"Демобаза 2.0" нагрузочное тестирование : СУБД оказалась устойчива к выбору между Join и коррелированным подзапросом
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).
СУБД оказалась прочнее, чем кажется: почему выбор запроса может не иметь значения для общей производительности системы.
ℹ️ Новый инструмент с открытым исходным кодом для статистического анализа, нагрузочного тестирования и построения отчетов доступен в репозитории GitFlic и GitHub
Предисловие:
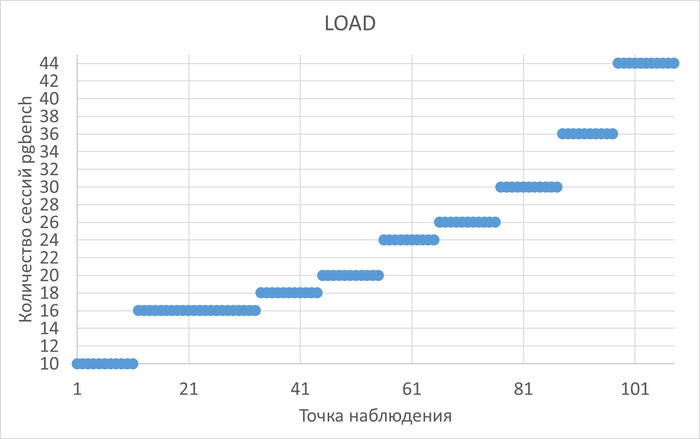
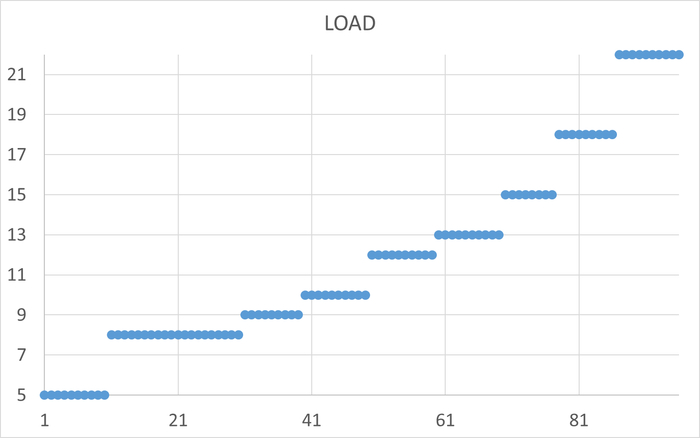
Принято считать, что выбор между JOIN и коррелированным подзапросом — одна из ключевых задач оптимизации, способная кардинально повлиять на нагрузку базы данных. В качестве эксперимента, было проведено нагрузочное тестирование, используя Демобазу 2.0 в качестве полигона и vmstat для мониторинга изменений со стороны инфраструктуры, готовясь наглядно продемонстрировать превосходство одного подхода над другим.
Однако результаты оказались неожиданными. Исследование показало практическое отсутствие существенного влияния выбранной структуры запроса на общую производительность СУБД и сервера. В данной статье показано, что в контексте современной оптимизации запросов и мощного аппаратного обеспечения, "страшилка" о катастрофических последствиях использования коррелированных подзапросов часто преувеличена. Нагрузочное тестирование выявило, что СУБД успешно справляется с обоими типами запросов, а реальное влияние на метрики vmstat оказалось малым, что позволяет разработчикам в подобных случаях делать выбор, основываясь на читаемости кода, а не на гипотетических рисках для производительности.
Демобаза 2.0
Тестовая виртуальная машина
CPU = 8
RAM = 8GB
PostgreSQL 17
Тестовый сценарий-4.1 (JOIN)
-- Запросы с JOIN
CREATE OR REPLACE FUNCTION scenario5() RETURNS integer AS $$
DECLARE
test_rec record ;
BEGIN
SET application_name = 'scenario4';
WITH seats_available AS
( SELECT airplane_code, fare_conditions, count( * ) AS seats_cnt
FROM bookings.seats
GROUP BY airplane_code, fare_conditions
), seats_booked AS
( SELECT flight_id, fare_conditions, count( * ) AS seats_cnt
FROM bookings.segments
GROUP BY flight_id, fare_conditions
), overbook AS (
SELECT f.flight_id, r.route_no, r.airplane_code, sb.fare_conditions,
sb.seats_cnt AS seats_booked,
sa.seats_cnt AS seats_available
FROM bookings.flights AS f
JOIN bookings.routes AS r ON r.route_no = f.route_no AND r.validity @> f.scheduled_departure
JOIN seats_booked AS sb ON sb.flight_id = f.flight_id
JOIN seats_available AS sa ON sa.airplane_code = r.airplane_code
AND sa.fare_conditions = sb.fare_conditions
WHERE sb.seats_cnt > sa.seats_cnt
)
SELECT count(*) overbookings,
CASE WHEN count(*) > 0 THEN 'ERROR: overbooking' ELSE 'Ok' END verdict
INTO test_rec
FROM overbook;
return 0 ;
END
$$ LANGUAGE plpgsql;
Тестовый сценарий-4.2 (Коррелированный подзапрос)
Создание индексов
demo=# CREATE INDEX CONCURRENTLY idx_seats_airplane_fare ON bookings.seats(airplane_code, fare_conditions);
CREATE INDEX
demo=# CREATE INDEX CONCURRENTLY idx_segments_flight_fare ON bookings.segments(flight_id, fare_conditions);
CREATE INDEX
demo=# CREATE INDEX CONCURRENTLY idx_routes_no_validity ON bookings.routes(route_no, validity);
CREATE INDEX
Изменение SQL запроса
-- коррелированный подзапрос
CREATE OR REPLACE FUNCTION scenario5() RETURNS integer AS $$
DECLARE
test_rec record ;
BEGIN
SET application_name = 'scenario4';
WITH seats_agg AS MATERIALIZED (
SELECT
airplane_code,
fare_conditions,
COUNT(*) AS seats_total
FROM bookings.seats
GROUP BY airplane_code, fare_conditions
)
SELECT
COUNT(*) AS overbookings,
CASE WHEN COUNT(*) > 0 THEN 'ERROR: overbooking' ELSE 'Ok' END AS verdict
INTO test_rec
FROM (
SELECT 1
FROM bookings.flights f
JOIN bookings.routes r ON r.route_no = f.route_no AND r.validity @> f.scheduled_departure
JOIN (
SELECT
flight_id,
fare_conditions,
COUNT(*) AS seats_booked
FROM bookings.segments
GROUP BY flight_id, fare_conditions
) sb ON sb.flight_id = f.flight_id
WHERE sb.seats_booked > (
SELECT sa.seats_total
FROM seats_agg sa
WHERE sa.airplane_code = r.airplane_code
AND sa.fare_conditions = sb.fare_conditions
)
) overbooked;
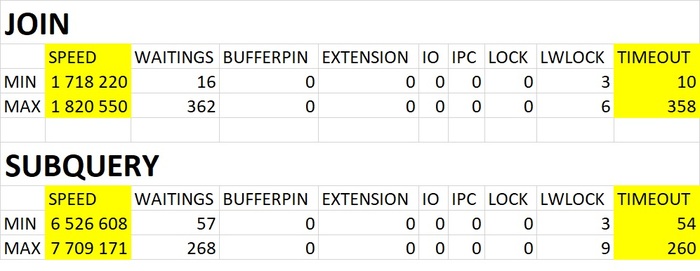
Анализ результатов нагрузочного тестирования - производительность СУБД
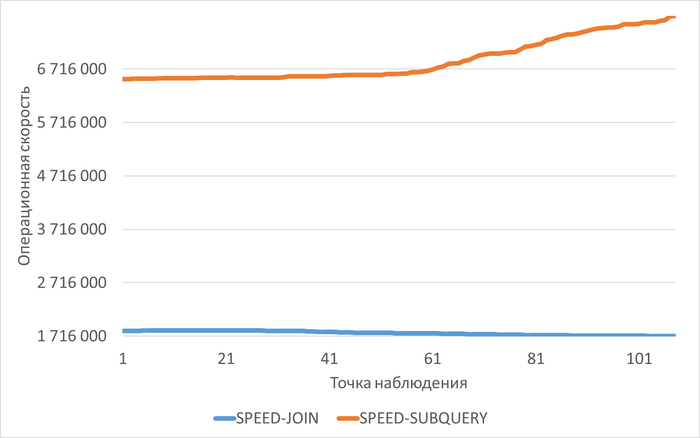
Операционная скорость СУБД
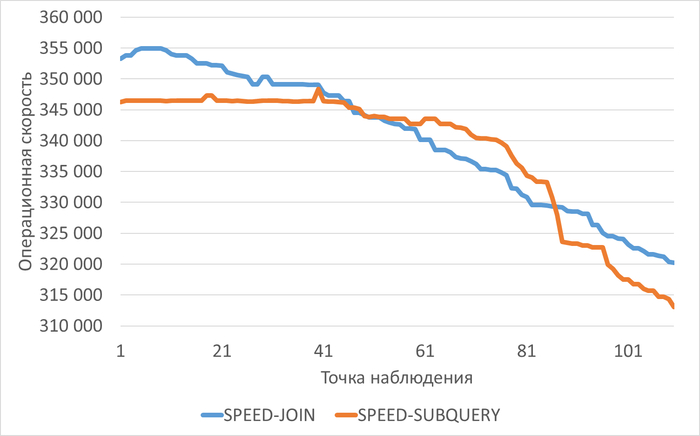
График изменения операционной скорости СУБД для нагрузочного тестирования с использованием Join и Коррелированного подзапроса.
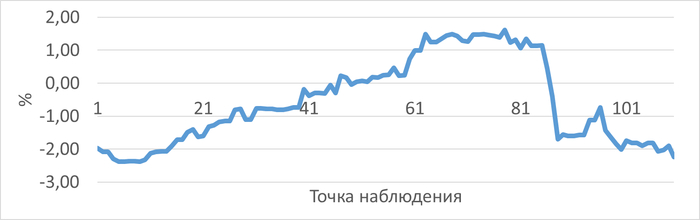
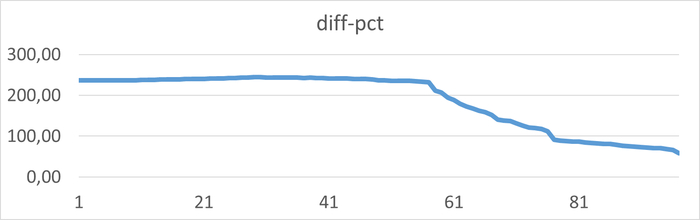
График изменения относительной разницы операционной скорости для нагрузочного тестирования с использованием коррелированного подзапроса по сравнению с использованием JOIN.
Средняя разница операционной скорости СУБД при использовании JOIN и Коррелированного подзапроса составила 0.58%.
Вывод по результатам анализа метрик производительности СУБД
Использование для тестового запроса JOIN или Коррелированного подзапроса - не оказывает влияния на производительность СУБД в целом и тестового сценария в частности.