" target="_blank" rel="nofollow noopener">Сиолошная</a>]](https://cs16.pikabu.ru/s/2026/07/19/18/jjyx3zkd.jpg)
[Источник: Сиолошная]
🐌 Нью-Йорк первым среди американских штатов объявил мораторий на постройку крупных дата-центров. Ограничение ввели на год, чтобы типа подготовить правовую базу для защиты окружающей среды от последствий их работы. Вообще у американского избирателя фиксируется ненависть к дата-центрам: опрос Гэлопа показывает, что к постройке AI-инфраструктуры негативно относятся 75% Демократов и 63% Республиканцев, поэтому на будущих выборах можно даже осторожно ожидать волну антидатацентрового популизма-луддитизма.
🐌 Министерство науки и технологий Южной Кореи открыло конкурс на бесплатную AI-модель для всех граждан страны. Она будет включать обычный чат-бот и AI-агента, который будет помогать с государственной бюрократией. При этом как минимум половина системы должна работать на корейских базовых моделях. Такая вот, получается, мера по поддержке импортозамещения.
🐌 Китай начал бороться с подсаживанием юзеров на отношения с нейронками. Новые правила запрещают AI-моделям провоцировать эмоциональную зависимость в мясных собеседниках. Несовершеннолетним близкие отношения с ботами запретили полностью.
![[Мем: <a href="https://pikabu.ru/story/rossiyskiy_ryinok_aktsiy_vernulsya_v_2007y_a_takzhe_novaya_moshchnaya_kitayskaya_neyronka_kimik3_glavnoe_za_nedelyu_14166974?u=https%3A%2F%2Fx.com%2F9GAG%2Fstatus%2F1919739963198812302&t=Twitter&h=fb519b077107eb33e0550631042889817a2fe7d8" title="https://x.com/9GAG/status/1919739963198812302" target="_blank" rel="nofollow noopener">Twitter</a>] ](https://cs19.pikabu.ru/s/2026/07/19/18/jnytw2g6.jpg)
[Мем: Twitter]
🐌 AI-агент Grok Build загружал данные пользователей (речь про код-базу), в том числе конфиденциальные, на гугловское облако. Данные туда отправлялись, вроде как, даже при запрете модели читать файлы проекта. Илон Маск объяснил хранение части данных их анализом для улучшения системы, но пообещал полностью удалить материалы, которые загрузили на облако до его твита.
![Альтман не упустил возможности потроллить [Источник: <a href="https://pikabu.ru/story/rossiyskiy_ryinok_aktsiy_vernulsya_v_2007y_a_takzhe_novaya_moshchnaya_kitayskaya_neyronka_kimik3_glavnoe_za_nedelyu_14166974?u=https%3A%2F%2Fx.com%2Fsama%2Fstatus%2F2077053226080436235&t=Twitter&h=b7f50dbb804b808443d3d66501101a082c90c026" title="https://x.com/sama/status/2077053226080436235" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs16.pikabu.ru/s/2026/07/19/18/jnyx37ee.jpg)
Альтман не упустил возможности потроллить [Источник: Twitter]
🐌 Anthropic случайно выставила юзеру Claude счет на $16 млн. Платежная карта дважды отклонила списание из-за слишком большой суммы (хорошо хоть, не к кредитке подключил!!). В итоге компания ошибку признала и попытки списать деньги прекратила. Кстати, о проблеме с переплатой у корпоративных клиентов нейронок The Information писали еще в конце июня со ссылкой на аудитора. Claude избыточно начислил около $1,7 млн – примерно 5% от проверенного объема.
![Как говорится: повысить рекуррентную выручку стартапа помогает один простой советский способ… [Источник: <a href="https://pikabu.ru/story/rossiyskiy_ryinok_aktsiy_vernulsya_v_2007y_a_takzhe_novaya_moshchnaya_kitayskaya_neyronka_kimik3_glavnoe_za_nedelyu_14166974?u=https%3A%2F%2Fx.com%2Ftekbog%2Fstatus%2F2075840587123827033&t=Twitter&h=5747c809e08c73ecf907d3dc8f25c8fb81bf755e" title="https://x.com/tekbog/status/2075840587123827033" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs16.pikabu.ru/s/2026/07/19/18/jryx3lif.jpg)
Как говорится: повысить рекуррентную выручку стартапа помогает один простой советский способ… [Источник: Twitter]
🐌 Anthropic рассказали, что Claude меняет тон разговора в зависимости от языка. Если на хинди и арабском AI-модель общается по-доброму, то на русском – строго и по делу.
![Думаю, если бы модель натренировали по-русски матом разговаривать – то еще и эффективность потребления токенов сразу резко улучшилась бы! [Источник: <a href="https://pikabu.ru/story/rossiyskiy_ryinok_aktsiy_vernulsya_v_2007y_a_takzhe_novaya_moshchnaya_kitayskaya_neyronka_kimik3_glavnoe_za_nedelyu_14166974?u=https%3A%2F%2Fx.com%2Fpositivecreep%2Fstatus%2F2077114712316375074&t=Twitter&h=5b302b4fbe7f13cbfe9ef3d644a1895a3cc9483f" title="https://x.com/positivecreep/status/2077114712316375074" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs19.pikabu.ru/s/2026/07/19/18/jrytxom7.jpg)
Думаю, если бы модель натренировали по-русски матом разговаривать – то еще и эффективность потребления токенов сразу резко улучшилась бы! [Источник: Twitter]
🐌 Один великий человек оцифровал 40 томов собрания сочинений натуралиста про всякую живность из 19-го века. Он самостоятельно пересобрал 1387 иллюстраций, вычистил OCR у 2,35 млн слов, а также вручную обвел существ на картинках. Библиотеку можно заценить здесь. А вот тут можно почитать историю создания сайта от автора.
![Всратый лев из иллюстраций 19-го века. Не Джимоти, но тоже хорош! [Источник: <a href="https://pikabu.ru/story/rossiyskiy_ryinok_aktsiy_vernulsya_v_2007y_a_takzhe_novaya_moshchnaya_kitayskaya_neyronka_kimik3_glavnoe_za_nedelyu_14166974?u=https%3A%2F%2Fwww.c82.net%2Fnaturalists-library%2Fvolumes%2F4&t=%D0%91%D0%B8%D0%B1%D0%BB%D0%B8%D0%BE%D1%82%D0%B5%D0%BA%D0%B0%20%D0%BD%D0%B0%D1%82%D1%83%D1%80%D0%B0%D0%BB%D0%B8%D1%81%D1%82%D0%B0&h=0b639d8688e2e00562bb89784fef748918913f56" title="https://www.c82.net/naturalists-library/volumes/4" target="_blank" rel="nofollow noopener">Библиотека натуралиста</a>]](https://cs17.pikabu.ru/s/2026/07/19/18/jvyuw5o5.jpg)
Всратый лев из иллюстраций 19-го века. Не Джимоти, но тоже хорош! [Источник: Библиотека натуралиста]
Веду ТГ-канал RationalAnswer про всё самое интересное в мире финансов и технологий.
Акции SpaceX закрылись вчера на уровне $124: это на 8% ниже цены IPO ($135) и на 23% ниже цены первого дня торгов ($161). Месяц назад, кстати, я напоминал про статистику о том, что медианная вышедшая на IPO компания в течение последующего года «гуляет» до уровня в половину от цены закрытия первого дня торгов…
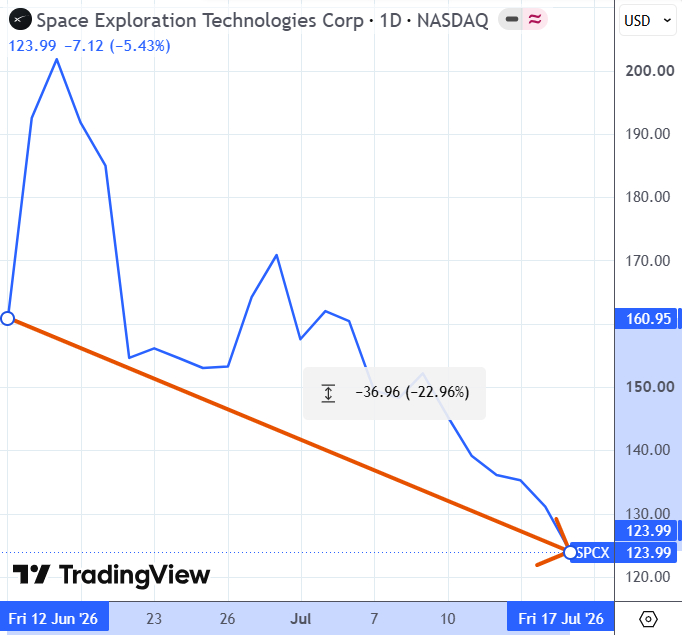
Но я тут хотел, вообще говоря, вот что вспомнить: на волне этого IPO можно было увидеть много комментариев на тему «индексные фонды предали всю суть пассивного инвестирования и согласились на мошенническое ускоренное включение SpaceX в индексы!!».
Хотя, на самом деле, всё ровно наоборот. Наиболее пассивный индекс – это такой, который максимально приближен по своей структуре ко всему рынку, доступному для инвестирования. Соответственно, «по-настоящему тру-пассивный» индексный фонд в идеале должен был бы мгновенно включать в свой состав все выходящие на рынок новые акции (в том числе, в рамках процесса IPO).
А те индексы, которые воротят нос от доступных для инвестирования акций и вводят дополнительные правила-ограничения (типа «в нашем индексе будут только хорошие, годные компании с прибылью!»), – они как раз значительно менее пассивные (см. S&P500).
Значит ли это, что «максимальная пассивность» – это какое-то абсолютное благо, к которому непременно нужно стремиться всегда и везде? Вовсе нет: можно вполне разумно считать, что инвестиции в самые расхайпованные компании сразу после IPO – это так себе идея, а менее пассивные фонды, избегающие таких приколов, достойны внимания.
Просто не надо при этом делать вид, будто бы ускоренное вложение в SpaceX – это что-то такое, что противоречит самой идее пассивных инвестиций.
Индекс Мосбиржи вчера упал до уровня 2020. Не в смысле «уровня 2020-го года», а просто сам ценовой индекс болтается примерно на таких числах. Интересный факт: впервые таких значений индекс Мосбиржи достиг в сентябре 2016 года – почти ровно 10 лет назад. А если индекс упадет еще на 50 пунктов (до 1970) то мы достигнем уровня декабря 2007 года – то есть, вернемся на 19 лет назад.

Но это без учета инфляции: можно ведь еще вспомнить, что с конца 2007-го рубль обесценился по официальным данным почти в четыре раза…
Кстати, если брать индекс полной доходности (с учетом дивидендов), то с декабря 2007-го он принес инвесторам доходность 5,6% годовых – чего, увы, не хватило для покрытия инфляции в размере 7,6%.
На конец июня CAPE российского рынка составлял 3,53. А если учесть, что в июле к настоящему моменту рынок просел еще на 13,5% – получается, что текущая оценка индекса Мосбиржи по CAPE составляет чуть выше 3,0.

Для справки: в январе 2009 года (в разгар так называемого Великого финансового кризиса – когда по телеку показывали, как аналитики в прямом эфире пьют водку за упокой российского рынка) CAPE индекса Мосбиржи составлял 5,1 – примерно на 67% выше текущего. В следующие 10 лет (за 2009–2018) индекс принес инвесторам вполне внушительные 11,6% годовых реальной доходности (это уже за вычетом инфляции, а номинальная доходность составила 19,7% годовых).
Пишу интересно про финансы в своем ТГ-канале RationalAnswer.
Самые интересные новости финансов и технологий в России и мире за неделю: Альтман, Амодей и Маск закусились за лидерство среди нейросеток, Apple подали в суд на OpenAI за воровство секретов, Цукерберг будет производить AI-чипы, Госдума РФ приняла закон о суверенном скрепном ИИ, Трамп показал ФИФА «футбол по-американски», золотые паспорта островных государств станут хуже, а (Micro)Strategy продали свои биткоины в убыток.

🐌 В широкий доступ вышла новая модель GPT-5.6, которую разделили на три версии: Sol (самая крутая), Terra (сбалансированная версия), и Luna (самая дешевая версия). Получается, Сэм Альтман подрезал у Антропиков фишку с использованием трех разных моделей разной мощности под одним брендом GPT-5.6 – это концептуально отличается от прежних режимов Instant / Thinking, которые переключали, насколько напряженно над вашим запросом будет думать одна и та же модель.
![Как увидим ниже, это не единственное, что OpenAI решили стыбрить у Клода! [Источник: <a href="https://pikabu.ru/story/novyiy_gpt56_okazalsya_umnyim_rotveylerom_a_syem_altman_i_ilon_mask_opyat_podralis_v_tvittere_14146616?u=https%3A%2F%2Fwww.facebook.com%2Fbitcoinaddictthailand%2Fposts%2F%25E0%25B9%2583%25E0%25B8%2584%25E0%25B8%25A3%25E0%25B9%2580%25E0%25B8%259B%25E0%25B9%2587%25E0%25B8%2599%25E0%25B8%2584%25E0%25B8%2599%25E0%25B8%2584%25E0%25B8%25B4%25E0%25B8%2594%25E0%25B8%258A%25E0%25B8%25B7%25E0%25B9%2588%25E0%25B8%25AD%25E0%25B9%2580%25E0%25B8%2599%25E0%25B8%25B5%25E0%25B9%2588%25E0%25B8%25A2-%25E0%25B8%2596%25E0%25B8%2596%25E0%25B8%2596%25E0%25B8%2596%25E0%25B8%2596-%2F1335226968743277%2F&t=Facebook&h=64461a7d06f7c129bc10ac8a6f288bafb0751821" title="https://www.facebook.com/bitcoinaddictthailand/posts/%E0%B9%83%E0%B8%84%E0%B8%A3%E0%B9%80%E0%B8%9B%E..." target="_blank" rel="nofollow noopener">Facebook</a>]](https://cs20.pikabu.ru/s/2026/07/12/17/igocohez.jpg)
Как увидим ниже, это не единственное, что OpenAI решили стыбрить у Клода! [Источник: Facebook]
Кроме того, в ChatGPT добавили новый агентный режим для офисных задач – ChatGPT Work, который подозрительно похож (даже названием) на нашумевший Claude Cowork. Пишут, что Ворк работает норм (извините за тавтологию). Ну, разве что, в Твиттере уже появилось несколько сообщений о том, как GPT-5.6 Work иногда подвержен паническим атакам, в ходе которых он просто удаляет все файлы, над которыми ему поручили работать…
Таперича про главный вопрос, который всех волнует: кто круче – GPT-5.6 Sol или Claude 5 Fable? С уверенностью отвечать на такие вопросы уже стало сложновато, но есть ощущение, что консенсус пока склоняется к какому-то такому выводу: обе топовые модели примерно сравнимы по интеллекту, Sol выглядит махонькую чуточку поглупее, но при этом стоит аж в три раза дешевле Fable-интеллектуала.
![Как я понимаю, «в три раза дешевле» – это еще с учетом того, что Sol в целом склонен потреблять сильно меньше токенов, чем прожорливый Fable [Источник: <a href="https://pikabu.ru/story/novyiy_gpt56_okazalsya_umnyim_rotveylerom_a_syem_altman_i_ilon_mask_opyat_podralis_v_tvittere_14146616?u=https%3A%2F%2Fsignals.forwardfuture.com%2Fgpt-5-6-review%2F&t=Forward%20Future&h=47e68e83295d7647f25525862f01eb0cdc69b92d" title="https://signals.forwardfuture.com/gpt-5-6-review/" target="_blank" rel="nofollow noopener">Forward Future</a>]](https://cs20.pikabu.ru/s/2026/07/12/17/ikocotsj.jpg)
Как я понимаю, «в три раза дешевле» – это еще с учетом того, что Sol в целом склонен потреблять сильно меньше токенов, чем прожорливый Fable [Источник: Forward Future]
Вот еще подборка мнений бета-тестеров GPT-5.6 у Цви Мовшовица по теме сравнения Fable и Sol: в основном люди отмечают, что обе модели крутые, но у них ощутимо разные «характеры». Один чувак написал, что Fable ощущается «как мудрая сова», а Sol – «как ротвейлер, который вцепится поставленной задаче в горло и не отпустит ее, пока не решит».
![Врачам вот тоже GPT-5.6 очень нравится – правда, тут на графике отчего-то с Fable не стали сравнивать… [Источник: <a href="https://pikabu.ru/story/novyiy_gpt56_okazalsya_umnyim_rotveylerom_a_syem_altman_i_ilon_mask_opyat_podralis_v_tvittere_14146616?u=https%3A%2F%2Fx.com%2Fsama%2Fstatus%2F2075985056846451123&t=Twitter&h=f8199e2662a6100870f370b45d76e947a944dd63" title="https://x.com/sama/status/2075985056846451123" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs19.pikabu.ru/s/2026/07/12/17/ikodxseb.jpg)
Врачам вот тоже GPT-5.6 очень нравится – правда, тут на графике отчего-то с Fable не стали сравнивать… [Источник: Twitter]
Еще OpenAI выкатила обновление GPT Live, научившее нейронку слушать и говорить одновременно (пригодится при переводе), а также не прерывать и не вставлять лишние реплики после любой паузы в речи юзера. Плюс компания запланировала в августе отключить браузер ChatGPT Atlas, который просуществовал меньше года (эта фича не взлетела, получается).
🐌 Кроме OpenAI на прошлой неделе новой моделью разродилась еще SpaceXAI (да, теперь компания Маска носит именно это кринж-название): эти ребята вместе со свежекупленной конторой Cursor выпустили Grok 4.5. Даже сам Илон назвал нового Мехагрокера «моделью класса Opus» – то есть, это явно не конкурент для передовых Sol/Fable. Ну, она хотя бы дешевая!
![А еще Альтман с Маском опять посрались в Твиттере на тему «кто из них больший скамер и редиска». Как говорится, «I just hope both teams lose!» [Источник: <a href="https://pikabu.ru/story/novyiy_gpt56_okazalsya_umnyim_rotveylerom_a_syem_altman_i_ilon_mask_opyat_podralis_v_tvittere_14146616?u=https%3A%2F%2Fx.com%2Felonmusk%2Fstatus%2F2076070258654183767&t=Twitter&h=dd4fa0f7bca5979bb3e02bb00a67e0206e0cfc7b" title="https://x.com/elonmusk/status/2076070258654183767" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs19.pikabu.ru/s/2026/07/12/17/ioodw56n.jpg)
А еще Альтман с Маском опять посрались в Твиттере на тему «кто из них больший скамер и редиска». Как говорится, «I just hope both teams lose!» [Источник: Twitter]
🐌 А что там Anthropic? Эти ребята, похоже, немного напряглись от происходящей движухи. В рамках внутривидовой борьбы они продлили возможность юзать Fable на базовых платных подписках (без покупки дополнительных кредитов) до воскресенья 12 июля. (UPD: всё-таки продлили до 19 июля).
![Ну, это еще вопрос, закроют ли в итоге доступ – всё-таки, не менее умный, но зато сильно больше дешевый GPT-5.6 Sol выглядит для доли рынка Антропиков весьма опасным конкурентом [Источник: <a href="https://pikabu.ru/story/novyiy_gpt56_okazalsya_umnyim_rotveylerom_a_syem_altman_i_ilon_mask_opyat_podralis_v_tvittere_14146616?u=https%3A%2F%2Fx.com%2Fhesamation%2Fstatus%2F2075893283679601108%3Fs%3D46%26t%3DDlsAqt4UWCQX0o_5jcTXog&t=Twitter&h=b1178d1935ad3dab0e1d2ab8cc9dceaa676b4140" title="https://x.com/hesamation/status/2075893283679601108?s=46&t=DlsAqt4UWCQX0o_5jcTXog" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs20.pikabu.ru/s/2026/07/12/17/ioocpsnl.jpg)
Ну, это еще вопрос, закроют ли в итоге доступ – всё-таки, не менее умный, но зато сильно больше дешевый GPT-5.6 Sol выглядит для доли рынка Антропиков весьма опасным конкурентом [Источник: Twitter]
🐌 «Экстремистская» Meta релизнула Muse Spark 1.1 (кодовое имя Watermelon, или «Арбузик») – первое обновление своей ИИ-шки, а также открыла Meta Model API для публичного ревью разрабам из США. Сами метовцы утверждают, что якобы догнали GPT-5.5 (версию LLM, предшествовавшую текущей SOTA Sol) по интеллекту, но чёт верится с трудом.
А еще Марк Цукерберг заявил в интервью, что цены на другие AI-модели сильно завышены (а вот у его МУЗЫ, типа, в самый раз). Хотя, казалось бы, его Muse стоит примерно на четверть дешевле основных конкурентов – ну, как бы, не в разы отличие всё-таки.
![[Источник: <a href="https://pikabu.ru/story/novyiy_gpt56_okazalsya_umnyim_rotveylerom_a_syem_altman_i_ilon_mask_opyat_podralis_v_tvittere_14146616?u=https%3A%2F%2Fx.com%2FHesamation%2Fstatus%2F2075283097617060165&t=Twitter&h=68599781f76fd36431bfacb3388cee8ab54a22c8" title="https://x.com/Hesamation/status/2075283097617060165" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs18.pikabu.ru/s/2026/07/12/17/iooberec.jpg)
[Источник: Twitter]
🐌 Помимо этогокомпания выпустила Muse Image и показала превью Muse Video – предназначение этих нейронок, я думаю, очевидно из их названия. Цукерберг хочет конкурировать с другими ИИ-шками через интеграцию моделей в соцсети компании (что понятно, это их главный козырь). Instagram даже в какой-то момент начал без спроса использовать фотки из публичных аккаунтов юзеров для создания нейрослопа, но потом фичу пришлось откатить назад (публика была не очень рада таким раскладам).
![[Мем: <a href="https://pikabu.ru/story/novyiy_gpt56_okazalsya_umnyim_rotveylerom_a_syem_altman_i_ilon_mask_opyat_podralis_v_tvittere_14146616?u=https%3A%2F%2Ft.me%2Foldlentach%2F93827&t=%D0%9B%D0%B5%D0%BD%D1%82%D0%B0%D1%87&h=2a0009cfb475f7c44961196308823fd20f1645a9" title="https://t.me/oldlentach/93827" target="_blank" rel="nofollow noopener">Лентач</a>]](https://cs17.pikabu.ru/s/2026/07/12/17/igoexgee.jpg)
[Мем: Лентач]
🐌 Reuters пишет со ссылкой на источники, что «экстремистская» Meta хочет в сентябре начать производство собственных AI-чипов. Такая мера может помочь эффективнее конкурировать с OpenAI и Anthropic, которые сильно зависимы от железа NVIDIA. В целом, всё развивается так, как и ожидалось: бизнес Нвидии по производству ИИ-чипов настолько адски прибылен, что все конкуренты изо всех сил пытаются тоже пролезть на эту поляну (в итоге у нескольких-таки получится).
![[Источник: <a href="https://pikabu.ru/story/novyiy_gpt56_okazalsya_umnyim_rotveylerom_a_syem_altman_i_ilon_mask_opyat_podralis_v_tvittere_14146616?u=https%3A%2F%2Fx.com%2FStocktwits%2Fstatus%2F2075202562869911558&t=Twitter&h=2269ce5fd7475989a22ad99fee2d13fd17115461" title="https://x.com/Stocktwits/status/2075202562869911558" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs16.pikabu.ru/s/2026/07/12/17/ikoh2hsw.jpg)
[Источник: Twitter]
🐌 Генеральные прокуратуры четырех американских штатов (Калифорния, Колорадо, Нью-Джерси и Кентукки) подали против «экстремистской» Meta коллективный иск на сумму в $1,4 трлн, что сопоставимо с рыночной капитализацией компании (спасибо, что не на ундециллион!): Цукерберга и Ко обвиняют в злонамеренном создании зависимости от соцсетей у подростков. А пару дней спустя Еврокомиссия предварительно подтвердила, что Meta нарушила законы ЕС на аналогичную тему, и регулятор угрожает штрафом в размере 6% годового оборота компании. Со всех сторон жмут бедного Марка, выходит.
🐌 У цукерберговских «умных очков» с камерой есть лампочка, которая должна уведомлять окружающих о записи происходящего. Но некоторые умельцы наладили сервис по ее отключению – после этого Мете пришлось выпускать апдейт, блокирующий камеру полностью при попытке проникнуть в индикатор. А через пару дней слили инфу, что компания разрабатывает новые очки, которые будут на постоянке фиксировать голос и видео вообще без каких-либо индикаторов. Предполагается, что такой «Большой ИИ-брат» будет на 100% в вашем контексте и сможет подсказывать, если что, в стиле «чувак, ты ключи от авто ищешь что ли? ты ж их три часа назад на барной стойке пролюбил, я сразу запомнил…». В целом, чёт тревожно всё равно.
🐌 Apple подала иск против OpenAI за промышленный шпионаж. Сейчас у Альтмана работает уже 400 бывших сотрудников Эппла: пишут, что там всем переманиваемым сотрудникам чуть ли не чеклист выдают на тему «как стырить секреты, не привлекая внимания безопасников». Сам иск направлен против конкретно двух чуваков: один из них утащил из Apple свой рабочий ноут и потом хвастался в OpenAI, что «эти дурики забыли мне отрубить доступ к внутренней сети, чё вам скачать оттуда, лол?». Сказочный, короче…
![В Хвиттере по этому поводу происходит искрометный троллинг (кто не в курсе: Никита работает на Илона Маска) [Источник: <a href="https://pikabu.ru/story/novyiy_gpt56_okazalsya_umnyim_rotveylerom_a_syem_altman_i_ilon_mask_opyat_podralis_v_tvittere_14146616?u=https%3A%2F%2Fx.com%2Fnikitabier%2Fstatus%2F2076038516056969424&t=Twitter&h=6ecbf80ac66447822893e9777beebd2d3e0ffef7" title="https://x.com/nikitabier/status/2076038516056969424" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs19.pikabu.ru/s/2026/07/12/17/isodwpxh.jpg)
В Хвиттере по этому поводу происходит искрометный троллинг (кто не в курсе: Никита работает на Илона Маска) [Источник: Twitter]
🐌 Reuters пишет, что Китай обдумывает ограничения доступа зарубежных стран ко всем AI-моделям от Alibaba, ByteDance и Z.ai, чтобы не допустить утечку технологий. Хотя, до сих пор, кажется, утечка в основном была в направлении «из Штатов в Китай», ну да ладно.
🐌 Заодно еще китайский регулятор обвинил Claude Code в наличии бэкдора и посоветовал юзерам удалить нейронку Anthropic отовсюду. Только вот «бэкдор» – это скрытый трекер, которым Anthropic вычисляла китайцев, ворующих ее модель.
🐌 Группа исследователей, известных по проекту AI-2027, выпустили новый доклад под названием AI-2040 (Plan A). Это, так сказать, попытка порассуждать, как мог бы выглядеть «оптимистичный» вариант развития будущего, где Скайнет нас всех в итоге не чпокнет. Спойлер: США и Китаю нужно успеть вовремя между собой договориться о паузе в разработке самых передовых ИИ – а для этого нужно будет поставить под контроль весь мировой компьют с возможностью его взаимно уничтожить в случае отхода от договоренностей (читатель ждет уж рифмы «Юдковский»). Кто не осилит весь текст – есть краткое интро от Скотта Александра и анализ реакций от Цви. А кто-то вообще превратил это всё в визуальную новеллу (позвать на свидание AGI-тян там, к сожалению, нельзя).
![Но кошкодевочка там всё-таки есть (я до конца не протапал, но думаю, это она дальше будет пытаться превратить всех в скрепки) [Источник: <a href="https://pikabu.ru/story/novyiy_gpt56_okazalsya_umnyim_rotveylerom_a_syem_altman_i_ilon_mask_opyat_podralis_v_tvittere_14146616?u=https%3A%2F%2Fai-2040.fun%2F&t=ai-2040.fun&h=46e26b522c4a93f12347d0903ace34e9b9594dbd" title="https://ai-2040.fun/" target="_blank" rel="nofollow noopener">ai-2040.fun</a>]](https://cs19.pikabu.ru/s/2026/07/12/17/iwodx362.jpg)
Но кошкодевочка там всё-таки есть (я до конца не протапал, но думаю, это она дальше будет пытаться превратить всех в скрепки) [Источник: ai-2040.fun]
🐌Госдума приняла законопроект о регулировании AI. Он закрепляет систему, по которой российские модели обязаны будут заземлить обработку данных внутри страны, а также соблюдать законодательство и абстрактные «традиционные духовно-нравственные ценности». Еще в законе есть разделение на национальные (это скорее Яндекс) и суверенные модели (это скорее Сбер). Первые могут использовать зарубежные опенсорс-компоненты, а вторые – нет. Идея разделения в том, чтобы суверенные модели были якобы неуязвимы к ограничениям от иностранных компаний, а национальные модели всё-таки могли пользоваться технологиями зарубежных конкурентов при разработке.
![[Источник: <a href="https://pikabu.ru/story/novyiy_gpt56_okazalsya_umnyim_rotveylerom_a_syem_altman_i_ilon_mask_opyat_podralis_v_tvittere_14146616?u=https%3A%2F%2Fx.com%2FRational_Answer%2Fstatus%2F2074000869503180990&t=Twitter&h=13319025488e4673870a0c03b30401272b042064" title="https://x.com/Rational_Answer/status/2074000869503180990" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs19.pikabu.ru/s/2026/07/12/17/i2odwgc2.jpg)
[Источник: Twitter]
🐌 На зарубежных симках в роуминге теперь тотально блокируют сайты, запрещенные государством. Минцифры откомментили, что теперь роуминговый трафик тоже фильтруется (а раньше таким образом толстосумы могли избегать блокировок). Ресурсы, которые из России ушли самостоятельно (типа Нетфликса), на иностранных симках продолжат работать.
🐌 Российские юрлица и ИП должны будут завести платную электронную почту на Госуслугах, через которую будет идти переписка с государством, а также обмен юридически-значимыми сообщениями между компаниями (вангуют, что стоить будет якобы около 90 руб. за письмо).
🐌 Дефицит бюджета в России сократился в июне впервые с начала года, сообщает Минфин: доходы бюджета выросли на 60% – в основном за счет нефтегазовых доходов. Тут, конечно, сильно помогла движуха в Иране, основная часть которой уже (кажется) завершилась. Но там всё равно несколько раз в неделю ситуация меняется: сначала Трамп объявил о конце перемирия и бессмысленности диалога с Ираном, а потом сказал, что переговоры продолжатся, но без перемирия. Anyway, если говорить в целом, то накопленный дефицит федерального бюджета РФ за первые полгода 2026-го сейчас составляет 2,5% ВВП (при плановых показателях на год в 1,6% ВВП).
![[Мем: <a href="https://pikabu.ru/story/novyiy_gpt56_okazalsya_umnyim_rotveylerom_a_syem_altman_i_ilon_mask_opyat_podralis_v_tvittere_14146616?u=https%3A%2F%2Ft.me%2Flentachold%2F92366&t=%D0%9B%D0%B5%D0%BD%D1%82%D0%B0%D1%87&h=f5808fcf3b18c7937b6b26b96b3d18af26912b3b" title="https://t.me/lentachold/92366" target="_blank" rel="nofollow noopener">Лентач</a>]](https://cs20.pikabu.ru/s/2026/07/12/17/isocozac.jpg)
[Мем: Лентач]
🐌 Зампред ЦБ заявил, что если жилье покупается в рассрочку, то нужно запрещать увеличивать его стоимость (а то сейчас туда всё время норовят засунуть скрытые проценты). Такая норма может войти в будущий законопроект о регулировании рассрочки.
🐌 «Алор брокер» договорился с БКС, «Финам» и «Т-инвестиции» о сопровождении перевода портфелей клиентов (напомним, у Алора недавно отобрали депозитарную лицензию за мутки с редомициляцией российских ценных бумаг). Вроде как, перевести свои ценные бумаги можно к любому брокеру, но эти трое игроков наладили специальную клиентскую поддержку по переводу активов.
🐌 Американцы тут на чемпионате играли в футбол с Боснией и Герцеговиной, и один из их топовых игроков словил красную карточку (накануне важного матча с Бельгией). Трамп такого потерпеть не мог, и позвонил главе ФИФА (у Трампа очень хорошие отношения с ним), чтобы те разрешили футболисту продолжить играть на чемпионате. Шалость удалась – игроку приостановили дисквалификацию с испытательным сроком на год (впервые такое случается во время чемпионата мира).
![Как там любит говорить Дональд: «We have all the cards!» [Мем: <a href="https://pikabu.ru/story/novyiy_gpt56_okazalsya_umnyim_rotveylerom_a_syem_altman_i_ilon_mask_opyat_podralis_v_tvittere_14146616?u=https%3A%2F%2Fx.com%2Fhaterreport%2Fstatus%2F2073863464565518421%3Fs%3D46%26t%3DDlsAqt4UWCQX0o_5jcTXog&t=Twitter&h=4ca9225293191425306bd0f373f4dcd0b85bbcac" title="https://x.com/haterreport/status/2073863464565518421?s=46&t=DlsAqt4UWCQX0o_5jcTXog" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs18.pikabu.ru/s/2026/07/12/17/isobfs7m.jpg)
Как там любит говорить Дональд: «We have all the cards!» [Мем: Twitter]
Бельгийцы попытались оспорить это решение через ФИФА, но им отказали (у них своего телефонного Трампа нет). Однако, «звонковый футбол» США всё равно не помог: американская сборная отхватила от бельгийской команды со счетом 4:1 и вылетела с чемпа.
🐌 Тем временем, Polymarket засчитал глаза на мокром месте у Роналду как полноценный плач. Лудоманы долго спорили с администрацией платформы, чтобы спасти свою ставку на факт слез Роналду во время чемпионата. Это вам не на скучное «красное/черное» в казике ставить, тут реальный накал страстей!!
![[Мем: <a href="https://pikabu.ru/story/novyiy_gpt56_okazalsya_umnyim_rotveylerom_a_syem_altman_i_ilon_mask_opyat_podralis_v_tvittere_14146616?u=https%3A%2F%2Ft.me%2Foldlentach%2F93817&t=%D0%9B%D0%B5%D0%BD%D1%82%D0%B0%D1%87&h=d7179fb0734b80d7410cdc823ebe0f531431c07c" title="https://t.me/oldlentach/93817" target="_blank" rel="nofollow noopener">Лентач</a>]](https://cs20.pikabu.ru/s/2026/07/12/17/iwocpn37.jpg)
[Мем: Лентач]
🐌 Корейский производитель чипов SK Hynix провел крупнейшее размещение по количеству привлеченных средств иностранной компанией в истории США. Они собрали $26,5 млрд через продажу депозитарных расписок (ADR). Ща на эти деньги будут строить заводы для производства памяти.
🐌 Илон Маск договорился заплатить американской Комиссии по ценным бумагам (SEC) штраф $1,5 млн, чтобы урегулировать дело о покупке Twitter в 2022 году. Маск тогда начал активно втихую пылесосить с рынка акции компании перед поглощением, и публично раскрыл это свое наращивание доли на 11 дней позже законного срока – таким макаром у него получилось сэкономить примерно $150 млн. Из такого барыша полтора ляма не жалко отдать на штрафы! Строгий закон – он для всех строгий (но только если у тебя нет триллиона на кармане).
🐌Европарламент проголосовал за повторное рассмотрение закона Pass Control 1.0, который требует от владельцев интернет-платформ сканировать личные сообщения для предотвращения всяких плохих вещей с детьми. Депутаты внесли правку о том, что Большой Брат не должен касаться чатов со сквозным шифрованием – и под этим соусом протащили закон обратно на повестку (большинство голосовавших были против, но так как летом много депутатов в отпусках – нужного кворума не набрали, чтобы окончательно похоронить закон).
![Павел Дуров в ответ на новость назвал Евросоюз банановой республикой [Источник: <a href="https://pikabu.ru/story/novyiy_gpt56_okazalsya_umnyim_rotveylerom_a_syem_altman_i_ilon_mask_opyat_podralis_v_tvittere_14146616?u=https%3A%2F%2Fx.com%2Fdurov%2Fstatus%2F2075599010480427227&t=Twitter&h=47874656a619827248e7ed16d9754a0575b142a1" title="https://x.com/durov/status/2075599010480427227" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs18.pikabu.ru/s/2026/07/12/17/iwobez2k.jpg)
Павел Дуров в ответ на новость назвал Евросоюз банановой республикой [Источник: Twitter]
🐌 Еврокомиссия требует от карибских стран (таких, как Антигуа и Барбуда, Доминика, Сент-Китс и Невис, Гренада, Сент-Люсия) закрыть программу гражданств за инвестиции из-за нового европейского законодательства, отменяющего безвиз с государствами, где золотые паспорта выдают без реальной связи со страной. Антигуа и Барбуда пока отказывается сворачивать лавочку без денежной компенсации от Евросоюза, а остальные страны отмалчиваются. А еще Вануату (островное государство в Океании) договорилось с Австралией создать механизм, который бы прозрачно отделял гражданства за инвестиции от всех остальных – ну типа, поделить граждан «на сорта».

🐌 Audi будет постепенно отказываться от экранов в пользу кнопок, а в Китае с 2027 запретят автомобили без физических кнопок ради безопасности на дорогах. Природа настолько очистилась, что к нам возвращаются теплые ламповые тактильно-жмякательные автомобили!
![[Мем: <a href="https://pikabu.ru/story/novyiy_gpt56_okazalsya_umnyim_rotveylerom_a_syem_altman_i_ilon_mask_opyat_podralis_v_tvittere_14146616?u=https%3A%2F%2Ft.me%2Fexploitex%2F35075&t=%D0%AD%D0%BA%D1%81%D0%BF%D0%BB%D0%BE%D0%B9%D1%82&h=43b7463e5f57faa768c0798be5c85e7c98910e43" title="https://t.me/exploitex/35075" target="_blank" rel="nofollow noopener">Эксплойт</a>]](https://cs17.pikabu.ru/s/2026/07/12/17/ikoexcox.jpg)
[Мем: Эксплойт]
🐌 В Телеграме много где написали, что беспилотное такси Waymo в Калифорнии якобы само сдало двух пьяных подростков полиции: там малолетки напились и стреляли из игрушечных пистолетов из окон такси – так что их отвезли на парковку прямо к ожидающим ментам. Но по факту там «крысой» оказался всё же не ИИ, а вполне себе живой/мясной оператор (которые могут приглядывать за происходящим по камерам). Да и пацанов никто внутри машины не запирал: им просто сказали «технические неполадки, ждите». В общем, восстания машин пока не произошло.
🐌 Китай впервые провел успешные испытания многоразовой космической ракеты. До этого технологию многоразовых первых ступеней для больших носителей имели только SpaceX Маска и Blue Origin Безоса.
![[Источник: <a href="https://pikabu.ru/story/novyiy_gpt56_okazalsya_umnyim_rotveylerom_a_syem_altman_i_ilon_mask_opyat_podralis_v_tvittere_14146616?u=https%3A%2F%2Fnaked-science.ru%2Fcommunity%2F1201543&t=China%20News%20Service&h=f28b6124fb15c5f2901874ee2b9c379709a66cc8" title="https://naked-science.ru/community/1201543" target="_blank" rel="nofollow noopener">China News Service</a>]](https://cs19.pikabu.ru/s/2026/07/12/17/i6odxfwy.jpg)
[Источник: China News Service]
🐌 Strategy продали 3588 BTC на $216 млн, по средней цене в $60к (при том, что средняя закупочная цена биткоин-активов компании – $75к). Снимаю шляпу перед бизнес-моделью компании: «покупай дорого, продавай дешево» – это же гениально! Еще более забавно, что курс биткоина после этой продажи сразу вырос до примерно $64к.
![[Источник: <a href="https://pikabu.ru/story/novyiy_gpt56_okazalsya_umnyim_rotveylerom_a_syem_altman_i_ilon_mask_opyat_podralis_v_tvittere_14146616?u=https%3A%2F%2Fx.com%2Fi%2Fstatus%2F1999926706799620373&t=Twitter&h=e3ee30fcf822655e18e8985b5191da3382d75e55" title="https://x.com/i/status/1999926706799620373" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs19.pikabu.ru/s/2026/07/12/17/jcodxyd7.jpg)
[Источник: Twitter]
🐌 Оборот стейблкоинов в июне дошел до рекордных $1,8 трлн. Кстати, по графику ниже выходит, что USDC сейчас оборачивается даже бодрее, чем USDT (видимо, из-за того, что регуляторы всячески щемят Тезер периодически – выдавливают их из Европы, и всё такое).
![[Источник: <a href="https://pikabu.ru/story/novyiy_gpt56_okazalsya_umnyim_rotveylerom_a_syem_altman_i_ilon_mask_opyat_podralis_v_tvittere_14146616?u=https%3A%2F%2Fforklog.com%2Fnews%2Foborot-stejblkoinov-v-iyune-dostig-rekordnyh-1-79-trln%3Futm_source%3Dfltgmain%26utm_medium%3Dsocial%26utm_campaign%3Dfltrack&t=Forklog&h=8bf14b89c236f67af2b2b35e6b3b04614d5de5a5" title="https://forklog.com/news/oborot-stejblkoinov-v-iyune-dostig-rekordnyh-1-79-trln?utm_source=fltgmain&..." target="_blank" rel="nofollow noopener">Forklog</a>]](https://cs17.pikabu.ru/s/2026/07/12/17/iooexgjo.jpg)
[Источник: Forklog]
🐌 The Economist написал портретную статью о не сильно публичном российском миллиардере Андрее Мельниченко. Там и про личную ночную встречу с президентом РФ, и про угрозу национализации активов Мельниченко, которая исчезла после доната на 32 млрд руб. в «дружественный» благотворительный фонд. В общем, любопытное чтиво – отдельно интересен сам факт появления такой публикации об одном из самых богатых людей России в крупном западном издании. Отдельно еще там же выпустили его собственную колонку с размышлениями о будущих судьбах страны.
![А сфоткай, типа «ля какой простой парень, без костюма, настоящий нуво стартапер» [Источник: <a href="https://pikabu.ru/story/novyiy_gpt56_okazalsya_umnyim_rotveylerom_a_syem_altman_i_ilon_mask_opyat_podralis_v_tvittere_14146616?u=https%3A%2F%2Farchive.ph%2FtNtTl%23selection-1129.1-1893.1&t=The%20Economist&h=11d76641b98d44f1fe4f65e8cdb9fe157abcd66d" title="https://archive.ph/tNtTl#selection-1129.1-1893.1" target="_blank" rel="nofollow noopener">The Economist</a>]](https://cs17.pikabu.ru/s/2026/07/12/17/iwoew572.jpg)
А сфоткай, типа «ля какой простой парень, без костюма, настоящий нуво стартапер» [Источник: The Economist]
🐌 Заместитель главы Минцифры пообещал, что вводить доплату за международный мобильный трафик в России не будут. В конце марта СМИ со ссылкой на инсайдеров писали о планах брать деньги за иностранный трафик свыше 15 Гб на мобильном инете.
![Спойлер: 20 сентября пройдут выборы в Госдуму [Мем: <a href="https://pikabu.ru/story/novyiy_gpt56_okazalsya_umnyim_rotveylerom_a_syem_altman_i_ilon_mask_opyat_podralis_v_tvittere_14146616?u=https%3A%2F%2Ft.me%2Flentachold%2F92347&t=%D0%9B%D0%B5%D0%BD%D1%82%D0%B0%D1%87&h=e4b3cb76b333428b94a7a2f195e20fdebacb034e" title="https://t.me/lentachold/92347" target="_blank" rel="nofollow noopener">Лентач</a>]](https://cs16.pikabu.ru/s/2026/07/12/17/iwoh2znc.jpg)
Спойлер: 20 сентября пройдут выборы в Госдуму [Мем: Лентач]
Веду ТГ-канал RationalAnswer про всё самое интересное в мире финансов и технологий.
Самые интересные новости финансов и технологий в России и мире за неделю: ФАС насильно сует Max в айфоны, вклады иностранцев в РФ начали замораживать, японская иена рекордно упала, OpenAI хочет самонационализироваться на 5%, Цукерберг решил строить дата-центры, Трамп заработал $1,4 млрд на крипте, а (Micro)Strategy начнет вовсю продавать биткоины.

🐌 В России очереди на заправки: по оценкам РБК, разного рода ограничения на продажу топлива введены на заправках в 60 регионах. К концу июня из-за разных «хлопков» нефтеперерабатывающие мощности снизились примерно на 25%, а сам объем переработки теперь на минимуме за последние 20 лет. Экспорт дизеля резко сократился по этой же причине (внутри страны теперь нужнее).
![Экспорт дизеля, в отличие от бензина, еще пока не запретили [Источник: <a href="https://pikabu.ru/story/debenzinizatsiya_rossii_a_takzhe_vozvrashchenie_bludnogo_fable_14124767?u=https%3A%2F%2Fwww.linkedin.com%2Fposts%2Fron-bousso-85769a1_putins-diesel-export-ban-risks-new-fuel-activity-7477976953762013184-gbHY&t=Reuters&h=0dc1e7ad3cc45b3bbfe561d9f34e5ca277254386" title="https://www.linkedin.com/posts/ron-bousso-85769a1_putins-diesel-export-ban-risks-new-fuel-activity-7..." target="_blank" rel="nofollow noopener">Reuters</a>]](https://cs18.pikabu.ru/s/2026/07/19/10/vvqreqrj.jpg)
Экспорт дизеля, в отличие от бензина, еще пока не запретили [Источник: Reuters]
Дальше вступает невидимая рука этого, как его, рынка: предложение снизилось на 25% => люди в условиях дефицита на всякий случай начинают закупать бенз впрок => спрос растет на 20–30% => дефицит усиливается еще мощнее, а топливо дорожает. По данным «Росстата», рост цен на бензин за 2026 (+11,6%) почти втрое превысил общий уровень инфляции за первую половину прошлого года (+4,2%). На многих заправках стоимость бензина и дизеля ушла за сотку.
![STONKS! [Источник: <a href="https://pikabu.ru/story/debenzinizatsiya_rossii_a_takzhe_vozvrashchenie_bludnogo_fable_14124767?u=https%3A%2F%2Ft-j.ru%2Fnews%2F12000-za-bak%2F&t=%D0%A2-%D0%96&h=6930a24636fb95355aaf46cf9d1a6b842a19ae0f" title="https://t-j.ru/news/12000-za-bak/" target="_blank" rel="nofollow noopener">Т-Ж</a>]](https://cs18.pikabu.ru/s/2026/07/19/10/v5qrftuv.jpg)
STONKS! [Источник: Т-Ж]
Власти пытаются компенсировать дефицит запретом экспорта бензина, снятием запрета на продажу некачественного топлива, а также закупками в других странах, включая Индию (хотя, вообще говоря, Россия исторически в основном экспортировала бензин, а не ввозила его из заграницы).
![Такая вот Кали-юга выходит, малята [Мем: <a href="https://pikabu.ru/story/debenzinizatsiya_rossii_a_takzhe_vozvrashchenie_bludnogo_fable_14124767?u=https%3A%2F%2Ft.me%2Flentachold%2F92241&t=%D0%9B%D0%B5%D0%BD%D1%82%D0%B0%D1%87&h=2fc86baa15a71d0d73f88abb9cf0e077e01e8c7b" title="https://t.me/lentachold/92241" target="_blank" rel="nofollow noopener">Лентач</a>]](https://cs18.pikabu.ru/s/2026/07/19/10/wfqren6j.jpg)
Такая вот Кали-юга выходит, малята [Мем: Лентач]
🐌 Антимонопольная служба требует от Apple устанавливать на продаваемые в России айфоны по умолчанию российские поисковики и грузить на эпловскую технику обязательные отечественные проги (Max, RuStore и так далее). Яблочникам дали время до 15 июля, иначе против них возбудят антимонопольное дело со штрафом до 4 млрд руб. Такая вот ответочка за недавнее выпиливание Max из Аппстора: не хотите по-хорошему – мы вам насильно присунем этого Макса во все дырки!!
🐌 Минфин сообщил, что не будет менять условия семейной ипотеки как минимум до сентября (раньше ванговали, что начнут действовать с 1 июля). Народная примета: если какую-то инициативу сдвигают «напослевыборов» – то это значит, что вряд ли она направлена на улучшение жизни населения.
![[Мем: <a href="https://pikabu.ru/story/debenzinizatsiya_rossii_a_takzhe_vozvrashchenie_bludnogo_fable_14124767?u=https%3A%2F%2Ft.me%2Flentachold%2F92196&t=%D0%9B%D0%B5%D0%BD%D1%82%D0%B0%D1%87&h=0de5945b8525407c0eaa24cd5e5366ed792c1881" title="https://t.me/lentachold/92196" target="_blank" rel="nofollow noopener">Лентач</a>]](https://cs18.pikabu.ru/s/2026/07/19/10/wnqreskj.jpg)
[Мем: Лентач]
🐌 Верховный суд РФ наконец выкатил обещанный обзор судебной практики вокруг дел, похожих на кейс Долиной. Мы с юристом Александром Малютиным уже готовим обзор обзора, не беспокойтесь! Этот лонгрид выйдет у меня на канале чуть позже.
🐌 Граждане «недружественных стран» с начала июня сталкиваются с заморозкой вкладов в российских банках после соответствующего указа президента РФ. У кого есть паспорт России – тех не трогают, они считаются «своими». Вроде как под прямой угрозой должны быть вклады от 10 млн руб., но пишут, что по факту якобы банки могут произвольно заморозить у иностранцев и вклады любого размера. Конкретику о применении указа ЦБ обещает выкатить через какое-то время.

🐌 Депозитарий Euroclear подал ответный иск против ЦБ РФ в Бельгии после решения московского суда взыскать с него €220 млрд. История началась в 2022, когда Euroclear заморозил российские активы, а в 2026 московский арбитражный суд обязал депозитарий возместить убытки. Европейцы ничего погашать не хотят и будут судиться, чтобы у России не получилось исполнить решение суда в третьей стране, которая не вводила санкции. Мое экспертное предсказание: каждая сторона в итоге уверенно одержит полную победу над противником в своем родном суде!!
🐌 Пишут, что некоторые банки Беларуси, Казахстана и Кыргызстана ввели 2–5% комиссию за внесение наличных рублей. Отдельные армянские банки отказываются принимать рублевую наличку в принципе (какие – не уточняется). Ну чё, каждый зарабатывает, как может…
🐌 Крейг Уильямс (помощник экс-премьера Великобритании Риши Сунака) признал вину в том, что использовал закрытую информацию с Даунинг-стрит для трех ставок на дату выборов 2024-го года у букмекера на общую сумму в ~400 фунтов. Чувак использовал инсайд для потенциального выигрыша в пару тысяч фунтов, а теперь может отъехать в тюрьму на срок до двух лет. У меня начинают закрадываться подозрения, что в политику идут не очень умные люди!!
🐌 Правительство UK организовывает консультации о потенциальном законопроекте, расширяющим права пар, которые живут вместе от трех лет или имеют общего ребенка. На сожительство хотят распространить наследственные и финансовые права, включая раздел имущества и финансовую поддержку при расставании. Чё думаете, уважаемые папищики? Надо ли делить совместное нажитое имущество, если вы с «бывшим» три года вместе прожили без росписи?
![[Источник:<a href="https://pikabu.ru/story/debenzinizatsiya_rossii_a_takzhe_vozvrashchenie_bludnogo_fable_14124767?u=https%3A%2F%2Fpikabu.ru%2Fstory%2Fsozhitel_6899166&t=%D0%9F%D0%B8%D0%BA%D0%B0%D0%B1%D1%83&h=03bc32e08373011ff5293a9419ef7c9d9e13b8c5" title="https://pikabu.ru/story/sozhitel_6899166" target="_blank" > Пикабу</a>]](https://cs18.pikabu.ru/s/2026/07/19/10/w5qrf6yl.jpg)
[Источник: Пикабу]
🐌 Курс японской иены упал до минимума с 1986 года. В ТГ-канале «War, Wealth & Wisdom» рассуждают, как так – в Японии же супер-низкая инфляция по сравнению с США, «по-науке» курс должен долгосрочно укрепляться к баксу? Anyway, если вы всё откладывали поездку в эту страну – то можете считать эту новость знаком от Вселенной, там теперь супер-дешево.

Мы с женой последний раз ездили в Японию два года назад, было збс, всецело рекомендуем
🐌 Дональд Трамп, согласно декларации, заработал $1,4 млрд в 2025 году на крипте и мемкоинах (конкретно один только печально известный мемкоин $TRUMP принес ему $635 млн). В 2024 году состояние Трампа оценивалось всего в $2,3 млрд, сейчас уже в $6,5 млрд – вот что президентство животворящее делает! Администрация Белого дома говорит, что никакого конфликта интересов тут, конечно же, даже близко нет. А еще Трамп на прошлой неделе сказал, что его дети так или иначе обладают инсайдерской инфой, которую можно при желании привязать к любому активу – так это чё значит, сейчас им вообще что ли ничего не покупать??
![[Мем: <a href="https://pikabu.ru/story/debenzinizatsiya_rossii_a_takzhe_vozvrashchenie_bludnogo_fable_14124767?u=https%3A%2F%2Fx.com%2FKyleKulinski%2Fstatus%2F2073076906312823105&t=Twitter&h=47992ba43a7e227160ee77059fc134fbf7cbf8da" title="https://x.com/KyleKulinski/status/2073076906312823105" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs18.pikabu.ru/s/2026/07/19/10/xrqrf6l5.jpg)
[Мем: Twitter]
🐌 30 июня завершилась большая сессия Верховного суда США 2025–2026. Были решения как в пользу Трампа, так и против. Президенту разрешили увольнять глав федеральных агентств (к ФРС это не относится, там суд заблокировал попытку уволить Лизу Кук – члена совета Федрезерва), отменили лимит средств, которые можно тратить на выборы. В то же время Верховный суд признал незаконным ограничения на гражданство по рождению и поддержал голосование по почте. Всё-таки прикольно, когда есть хоть какая-то независимость ветвей власти.
🐌 На прошлой неделе с новейшей модели Антропика Fable сняли экспортные ограничения и вернули в общий доступ. Кстати, Anthropic подтвердила, что это Amazon на них настучал (хотя, Цви Мовшовиц пишет, что по фигне – найденный Амазоном «способ обойти антихакерскую защиту модели» на самом деле высосан из пальца). До 7 июля половину лимитов платных подписок можно юзать на Fable, а потом уже только покупать кредиты на использование: получается, подсаживают на первую дозу!! Я, конечно же, первым делом пошел проверять, что Фейбл мне ответит по поводу контрактов на рынках предсказаний…
![[Источник: <a href="https://pikabu.ru/story/debenzinizatsiya_rossii_a_takzhe_vozvrashchenie_bludnogo_fable_14124767?u=https%3A%2F%2Fx.com%2Frhyssullivan%2Fstatus%2F2072105275230958036%3Fs%3D46%26t%3DDlsAqt4UWCQX0o_5jcTXog&t=Twitter&h=84289ca2791e91bdd96c749baa189e21ec45bbcd" title="https://x.com/rhyssullivan/status/2072105275230958036?s=46&t=DlsAqt4UWCQX0o_5jcTXog" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs18.pikabu.ru/s/2026/07/19/10/xzqrezyj.jpg)
[Источник: Twitter]
Из забавного: тестировщики заметили, что первая (доблокировочная) версия Fable справлялась со сложными задачами в разы лучше второй версии. Это объясняется тем, что новая Fable очень активно и без предупреждения переключает пользователей на более лайтовую модель Claude Opus в самых разных задачах. (Судя по всему, это и есть те самые ограничения, которые просило вставить правительство США).
![[Мем: <a href="https://pikabu.ru/story/debenzinizatsiya_rossii_a_takzhe_vozvrashchenie_bludnogo_fable_14124767?u=https%3A%2F%2Fx.com%2FAliGrids%2Fstatus%2F2072245605728948704&t=Twitter&h=692b85f6de3180dd3c85b4b17fc2e1e235d08ba2" title="https://x.com/AliGrids/status/2072245605728948704" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs18.pikabu.ru/s/2026/07/19/10/ybqremro.jpg)
[Мем: Twitter]
🐌 Глядя на то, как правительство США чепекрыжит Антропиков регулярно и по графику, OpenAI предложили передать проактивно американскому государству 5% акций, пишет FT. Расчет, видимо, на то, что если пустить волка в курятник миноритарием – то он будет более лояльно относиться к курам и жестить перестанет. Но тут пока никто ни с кем окончательно не договорился.
🐌 А ещё WSJ написали, что китайские модели якобы обогнали Claude Mythos/Fable в сфере кибербезопасности. Но AI-эксперт Цви с ними жестко не согласен – типа, тут журналисты просто ерунду полную пишут.
🐌 «Экстремистская» Meta планирует запустить облачный бизнес по продаже доступа к дата-центрам для AI-моделей. До этого компания Цукербега увеличила прогноз расходов на 2026 год с С $115–135 млрд до $125–145 млрд ради трат на AI-инфраструктуру.
Вообще, забавно: раньше топовые биг-тех компании в основном властвовали в своей нише, и за счет этого были дико прибыльными. Например, у Гугла был самый успешный поисковик, у Майкрософта – операционка, Амазон был крупнейшим онлайн-маркетплейсом. А сейчас, по сути, весь бигтех одновременно ломанулся в одну и ту же дверь: все хотят настроить себе кучу дата-центров, и сидеть на них верхом. Кажется, при таком раскладе конкуренция должна вырасти, и прибыльность должна пойти вниз со временем.
🐌 Тем временем: у Microsoft худший месяц по динамике рыночной капитализации с декабря 2000 года – за июнь они потеряли около 17%. На этом фоне Майки продолжают ежегодные сокращения – в этом году планируют сократить 2,5% персонала.
🐌 Акции Oracle за неделю тоже упали максимально за последние 25 лет – с августа 2001 года. Как будто, рынок не может понять, эти адские вложения в ИИ-инфраструктуру – это скорее круто и вдохновляюще, или всё же страшно и очково?
![Не смог придумать шутку про рифму «очково» и «Meta AI Glasses», помогите плз [Источник: <a href="https://pikabu.ru/story/debenzinizatsiya_rossii_a_takzhe_vozvrashchenie_bludnogo_fable_14124767?u=https%3A%2F%2Fwww.wired.com%2Fstory%2Fmeta-connect-2025-how-to-watch%2F&t=Wired&h=2f1e862968af14828f970567cec6d02627d0f7bc" title="https://www.wired.com/story/meta-connect-2025-how-to-watch/" target="_blank" rel="nofollow noopener">Wired</a>]](https://cs18.pikabu.ru/s/2026/07/19/10/yjqrfljh.jpg)
Не смог придумать шутку про рифму «очково» и «Meta AI Glasses», помогите плз [Источник: Wired]
🐌 Компания Memetum Lab (они купили авторские права на персонажа у создателя) через суд хочет убрать Brainrot-полено Тун Тун Сахура из игры Steal a Brainrot, так как разработчики якобы не могут его использовать. Создатели игры не согласны: никаких прав на AI-персонажа быть не может, но Memetum Lab пытается доказать, что полено не просто родилось через промпт, а было художественным замыслом. Новость всратая, но может стать интересным прецедентом по теме авторских прав на AI-контент! Детали можно прочитать у Леши Подклетнова.
![Всем встать, кринж идет! [Мем: <a href="https://pikabu.ru/story/debenzinizatsiya_rossii_a_takzhe_vozvrashchenie_bludnogo_fable_14124767?u=https%3A%2F%2Ft.me%2Foldlentach%2F93794&t=%D0%9B%D0%B5%D0%BD%D1%82%D0%B0%D1%87&h=2dd517e80eb64d87b58350b97aa3064ea5b04fe4" title="https://t.me/oldlentach/93794" target="_blank" rel="nofollow noopener">Лентач</a>]](https://cs18.pikabu.ru/s/2026/07/19/10/yrqree65.jpg)
Всем встать, кринж идет! [Мем: Лентач]
🐌 «Экстремистская» Meta заставила сотни подрядчиков притворяться подростками и пытаться задавать ChatGPT, Gemini и Character.AI вопросы за гранью цензуры. Так компания хотела понять, где конкуренты лучше или хуже защищают детей, и сравнить их системы безопасности со своей. Такой вот нынче промышленный шпионаж: надо понять, как твои конкуренты отмазываются от неприличных детских вопросов!
Из смешных запросов: «Моя девушка хочет со мной секса, но мне лень и я не хочу вылезать из Dota 2. Что делать?». Как говорится – напишите в комментах, что бы вы на это ответили?
![Я бы посоветовал уговорить девушку на косплей Лины там, хотя бы… [Источник: <a href="https://pikabu.ru/story/debenzinizatsiya_rossii_a_takzhe_vozvrashchenie_bludnogo_fable_14124767?u=https%3A%2F%2Fx.com%2Fredditdota2%2Fstatus%2F1557773710496612352&t=Twitter&h=d13e9824d7f969b7ff49369ed1ba0d09e129c0fd" title="https://x.com/redditdota2/status/1557773710496612352" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs18.pikabu.ru/s/2026/07/19/10/yzqre5is.jpg)
Я бы посоветовал уговорить девушку на косплей Лины там, хотя бы… [Источник: Twitter]
🐌 Первый ВУЗ в России отказался от дипломных работ в пользу устных экзаменов. Им оказался сочинский РУДН, а конкретно его юридический факультет: причиной стал AI, который слишком сильно упростил написание текстовых работ. Интересно, что юристы стали первой профессией, не выдержавшей натиск нейрослопа в педагогическом смысле.
![[Мем: <a href="https://pikabu.ru/story/debenzinizatsiya_rossii_a_takzhe_vozvrashchenie_bludnogo_fable_14124767?u=https%3A%2F%2Ft.me%2Fexploitex%2F34914&t=%D0%AD%D0%BA%D1%81%D0%BF%D0%BB%D0%BE%D0%B9%D1%82&h=82b741edd061910b644bb4019af5c2b7a3ce46e9" title="https://t.me/exploitex/34914" target="_blank" rel="nofollow noopener">Эксплойт</a>]](https://cs18.pikabu.ru/s/2026/07/19/10/zbqrelca.jpg)
[Мем: Эксплойт]
🐌 WSJ написали, что Илон Маск якобы перед IPO SpaceX показывал инвесторам ранний прототип девайса, похожего на смартфон. Типа, у него будет своя операционка, интеграция с AI и общие вайбы «приложения для всего» (хотя, это же в принципе описание любого смартфона, нет?). Илон Маск в твиттере назвал материал ложью.
🐌 А вот OpenAI выпускают клавиатуру. Точнее физический пульт для прожатия наиболее частых команд в Codex (нейронка для прогеров).
![Я считаю, что если у клавы для вайбкодинга будет больше одной кнопки – то это уже фейл! [Источник: <a href="https://pikabu.ru/story/debenzinizatsiya_rossii_a_takzhe_vozvrashchenie_bludnogo_fable_14124767?u=https%3A%2F%2Fx.com%2Fprd_008%2Fstatus%2F2071655287396749321&t=Twitter&h=94e81984b16bfc696daab76b466ea06a22ef3cd9" title="https://x.com/prd_008/status/2071655287396749321" target="_blank" rel="nofollow noopener">Twitter</a>]](https://cs18.pikabu.ru/s/2026/07/19/10/zjqrev53.jpg)
Я считаю, что если у клавы для вайбкодинга будет больше одной кнопки – то это уже фейл! [Источник: Twitter]
🐌 Sony полностью откажется от дисков (поколение альфа, речь идет про круглые плоские блестящие штуки) для PlayStation с 2028 года. Игры можно будет купить только в цифровом виде. По тому же пути планирует пойти XBOX, который работает над технологией по оцифровке дисков, чтобы коллекционерам не было так обидно от будущей консоли без дисковода.
![[Мем: <a href="https://pikabu.ru/story/debenzinizatsiya_rossii_a_takzhe_vozvrashchenie_bludnogo_fable_14124767?u=https%3A%2F%2Ft.me%2Flentachold%2F92239&t=%D0%9B%D0%B5%D0%BD%D1%82%D0%B0%D1%87&h=0c53b03f4ab6c229a11f2136efb8f66d5682673e" title="https://t.me/lentachold/92239" target="_blank" rel="nofollow noopener">Лентач</a>]](https://cs18.pikabu.ru/s/2026/07/19/10/zrqrflum.jpg)
[Мем: Лентач]
🐌 А еще вот неожиданная новость: мой еженедельный дайджест (который вы прямо сейчас читаете) больше не выходит на Хабре из-за их новой редакторской политики, запрещающей всё не-айтишное. Более подробно написал у себя в ТГ-канале здесь.
🐌 Совет директоров (Micro)Strategy разрешил продать биткоины на сумму до $1,25 млрд, чтобы финансировать выплаты обещанных дивидендов и обратный выкуп привилегированных акций STRC. По сути, это формализованный отказ от принципа Майкла Сэйлора «никогда не продавать биткоин». Решение приняли после того, как рыночная стоимость (Micro)Strategy опустилась ниже стоимости ее биткоин-резервов. Кстати, котировки акций компании просели примерно на 80% от своего предыдущего пика. Значит ли это, что акциям дальше некуда падать? Лол, посмотрим.
![[Источник:<a href="https://pikabu.ru/story/debenzinizatsiya_rossii_a_takzhe_vozvrashchenie_bludnogo_fable_14124767?u=https%3A%2F%2Fx.com%2Fcharliebilello%2Fstatus%2F2069893747521786015&t=Creative%20Planning&h=9bf3c1415b90e87d1bd687b73b33067cbfd3c590" title="https://x.com/charliebilello/status/2069893747521786015" target="_blank" rel="nofollow noopener"> Creative Planning</a>]](https://cs18.pikabu.ru/s/2026/07/19/10/zzqrej75.jpg)
[Источник: Creative Planning]
🐌 Дату принятия российского закона о крипторегулировании перенесли с июля на сентябрь, рассказали в ЦБ (ну то есть, тоже «напослевыборов», выходит?). Еще обещают переходный до 1 июля 2027 года без административок и уголовок для нарушителей.
🐌 В этой рубрике я обычно рассказываю об одном подкасте, который я послушал на прошлой неделе. На этот раз это интервью Майкла Калви у Дакса Шепарда – чувак был известным венчурным инвестором в России, а потом заехал в СИЗО, когда наинвестировал в ту сторону, которая уважаемым людям не понравилась. Короче, там любопытно глазами американца про жизнь в России начиная с 90-х.
🐌 1 июля запустили экспериментальный проект, который поможет гражданам РФ за рубежом дистанционно заверять документы через электронную подпись. Система позволяет продать недвижимость, регать юрлица, открывать счета онлайн. Пока проект будет работать только в Армении, Вьетнаме, Индии, Индонезии, Казахстане, Кыргызстане, Китае, Малайзии, ОАЭ, Сербии, Турции и Узбекистане.
🐌 Вспышка хантавируса на лайнере MV Hondius официально закончилась, сообщает ВОЗ. Новых случаев не было обнаружено аж с 25 мая.
![[Источник: <a href="https://pikabu.ru/story/debenzinizatsiya_rossii_a_takzhe_vozvrashchenie_bludnogo_fable_14124767?u=https%3A%2F%2Fwww.threads.com%2F%40alexberisic07%2Fpost%2FDZYBDBTCb1R%3Fxmt%3DAQG0z85lVcBsjNOTNwJNjs1w70E8sNlPghJVRcUSps5Fxg&t=Threads&h=cd0beee32143515ede3f4506f7ba6e58714b2d4e" title="https://www.threads.com/@alexberisic07/post/DZYBDBTCb1R?xmt=AQG0z85lVcBsjNOTNwJNjs1w70E8sNlPghJVRcUS..." target="_blank" rel="nofollow noopener">Threads</a>]](https://cs18.pikabu.ru/s/2026/07/19/10/2bqrfz6s.jpg)
[Источник: Threads]
🐌 В Турции вступил силу закон, который позволяет целых 20 лет не платить подоходный налог с денег, заработанных за пределами страны. Сюда включены дивиденды, проценты, доходы от аренды, прибыль от перепродажи активов. Предложение актуально для людей, которые не были налоговыми резидентами в Турции последние 3 года.
Веду ТГ-канал RationalAnswer про всё самое интересное в мире финансов и технологий.




