Сетевые конторы в Телеграм (сантехника)
ДЛЛ: если вы обратились в чат ЖК с просьбой порекомендовать какого-нибудь специалиста, обязательно проверьте, состоит ли порекомендовавший его сосед в вашем чате.
Надысь в очередной раз полилась вода из кухонной вытяжки (СПб). На плиту и духовку под ним. Это у нас раз в полгода повторяется - стыки вентшахты и плит перекрытия ни у кого не заделаны (дом 2021 постройки) и когда у кого-то в узле водоподготовки начнет течь, поток устремляется в шахту, а потом через спутник к нам.
Необычные звуки привлекли внимание, и оказалось, что это не кот блюет.
Звонок соседке сверху (уже топила год назад, фильтр рванул) выявил ее отсутствие в квартире, время прибытия - 40 мин. Позвонил в УК с докладом.
Визит УК в составе сантехника и дежурной выявил протечку в квартире над нами через этаж - потек стык счетчика и магистрали ГВС (ПВХ). Монтаж был год назад и вот, при отключении горячей воды стрельнуло.
Как самый страдающий от инцидента (льет на столешницу, варочную панель и духовку), решил добраться до виновницы и поинтересоваться перспективами решения проблемы.
Чуйка не повела - решение проблемы застопорилось. УКшный сантехник перекрыл кран ГВС в квартире и произнеся сакраментальное - ебитесь как ищите сантехника в открытых источниках, свалил в закат. Свое нежелание исправлять аварию мотивировал чрезвычайной загруженностью по решению общедомовых задач (частично присутствуют).
Как итог я остался один на один с охуевшей от обстоятельств хозяйкой и ее немым вопросом - а что дальше делать?
Меня, по правде говоря, волновал одно - через скока времени она не дай бог по какой-либо нужде снова откроет перекрытый кран и я опять пойму, что это не кот...
С другой стороны, было очевидно, что если хозяйка щас в Яндексе начнет искать сантехника, то ее не только разгрузят косарей на 20-30, но еще с высокой вероятностью нихуя не сделают.
А как вообще быть, если по итогу после проеба двух месячных пенсий ее накроет и под стрессом она перестанет открывать дверь, оставит открытым кран - это целый квест. Еще по разговорам с УК я понял, что перекрытие стояка парадной - проблема неординарная и пару часов мне придется скакать с кастрюлями. А вода из вытяжки в кастрюли падает с высоты, летят брызги и водичка просачивается в стыки варочной и столешницы. А она (столешница), пытается разбухать. В общем, я пообещал хозяйке попробовать найти проверенного сантехника через чаты ЖК, в которых состою, и передать ей.
Собственно, это была завязка.
Развитие.
В ТГ час нашего ЖК (1 121 рыл соседей) кидаю просьбу порекомендовать проверенного сантехника.

Через 5 минут прилетает первый добрый совет.
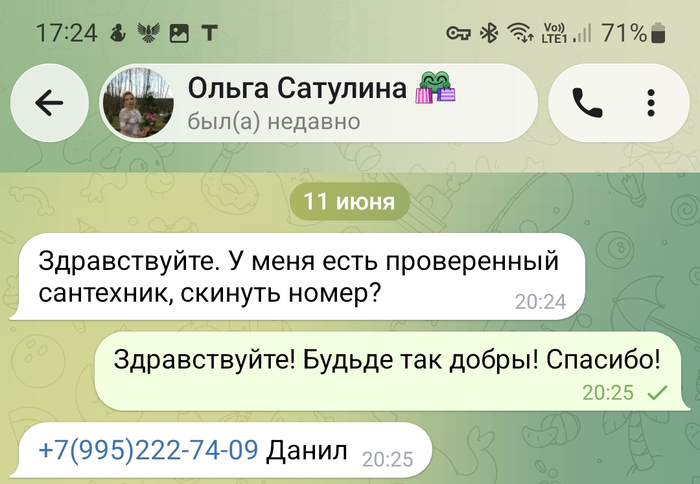
Благодарю и звоню по номеру...
Отвечает мужик, спрашивает суть проблемы (поверхностно), адрес, говорит, что завтра может помочь. Я начинаю объяснять, что заказчик не я и нужно связаться с клиентом... И звонок сбрасывается...
Пытаюсь перезвонить - не дозваниваюсь...
И чем бог миловал - через 3 минуты на мой номер начинаются звонки с 3 московских номеров с периодичностью в 2 минуты. Звонящий - "мы вот тут с вами общались, звонок прервался, я перезваниваю..."
Только вот голоса звонящих похожие, но разные и по наводящим вопросам им они не в курсе контекста первого разговора, который прервался.
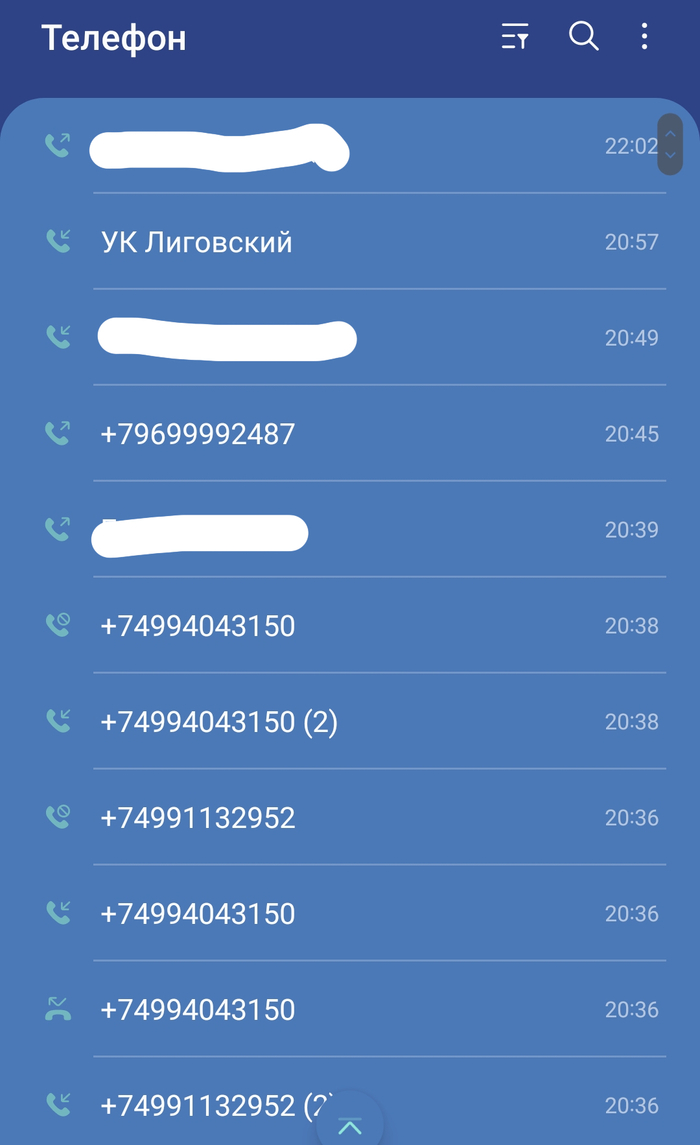
Все кроме замазанных (затопившая соседка) - МСК
Хуясе, думаю. Ищу в поиске по чату соседку с переданным мне контактом сантехника и не нахожу - в домовом чате, где я писал просьбу поделиться им, ее нет. Блочу эту соседку в ТГ, через 3 минуты шквал звонков из Москвы прекращается.
Тут небольшой оффтоп про психологию - мне очень хотелось проверенного сантехника назавтра чтобы решить проблему. И когда прилетело второе сообщение от соседки с номером сантехника, я туда позвонил.
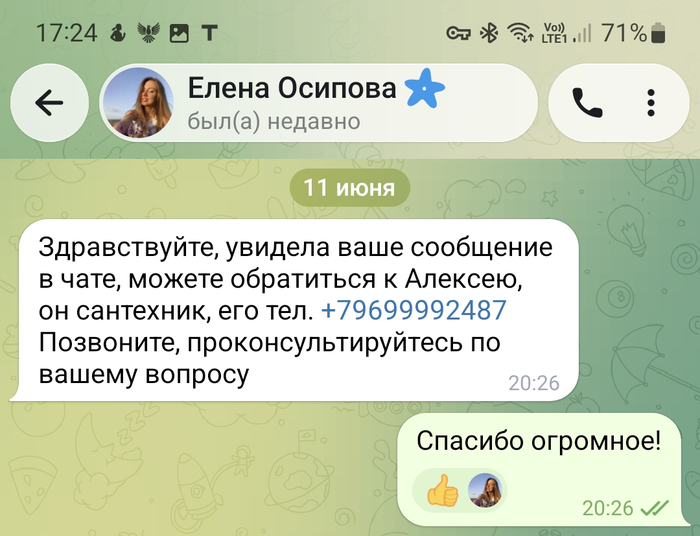
Там диспозиция была другая. Человек сразу спросил, у кого течь. Я объяснил, что у соседки сверху. Он попросил ее телефон (логично). Я дал.
Сижу, и думаю... бля... Ищу вторую "соведку" в чате ЖК - хуй!
Звоню затопившей меня мадам, объясняю ей весь расклад. Ей второй мастер уже позвонил, договорились на завтра на утро чинить. Но топившая меня мадам оказалась сообразительной - "Вы знаете, Алексей, меня смутило что номер, с которого этот сантехник звонил, отображается как Московский."
Кароче, мы с ней договорились, что она звонит туда и отменяет заказ. На случай, если начнут наезжать, говорит, сто пришел сантехник из УК и все починил. Отменила, наутро никто к ней не приехал (отдельно предупредил, что если заказанный и отмененный специалист с утра начнет к ней ломиться, слать его нахер и в квартиру не пускать).
Вот такой пердомонокль в социальной инженерии, дорогие Пикабушники.
ПС1. Где искать сантехника? Пошел в УК, долго ругался, мотивируя тем, что не устраняя проблему в индивидуальном узле, они создают длящеюся аварию, приносящую ущерб имуществу собственным жильцам. В результате УКшный сантехник согласился исправить проблему, что на следующий день и выполнил.
ПС2. Как такое возможно?
На это есть несколько версий:
1. Сетевые конторы парсят чаты ЖК с большим числом участников. Таких ЖК в 16 городах-миллионниках, по всей видимости, больше 10 000. Но чтобы их парсить, вы должны туда вступить. Это не всегда просто, т. к. иногда для этого требуется не только обойти бота с капчей, но и пройти ручную модерацию. Но тем не менее такой вариант вполне рабочий.
2. С п. 1 есть такая проблема - в собственном чате я месяц назад прокинул тему про ВПН (просто была фраза "MTPProxy") и через 5 минут нам прилетела реклама его от вновь вступившего пользователя.
Ту без вариантов про парсинг - в канале 70 делб (включая модераторов Пикабу) (извинити) пользователей и он ни при каких обстоятельствах не мог попасть в списки для парсинга.
И это точно не популярные боты-помощники типа ChatKeeperBot - у нас он не установлен.
3. Поэтому есть высокая доля вероятности, что ключевые слова в частных чатах ТГ продаются. Кем (самим ли ТГ или канторами на аутсорсе за комиссию, не важно). Главное - будьте бдительны!
Если вы обратившись в чат к своим казалось бы реальным соседям (которые вряд ли вас обманут), будьте готовы их проверить хотя бы на регистрацию в чате, куда вы обратились.
ПС3. Наутро (через 12 часов после обращения в домой чат) прилетел 3-й контакт сантехника от доброй соседки. Тоже не в домовом чате, перезванивать по номеру не стал.
КМК, присутствуют несколько моделей наебки:
1. TG, по всей видимости, сливает ключевые слова из чатов (см. ПС2). Но услуга дорогая, не все, похоже, могут ее себе позволить.
2. Парсинг - 3-й лже-контакт от "соседки" через 12 часов после просьбы очень похож на обычный парсинг без привлечения TG.
Как вывод - будьте, пожалуйста, бдительны. Особенно если вы вызываете специалиста не себе, а маме, соседке или забухавшему другу. Проверьте (позвоните сами как будто это вы и есть заказчик) не только его регистрацию в чате, где он вам написал, но и попытайтесь пообщаться - как правило бот заглючит и начнет нести противоречивые тезисы при обсуждении предметных и сложных обстоятельств вашей проблемы.
ПС4. @Chatlanka просила меня не доебываться до Пикабушников попусту, но тут я попрошу нашего уважаемого @nestandart2886 прокомментировать, сталкивался ли он с похожими ситуациями и что он по этому поводу думает.
Резюме.
1. В общедомовые чаты все-таки стоит обращаться за помощью, если у вас срочная проблема. Это, скорее всего, более эффективный путь, чем обращаться в конторы, выдаваемые в первых списках Яндекса или других поисковиков. Принцип простой - первые места в выдаче поисковиков очень дорогая услуга, которая вряд ли окупается оказанием качественной работы за вменяемую цену. Скорее всего - это сетевые конторы, которые начнут вас разводить на сумасшедшие деньги, причем не факт, устранив реальную проблему.
2. После получения в чате контакта специалиста:
2.1. Проверьте, состоит ли рекомендатель в чате вашего ЖК
2.2. Если состоит, насколько активен он был в общении (если он не общался в чате - не публиковал сообщения), есть повод задуматься.
2.3. Если вы все же решили позвонить этому мастеру, попробуйте подгрузить его лишними обстоятельствами, усложняющими ему ответы по "скрипту". Типа: я еще не до конца определился, нужна ли мне ваша услуга (жду ответа от сантехника от УК). Но позвонил, чтобы узнать ваши условия... При такой формулировке у "специалиста" может поплыть скрипт и он может начать произносить вещи, не соответствующие логике вашего запроса на услугу. Например: "Ну и что, что сантехник от УК еще не решился, я приеду - просто посмотрю, бесплатно." Это 100% спам о обман, не ведитесь на это.
Если вы вдруг ляпнули, что согласны на услугу, а потом до вас дошло, что что-то не так, не стесняйтесь перезвонить на номер, по которому вы общались и отменить заказ.
Если дозвониться не удалось, ни в коем случае не пускайте "мастера" в квартиру когда он по вашей заявке придет. Через закрытую дверь объясните, что заказ вы отменили и в услугах не нуждаетесь. При слишком назойливой попытке проникнуть к вам, предупредите, что вы вызовете полицию по поводу незаконного проникновение в ваше жилище. Если прессинг вас не прекратится, вызывайте полицию - неизвестный вам человек штурмует вашу дверь и требует ее открыть.
3. Если от соседей ничего кроме спама не пришло, идите в УК. В каждой УК (ТСЖ) должен быть дежурный сантехник (время прибытия на аварию - 2 часа). Формально, УК не обязана устранять повреждения за пределами ее зоны ответственности (как правило после счетчика). Однако вы можете настаивать на том, что вам достоверно не известно, находится ли дефект в зоне ответственности вашей или общедомового имущества. И при прибытии специалиста при известной силе убеждения (и аргументации, что его невмешательство произведет значительный ущерб другим собственникам), а также факта того, что внутриквартирную вашу проблему он будет устранять на коммерческой основе, скорее всего, попробуйте убедить его оказать необходимую вам услугу.
4. Надеюсь, участники Сообщества накинут еще достаточно здравых советов как решать указанную проблему.
Все всех благ.
Пропущенный пост скоро появится - уронил систему, почти восстановил.