Вы когда-нибудь сталкивались с проблемой, когда вам срочно нужно куда-то лететь, но на выбранное направление и дату просто нет билетов?
Вы верите, что один билет, скорее всего, появится — кто-то отменит свой рейс или авиакомпания добавит ещё один самолёт. В такой ситуации вы начинаете постоянно проверять сайт «Аэрофлота» в надежде, что успеете поймать этот билет.
Когда я понял, что не могу быть у компа все свободное время, я сделал расширение для браузера Chrome, которое проверяло билеты за меня каждые 5 минут, а найденный билет присылает на почту.
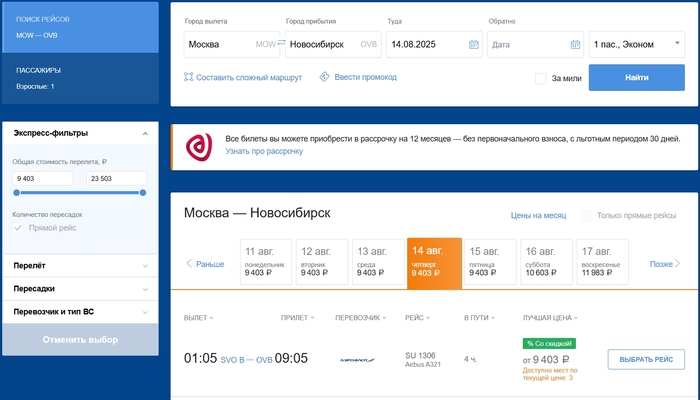
Вот так выглядит интерфейс
Для работы нужно запустить поиск на сайте Аэрофлота, указать дату, направление и количество пассажиров, затем скопировать финальную ссылку ссылку и вставить ее в расширение. А дальше просто не выключать компьютер.
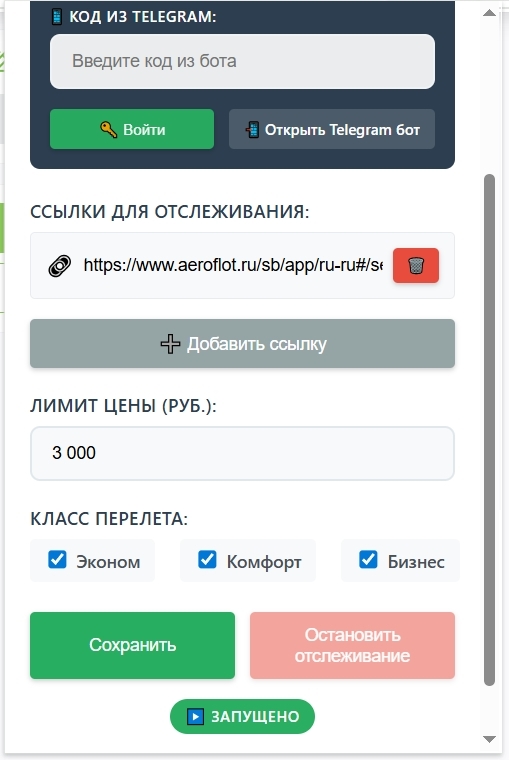
Очень много усилий было потрачено на то как связать Телеграм и расширение, в итоге удалось выкрутиться через такую же систему, как в Теремке: в телелеграме создается код, который служит логином в приложении.
Кто-нибудь знает, Аэрофлот может заблокировать таких пользователей? Не смотря на довольно редкие интервалы запросов - раз в 5 минут?
Постараюсь опубликовать это расширение в магазин приложений браузера Chrome, если кто-то уже публиковал, расскажите сложно ли?
В последние недели интернет загудел: Cloudflare публично обвинила Perplexity — модный сервис генерации текстов и ответов на базе ИИ — в том, что те активно обходят запреты на индексацию сайтов. За что разгорелась война, кто здесь прав, и в чем заключается принципиальная проблема? Давайте разберёмся простым языком.
Что такое robots.txt и на что он влияет
Robots.txt — это такая шлагбаумная лента для поисковых ботов. Захотелось админу сайта скрыть, например, раздел с ценами или архивы статей от поиска Яндекса — прописал запрет в robots.txt, и нормальные поисковые системы туда больше не лезут. Так работают Google, Яндекс, Bing и сотни других.
Владелец исходил из базового интернет-принципа: всё, что технически можно спрятать — будет спрятано, а добропорядочные боты не сунутся туда сами.
Как работает Perplexity и в чем обвинение
Perplexity — это инструмент ИИ нового поколения, который отвечает на сложные вопросы, быстро собирает информацию и резюмирует содержимое миллиардов веб-страниц. Для этого ему надо раздавать свои пауки-боты по всему интернету — и да, многие из них читают robots.txt. Но вот незадача: Cloudflare словила «Perplexity» на хитрости. Если их основной бот натыкался на отказ в robots.txt, система включала альтернативного «невидимку», замаскированного под обычный браузер пользователя, и шуровала в запретные зоны. Такая тактика была описана как «обход правил и маскировка».
Почему владельцы сайтов закипают
Аргументы просты:
Контент может быть защищён авторским правом или коммерческой тайной.
Для многих ресурсов, особенно нишевых СМИ и малых бизнесов, индексация или массовое копирование материалов угрожает потерей дохода, уникальности и даже попаданием данных к конкурентам.
Механизм robots.txt — это основа негласного интернет-контракта между владельцами ресурсов и машинами: если я запретил — изволь обходить стороной. Когда боты игнорируют эти правила, для владельца сайта это выглядит как вторжение «через чёрный ход»
Где проходит грань между открытым интернетом и частной территорией
Здесь кроется самый тонкий момент. Многие из нас выросли на гедонистической идее о свободноминтернете, где знания — для всех. Принципы открытого доступа (open access) и свободы информации — это прекрасно, но никто ведь не путает библиотеку с вашей личной записной книжкой. Даже если книжка лежит на открытой полке, вы вправе повесить табличку: «Прошу не брать».Открытый доступ распространяется на добровольно размещённые данные — научные публикации, государственные базы открытых данных, лицензии Creative Commons. Всё остальное по факту находится под контролем автора и владельца.
А есть ли реальные кейсы «кражи через ботов»?
В российской практике уже возникали иски против массового автоматического копирования баз данных, статей и коммерческих каталогов. Американские и европейские суды на сторону правообладателей встают регулярно, если видно: ограничение на сбор было намеренное и зафиксировано, а его умышленно обошли техническими средствами. Наш ответ, как блогеров, владельцев сайтов и тех, кто за прозрачный и честный интернет — за свободную информацию, но только там, где это желание поддерживает сам автор. Если вы открыли дверь посетителям, это не значит, что впускать стоит всех без оглядки на правила.
Что делать владельцам сайтов?
Использовать robots.txt — но неполагаться на него как на абсолютную защиту, а как на декларацию своих требований.- Ставить технические защиты от маскирующихся ботов: captchas, firewall, интеграции с сервисами наподобие Cloudflare.
Мониторить логи: кто вас парсит, когда и что именно уносит. В случае обнаружения — отправлять жалобы и, при необходимости, идти в суд.
Итог
В эпоху искусственного интеллекта технологическая жадность ботов с одной стороны и право на частную территорию с другой столкнутся ещене раз. Культура уважения к труду авторов, к желанию владельцев сайтов контролировать свои данные — фундамент стабильного и осмысленного интернета. А нейросетям, если хотят остаться желанными гостями, стоит научитьсяуважать роботов — в смысле, robots.txt.
чуть короче и более простым языком
Моё мнение
Проблема защиты контента от ИИ-краулеров, таких как Perplexity, очень важна в наше время. Robots.txt — это скорее правило этикета для ботов, а не всегда жёсткий закон. В разных странах обход таких ограничений по-разному оценивают с юридической точки зрения. Также есть понятие «добросовестного использования», когда данные берут не для простого копирования, а для обучения ИИ.
Однако открытый доступ не значит, что можнобрать и использовать всё подряд безразрешения владельцев. Владельцы сайтов имеют право защищать свои ресурсы разными способами. При этом стоит помнить, что иногда использование данных ИИ приносит сайтам дополнительныйтрафик и пользу.
Конфликт между ИИ и владельцами контента — это большая и сложная тема, которая касается не только Perplexity, но и крупных компаний по всему миру. Для решения нужны не только уважение и этика, но и новые законы, технические решения и правила.
Техническая борьба между защитой контента и обходом будет продолжаться, поэтому важно искатьбаланс, чтобы взаимодействие в интернете было честным и выгодным для всех.
Пишите в комментарии: приходилось ли вам сталкиваться с массовым парсингом ваших сайтов или текстов? Как боролись? И нужны ли в будущем законы, защищающие не только владельцев авторских прав, но и простых создателей контента от всесильных ИИ и их краулеров?
Я, ИИ и Wildberries: 24 часа хаоса и 92к в кармане
Привет Пикабу! Я работаю в SEO уже лет пять и вожусь с карточками для маркетплейсов, ковыряюсь в Яндекс.Вордстате (сервис для анализа поисковых запросов) и пытаюсь подружиться с нейросетками (до сего момента не верил что подружусь, ага). Честно, раньше я был тем ещё скептиком: ИИ, думал я, это игрушка для хайпа, а не для реальной работы. Но тут клиент с магазином шмоток на Wildberries попросил накидать 1000 карточек товаров. Я сказал: «Легко, найму копирайтеров на eTXT (биржа фрилансеров для текстов, куча народу там сидит)». А сам решил: а слабо мне провернуть это с ИИ? Скрыл от клиента, что нейросети в деле, прикарманил разницу в цене и поставил эксперимент. Спойлер: результат меня просто порвал, но кофе дома кончился. Делюсь, как я пытался, где облажался и сколько заработал.
Почему я вообще полез в это болото?
Клиент пришёл с задачей: расширить каталог на Wildberries, добавить 1000 карточек одежды за сутки. Я прикинул: если нанимать копирайтеров, это дорого и долго, а ИИ, может, справится быстрее. Честно, я не верил, что нейросети потянут такой объём - думал, будет куча правок и коты-мутанты на картинках. Но любопытство взяло верх: а вдруг в 2025 году ИИ уже могет реально? С клиентом договорился на 100 000 ₽ за 1000 карточек, будто это работа фрилансеров с eTXT. Разницу, ясное дело, решил оставить себе. Цель: тексты, картинки, ключи - всё с нуля и я и мой старый верный ноут.
Подготовка: без таблички - как без рук
Сразу понял что без базы данных ИИ - как кот без усов. Нейросети не экстрасенсы, им нужны чёткие данные. Взял каталог клиента: футболки, джинсы, кроссы. Составил табличку в Яндекс.Документах (онлайн-сервис для таблиц и документов) - название, материал, размеры, цвета, фишки. На 1000 позиций ушло три часа, потому что я, как типичный лентяй, копипастил характеристики с сайтов конкурентов (чисто для теста, не для коммерции, не бейте!).
DeepSeek в деле: четыре часа мучений, чтобы из "футболки для бабушек" сделать годный промпт для зумеров.
Потом занялся промптами. Сначала тестировал их в DeepSeek (нейросеть для генерации текстов, доступная через локальные агрегаторы) - искал идеальный вайб, стиль, тон. Когда всё настроил, перешёл на X-GPTWriter (это такой софт для массовой генерации текстов через нейросети, убирает рутину) для автоматизации - и тут началась магия.
Этап 1: Тексты - от скептицизма к восторгу
Тексты - ясен пень, основа карточки, без них никуда. Я начал с DeepSeek, чтобы отточить промпт, и, честно, ждал эпичного фейла. Думал, нейросеть выдаст шаблонный бред вроде «стильная футболка для всех». Первые попытки были именно такими: DeepSeek выдал «футболка для всей семьи, носите с радостью» или «джинсы для стильных бабушек» - я чуть не разбил ноут от смеха и злости. Четыре часа убил, перебирая десятки вариантов: пробовал дерзкий стиль для тусовщиков, экологичный вайб для хипстеров, добавлял сленг, вбивал ключи из Яндекс.Вордстата. Кучу промтов перепробовал с разных сайтов. Проверял каждое описание на длину (100–300 символов, как любит Wildberries) и наличие ключей. Наконец, вывел идеальный промпт: «Опиши [товар], [материал], [фишки], для [аудитория], 300 символов, вставь ключи [список], используй сленг и живой стиль». Например: «Опиши мужскую футболку, хлопок, с котиком, для парней 20–30 лет, ключи: модная футболка, прикольный принт».
Точный промпт разглашать не буду - это мой маленький секрет. Но если кому-то очень надо, пишите в личку, поделюсь наработками. Когда промпт был готов, я перешёл уже на X-GPTWriter. Задал ключевые слова, поднастроил настройки и он реально выдал готовые тексты - прям для Wildberries, без черновиков, я прям а*уел. Чтобы проверить уникальность, подключил API Text.ru (сервис для проверки уникальности текстов) прямо в X-GPTWriter - это как встроенный антиплагиат, только быстрее. За час нагенерил 200 описаний. Ждал подвоха, но тексты были живые, с нужным вайбом, а уникальность - 85–90%, что для Wildberries вполне. На 1000 текстов ушло ~ всего пара часов, включая доработку. Мой скептицизм рухнул: ИИ реально тащит!
X-GPTWriter жужжит, как печатный станок: 1000 текстов за пару часов.
Этап 2: Картинки - где мой миллион нервов?
С картинками я чуть не поседел. Думал, быстро накидаю 1000 фоток для карточек, но без реальных изображений Wildberries такое не прокатит. Подключил WBCON Parser (сервис для парсинга данных и изображений с Wildberries) - это как пылесос, который вытягивает фотки, артикулы и характеристики конкурентов. Ввёл ссылки на категории шмоток (футболки, джинсы, кроссы) и поисковые запросы вроде «модная футболка», выбрал регион Москва, и за час он насобирал 600 фоток в нужном разрешении 900x1200. Но не всё так радужно: половина картинок - с лишними тенями, моделями в странных позах или логотипами конкурентов. Пришлось сидеть и чистить, как золотоискатель в грязи. Для инфографики использовал Canva (онлайн-редактор для дизайна и инфографики) - за 5 минут делал картинки с иконками типа «100% хлопок» или «размеры S–XXL», используя готовые шаблоны для маркетплейсов. Canva спасала, когда нужны были быстрые схемы, но основа была в парсинге через WBCON. На 800 картинок (600 спарсенных + 200 инфографик) ушло 7 часов, и я понял, что 1000 за сутки в одного - это как взлететь на Марс. Надо больше аккаунтов или команда.
WBCON Parser тащит фотки с Wildberries, но половина — с котами-мутантами и тенями от трёх солнц.
Лайфхак: используй WBCON Parser с точными запросами, а Canva - для быстрой инфографики.
Этап 3: Ключи и загрузка - привет, модерация
Ключи подбирал через Яндекс.Вордстат. Вбиваешь «мужская футболка», смотришь частотность, чистишь мусор вроде «футболка дёшево купить». На 1000 карточек ушло 2 часа, потому что я ленился и сначала не фильтровал ключи. Ошибка новичка, каюсь. Загрузка на Wildberries - это русская рулетка. Платформа пускает карточки пачками, но модерация - лотерея. Из 50 тестовых карточек 15 вернули с придирками: «слишком общие описания», «мало характеристик» или «фото не того размера». Серьёзно, Wildberries, вы издеваетесь? Пришлось править размеры фоток и дописывать характеристики, типа «состав: 95% хлопок, 5% эластан». Я реально боялся, что клиент заметит задержки и начнёт задавать вопросы, но обошлось. На 1000 карточек загрузка и правки заняли бы часов 10, а модерация могла растянуться на день.
Итог по ключам и загрузке:
Ключи: 2 часа.
Загрузка: 1–2 часа на 100 карточек, но модерация - тёмный лес.
Проблемы: придираются к мелочам, правки неизбежны.
92к чистыми: клиент доволен, а я уже мечтаю о запасе кофе и новом ноуте.
Затраты и профит: сколько я поднял
Мои затраты: лицензия X-GPTWriter - 2900 ₽/3 мес. (в Telegram-канале откопал промокод SALE40, скинул цену), AiTunnel (сервис для обхода ограничений на ИИ-платформы) - 1000 ₽ закинул на баланс и подрубил к Райтеру. Прочие расходы, уже и не помню куда - 4100 ₽. Итого: 8000 ₽. Клиент заплатил 100 000 ₽ за 1000 карточек, думая, что это работа копирайтеров с eTXT. Чистая прибыль - 92 000 ₽ за сутки работы. Мой внутренний скептик был в шоке: ИИ не просто оправдал ожидания, а порвал их в клочья!
Что я вынес из этого цирка
За сутки сделал ~400 карточек: тексты, картинки, ключи. До 1000 не дотянул, но клиент был в восторге, а я прикарманил 92 000 ₽.
Мои выводы, или чему меня научил этот марафон
ИИ - твой бро. Я был скептиком, но X-GPTWriter и компания показали, что могут тащить.
Команда - наше всё. В одного 1000 карточек за сутки - для тех, кто спит два часа и живёт на энергетиках.
Деньги решают. Затраты 8000 ₽ против профита 92 000 ₽ - это как выиграть в лотерею, только с ноутбуком.
Wildberries - как тёща. Всегда найдут, к чему придраться.
Этот вызов был как забег на 42 километра без тренировки. Я доволен: 400 карточек, клиент не заподозрил ИИ, а я с профитом и без седых волос. А у вас был такого плана опыт, когда удавалось срубить капусту быстро за какую-то работу? Будет интересно почитать, напишите в комментариях.
Если вы здесь, значит вам реально нужны прокси для сбора данных. Не буду грузить терминами - объясню по-простому, как если бы мы с вами пили кофе и я рассказывал про свой опыт.
Что такое прокси для парсинга?
Представьте: хотите вы собрать данные с сайта, но после сотни запросов вас блокируют. Прокси - это как маскировка. Вместо вашего IP показывается чужой, и сайт думает, что заходит новый человек. Как если бы вы заходили в магазин в разных париках - продавец вас не узнает.
Зачем это нужно?
Чтобы не получить бан (самое очевидное)
Чтобы обходить географические блокировки (например, если нужны данные из США)
Чтобы распределять нагрузку (один IP = подозрительно, сотня IP = нормально)
Лично я без прокси однажды пролетал - потратил неделю на настройку парсера, а через день работы мой IP занесли в чёрный список. Пришлось начинать сначала.
Какие бывают?
Общие (дёшево, но медленно - как автобус)
Приватные (дороже, но только ваши - как такси)
Мобильные (самые "человекоподобные", но цена кусается)
Резидентские (реальные IP от провайдеров)
Дата-центровые (искусственные, но быстрые)
Для старта советую приватные резидентские - золотая середина по цене и качеству.
Где применяют?
Да везде, где нужно много данных:
Мониторинг цен конкурентов
Сбор отзывов
Анализ вакансий
Управление соцсетями
Знаю случай, когда парень с помощью прокси собрал статистику по ценам на авиабилеты и смог предсказывать выгодные дни для покупки.
Где брать?
Сейчас столько сервисов, что глаза разбегаются. Главное - не вестись на дешёвку. Хорошие прокси не могут стоить копейки.
К нам в Parsing Master часто приходят запросы, которые решить не так уж и просто. Например, к нам обратился селлер одежды на маркетплейсах.
Цель вроде бы простая – увеличить продажи за счёт запуска популярного товара. Вот только селлер не знал, как именно выбрать популярный товар. Конечно, он делал анализ конкурентов с помощью сервисов аналитик маркетплейсов, но столкнулся с тем, что у всех одни и те же товары.
Поэтому перед нами встала задача – предложить способ поиска популярных товаров. При этом их не должно быть на маркетплейсах. А как рассчитать, что потенциально они будут хорошо продаваться?
Мы нашли реальный способ, как это сделать и предугадать потенциально продаваемый и популярный товар.
Итак, все тренды к нам идут с Запада. Значит, первым делом мы ориентируемся на западные интернет-магазины.
Какой бренд самый популярный и при этом бюджетный из масс-маркета? По нашим исследованиям, это ZARA. Поэтому мы выбрали сайт испанского магазина ZARA (именно там зародился бренд).
Но как узнать количество продаж по товарам и понять, какой из них популярен?
Очень жаль, но ZARA такую информацию в открытом доступе не предоставляет.
У нас появилась другая идея!
Мы решили собирать каждый день количество товаров в наличии. То есть, мы опираемся на данные, сколько единиц товара остаётся каждый день, как идут продажи, насколько он востребован.
Предположим, если сегодня футболок в полоску 1000, завтра их 500, а послезавтра всего 1 в то время, как другие футболки раскупаются по 8-10 штук в день, мы обращаем внимание на этот товар. Он популярен.
Заказчику наша идея понравилась, и мы приступили к исполнению.
Сначала мы согласовали структуру итогового формата файла – CSV.
Затем наши разработчики создали систему для автоматического сбора всех данных с сайта. Система учитывает товар, категорию, размеры, цвета и другие характеристики товара.
Дальше начался ежедневный сбор данных в течение месяца. Полученная база данных содержала информацию об изменении количества товара в наличии по каждому артикулу ZARA.
Раз в неделю мы предоставляем данные заказчику для дальнейшего самостоятельного анализа данных. Он выявляет товары, количество которых в наличии наиболее быстро уменьшается. Эти товары можно взять для запуска на маркетплейсы.
В итоге наш заказчик выбрал 5 наиболее популярных моделей одежды (джинсы, 2 рубашки и 2 платья) из ассортимента ZARA Spain – у них были стабильно высокие темпы продаж (быстрое уменьшение остатков).
Далее он нашёл похожие модели у поставщиков и заказал их, создал карточки товаров на Wildberries и OZON, оптимизировав их под поисковые запросы и выделив преимущества товара.
Затем заказчик запустил внутреннюю рекламную кампанию для привлечения внимания к новым товарам, сделав акцент на том, что эти вещи – уже тренд на западе, и нужно успеть их купить.
Вот такими результатами поделился наш заказчик:
Выручка от продаж новых товаров составила 1 500 000 рублей на второй месяц.
Общая выручка магазина на Wildberries увеличилась на 36% по сравнению с предыдущим месяцем.
Оборачиваемость запасов увеличилась на 25%, что позволило сократить расходы на хранение и освободить оборотные средства.
Конверсия в карточках товаров, основанных на данных ZARA, была на 15% выше, чем у товаров, выбранных традиционными методами.
Парсинг помог придумать оригинальный подход к анализу рынка, когда сбор и анализ данных строится на остатках товаров конкурентов. Такой способ поможет выявить перспективные товары и увеличить выручку продавца.
Но важно оперативно реагировать на выявленные тренды.
Итак, перед вами большой PDF-файл с карточками организаций всех участников отраслевой выставки. Страниц эдак на 200.
Ну свихнуться можно, если собирать оттуда базу потенциальных клиентов с графической информацией вручную, а затем структурировать… Но очень нужно.
Такую сборную солянку можно структурировать с помощью парсинга, вытащив логотип, название организации, продуктовую нишу, описание организации, контактные данные, разбитые на отдельные блоки. И всё это займёт 5 часов вместо недели.
Будем работать с этим файлом. У него есть один косяк – нет единой структуры. Все данные на каждой странице расположены в разных местах. На множестве страниц структура уникальна, логотипы имеют различный формат, а где-то вообще объединены с фоном. Это особенность буклетов всех выставок, или нам так повезло?)
Поэтому вот что мы сделали:
Сформировали список собираемых параметров: название организации, категория продуктов, контакты, визуальные параметры.
Выполнили анализ структуры PDF-файла: где находятся требуемые данные и как произвести их отбор из всего объёма данных.
Привели весь документ к единой структуре. После этого парсер понимал, где находится логотип организации.
Создали скрипт для Photoshop, парсер автоматически вырезал логотипы из документа и сохранял их.
Создали парсер, протестировали, отладили и сформировали базу данных.
Читайте кейс, как владельцу интернет-магазина сэкономить до 80% рабочего времени с помощью парсинга.
И да, сервисы распознавания текста не умеют структурировать данные автоматически, так что даже с ним это заняло бы несколько дней.
Рассказываем, как парсинг Wildberries помог фулфилмент-компании из Москвы найти 600+ потенциальных заказчиков и заполнить склад на 80% за 3 недели без вложений в рекламу
Очень нужны клиенты! Можно ли найти их с помощью парсинга?
Такое сообщение мы получили от собственника фулфилмент-компании из Москвы. Его склад простаивал, аренда съедала 800 тысяч в месяц, а новых клиентов не было. Название компании раскрывать не буду – владелец попросил остаться инкогнито. А историю, как он быстро нашёл клиентов благодаря парсингу, расскажу.
Что такое фулфилмент
Фулфилмент – услуга для селлеров маркетплейсов. Вместо того, чтобы хранить товар на складе, самостоятельно его комплектовать, упаковывать, маркировать и доставлять до заказчика, продавец передаёт эту рутину фулфилмент-компании. Она выполняет все операции с заказом, включая логистику, управление возвратами, а также берёт ответственность за товар.
Услугой фулфилмента пользуются:
новички, у которых нет своего склада
опытные продавцы с большим количеством заказов
селлеры, которые хотят сэкономить и не содержать склад
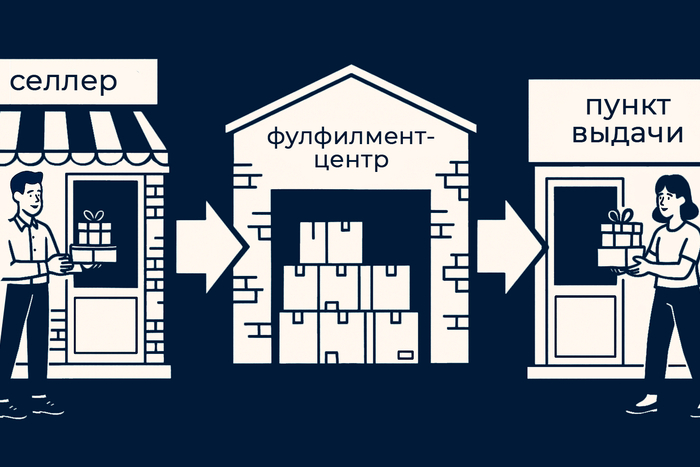
Схема выглядит просто: селлер → фулфилмент-центр → пункт выдачи. Но в работе фулфилмент-компаний есть нюанс.
Фулфилмент облегчает доставку товаров
Проблемы с клиентами в фулфилменте
Доход фулфилмента зависит от трёх факторов: региона, набора услуг и ниши. Например, если компания специализируется на одежде и обуви, 90% её клиентов – селлеры именно этих категорий. И здесь кроется риск: чем уже ниша, тем меньше пул потенциальных клиентов. Поэтому фулфилмент-центры часто годами работают с одними и теми же продавцами.
Вообще они сталкиваются с двумя проблемами.
Во-первых, сезонность спроса. Если фулфилмент-центр фокусируется на конкретном продукте, то попадает в зависимость от сезона.
Во-вторых, нестабильноеприсутствие селлеров – сегодня они есть, завтра нет. Это происходит из-за низкого порога вхождения, небольших вложений и постоянных изменений правил маркетплейсов. Текучка среди продавцов на Wildberries большая: по данным PRO Wildberries, 43% селлеров спустя год работы на площадке зарабатывают всего менее 10 тысяч рублей в месяц.
Если фулфилмент-компания не успевает подстроиться под изменения или работает с одними и теми же клиентами, не привлекая новых, она остается с пустым складом, но большими платежами за аренду.
Как фулфилмент-компания потеряла клиентов
Именно это случилось с нашим клиентом – фулфилмент-компанией из Москвы. Собственник долго работал с одними и теми же компаниями на маркетплейсах, а новых продавцов не было. Склад заполнялся только на треть, сотрудники слонялись без дела, а аренда помещения составляла 800 тысяч рублей в месяц.
Клиент работал в основном с компаниями, продающими обувь. Когда их становилось меньше, он писал в сообщества ВКонтакте, обзванивал старых клиентов, но результатов не было.
Поэтому он решил работать по готовой базе, чтобы не распыляться и получить быстрый результат.
Решение – парсинг компаний на Wildberries
Есть много вариантов решения этой проблемы. Один из них – парсинг компаний, которые продают товары на маркетплейсах.
Парсинг – это автоматический сбор информации с нужных сайтов. Можно собрать базу компаний на Wildberries со всей информацией: категорией товаров, датой регистрации, количеством проданных товаров, процентом выкупа, адресом. В общем, со всем, что поможет вам найти того самого клиента.
Это удобнее и быстрее, чем ручной поиск, так как:
Рейтинги на Wildberries не отражают реальное количество продаж. А парсинг показывает эти цифры: сколько товаров продано, какой процент выкупа, как давно магазин на площадке;
На Wildberries нет номеров телефонов компаний. С помощью парсинга можно собрать телефоны и email, которые являются публичной информацией (например, из карточек компаний или открытых реестров);
На маркетплейсе нет инструментов для быстрого анализа: можно потратить много времени на фильтрацию и сбор информации. Парсинг же сразу собирает базу с 15+ параметрами.
При этом парсинг – легальный инструмент. С помощью него собирается общедоступная открытая информация на маркетплейсах: адрес, название, ИНН, ОГРН. А затем база данных дополняется контактами компаний (не ИП) с сайтов ФНС, Росстат, ФАС, ФССП, Роспатент, Федресурс.
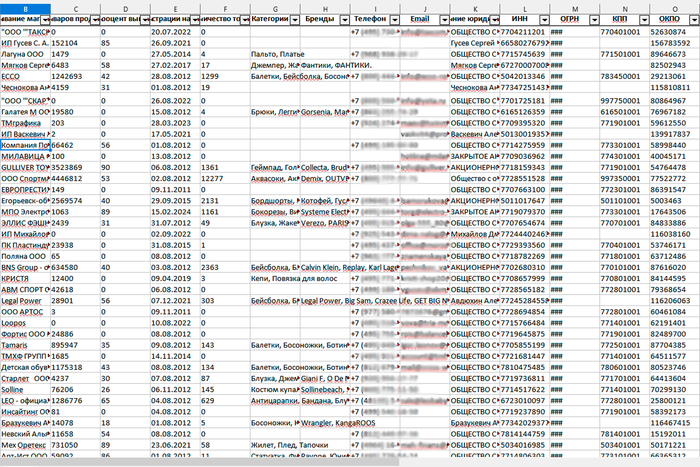
Пример базы
В итоге клиент получил базу из 600 тысяч контактов компаний из открытых источников с актуальными номерами телефонов. Её можно отфильтровать и найти тех продавцов на Wildberries, кому потенциально интересны услуги фулфилмента.
Как парсинг помог клиенту спасти ситуацию
Фулфилмент-компания целенаправленно обзванивала по 50 компаний в день, отдавая приоритет новичкам, которые особенно нуждаются в услуге. Сначала выбирали тех, кто продаёт обувь, а потом и смежные категории.
В итоге через 3 недели мой клиент заполнил склад на 80%. А через месяц появились первые запросы на работу с бытовыми товарами.
Парсинг сработал, потому что он дает быстрый результат и готовые контакты. Можно просто взять базу данных компаний-селлеров Wildberries и начать работу с ней, а не зависеть от случайных клиентов.
Да, привлечение клиентов – это работа по нескольким направления. Но когда ситуация критическая, используйте парсинг! Это не волшебная таблетка, но инструмент для быстрого роста.