Как рекуррентная память открывает новые возможности для LLM на примере Kimi K3

Kimi K3

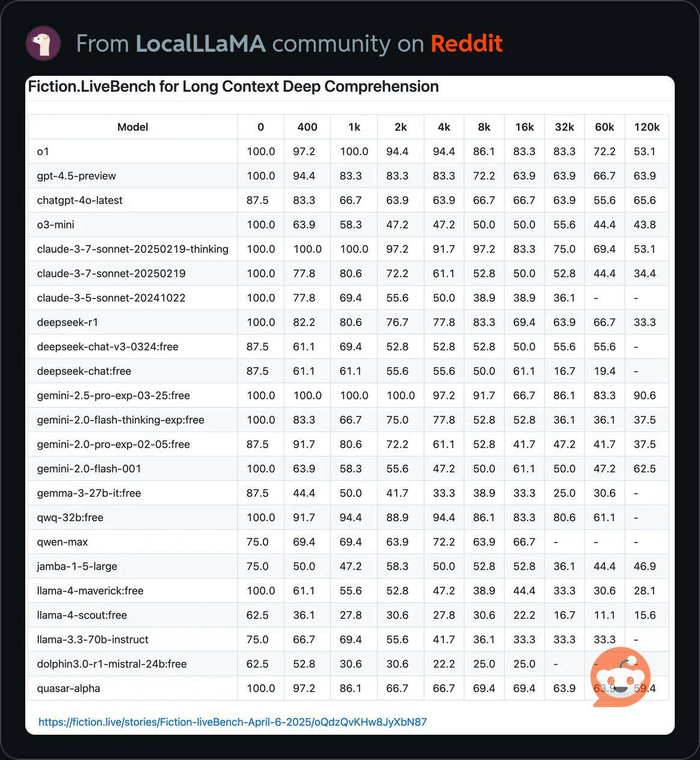
Бенчмарки
Moonshot AI сделали анонс Kimi K3, первой модели с открытыми весами, у которой больше 2.8 триллионов параметров. Эта модель, как было заявлено, превосходит по качеству флагманские пропиетарные модели – Claude Opus 4.8, GPT 5.6 Sol – в задачах по сложному кодингу типа оптимизации GPU-кернелов, и показывает производительность на уровне Fable 5.
В этой статье я попытался разобраться, на какие механизмы опирается одна из самых совершенных современных LLM-архитектур, так как нам впервые представляется уникальный случай видеть эти механизмы как они есть – веса Kimi K3 будут опубликованы 27 июля 2026 года.
Для начала немного истории – дело в том, что многие новейшие LLM, включая Kimi Linear, Qwen 3 Next, Nemotron 3 используют гибридное внимание: часть слоев реализована по принципу линейных рекуррентных моделей – Mamba, Gated DeltaNet, которые можно рассматривать как эволюцию более “древних” RNN. У некоторых облачных провайдеров есть каталог нейросетевых моделей. При подготовке статьи я использовал один из них.
Проблема последних была в том, что они хранили скрытое состояние буквально в одном векторе. Если состояние имеет размер 2048, то независимо от того, прочитала модель десять слов или миллион токенов, вся память упакована в один вектор из 2048 чисел. Возникает бутылочное горлышко. LSTM, обучением которых автор занимался шесть лет назад, сделали первую серьезную попытку решить проблему.
Вместо следующей схемы: новое состояние = полностью переписать старое.
Они предложили: новое состояние = немного забыть + немного записать
Преобразования, через которые проходит последовательность токенов в LSTM, включают forget gate, input gate и output gate.
Пусть:
x_t – вход в момент времени t,
h_{t−1} – предыдущее скрытое состояние,
c_{t−1} – предыдущее состояние памяти (cell state),
σ(x) = 1/(1+e^(−x)) – сигмоида,
tanh(x) – гиперболический тангенс.
Тогда первым делом LSTM вычисляет, какую часть памяти сохранить (forget gate):
F_t = σ(W_f*x_t + U_f * h_{t−1} + b_f)
Где W_f – веса для входа, U_f – рекуррентные веса, b_f – байас.
Input gate определяет, какая новая информация будет записана, вычислив сначала маску записи:
i_t = σ(W_i * x_t + U_i *h_{t − 1}+b_i)
Что уже позволяет вычислить кандидат на новую память:
~c_t = tanh(W_c * x_t + U_c * h_{t−1} + b_c)
И далее происходит главное, старая память частично забывается и заменяется новой:
c_t = f_t ⋅ c_{t − 1} + i_t ⋅ ~c_t
Наконец, output gate определяет, какая часть памяти станет скрытым состоянием:
o_t = σ(W_o * x_t + U_o * h_{t−1} + b_o)
И вычисляется новое скрытое состояние:
h_t = o_t ⋅ tanh(c_t)
На практике не стоит говорить “Сначала вычисляется это, потом другое”, потому что линейные преобразования происходят разом в виде эффективно распараллеленного матричного умножения на GPU –
z = W * concat(x_t, h_{t-1}) + b
А результат уже разбивается на четыре части:
f_t = σ(z_f)
i_t = σ(z_i)
~c_t = tanh(z_c)
o_t = σ(z_o)
Где z_f, z_i, z_c, z_o это просто непрерывные сегменты одного большого вектора z. И хотя по сути это всё еще один вектор, но его умная перезапись, управляемая тремя gate, позволяет LSTM хранить информацию значительно дольше обычной RNN. “Умная” – потому что значения каждого gate определяются обучаемыми весами (LSTM обучается тому, какую информацию можно забывать, а какую стоит сохранить).
Интересно, что идея использовать для “долговременной” непрерывно обновляемой памяти не просто вектор, а полноценную матрицу весов, появилась даже раньше. Один из авторов LSTM – Шмидхубер еще в начале 90-х предложил именно такую идею: вместо вектора сделать память матрицей. Эта матрица постоянно обновляется,
то есть сеть буквально изменяет собственные веса во время инференса. Не основные веса модели, а специальную временную память. Это называли Fast Weights. Идея была красивой и переносила в математическую модель процессы, которые в действительности происходят в долговременной памяти мозга, но на практике LSTM оказалась эффективнее, решая ту же проблему проще и стабильнее. Однако идея изменяемых в процессе инференса весов со временем снова появилась на горизонте языковых state-of-the-art моделей. После появления механизмов внимания многие исследователи заметили, что self-attention очень похож на современную интерпретацию Fast Weights. В частности, обновление fast weights через внешнее произведение hh^T напоминает запись пар key–value, матрица внимания фактически играет роль быстро изменяемой памяти. В 2016–2022 годах появилось несколько работ, переосмысливающих attention как разновидность Fast Weight Programmers. Сам Шмидхубер неоднократно отмечал, что считает современные механизмы внимания развитием идей Fast Weights.
Однако в attention структура данных динамическая, в этом ее преимущество и главный недостаток. Каждый токен записывает векторы Key и Value. Когда приходит Query, мы ищем похожий Key, получаем соответствующий Value.
Это тоже ассоциативная память, только она постоянно растет. Вместе с длиной последовательности растет объем памяти под key-value кэш, для полного внимания это существенная проблема вычислительной сложности, которая составляет O(N^2) по отношению к длине последовательности.
DeltaNet делает следующий шаг: вместо хранения всех Key/Value она хранит одну матрицу памяти M, и каждый новый токен обновляет её.
Вместо:
K1 -> V1
K2 -> V2
K3 -> V3
Получается:
M0 → M1→M2→M3, это уже линейная сложность O(N). Размер матрицы постоянный. Таким образом, DeltaNet / Gated DeltaNet и ее прямое продолжение в лице Kimi Delta Attention – это современное поколение линейных рекуррентных сетей, которые возвращают к жизни идею обновляемых в процессе инференса весов и таким образом привносят в LLM компактную долговременную память.
Что именно хранит M? Это не просто скрытое состояние, матрица M гораздо ближе к таблице соответствий. Если сильно упростить, то M ≈ сопоставление Key → Value, то есть если приходит запрос Q, то ответ получается Q × M – это линейное преобразование, поэтому DeltaNet относится к классу линейных рекуррентных моделей, в отличие от той же LSTM (выше мы видели, что для вычисления h_t в ней используется tanh), или от внимания, в котором нелинейной составляющей является софтмакс. Тем не менее, это очень похоже на обычное Attention(Q,K,V), только вместо хранения всех K и V мы имеем их сжатую статистику.
Нельзя не коснуться вопроса, как в этой модели обновляется память. Вот здесь появляется delta rule. Допустим, новый токен имеет Key k и Value v.
Мы хотим записать:
k → v
Но память уже что-то знает. Сначала она делает прогноз:
v' = M_k
То есть – "что я сейчас думаю по поводу этого ключа?" Далее вычисляется ошибка:
error = v-v'
Именно отсюда происходит слово Delta.
Затем память исправляется:
Обновление имеет вид примерно
M_{t+1} = M_t + (v−M_t * k)k^T
Глубокая идея в том, что мы не переписываем память полностью, мы исправляем только ошибку, то есть память ведет себя как онлайн-обучаемая линейная модель.
Оригинальный DeltaNet имел один недостаток. Каждый токен обновлял память примерно одинаково, а это опасно. Представьте книгу: каждое новое предложение немного меняет содержание всей книги. Через миллион токенов всё размоется. Поэтому появилась Gated DeltaNet с несколькими gate – идея практически такая же, как у LSTM. Появляется коэффициент g, который говорит, записывать или не записывать. Фактически обновление становится
M_{t+1} = M_t + g_t(v − M_t *k)k^T
Если g=0, ничего не происходит, если g=1, происходит полная коррекция.
Gated DeltaNet отлично показала себя в гибридных LLM поколения Qwen3 Next. Это не попытка заменить attention «другим attention», а скорее возвращение к идее рекуррентной памяти — но с гораздо более выразительным внутренним состоянием и механизмом обновления, вдохновлённым как классическими RNN (через gate), так и алгоритмами онлайн-обучения (через delta rule). Именно поэтому Gated DeltaNet можно рассматривать как своего рода «LSTM с ассоциативной матричной памятью» — аналогия не точная математически, но очень полезная для понимания принципа работы.
Здесь уже остался буквально один шаг до Kimi Delta Attention. KDA добавляет следующий уровень управления. Вместо одного скалярного коэффициента g_t используются поканальные коэффициенты (channel-wise gating), поэтому разные части памяти могут обновляться с разной скоростью. Кроме того, в архитектуру добавлены более эффективные способы организации памяти и вычислений, что делает её масштабируемой для очень длинных последовательностей.
Kimi K3 в своей архитектуре имеет еще одно нововведение – Attention Residuals (не стоит путать с residual connections в трансформере, которые в MLA слоях Kimi K3 тоже присутствуют). Линейное внимание обычно предлагает механизмы, компенсирующие в той или иной мере недостаток точности по сравнению с полным вниманием трансформера – ведь, как ни крути, матрица фиксированной памяти в KDE – это приближенное представление реальных зависимостей между токенами, и чем длиннее последовательность, тем существеннее фактор этого приближения. AttnRes – это один из таких компенсирующих механизмов. Его смысл в том, чтобы обучить небольшой блок обычного внимания трансформера вместе с KDA, как остаточную функцию (отсюда слово Residual), которая исправляет ошибку KDA, если таковая присутствует.
(y_t)^Res ≈ y_t - (y_t)^KDA
Чем больше ошибка KDA, тем больше градиент получают веса AttnRes, и модель учится использовать сигнал именно этого блока для таких случаев, на которых KDA дает слабину. Это узкий спектр задач на поиск и точное копирование фрагментов данных, редких токенов и т.д. В большинстве же случаев, когда KDA сам выдает достаточно малый Loss, AttnRes получает малые градиенты и соответственно мало участвует в предсказании для задач этой области.
Вывод:
Таким образом, за счет компактности и выразительности линейной рекуррентной памяти гибридная архитектура Kimi K3 позволяет выполнять инференс на весах невиданного ранее масштаба и с огромными контекстами. Память, которая обновляется непрерывно онлайн и при этом не разрастается вместе с контекстом, является приближением к биологическому механизму долговременной памяти, по сравнению с классическими трансформерами. Именно теперь буквальный смысл названия модели LSTM – Long-Short Term Memory – становится наконец реальностью.