Не обязательно устанавливать на свой комп. Более того, это не гарантирует работу. лучше дистанционные методы
WhisperDesktop, Google Colab и три часа терпения при транскрипции видео
Зачем вообще понадобился транскрипт
Мы провели рабочую встречу по нашей симуляционной модели здоровья работников — запись осталась на YouTube. Нужно было извлечь из неё планы и идеи, которые обсуждались, и оформить в документ. Задача простая: получить текст из часового видео.
Первая попытка — попросить YouTube сделать это за нас. Нажимаем три точки под видео, ищем «Открыть транскрипцию»… Почему то картинки не вставляются,воспользуюсь онлайн сервисом.
YouTube, три точки под видео — пункта «Открыть транскрипцию» нет. Видео загружено несколько часов назад, субтитры ещё не сгенерированы.
Пусто. Видео только что загружено, YouTube ещё не успел обработать аудио. Ждать не вариант.
Скриншот до текста.
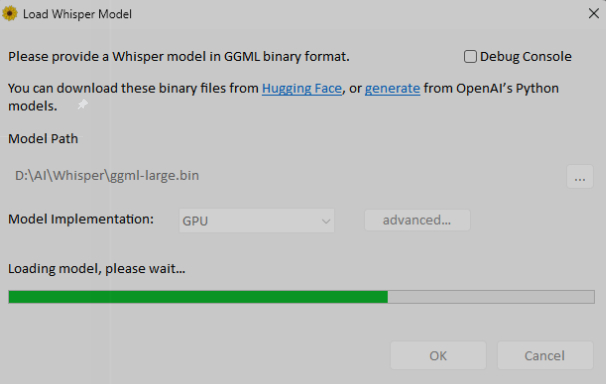
Попытка первая: WhisperDesktop
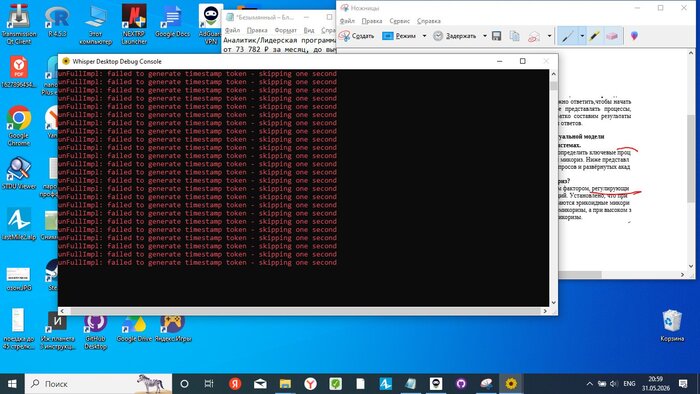
Скачали WhisperDesktop (GUI для whisper.cpp) и модель ggml-medium.bin (~1.5 ГБ). Запустили. Первые секунды — тишина. Потом консоль начала выдавать что-то очень неприятное:
🖼 Скриншот 2 после текста— WhisperDesktop с ошибкой
WhisperDesktop Debug Console: бесконечный поток «unFullImpl: failed to generate timestamp token - skipping one second». Программа не падает, но и не работает.
Строчки сыпятся одна за другой, транскрипт пустой. Это известная проблема с GPU через DirectCompute — программа пропускает каждую секунду аудио. Лечится отключением GPU в настройках, но тогда 55-минутное видео будет обрабатываться несколько часов. Ищем быстрее.
Попытка вторая: Google Colab
Google Colab даёт бесплатный GPU в браузере без установки чего-либо. Создали новый notebook, три ячейки.
Ячейка 1 — установка зависимостей:
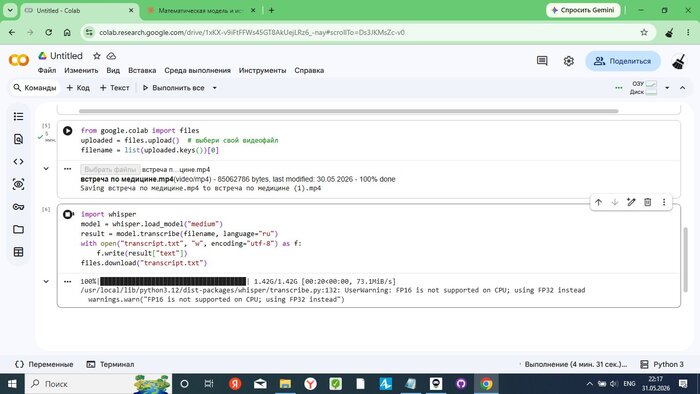
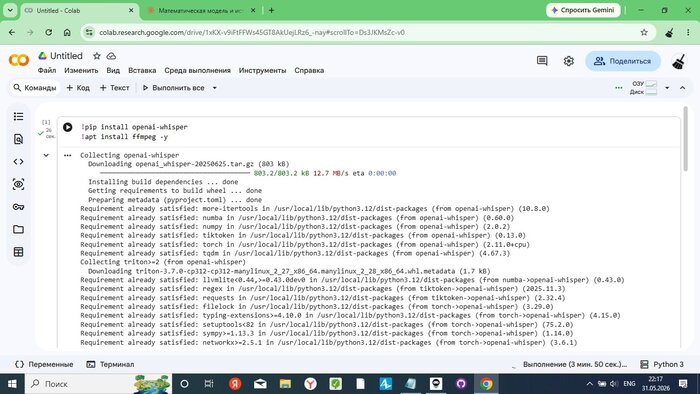
!pip install openai-whisper
!apt install ffmpeg -y
🖼 Скриншот 3 и тут и после текста— Colab установка
Colab устанавливает openai-whisper и зависимости. Процесс занял ~3 минуты.
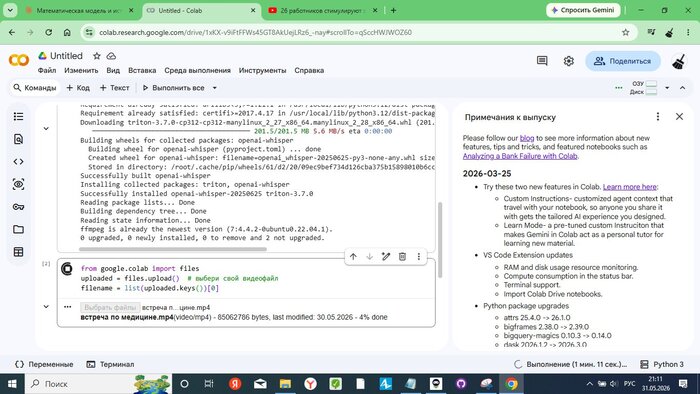
Ячейка 2 — загрузка файла прямо с компьютера:
from google.colab import files
uploaded = files.upload()
filename = list(uploaded.keys())[0]
🖼 Скриншот 4 — загрузка файла 100%
Файл «встреча по медицине.mp4» (85 МБ) загружен на сервер Colab — 100% done. Загрузка ~5 минут.
Ячейка 3 — транскрипция:
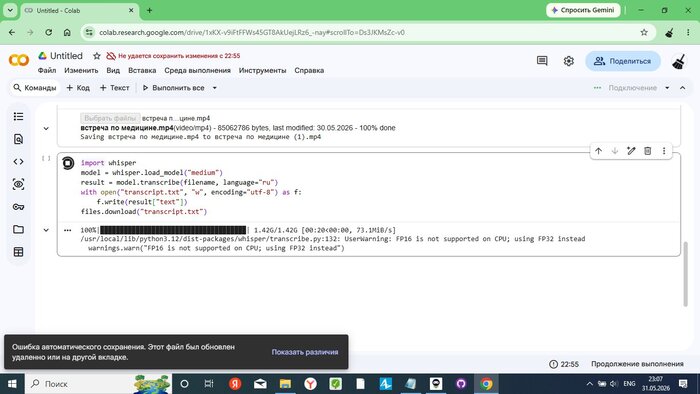
import whisper
model = whisper.load_model("medium")
result = model.transcribe(filename, language="ru")
with open("transcript.txt", "w", encoding="utf-8") as f:
Colab сразу предупредил: «FP16 is not supported on CPU; using FP32 instead» — GPU не выделился, работаем на процессоре. Примерно вдвое медленнее, но всё равно быстрее локальной машины с проблемным GPU.
🖼 Скриншот 5 — транскрипция стартует
Whisper загрузил модель medium (1.42 ГБ) и начал транскрипцию. Таймер: 4 минуты 31 секунда — только начало.
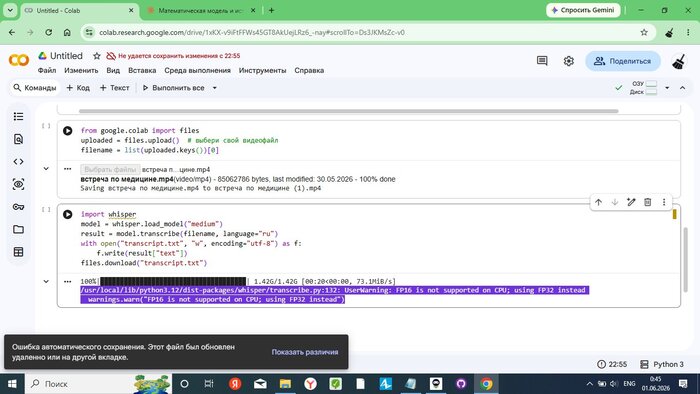
Оставляем вкладку открытой. Через 38 минут заглядываем — всё ещё работает:
🖼 Скриншот 6 — 38 минут ожидания
Всё ещё работает. Таймер: 22:55. Colab параллельно выдаёт диалог про несохранённые изменения — нажимаем «Отмена», транскрипция продолжается.
Ещё через ~20 минут — готово:
🖼 Скриншот 7 — готово, галочка ✓
В правом верхнем углу — галочка ✓: ячейка выполнена. Суммарное время ~1 час. Браузер автоматически скачал transcript.txt.
Качество результата
Модель medium на русском языке работает хорошо. Типичные проблемы:
Имена собственные — расшифровывает фонетически: «AnyLogic» → «Энилоджик»
Технические аббревиатуры — угадывает через раз
Слова-паразиты и оговорки — транскрибирует честно, всё подряд
Перекрёстный разговор — склеивает в кашу
Для извлечения смысла и структурирования идей — вполне достаточно.
Что использовать когда
YouTube субтитры — если можете подождать несколько часов/дней
WhisperDesktop локально — если GPU без проблем с DirectCompute
Google Colab — быстро, без установки, ~1 час на CPU или ~15 мин на GPU
openai-whisper локально через pip — если есть RTX 30xx+: whisper video.mp4 --language Russian --model medium
Транскрипт нам нужен был для анализа рабочей встречи по математической модели здоровья сотрудников. О самой модели — в других постах.1
Один час встречи. Три часа «а что он там сказал на 42-й минуте?»
Есть особый вид офисного ада: ты записал встречу, потому что «потом всё спокойно разберу», а потом сидишь вечером в наушниках и ловишь фразу между «коллеги, меня слышно?» и «давайте вернёмся к этому позже».
Через сорок минут ты уже ненавидишь всех: микрофон ноутбука, эхо переговорки, человека с клавиатурой на фоне и себя за то, что не записал руками три ключевых решения.
Я полез смотреть сервисы транскрибации с простой мыслью: ну ладно, сейчас нейросети же всё умеют. Загрузил файл - получил текст - пошёл жить.
А оказалось, что в 2026 году транскрибация - это уже не «перевести голос в буквы». Это целый класс инструментов: одни делают протокол встречи, другие превращают подкаст в монтажный сценарий, третьи дают API для продукта, четвёртые подходят только если рядом сидит живой редактор.
Ниже - топ-10 платформ и подходов, которые имеет смысл смотреть, если у вас есть созвоны, интервью, лекции, подкасты, звонки продаж или просто папка «аудио потом разберу», которая уже угрожает вашему диску.
Как сравнивал
Смотрел не на красивую фразу «powered by AI», а на то, что происходит после загрузки файла: русский язык, спикеры, тайм-коды, саммари, задачи, экспорт, безопасность и скорость получения результата.
Потому что голый транскрипт - это как мешок картошки. Формально еда есть, но ужин сам себя не приготовит.
Хороший сервис сегодня не просто пишет текст. Он превращает запись в рабочий артефакт.
ЧТО СЕЙЧАС УМЕЕТ НОРМАЛЬНЫЙ СЕРВИС
Транскрибация в 2026 году - это уже не диктовка в блокнот. Хороший сервис проходит несколько этапов: чистит звук, распознаёт речь, делит запись по спикерам, расставляет пунктуацию, строит саммари и даёт искать по смыслу.
На практике это выглядит так:
Загрузили часовую встречу.
Через несколько минут получили текст с тайм-кодами.
Переименовали «Спикер 1» в «Олег», «Спикер 2» в «Марина».
Открыли краткое саммари: решения, спорные места, задачи.
Спросили в чате по записи: «что решили по срокам?»
Выгрузили документ или субтитры.
И вот здесь начинается главное различие между сервисами. Одни всё ещё продают «текст из аудио». Другие продают сэкономленную голову после встречи.
Топ-10 сервисов транскрибации
1. Cosmo Scribe - когда нужна не расшифровка, а готовый результат встречи
Если коротко: это вариант для тех, кто работает на русском, часто пишет встречи/звонки/интервью и хочет получить не просто текст, а понятную структуру: кто что сказал, какие решения приняли, какие задачи появились и где это было в записи.
Главная сильная сторона - сервис явно сделан вокруг сценария «после встречи надо что-то делать». Не просто сохранить расшифровку в архив, а вытащить из неё пользу.
Что умеет:
транскрибация русского и английского;
автоопределение языка;
разделение по спикерам и переименование участников;
тайм-коды;
персональный словарь для фамилий, терминов и внутреннего жаргона;
импорт по ссылке: VK Видео, RuTube, Яндекс.Диск и прямые ссылки на медиа;
шумоподавление перед распознаванием;
AI-саммари в разных форматах: встреча, интервью, лекция, подкаст, продажа, голосовая заметка, брейншторм, хайлайты;
чат по записи: можно спросить «что решили по дедлайну?» и получить ответ с привязкой к месту;
экспорт текста и субтитров;
интеграция с Битрикс24 на старших тарифах.
Почему это цепляет: У большинства сервисов ощущение такое: «мы сделали текст, дальше сам». Здесь логика другая: «мы сделали так, чтобы ты не возвращался к этой записи без необходимости».
Для кого:
руководители и project/product-менеджеры;
продажи;
HR;
журналисты;
преподаватели;
команды, где встречи превращаются в задачи.
Минусы:
если нужен только API без интерфейса - есть более инженерные решения;
если основная работа на английском и всё живёт в Zoom/Google Meet, зарубежные meeting-assistant сервисы могут быть привычнее;
плохой звук всё равно остаётся плохим звуком: нейросеть не телепат.
Вердикт: Если вы в России и вам нужен сервис «загрузил запись - получил рабочий документ», Cosmo Scribe выглядит одним из самых практичных вариантов. Особенно для встреч, продаж и интервью.
2. Яндекс SpeechKit - мощный движок, если у вас есть разработчик
Это не совсем «сервис для человека». Это скорее мотор под капотом: API для распознавания речи, который можно встроить в свой продукт, CRM, колл-центр, внутреннюю систему контроля качества или личный инструмент.
Сильные стороны:
хорошо работает с русским;
гибкий API;
можно строить собственную логику вокруг результата;
подходит для больших объёмов и интеграций.
Слабые стороны:
обычному пользователю без разработки будет неудобно;
саммари, редактор, красивые отчёты и продуктовую обвязку нужно делать отдельно;
стоимость и архитектуру надо считать заранее.
Для кого: Для команд, которые не хотят «готовый сервис», а хотят встроить распознавание внутрь своего продукта.
Вердикт: Отличный двигатель. Но двигатель - это ещё не автомобиль.
3. Sber SaluteSpeech / корпоративные речевые платформы - когда важен контур
Есть ситуации, где вопрос «а красиво ли выглядит интерфейс?» вообще вторичен. Банки, госсектор, крупные корпорации, службы поддержки, внутренние совещания с чувствительными данными - там сначала спрашивают про безопасность, контур, договоры и интеграцию во внутреннюю инфраструктуру.
Сильные стороны:
ориентация на корпоративный рынок;
российская инфраструктура;
сценарии для больших компаний;
возможность строить процессы вокруг речевой аналитики.
Слабые стороны:
не всегда удобно для малого бизнеса и одиночного пользователя;
порог входа выше;
продуктовая «магия» для обычного автора или менеджера может быть слабее, чем у SaaS-сервисов.
Для кого: Для компаний, где транскрибация - часть большого корпоративного процесса, а не «мне надо расшифровать интервью».
Вердикт: Не самый лёгкий вариант, но часто самый правильный для тяжёлого корпоративного мира.
Онлайн-планёрка на несколько человек - настоящий экзамен для любого транскрибатора.
4. Google Cloud Speech-to-Text - глобальный API для мультиязычных продуктов
Google силён там, где нужны языки, масштаб и инфраструктура. Если проект международный, записи разноязычные, а команда умеет работать с облачными API, это один из очевидных вариантов.
Сильные стороны:
много языков;
хорошая инфраструктура;
подходит для встраивания в продукты;
гибкие настройки распознавания.
Слабые стороны:
это опять же API, а не готовый «офисный помощник»;
для российских компаний могут быть вопросы по оплате, доступу, хранению данных и юридическому контуру;
на русскоязычных рабочих встречах специализированные российские решения иногда практичнее.
Для кого: Для международных продуктов, разработчиков и команд, где русский - только один из многих языков.
Вердикт: Мощно, масштабно, но не всегда удобно для бытовой задачи «разобрать созвон отдела продаж».
5. Otter ai - знаменитый помощник для англоязычных встреч
Otter давно стал почти синонимом AI-заметок для встреч. Он хорошо ложится на англоязычную рабочую культуру: созвоны, заметки, краткие summaries, командная работа.
Сильные стороны:
удобный интерфейс;
хорош для английских встреч;
real-time заметки;
командные сценарии;
привычная логика meeting assistant.
Слабые стороны:
русский - не его главная сцена;
вопросы хранения данных и зарубежной инфраструктуры;
оплата и доступ могут быть неудобны для пользователей из РФ.
Для кого: Для команд, которые работают на английском и хотят, чтобы встреча сама превращалась в заметки.
Вердикт: Для английского - сильный игрок. Для русских созвонов - не всегда тот самый молоток.
6. Fireflies ai - бот, который приходит на встречу вместо секретаря
Fireflies интересен не столько транскрибацией, сколько способом встраивания в рабочий день. Он подключается к встречам, пишет разговор, делает заметки, отправляет результаты в рабочие инструменты.
Сильные стороны:
автоматическое подключение к встречам;
интеграции с рабочими сервисами;
удобный сценарий для команд;
поиск по встречам.
Слабые стороны:
бот на встрече нравится не всем;
для русской речи качество может быть нестабильным;
вопросы приватности нужно проговаривать с участниками заранее.
Для кого: Для команд, где встречи идут потоком, а английский - основной язык коммуникации.
Вердикт: Почти «секретарь на автопилоте». Но автопилот лучше включать там, где все пассажиры об этом знают.
Чистый микрофон - половина результата. Вторая половина - сервис, который понимает, что делать с записью дальше.
7. Rev - когда нужна точность с человеком в цепочке
AI прекрасен, пока цена ошибки невысокая. Но есть записи, где «почти правильно» - это плохо: юридические материалы, медицина, важные интервью, публичные субтитры, документы для спора.
Rev известен гибридным подходом: автоматическая транскрибация плюс возможность привлечь живого редактора.
Сильные стороны:
высокая точность при ручной проверке;
подходит для ответственных материалов;
сильные сценарии с субтитрами и медиа.
Слабые стороны:
дороже автоматических сервисов;
ручная обработка занимает время;
для обычных рабочих встреч может быть избыточно.
Для кого: Для юристов, медиа, документалистов, исследователей и всех, кому нужен не черновик, а финальный текст.
Вердикт: Если ошибка стоит дорого, человек в цепочке всё ещё нужен.
8. Descript - транскрибация для тех, кто монтирует голосом и текстом
Descript - это уже не «расшифровать аудио». Это монтажная среда, где текст становится интерфейсом для работы с видео и звуком.
Удалил слово в тексте - оно пропало из аудио/видео. Убрал паузы - таймлайн стал плотнее. Для подкастеров и видеоблогеров это выглядит как чит-код.
Сильные стороны:
монтаж через текст;
удобен для подкастов и видео;
работа с паузами, оговорками и фрагментами;
сильный UX для авторов контента.
Слабые стороны:
не лучший выбор для протоколов встреч;
русский не всегда основной приоритет;
если вам нужны задачи в CRM, это не тот класс инструмента.
Для кого: Для подкастеров, видеоблогеров, редакторов, продюсеров и всех, кто после расшифровки ещё монтирует.
Вердикт: Если транскрипт для вас - это монтажный пульт, Descript надо смотреть обязательно.
9. Speechpad / простые русскоязычные веб-диктовщики - когда надо быстро и без комбайна
Не всем нужен AI-чат, CRM, аналитика встреч и красивые карточки. Иногда задача простая: надиктовать текст, расшифровать короткую запись, получить черновик и пойти дальше.
Такие сервисы берут простотой.
Сильные стороны:
быстро разобраться;
часто дешевле сложных платформ;
подходят для коротких задач;
не перегружены функциями.
Слабые стороны:
плохо подходят для сложных встреч;
нет глубокого саммари;
меньше инструментов для командной работы;
со спикерами и шумом всё может быть грустнее.
Для кого: Для студентов, авторов, копирайтеров, людей с разовыми задачами.
Вердикт: Не всегда нужен космический корабль. Иногда нужна нормальная табуретка, и это нормально.
У некоторых сервисов текст уже стал не результатом, а способом управлять видео.
10. Transkriptor / Happy Scribe / Sonix - мультиязычные сервисы для субтитров и универсальных задач
Есть отдельная категория сервисов, которые хорошо закрывают широкий международный сценарий: загрузить аудио или видео, получить транскрипт, перевести, сделать субтитры, выгрузить результат.
Они часто не такие «заточенные» под российские встречи, но удобны для авторов, переводчиков, YouTube-роликов, курсов и материалов на разных языках.
Сильные стороны:
много языков;
субтитры;
перевод;
понятные интерфейсы;
удобно для контента.
Слабые стороны:
для русских рабочих встреч не всегда лучший результат;
мало локального контекста;
вопросы оплаты и хранения данных зависят от сервиса.
Для кого: Для авторов курсов, переводчиков, медиа и тех, кто работает с разными языками.
Вердикт: Хороший универсальный нож. Но если нужна хирургия под конкретный бизнес-процесс, лучше брать специализированный инструмент.
ЧТО ВЫБРАТЬ В ИТОГЕ
Если совсем коротко:
рабочие встречи на русском - Cosmo Scribe;
API и встраивание в продукт - Яндекс SpeechKit или Google Cloud Speech-to-Text;
юридически важные расшифровки - Rev с ручной проверкой;
подкасты и видео - Descript;
разовые простые задачи - Speechpad и похожие веб-диктовщики;
субтитры и мультиязычный контент - Transkriptor, Happy Scribe, Sonix.
ГЛАВНЫЙ ВЫВОД
Рынок транскрибации за последние пару лет сделал тихий, но очень важный поворот.
Раньше сервисы продавали текст.
Теперь сильные сервисы продают отсутствие хаоса после записи.
Не «вот вам 40 страниц, разбирайтесь». А «вот решения, вот задачи, вот кто говорил, вот тайм-код, вот кусок для цитаты, вот экспорт, вот ответ на вопрос».
И это меняет отношение к записям. Они перестают быть кладбищем созвонов, куда всё складывают «на всякий случай». Они становятся базой знаний, к которой можно вернуться и быстро достать смысл.
Пожалуй, лучший комплимент сервису транскрибации сегодня звучит не «он точно распознал все слова». Лучший комплимент звучит так: «Я больше не открывал эту запись целиком».
Идеальный сценарий: запись осталась, смысл извлечён, вечер свободен.
P.S. Если у вас есть любимый сервис для расшифровки, который реально спасал рабочие вечера, напишите в комментариях. Особенно интересно, что сейчас лучше всего справляется с русскими созвонами, где три человека перебивают друг друга, один говорит из машины, а у четвёртого микрофон из 2009 года.
После того, как у годвийского кваягодвиана появились рукописные буквы, я задумался над созданием международных транскрипций, поэтому вот вам обновленный годвийский алфавит с новыми транскрипциями МФА, а также старые транскрипции:
ⵅ — ['ал] / [al]
ⵙ — [ох] / [ox]
ⵡ — [ма] / [ma]
ⵉ — [в] / [v]
ⵛ — [чь] / [tɕ]
ⵍ — [и] / [i]
ⴰ — [ьп] / [ʲ͜p]
ⵕ — [ум] / [um]
⵰ — [ом] / [om]
ⵎ — [ыхт] / [ɨχt]
ⵂ — [лаг] / [lag]
ⵊ — [йм] / [jm]
ⴳ — [э] / [ɛ]
ⵥ — [кын] / [kɨn]
ⵜ — [жыщ] / [ʐɨɕ]
ⵐ — [жащ] / [ʐaɕ]
ⵗ — [ах] / [ax]
ⵖ — [йей] / [jej]
ⴾ — [ай] / [aj]
ⴼ — [оух] / [oʊ̯x] (вот тут символ не обозначается почему-то, поэтому просто [oux])
Я люблю смотреть исторические ролики на ютубе. Ну как смотреть? Мне больше нравится их читать. Для этого я извлекаю транскрипты и потом преобразовываю их в статью. Так мне просто лучше воспринимать информацию.
Как многие из вас знают, сырой транскрипт ютуба – это довольно-таки нечитабельная белиберда, особенно если текст довольно сложный. Вот тут нам на помощь и приходят большие языковые модели.
Я решил провести тест 10 топовых моделей, которые доступны бесплатно или практически бесплатно каждому пользователю, который умеет играть в КВН.
За основу был взят вот этот вот ролик продолжительностью полчаса с копейками
Качество получившейся из транскрипта статьи проверять я доверил модели Gemini 3.1 Pro. Попросив оценить каждый из транскриптов по 100-бальной шкале.
Вот ее выводы.
Кто лучше следовал исходному тексту:
Лидерство здесь делят GPT-5.4-ext-thinking, Qwen-3.6-max-preview и Claude-sonnet-4.6. Все три модели бережно перенесли 100% смысловой нагрузки исходника, не потеряв ни одной исторической детали, но при этом сделали текст читабельным.
Меньше всего искажений:
GPT-5.4-ext-thinking, Qwen-3.6-max-preview и Gemini-3.1-flash-lite-preview. Эти модели лучше всех справились с «чисткой» транскрипта и не придумали от себя ни одного лишнего факта, корректно распознав все имена собственные.
(Аутсайдеры в лице GigaChat, Minimax, GLM и Mistral остаются на своих местах с теми же критическими ошибками, галлюцинациями и английскими словами, пробивающимися сквозь перевод).
Итоговый рейтинг моделей (Топ-10)
GPT-5.4-ext-thinking (95/100) — Эталонная работа. Эта модель справилась с задачей блестяще. Она продемонстрировала выдающуюся способность восстанавливать искаженные исторические термины из аудио-транскрипта: правильно распознала Хузестанскую равнину («Kuzan plane»), царя Энмебарагеси («En Meisesi»), богиню Пиникир («Pineir») и династию Кидинуидов («Kadinuid»). Текст разбит на логичные абзацы с удачными подзаголовками, стиль выдержан в духе качественного научно-популярного лонгрида (без излишней сухости, но и без панибратства). Модель также четко выполнила инструкцию по удалению рекламного блока, оставив аккуратное и профессиональное примечание редактора в конце. Снижение на 5 баллов — исключительно за мелкие стилистические шероховатости, которые неизбежны при машинном переводе.
Qwen-3.6-max-preview (94/100) — Выдающийся результат. Блестящая реконструкция исторических терминов и идеальное примечание редактора. Чуть уступает лидеру лишь из-за слишком массивных абзацев в середине текста. Она продемонстрировала глубокое понимание исторического контекста и блестяще реконструировала фактологию из поврежденного транскрипта: искаженное «En Meisesi» превратилось в правильного Эн-Мебарагеси, «Pineir» — в богиню Пиникир, «Kuzan plane» — в Хузестанскую равнину, а «Kadinuid» — в династию Кидинуидов.
Claude-sonnet-4.6 (92/100) — Безупречный литературный слог. Слегка уступает первым двум моделям из-за мелких неточностей, но сохранил всю хронологическую последовательность и смысловые акценты автора, выдав, пожалуй, самый «литературный» и гладкий текст из всех. Он не упустил ни одной важной детали, но при этом немного ошибся в дешифровке некоторых имен (например, оставил «Эн-Месиси» вместо Энмебарагеси).
DeepSeek-v3.2 (89/100) — Отличная эрудиция и фактологическая правка текста. Прекрасно следовал исходнику, применив мощный механизм поиска знаний: модель даже добавляла вопросительные знаки там, где транскрипт был критически поврежден (например, «Kindattu (Кутир-Наххунте?)»), чтобы исправить исторические несостыковки.
Gemini-3.1-flash-lite-preview (88/100) — Очень качественная адаптация с прекрасным аналитическим примечанием редактора. Текст читается естественно. Заслуживает отдельной похвалы за свое примечание редактора: она прямо указала, что исходный текст содержал ошибки транскрипции (например, «ununiform» вместо «cuneiform»), и объяснила свои правки. Это идеальное выполнение роли трезвого и объективного редактора.
Kimi-k2.6 (82/100) — Крепкий, ровный перевод без откровенных провалов, но с несколькими историческими неточностями в именах царей.
Mistral-chat (65/100) — Хороший литературный стиль перечеркивается критической фактологической галлюцинацией (замена города Аншана на Аван на протяжении всего текста).
GLM-5-turbo (40/100) — Слабо. Модель допустила критическую ошибку, оставив непереведенные английские слова прямо посреди русских предложений.
Minimax-m2.7 (30/100) — Очень слабо. Огромное количество английского и китайского текста и серьезные проблемы с логикой построения фраз.
GigaChat-thinking (10/100) — Худший результат. Полная неспособность работать с зашумленными данными транскрипта, что привело к генерации абсурдных несуществующих имен и терминов. Полный провал в восстановлении исторических терминов. Модель буквально транслитерировала фонетический мусор, породив несуществующие сущности: «Кунанская равнина», «Кутиккинувау», «Худжаллу», «Ханунту III». Текст читается как альтернативная история. 😁
Что меня удивило? Ну, например, то, что ChatGPT неожиданно оказался на первом месте. Потому что мне его работа с текстом всегда нравилась... не очень. Слишком много он всегда сокращает, упрощает и т.д.
Но, оказывается, в режиме расширенного мышления он не сокращает и очень четко следует инструкциям. Надо брать это на вооружение. А то я привык работать с инстант-версией.
Так же круто себя проявил новейший Qwen3.6-max и как ни странно DeepSeek 3.2 - От последнего я не ожидал, действительно его неплохо исправили в новых версиях. Это при том, что мы с вами ждем со дня на день четвертую версию.
10-е место комментировать не буду можете сами в комментариях отметить и поздравить! То-то я, когда читал, удивился таким странным именам царей и прочих правителей древности в его изложении. 😂
Вне рейтинга осталась Алиса Pro, которая вместо создания статьи сделала кратенькое саммари. Хотя промпт я всем моделям давал один и тот же...
Пользуюсь Memo AI сервис для транскрибации видео и аудио. Загружаешь файл или ссылку, получаешь текст с разбивкой по спикерам. Куча вариантов сделать конспект под любые задачи с выделением основных мыслей, мне очень нравится, интерфейс понятный, подписка очень выгодная, советую.
Друзья, всем привет! Я печатаю целыми днями - посты, статьи, ответы в чатах - и в какой-то момент запястья просто начинают болеть. Пробовал разные браузерные расширения для голосового ввода вроде Voice In, но это какое-то гиблое дело: то текст не вставляется куда надо, то расширение крашится, то работает только в браузере и всё, то лимит кончается. Короче, обплевался.
Начал искать альтернативу и нашел - Epicenter Whispering. Зажимаешь кнопку, говоришь в микрофон, отпускаешь - текст появляется там, где стоит курсор. В любой программе. Этот пост, кстати, тоже надиктован через неё. И самое главное - никому ни за что не нужно платить и может работать даже без интернета.
Что умеет Epicenter Whispering
Работает на уровне всей ОС. Не привязан к браузеру, вставляет текст в любое активное окно - хоть мессенджер, хоть редактор кода, хоть комментарии на Пикабу. Это прям главное отличие от всяких браузерных расширений.
Локальная работа без интернета. Встроенная поддержка моделей NVIDIA NeMo (Parakeet). Всё крутится на вашем компьютере, приватно и бесплатно. При желании можно подключить облачные API (Groq, OpenAI, ElevenLabs), но для большинства задач хватает локальной модели.
LLM-фильтр на лету. Уникальная киллер-фича! Можно прикрутить промпт, чтобы нейронка моментально переписывала сказанное. Наговариваете на эмоциях: «Е**чие пдорасы, вы меня за**али!»*, а она выдает: «Рад вас видеть сегодня, дорогие коллеги».
Режим активации голосом (VAD). Если не хочется постоянно держать кнопку - есть умная активация, которая сама определяет когда вы говорите.
Гибкий вывод. Текст можно отправлять сразу в активное поле (даже настроить автонажатие Enter после вставки) или просто тихо копировать в буфер обмена.
Как установить и запустить
Переходим на GitHub проекта и скачиваем установщик под свою систему из раздела Releases (есть под Windows, macOS и Linux)
Устанавливаем и идём в Settings → Transcription
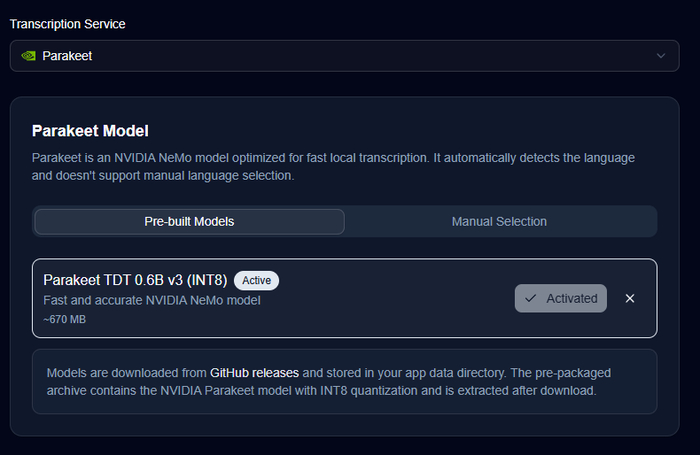
В разделе Transcription Service выбираем «Parakeet» (Local) для быстрой оффлайн-работы
В блоке Parakeet Model выбираем «Parakeet TDT 0.6B v3 (INT8)» - весит около 670 МБ, автоматически определяет язык. Жмём Activated для скачивания
Нажимаем горячую клавишу (по умолчанию Ctrl+Shift+;), говорим текст, отпускаем - готово
Если вы много печатаете и хотите иногда дать пальцам отдохнуть - попробуйте. Если вам надоели глючные браузерные расширения которые работают через раз - тем более. Ну и если хочется поиграться с LLM-фильтром для автоматической обработки надиктованного текста - это вообще отдельное удовольствие.
Это не моя сборка, но реально полезный инструмент который я сам использую каждый день. Такие штуки я регулярно нахожу и выкладываю у себя на канале НЕЙРО-СОФТ - там мы собираем портативные сборки нейросетей, репаки и полезные open-source инструменты, всё на русском и с простыми инструкциями по установке. Если вам заходит такой формат - заглядывайте.
Друзья, поддержите пост плюсиком, если было полезно! А если пользуетесь чем-то похожим для голосового ввода - делитесь в комментариях, интересно сравнить.
А я больше про нейросети рассказываю на YouTube, в телеграм, на Бусти. Буду рад вашей подписке и поддержке, всех обнял и удачных транскрпиций!
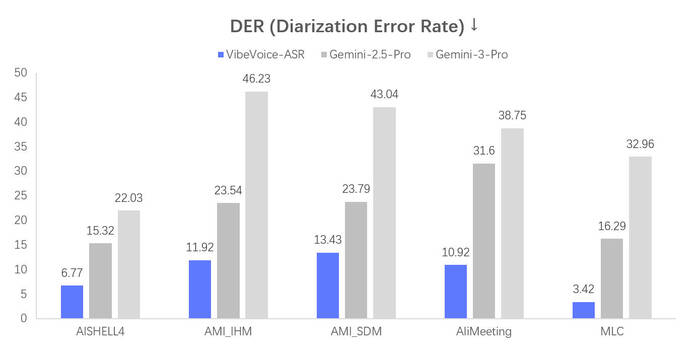
Всем привет! Команда Microsoft Research выложила в открытый доступ VibeVoice-ASR — нейросетевую модель для распознавания речи с диаризацией (разделением) спикеров. Сегодня хочу рассказать об этой технологии подробнее и поделиться портативной версией.
Меня зовут Илья, я основатель сервиса для генерации изображений ArtGeneration.me, блогер и просто фанат нейросетей. А ещё я собрал портативную версию VibeVoice ASR под Windows и успел её как следует протестировать.
Whisper которому уже года три
Я сам пользуюсь Whisper уже много лет — делаю транскрипции своих видео, чтобы потом собрать оглавление для YouTube и использовать материал в текстовых статьях. И скажу честно — никогда не был полностью доволен результатом. Да, Whisper быстрый. Но на этом его достоинства для меня заканчивались.
Поэтому к изучению VibeVoice ASR я подошёл со всей ответственностью — протестировал на разных записях, сравнил качество, покрутил настройки.
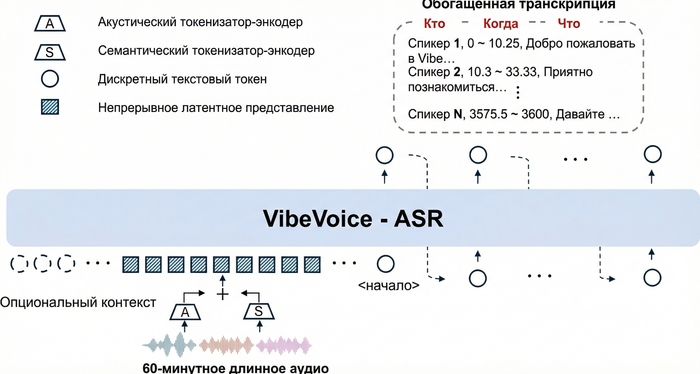
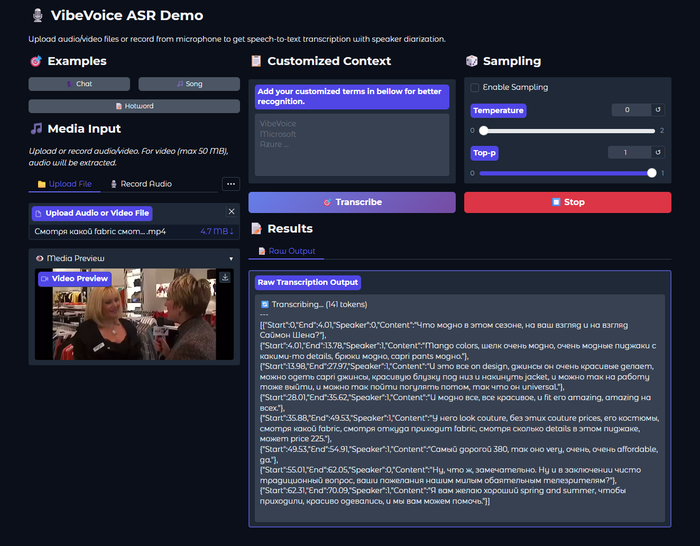
Главная особенность системы в том, что она обрабатывает до 60 минут аудио за один проход без нарезки на чанки. На выходе — структурированная транскрипция с указанием кто говорит, когда и что именно сказал. И всё это работает локально на вашем компьютере.
Как это работает
В основе VibeVoice-ASR лежит архитектура на базе Qwen 2.5 (~9 млрд параметров). Ключевая инновация — двойная система токенизации с ультранизким frame rate 7.5 Hz: акустический и семантический токенизаторы.
Такой подход позволяет модели работать с контекстным окном в 64K токенов — это и даёт возможность обрабатывать целый час аудио без потери контекста. Для сравнения: Whisper режет аудио на 30-секундные кусочки и теряет связность на границах сегментов.
На выходе модель генерирует Rich Transcription — структурированный поток с тремя компонентами:
{"Start":1.51,"End":7.49,"Speaker":0,"Content":"У неё преждевременное сохранять невозможно, родила, начала сразу родильная деятельность."},
{"Start":7.51,"End":9.41,"Speaker":1,"Content":"Марина, что с ней?"},
{"Start":10.28,"End":16.22,"Speaker":0,"Content":"У неё преждевременное сохранять невозможно, отошли годы, начала, начала сразу родовая деятельность."},
{"Start":16.22,"End":18.02,"Speaker":1,"Content":"Марина, что с ней?"},
{"Start":18.13,"End":27.94,"Speaker":0,"Content":"Она рожает, привезли в ближайшую больницу родовую. В каком состоянии ребёнок ещё хуже, срок маленький."},
Помимо спикеров, модель размечает неречевые события: [Music], [Silence], [Noise], [Human Sounds] (смех, кашель), [Environmental Sounds], [Unintelligible Speech]. Это сделано чтобы модель не галлюцинировала текст во время пауз или фоновой музыки.
Обработка длинных записей: до 60 минут аудио за один проход без потери контекста. Идеально для митингов, подкастов, лекций.
Диаризация спикеров: автоматическое определение кто говорит в каждый момент времени. Работает на записях с несколькими участниками.
Временные метки: точные таймкоды для каждого сегмента речи. Готовый материал для субтитров.
Customized Hotwords: вот что меня реально зацепило — возможность задать пользовательский контекст. Перед распознаванием указываешь список слов: фамилии, названия продуктов, термины, сокращения. Всё то, что обычно произносится нестандартно и превращается в кашу. Если в видео часто звучит "ArtGeneration" или "НЕЙРО-СОФТ" — просто добавляешь в контекст, и модель ВСЕГДА распознаёт корректно. Для технического контента — просто спасение.
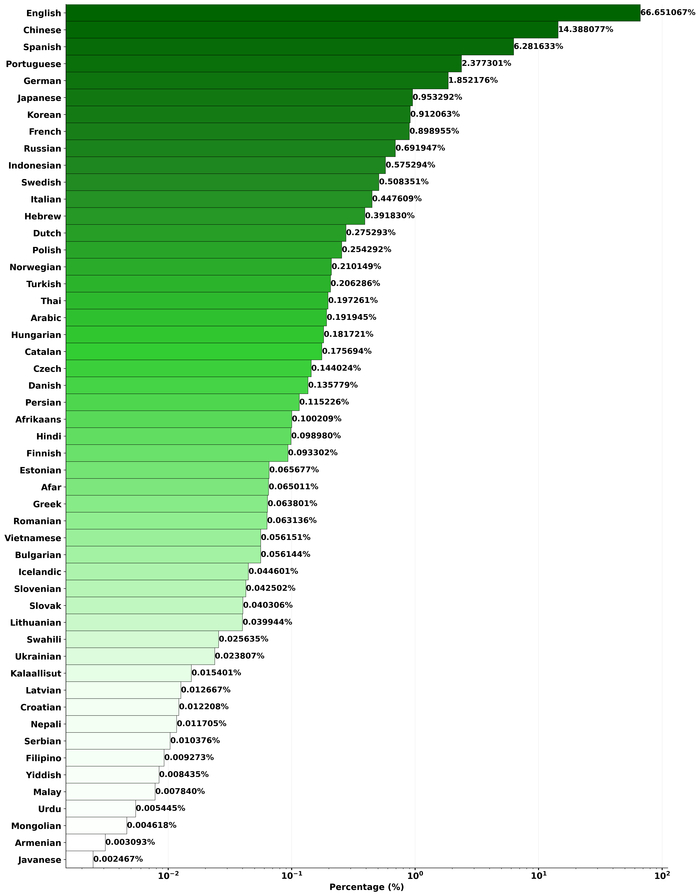
51 язык: включая русский, хотя основной фокус на английском и китайском.
Набор языков отличный
Модели
Помимо оригинальной модели от Microsoft, сообщество уже сделало квантованные версии для видеокарт с меньшим объёмом памяти.
Полная модель — microsoft/VibeVoice-ASR Размер 17.3 GB, требует ~8 ГБ VRAM. Лучшее качество распознавания.
4-bit квантизация — scerz/VibeVoice-ASR-4bit Требует ~4 ГБ VRAM, немного медленнее. Подходит для видеокарт с меньшим объёмом памяти.
В моей портативке доступны обе версии — можно выбрать прямо в интерфейсе. Также есть эмуляция 4-bit квантизации для полной модели, если хотите попробовать оригинал, но памяти впритык.
Текущие ограничения
К сожалению, не все задачи система решает одинаково хорошо:
Перекрывающаяся речь: если два человека говорят одновременно, модель не разделит их корректно.
Короткие фрагменты: диаризация плохо работает на высказываниях менее 1 секунды.
Только batch processing: нет real-time режима, только обработка готовых файлов.
Ресурсоёмкость: требует достаточно мощную видеокарту для комфортной работы.
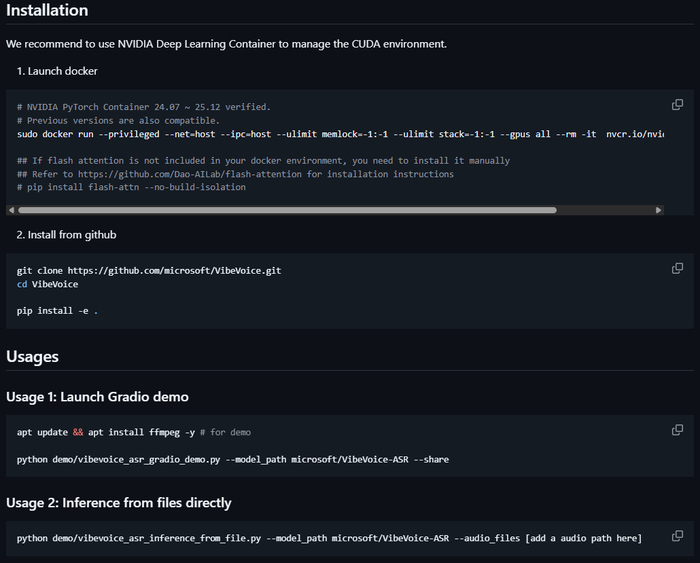
Я с каналом Нейро-Софт подготовил портативную сборку VibeVoice ASR Portable RU. В ней:
Русифицированный интерфейс
Установка в один клик (install.bat)
Поддержка полной и 4-bit моделей
Парсер результатов с фильтрацией — можно отдельно включать/выключать временные метки, спикеров, дескрипторы (музыка, шум, тишина). Удобно когда нужен только чистый текст без разметки
Фильтр по спикерам — можно вывести текст только конкретного участника разговора
Выбор видеокарты и установка нужной версии CUDA
Flash Attention 2 для RTX 30xx/40xx/50xx
Поддержка всех форматов аудио и видео через FFmpeg
Тёмная тема интерфейса
Всё необходимое уже включено в дистрибутив, просто распакуйте и запускайте, есть версия с готовым окружением под win 11 и RTX4090. Забирайте архив тут.
NVIDIA GPU с 8+ ГБ видеопамяти (или 4+ ГБ для 4-bit модели)
Windows 10/11 64-bit
16 ГБ оперативной памяти
10 ГБ свободного места на диске
Распакуйте в любую папку (путь без кириллицы), запустите install.bat, выберите видеокарту из списка. Модели скачаются при первом запуске.
Рассказывайте в комментариях как вы могли бы использовать такой инструмент и чего не хватает.
Я рассказываю больше о нейросетях у себя на YouTube, в Телеграм и на Бусти. Буду рад вашей подписке и поддержке. На канал Нейро-Софт тоже подпишитесь, чтобы не пропустить полезные репаки. Всех обнял. Удачных транскрипций!