


Немного истории
47 постов
47 постов
10 постов
180 постов

4 поста

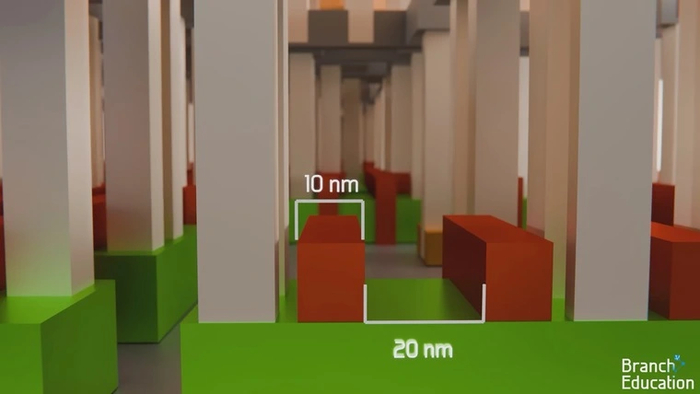
Выбор рисунка зависит от типа маски-трафарета. Там, где соединения идут преимущественно горизонтально, лучшим образом подходит одна схема освещения. Там, где вертикально — вторая, а для круглых межслойных соединений — третья.

Здесь вновь можно вспомнить аналогию с тонкой ручкой. Например, чтобы рисовать точечные межслойные соединения, свет от «ручки» должен быть направлен строго вниз. А для создания прямых непрерывных линий нужно наклонить ее под углом.

Теперь посмотрим, как происходит работа с фотомаской — шаблоном-трафаретом одного слоя будущих чипов.
С помощью подвесной транспортной системы маска в условиях вакуума загружается в EUV-машину. Там первым делом сверяется ее штрих-код и происходит проверка на дефекты. Пройдя ее, положение маски выравнивается по специальным меткам на краях с точностью до нанометра.

Проверенная маска закрепляется на столике визирной сетки. В процессе работы машины он движется вдоль лучей EUV-света на очень высокой скорости, линия за линией проецируя рисунок с маски на кремниевую пластину.

Поверхность маски напоминает уже описанный нами многослойный отражатель Брэгга. Но в местах, где рисунок отсутствует, используется светопоглощающий материал. Размер точки этого материала очень мал — примерно 10х10 нм. Габариты самой маски составляют 104х132 мм, поэтому разрешение ее рисунка получается очень высоким.

С помощью системы зеркал рисунок от маски масштабируется, попадая на кремниевую пластину в уменьшенном виде. Каждая маска может содержать от одного до нескольких шаблонов будущих чипов — это зависит от их размера. Например, на ней поместится один крупный графический процессор, два менее габаритных центральных процессора, или сразу 12 чипов оперативной памяти.

В соответствии с размерами чипов меняется и их общее количество, умещающееся на одной пластине. Крупных графических процессоров получится 90, центральных процессоров — 185, а чипов памяти — почти 1000.

Маска для будущих чипов не должна иметь ни малейшего дефекта. Если вспомнить нашу аналогию с библиотекой, то ни в одной ее книге среди 21 миллионов страниц текста не должно ни грамматической ошибки, ни даже лишнего изгиба буквы — иначе это повредит каждую заготовку чипа на пластине.

Настала очередь рассмотреть работу с кремниевыми пластинами. В контейнере FOUP они транспортируются на литографический кластер, состоящий из трекового инструмента и EUV-машины.

В условиях вакуума пластина перемещается из контейнера в трековый инструмент. В первой его области наносится слой фоторезиста, а затем происходит перемещение во вторую область — там, где резист нагревается и высушивается.

С помощью роботизированного манипулятора через вакуумный шлюз пластина переносится в EUV-машину.

Данная система получила название TwinScan. Она позволяет за раз транспортировать две пластины: пока одна обрабатывается, вторую за это время можно загрузить на столик и выровнять с точностью до нанометра.
Чтобы убедиться, что формируемый слой идеально совмещен с предыдущим, пластина тщательно проверяется с помощью меток совмещения и датчиков выравнивания. На основе этой информации создается высокоточная двухмерная карта смещений.

Затем датчики выравнивания используют отраженный свет для измерения высоты по всей поверхности пластины. Таким образом, формируется еще и топологическая карта пластины, позволяющая идеально сфокусировать на ней EUV-лучи.
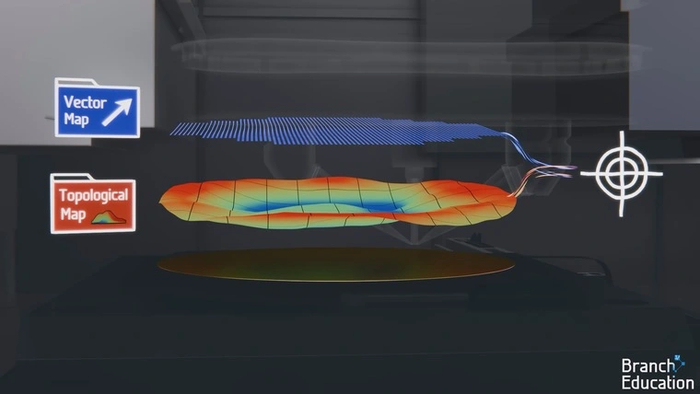
Подобная точность — важная составляющая производственного процесса. Размеры самых маленьких элементов транзисторов составляют менее 10 нм, поэтому даже погрешность в пару нанометров может привести к нарушению их электрических соединений со следующим слоем.
Когда чипы будут готовы, пластина будет разрезана по их размерам. Поэтому между рисунками на пластине должны оставаться небольшие промежутки. Когда нанесение одной копии рисунка закончено, затвор столика визирной сетки временно перекрывается — до тех пор, пока столик с пластиной не сдвинется и не примет положение для печати следующей заготовки.

Напоследок расскажем, как устроен фоторезист. Он представляет собой синтетическую смолу, смешанную с фоточувствительным органическим красителем — сенсибилизатором. Когда фотоны EUV-света попадают на смолу, высвобождаются электроны с высокой энергией. Под их воздействием сенсибилизатор превращается в кислоту, делающую структуру смолы слабее.

В результате на областях, подвергшихся EUV-излучению, резист легко становится легко смываемым с помощью проявляющей жидкости.

Важно то, что резист не разрушается кусками: ослабевает лишь та его часть, в которую непосредственно проникли лучи света. Это позволяет создавать элементы транзисторов и их соединений с четкими контурами.


Далее пластина вновь перемещается в трековый инструмент. Здесь модифицированный резист смывается с ее поверхности с помощью растворителя, а для затвердевания оставшегося резиста еще раз применяются нагрев и высушивание.

После формирования рисунка пластина отправляется в другие машины. Области без затвердевшего резиста подвергаются травлению, и на них распыляются различные химические вещества — одни заполняют собой образовавшиеся канавки, а другие образуют основу для следующего слоя.

Данный процесс повторяется несколько раз, пока поверх первого слоя не образуется множество дополнительных слоев соединений. Именно через них транзисторы чипов будут «общаться» друг с другом. Толщина этих соединительных проводов зависит от высоты слоя: внизу с транзисторами контактируют самые тонкие, а наверху располагаются самые крупные.

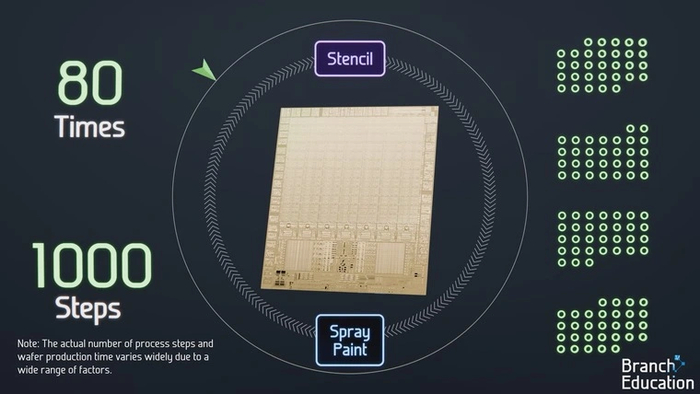
Циклы построения слоев повторяются десятки раз, а количество их отдельных этапов приближается к тысяче. Поэтому общее время, необходимо для создания одной пластины с чипами, достигает четырех месяцев.
Транзисторный слой современных чипов формируется с помощью машин EUV (Extreme UltraViolet), которые работают с экстремально короткими ультрафиолетовыми волнами длиной всего 13 нм.

Верхние соединения чаще всего создаются с помощью машин DUV (Deep Ultra Violet), которые работают с более длинными ультрафиолетовыми волнами — обычно от 193 до 365 нм.

Машины DUV появились еще в 2000-х годах и обходятся намного дешевле, чем более передовые EUV. Поэтому некоторые простые чипы, для которых не требуются тонкие техпроцессы производства, до сих пор производятся только их силами.
Давайте заглянем внутрь EUV-машины. Она состоит из пяти основных компонентов: источника света (Source), осветителя (Illuminator), манипулятора и столика визирной сетки (Reticle Handler/Stage), проекционной оптики (Projection Optics), а также манипулятора и столика пластин (Wafer Handler/Stage).

Ключевой компонент — это источник экстремального ультрафиолетового света (EUV). Почему используется именно такой свет, и что он дает?
Представьте, что вы переносите буквы с трафарета на бумагу с помощью толстого маркера. Если закрашивать крупные буквы, они будут выглядеть четко. Но стоит закрасить несколько мелких букв рядом, и краска расплывется, не давая их прочитать. А вот если повторить тот же процесс с помощью тонкой ручки, то даже мелкие буквы перенесутся четко и будут читаемыми.

EUV-свет с длиной 13 нм — это та самая тонкая ручка, которая позволяет копировать рисунки с линиями толщиной около 10 нм.

Если использовать свет с большой длиной волны, то он не сможет проникнуть в микроскопические отверстия нашей маски-трафарета, и узор ее рисунка потеряется.

В отличие от него, экстремально короткие ультрафиолетовые волны беспрепятственно проходят через маску, четко перенося на пластину все детали и контуры.

Ультрафиолетовое излучение такой длины не встречается в природных источниках света, поэтому создается искусственно. Для этого используется сложная система из двух лазеров и нескольких усилителей, которые установлены под EUV-машиной.

С помощью зеркал импульсы лазера проходят в контейнер-источник, где на их пути распыляются микроскопические шарики из олова. Первый импульс мощностью в 5 кВт превращает олово в жидкую каплю. Второй импульс имеет мощность в 25 кВт — при взаимодействии с ним капля испаряется, переходя в состояние раскаленной плазмы. В процессе этого происходит выброс электронов, благодаря которому и возникает EUV-свет.

Олово для этой операции хранится в специальной емкости и поддерживается в расплавленном состоянии. С помощью системы шлангов оно попадает в пьезоэлектрический распылитель, который за счет высокого давления азота внутри своего резервуара обеспечивает подачу тонкой и равномерной струи.

Когда капля олова попадает в рабочую область контейнера, ее траекторию отслеживает несколько высокоскоростных камер. Эта информация передается приводам зеркал, цель которых сдвинуть отраженный лазерный луч так, чтобы он попал точно в каплю.

Для генерации EUV-света нужной интенсивности выстрелы по каплям совершаются около 50 тысяч раз в секунду. Чтобы поддерживать равномерный темп излучения, система может пропускать некоторые капли мимо лазера — они попадают в специальный отвод.

Излученный свет собирается в пучок с помощью первого зеркала, называемого коллектором. Он направляется в промежуточный фокус — микроскопическое отверстие, которое пропускает только EUV-лучи и отсеивает более длинные.
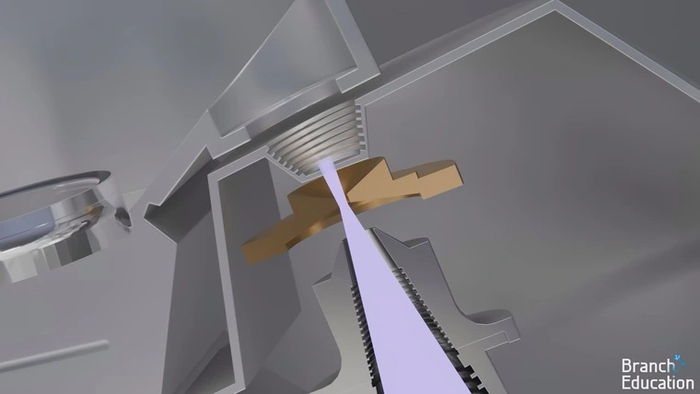
Затем луч EUV-света попадает в осветитель — систему из нескольких фацетных зеркал, которые рассеивают его на более широкий пучок из множества линий.

Пучок света проецируется на маску, а прошедшие через нее лучи с помощью еще одного массива зеркал отправляются в конечную цель путешествия — на поверхность кремниевой пластины.

Экстремально глубокий ультрафиолет отличается от видимого света многими свойствами. Например, он сразу поглощается молекулами воздуха, поэтому внутри его пути в EUV-машине всегда соблюдается вакуум.

Более того, EUV поглощается стеклом и почти всеми прочими материалами. Поэтому для фокусировки и передачи такого света используются зеркала, а не линзы. Но и обычные зеркала для этой цели тоже не подходят. В EUV-машине используются специальные зеркала, называемые отражателями Брэгга. Они состоят из десятков чередующихся слоев кремния и молибдена, каждый из которых имеет толщину всего в несколько нанометров. Когда EUV-луч попадает на поверхность такого отражателя, то только 3 % отражается от одного слоя, а оставшийся свет проходит насквозь. Благодаря множеству слоев луч отражается от каждого, поэтому в сумме одно зеркало способно перенаправить чуть более 70 % попавшего на него света.

В оптической системе EUV-машины более десяти зеркал, поэтому часть исходного потока света теряется после каждого переотражения. В результате до кремниевой пластины доходит менее 10 % от его изначальной яркости. Именно поэтому первоначальный свет от источника должен быть максимально ярким.

Другой особенностью работы с EUV-лучами являются фацетные зеркала. Они состоят из множества сегментов, наклон каждого из которых управляется независимо с помощью системы с миниатюрным электроприводом.

За счет этого можно создавать из точечного EUV-света сложные рисунки освещения.
В виду ограничения фотоматериалов
ПРОДОЛЖЕНИЕ СЛЕДУЕТ...

В основе любой электроники, которой мы пользуемся ежедневно, лежат микрочипы из миллиардов транзисторов. Их существование стало возможным благодаря фотолитографии — сложному процессу, позволяющему наносить огромное количество логических элементов на миниатюрные кремниевые пластины. Как работает современное фотолитографическое производство, и как оно устроено внутри?
ПК, ноутбуки, смартфоны, планшеты, громоздкие автомобили и миниатюрные смарт-часы. Внутри этих устройств скрывается несколько разновидностей современных микрочипов: центральные и графические процессоры, системы на чипе (SoC), а также чипы оперативной (DRAM) и флеш-памяти (NAND).

Каждый из таких чипов состоит из миллиардов миниатюрных транзисторов, соединенных вместе несколькими слоями токопроводящих дорожек.

Самые мелкие элементы подобных транзисторов имеют размер около 10 нм — это всего 45 атомов кремния.
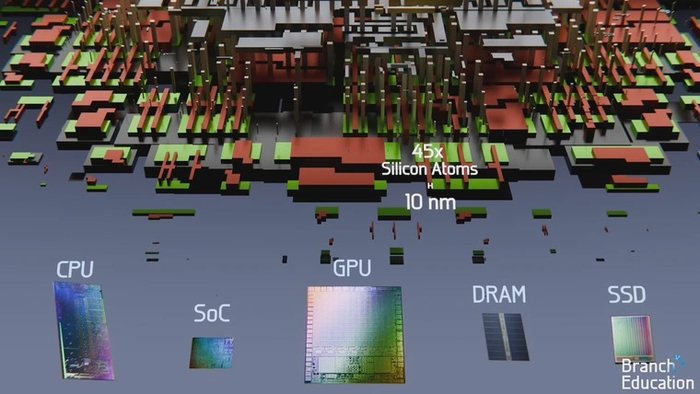
Чтобы производить такие сложные чипы, используется сложная последовательность фотолитографических процессов. Каждый из них состоит из нескольких этапов, которыми занимается специализированная машина-установка.

Принцип фотолитографии можно сравнить с копировальным аппаратом. С ее помощью на кремниевую подложку переносятся микроскопические рисунки элементов транзисторов и слоев соединяющих их дорожек.

Инструменты для фотолитографии постоянно совершенствуются, позволяя копировать все более мелкие элементы. Тут можно привести сравнение с печатью текста: чем тоньше и прогрессивнее технологический процесс, тем меньшим шрифтом можно напечатать буквы (то есть — транзисторы чипа).

Ключевыми установками для производства современных микрочипов являются машины, работающие с экстремально глубоким ультрафиолетовым светом — EUV (Extreme UltraViolet).
Начнем обзор с принципа работы EUV-машины. Первым делом в нее помещается фотомаска — трафарет транзисторного слоя будущего чипа.

Затем в машину загружается предварительно обработанная круглая пластина из кремния диаметром 300 мм.

С помощью источника ультрафиолетового света и системы зеркал шаблон с маски переносится на небольшой кусочек пластины. После этого пластина сдвигается, и процесс повторяется снова и снова — до тех пор, пока она полностью не заполнится «рисунками» транзисторного слоя будущих микрочипов.

На обработку одной пластины EUV-машина тратит около 18 секунд — за это время шаблон переносится около сотни раз. Затем подается следующая пластина, и весь процесс повторяется снова. После окончания процедуры заготовка отправляется в другую разновидность фотолитографической машины, где поверх транзисторов аналогичным образом формируются несколько слоев их соединений. Если заглянуть внутрь готового чипа, можно будет увидеть вот такой лабиринт из них.

Здесь можно привести аналогию с книгой. Слои соединений — это страницы с буквами среднего размера, а транзисторный слой — страница с самыми мелкими. Поэтому для «печати» соединений в ряде случаев может использоваться более простая фотолитография в глубоком ультрафиолете (DUV — Deep Ultra Violet).
Насколько мелки элементы транзисторного слоя? Представьте, что толщина штриха каждой буквы составляет 13 нм. Тогда слово «cat» будет иметь размер в 240х155 нм.

Страница подобного текста будет иметь размер эритроцита. А одна глава книги займет область, схожую по размерам с пылинкой.

С таким шрифтом на площади графического процессора топовой видеокарты уместятся семь книг о Гарри Поттере, все творчество Стивена Кинга, весь текст английской Википедии, а также все книги из крупной городской библиотеки. Система фотолитографии копирует подобный рисунок с «текстом» из транзисторов очень быстро — менее, чем за одну секунду.
Рассмотрев принцип формирования микрочипов, совершим виртуальную экскурсию на их производство. Кремниевые пластины попадают сюда сложенными в специальные контейнеры FOUP.

В процессе производства чипов эти контейнеры переносятся от машины к машине с помощью автоматизированной подвесной транспортной системы.

Прибыв к нужной машине, контейнер опускается. Пластины поочередно выгружаются из него для той или иной обработки — нанесения, засвечивания или удаления материала.

После завершения одного процесса пластины вновь попадают в FOUP и переносятся к следующей машине. Так продолжается до тех пор, пока не будут «выстроены» все слои будущих чипов.

Шаги этого процесса можно сравнить с распылением краски на бумагу через трафарет: она остается там, где в трафарете присутствуют отверстия, и не попадает туда, где этих отверстий нет.

А после распыления нескольких слоев краски разных цветов получается итоговое цветное изображение.

В нашем случае вместо слоев рисунка на масках-трафаретах находятся схемы слоев транзисторов и соединяющих их дорожек, которые вместо бумаги переносятся на пластину из кремния.

В этом процессе участвуют разные типы установок. Одни осаждают материалы на кремний или смывают их с него (Spray Paint) — подобно тому, как распыляется или смывается краска. А EUV- и DUV-машины выполняют роль трафаретной печати (Stencil), благодаря которой перед нанесением краски на пластины переносятся контуры нужного рисунка.

Перейдем к тому, как создаются слои чипа. Сначала кремниевая пластина поступает в установку, называемую трековым инструментом. Здесь на нее добавляется светочувствительный материал — фоторезист, который равномерно распределяется по поверхности пластины за счет вращения центрифуги.

Чтобы резист затвердел, пластина нагревается и высушивается.

По окончанию процедуры пластина переходит в EUV-машину. Здесь ультрафиолетовый свет пропускается через маску-трафарет, а затем с помощью системы зеркал уменьшается и проецируется на малую область пластины.

На всех участках, где свет попал на пластину, резист под действием ультрафиолета модифицируется — таким образом, рисунок маски «отпечатывается» на ее поверхности. Затем пластина сдвигается, и процесс повторяется сотни раз до ее полного заполнения этими отпечатками.
В виду ограничения фотоматериалов
ПРОДОЛЖЕНИЕ СЛЕДУЕТ...
После этого выполняются расчеты для обнаружения пересечения луча и полигонов — вместо миллиардов операций при обычном подходе здесь их требуется всего шесть.

Несмотря на все ухищрения, для быстрых расчетов трассировки все также требуется мощное вычислительное оборудование. Поэтому видеокарты, поддерживающие ее, оснащаются тысячами шейдерных процессоров и специализированными вычислительными блоками — RT-ядрами.

Шейдерные процессоры выполняют арифметические операции, в то время как RT-ядра разработаны и оптимизированы именно для операций трассировки лучей.

Внутри RT-ядер находится два вычислительных движка. Первым начинает работу движок, занимающийся поиском пересечений лучей с объемами-коробками BVH.
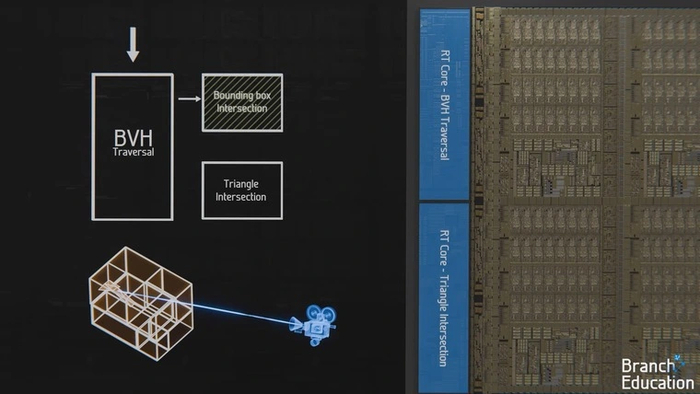
Когда находится самая маленькая коробочка, пересекающая луч, в дело вступает второй движок. Он ищет пересечения лучей с полигонами.
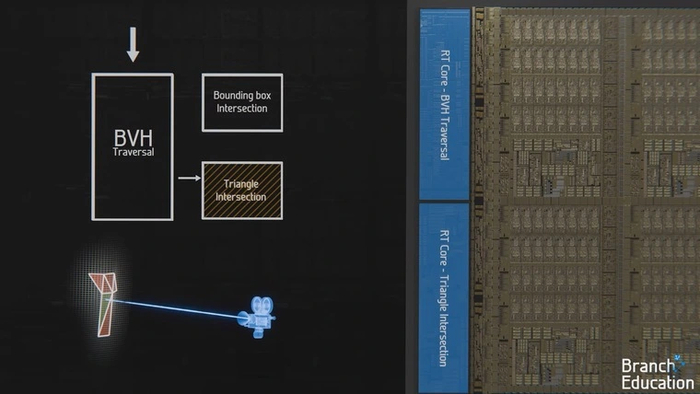
Как и шейдерные процессоры, RT-ядра работают параллельно друг с другом. На современных видеокартах это позволяет обрабатывать несколько миллиардов лучей в секунду, а общий счет выполненных операций при этом достигает триллионов. Например, NVIDIA GeForce RTX 3090 родом из 2022 года выполняет за одну секунду до 36 триллионов операций. Тогда как самый мощный суперкомпьютер 2000 года, полагающийся на грубую вычислительную мощность центральных процессоров, за то же время осуществлял лишь 12,3 триллиона.

Трассировка пути — наиболее продвинутый способ получения компьютерных изображений. Но из-за ее высоких требований в играх пока более распространена обычная трассировка лучей. Оба способа имеют схожую основу, но трассировка лучей обеспечивает меньшую реалистичность освещения взамен на гораздо более скромные требования к оборудованию.
Для реализации трассировки лучей существует несколько техник. Рассмотрим две самые распространенные. Первый вариант схож с трассировкой пути, но имеет некоторые упрощения. Сначала для моделей сцены создаются дубликаты низкого разрешения с малым количеством полигонов.

Кадр с этими моделями просчитывается вне экрана, чтобы получить карту освещенности поверхностей. А затем полученная карта накладывается на кадр высокого разрешения, выводимый на экран.
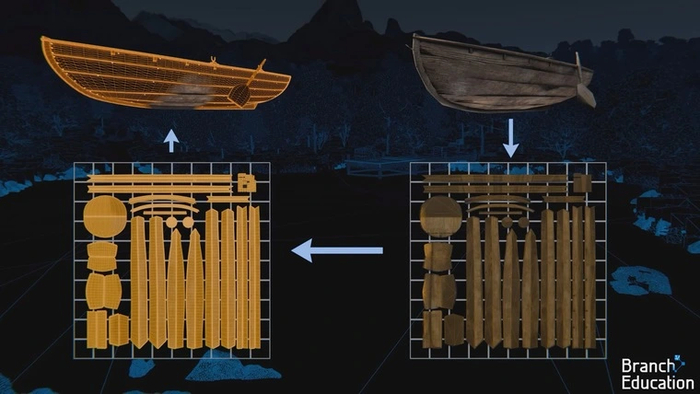
Это позволяет хорошо интерполировать непрямое освещение, не прибегая к огромному количеству вычислений. Данный способ является одним из методов трассировки, который используется системой освещения Lumen в графическом движке Unreal Engine 5. Второй вариант техники называется трассировкой лучей в экранном пространстве. Тут используется совершенно другой подход на основе трех составляющих: изображения, полученного с помощью традиционного рендеринга, карты глубины кадра и карты нормалей. Из отрендеренного изображения берется информация о цвете объектов. Карта глубины показывает, насколько далеко они находятся от камеры.

В свою очередь, карта нормалей сообщает, в какую сторону полигоны отражают свет.

Когда в процессе трассировки луч попадает на отражающую поверхность, его дальнейшее распространение продолжается в соответствии с этой информацией. Например, попав в озеро, лучи отразились в сторону деревьев — значит на поверхности озера появится искаженное изображение последних.

Главная проблема подобного подхода в том, что он может использовать только отрендеренные кадры с экрана. То есть, когда деревья исчезнут из поля зрения игрока, пропадет и их отражение в озере. Такую технику трассировки лучей используют многие игры прошлых лет, в том числе — Cyberpunk 2077.

Трассировка пути — продвинутая технология построения изображений в компьютерной графике. Она широко применяется для создания реалистичных сцен в фильмах, и все больше становится популярной в новых играх для ПК и консолей. Как работает эта технология, и в чем ее отличия от более распространенной трассировки лучей?
Компьютерная графика, используемая в современном кинематографе, основана на одной из техник трассировки лучей — трассировке пути (Path Tracing). Этот алгоритм появился в далеком 1986 году, но из-за своей сложности лишь спустя 30 лет начал массово использоваться для создания графики в фильмах.
Чтобы понять, почему все это время трассировка пути оставалась неосуществимой, ознакомимся с основами построения подобной картинки. Сначала 3D-художники вручную моделируют форму объектов в сцене, а программное обеспечение для рендера разбивает их на мелкие треугольники — полигоны.

Затем на модели накладываются текстуры, которые симулируют материалы определенного цвета и типа — например, шероховатые, гладкие или стеклянные.

Готовые объекты и источники света: солнце, небо, фонари, размещаются в нужных положениях на 3D-сцене. После этого добавляется виртуальная камера и запускается процесс рендеринга — благодаря ему картинка в кадре визуализируется в виде привычного 2D-изображения.

С помощью трассировки пути имитируются отражения света от различных материалов. К примеру, попав на матовую красную черепицу крыши, часть света ей будет поглощена, а другая часть — отразится красным. Отраженный свет от каждого объекта попадает в виртуальную камеру, внося свой вклад в создание изображения.

Для образования каждой точки конечной картинки осуществляется несколько тысяч подобных расчетов. А для формирования одного кадра изображения с разрешением 4К их потребуется несколько миллиардов.

Именно из-за этого долгое время создание изображений с использованием трассировки пути было очень медленным процессом. Например, в 2016 году рендерингом фильмов «Зверополис» и «Моана» занималась ферма из тысяч серверов, которые производили вычисления в течении нескольких месяцев — и это всего для двух часов анимации.
Для начала ознакомимся с принципом создания изображения при трассировке пути. Этот алгоритм относится к виду вычислений, которые очень хорошо распараллеливаются: точки картинки независимы друг от друга, поэтому тысячи лучей для каждой из них можно рассчитывать одновременно.

Если показать на картинке траектории всех лучей, которые просчитываются для этой сцены, то она заполнится огромным количеством линий. Поэтому рассмотрим данный процесс на примере одной точки. Первый луч испускается из ее центра и попадает на полигон какого-либо объекта в кадре.

Базовый цвет точки формируется с помощью нескольких лучей, которые попадают рядом с центральным — для этого все их цвета усредняются. Подобные лучи называются первичными.

В результате такого подхода формируется изображение с правильной перспективой.

Мы рассмотрели, как цвет полигонов передается точкам виртуального кадра. Но для получения реалистичной сцены нужно просчитать глобальное освещение объектов — ведь яркость и оттенок цвета каждой точки зависит именно от него.

Для этой цели комбинируются два вида расчетов: прямого (Direct) и непрямого (Indirect) освещения. При первом виде вычислений просчитываются лучи непосредственно от источников освещения — солнца, неба и ламп. Они называются теневыми.

Теневые лучи отражаются от всех объектов сцены, попутно приобретая характер и окраску от их материалов. Таким образом все поверхности, на которые попадает прямое освещение, становятся источниками непрямого. Отраженный свет проникает во все области кадра. В том числе в те, которые закрыты преградами от лучей прямого освещения. На примере ниже можно увидеть, как освещенная зеленая точка на стене отражает свой свет на синюю точку столба, находящуюся в тени.
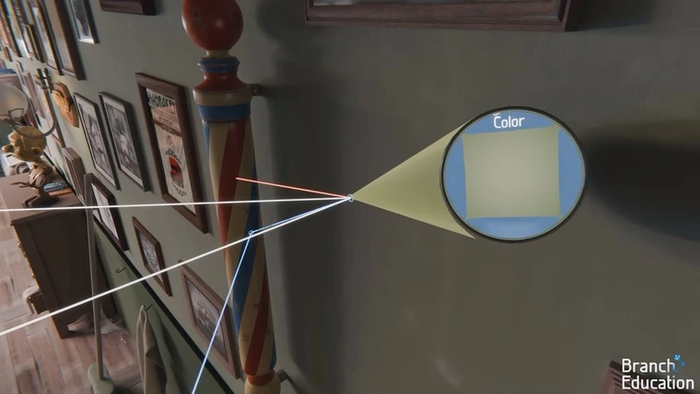
Этот луч, проходящий между двумя точками, называют вторичным. Если при первом отражении он снова попадет в тень, то от него будут просчитаны дополнительные лучи. Так будет продолжаться либо до попадания на освещенную прямым светом точку, либо до достижения лимита отскоков, при котором дальнейший поиск траектории луча прекращается.

Вместе с траекториями лучей от источников прямого освещения это создает большое количество вычислений. Например, в кадре ниже для получения 20 первичных лучей необходимо рассчитать почти сотню вторичных и теневых.

Благодаря непрямому освещению реалистично просчитывается не только изменение яркости точек, но и их взаимное влияние на цвет друг друга. К примеру, если расположить рядом со столбом красный воздушный шар, то за счет непрямого освещения в его оттенок окрасится и тень от столба.

Не менее важно и то, что направление распространения вторичных лучей зависит от свойств материала объекта. Если он идеально гладкий, то угол падения луча будет равен углу его отражения — благодаря этому поверхность будет выглядеть зеркальной. А от шероховатого материала того же цвета лучи будут отражаться в случайные стороны — из-за этого он, как и положено, будет отображаться матовым.

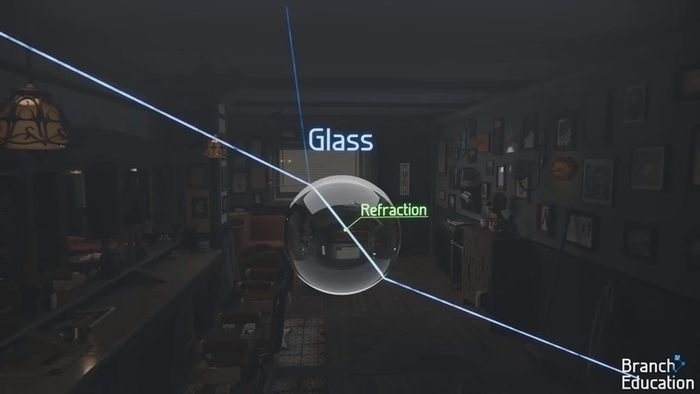
В случае, если материалом выступает стекло, то будет просчитываться не только отражение света, но еще и его преломление при прохождении насквозь.
Сложность трассировки пути зависит от количества источников света, количества лучей на точку и предельно допустимого числа их дополнительных отскоков. У сцены из первого примера с замком используется четыре источника света, тысяча лучей на точку и 12 отскоков. Чтобы визуализировать один ее кадр в 4К, нужно просчитать примерно 400 миллиардов лучей.

А для создания всего одной секунды такого видео их понадобится просчитать уже около триллиона. Именно поэтому в течение нескольких десятилетий трассировка пути для фильмов считалась невозможной.
Чтобы достичь приемлемой производительности, в современных играх трассировка пути реализована намного проще — один-два луча на точку и от одного до четырех отскоков. Но даже при таких параметрах и базовом разрешении Full HD для комфортной игры каждую секунду видеокарте понадобится просчитывать около полумиллиарда лучей.
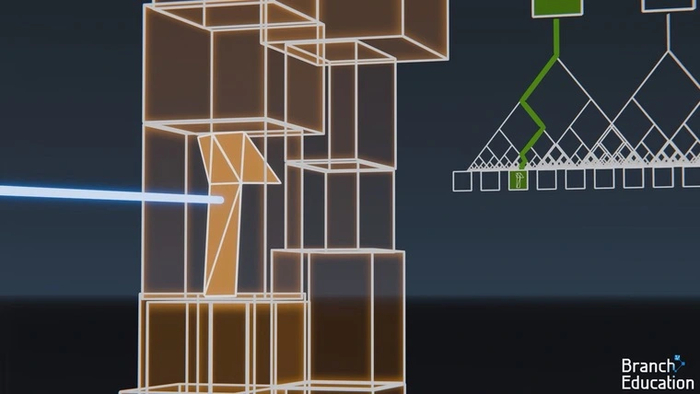
Еще одна ключевая трудность при трассировке пути — узнать, на какой именно полигон луч из точки попадает первым, чтобы определить ее основной цвет. В случае, если полигонов десятки или сотни, можно воспользоваться вычислением траектории луча с помощью математических уравнений. Но в современных сценах их миллионы, поэтому этот способ потребует огромных вычислительных ресурсов. Чтобы упростить данный процесс, используется иерархия ограничивающих объемов (Bounding Volume Hierarchy, BVH). При таком подходе сцена разделяется на виртуальные объемы-коробки, в каждой из которых оказывается одинаковое количество полигонов.
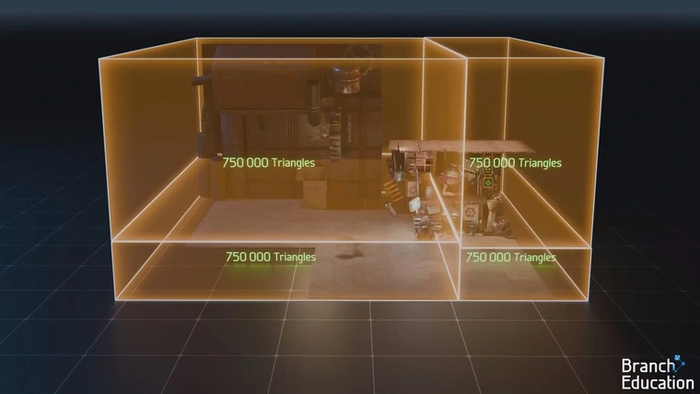
Коробки делятся надвое до тех пор, пока в каждой из них не останется всего несколько полигонов (обычно от 4 до 32). В нашем примере сцена состоит из трех миллионов полигонов, которые «раскладываются» в полмиллиона небольших коробочек.

Положение каждой коробки в пространстве выровнено строго по осям координат. Когда луч начинает свое путешествие из точки, его направление сравнивается с координатами первой пары больших коробок. Коробка, которую он не пересекает, исключается из расчетов — как и все более мелкие, на которые она поделена.
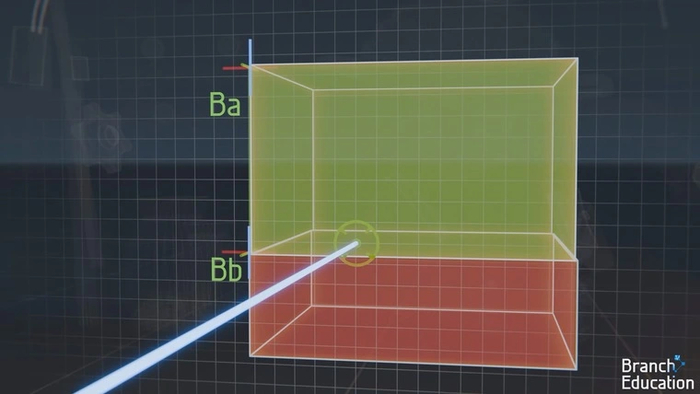
Затем направление луча сравнивается с координатами двух меньших коробок, на которые разделена исходная. И так до тех пор, пока луч не достигнет самой маленькой коробки.
В виду ограничения фотоматериалов
ПРОДОЛЖЕНИЕ СЛЕДУЕТ...

NAND — разновидность флеш-памяти, которая является одним из ключевых компонентов огромного количества электронных устройств. Где используется NAND, как связана с искусственным интеллектом, и почему сейчас такая память в дефиците?
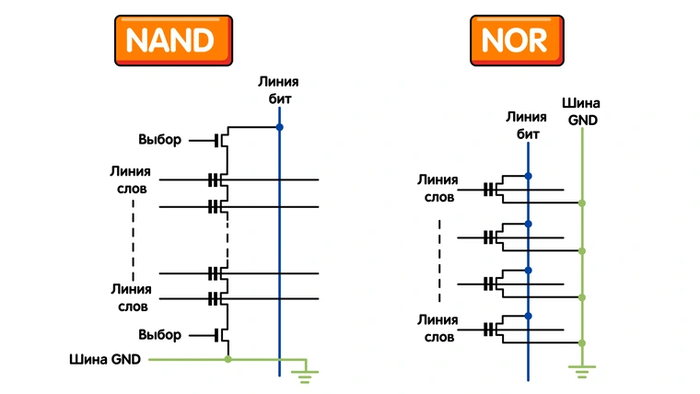
NAND представляет собой один из видов флеш-памяти — постоянной перезаписываемой памяти на основе транзисторов с плавающим затвором. Свое название она получила благодаря организации ячеек в виде цепочек, напоминающих логические элементы «И-НЕ» («Not-AND»). Подобное устройство позволяет упаковывать их более плотно и обеспечивать большие скорости доступа, чем у флеш-памяти типа NOR («И-ИЛИ», «Not-OR»). Именно поэтому NAND получила куда более широкое распространение.
Современные разновидности микросхем NAND имеют 3D-компоновку, за счет которой ячейки памяти размещаются в несколько слоев.
Во всех устройствах, имеющих флеш-память для пользовательских данных, используется именно NAND. Сегодня ее можно встретить в огромном количестве различной электроники: как в самостоятельных накопителях вроде SSD или флешек, так и в виде встроенных чипов в «умных» устройствах — начиная от громоздких автомобилей и заканчивая миниатюрными смарт-часами.
NAND была изобретена в 1989 году, и впервые появилась в потребительской электронике еще в середине 90-х. Однако долгое время она была дорога в производстве и не очень быстра. Поэтому чипы такой памяти использовались в ограниченных объемах лишь в тех устройствах, которые в силу своей компактности не могли работать с жесткими дисками.
С развитием технологий стоимость производства NAND снижалась, а скорость работы памяти и обслуживающих ее контроллеров росла. Благодаря этому к 2007 году на рынке появились первые накопители на базе NAND-памяти для компьютеров и ноутбуков — SSD.

К сегодняшнему дню представить ПК без твердотельных накопителей просто невозможно. Микросхемы NAND внутри них обеспечивают намного более высокие скорости операций с данными и имеют в разы меньшие задержки доступа, чем магнитные пластины жестких дисков.
Использование NAND критично для тех задач, которые требуют быстрого доступа с минимальными задержками к большим объемам памяти. В последние годы самой распространенной из них стал искусственный интеллект. ИИ-модели используют для обучения огромное количество информации, к хранилищу которой должен быть организован молниеносный доступ — иначе скорость этого процесса может снизиться в разы.
В современном мире цифровой техники потребность в NAND растет не по дням, а по часам. Если в центрах обработки данных (ЦОД) раньше можно было обойтись относительно небольшими SSD для «горячих» данных и большими жесткими дисками для «холодных», то сегодня для задач искусственного интеллекта требуются кратно большие объемы твердотельных накопителей. Поэтому ежегодное потребление NAND в серверном сегменте все время растет — если в 2020 году оно составляло около 18% от объемов произведенной памяти, то к сегодняшнему дню эта цифра увеличилась вдвое.
И, хотя объемы производимой NAND с каждым годом увеличиваются примерно на 30–40%, серверы постепенно откусывают от ее «пирога» еще больший кусок. Из-за этого все меньше памяти остается для других основных потребителей — рынка мобильных устройств и ПК. Это можно наглядно проследить с помощью следующей таблицы.
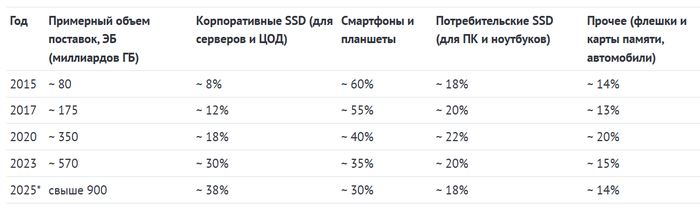
* - прогноз на основе первых десяти месяцев
Как видим, для центров обработки данных с течением времени требуется все больше и больше NAND — в этом году они впервые обогнали по этому параметру исторически лидирующие мобильные устройства. И, судя по тому, что различные ИИ по мере совершенствования начинают требовать для своих нужд еще большие объемы памяти, такая тенденция будет продолжаться и дальше.
Рост потребления NAND серверами не проходит бесследно для рынка электроники. Из-за дефицита памяти спрос на нее увеличивается, а производители начинают повышать цены. В свою очередь, это приводит к удорожанию конечных устройств с NAND. Особенно тех, которые оснащаются большими ее объемами: SSD-накопителей, готовых ПК и ноутбуков, смартфонов и планшетов.

Производители NAND не могут резко нарастить объемы ее производства: строительство новых фабрик — процесс долгий и затратный, а уже существующие мощности и так загружены на полную. Это усугубляется и тем, что три крупных производителя (Samsung, Micron, SK Hynix) сконцентрированы на выпуске чипов памяти HBM — ведь без них невозможно создание производительных ускорителей искусственного интеллекта. Перераспределение производственных мощностей в сторону NAND могло бы помочь сократить дефицит. Но до тех пор, пока HBM приносит большую прибыль, вряд ли кто-то из «большой тройки» на это пойдет. Поэтому основным способом борьбы с дефицитом флеш-памяти сегодня является технологический прогресс, позволяющий создавать чипы увеличенной емкости. Благодаря ему производители постепенно учатся «выращивать» 3D-стеки NAND с большим количеством слоев, а вдобавок — еще и склеивать больше таких стеков между собой. К примеру, SK Hynix за счет использования этих двух приемов нарастила общее количество слоев последнего поколения своей NAND с 238 до 321.

Наращивание слоев позволяет увеличить не только емкость, но и скорость памяти. Однако последней в серверах и так достаточно. Поэтому в погоне за удешевлением и более высокой плотностью NAND производители постепенно увеличивают количество бит, хранящихся в одной ее ячейке. Как результат, даже в ЦОД четырехбитная QLC NAND постепенно становится из экзотики вторым игроком: если в 2021 году ее имели лишь 10% серверных SSD, то к 2026 году их доля вплотную приблизится к половине.
NAND-память — один из ключевых компонентов современной техники. Ее главными достоинствами являются скорость и компактность, благодаря которым эта память нашла приют в огромном количестве различных устройств. Среди потребительской техники основные объемы NAND приходятся на накопители для ПК, смартфоны и планшеты. Но из-за непрекращающегося бума искусственного интеллекта все больше такой памяти уходит в серверы, приводя к ее дефициту.
Подобный расклад сил на рынке приводит к эффекту домино: помимо NAND, дорожает оперативная память, память для видеокарт и даже жесткие диски, которые в условиях недостатка SSD все чаще используются в серверах для хранения «холодных» данных. Учитывая, что снижения востребованности NAND в ближайшее время не ожидается, такая ситуация останется с нами надолго.

Для хранения данных в различных «умных» гаджетах используются накопители на базе флеш-памяти. Они имеют много подвидов, различающихся по типу подключения, поколениям и скоростям. Почему один и тот же объем памяти в бюджетном и флагманском устройстве — это не одно и то же? И почему не всякая память одинаково полезна?
Исторически первыми и единственными накопителями персональных компьютеров на протяжении долгого времени были жесткие диски. Флеш-память в начале своего развития была дорогая, и создать доступный по цене накопитель приличного объема в те времена просто не представлялось возможным. И только в последнее десятилетие новые технологии стали позволять производить накопители на флеш-памяти нужного для ПК объема по достаточно доступной цене, вследствие чего системные жесткие диски в пользовательских компьютерах и ноутбуках плавно заменили SSD.
В противовес этому, даже первые мобильные устройства с мультимедийными возможностями изначально оснащались накопителями на базе флеш-памяти и картами памяти на их же основе. Благо объемы тогда были небольшие, а устанавливать даже небольшой жесткий диск в мобильное устройство было чревато чувствительностью к падениям, большим энергопотреблением, размерами и весом устройства. Впрочем, редкие исключения все же были — взять тот же Nokia N91 2006 года с миниатюрным жестким диском. Однако практически все устройства с тех годов и по сегодняшний день оснащаются именно накопителями на базе флеш-памяти. Ее развитие в мобильных устройствах имеет долгую историю, за которую сменилось несколько типов памяти, у каждой из которой есть несколько версий со своими особенностями. Рассмотрим варианты памяти, встречающиеся в современных устройствах.
Встроенная память Embedded MMC основана на стандарте карт памяти MultiMedia Card, впервые представленном в 1997 году. В 1999 году был представлен усовершенствованный стандарт MMC 2.0, в 2001-м — MMC третьей версии. Первые варианты карт MMC не блистали высокой скоростью, вследствие чего для основы стандарта внутренней памяти мобильных устройств их спецификации подходили мало.

MMC 4.0, увидевший свет в 2003 году, получил возможность значительного увеличения скорости «общения» карт с устройством — ранее используемый однобитный режим передачи данных по умолчанию сменил четырехбитный, опционально мог задействоваться и режим 8-бит. Эти спецификации легли и в основу первого стандарта встроенной памяти семейства eMMC под версией 4.1, разработанного организацией JEDEC в середине 2007 года. Последующие версии стандартов 4.2, 4.3, 4.4 и 4.41 включают в себя улучшения по управлению питанием памяти, контроль плохих блоков, оптимизации для операций чтения и записи. Максимальная скорость передачи данных первых версий eMMC ограничена 52 МБ/c. С версии 4.4 она удвоена до 104 МБ/с.
В 2011 году JEDEC представила стандарт eMMC 4.5, основным улучшением которого является увеличение скорости интерфейса до 200 МБ/c благодаря более быстрой шине. В версии eMMC 5.0, датирующейся 2013 годом, пиковая скорость передачи интерфейса вновь увеличилась вдвое, была проведена большая оптимизация для достижения более высокой производительности памяти в режиме случайной записи. Последняя версия стандарта eMMC 5.1 датируется 2015 годом, включая в себя новые оптимизации операций чтения и записи. Благодаря этому венец развития eMMC в реальном использовании стал немного быстрее своей предыдущей версии, хотя пропускная способность интерфейса осталась прежней.

Карты памяти MMC с портативных устройств уже давно вытеснили их «внуки» стандарта Secure Digital (SD), который является дальнейшим развитием MMC. А встроенную eMMC в среднебюджетных и флагманских устройствах заменила более совершенная память UFS. Несмотря на это, внутренняя память eMMC широко используется огромных количеством бюджетных устройств и по сей день — для них ее скорости достаточны, да и обходится такая память производителям дешевле более быстрых современников.
Как бы ни совершенствовалась eMMC, с каждым годом становилось все понятнее, что ей нужна более высокопроизводительная замена. В 2011 году организацией JEDEC был опубликован стандарт первой версии новой мобильной памяти следующего поколения — Universal Flash Storage (UFS).
Различия между двумя типами памяти оказались куда глубже, чем в простом увеличении скорости. Память eMMC использует параллельный доступ подобно интерфейсу IDE старых компьютерных жестких дисков. UFS же основана на последовательном интерфейсе, как у более современных SATA и NVMe. Аналогично последнему реализована у UFS и масштабируемость — для достижения более высокой пропускной способности можно задействовать сразу несколько линий интерфейса. Помимо этого, благодаря другой внутренней организации и использованию очереди команд память нового типа демонстрирует гораздо более высокие показатели случайных операций, которые особенно важны для увеличения скорости работы операционной системы устройства и установленных программ.
К тому же интерфейс у eMMC полудуплексный. То есть данные с максимальной скоростью в один момент времени могут передаваться только в одном направлении — либо от накопителя к устройству, либо от устройства к накопителю. Параллельное чтение и запись делят между собой пропускную способность и приводят к снижению производительности. UFS такой проблемы лишена — интерфейс полнодуплексный, и максимальная скорость обмена может достигаться одновременно в обоих направлениях.
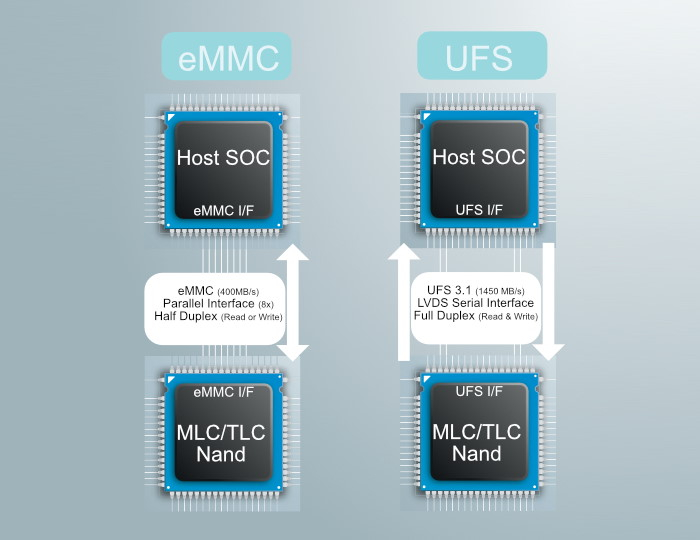
Первая версия UFS основывалась на одной линии со скоростью соединения 300 МБ/c. В 2012 году была выпущена спецификация 1.1, которая включала некоторые улучшения по управлению памятью, но скорость не увеличивала. Производители мобильных чипов и гаджетов на то время не видели особых смысла в использовании UFS первых версий — конкурирующий eMMC 4.5 мог передавать до 200 МБ/с, а разработка и внедрение в SoC контроллера для работы с памятью нового типа удорожала их при сравнительно небольшом выхлопе. При этом сами чипы памяти для UFS находились в начале своего развития и стоили достаточно дорого, что также делало внедрение нового вида накопителей экономически невыгодным.
В 2013 году было представлено второе поколение UFS. Новая спецификация включала доработки управления питанием для лучшего энергосбережения и улучшенные функции безопасности. Но самое главное — версия 2.0 получила значительное увеличение пропускной способности интерфейса. Скорость линии удвоили до 600 МБ/c, а количество самих линий нарастили до двух, в результате чего максимальная пропускная способность увеличилась до 1200 МБ/c. Такие улучшения по сравнению с eMMC были уже гораздо более существенны, и практическим внедрением нового типа памяти заинтересовалась компания Samsung. Южнокорейский гигант, который сам разрабатывает память и системы на чипе для мобильных устройств, первым внедрил в свой флагманский SoC Exynos 7420 контроллер памяти UFS 2.0. Новая память дебютировала в линейке смартфонов Samsung Galaxy S6.
В 2016 году было решено обновить спецификацию UFS до версии 2.1, добавив в нее поддержку индикатора «здоровья» памяти, оптимизацию операций записи, введение приоритета команд и возможность безопасного обновления микрокода прошивки. По функциональности и принципам работы накопители данного типа становились все больше похожими на своих старших братьев — SSD.
В 2018 году была представлена спецификация нового поколения памяти UFS 3.0. Введен новый режим обновления команд, предусмотрен расширенный рабочий температурный режим от -40 до 105 °C, ведь память данного типа все больше начинала применяться в автомобилестроении. Линий передачи данных все также две, но они значительно ускорились. Теперь каждая способна выдать до 1450 МБ/c, вследствие чего общая пропускная способность увеличивается до 2900 МБ/c.
К 2020 году память UFS набрала популярность в массовых мобильных устройствах, и JEDEC представила еще две обновленные спецификации — топовую UFS 3.1 и мейнстримовую UFS 2.2. Новинки не получили увеличения пропускной способности интерфейса, но обзавелись новой функцией WriteBooster, еще на один шаг приблизив мобильную память к SSD. Технология призвана увеличить скорость записи по сравнению с предшественниками за счет добавления SLC-кеша.
Высокопроизводительная UFS 3.1 дополнительно получила еще два нововведения — режим глубокого сна DeepSleep для меньшего энергопотребления и функцию Performance Throtlling Notification для контроля производительности при перегреве памяти. Также было добавлено расширение стандарта UFS Host Performance Booster. Оно предусматривает кеширование в ОЗУ карты логических и физических адресов памяти, благодаря чему должна повыситься скорость доступа к накопителям большого объема.

Летом 2022 года была представлена последняя на данный момент спецификация быстрой мобильной памяти — UFS 4.0. В ее основе все те же две несменные линии, каждая из которых удвоила свою пропускную способность до 2900 МБ/c, тогда как общая скорость по двум линиям может доходить до невероятных 5800 МБ/c. Помимо ускорения линий, новая спецификация подразумевает снижение питающего напряжения, за счет чего память должна меньше греться и быть более экономичной. UFS 4.0 получила поддержку многоуровневых очередей запросов Multi-Circular Queue, усовершенствованный интерфейс RMPB и несколько новых команд для снижения системных задержек.
Отдельно стоит упомянуть о картах памяти UFS. Если память eMMC «выросла» из стандарта для карт памяти MMC, то здесь все наоборот: карты UFS появились благодаря развитию встроенной памяти UFS, которую в данном контексте правильнее называть eUFS. Первая версия стандарта UFS Card датирована 2016 годом и основана на UFS 2.0, но использует одну линию вместо двух. Это дает 600 МБ/c пропускной способности при сохранении всех остальных функциональных преимуществ.

Обновленная версия UFS Card 1.1 была представлена в 2018 году вместе со стандартом UFS 3.0. Потолок скорости остался прежним, изменения ограничились добавлением некоторых функций и оптимизаций от «старшей сестры» UFS 3.0. В 2020 году была представлена последняя на данный момент версия UFS Card 3.0, для работы которой все так же используется одна линия, но с удвоенной скоростью передачи данных — до 1200 МБ/c. К сожалению, карты памяти формата UFS так и не нашли применения в реальных массовых устройствах, хотя компания Samsung анонсировала выпуск таких продуктов уже несколько раз.
До 2015 года память eMMC использовалась повсеместно во всех мобильных гаджетах, независимо от производителя. В 2015 году, когда Samsung выпустила первый смартфон c UFS 2.0, компания Apple решила пойти по своему пути развития скоростной памяти в собственных гаджетах. Система на чипе Apple A9, ставшая сердцем смартфона iPhone 6S, впервые включала в себя кастомный NVMe-контроллер для связи с внутренним накопителем. По сути, компания перенесла компьютерный NVMe SSD в смартфон — с некоторыми упрощениями и более медленной памятью, но все же.

Как и в случае других своих разработок, Apple не раскрывала подробности технических характеристик своего накопителя. Судя по независимым тестам, в чипе A9 устанавливалась разновидность NVMe-контроллера собственной разработки Apple, который использовался компанией в ноутбуке MacBook 12" 2015 года выпуска. Этот контроллер подключается по четырем линиям шины PCI-E 2.0 и обеспечивает максимальную пропускную способность в 2 ГБ/c.
Все последующие системы на чипе компании оснащаются похожими NVMe-контроллерами собственной разработки с аналогичной пропускной способностью. Начиная со смартфонного чипа A14 и планшето-ноутбучного M1, в состав разработок Apple входит более скоростной NVMe-контроллер c максимальной пропускной способностью до 3.9 ГБ/c. Однако память в смартфонах этих значений не достигает, среди мобильных гаджетов только планшеты iPad на чипе M1 с большим объемом памяти способны превышать прежний порог в 2 ГБ/c на кратковременных операциях. Более быстрые компьютерные чипы M1 серий Pro, Max и Ultra имеют в своем составе самый быстрый NVMe-контроллер компании со скоростью до 7.8 ГБ/c, но в смартфонах и планшетах они не встречаются, оставаясь прерогативой ноутбуков и компьютеров компании.
Высокие скорости и тысячи операций в секунду красиво выглядят на бумаге. Но не стоит забывать, что любой вид памяти из описанной троицы — это всего лишь спецификация. Компьютерный интерфейс NVMe 4.0 x4 имеет пропускную способность более 7 ГБ/c, но все ли SSD с его поддержкой достигают на практике этих значений? То же самое и с мобильными видами накопителей. Сравним разные виды памяти в таблице ниже, учитывая как заявленные спецификации, так и наиболее часто встречающиеся в реальных устройствах характеристики каждого вида памяти.
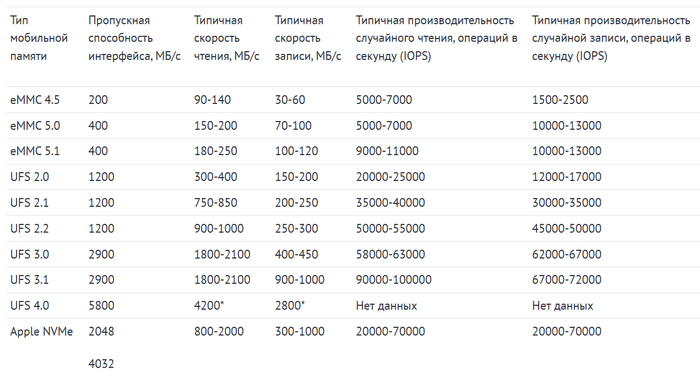
* данные презентации памяти UFS 4.0 производства компании Samsung.
Как видите, разброс между скоростью интерфейса и устанавливаемой памяти в большинстве случаев довольно существенный. Более того, приведены данные для одних из самых емких накопителей каждого типа памяти. Например, для UFS 3.1 цифры производительности даны для накопителя объемом 512 ГБ, тогда как для смартфонов с 256 или 128 ГБ такой памяти некоторые характеристики могут быть значительно меньше. Компания Apple не анонсирует изменения в каждом поколении своих контроллеров, поэтому в таблице ее устройства даны одной строкой — из-за этого разброс указанных характеристик по сравнению с другими типами памяти еще больше.

Тем не менее, чем новее тип памяти в устройстве, тем быстрее в среднем его накопитель. Однако стоит учитывать, что отдельно вид накопителя вы все равно выбрать не сможете: все зависит от используемой системы на чипе, у которой должна быть поддержка того или иного вида памяти, и от реализации ее возможностей в самом смартфоне. К тому же не стоит забывать, что у младших модификаций устройств с самым малым в линейке количеством памяти скорость последней чаще всего значительно меньше, чем у моделей с большим объемом накопителя.
Как правило, современные мобильные устройства высокого ценового диапазона оснащаются памятью с интерфейсом UFS 3.1 (или NVMe в случае Apple). В среднем классе встречаются как третья, так и вторая версии UFS. А в бюджетный, где до сих пор господствует eMMC, все чаще проникают некоторые смартфоны с UFS 2.x. Топовые модели конца 2023 года впервые начали оснащаться самой скоростной мобильной памятью UFS 4.0, экспансия которой намечалась на флагманский сегмент смартфонов в 2024 году.
Период 2024-2025 годов можно охарактеризовать как этап объединения и подготовки к следующему скачку.
Массовое распространение UFS 4.0 и 4.1 во флагманах: UFS 4.0 стала новым стандартом производительности для топовых smartphones. К концу 2024 — началу 2025 года всё больше флагманов, таких как линейка Samsung Galaxy S24, OnePlus 12 и Xiaomi 14 Pro, используют именно эту память или её незначительно улучшенную версию — UFS 4.1. Прирост скорости между UFS 4.0 и UFS 4.1 не столь велик, как предыдущие поколения, но он демонстрирует продолжающееся развитие технологии в сторону не только скорости, но и энергоэффективности.
Начало внедрения UFS 4.1: Этот стандарт уже анонсирован и демонстрируется производителями чипов, как, например, SK Hynix. Он предлагает незначительное увеличение скорости записи (на 7%) и снижение энергопотребления (примерно на 7%) по сравнению с UFS 4.0. В 2025 году можно ожидать его появление в новейших флагманских устройствах.
Укрепление UFS 3.1 в среднем сегменте: В то время как флагманы перешли на UFS 4.x, UFS 3.1 остается отличным и востребованным решением для смартфонов среднего ценового диапазона, предлагая более чем достаточную производительность для большинства пользователей.
Что касается 2026 года, то здесь картина выглядит достаточно определенно, но без сенсаций.
UFS 5.0 — будущее, которое пока не наступило: Хотя стандарт UFS 5.0 был официально анонсирован JEDEC в конце 2024 года и обещает колоссальный прирост производительности (скорость чтения до 6000 МБ/с), его массовое внедрение в смартфоны ожидается не раньше 2027 года, согласно дорожной карте Samsung Semiconductor.
Год UFS 4.1: Таким образом, 2026 год, скорее всего, станет временем, когда UFS 4.1 окончательно заменит UFS 4.0 в качестве памяти для флагманских устройств. Производители будут активно осваивать этот стандарт, в то время как инженеры будут готовить платформы для интеграции UFS 5.0 в будущих моделях. В массовом сегменте продолжится вытеснение UFS 2.x более быстрой UFS 3.1.
Подводя итог, можно сказать, что экспансия UFS 4.0, успешно состоялась. На период 2024-2025 годов приходится её закрепление во флагманском сегменте и плавный переход к UFS 4.1. Ожидаемого прорыва в лице UFS 5.0 в 2026 году, по всей видимости, не произойдет — этот этап намечен на 2027 год.

Qualcomm Snapdragon — популярные процессоры для смартфонов. Каждый год их ряды пополняются различными моделями, но движущей силой среди решений компании всегда являлся флагманский чип. Сегодня это место занимает Snapdragon 8 Elite, который заметно отличается от прошлых топов Qualcomm. Какие ключевые изменения он получил, и почему они так важны?
Qualcomm — старожил рынка чипов для мобильных устройств. Ее первые решения использовались в кнопочных телефонах, а ранние процессоры обосновались в смартфонах уже в 2006 году — тогда эти гаджеты работали на операционных системах Symbian и Windows Mobile.
Появление Android в конце 2008 года поспособствовало увеличению популярности продукции компании. Первый смартфон HTC Dream на новой ОС дебютировал именно с чипом от Qualcomm. Затем его инициативу подхватили и многие модели от других производителей. А через год появляются смартфоны на новом чипе, который положил начало знаменитой линейке — Qualcomm Snapdragon QSD8250.
К сегодняшнему дню линейка Snapdragon насчитывает десятки различных моделей, а ее топовые решения по праву носят звание самых производительных и оптимизированных систем на чипе (SoC) для ОС Android.
В октябре 2024 года был представлен очередной топ серии Snapdragon 8, получивший непривычную приставку «Elite». Таким образом Qualcomm решила дистанцировать новую модель от своих прежних разработок. И неспроста — его внутреннее устройство заметно отличается от последних поколений флагманских SoC компании.
Когда появились первые модели Snapdragon, на рынке мобильных SoC у Qualcomm было несколько конкурентов. Но уже тогда именно ее решения чаще всего становились выбором производителей смартфонов, особенно — для флагманских моделей. Не в последнюю очередь благодаря тому, что Qualcomm не использовала готовые ядра ARM Cortex, а разрабатывала их сама.
Первым таким ядром стало Scorpion. Имеющее общие элементы с Cortex-A8 и представленное практически одновременно с ним, Scorpion было заметно быстрее: часто оно показывало результаты, сравнимые с более новым Cortex-A9.

В 2012 году компания представила следующее ядро собственной разработки под названием Krait. Оно было основой для ее чипов вплоть до 2015 года, когда появился Snapdragon 810. Это дебютный 64-битный SoC Qualcomm, который стал ее первым за много лет решением на базе стандартных ядер ARM Cortex.
Годом спустя был выпущен Snapdragon 820, в котором были использованы ядра Kryo — так компания назвала немного доработанные ей ядра ARM Cortex. В отличие от Scorpion и Krait, улучшения в Kryo достаточно поверхностные. Поэтому в большинстве сценариев эти ядра не имеют весомых преимуществ перед стандартными ARM Cortex, на которых они основаны.
Такой подход для ядер сохранялся и по сей день, включая флагман прошлого поколения Snapdragon 8 Gen 3. А в Snapdragon Elite компания впервые за десять лет вновь использовала собственное ядро — Oryon.
Qualcomm является лидером на рынке чипов для Android-устройств. Однако ядра компании Apple, которые она разрабатывает для своих SoC самостоятельно, уже много лет заметно превосходят стандартные решения ARM и современные Kryo. Благодаря их высокой производительности, с 2020 года SoC Apple используются не только в ее собственных смартфонах и планшетах, но и в компьютерах серии Mac.
Qualcomm пыталась опередить Apple на этом рынке, еще в 2019 представив SoC линеек 8cx и 7c — специальные версии Snapdragon, предназначенные для ноутбуков и планшетов на ОС Windows. Однако их производительность при работе с данной системой оставляла желать лучшего. Последние чипы этих серий были выпущены в 2021 году, так и не став популярными.
Но у компании уже был готов дальнейший план действий. В том же году она приобрела стартап NUVIA, который занимался разработкой нового ARM-ядра Phoenix для серверов. Главными фигурами в нем были опытные инженеры, которые ранее работали в Apple над архитектурой чипов Apple Silicon. Ключевой особенностью Phoenix была высокая производительность на ватт. В 2020 году NUVIA заявляла, что по этому параметру оно превосходит все существующие ядра процессоров.
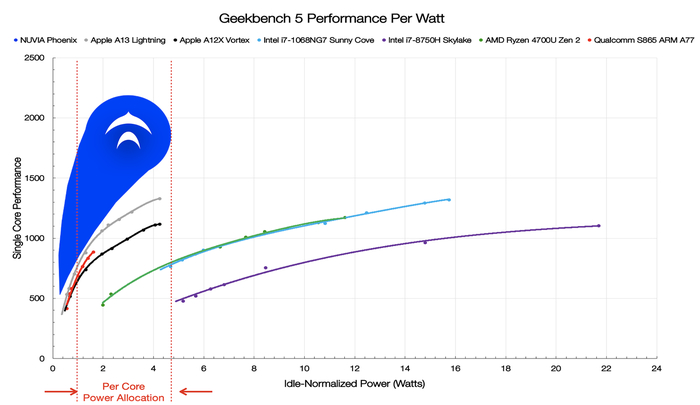
После объединения с Qualcomm это ядро было немного доработано для использования в потребительских устройствах, получив название Oryon. Первыми продуктами на его основе стали процессоры линейки Snapdragon X. Они были представлены в конце 2023 года, позиционируясь в качестве замены линейкам 8cx/7c для ноутбуков и производительных планшетов на ОС Windows.
В отличие от стандартных ядер ARM, которые делятся на «малые» и «большие», ядро Oryon разрабатывалось с учетом как максимальной производительности, так и высокой энергоэффективности. Линейка чипов Snapdragon X получила от 8 до 12 таких ядер.

Не став долго тянуть с чипом для смартфонов, в октябре 2024 года Qualcomm представила Snapdragon 8 Elite. Он производится по техпроцессу TSMC N3E (3 нм), и имеет два варианта: с семью и восемью ядрами Oryon.
Ядра делятся на два кластера. В кластере Prime находятся два главных ядра, которые могут достигать частоты 4,32 ГГц. В кластере Performance — остальные, работающие на 3,53 ГГц. Для смартфонов Samsung используется разогнанная восьмиядерная версия Snapdragon 8 Elite for Galaxy. У нее пиковые частоты cтаршего кластера чуть выше — до 4,47 ГГц.

Одним из ключевых отличий от других SoC здесь является система кэширования. Обычно используется классический подход: маленький L1 и небольшой L2 для каждого ядра, и большой общий L3 для всех ядер. Здесь у ядер старшего кластера довольно вместительный кэш L1I объемом 192 Кб для инструкций, и вдвое меньший L1D для данных.

У младшего кластера объемы кэшей чуть меньше — 128 и 64 Кб, соответственно. На каждый из кластеров выделено 12 Мб общего L2. Таким образом, даже при нагрузке одного ядра в кластере оно может использовать весь объем этого большого кэша для своей работы. Аналогичный подход был использован и в серии Snapdragon X — с той разницей, что там все кластеры состоят из четырех ядер.

После L2 cледует кэш L3 объемом 8 Мб. Он общий для всех ядер. Таким образом, объем кэшей двух последних уровней составляет внушительные 32 Мб — это самое высокое значение среди мобильных SoC.
Ядро Oryon имеет восьмиполосный декодер — как, к примеру, самое современное Intel Lion Cove или Apple Everest. У топовых ядер ARM Cortex X4/X925 декодер имеет 10 полос, но работать на схожих с Oryon частотах они не могут.

Вычислительный конвейер Oryon состоит из 14 исполнительных портов. Среди них шесть целочисленных арифметико-логических устройств (ALU) и четыре блока для вычислений с плавающей запятой, каждый из которых имеет собственный блок для работы со 128-битными инструкциями NEON. Компанию им составляют четыре блока загрузки/выгрузки данных.
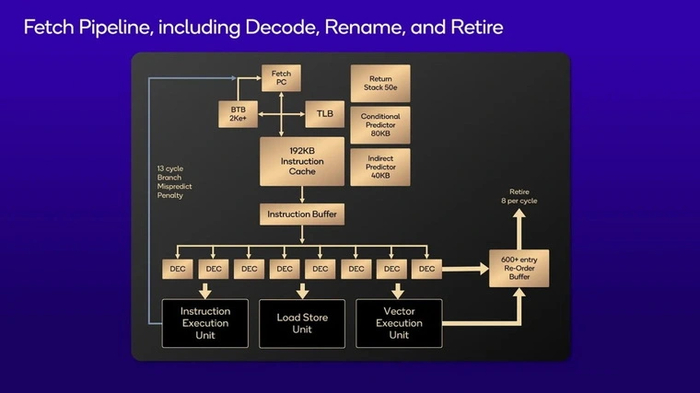
Главное отличие от стандартных ядер ARM — множественные аппаратные доработки ядер, служащие для повышения производительности кода x86. Это значит, что Oryon теряет заметно меньше производительности при выполнении x86-приложений, в том числе — запуске ОС Windows и игр для нее через эмулятор.
Из-за высокой тактовой частоты Oryon в Snapdragon 8 Elite гораздо быстрее, чем Cortex-X4 в Snapdragon 8 Gen 3: рост однопоточной производительности от поколения к поколению достиг практически полуторакратного. По этому параметру Qualcomm наконец приблизилась к современным SoC Apple A — если верить бенчмарку GeekBench 6, преимущество чипа A18 Pro над 8 Elite составляет всего несколько процентов.

Многопоток тоже не подвел. В нем детище Qualcomm опережает все существующие чипы: как топ от Apple, так и конкурирующий Dimensity 9400 от Mediatek.
За связь с ОЗУ у Snapdragon 8 Elite отвечает блок управления памятью. Он поддерживает аппаратный обход таблиц, который может использоваться для быстрого запроса данных из оперативной памяти в случае промаха кэша. На каждое ядро поддерживается 16 одновременных вызовов обхода.

В качестве оперативной памяти используется LPDDR5X-10667 — самый быстрый стандарт мобильной ОЗУ на сегодняшний день. Для связи с ней контроллер памяти оснащен четырьмя 16-битными каналами доступа. Таким образом, пропускная способность ОЗУ достигает 85,3 Гбит/c. Рост по сравнению с предыдущим поколением небольшой — около 11 %. Предельный объем памяти, поддерживаемый SoC, сохранился на уровне 24 Гб.
В качестве постоянной памяти используется быстрая UFS 4.0. В этом плане изменений по сравнению со Snapdragon 8 Gen 3 и 8 Gen 2 нет.
В Snapdragon 8 Elite используется графическая архитектура Qualcomm восьмого поколения. В отличие от предшественницы, она имеет слайсовое строение. При нем вычислительная часть ГП поделена на несколько равнозначных фрагментов. В нашем случае это графика Adreno 830, в которой таких фрагмента три. Все они имеют доступ к быстрой графической памяти объемом 12 Мб, служащей кэшем между ГП и ОЗУ. Управляет работой слайсов командный процессор.

В одном слайсе два блока SIMD Shader Processor (SP). Каждый из них состоит из двух микроконвейеров (micro shader pipe texture pipe, μSPTP), которые имеют общий кэш инструкций.
μSPTP — самый маленький вычислительный блок Adreno, аналогично мультипроцессорам SM в ГП NVIDIA и вычислительным блокам CU в ГП AMD. Но, в отличие от «старших» братьев, здесь универсальные шейдерные процессоры устроены по-другому. Они имеют отдельные блоки для двух видов графических вычислений — FP32 (полная точность) и FP16 (половинная точность). При этом блоки FP32 тоже могут переключаться в режим FP16 по мере необходимости.
В одном μSPTP находится 128 блоков FP32 и 256 блоков FP16. Помимо этого, в его состав входят четыре текстурных модуля (TMU), блок трассировки лучей, 16 блоков работы со сложными инструкциями (EFU — аналог SFU у ГП NVIDIA), регистровый файл объемом 192 Кб и небольшой текстурный кэш.

Пара μSPTP, объединенная в SIMD Shader Processor, соединена с 8 блоками растеризации (ROP). Таким образом, Adreno 830 имеет в своем составе 1536 шейдерных блоков FP32, 48 ROP и 96 TMU. Графика работает на частоте до 1100 МГц, достигая пиковой производительности в 3,38 терафлопс (у Snapdragon 8 Elite for Galaxy — 1200 МГц и 3,68 терафлопс, соответственно).
В Snapdragon 8 Gen 3 использовался Adreno 750, который имел чуть меньшую частоту, но при этом схож с новым ГП по основным характеристикам. Однако Qualcomm утверждает, что благодаря переработанной графической архитектуре Adreno 830 на 40 % быстрее в растеризации, и на 35 % — при использовании трассировки лучей.

Дополнительный плюс — сниженное энергопотребление. Слайсовая архитектура позволяет полностью отключать фрагменты ГП, когда в них нет нужды. При запуске игр с относительно несложной графикой часть нового Adreno остается неактивной, позволяя заметно продлить время работы от батареи в играх — по заверениям Qualcomm, до двух с половиной часов. Приводятся и другие цифры: при снижении производительности до уровня Adreno 750 новый ГП потребляет на 40 % меньше энергии.
Не обошлось без улучшений самого «модного» сегодня блока — нейронного процессора. В отличие от компьютерных процессоров, где он только появляется, в мобильных чипах NPU является неотъемлемым решением уже много лет. У SoC Qualcomm эту роль выполняет Hexagon — вычислительный блок, совмещающий функции нейронного и цифрового сигнального процессора (DSP).
В новом чипе он получил очередные усовершенствования. По сравнению с Hexagon в Snapdragon 8 Gen 3, было увеличено количество вычислительных блоков: скалярных — с шести до восьми, векторных — с четырех до шести. Тензорная часть тоже ускорилась, но значения в цифрах не приводятся. Qualcomm указывает лишь то, что поддерживаются вычисления в форматах INT4, INT8, INT16 и FP16 (как и у 8 Gen 3).

Благодаря произведенным улучшениям производительность NPU возросла на 45 %, что позволяет использовать более широкие возможности локального искусственного интеллекта на устройстве. При этом производительность была увеличена не в ущерб энергопотреблению: в нем новый нейронный блок экономичнее предшественника на те же 45 %.
Hexagon связан с блоком Spectra. Это процессор обработки изображений (ISP), который состоит из трех блоков. В этом поколении производительность Spectra увеличилась до 4300 Мп/c. За счет этого блок умеет обрабатывать картинку с частотой 30 кадр/c сразу с трех 48 Мп сенсоров одновременно. У Snapdragon 8 Gen 3 в сравнимых условиях поддерживались сенсоры на 36 Мп.

Благодаря новому ISP Snapdragon 8 Elite может работать с модулями камер, которые обладают сумасшедшим разрешением 320 Мп, тогда как предшественник поддерживал только 200 Мп сенсоры. При этом часть конвейера Spectra была заметно переработана, позволяя обрабатывать «сырую» RAW-информацию с датчиков в комбинации с вычислениями на NPU.

За счет такой связки алгоритмы искусственного интеллекта могут в реальном времени обрабатывать запись видео 4К с 60 кадр/c. Помимо фильтров и эффектов, вроде удаления ненужных объектов из кадра, это позволяет заметно улучшить видеосъемку в условиях плохого освещения.
Snapdragon 8 Elite получил новый модем X80. Изменений в пиковой скорости сетей 5G по сравнению с тремя прошлыми поколениями чипов Snapdragon 8 тут нет: поддерживается до 10 Гбит/c на прием и до 3,5 Гбит/c на отдачу. Но X80 должен приблизить теоретические значения к практике сильнее, чем прошлые поколения. Он имеет шесть антенн, с которых может производиться агрегация сигнала, тогда как у более ранних решений их только четыре.

Главная фишка X80 — встроенная поддержка спутниковой связи в узкополосных диапазонах (NB-NTN). Теперь для ее реализации производителям смартфонов не нужно будет использовать сторонние чипы.
Улучшить стабильность соединения должна «ИИ-система» третьего поколения — это тензорный ускоритель, встроенный прямо в модем. Он более точно определяет, к каким станциям лучше подключаться и как перераспределять потоки данных, чтобы добиться максимальной скорости и минимизировать задержки.
За беспроводные сети отвечает комплекс FastConnect 7900. Как и в прошлом поколении, им поддерживается Wi-Fi 7 со скоростью до 5,8 Гбит/c. Ключевых отличий тут несколько. Первое — использование ИИ-функций для улучшения соединения, аналогично таковым для мобильной сети. Второе — новый Bluetooth 6.0, который уменьшает задержки при передаче звука и дополнительно экономит энергию. Третье — поддержка технологии Ultra Wideband (UWB), позволяющая избавиться еще от одного лишнего чипа в смартфоне.

Теория хорошо, но практика — лучше. Сравним основные характеристики и производительность Snapdragon 8 Elite с предшествующими топовыми чипами Qualcomm, чтобы понять, насколько велика разница между поколениями.

* в скобках результатов бенчмарков указан процентный прирост по сравнению с предыдущим поколением SoC.
Как можно видеть по результатам бенчмарков, Snapdragon 8 Elite совершил существенный рывок по скорости однопоточных вычислений — тех самых, что являются ключевым фактором для повышения производительности при работе с основной массой программ и игр. В этом плане новая SoC Qualcomm практически перестала уступать своим конкурентам из стана Apple A. Скорость многопоточных вычислений и встроенной графики тоже заметно увеличилась. Но схожий прирост уже можно было видеть между прошлыми поколениями Snapdragon 8.
Сегодня новый чип Qualcomm используется в большинстве флагманских Android-смартфонов. В их числе серия Samsung Galaxy S25, Xiaomi 15, Honor Magic 7, Realme GT 7 Pro, OnePlus 13 и Ace 5 Pro, ASUS Rog Phone 8 и ZenFone 12 Ultra, Vivo iQOO 13, а также многие другие.
Главная движущая сила Snapdragon 8 Elite — ядра Oryon. В будущем Qualcomm планирует оснастить ими более широкий ассортимент своих систем на чипе, что позволит заметно повысить комфорт их использования. Но на данный момент Oryon требует слишком много транзисторного бюджета, чтобы проникнуть в чипы даже субфлагманского класса. Поэтому ожидаемая в ближайшие месяцы SoC Snapdragon 8s Elite, несмотря на свое название, получит лишь очередные ядра Kryo на основе современных ARM Cortex.
