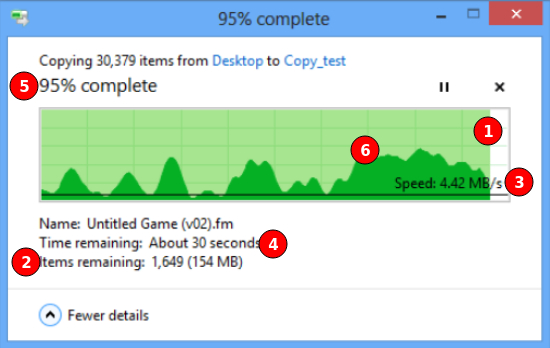
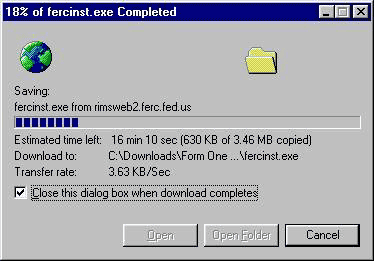
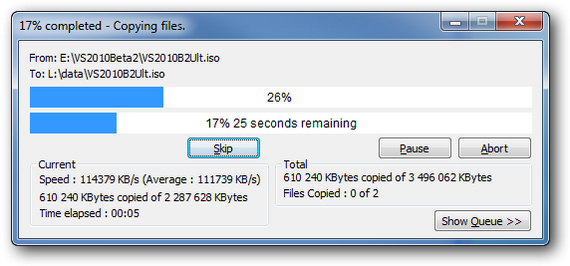
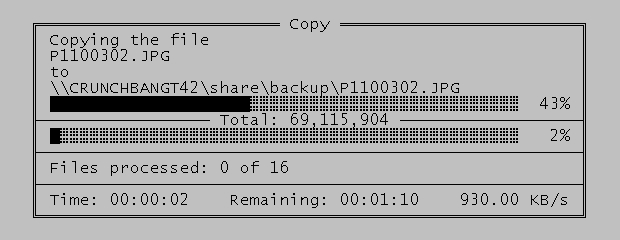
Ответ на пост «Тсс, этот секрет останется между нами и теми самыми библиотеками»1
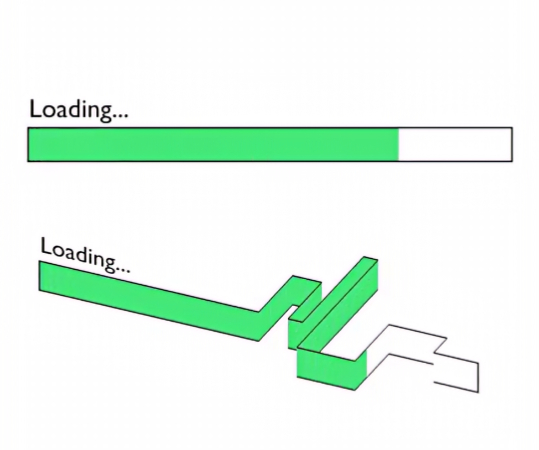
Доступно об АйТи: Почему ПО стало раздуваться
Я и сам против раздувания, и расскажу на примере своей программы «Юникодия». Это небольшая энциклопедия письменностей и самая лучшая замена Таблице символов, качать тут.

Исходный мем
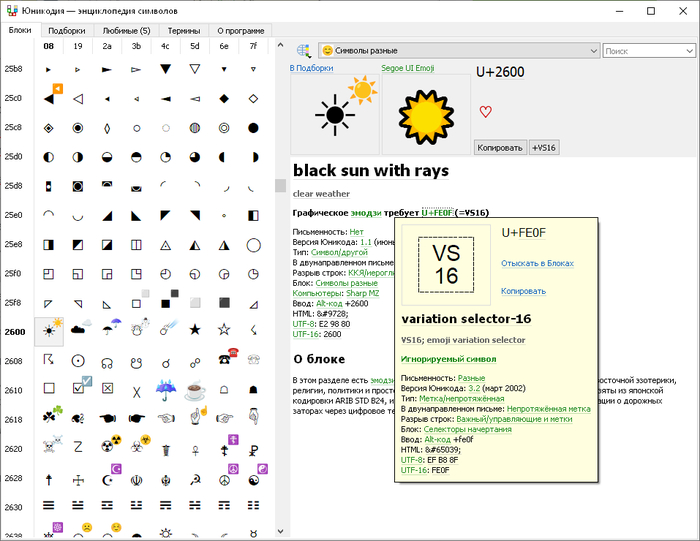
Моя Юникодия
Использование фреймворков
«Юникодия» использует фреймворк Qt 6.1.3 — последний поддерживающий Windows 7. Думаю бросить «семёрку» и поднять версию Qt, но не знаю. Один только Qt занимает 24 мегабайта.
Слово «фреймворк» изначально (в вебе это слегка не то) означало библиотеку, которая содержит внешний цикл. Программист пишет программу, прописывая собственные события, вызываемые этим внешним циклом.
В настольном программировании фреймворк чаще всего используется для создания пользовательского интерфейса.
Кроссплатформенность
Одна из причин, почему используют фреймворки.
«Юникодия» есть только под Windows: у меня нет Мака, и и вообще на нём придётся учиться многому: свои цепочки шрифтов, свои механизмы сборки пакета, свои разглючки… Но, полагаю, фреймворк Qt поможет наладить Мак за пару недель, ведь он объединяет совершенно разные API операционных систем в один собственный.
Поднявшиеся требования к интерфейсу
Одна из причин, почему используют фреймворки: интерфейс должен давать тени, прозрачности и анимации.
Даже банальная таблица слева — это не стандартный элемент Windows, а нечто сделанное Qt с нуля.
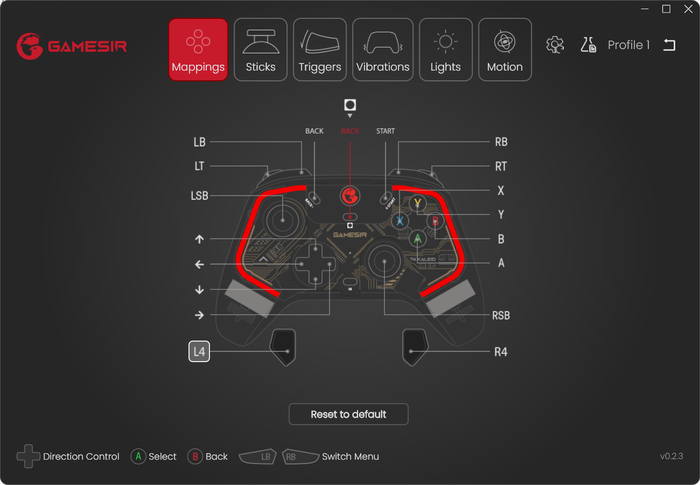
Программа с собственным роскошным интерфейсом (драйвер от джойстика)
Сейчас очень многие проги делают собственный интерфейсный стиль. Сам я, как программист, говорю: нет денег на хорошую дизайнерскую группу — в настольной программе используйте акценты, а не стройте новую «шкурку». У вас просто не получится сделать лучше, чем есть в ОС «из коробки». Решение моей Юникодии — только кое-где убрать рамку, чтобы уменьшить визуальный шум. Плюс пара цветных плашек.
HiDPI
…То есть экраны с высокой плотностью пикселей. Одна из причин, почему используют фреймворки.
Сами фреймворки налаживают довольно сложную поддержку HiDPI.
Программисту активно приходится писать функциональность по поддержке HiDPI там, где фреймворк сплоховал или нужно что-то нарисовать программно. Мороки много, килобайтов мало.
Широкое использование векторной графики, растра запредельного разрешения. У меня из растров запредельного разрешения только иконки разных размеров от 16×16 до 256×256, а вот поддержка SVG от Qt занимает дополнительные 480 килобайт.

Иконки блоков на 175%
Загадка. Сможете сказать про каждую иконку, каким образом она рисовалась? Варианты: 1) Простой SVG; 2) Хинтованный SVG — SVG сдвигается на долю пикселя так, чтобы какая-то линия попала точно в пиксель; 3) Полупрограммно или программно — особый метод, придуманный специально для данной иконки.
Визуальные решения, взятые из веба
В частности, широкое использование иллюстраций.
Ольга Шаврина говорит, что иллюстрации в интерфейсе нужны в таких местах.
Пустые состояния — там, где (пока) нет контента.
Онбординг — там, где мы подсаживаем пользователя на нашу программу/службу. Приветствует, знакомим, обучаем, помогаем.z
Уведомления — извещаем о событиях, добавляем эмоций в сообщение.
Индикация прогресса — отражаем текущий статус пользователя или системы.
Облегчение выбора — картинкой уменьшаем количество текста.
Что из этого актуально для «Юникодии…
Иконки — это то самое пятое, когда привыкший к «Юникодии» запоминает цвет и символ.
Пустое состояние тоже есть в количестве одной штуки. Но встроенный минибраузер плохо работает с HiDPI (и не знаю, как разглючить), а я не переношу «корпоративного мемфиса» — потому оставил без картинки.
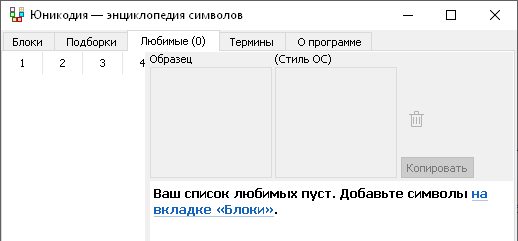
Пустое состояние — не помешала бы картинка

Рандомная картинка в стиле «корпоративный мемфис»
Интернет
Библиотеки доступа к интернету занимают мегабайты, и дело в протоколе HTTPS: он в принципе полагается на здоровенную батарею шифров. Даже если вся интернет-функциональность — проверить обновление.
Я наткнулся на проблему: программе рано или поздно придётся заказывать электронную подпись, и затык в интернет-библиотеке: старый Qt использует брошенный и неофициально поддерживаемый кем -то OpenSSL 1.1. Разумеется, неподписанный.
Существует старая цитата:
Каждая программа будет расширяться, пока не научится читать почту. Программы, которые не могут так расшириться, заменяются теми, которые могут.
— Джейми Завински, разработчик Netscape
В современных реалиях это не почта, а веб. Некоторые программы — к Юникодии это не относится — таскают с собой целый браузерный движок размером мегабайт тридцать.
Расширение функциональности
Тут всё просто. По Блокам оказалось сложно выискивать некоторые символы? Сделаем Подборки. Кто-то просит Любимые? Ну, давай.
Поскольку я одиночка, само расширение функциональности отнимает немного — зато нет-нет, да подтяну какую-то библиотеку для этого (например, поддержку ZIP).
Локализация
Пять языков занимают не так много, всего 3 мегабайта. Это включает как модули локализации Qt, так и мои собственные. «Юникодия» содержит текста на небольшую книгу (200 тысяч знаков), и мои модули несколько больше Qt’шных.
Новая функциональность новых ОС
Занимает не так много, несколько десятков килобайт, но в стартовом меню Windows 10 используются свои иконки особого размера.
Специфичное для Юникодии
Я не использую каких-то цветастых интерфейсов, программа таскает необходимый минимум графики.
Зато Юникодия, раз уж это энциклопедия символов, таскает 110 мегабайт шрифтов, и с каждым новым Юникодом этих шрифтов становится больше и больше. Основной источник увеличения — китайские иероглифы: шрифту А я максимально доверяю, шрифт Б содержит новые символы, шрифт В — корейский и японский в каноничном для них формате «без засечек».
За китайскими иероглифами с непреодолимым отрывом отстают египетские и… жестовое письмо Валери Саттон.
Ответ на загадку. Простой SVG — всё, что не содержит горизонтальных/вертикальных линий. Хинтованный SVG — если таковая есть (нота, например). Программно — сложные структуры, где полное попадание в пиксели важнее попадания в размер (все пиксельные, а также счётные палки).
Спасибо за внимание!