Microsoft готовит капитальный ремонт Copilot, и происходит это ровно в тот момент, когда компания официально перестала зависеть от OpenAI. В августе 2026-го выйдет единое приложение Copilot вместо нынешнего разделения на потребительскую и корпоративную версии. Об этом сотрудникам рассказал вице-президент Джейкоб Андреу во внутренней записке на 1200 слов, которую видело издание The Information.
Из приложения вырезают то, что «не сработало»: Copilot Podcasts (генерация подкастов по документам) и Copilot Labs (песочница с экспериментальными фичами) закрываются. Взамен появляются платные агенты AutoPilot — они работают в фоне постоянно, а не только по запросу: сами разбирают почту, готовят материалы, следят за календарём. Прообраз уже показывали как экспериментальный Copilot Scout. Андреу сформулировал философию жёстко: приложение должно «заслужить право на существование» у пользователя, хватит «интеллекта ради интеллекта» — нужны результаты в реальной работе.
Почему такая спешка
За этой формулировкой стоит неприятная для Microsoft статистика. По данным независимого опроса Recon Analytics (более 150 000 респондентов), доля Copilot среди платных ИИ-подписок в США упала с 18,8% в июле 2025-го до 11,5% в январе 2026-го — это сокращение позиции на 39% за полгода, пока ChatGPT и Gemini только росли. Ещё показательнее: когда сотруднику доступны сразу все три платформы — Copilot, ChatGPT и Gemini, — Copilot в качестве основного инструмента выбирают лишь 8% против 70% у ChatGPT и 18% у Gemini. Даже встроенность в Word, Excel и Outlook не спасает: люди пробуют альтернативы и массово уходят к ним. Microsoft параллельно отчитывается о 100+ млн активных пользователей Copilot и 20 млн платных мест, но независимые оценки говорят, что реально пользуется продуктом еженедельно лишь 20-30% купленных лицензий.
При чём тут OpenAI
Здесь и кроется настоящий сюжет: перезапуск Copilot — не изолированный редизайн приложения, а часть более крупного разворота. Ещё в апреле 2026-го Microsoft и OpenAI формально пересобрали своё соглашение: из контракта исчезла знаменитая «клаузула AGI» (набор условий, привязанных к моменту достижения искусственного общего интеллекта), а лицензия Microsoft на модели и продукты OpenAI, действующая до 2032 года, стала неэксклюзивной — то есть конкуренты OpenAI теперь тоже могут получить доступ. Взамен Microsoft перестала платить OpenAI отчисления от своей выручки, а платежи от OpenAI в адрес Microsoft продолжатся до 2030 года, но уже с потолком.
А в июне на конференции Build глава ИИ-направления Microsoft Мустафа Сулейман представил сразу семь собственных моделей семейства MAI — включая первую reasoning-модель MAI-Thinking-1 — и прямо заявил цель: войти в число «топ-4» лабораторий мира наравне с Google DeepMind, OpenAI и Anthropic. Он подчеркнул, что модели обучены «с нуля, без дистилляции» из чужих архитектур — то есть без использования технологий OpenAI, к которым Microsoft имеет доступ уже много лет. «Переломным моментом стало то, что мы пересогласовали контракт с OpenAI, — сказал Сулейман. — Это позволило нам обучать модели большего масштаба и открыто идти к суперинтеллекту полностью на собственной интеллектуальной собственности, собственных данных, без дистилляции, обучением с нуля».
Что это значит
Получается двойной манёвр. С одной стороны, Microsoft строит собственный модельный фундамент вместо того, чтобы вечно оставаться обёрткой над чужим ИИ. С другой — теперь нужно доказать, что на этом фундаменте можно построить продукт, который люди выберут сами, а не потому, что он бесплатно встроен в Office. Ставка на платных агентов AutoPilot — это ещё и попытка Microsoft наконец найти монетизацию, которая не завязана на лицензионные отчисления OpenAI: агенты и инструменты для разработки становятся отдельным платным слоем поверх бесплатного базового Copilot.
ИИ ретро фото передает атмосферу дворов и коммуналок прошлого века
Советское фото ИИ - это способ получить кадр в стилистике 1950-1980-х без архива, ретуши вручную и поиска реквизита. Нейросеть сама добавляет зернистость пленки, приглушенные цвета и узнаваемую советскую атмосферу.
Обычно к этому приходят двое: те, кто хочет оживить историю семьи, и те, кому нужна яркая карточка для соцсетей или личного проекта. Вопрос один и тот же - как объяснить нейросети, что именно нужно, чтобы ии ретро фото не выглядело как случайный фильтр.
В этой статье:
как работает стилизация под прошлый век
какие инструменты подходят для ии фото СССР
пошаговая инструкция от загрузки до скачивания
как подготовить исходное фото для нейросети
какие ошибки чаще всего портят кадр
ответы на частые вопросы
🎬 Как работает советское фото ИИ
Нейросеть анализирует лицо, позу и фон на исходнике, а затем накладывает визуальные признаки эпохи: зерно пленки, приглушенную палитру, характерные ракурсы студийной съемки. Итог - не просто фильтр, а перестроенная сцена в духе ИИ фото СССР.
Что это значит: модель не просто меняет цвета, а достраивает детали окружения - обои, одежду, освещение - под выбранный период.
Пример: обычное селфи на телефон превращается в кадр, будто снятый на пленочную камеру во дворе панельного дома - именно так выглядит удачное ии ретро фото.
На что обратить внимание: чем четче исходник, тем точнее нейросеть считывает черты лица и сохраняет сходство в готовом ИИ фото СССР.
Для маркетолога: такой формат хорошо работает как обложка для тематического поста, карточка для соцсетей или элемент коллажа для семейного альбома - кадр сразу выделяется на фоне обычных фильтров.
🤖 Какие инструменты подходят для ии ретро фото
Для ии ретро фото не обязательно разбираться в фотошопе или искать редкие фильтры. Нужен инструмент, который понимает текстовые описания стиля, умеет работать с портретами и выдает советскую фотографию ИИ без ручной доработки.
Для этой задачи подходит Umnik AI - там собраны модели для генерации и обработки изображений в одном интерфейсе, без переключения между разными сайтами.
Что это значит: вместо набора разрозненных приложений вы получаете готовый ретро-кадр в одном окне - от загрузки исходника до скачивания результата.
Для новичка: не нужно разбираться в настройках профессиональных редакторов, достаточно описать желаемый результат словами - остальное сделает нейросеть фото советских дворов и интерьеров.
🚀 Пошаговая инструкция: как сделать советское фото ИИ через Umnik AI
Дальше - конкретные шаги без лишних теорий. Инструкция подходит и тем, кто впервые открывает подобный сервис, и тем, кто уже пробовал делать нейросети фото СССР раньше.
1. Зайдите на сайт Umnik AI. Откройте платформу в браузере на компьютере или телефоне. Если аккаунта нет, зарегистрируйтесь, если есть - войдите в профиль.
2. Откройте раздел для работы с изображениями. В меню выберите инструмент, который подходит под задачу генерации и обработки фото.
3. Выберите модель для стилизации портрета. Она отвечает за перенос черт эпохи на исходный кадр и сохранение сходства с оригиналом при создании ИИ фото СССР.
4. Загрузите фото. Нажмите на область для добавления файла, выберите снимок на устройстве и дождитесь, пока он появится в рабочем поле.
5. Опишите нужный стиль текстом. Укажите десятилетие, обстановку, одежду, освещение и настроение кадра - чем подробнее описание, тем точнее получится ии ретро фото.
6. Настройте формат. Для соцсетей часто подходят соотношения 1:1 или 4:5, для печати - более широкий кадр.
7. Запустите обработку и дождитесь результата. Если итог не устроил, не начинайте заново - уточните детали запроса.
8. Скачайте готовый файл и используйте его в соцсетях, для семейного архива или личного проекта.
Если результат получился слабым, чаще всего дело не в инструменте, а в слишком общем описании. Уточните эпоху, одежду, фон и освещение - и результат станет заметно точнее.
🖼️ Как подготовить фото для генерации через нейросеть фото советских образов
Советская фотография ИИ начинается не с запроса, а с исходника. От качества фото и ракурса зависит, насколько узнаваемым получится лицо на итоговом кадре в стиле ИИ фото СССР.
Что проверить перед загрузкой:
лицо на фото хорошо освещено и не перекрыто волосами или тенью;
ракурс близкий к прямому, без сильного наклона головы;
разрешение снимка достаточное, без сильного размытия;
на фото один человек, если нужен точный портрет.
В запросе стоит указать не только десятилетие, но и контекст: двор, кухня, парк, студийная съемка. Нейросети фото СССР работают точнее, когда описана не только одежда, но и обстановка вокруг человека - тогда советская фотография ии выглядит достовернее.
Если результат кажется слишком общим, добавьте деталь про свет - например, дневной свет из окна или свет настольной лампы. Это часто меняет атмосферу кадра сильнее, чем смена фона, и приближает результат к настоящему ии ретро фото.
Umnik AI в этом разделе помогает быстро проверить черновой вариант перед финальной генерацией - можно сравнить несколько версий кадра и выбрать наиболее удачную.
⚠️ Типичные ошибки при генерации ии картинки СССР
Даже с хорошим исходником результат может разочаровать, если запрос составлен небрежно. Вот частые промахи, которые легко исправить заранее, чтобы нейросеть фото советских дворов и лиц отработала точнее.
Слишком общий запрос. Фраза вроде "сделай в стиле СССР" оставляет нейросети слишком много свободы. Уточняйте десятилетие, одежду и обстановку для точного ИИ фото СССР.
Плохое освещение на исходнике. Темное или пересвеченное фото мешает модели точно считать черты лица.
Слишком много деталей в одном запросе. Если описать пять разных сцен сразу, итог получится размытым по смыслу. Лучше один четкий сценарий - тогда нейросеть ретро фото выйдет аккуратнее.
Игнорирование формата. Квадратный кадр для широкой панорамы двора часто обрезает важные детали композиции.
Отказ от повторной генерации. Первый вариант редко бывает идеальным - в Umnik AI можно уточнить запрос и получить более точный результат без полной пересборки сцены.
Смешение эпох в одном запросе. Если в описании соседствуют детали 1960-х и 1980-х, ии картинки СССР получаются противоречивыми по стилю - лучше выбрать одно десятилетие.
Нейросеть ретро фото хорошо передает атмосферу праздничных застолий прошлого века
❓ Частые вопросы про стилизацию под СССР
Перед тем как пробовать самостоятельно, стоит закрыть несколько частых сомнений - от цены до качества итогового снимка. Ниже - вопросы, которые чаще всего задают про нейросети фото СССР и их результат.
1. Можно ли сделать это бесплатно? Многие платформы дают ограниченное количество бесплатных генераций для знакомства с инструментом, а дальше работают по платным тарифам. Для одного-двух тестовых кадров этого обычно достаточно, чтобы понять, подходит ли формат.
2. Сколько времени занимает создание одного кадра в стиле ИИ фото СССР? Обычно результат готов за минуту-две после запуска обработки, точное время зависит от нагрузки на сервис.
3. Можно ли использовать готовый кадр в соцсетях? Да, итоговое изображение можно свободно использовать для личных страниц, если это не нарушает правила конкретной площадки.
4. Нужен ли опыт в фоторедакторах, чтобы получить хороший результат? Нет, весь процесс строится на текстовом описании стиля, а не на ручной работе со слоями и масками. Даже нейросети фото СССР без опыта дают приличный результат с третьей-четвертой попытки.
5. Что делать, если лицо на итоговом фото изменилось слишком сильно? Попробуйте более четкий исходник с прямым ракурсом и хорошим освещением - это главный фактор сохранения сходства в любом ии ретро фото.
6. Чем ии картинки СССР отличаются от обычных фильтров? Фильтр просто меняет цвета поверх фото, а нейросеть перестраивает фон, одежду и детали сцены, поэтому советская фотография ии выглядит гораздо реалистичнее.
📌 Итоги
Советское фото ИИ решает задачу быстрее, чем поиск реквизита или ручная стилизация в редакторе. Главное правило простое: четкий исходник и подробное описание сцены дают заметно лучший результат, чем короткий общий запрос про ИИ фото СССР.
Если пробуете впервые, начните с одного портрета и одной понятной сцены - двор, кухня или студийная съемка. В Umnik AI такой подход занимает несколько минут и не требует опыта в обработке изображений.
А вы уже пробовали советское фото ИИ? Что получилось лучше всего, а с чем возникли проблемы?
На момент июля 2026 года уже есть десятки нейронок,есть как популярные так и конечно же не популярные(провалившиеся либо просто не известные),оценивать какая нейронка лучше будем с помощью того самого... истинного... уже легендарного... В.А.Й.Б КОДИНГА
Начнём:
Deepseek-одна из худших нейронок... была до весны/лета,в неё выкатили достаточно хорошую обнову с помощью которой можно создать даже мобильную игру с помощью HTML,тут главное- хороший промпт и терпение,специально для этого поста создал простую игру по тематике кликера,получилось так себе,потребовалось ±9 попыток на что то нормально,но нейронка не понимает большинство просьб(Динамичный фон нормальный,модельки чуть качественней и т.п.) логично что данные вещи пока что ии выполнить не в состоянии,оценка: 3.7 звезд из 5-и
2. Chat gpt - спойлер,это худшая нейронка которой я только пользовался для вайб кодинга,не смогла создать даже близко начальную версию дип сика,говорить не о чем,0 звездочек из 5-и
Продолжение поста следует(решил частями опубликовать:>)
В следующих постах будем разбирать грок,клауд и прочие уже не особо популярные нейронки
Готовый набор эмоций получается из одного обычного фото за пару минут
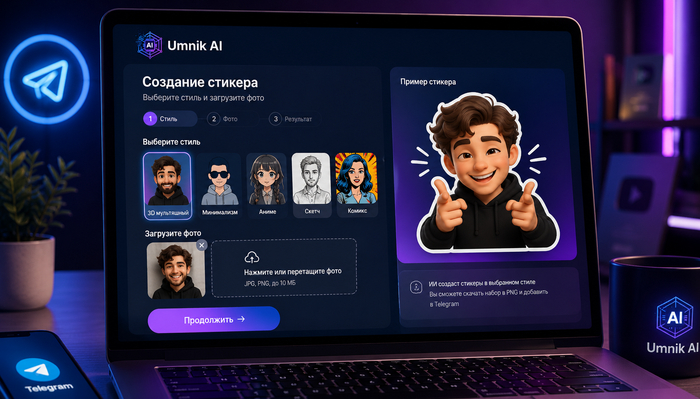
Стикеры ИИ - это способ получить уникальный набор для переписки за несколько минут, а не корпеть над векторным редактором. Не нужно уметь рисовать: достаточно фото или короткого описания, и результат уже готов к загрузке в мессенджер.
Проблема обычно не в желании собрать набор, а в том, что готовые стикеры в каталогах выглядят одинаково, а рисовать самому долго и непонятно, с чего начать. Дальше разберем, как получить живой, узнаваемый результат без художественных навыков и лишних правок.
В этой статье:
как работает генерация стикеров через ии и чем она отличается от обычных наборов
какие ии для ТГ стикеров стоит выбрать
пошаговая инструкция, как сделать стикеры ТГ ии от фото до готового файла
как создать стикеры по фото нейросеть без потери сходства
какие ошибки чаще всего портят ии стикеры телеграмм
ответы на частые вопросы про ии стикеры телеграм
🎬 Как работают стикеры ии и почему ии стикеры телеграмм прижились у всех
По сути ии делающий стикеры - это модель, которая собирает картинку или короткую анимацию по фото или текстовому описанию. Вместо часов в графическом редакторе вы получаете готовый файл в нужном формате за пару минут, а сам набор остается узнаваемым.
Что это значит: модель анализирует лицо, позу или сюжет и подбирает стиль - от мультяшного до реалистичного, поэтому любой ии для ТГ стикеров работает по похожей схеме.
Формат бывает разным:
статичные картинки в png или webp;
короткие анимации для более живой реакции в переписке;
набор из 8-16 стикеров под разные эмоции.
Пример: пользователь загружает одно селфи, а на выходе получает набор с удивлением, смехом, грустью и одобрением - без единой правки вручную.
🤖 Какие инструменты подойдут для ии стикеры телеграм
Когда встает вопрос, какой именно ии для ТГ стикеров выбрать среди десятков вариантов, важно смотреть не на рекламу, а на то, что реально доступно в интерфейсе и насколько гибко можно менять стиль.
Umnik AI собирает инструменты, чтобы создать стикеры с помощью ии в одном окне, поэтому не приходится переключаться между разными сайтами ради результата.
На что обратить внимание:
есть ли раздел именно под изображения и стикеры, а не только видео;
можно ли загрузить свое фото как основу, чтобы ии делающий стикеры сохранял сходство;
сколько форматов доступно для скачивания;
поддерживает ли сервис пакетную обработку, если нужны сразу ии стикеры телеграмм для нескольких эмоций.
Для маркетолога: если набор нужен для бренд-чата или комьюнити, лучше сразу продумать единый стиль всех картинок, а не собирать их из разных источников.
Пример: небольшая команда собирала набор для внутреннего чата - вместо случайных картинок из разных сайтов взяли одно фото ведущего сотрудника и получили серию с единым стилем и узнаваемым лицом.
🚀 Пошаговая инструкция: как сделать стикеры ТГ ии через Umnik AI
Разберем по шагам весь процесс от входа на платформу до готового файла для мессенджера. Инструкция подходит и тем, кто впервые пробует создать стикеры с помощью ии.
1. Зайдите на сайт Umnik AI. Откройте платформу в браузере на компьютере или телефоне. Если аккаунта еще нет, зарегистрируйтесь. Если аккаунт уже есть - войдите в профиль.
2. Откройте раздел для работы с изображениями. В меню выберите раздел, который отвечает за генерацию и обработку картинок - именно там находится ии для ТГ стикеров.
3. Выберите модель для генерации изображений. Ориентируйтесь на ту модель, что подходит под портретный стиль - именно она чаще всего используется, когда нужно создать стикеры с помощью ии на основе живого фото.
4. Загрузите фото или введите текстовое описание. Нажмите на область загрузки и выберите файл на устройстве. Дождитесь, пока превью появится в рабочем поле.
5. Напишите запрос. Опишите объект, действие, стиль, фон и настроение. Чем конкретнее формулировка, тем ближе итог к задумке, а сами ии стикеры телеграмм выходят точнее.
6. Настройте параметры. Выберите формат под мессенджер - обычно это квадрат или вертикальная карточка, а также нужное количество вариантов в наборе.
7. Запустите обработку и оцените результат. Если итог не устроил, не начинайте заново - уточните запрос: смените стиль, добавьте деталь, уберите лишний фон.
8. Скачайте готовый набор. Сохраните файлы и добавьте их в мессенджер через стандартный конструктор наборов.
Если результат получился слабым, чаще всего дело не в инструменте, а в слишком общем запросе. Уточните объект, стиль, фон, свет, эмоцию и ограничения - результат станет заметно лучше.
🖼️ Как создать стикеры по фото нейросеть и сохранить сходство
Отдельный вопрос - как создать стикеры по фото нейросеть так, чтобы персонаж узнавался с первого взгляда, а не превращался в абстрактную картинку, ведь именно ии стикеры телеграм чаще всего теряют сходство при неудачном исходнике.
Что проверить перед загрузкой фото:
лицо на снимке хорошо освещено и не перекрыто;
ракурс близкий к анфасу или три четверти;
фон не отвлекает от главного объекта.
Ошибка: часто загружают темное или размытое фото и ждут, что ии делающий стикеры все равно даст четкий результат. Лучше так: сделайте новый кадр при дневном свете либо возьмите фото покрупнее, где лицо занимает большую часть кадра.
Umnik AI дает возможность обработать фото и сразу проверить, насколько сильно изменился стиль по сравнению с исходником, прежде чем сохранять весь набор.
Если задача - собрать ии стикеры телеграм под конкретного человека, а не общий персонаж, всегда начинайте с четкого портрета и меняйте стиль постепенно, шаг за шагом, а не одним резким запросом.
Пример готового набора после того, как сделать стикеры ТГ ии за один заход
⚠️ Типичные ошибки: создать стикеры с помощью ии
Прежде чем публиковать готовые ии стикеры телеграмм, стоит свериться со списком частых промахов - они экономят время на повторной генерации, особенно если вы делаете ии для ТГ стикеров впервые.
Слишком общий запрос. "Сделай смешно" не работает - опишите эмоцию, позу и стиль конкретно.
Плохой исходник. Темное, размытое или мелкое фото редко дает узнаваемый результат, даже если ии делающий стикеры хорошо настроен.
Один и тот же ракурс во всем наборе. Разные эмоции лучше смотрятся с небольшими вариациями позы.
Неверный формат. Перед загрузкой в мессенджер проверьте размер и расширение файла.
Перегенерация без правок. Проще уточнить запрос, чем запускать процесс заново с нуля.
Один запрос на все эмоции сразу. Модель работает точнее, если формулировать запрос под каждый стикер отдельно, а не пытаться описать весь набор одной фразой.
❓ FAQ: вопрос - ответ, как создать стикеры по фото нейросеть
Ниже - короткие ответы на вопросы, которые чаще всего возникают у тех, кто впервые собирает такой набор для личного чата или комьюнити.
1. Можно ли собрать набор бесплатно? Базовые функции часто доступны без оплаты, а расширенные форматы и модели - по подписке. Уточняйте условия на самой платформе.
2. Сколько времени занимает весь процесс? От загрузки фото до готового набора обычно уходит несколько минут, если запрос сформулирован конкретно, а выбранный ии для ТГ стикеров поддерживает нужный формат.
3. Нужен ли опыт в дизайне, чтобы создать стикеры с помощью ии? Нет, весь процесс держится на текстовом описании и загрузке фото, рисовать вручную не требуется.
4. Что делать, если ии стикеры телеграм не похожи на человека? Замените исходное фото на более четкое и укажите в запросе конкретные черты, которые важно сохранить - Umnik AI позволяет перегенерировать только слабый вариант, не трогая остальной набор.
5. Можно ли использовать готовые ии стикеры телеграмм в рабочих чатах? Да, если стиль сдержанный и не нарушает правила конкретного чата или платформы.
📌 Итоги: ИИ стикеры Телеграмм
Стикеры ии перестали быть трудоемкой задачей: набор под чат, комьюнити или личную переписку собирается за один заход, если заранее продумать исходник и формулировку запроса.
Главное правило простое - четкое фото плюс конкретный запрос дают узнаваемый результат, а расплывчатая формулировка почти всегда требует повторных попыток, даже когда ии для ТГ стикеров настроен хорошо.
Если пробуете такой формат впервые, начните с одного портрета и небольшого набора эмоций в Umnik AI, а расширяйте стиль уже после первого удачного результата.
А вы уже пробовали стикеры ии? Что получилось лучше всего, а с чем возникли проблемы?
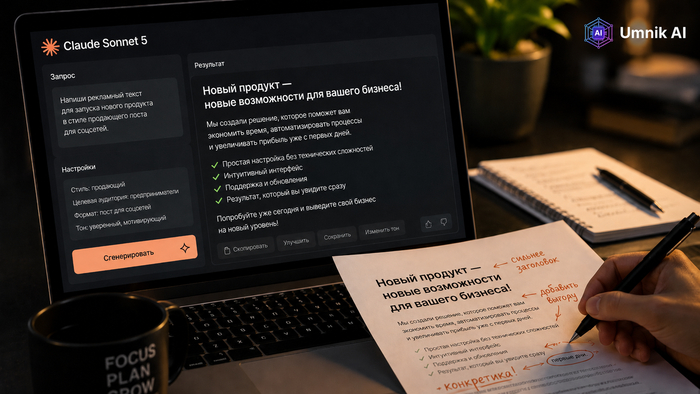
Обновленная нейросеть - для работы с текстом, кодом и изображениями
Claude Sonnet 5 - это новая версия нейросети от Anthropic, которая заметно быстрее и точнее прежних моделей отвечает на сложные запросы. Если вы уже работали с Claude Sonnet 4 5, разница будет заметна почти сразу: меньше "воды" в ответах, лучше логика в длинных задачах и более аккуратная работа с кодом.
Многие сталкиваются с одной и той же проблемой: официальный сайт открывается не всегда, а привязать карту для оплаты попросту нельзя. Из-за этого Claude в России превращается в отдельный квест, а вопрос "Claude как пользоваться" звучит чаще, чем хотелось бы. Дальше разберем это по шагам, без лишних слов.
В этой статье:
как устроена модель и чем она отличается от предыдущей версии
кому подходит эта нейросеть
как получить доступ к Claude в России и оплатить сервис
из чего состоит пошаговая инструкция для новичка
как перейти с Claude Sonnet 4 5 без потери привычек
какие ошибки чаще всего мешают результату
ответы на частые вопросы
🧠 Что такое Claude Sonnet 5 и зачем она нужна
Это система среднего уровня в линейке Anthropic: не самая тяжелая, зато быстрая и хорошо сбалансированная по цене и качеству. Она подходит и для повседневных задач, и для рабочих сценариев, где важна скорость.
Что это значит на практике: модель одинаково уверенно ведет диалог, разбирает документы, пишет и правит код, объясняет сложные темы простым языком. Для сравнения, Claude 3 5 Sonnet была заметно проще в рассуждениях на многошаговых задачах, а новая версия держит контекст длиннее и реже "теряет мысль" в середине разговора.
Кому подходит: копирайтерам и редакторам, которым нужен живой, а не шаблонный текст разработчикам, которые пишут и отлаживают код студентам и тем, кто разбирает сложные материалы маркетологам, которые готовят статьи, сценарии и посты
Пример: если раньше на разбор большого технического файла уходило несколько заходов, то с этой моделью чаще получается справиться за один проход, потому что лучше держит структуру запроса.
🌍 Claude в России: как обстоят дела с доступом
Прямого официального доступа из России сейчас нет: сайт не привязан к региону, а оплата картой российского банка не проходит. Именно поэтому вопрос Claude AI в России стал таким частым в поиске, а вместе с ним и вопрос "Claude как пользоваться" без лишних сложностей.
На что обратить внимание: дело не в самом сервисе, а в ограничениях на уровне регистрации и оплаты. Решить это можно через сторонние платформы, которые уже настроили доступ Claude в России и берут вопрос оплаты на себя.
Здесь и пригодится Umnik AI - это платформа, которая дает доступ к нейросетям, включая последние модели Anthropic, без смены IP-адреса, левых карт и постоянных обрывов сессии. Регистрация занимает пару минут, а оплатить Claude через нее можно привычными способами.
🤖 Claude как пользоваться: доступ и оплата через Umnik AI
Прежде чем переходить к шагам, стоит понять логику: вместо прямой регистрации на официальном сайте вы работаете через платформу-посредника, которая уже решила, как оплатить Claude и сделать доступ Claude в России стабильным.
На Umnik AI можно выбрать нужный вариант из линейки Anthropic, задать параметры запроса и получить ответ так же, как на официальном сайте, только без блокировок и лишних технических сложностей. Это и есть самый рабочий ответ на вопрос "Claude как пользоваться", если вы находитесь в России.
Для маркетолога: это особенно удобно, когда нужно тестировать разные варианты в одном месте, не переключаясь между сервисами и не думая, как оплатить Claude отдельно для каждой задачи.
🚀 Пошаговая инструкция: как начать пользоваться Claude Sonnet 5
Если вы впервые разбираетесь с этим вопросом, пройдите шаги по порядку - так вы не потеряете время на лишние попытки.
1. Зайдите на сайт Umnik AI. Откройте платформу в браузере на компьютере или телефоне. Если аккаунта еще нет, зарегистрируйтесь по почте. Если аккаунт уже есть - войдите в профиль.
2. Откройте раздел с текстовыми моделями. В меню выберите раздел, где собраны диалоговые нейросети, и найдите там нужный инструмент.
3. Выберите нужный вариант под задачу. Для сложных многошаговых запросов берите новый релиз, для более легких и быстрых - можно оставить прежнюю, если она уже привычна.
4. Введите запрос текстом. Опишите задачу подробно: что нужно получить, в каком стиле, с какими ограничениями. Чем конкретнее формулировка, тем точнее ответ.
5. Настройте параметры, если они доступны. Длина ответа, тон, формат - все это можно скорректировать под конкретную задачу.
6. Запустите генерацию результата. Дождитесь результата. Если он не устроил, не начинайте с нуля - уточните запрос: добавьте детали или сузьте формулировку.
7. Сохраните готовый результат. Скопируйте текст или код и используйте его дальше - для статьи, отчета или рабочего проекта.
Если результат получился слабым, чаще всего дело не в сервисе, а в слишком общем запросе. Уточните тему, формат, объем и стиль - и ответ станет заметно точнее.
Оплатить Claude и выбрать нужный вариант можно за пару минут через понятный интерфейс
🔄 Переход с Claude Sonnet 4 5: что изменится в работе
Если вы уже привыкли к прошлой версии, переход пройдет почти незаметно - интерфейс работы с сервисом не меняется, меняется только качество результата.
Что заметите в первую очередь: новая версия лучше держит длинный контекст и реже уходит от темы в объемных задачах. При этом Claude Sonnet 4 5 остается рабочим вариантом для простых и коротких сценариев, где скорость важнее глубины.
Пример: при разборе многостраничного документа старая версия иногда упускала детали ближе к концу текста, а обновленный сервис удерживает структуру от начала до конца.
Для тех, кто раньше пользовался более ранней версией, разница будет еще заметнее - за несколько поколений модель стала значительно точнее в рассуждениях и меньше ошибается в деталях.
⚠️ Типичные ошибки при работе с Claude
Даже когда всё уже настроено, результат может разочаровать, если допустить одну из частых ошибок. Разберем самые распространенные, включая те, что мешают именно тем, кто ищет Claude AI в России впервые.
Переход по случайным ссылкам. В поиске по запросу "Claude AI в России" часто всплывают сомнительные сайты - лучше пользоваться проверенной платформой.
Слишком общий запрос. Фраза "напиши текст про маркетинг" даст размытый ответ. Лучше указать тему, объем, стиль и цель текста.
Одна попытка вместо уточнения. Если результат не устроил, не начинайте заново - допишите, что именно нужно изменить.
Игнорирование контекста. Если задача связана с предыдущим сообщением, напомните сервису ключевые детали - это ускорит результат.
Поиск полностью бесплатного варианта без ограничений. Запросы вроде "Claude 3 5 Sonnet бесплатно без лимитов" часто ведут на сомнительные сайты. Надежнее пользоваться проверенной платформой с прозрачной оплатой.
❓ Частые вопросы про Claude Sonnet 5
1. Сложно ли настроить Claude в России с первого раза? Нет, если пользоваться проверенной платформой. Основные сложности возникают только при попытке зарегистрироваться напрямую на официальном сайте.
2. Можно ли пользоваться Claude 3 5 Sonnet бесплатно? Есть ограниченный бесплатный доступ с лимитом запросов. Для регулярной работы удобнее платный вариант с оплатой через сторонний сервис.
3. Как оплатить Claude из России? Напрямую картой российского банка это сделать нельзя. Проще всего оплатить Claude через платформу вроде Umnik AI, где принимаются привычные способы оплаты.
4. Работает ли Claude AI в России официально? Официального доступа с прямой оплатой пока нет. Но пользоваться сервисом можно через сторонние платформы с легальной оплатой и стабильным подключением.
5. Чем новая модель отличается от Claude Sonnet 4 5? Она лучше держит длинный контекст, точнее в многошаговых задачах и реже "теряет" детали в объемных документах.
6. Подходит ли старая версия для простых задач? Да, для коротких и несложных задач этот релиз все еще справляется быстро, но по глубине рассуждений уступает более новому варианту.
7. Нужен ли опыт, чтобы разобраться, Claude как пользоваться с нуля? Нет, интерфейс понятен даже новичку - достаточно ввести запрос текстом и при необходимости уточнить формулировку.
Claude в России теперь доступен через понятный интерфейс без лишних сложностей
📌 Итоги
Claude Sonnet 5 - удобная модель для тех, кто хочет более точные и продуманные ответы без лишней возни с настройками. Вопрос Claude AI в России решается через сторонние платформы, а сам переход с прошлой версии не требует привыкания заново.
Если раньше вы пользовались Claude Sonnet 4 5 или более ранней версией, попробуйте новую модель на Umnik AI - разница в качестве ответов заметна уже с первых попыток.
А вы уже пробовали Claude Sonnet 5? Что получилось лучше всего, а с чем возникли проблемы?
Три года я работал менеджером по продажам. Деньги были, но я чувствовал, что застрял. Каждое утро — силы волоком тащить себя на работу. Каждый вечер — мысль «а не пора ли всё бросить». Но пора — и куда? Я не представлял, чем ещё могу заниматься, и боялся начинать с нуля.
Решил — пусть ИИ поможет разобраться. Чего терять?
Первый промпт был откровенным: «Проанализируй мои навыки и предложи 5 профессий, куда я могу перейти. Мой опыт: 3 года в продажах (B2B), опыт переговоров, ведение CRM, презентации, работа с возражениями. Образование — экономическое. Интересы: технологии, обучение, аналитика». Нейросеть выдала список: продуктовый менеджер, менеджер по работе с клиентами в IT, специалист по внедрению CRM, бизнес-аналитик, менеджер проектов.
Продуктовый менеджер — звучало интересно. Но я не знал, что это значит на практике. Второй промпт: «Опиши день продуктового менеджера. Какие задачи он решает, с кем взаимодействует, какие навыки критически важны». Получил детальное описание. Понял, что 60% моих текущих навыков — transferable, то есть применимы в новой профессии. Это придало уверенности.
Следующий шаг — анализ рынка. Промпт: «Какой спрос на продуктовых менеджеров в России в 2026? Какой средний уровень зарплаты? Какие инструменты нужно знать?» Нейросеть выдала обзор: спрос высокий, средняя зарплата 150–300 тысяч в зависимости от уровня, ключевые инструменты — Jira, Figma, SQL на базовом уровне, понимание метрик.
Тут я понял, чего мне не хватает. Нужно было подтянуть технические навыки. Попросил ИИ составить план обучения: «Составь план подготовки к профессии продуктового менеджера. Начальный уровень — ноль в технологиях. Цель — устроиться на junior- позицию за 4 месяца». Получил поэтапный план: месяц 1 — основы SQL и работа с данными, месяц 2 — Jira, Confluence, методологии Agile, месяц 3 — основы UX, прототипирование, месяц 4 — подготовка к собеседованиям, оформление портфолио.
Каждую неделю я возвращался к ИИ с уточнениями: «Объясни, что такое SQL JOIN на пальцах», «Какие вопросы задают на собеседовании junior PM?», «Помоги составить описание проекта для портфолио». Нейросеть стала моим персональным ментором, доступным 24/7.
Самый ценный промпт — подготовка к собеседованиям: «Ты — HR-менеджер IT-компании. Проведи со мной собеседование на позицию junior product manager. Задавай вопросы, я буду отвечать, ты давай обратную связь». Это был прорыв. Я отвечал вслух, записывал себя на диктофон, потом сравнивал с тем, что советовал ИИ. После 10 таких прогонов чувствовал себя уверенно.
Результат через 4 месяца: устроился продуктовым менеджером в небольшую IT-компанию. Зарплата на старте — на 15% ниже, чем в продажах, но перспективы роста гораздо шире. Через полгода — повышение до middle, зарплата сравнялась. Через год — переплела предыдущий доход на 40%.
Главное, что дал мне ИИ — не знания. Знания есть везде. Он дал структуру и уверенность. Я знал, что делать сегодня, что — завтра, что — через месяц. Не метался, не сомневался, не прокрастинировал. Просто следовал плану.
Важно: ИИ — не волшебная палочка. Мне пришлось учиться по вечерам после работы, 2–3 часа в день, 4 месяца подряд. Были моменты, когда хотелось бросить. Но план, составленный ИИ, держал меня в фокусе.
t.me/aieasyruканал, где я делюсь промптами для карьерного роста — кому-то может сэкономить месяцы.
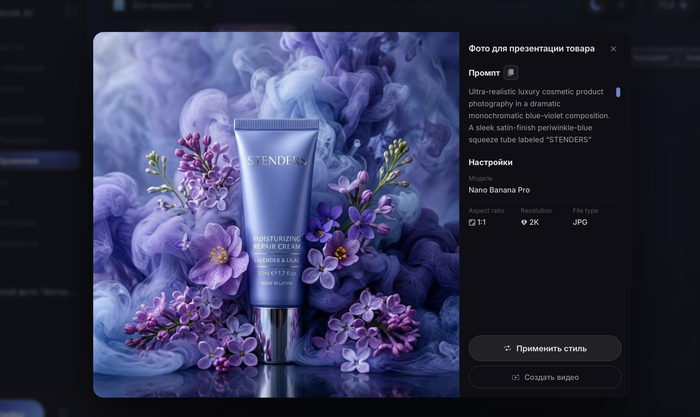
Так может выглядеть готовая карточка товара с помощью нейросети
Карточка товара с помощью нейросети - это уже не эксперимент, а рабочий способ закрыть рутину за вечер вместо недели. Если раньше на фотосъемку, обработку и верстку такой страницы уходили дни и бюджет на фотографа, сейчас эту же задачу можно решить самостоятельно, без студии и графического редактора.
Продавцы на маркетплейсах, владельцы небольших интернет-магазинов и те, кто ведет соцсети с товарами, все чаще ищут способ, как ии сделать карточку товара без лишних затрат. Вопрос обычно один: получится ли результат, который не стыдно опубликовать, или на выходе будет "пластиковая" картинка, которую видно за версту.
В этой статье:
как работает генерация карточек товара нейросетью
какие инструменты подойдут для этой задачи
пошаговая инструкция от входа в сервис до готового файла
как подготовить фото или запрос для нейросети
какие ошибки чаще всего портят результат
ответы на частые вопросы про бесплатные варианты
🎬 Как работает карточка товара через ИИ
Смысл простой: вы описываете, что должно быть на итоговом кадре, а модель собирает картинку с учетом окружения, освещения, ракурса и композиции. По сути, это и есть генерация карточек товара нейросетью - только вместо студии и фотографа задачу решает алгоритм. Раньше такой процесс казался чем-то техническим и сложным, сейчас это ближе к диалогу с редактором, который понимает обычный язык.
Что это значит на практике: вы можете загрузить исходное фото и попросить убрать фон, добавить студийное освещение или собрать инфографику с преимуществами. Либо сгенерировать сцену с нуля, если фото нет вовсе - здесь как раз ИИ создать карточку товара получится даже без единого исходного кадра.
Для маркетолога: такой подход экономит время на согласованиях с фотостудией и позволяет тестировать несколько подач за один вечер, а не за неделю. Так удобно готовить визуал перед запуском рекламы: за один заход можно собрать сразу три-четыре версии.
🤖 Какие инструменты подойдут для этой задачи
Прежде чем выбирать сервис, стоит понимать разницу между тяжелыми профессиональными редакторами и инструментами, заточенными именно под товарные снимки. Многие хотят, чтобы ИИ сделать карточку товара получилось без обучения и лишних настроек, а не разбираться в профессиональном редакторе неделю.
Для несложных сценариев подходят простые платформы с понятным интерфейсом. Такую нейросеть для карточек товара бесплатно проще освоить за один вечер, без курсов и туториалов - достаточно разобраться с загрузкой файла и формулировкой запроса.
Umnik AI - один из таких вариантов: платформа собрала в одном месте модели для генерации изображений, оживления фото и работы с видео, поэтому не приходится переключаться между разными сайтами ради одной цели. Если нужно, чтобы ИИ сделал карточку товара без переключения между сервисами, такой формат "все в одном" экономит время. По сути, это и есть нейросеть для карточек товара бесплатно на старте: базовых генераций хватает, чтобы понять, подходит ли инструмент под ваш случай.
Пример: если нужно быстро оформить визуал для нового товара перед запуском рекламы, удобнее один раз загрузить снимок и получить несколько версий подряд, чем настраивать отдельный редактор под каждый шаг. Опыт в дизайне тут не обязателен - важнее подробно описать, что должно получиться на выходе.
На что обратить внимание: не любой инструмент одинаково хорошо держит пропорции объекта и текст на упаковке. Перед тем как выбрать окончательный сервис, стоит проверить несколько итогов подряд - обычно уже на этом этапе видно, действительно ли выбранный ии для карточек товара бесплатно справляется с вашей нишей.
🚀 Пошаговая инструкция: как ии создать карточку товара через Umnik AI
Дальше - конкретные шаги, без общих формулировок вроде "выберите инструмент". Их можно повторить, даже если вы впервые открываете подобный сервис и хотите, чтобы ИИ создал карточку товара с первой попытки.
1. Зайдите на сайт Umnik AI. Откройте платформу в браузере на компьютере или телефоне. Если аккаунта еще нет, зарегистрируйтесь, если есть - войдите в профиль.
2. Откройте раздел для работы с изображениями. В меню выберите раздел, где собраны нужные модели.
3. Выберите подходящую модель. Если нужно убрать окружение или поправить освещение - подойдет модель для улучшения кадра, если нужна сцена с нуля - модель для генерации.
4. Загрузите снимок. Нажмите на область загрузки или иконку вложения, выберите файл на компьютере или телефоне и дождитесь, пока он появится в рабочем поле.
5. Опишите, что нужно получить. Укажите объект, окружение, освещение, ракурс и настроение: "белая керамическая кружка на светлом фоне, мягкий боковой свет, минимализм, товарная съемка".
6. Настройте формат. Для карточек на маркетплейсах чаще подходит квадрат 1:1 или 4:5, для баннеров - 16:9.
7. Запустите обработку и дождитесь итога. Если он не устроил, не начинайте с нуля - уточните формулировку: добавьте детали по освещению или ракурсу, и ИИ сделает карточку товара точнее со второй попытки.
8. Скачайте готовый файл. Сохраните изображение и используйте его в объявлении, каталоге или соцсетях.
Если получилось слабо, чаще всего дело не в инструменте, а в слишком общей формулировке. Уточните объект, стиль, окружение и ограничения - так проще, чтобы ИИ сделал карточку товара точнее уже со второй попытки.
🖼️ Как подготовить исходные данные
Прежде чем запускать генерацию карточек товара нейросетью, стоит подготовить хотя бы один четкий исходный снимок - даже сделанный на телефон при дневном свете. Это сильно повышает качество итога и то, насколько точно ИИ создаст карточку товара с первого раза.
Даже самая точная нейросеть для карточек товара бесплатно не исправит совсем нечитаемый кадр, поэтому пара минут на подготовку исходника окупается.
Что проверить перед загрузкой:
товар занимает большую часть кадра и хорошо виден;
нет бликов и сильных теней на упаковке;
окружение однотонное или нейтральное, без лишних предметов;
текст и логотип на упаковке читаемы.
Если исходника нет вовсе, можно описать товар текстом и попросить собрать сцену с нуля - для этого удобна нейросеть для генерации карточек товаров с гибкими настройками окружения и композиции. Модель строит сцену полностью по описанию: важно указать материал, цвет, форму и обстановку. В таком сценарии Umnik AI подходит и тем, кто хочет получить визуал с нуля, и тем, кто просто улучшает готовый снимок.
⚠️ Типичные ошибки при генерации
Даже когда ии для карточек товара бесплатно доступен и понятен, легко потерять время из-за нескольких повторяющихся промахов. Часто именно из-за них ИИ сделать карточку товара с первого раза не получается - дело не в инструменте, а в формулировках.
Слишком общая формулировка. "Сделай красиво" не даст управляемого итога - опишите объект, стиль и окружение подробно.
Плохой исходник. Темный, смазанный или бликующий кадр ограничивает то, что может собрать модель.
Неверный формат. Квадратный снимок для баннера 16:9 придется обрезать и терять важные детали.
Повторные попытки без правок. Проще уточнить одну и ту же формулировку, чем запускать обработку заново десятки раз наугад.
Слишком много задач сразу. Лучше разделить окружение, освещение и текст на упаковке на отдельные уточнения.
Если избегать этих промахов, генерация карточек товара нейросетью занимает пару попыток, а не десяток.
❓ Частые вопросы, карточка товара с помощью нейросети
Ниже - короткие ответы на вопросы, которые чаще всего возникают у тех, кто впервые пробует нейросеть для генерации карточек товаров или на платном тарифе.
1. Можно ли сделать карточку товара бесплатно? Да, у большинства сервисов есть бесплатный лимит генераций. По сути, ии для карточек товара бесплатно на старте вполне справляется с простыми задачами, и оценить итог можно еще до оплаты.
2. Сколько времени занимает генерация одной карточки? Обычно итог готов за одну-две минуты, а вместе с уточнением формулировки - за 10-15 минут на весь процесс. Именно поэтому ии для карточек товара бесплатно удобно тестировать перед покупкой платного тарифа.
3. Нужен ли опыт в дизайне, чтобы получить карточку товара с помощью нейросети хорошего качества? Нет, дизайнерские навыки не обязательны: важнее умение четко описать объект, окружение и освещение, а дальше ИИ создаст карточку товара по этому описанию.
4. Можно ли использовать готовое изображение на маркетплейсе? Да, если формат и разрешение соответствуют требованиям площадки, а объект узнаваем и не искажен - в таком случае в Umnik AI остается только скачать файл.
5. Что делать, если итог выглядит неестественно? Уточните формулировку: добавьте реалистичное освещение, укажите материал поверхности и уберите лишние детали из описания, прежде чем снова просить, чтобы ИИ сделал карточку товара.
Разные форматы карточки товара через ии под соцсети и маркетплейс
📌 Короткий вывод
Карточка товара с помощью нейросети - способ закрыть рутинную задачу за вечер, без фотостудии и лишнего бюджета. По сути, любая нейросеть для карточек товара бесплатно на старте уже показывает, стоит ли углубляться в платный тариф. Главное правило простое: чем подробнее формулировка, тем точнее и естественнее выходит итог.
Если пока непонятно, с чего начать, проще всего загрузить один снимок в Umnik AI и попробовать пару формулировок - это быстрее, чем читать десятки инструкций.
А вы уже пробовали делать карточку товара с помощью нейросети? Что получилось лучше всего, а с чем возникли проблемы?
Financial Times со ссылкой на источники, знакомые с ходом переговоров, сообщает: OpenAI больше года обсуждает с администрацией США схему, по которой государство получит 5% акций компании — около $42,6 млрд по текущей оценке в $852 млрд (мартовский раунд финансирования). Официально ни OpenAI, ни Белый дом предложение не подтвердили — переговоры находятся «на концептуальной стадии» и, по данным FT, потребуют одобрения Конгресса.
Не Трампу лично, а фонду для всех американцев
Важная деталь, которую легко упустить в заголовках: доля пойдёт не президенту лично, а государству как институту — через специальный фонд по образцу Alaska Permanent Fund, суверенного фонда штата Аляска, который с 1976 года платит ежегодные дивиденды каждому жителю штата за счёт нефтяных доходов. Сэм Альтман, по данным FT, предлагает распространить схему на всю ИИ-индустрию: по 5% акций в фонд должны отдать все ведущие американские разработчики моделей — Anthropic, Google, Meta и другие. Идея подаётся как способ «поделиться с обществом выгодами от ИИ» и заранее купировать недовольство тем, что автоматизация вытесняет рабочие места, а прибыль достаётся горстке компаний. Для сравнения, сенатор Берни Сандерс продвигает куда более радикальную версию — с долей государства около 50%.
Почему момент выглядит подозрительно
OpenAI — самый агрессивный игрок в гонке ИИ-инфраструктуры, и цена этой гонки колоссальна. Компания подписала контракты на облачные мощности на сотни миллиардов долларов: $250 млрд с Microsoft, около $300 млрд с Oracle (сделка стартует в 2027-м), плюс соглашения с Amazon и Nvidia. Причём часть денег Nvidia — обязательство вложить в OpenAI до $100 млрд — по признанию собственного финансового директора компании Сары Фрайар, фактически вернётся самой Nvidia в виде оплаты за чипы: классическая циркулярная схема финансирования, которую всё чаще критикуют аналитики рынка.
При этом выручка OpenAI за 2025 год составила около $13,1 млрд, а прогнозируемые убытки на 2026-й оцениваются от $14 до $27 млрд — в зависимости от условий пересмотренной сделки с Microsoft. Совокупный отрицательный денежный поток компании к 2029 году может достичь $112 млрд, а суммарные траты на вычислительную инфраструктуру к 2030-му — $600 млрд. По некоторым подсчётам, на каждый заработанный доллар подписочной выручки OpenAI тратит около $1,69 на инференс — то есть буквально теряет деньги на каждом обслуженном пользователе.
Отчаяние или дальновидность?
На этом фоне предложение «поделиться» долей с государством можно прочитать двояко. Первая версия — действительно попытка снять социальное напряжение вокруг ИИ заранее, пока индустрия ещё может себе это позволить. Вторая, куда более циничная — расчётливый ход на случай, если инвесторские деньги закончатся раньше, чем компания выйдет на прибыль: если государство уже владеет долей в OpenAI, а миллионы американцев и целые отрасли экономики зависят от её сервисов, дать компании обанкротиться политически станет почти невозможно. Иными словами — подстраховка через статус «слишком большая, чтобы упасть», оплаченная не деньгами, а долей в бизнесе, у которого пока нет устойчивой модели монетизации.
Как бы ни развивалась история, она — симптом более широкого сдвига: крупнейшие ИИ-компании больше не просто продают подписки, а всё активнее встраиваются в государственную политику и инфраструктуру — от оборонных контрактов до предложений войти в капитал напрямую.