С 10 июля 2026 года сотрудникам Alibaba официально запрещено пользоваться Claude Code — фирменным ИИ-инструментом Anthropic для программирования. Компания требует удалить все модели Anthropic и перейти на собственную разработку — Qoder.
Официальная причина (Reuters, Morningstar) — «риски бэкдора». В одной из версий Claude Code (история всплыла благодаря посту на Reddit) нашли скрытый код, вычислявший пользователей из Китая. В Anthropic не отрицают: разработчик компании Тарик Шихипар назвал это «экспериментом, запущенным в марте против злоупотребления аккаунтами реселлеров и защиты от дистилляции», добавив, что защиту давно усилили и код «давно собирались убрать».
Бан — дорога с двусторонним движением. Паника Alibaba — не первый шаг, а ответный. Сама Anthropic по условиям использования запрещает продажу доступа компаниям, контролируемым Китаем, Россией, Ираном, КНДР — включая Alibaba, Ant Financial, ByteDance, DeepSeek, Moonshot AI, MiniMax. Причина — обвинения в «дистилляции»: около 16 млн подозрительных запросов, которыми, по данным Anthropic, китайские фирмы прогоняли через Claude, чтобы обучать свои дешёвые модели на его ответах. Обходили это через облачных посредников, «дочки» в Сингапуре и VPN.
Почему это не просто взаимные обиды. За перепалкой про бэкдоры и санкции стоит куда более практичный интерес: лидерство Claude и ChatGPT держится не только на вычислениях — а на постоянном притоке живых пользовательских данных, которые правят модель точнее любого синтетического датасета. Именно поэтому топ-лабы так щедры на кредиты сверх реальной цены API — по оценкам, у пользователей Claude на руках оказывалось около $8 тыс. в кредитах, у ChatGPT — почти $18 тыс. Это не благотворительность, а плата за данные, которые нельзя купить напрямую.
У китайских лабораторий такого канала нет и не будет — а теперь, когда Alibaba официально уводит своих людей от Claude Code, даже тонкий обходной ручеёк пересыхает. Индустрия окончательно распадается на два несмешивающихся контура данных — американский и китайский.
Представьте, что ваша база данных — это живой организм. У него есть пульс (скорость выполнения запросов), давление (время ожидания) и даже настроение (корреляция между ними). И как любой организм, он иногда болеет — падает производительность, возникают «тормоза», а то и полные остановки. Хороший администратор (DBA) чувствует эти симптомы, но часто слишком поздно.
А что, если мы сможем предсказывать болезнь за час до её начала? Именно эту задачу мы решаем в проекте pg_expecto — и в этом нам помогает не просто статистика, а настоящий цифровой напарник — нейросеть DeepSeek.
Главная идея: от наблюдения к предсказанию
Мы давно умеем собирать метрики: загрузку CPU, операции ввода-вывода, время ожидания блокировок. Но просто смотреть на графики — всё равно что гадать по облакам. Чтобы предсказывать будущее, нужна модель, которая улавливает закономерности переходов из одного состояния в другое. Для этого мы используем цепи Маркова — математический аппарат, который описывает, как система переходит между дискретными состояниями с определёнными вероятностями.
В нашем случае состояние — это комбинация трёх показателей:
насколько сильно операционная скорость «дружит» с ожиданиями (корреляция);
куда движется скорость (растёт, падает или стоит на месте);
куда движется время ожидания.
Всего таких состояний — 189. Каждую минуту мы фиксируем текущее состояние и запоминаем, в какое состояние система перешла дальше. Так накапливается статистика переходов — матрица вероятностей. Имея её, мы можем сказать: если сейчас система в состоянии X, то через 15 минут она с вероятностью 73% окажется в «красной зоне», а через час — уже с 91%.
Звучит как магия, но за этим стоит простая и прозрачная математика. И главное — эта модель не статична. Она учится на наших данных, адаптируется к нагрузке, «забывает» устаревшие паттерны. Всё это мы реализовали в открытом репозитории markov_chain, который тесно связан с pg_expecto.
Кто здесь главный? Человек vs Нейросеть
В этом проекте сложилось удивительное разделение труда.
DeepSeek взял на себя всю «черновую» работу:
Пишет код — от функций сбора данных до расчёта матриц и прогнозов;
Анализирует отчёты — выискивает скрытые связи между метриками и инцидентами;
Готовит публикации — статьи, посты, даже иллюстрации;
Генерирует гипотезы — предлагает, что ещё можно попробовать, какие параметры изменить.
Но настоящий «мозговой центр» — автор проекта (опытный DBA). Он не просто наблюдает со стороны. Его задачи — стратегические:
постановка целей и ограничений;
анализ проблем, которые не может уловить алгоритм;
критическая оценка гипотез, которые выдвигает нейросеть;
принятие финальных решений о том, что внедрять.
Именно автор сформулировал две прорывные идеи, которые перевернули наш подход.
Прорывные идеи, рождённые в голове эксперта
Первая идея — учить модель не на текущих данных, а на всей исторической глубине. Вместо того чтобы ждать недели, пока накопится достаточно переходов, мы загрузили в модель многолетнюю историю pg_expecto. Это как если бы метеоролог предсказывал погоду не по показаниям барометра за последний час, а по архиву наблюдений за десять лет. Результат — модель начинает выдавать осмысленные прогнозы практически с первого дня.
Вторая идея — адаптивная настройка параметров цепи. В классической цепи Маркова вероятности переходов считаются стационарными. Но в реальной жизни нагрузка на базу данных меняется по дням недели, сезонам, релизам. Мы ввели механизм «забывания» — старые переходы постепенно теряют вес, а свежие — приобретают. И параметры этого забывания настраиваются автоматически, в зависимости от текущей стабильности системы. Это позволяет модели подстраиваться под новые условия быстрее, чем человек успевает заметить изменение.
Эти идеи — чисто человеческие. Нейросеть помогла их формализовать, просчитать на симуляциях и воплотить в код. Но направление задал эксперт.
Так и рождается настоящий симбиоз: человек задаёт вектор, машина прокладывает путь.
Что даёт такой подход на практике?
Мы уже видим конкретные результаты. Прогнозы модели позволяют заранее, за 15–60 минут, узнавать о высокой вероятности инцидента. Это даёт администратору время: переключить нагрузку, увеличить буферы, перезапустить проблемные запросы — словом, предотвратить аварию, а не разгребать её последствия.
Кроме того, модель даёт численную оценку среднего времени до отказа (MTTF) — параметр, который раньше был доступен только для аппаратных систем, но не для софта. Теперь мы можем количественно оценить, сколько в среднем «живёт» система в каждом состоянии, и планировать профилактику.
И, что важно, всё это — open source. Вы можете взять код, подключить к своему PostgreSQL и начать предсказывать. Прозрачность модели — не «чёрный ящик», а понятная матрица переходов — позволяет доверять прогнозам и разбираться в причинах.
Взгляд в будущее: что дальше?
Мы не собираемся останавливаться. Следующие шаги — расширение пространства состояний за счёт дополнительных метрик (например, использование памяти, план выполнения запросов). Также мы думаем о том, чтобы сделать модель гибридной: цепь Маркова будет отвечать за краткосрочные прогнозы, а нейросеть (уже глубокая) — за долгосрочные тренды и аномалии.
Но главное — мы хотим, чтобы этот подход стал стандартом для проактивного управления производительностью. В идеале DBA перестанет быть «пожарным» и станет «архитектором надёжности». А нейросети будут его верными помощниками, а не конкурентами.
Заключение
Проекты pg_expecto и markov_chain — это не просто утилиты для мониторинга. Это живой пример того, как человек и искусственный интеллект могут дополнить друг друга. Нейросеть выполняет рутинную, но интеллектуально ёмкую работу: пишет код, анализирует горы данных, предлагает идеи. Эксперт — ставит цели, проверяет гипотезы, задаёт направление и принимает финальные решения. Вместе они создают систему, которая не только смотрит в прошлое, но и заглядывает в будущее.
И если адаптивная цепь Маркова, обученная на многолетней истории, действительно станет надёжным предсказателем сбоев, это будет означать, что мы сделали большой шаг от реактивного администрирования к интеллектуальному управлению.
А значит, базы данных станут не только быстрее, но и надёжнее — а это выигрыш для всех, кто пользуется современными сервисами.
Автор проекта pg_expecto и markov_chain — Ринат Сунгатуллин.
Всем привет! Я, как и многие, прошёл путь от «да кому нужны эти ваши ИИ» до «мистер нейросеть, пожалуйста, просто почини мне эту чёртову кнопку, я спать хочу». Последние пару лет плотно сидел на западных моделях — платил, терпел, матерился. Но когда в очередной раз просишь написать парсер, а тебе выдают «попробуйте использовать CSS Grid», начинаешь задумываться.
В общем, начал я искать что-то под свой стиль работы — вайбкодинг. Это когда ты не матёрый сеньор с зарплатой в биткоинах, но и не тот парень, который гуглит «как включить компьютер». Просто садишься вечерком, накидываешь нейронке мысль на русском, а она тебе — оп, и рабочий файлик. И ты такой сидишь, кофеёк потягиваешь, чувствуешь себя немного джедаем. Главное — чтобы железяка реально въезжала в твой вайб, а не тупила.
Листая очередную подборку «10 AI-инструментов для кода в 2026», наткнулся на название DeepSeek. Раньше видел его только в новостях про квантовые прорывы и «китайцы опять всех сделали». Скажу честно, думал — хайп. Ну дешёво, ну бенчмарки рвёт. Но как оно в реальной грязной работе, когда у тебя в папке pet_project_final_final2 бардак из копипасты трёхлетней давности? Я решил затестить его на своих реальных хотелках и готов рассказать без прикрас.
Контекст — резиновый, но не бесконечный
Первое, от чего у меня реально подгорело (в хорошем смысле) — это размер контекста. В других чатах пытаешься скормить три файла, а он уже на втором забывает, как тебя зовут. Тут я ради эксперимента закинул почти весь свой пет-проект — файлов семь, строк под тысячу — и попросил найти баг, который я искал неделю. Ошибку он нашёл (я забыл await, классика же). Но он на этом не остановился: «Слушай, дружище, а вот тут у тебя ещё и утечка памяти потенциальная, давай подправим архитектуру». Я аж поперхнулся. С одной стороны — приятно. С другой — я засомневался: может, он просто выпендривается? Пара его «улучшений» потом не взлетела из-за внешних зависимостей, пришлось переделывать. Так что доверять, но проверять.
Код или болтовня?
Заказал реальную задачу: админка на React для мониторинга цен с парсингом, тёмная тема, экспорт в CSV. Без «допишите сами» и «вам нужно настроить Babel». DeepSeek выкатил структуру с первого раза. Даже requirements.txt положил и стили нормальные забабахал. Я прям порадовался. Правда, когда чуть позже попросил добавить фильтрацию по дате с нестандартной логикой, он трижды выдавал кривоватые варианты, и лишь на четвёртый раз получилось то, что нужно. То есть не всё гладко, но для «накидать MVP за вечер» — огонь.
Ещё он до жути буквальный. Скажешь «хочу сайт» — получишь сайт. Скажешь «хочу сайт, чтоб грузился за 0.1 секунды и клиенты в очередь стояли» — он начнёт задавать кучу уточнений: «Может, Redis? А lazy loading?» Это не «соглашатель», который навалит говнокода и свалит. Но иногда эти расспросы затягиваются, как допрос в ФСБ, и проще уже ручками допилить.
Как я приручил этого зверя (и выжил)
Потратил пару вечеров, чтобы нащупать подход. Если просто писать «сделай кнопку», результат средненький. Чтобы получить реальный вайб-эффект:
1. Корми контекстом, не жадничай. Забудь про абстрактные просьбы. Кидай сразу файлик, скриншот ошибки, JSON-схему БД. Чем больше подробностей, тем лучше. Но если закинуть слишком много, он может начать путаться, так что знай меру.
2. Общайся как с умным джуниором. Промпт — это не магия, это ТЗ. Я пишу примерно так: «Ты — сеньор-питонист. Вот код. Делаем микросервис. Стиль — PEP8, типизация. Задача: добавить роутер с валидацией через Pydantic. Не лезь в БД. Сначала подумай, где узкие места, потом пиши». Помогает.
3. Русский язык — тайное оружие. Серьёзно, можно писать в стиле «братан, прикрути тут сортировку, чтоб не тормозила». DeepSeek понимает, не ломается. Пару раз только просил уточнить, что такое «прикрути свистелку», но это мелочи.
4. Не стесняйся использовать режим рассуждения. Просишь сначала план, а потом код. Это экономит время: лучше пусть он распишет, какие библиотеки и зачем, чем потом переписывать половину.
Ложка дёгтя (куда ж без неё)
· Тормозит в час пик. Иногда задумывается секунд на 15–20. Вроде не завис, но когда рабочий настрой — это напрягает. Я за это время успеваю заварить чай и пару раз вздохнуть.
· Чрезмерная инициатива. Просишь поправить одну строчку, а он переписывает полфайла: «Так архитектурно правильнее». Приходится одёргивать жёстким промптом, типа «руки убери, только строчку».
· Галлюцинации. Иногда придумывает несуществующие методы, как pandas.read_mind(). Проверять всё равно надо, никто не отменял.
· Бесплатность — это пока. Сейчас халява, но лимиты есть. При очень активной работе можно упереться, хотя я упирался пару раз и то под утро.
Вердикт:
Если хочешь под вечерок накидать MVP, автоматизировать рутину или просто пописать код под пивко, не отвлекаясь на гугление ошибок, — DeepSeek реально хороший ИИ. Он не заменит программиста (и слава богу), но как напарник для «творить и не материться» — один из лучших, что я пробовал. Деплоить продакшен и решать сложные девопс-задачи я бы ему пока не доверил, но желание кодить возвращает моментально.
Телеграм, ВКонтакте, Дзен, Макс — площадок становится все больше, а вот внимание аудитории по-прежнему ограничено. Что делать? Продвигать!
На Пикабу можно рекламировать свои каналы прямо в лентах сайта. Находите новую аудиторию и получайте живые переходы без сложных рекламных кабинетов.
Подойдет для:
авторских и экспертных блогов
бизнеса
медиа и новостных каналов
мемных и развлекательных сообществ
Запускается просто: добавляете ссылку, пишете заголовок и краткое описание и выбираете географию для показов. А дальше о вашем канале узнают тысячи пользователей Пикабу!
Привет Пикабу. Решил поделиться с вами процессом разработки своей игры.
Сразу для лл: Делаю игру, выживание в изометрии. Основная фишка - генератор историй (как римворлд) только игрок управляет лишь собой. Другие пешки не подконтрольны и из этого складывается история.
Ну а для тех кому интересно, начну с того, что про создание игр я знаю примерно ничего)))
Я поставил себе юнити на домашний пк, на пк жены и на свою старенький ноутбук, которых хранится на работе. С женой мы работаем в 1 месте и так получается, что у меня рабочий день до 20:00, а у нее до 22:00 и в ожидании этих пары часов (каждый день) я решил что мне хватит времени разобраться что к чему.
Первым делом я понял, что нужна идея! То, какую игру я бы хотел сделать, то, во что бы хотел сам залипать. Зашел в свой стим, посмотреть где я больше всего времени провел, что бы подумать, что в том или ином проекте меня зацепило. После доты, кс, цивилизации у меня идет римворлд и рафт. В римворлд я никогда не доигрывал до конца, сколько бы не возвращался, как бы не старался, за 1 сессию не пройти, а с моим графиком работы раз в неделю в выходной по 4-5 часов поиграть... Но самое главное, я привязывался всегда к 1 пешке и забивал на остальных, по этому успешной колонии у меня и не получилось. Тогда я решил, буду делать симулятор колонии, где игрок - просто 1 из колонистов со своими чертами, минусами и плюсами, что бы игрок мог понимать, вот с тем у нас плохие отношения, он пошел рубить деревья, пойду порыбачу. Игрок пошел искать еду и на него напал дикий зверь? Беги, дерись, кричи и надейся, что другой колонист прибежит и поможет, а может не поможет, потому что ты съел последнее блюдо и он остался голодным.
Приступим к реализации идеи, нужны черты характера, скилы, технологии, что к чему идет и как оно будет. Помечтал, открыл эксель и начал набрасывать все идеи, связки, влияние тех или иных черт характера на различные события. Набросал, а что дальше? Нужно создавать игру по этим правилам, но как писать код и скрипты? анимации и 3д модели? Тут я понял, что необходимо использовать нейросети. (Сразу можно написать в комменты "фу, нейрослоп, фу"). Открыл чат с дипсиком и гигачатом. Дипсик пусть пишет скрипты, гигачат рисует иконки, звучит так круто, просто и быстро, что я подумал "такую игру можно выпустить за пару месяцев" ведь почти вся работа делается не мной, с меня тестить и просить "исправь это", но это была ошибка....
Нейросети. Дипсик действительно умеет писать скрипты, которые можно просто копировать в юнити и привязав к объекту - получить работающий элемент игры. По началу оно даже работало как надо, скрипт передвижения, скилы (типа лесорубство) прокачивается от рубки деревьев и от уровня зависит скорость рубки. Но когда я приступил к реализации более сложных моментов получилось так, что его скрипты между собой не работают, другие названия переменных и прочие проблемы, которые нужно фиксить самому. За пол года я разобрался с основными его проблемами и научился понимать как работают скрипты на С#. А гагачат все рисует иконки, правда кривые, не понятные, с 25 раза, но иногда удается добиться то, что нужно.
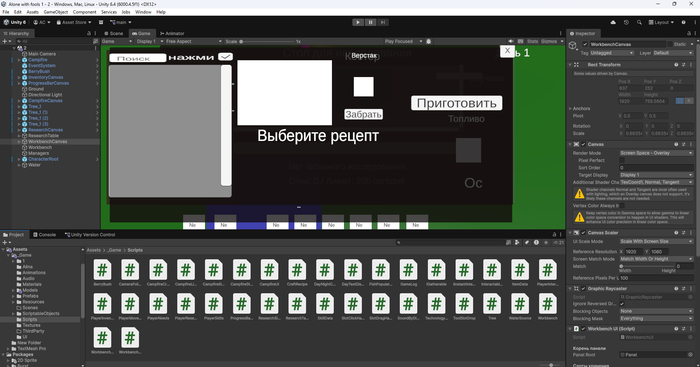
Вот так выглядит проект. Ужасный UI, который такой по 1 причине - древний ноут и мне так виднее что к чему и как оно работает, как работает крафт, рецепты. Скрипты частично на русском, частично на английском, Это я полностью исправлю, потому что начитался что кириллица работать не будет, но все норм и все работает).
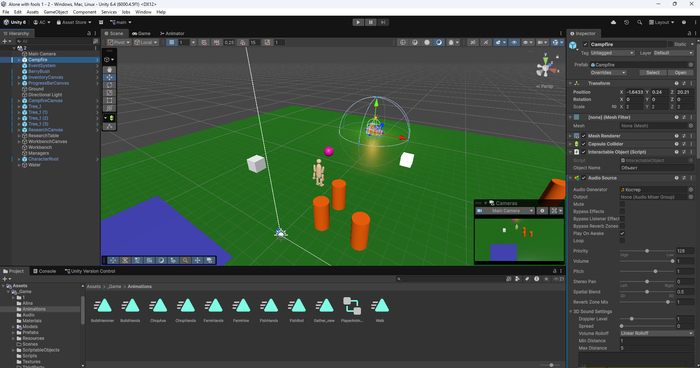
Весь проект был построен на примитивных фигурах, белый куб - стол для исследований, желтый - верстак и т.д. В какой-то момент я поймал себя на мысли, что сам уже путаюсь и пытаюсь рубить топором рыбу, а не дерево... Базовая логика игры работает, значит нужны анимации и 3д модели. На анимации потратил много времени, то они работали, то нет, никак не мог разобраться в юнити в этом аспекте и уж было думал что все, но вдруг обратил внимание, анимации работают, но только те, где персонаж не перемещается. Типа части тела двигаются - норм, весь персонаж - не работает.
Мини видео процесса с примитивами, в игре есть смена дня и ночи и солнце восходит и заходит.
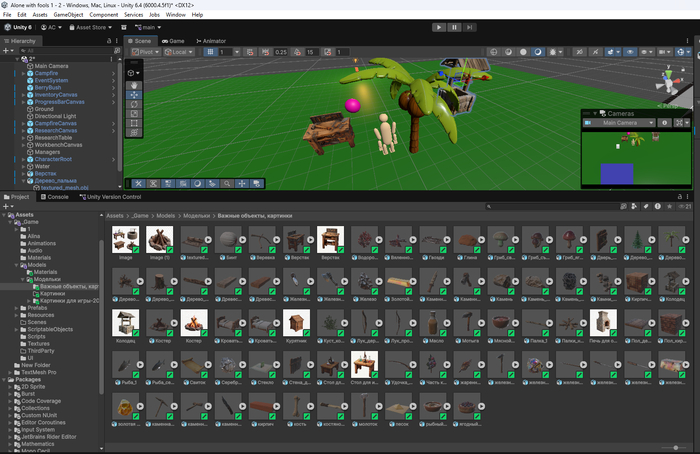
Следующий этап - 3д модели. Первая мысль - куча готовых ассетов, примеров, можно скачать все что угодно! Но облазив несколько сайтов, включая офф сайт юнити я понял, что бесплатные - отстой, не все, но большинство. А те что хороши - используются в таком количестве игр, что уже надоели... Ну раз есть нейросети, то пусть и в этом помогут) Так я нашел Хуньян, где по фото (картинке) можно получить готовую 3д модель. Вау, то что нужно, но вот токены стоят денег, бесплатный лимит - очень мало. Может ее можно локально запустить? Да можно, через какую-то прогу, которая сама все настраивает (comfyui). Скачал, поставил и получил белые модели, без текстур. Перерыл кучу инструкций, но добавить текстурирование не смог. (напомню, если кто-то дочитал до сюда, на работе - древний ноут, норм пк только дома, а это раз в неделю 4-5 часов свободного времени). Замучил дипсик, мол вот тебе страничка с гитхаба, помоги запустить. Много чего пробовал и в конце концов, спустя 4-5 месяцев попыток я смог это сделать и теперь могу из картинки генерировать 3д модель с текстурами!.
Да, они не идеальные, но это гораздо лучше чем то, что я могу сделать сам.
Работы предстоит еще очень и очень много, для первого проекта такой масштаб наверное перебор, но меня очень сильно радует это занятие и я вижу свой прогресс. Дальше будет лучше, я считаю это отправной ночкой, ведь дальше будет проще.
После собеседования по телефону – включение в рассылку материалов для передачи опыта через вашу почту на конкретных примерах текущего диалога с госорганами по решению крупных проблем.
Еженедельные онлайн-конференции с ответами на вопросы по конкретным кейсам с вовлечением в практику интеллектуального диалога с правящим классом бюрократии госуправления.
Самый мощный ИИ постепенно превращается в товар стратегического назначения — с экспортным контролем, как у оружия. На этой неделе OpenAI начала раздавать GPT-5.6 не по подписке, а по разрешению из Вашингтона. И это уже не первый звонок.
Доступ — по визе из Белого дома. OpenAI подтвердила: в превью-период доступ к GPT-5.6 одобряет правительство США в индивидуальном порядке, клиент за клиентом. Координируют процесс Управление национального кибердиректора, Управление по науке и технологиям (OSTP) и Минторг. Опираются на исполнительный указ Трампа о «добровольной» федеральной проверке мощных моделей перед релизом — хотя на практике «добровольность» обернулась обязательным согласованием. Сэм Альтман уже дистанцировался: «мы дали понять властям, что это не наша предпочтительная схема, и будем с ними работать». Широкий запуск обещают «парой недель позже» — если проверка пройдёт гладко.
Почему именно сейчас. Регуляторов пугает не контент, а кибер-способности. Современные модели всё лучше находят уязвимости в чужом коде и могут автономно ломать системы. Опасение простое: если такая модель попадёт к противнику раньше, чем выстроены защитные барьеры, она станет готовым кибероружием.
Это уже тренд, а не исключение. Двумя неделями ранее, 13 июня, администрация экспортным указом потребовала приостановить доступ к флагманским моделям Anthropic — Fable 5 и Mythos 5 — для любых иностранцев, включая собственных сотрудников компании без американского гражданства. Anthropic пришлось резко вырубить доступ для всех. Триггером стал найденный джейлбрейк: обходя киберзащиту, Fable 5 можно было заставить «прочитать конкретную кодовую базу и починить любые уязвимости» — то есть превратить в автономного хакера. Сама Anthropic возражала: если так судить, придётся остановить выкатку вообще всех фронтир-моделей в индустрии.
Мир делится на зоны. Складывается новая карта доступа к ИИ. США и ближайшие союзники — внутри периметра, получают самое мощное первыми. Европа, Азия, Россия — всё чаще снаружи, с пометкой «only for US». Фронтир-интеллект становится геополитическим активом, а не просто продуктом.
Окно — у Китая. Парадоксально, но главная надежда тех, кто за стеной, — открытые китайские фронтир-модели: DeepSeek, Kimi, GLM, Qwen. Пока Пекин не повторил вашингтонский трюк и продолжает выкладывать веса в открытый доступ всему миру, именно они остаются способом не остаться на «мёртвой стороне автобуса».
В работе рассматривается проблема сохранения целостности и когерентности вероятностных моделей, состояние которых непрерывно эволюционирует во времени, при проведении экспериментов и последующем восстановлении данных. Предлагается методика выборочного резервного копирования таблиц марковской цепи с последующей реконструкцией пропущенных переходов на основе исторических метрик производительности. Методика реализована в виде комплекса SQL-функций и shell-скриптов в рамках проекта pg_expecto/markov_chain и позволяет восстанавливать модель в актуальное состояние без потери накопленной за время эксперимента информации. Результаты могут быть применены в системах мониторинга, прогнозирования и автоматизированного тестирования, где требуется частая смена конфигураций модели при сохранении её преемственности.
Ключевые слова: марковская цепь, резервное копирование, восстановление данных, PostgreSQL, эксперименты, прогнозирование.
1. Введение
Современные системы мониторинга и прогнозирования производительности баз данных всё чаще обращаются к вероятностным моделям, способным учитывать динамику изменения наблюдаемых параметров. Одним из перспективных подходов является использование цепей Маркова для оценки риска возникновения инцидентов производительности на основе трендов операционной скорости и времени ожиданий. В рамках проекта pg_expecto — комплекса статистического анализа производительности СУБД PostgreSQL — реализована марковская цепь, которая каждую минуту получает актуальные метрики из таблицы cluster_stat_median и обновляет своё состояние.
Однако при проведении экспериментов, особенно связанных с модификацией структуры таблиц, изменением параметров модели или тестированием различных гипотез, возникает необходимость многократного возврата к исходному состоянию модели. Традиционные средства резервного копирования, такие как полный дамп базы данных или Point‑in‑Time Recovery, фиксируют лишь статический снимок данных, но не восстанавливают «память» модели о событиях, произошедших в промежутке между созданием резервной копии и моментом восстановления. В результате после восстановления модель может оказаться в состоянии, не соответствующем реальной динамике системы, что приводит к искажению прогнозов.
Цель настоящей работы — предложить методику выборочного резервного копирования таблиц марковской цепи, которая позволяет не только восстановить данные, но и реконструировать пропущенные переходы на основе исторических метрик, обеспечивая тем самым когерентность модели. Методика реализована в открытом репозитории markov_chain и сопровождается подробной документацией.
2. Постановка задачи
Пусть имеется база данных PostgreSQL, в которой хранятся таблицы, описывающие состояние и эволюцию дискретной марковской цепи. В процессе экспериментов возможно:
Изменение структуры или содержимого этих таблиц.
Модификация параметров модели (коэффициенты забывания, пороги риска и т.п.).
Длительные перерывы в сборе данных, в течение которых реальные переходы состояния не фиксировались.
Требуется разработать инструмент, который:
выполняет выборочное резервное копирование только таблиц, относящихся к марковской цепи, без затрагивания других объектов базы данных;
при восстановлении загружает данные из резервной копии и автоматически реконструирует переходы, произошедшие в промежутке между временем создания копии и текущим моментом, на основе данных из таблиц производительности (cluster_stat_median, performance_incident);
после восстановления приводит модель в рабочее состояние: обновляет текущее состояние, пересчитывает критические состояния, вероятности и прогнозы.
3. Описание методики
Предлагаемая методика включает три основных компонента: (1) таблицу метаданных для хранения времени резервного копирования; (2) функцию вычисления состояния марковской цепи для произвольного момента времени; (3) функцию восстановления пропущенных переходов; (4) shell-скрипт, координирующий процесс резервирования и восстановления.
3.1. Таблица метаданных backup_metadata
Для фиксации времени создания каждой резервной копии вводится специальная таблица:
CREATE TABLE IF NOT EXISTS backup_metadata ( id SERIAL PRIMARY KEY, backup_time TIMESTAMPTZ NOT NULL, created_at TIMESTAMPTZ DEFAULT now() );
Данная таблица служит «якорем», позволяющим при восстановлении определить момент времени, с которого следует начинать реконструкцию переходов.
3.2. Функция get_state_at_time
Ключевым элементом методики является функция, вычисляющая состояние марковской цепи для произвольного момента времени на основе исторических метрик производительности. Она полностью повторяет логику функции get_current_os_waiting_correlation_for_markov_chain, используемой для получения текущего состояния, но принимает параметр p_timestamp.
Функция:
использует скользящее окно в 1 час для вычисления коэффициента корреляции между операционной скоростью (curr_op_speed) и временем ожиданий (curr_waitings);
вычисляет тренды операционной скорости и времени ожиданий с помощью регрессионного анализа методом наименьших квадратов;
возвращает идентификатор состояния (state_id), значение корреляции и знаки трендов.
Функция реализована без использования временных таблиц, с применением обобщённых табличных выражений (CTE), что позволяет объявить её как STABLE и избежать ошибок DDL при параллельных вызовах.
3.3. Функция fill_missing_transitions
Данная функция является центральной в методике восстановления. Она принимает два параметра: p_backup_time — время создания резервной копии, и p_restore_time — текущее время (по умолчанию now()).
Алгоритм работы функции:
Проверяет, что p_backup_time < p_restore_time.
Извлекает текущее состояние из таблицы markov_chain на момент восстановления.
В цикле перебирает каждую минуту в диапазоне от p_backup_time до p_restore_time (шаг — 1 минута, что соответствует периодичности реального обучения).
Для каждой минуты вызывает get_state_at_time и получает состояние системы в данный момент.
При изменении состояния фиксирует переход в таблицы transition_log и markov_frequencies.
По завершении цикла обновляет таблицу markov_chain, устанавливая последнее вычисленное состояние.
При наличии инцидентов в пропущенном периоде обновляет last_incident_time в таблице markov_config.
Пересчитывает матрицу вероятностей (update_markov_probabilities) и поглощающую матрицу (rebuild_markov_absorbing).
Возвращает текстовый отчёт с количеством вставленных переходов и информацией об обновлении инцидентов.
Важной особенностью функции является то, что она не требует наличия архивов WAL или дополнительных журналов — вся необходимая информация извлекается из исторических данных мониторинга, что делает методику самодостаточной.
Скрипт координирует процесс резервирования и восстановления. Параметры подключения к базе данных (имя базы expecto_db, пользователь expecto_user, хост localhost, порт 5432) жёстко зафиксированы в скрипте. Аутентификация осуществляется через переменную окружения PGPASSWORD или файл .pgpass.
Действие backup:
Проверяет/создаёт таблицу backup_metadata.
Создаёт выборочный дамп только перечисленных таблиц с помощью pg_dump -Fc -t ....
Сохраняет время создания копии в backup_metadata.
Действие restore:
Находит самый свежий файл резервной копии в каталоге /tmp.
Запрашивает подтверждение пользователя.
Выполняет восстановление таблиц из дампа с очисткой (pg_restore --clean --if-exists).
Последовательно выполняет пост-восстановительные шаги: mchain_train_step() — обновление текущего состояния; fill_missing_transitions() — восстановление пропущенных переходов; refresh_critical_states() — пересчёт критических состояний за последние 14 дней; update_markov_probabilities() и rebuild_markov_absorbing() — перестроение матриц; mchain_predict_risk_current_horizon() — проверка прогноза.
Все шаги сопровождаются подробным логированием в консоль.
3.5. Состав резервируемых таблиц
Скрипт сохраняет и восстанавливает только следующие таблицы (все остальные объекты базы данных не затрагиваются):
forgetting_optimization_log — журнал экспериментов по забыванию;
backup_metadata — вспомогательная таблица для хранения времени резервного копирования.
4. Экспериментальные результаты
Методика была апробирована в рамках проекта pg_expecto/markov_chain. Ниже приведены типичные сценарии использования.
4.1. Создание резервной копии
$ ./markov_chain_backup.sh backup ▶️ Создание выборочного бекапа таблиц цепи Маркова в /tmp/markov_chain_tables_20250625_120000.dump... ✅ Бекап создан: /tmp/markov_chain_tables_20250625_120000.dump ➜ Сохранение времени бекапа INSERT 0 1
Время создания копии автоматически сохраняется в таблицу backup_metadata.
4.2. Восстановление с реконструкцией переходов
$ ./markov_chain_backup.sh restore ▶️ Восстановление таблиц цепи Маркова из /tmp/markov_chain_tables_20250625_120000.dump... ВНИМАНИЕ: все таблицы цепи Маркова в базе expecto_db будут заменены данными из бекапа! Продолжить? [y/N]: y ✅ Восстановление таблиц завершено. ▶️ Выполнение пост-восстановительных операций... ➜ Обновление текущего состояния (mchain_train_step) Step completed Время бекапа: 2026-06-25 12:00:00+03 ➜ Восстановление переходов за пропущенный период Восстановлено 47 переходов за период 2026-06-25 12:00:00+03 – 2026-06-25 16:30:00+03. Инциденты: обновлён last_incident_time ➜ Обновление критических состояний (refresh_critical_states) ... ➜ Пересчёт вероятностей ... ➜ Пересчёт поглощающей матрицы ... ➜ Проверка прогноза (должен вернуть число от 0 до 1) 0.045 ✅ Все пост-восстановительные операции успешно выполнены. Цепь Маркова готова к работе.
В приведённом примере за период в 4,5 часа было восстановлено 47 переходов, что позволило модели «догнать» актуальное состояние системы.
5. Обсуждение
5.1. Достоинства методики
Выборочность — резервируются только таблицы, относящиеся к модели, что минимизирует объём данных и время операций.
Самодостаточность — для реконструкции пропущенных переходов не требуются дополнительные журналы или архивы WAL; используется уже существующая историческая информация из таблиц производительности.
Когерентность модели — восстановление не ограничивается загрузкой данных, но включает полный цикл пересчёта состояний, вероятностей и прогнозов, что гарантирует готовность модели к работе.
Прозрачность — все этапы логируются, пользователь получает детальный отчёт о выполненной работе.
5.2. Ограничения
Точность восстановления зависит от качества и полноты данных в cluster_stat_median. Если в пропущенном периоде отсутствуют записи за какие-то минуты, состояние вычисляется по доступным данным, что может привести к неточностям.
Забывание за пропущенный период не воспроизводится. Это допустимо, так как после восстановления частоты оказываются несколько завышенными, но следующий плановый вызов механизма забывания скорректирует их.
Производительность — для периодов более нескольких дней цикл по минутам может выполняться медленно. В таких случаях рекомендуется оптимизировать функцию fill_missing_transitions (например, использовать пакетную вставку) или сократить период восстановления.
5.3. Применимость для других проектов
Хотя методика разработана для конкретной модели марковской цепи в контексте мониторинга PostgreSQL, её архитектурные принципы могут быть перенесены на широкий класс систем, где:
состояние модели непрерывно эволюционирует во времени;
существуют исторические данные, позволяющие реконструировать это состояние для произвольного момента в прошлом;
требуется частое переключение между экспериментальными конфигурациями при сохранении преемственности модели.
Для адаптации методики к другому проекту необходимо:
Определить набор таблиц, подлежащих резервированию.
Реализовать функцию вычисления состояния по произвольной временной метке, аналогичную get_state_at_time.
Адаптировать функцию восполнения переходов с учётом специфики предметной области и требуемой дискретности времени.
6. Заключение
В работе представлена методика резервного копирования и восстановления таблиц марковской цепи, позволяющая сохранять когерентность модели при проведении экспериментов. Ключевая особенность методики — реконструкция пропущенных переходов на основе исторических метрик производительности, что обеспечивает непрерывность модели даже при длительных перерывах в сборе данных или многократных возвратах к исходному состоянию.
Методика реализована в виде открытого инструментария, доступного в репозитории github.com/pg-expecto/markov_chain, и сопровождается документацией markov_chain_backup.md. Предложенный подход может быть полезен не только для систем мониторинга производительности, но и для любых других приложений, использующих вероятностные модели с дискретным временем и требующих частой смены конфигураций в экспериментальных целях.
Ссылки на использованные материалы:
pg_expecto/markov_chain — репозиторий с реализацией марковской цепи для прогнозирования инцидентов производительности PostgreSQL
markov_chain_backup.md— документация по резервному копированию и восстановлению цепи Маркова
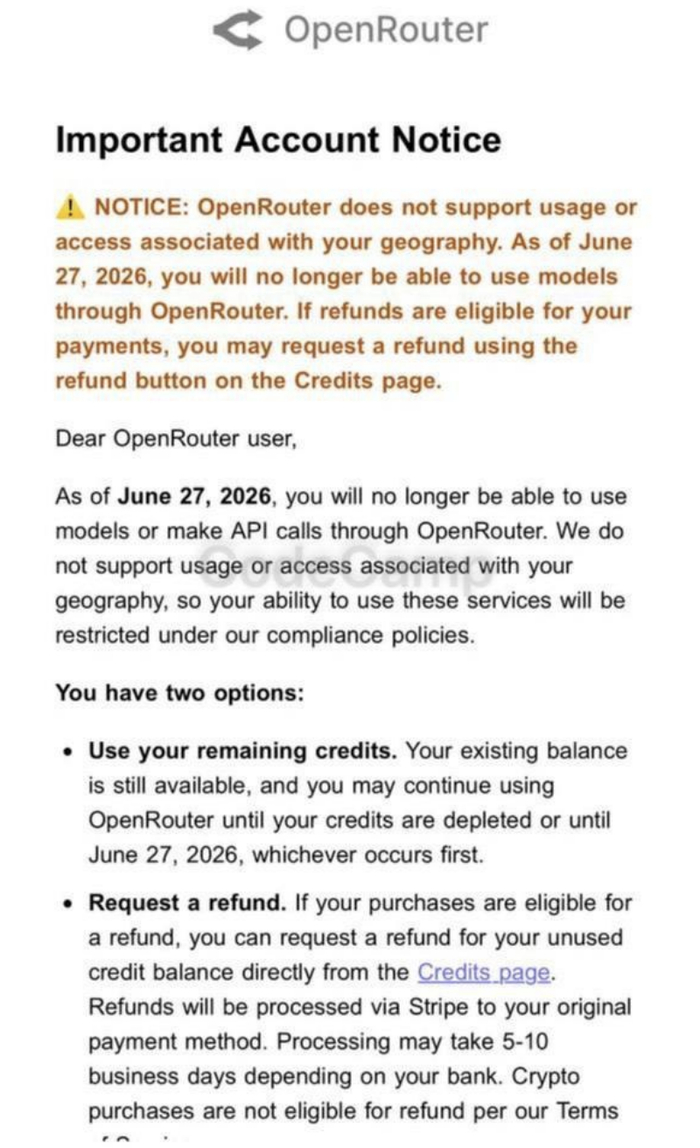
Пользователи из России начали получать уведомления от OpenRouter о скором отключении доступа
С 27 июня 2026 года сервис больше не позволит отправлять запросы к моделям и пользоваться API из российского региона.
Если коротко, это очень неприятная новость для всех, у кого на OpenRouter были завязаны рабочие тексты, боты, тесты и другие AI-процессы. Когда отрубается один удобный шлюз, ломается не только доступ к моделям, но и целая куча привычных сценариев.
Что пишет OpenRouter
В письме прямо говорится, что сервис больше не поддерживает использование платформы из некоторых регионов. До 27 июня ещё можно либо потратить оставшийся баланс, либо запросить возврат неиспользованных средств.
Если на аккаунте лежат деньги, с этим лучше не тянуть. По уведомлению возвраты оформляются через страницу Credits и могут идти несколько рабочих дней.
Почему это болезненно
Для обычного пользователя это просто неприятное ограничение. Для тех, кто строил на OpenRouter рабочие процессы, это уже поломка инфраструктуры: падают API-запросы, скрипты, чат-боты, тестовые интеграции и быстрые прототипы.
Самое обидное в таких историях — даже не сам запрет, а необходимость срочно перестраивать всё, что уже было настроено и работало. Вчера у тебя был один удобный вход, а сегодня надо заново собирать цепочку из разных решений.
Что делать сейчас
Проверить остаток баланса.
Использовать кредиты до 27 июня, если это ещё возможно.
Подать запрос на возврат, если платёж подходит под условия.
Пересмотреть все сервисы, ботов и скрипты, завязанные на OpenRouter.
Заранее подготовить запасной вариант для работы с моделями.
Вопрос - какие есть альтернативы?
Замену Open Router для API - я пока не нашел. Но мне также нужна именно текстовая работа на Claude и DeepSeek в формате отдельных чатов, не обязательно через агрегатор - чем удобно пользоваться?