

Качатель YT
Нахуй вас, злые пикабушники.
Нахуй вас, злые пикабушники.
Представьте дерево. У него есть корень, от него отходят ветки, от больших веток - более мелкие, а затем листья.
Примерно так же устроены иерархические справочники в информационных системах.
И как же можно понять: что есть ветка, а что есть лист в этом иерархическом справочнике?
В канале Аналитика FM я часто разбираю такие ситуации - когда задача вроде решаема, но без нормальной структуры превращается в кашу.

Например:
📁 Транспорт
├── Легковой транспорт
│ ├── Седаны
│ └── Кроссоверы
└── Грузовой транспорт
├── Малотоннажный
└── Тягачи
Или:
📁 Товары
├── Электроника
│ ├── Телефоны
│ └── Ноутбуки
└── Бытовая техника
├── Холодильники
└── Стиральные машины
На самом деле всё гораздо проще, чем кажется.
Обычно таблица справочника выглядит примерно так:
| id | name | parent_id |
| --- | ----------------------------------- | --------------- |
| 1 | Транспорт | NULL |
| 2 | Легковой транспорт | 1 |
| 3 | Грузовой транспорт | 1 |
| 4 | Седаны | 2 |
| 5 | Кроссоверы | 2 |
| 6 | Тягачи | 3 |
Структурно это выглядит так:
1 Транспорт
├── 2 Легковой транспорт
│ ├── 4 Седаны
│ └── 5 Кроссоверы
└── 3 Грузовой транспорт
└── 6 Тягачи
Каждая запись имеет:
id - собственный идентификатор;
parent_id - идентификатор родительского элемента.
Например:
id = 4
name = Седаны
parent_id = 2
Это означает:
Седаны → Легковой транспорт → Транспорт
Именно благодаря полю parent_id база понимает, что "Седаны" и "Кроссоверы" относятся к одной ветке дерева.
Если подниматься по родителям вверх, то рано или поздно мы придём к общему узлу - корню ветки.
Получается, что вся иерархия строится буквально на одном поле: parent_id
Они позволяют хранить данные не просто списком, а показывать связи между объектами.
Благодаря этому можно:
✅ группировать данные;
✅ строить отчёты по категориям;
✅ наследовать свойства от родительских узлов;
✅ задавать правила сразу для целой ветки;
✅ быстро находить все дочерние элементы.
Например, если правило применяется ко всей категории "Легковой транспорт", то оно автоматически действует и для седанов, и для кроссоверов, и для любых новых подкатегорий, которые появятся позже.
📌 MDM-системы (Master Data Management);
📌 каталоги товаров интернет-магазинов;
📌 банковские и страховые системы;
📌 ERP и CRM;
📌 классификаторы услуг и продуктов;
📌 организационная структура компании;
📌 государственные классификаторы и справочники.
✔ Гибкость. Можно добавлять новые ветки без изменения структуры данных.
✔ Удобная аналитика. Легко получить данные как по конкретному элементу, так и по всей категории.
✔ Наследование правил. Одно правило может применяться сразу к тысячам объектов.
✔ Масштабируемость. Структура может содержать десятки и сотни уровней вложенности.
❌ Сложность запросов. Иногда, чтобы найти всех потомков или родителей, приходится строить рекурсивные запросы.
❌ Производительность. Глубокие иерархии могут существенно замедлять выполнение запросов.
❌ Риск циклических ссылок. Если по ошибке сделать узел потомком самого себя, можно получить бесконечный цикл.
❌ Сложность сопровождения. Изменение структуры верхних уровней может затронуть большое количество дочерних элементов.
При работе с иерархическими справочниками чаще всего приходится решать четыре задачи:
🔹 найти всех потомков узла;
🔹 найти всех родителей элемента;
🔹 определить, принадлежит ли элемент определённой ветке;
🔹 определить, к какому верхнему узлу относится конкретный элемент.
В Oracle для этого используются специальные иерархические запросы:
START WITH ...
CONNECT BY ...
Именно они позволяют "обходить дерево" вверх или вниз по веткам.
В канале Аналитика FM (клик :-) ) уже готов пост про конструкцию START WITH и CONNECT BY.
Подписывайся, если интересно разбираться в особенностях работы аналитика.
Иерархический справочник - это не просто список значений. Это способ описать реальные взаимосвязи между объектами и сделать систему более гибкой и управляемой.
А одна маленькая колонка parent_id превращает обычную таблицу в целое дерево данных.
Закладка по мотивам
https://github.com/mikeroyal/Self-Hosting-Guide
Система прошивки для микроконтроллеров ESP8266 и ESP32. Вместо того чтобы писать код на C++, вы описываете поведение устройства в простом YAML-файле: какие пины используются, какой протокол, какое имя сенсора — и ESPHome сам генерирует прошивку и загружает её по воздуху.
Главная прелесть — автоматическое обнаружение в Home Assistant через mDNS. Собрали датчик температуры на ESP32, прошили, включили — через минуту он уже в HA без лишних настроек. На этой же платформе делают кнопки, дисплеи, реле, ИК-передатчики и даже голосовые устройства на базе ESP32-S3.
Мост между Zigbee-сетью и брокером MQTT. Работает с USB-координатором (Sonoff Zigbee Dongle, CC2652, HUSBZB-1) и поддерживает более 3000 устройств от разных производителей — без их проприетарных хабов.
Все устройства публикуют состояние и принимают команды через MQTT-топики, а дальше стандартная интеграция mqtt в HA разбирает всё автоматически. Есть веб-интерфейс для управления сетью, мониторинга связи и обновления прошивок устройств по воздуху.
Визуальный редактор потоков для построения автоматизаций и интеграций. Вместо YAML-правил в HA вы соединяете блоки на холсте: триггер → условие → действие, причём каждый блок может обращаться к MQTT, HTTP, WebSocket, базам данных и сотне других источников.
Особенно полезен там, где логика слишком сложна для стандартных автоматизаций HA: многошаговые сценарии, работа с внешними API, преобразование данных, интеграция с сервисами, у которых нет готового компонента. Устанавливается как аддон Supervisor.
Python-фреймворк для написания приложений поверх Home Assistant. Каждое «приложение» — это класс на Python с полным доступом к состояниям и сервисам HA, системой колбэков на изменение состояний, расписания и событий.
Открывает возможности, которых нет ни в YAML-автоматизациях, ни в Node-RED: сложная математика, работа с историей через API, динамические расписания, машинное обучение прямо в автоматизации. Параллельно идёт HADashboard — отдельный движок для создания кастомных дашбордов.
NVR с ИИ-детекцией объектов в реальном времени. Подключаете IP-камеры через RTSP, Frigate непрерывно анализирует поток и определяет: человек, животное, машина, велосипед. Поддерживает аппаратное ускорение — Coral USB TPU, GPU через OpenVINO или TensorRT.
Интеграция с HA нативная: каждое событие детекции создаёт сенсор, уведомление и превью-изображение. Можно автоматизировать: «если камера у входа зафиксировала человека и никто не дома — включить освещение и отправить снапшот в Telegram». Также пишет записи только по событиям, экономя место.
Открытый P2P-протокол для голосовых сервисов в Home Assistant. Faster Whisper обрабатывает речь в текст локально — модели от tiny до large, включая поддержку русского языка. Piper синтезирует ответ обратно в речь с нейросетевыми голосами (irina, dmitri и другие для RU).
Весь стек работает без интернета: Wyoming Satellite на Orange Pi Zero 3 захватывает звук, детектирует wake-слово через openWakeWord, отправляет аудио на сервер с Whisper и Piper, получает ответ обратно. Home Assistant выступает мозгом — обрабатывает намерения и выполняет команды. Полная приватность, нулевая задержка на облаках.
Инструмент для запуска больших языковых моделей локально — Llama 3, Mistral, Gemma, Qwen и десятки других. Скачивает модели одной командой, предоставляет OpenAI-совместимый REST API на localhost:11434.
Подключается к HA через интеграцию Extended OpenAI Conversation как альтернатива OpenRouter или ChatGPT — ответы генерирует локальная модель без отправки запросов наружу. Хорошо работает на машинах с дискретной видеокартой; на CPU тоже запускается, но медленнее. Полезен как «умный» бэкенд для голосового ассистента или для обработки данных в автоматизациях.
Классический тандем для визуализации метрик умного дома. InfluxDB — time-series база данных, куда HA записывает историю всех сенсоров через интеграцию influxdb. Grafana подключается к ней как источник данных и позволяет строить дашборды с графиками температуры, влажности, потребления электроэнергии, состояния устройств.
Оба устанавливаются как аддоны Supervisor. Главное преимущество перед встроенной историей HA — произвольные запросы (Flux или InfluxQL), большой retention, и возможность мониторить одновременно HA, сервер Proxmox, роутер MikroTik и любые другие источники метрик на одном дашборде.
Красивый self-hosted монитор доступности сервисов. Проверяет HTTP/HTTPS, TCP, DNS, MQTT, а также поддерживает push-модель через heartbeat — ваш сервис сам отправляет сигнал «я живой». Интерфейс напоминает Betteruptime, но полностью на вашем сервере.
Уведомления о падении сервисов идут через Telegram, Email, Slack, Webhook — или напрямую в HA через его нотификационный сервис. Полезно мониторить: сам HA, Zigbee2MQTT, сервер VDS, Nextcloud, все аддоны, которые слушают порт снаружи.
DNS-сервер с блокировкой рекламы, трекеров и вредоносных доменов для всей домашней сети. Устанавливается как аддон HA, прописывается как DNS в роутере — и с этого момента все устройства в сети работают без рекламы без каких-либо клиентских приложений.
Ведёт статистику запросов по устройствам, позволяет видеть какие домены запрашивают умные лампочки или телевизор, поддерживает DNS-over-HTTPS и DNS-over-TLS. Интеграция с HA позволяет отображать статистику прямо на дашборде: сколько запросов заблокировано за сутки, топ клиентов, топ заблокированных доменов.
Self-hosted сервер, полностью совместимый с протоколом Bitwarden. Вы используете официальные клиенты Bitwarden (браузерные расширения, мобильные приложения, десктоп) — но все данные хранятся на вашем сервере, а не в облаке Bitwarden.
Написан на Rust, потребляет минимум ресурсов (работает на Raspberry Pi без проблем). Поддерживает двухфакторную аутентификацию, организации, коллекции, аварийный доступ. Хорошо живёт в LXC-контейнере на Proxmox за Nginx Proxy Manager с Let's Encrypt.
VPN поверх WireGuard с нулевой конфигурацией. Создаёт защищённую оверлейную сеть между вашими устройствами — без проброса портов, без статического IP, через любые NAT. Устанавливается как аддон HA и даёт безопасный доступ к интерфейсу Home Assistant из любой точки мира.
В бесплатном тарифе — до 100 устройств и 3 пользователя, чего домашнему использованию более чем достаточно. Функция Tailscale Funnel позволяет опубликовать отдельный сервис (например, webhook для интеграций) через защищённый туннель без открытия портов на роутере.
Полноценная платформа для личного облачного хранилища и совместной работы. Синхронизация файлов, встроенный офис (Collabora/OnlyOffice), видеозвонки (Talk), почта, задачи, галерея фото. Всё на своём сервере.
Интегрируется с HA через CalDAV — события из Nextcloud Calendar появляются как сенсоры в HA и могут триггерить автоматизации. Nextcloud Talk подключается как канал для уведомлений HA вместо Telegram — полностью приватный мессенджер с push-уведомлениями. Nextcloud AIO (All-in-One) — самый простой способ развернуть всё одной Docker-командой.
Веб-интерфейс для управления Docker-контейнерами, Swarm и Kubernetes. Визуально показывает все запущенные контейнеры, их логи, переменные окружения, порты, volumes; позволяет запускать, останавливать, пересоздавать контейнеры и разворачивать стеки через docker-compose прямо из браузера.
Незаменим при построении self-hosted стека на Proxmox LXC или выделенном сервере. Поддерживает Portainer Agent — можно управлять несколькими Docker-хостами из одного интерфейса. Для домашнего использования Community Edition полностью бесплатен.
Современный reverse proxy с автоматическим обнаружением Docker-контейнеров. Запустили новый контейнер с нужными лейблами — Traefik сам создаёт роут и получает SSL-сертификат через Let's Encrypt без перезапуска.
Особенно удобен в связке с Proxmox + Docker: один Traefik принимает весь HTTPS-трафик на 443 порту и маршрутизирует по доменным именам к нужным контейнерам — Nextcloud, Vaultwarden, Uptime Kuma, Grafana. Поддерживает middleware для аутентификации, rate limiting, IP-фильтрации.
Программный мост для подключения устройств, не поддерживающих Apple HomeKit, к экосистеме Apple. Более 2000 плагинов — от умных розеток до роботов-пылесосов. Работает рядом с HA или вместо него для тех, кто живёт в экосистеме Apple.
Интересен в контексте HA тем, что сам Home Assistant можно выставить в HomeKit через встроенную интеграцию — тогда все устройства HA управляются из приложения «Дом» на iPhone и через Siri. Homebridge при этом нужен для устройств, у которых нет компонента ни в HA, ни в HomeKit напрямую.
Централизованная панель управления устройствами с прошивкой Tasmota — умными розетками, реле, диммерами, сенсорными выключателями. Показывает все Tasmota-устройства в сети, позволяет обновлять прошивку сразу на всех, менять настройки, следить за состоянием.
Устанавливается как аддон HA. Сами устройства Tasmota общаются с HA через MQTT — включается один раз и работает без облаков. Особенно актуально, если у вас десятки Sonoff-девайсов: обновить прошивку на всех одновременно через TasmoAdmin вместо поштучной настройки.
Self-hosted платформа GPS-трекинга. Поддерживает более 200 протоколов GPS-трекеров — от дешёвых китайских GT06 до профессиональных устройств. Показывает историю маршрутов на карте, уведомляет о зонах входа/выхода, скорости, состоянии батареи.
Устанавливается как аддон HA. Интеграция с HA позволяет использовать GPS-трекер как источник состояния device_tracker — то есть автоматизации на основе геолокации работают через ваш сервер, а не через Google/Apple. Полезно для автоматизаций «дома/не дома» без зависимости от телефона.
Открытый федеративный протокол для мессенджеров. Запускаете собственный сервер Matrix (Synapse или Conduit), подключаетесь клиентом Element — получаете зашифрованный чат, который никому не принадлежит.
Аддон HA позволяет отправлять уведомления и получать команды через Matrix. Альтернатива Telegram для тех, кто хочет полный контроль: сервер на своём железе, сквозное шифрование, федерация с другими серверами. Conduit — более лёгкий вариант сервера на Rust, хорошо живёт на Orange Pi или в LXC.
Полностью свободный медиасервер без подписок, трекинга и принудительных аккаунтов. Организует фильмы, сериалы, музыку и фото с автоматическим получением метаданных, постеров и субтитров. Поддерживает аппаратное транскодирование (Intel Quick Sync, VAAPI, NVENC).
Интеграция с HA: сенсоры активного воспроизведения, управление плеером как media_player объектом. Можно автоматизировать: «если Jellyfin начал воспроизведение в гостиной — приглушить свет, поставить Do Not Disturb». Клиенты есть для всего: Android TV, iOS, Roku, Kodi, веб.
Self-hosted альтернатива Google Фото. Автоматическое резервное копирование с телефона, распознавание лиц и объектов, поиск по содержимому, временная шкала, альбомы, шаринг. Интерфейс практически идентичен Google Фото — переход почти незаметен.
Развёртывается через docker-compose, активно развивается (обновления почти каждую неделю). С HA прямой интеграции нет, но через webhook или MQTT можно, например, автоматически архивировать снапшоты с камер Frigate прямо в Immich. Заменяет Google Фото полностью, данные остаются дома.
P2P-синхронизация файлов между устройствами без центрального сервера. Выбираете папки, указываете устройства для синхронизации — и файлы реплицируются напрямую, зашифрованно, без облака.
Практически применим в связке с HA для синхронизации конфигов: папка /config HA синхронизируется на резервный компьютер в реальном времени. Также удобно держать в синхронизированной папке бэкапы, фото с телефонов, документы — без Nextcloud, проще в настройке, но без веб-интерфейса для доступа из браузера.
DNS-sinkhole для блокировки рекламы и трекинга на уровне всей сети. Прописывается как DNS в DHCP-сервере роутера и с этого момента блокирует рекламу на всех устройствах без исключения — смарт-ТВ, консолях, IoT-устройствах, где расширения браузера не работают.
Интеграция с HA через компонент pi_hole — сенсоры статистики: процент заблокированных запросов, количество запросов за сутки, статус сервиса. Можно добавить на дашборд HA как виджет. Альтернатива AdGuard Home — Pi-hole старше и имеет большую экосистему плагинов, AdGuard современнее по интерфейсу.
Веб-интерфейс поверх Nginx для управления reverse proxy. Добавляете новый хост через форму в браузере: домен, IP:порт назначения, кнопка «запросить SSL» — готово. Никакого ручного редактирования конфигов.
Хорошая точка входа перед переходом на Traefik: проще в понимании, меньше движущихся частей, не требует изменений в docker-compose всех сервисов. Живёт в отдельном LXC на Proxmox, принимает весь входящий трафик и маршрутизирует к HA, Nextcloud, Grafana, Vaultwarden по доменным именам с валидными Let's Encrypt сертификатами.
Open-source платформа для управления WireGuard-сетями. В отличие от обычного WireGuard, где нужно вручную прописывать пиры, NetBird управляет конфигурацией централизованно через веб-панель. Есть self-hosted версия сервера управления.
Ближайший аналог Tailscale, но полностью на своём железе. Поддерживает ACL-правила, группы устройств, роуты в локальные подсети. Для доступа к HA снаружи — та же логика, что у Tailscale: никаких открытых портов, трафик идёт через зашифрованный туннель.
Лёгкий веб-интерфейс для просмотра логов Docker-контейнеров в реальном времени. Подключается к Docker socket, показывает потоки stdout/stderr всех контейнеров, поддерживает поиск и фильтрацию.
Не хранит логи (только live-просмотр) — именно поэтому весит практически ничего. Удобен для быстрой диагностики: что-то сломалось в HA аддоне или docker-контейнере — открываете Dozzle, смотрите логи без SSH. Работает в паре с Portainer: Portainer для управления, Dozzle для логов.
Автоматическое обновление Docker-образов. Периодически проверяет Docker Hub или другой реестр на наличие новых версий образов запущенных контейнеров и пересоздаёт их с новым образом, сохраняя все переменные и volumes.
Настраивается гибко: обновлять все контейнеры или только помеченные лейблом, присылать уведомления о каждом обновлении (в Telegram или через webhookHA), обновлять только в определённое время суток. Снимает рутину ручного docker pull && docker-compose up -d для всего стека.
VS Code в браузере. Полноценный редактор с расширениями, терминалом, Git-интеграцией — только работает на сервере, а вы подключаетесь через браузер с любого устройства.
Применительно к HA: редактировать конфиги, скрипты Python для AppDaemon, YAML автоматизации — прямо с планшета или с чужого компьютера без установки чего-либо. Живёт в LXC или Docker, доступен через тот же Nginx Proxy Manager с авторизацией. Поддерживает extensions из Open VSX Registry (аналог Marketplace без Microsoft-лицензий).
Лёгкий self-hosted Git-сервис. Интерфейс как у GitHub, но всё на вашем сервере: репозитории, Issues, Pull Requests, CI через встроенный Gitea Actions или внешний Woodpecker CI.
Удобен для хранения конфигов Home Assistant под версионным контролем: пушите изменения в конфигах, откатываетесь при ошибке, видите историю что и когда менялось. Также хорошее место хранить все скрипты инфраструктуры — Ansible playbooks, docker-compose файлы, PowerShell для AD.
Коллекция из 60+ утилит для разработчиков и администраторов в виде удобного веб-интерфейса: конвертеры форматов (JSON/YAML/TOML/XML), генераторы паролей и UUID, кодировка/декодировка Base64 и URL, работа с датами, регулярные выражения, расчёт подсетей, форматирование кода и ещё много всего.
Развёртывается одним Docker-образом, работает полностью офлайн — никакие данные не покидают ваш сервер. Заменяет десятки онлайн-сайтов (многие из которых логируют запросы) одним локальным инструментом. Живёт за Nginx Proxy Manager, доступен по адресу типа tools.home.local.
Телеграм, ВКонтакте, Дзен, Макс — площадок становится все больше, а вот внимание аудитории по-прежнему ограничено. Что делать? Продвигать!
На Пикабу можно рекламировать свои каналы прямо в лентах сайта. Находите новую аудиторию и получайте живые переходы без сложных рекламных кабинетов.
Подойдет для:
авторских и экспертных блогов
бизнеса
медиа и новостных каналов
мемных и развлекательных сообществ
Запускается просто: добавляете ссылку, пишете заголовок и краткое описание и выбираете географию для показов. А дальше о вашем канале узнают тысячи пользователей Пикабу!
Доброе утро! ну или просто утро, я хз честно говоря почему это оно вдруг доброе. Долго ничего не постил из за некоторых проблем с психикой ну и банально экзамены и ещё не особо понятно что изучать дальше и куда двигаться в том звиздеце который происходит. В последнее время углубился в тематику линукс, дважды ставил и ломал виртуальные машины Debian, сейчас плавно пришёл к arch niri, даже недавно использовал Kali linux и ко что просканировал ну в общем слегка углубился в эту тему. Сегодня решил 2 каты на codewars обе на 5 сложности из 8, так что могу считать что постепенно возвращаюсь в форму. Кстати если кому интересно - вот скрины из линукса:

Привет всем пикабушникам)
Сижу давненько на данном ресурсе, читаю истории других людей, но ни разу сам не создавал какой либо пост. Вот наконец-то решился попробовать , так сказать узнать мнение людей.
Если ли смысл в данное время изучать программирование с нуля? Да и еще в 35 лет)))
сам работаю электромонтёром, но эта работа уже совсем не доставляет удовольствия. Хочется каких нибудь перемен, например попробовать себя в новой профессии)
Что можете посоветовать? И вообще стоит в таком возрасте суваться в такую индустрию?
Приборка, ретро-киберпанк и мемный штурман: когда навигатор стал companion app
После карты, маршрутов и борьбы с развязками я мог бы остановиться. Навигатор работает, телефон показывает позицию, маршрут строится, HUD в игре можно выключить. Казалось бы, все.
Но телефон уже лежит рядом с рулем. Он уже стал частью кокпита. И тут в голове появляется абсолютно нездоровая, но очень логичная мысль: а почему он должен быть только картой? Пусть будет приборкой. А если есть телеметрия, пусть еще и реагирует на события. Потому что если машина влетела в стену на 180 км/ч, программа имеет моральное право сказать что-нибудь мемное.
В некоторых машинах Forza внутренняя приборка работает нормально. Поэтому экранный спидометр я выключил почти сразу. Но внешний HUD на телефоне дает другое ощущение: не “еще один интерфейс поверх игры”, а отдельный прибор рядом с рулем.
Я хотел не стерильную табличку speed/gear/rpm, а что-то ближе к электронным приборкам авто их 80х в смеси с современными технологиями: скорость, передача, TRIP A, RPM bar, мини-карта, маршрут, темный фон, цифры как на старой электронике. Такое, чтобы выглядело не как админка роутера, а как штука, которую кто-то прикрутил к машине в гараже в 2003 году и почему-то она работает.
Можно было взять шрифт. Но я захотел нормальные семисегментные цифры из отдельных сегментов. В браузере это делается довольно приятно: у каждой цифры есть набор включенных сегментов, а дальше DOM собирает маленький индикатор.
Это не самая сложная часть проекта, зато она очень влияет на настроение. Обычный текст говорит “это веб-страница”. Семисегментный индикатор говорит “добро пожаловать в странный автомобильный прибор”.
Семисегментные цифры приборки
const DASH_SEGMENTS = {
"0":"abcdef", "1":"bc", "2":"abged", "3":"abgcd",
"4":"fgbc", "5":"afgcd", "6":"afgecd", "7":"abc",
"8":"abcdefg", "9":"abfgcd", "-":"g", "N":"ceg", "R":"efgab"
};
function renderDashboardDigits(el, value, small=false){
const text = String(value ?? '0').toUpperCase().slice(0, 4);
el.innerHTML = '';
for(const ch of text){
const on = DASH_SEGMENTS[ch] || DASH_SEGMENTS[' '];
const digit = document.createElement('span');
digit.className = 'dashboardDigit' + (small ? ' small' : '');
for(const seg of ['a','b','c','d','e','f','g']){
const part = document.createElement('span');
part.className = 'dashboardDigitSeg s-' + seg + (on.includes(seg) ? ' on' : '');
digit.appendChild(part);
}
el.appendChild(digit);
}
}
Обороты приходят из телеметрии. Максимальные обороты тоже могут прийти, но на всякий случай интерфейс умеет подстроиться под увиденный максимум. Полоса RPM собрана из 88 сегментов, последние сегменты помечены как red zone.
Здесь я окончательно понял, что приборка - это не про “показать число”. Это про ощущение. Когда шкала оборотов бежит рядом с рулем, мозг почему-то верит ей сильнее, чем сухому тексту.
RPM bar из 88 сегментов
function ensureDashboardRpmSegments(){
const track = document.getElementById('dashboardRpmTrack');
if(!track || dashboardRpmBuilt) return;
track.innerHTML = '';
dashboardRpmSegs = [];
for(let i = 0; i < 88; i++){
const seg = document.createElement('span');
seg.className = 'dashboardRpmSeg' + (i >= 76 ? ' red' : '');
track.appendChild(seg);
dashboardRpmSegs.push(seg);
}
dashboardRpmBuilt = true;
}
const ratio = clamp(rpm / Math.max(1000, dashboardLearnedMaxRpm), 0, 1);
const activeCount = Math.round(ratio * dashboardRpmSegs.length);
TRIP A выглядит как декоративная мелочь. Но именно такие мелочи делают приборку живой. И, конечно, даже она не могла просто работать без вопросов.
Если DistanceTraveled из телеметрии приходит нормально - используем его. Если он не двигается или приходит как бесполезный ноль - считаем расстояние сами, интегрируя скорость по времени. Это типичный момент разработки: хотел маленькую цифру, получил fallback-логику.
TRIP A с fallback-расчетом
function updateDashboardTrip(){
const rawDistance = Number(telemetry && telemetry.distance_traveled_m);
const rawValid = Number.isFinite(rawDistance) && rawDistance > 1;
if(rawValid){
if(dashboardTripRawBaseM === null || rawDistance + 5 < dashboardTripRawLastM){
dashboardTripRawBaseM = rawDistance;
}
dashboardTripRawLastM = rawDistance;
dashboardTripKm = Math.max(0, (rawDistance - dashboardTripRawBaseM) / 1000);
} else {
const dtMs = Math.max(0, Math.min(2500, now - dashboardTripLastAt));
const speedKmh = Math.max(0, Number(telemetry.speed_kmh) || 0);
dashboardTripKm += (speedKmh * dtMs) / 3600000;
}
}

В приборке есть мини-карта. Но ее нельзя было просто нарисовать как полноценную большую карту еще раз. Телефон должен держать нормальный FPS, не греться как кирпич и не превращать езду в презентацию PowerPoint.
Поэтому мини-карта живет на canvas, использует кэш тайлов и подбирает zoom по скорости. Чем быстрее едет машина, тем дальше навигатор должен смотреть вперед. На медленной скорости можно приблизить, на высокой - отодвинуть камеру, чтобы не ехать носом в край экрана.
Автоzoom мини-карты по скорости
function dashboardMiniDesiredZoom(mode, vw, vh, anchor, deg){
const kmh = Math.max(0, Number(telemetry.speed_kmh) || 0);
const lookSeconds = 4.5;
const lookMeters = Math.max(35, (kmh / 3.6) * lookSeconds);
const lookPx = mapPxFromMeters(lookMeters);
const ahead = dashboardForwardLookPoint(lookPx);
for(let z = MAX_ZOOM; z >= MIN_ZOOM; z--){
const v = viewFor(z);
const raw = {x: ahead.map_x * v.s - v.px, y: ahead.map_y * v.s - v.py};
const screen = rotatePointAround(raw.x, raw.y, anchor.x, anchor.y, deg);
if(screen.x >= sideMargin && screen.x <= vw - sideMargin &&
screen.y >= topMargin && screen.y <= vh - bottomMargin){
return z;
}
}
return MIN_ZOOM;
}
Дальше случилось неизбежное. Если программа знает скорость, тормоз, вертикальную скорость и высоту, она может понимать игровые события. А если понимает события, может реагировать звуком.
Так появился мемный слой. Сэмплы лежат в папках samples/collision, samples/mega_fail_crash и samples/jump_takeoff. Сервер отдает список доступных звуков, телефон проигрывает случайный сэмпл при событии. Никакого облака, никакого сервиса, просто свои локальные файлы и браузер.
Настройки событий мемного слоя
MEME_EVENT_DEFAULTS = {
"mega_fail_crash": {
"window_sec": 0.15,
"min_previous_speed_kmh": 120.0,
"max_current_speed_kmh": 15.0,
"min_speed_drop_kmh": 100.0,
},
"collision": {
"window_sec": 0.5,
"min_speed_drop_kmh": 40.0,
"min_previous_speed_kmh": 60.0,
"max_brake_pct": 5.0,
},
"jump_takeoff": {
"detection_mode": "fast_freefall_confirmed",
"min_speed_kmh": 75.0,
"freefall_window_sec": 0.15,
"min_takeoff_vertical_speed_mps": 1.0,
"max_freefall_vertical_speed_mps": -0.25,
},
}
Самое важное для collision - не срабатывать на обычное торможение. Если игрок нажал тормоз, скорость упала, это не авария. Это водитель. Поэтому событие смотрит на падение скорости и одновременно проверяет, что тормоз почти не нажат.
Столкновение как резкое падение скорости без тормоза
if(collisionPast){
const drop = collisionPast.speed - speed;
const maxBrake = Number(collisionCfg.max_brake_pct ?? 5);
const noBrake = (brake <= maxBrake) && (Number(collisionPast.brake || 0) <= maxBrake);
if(noBrake &&
collisionPast.speed >= Number(collisionCfg.min_previous_speed_kmh || 60) &&
drop >= Number(collisionCfg.min_speed_drop_kmh || 40)){
playMemeEvent('collision');
return;
}
}
С прыжком было веселее. Нельзя просто сказать: машина поднялась вверх, значит прыжок. В игре есть холмы, эстакады, подъемы. Поэтому логика ждет не только рост высоты, но и признаки полета: вертикальную скорость, апекс, начало падения, небольшой drop from apex. По сути, нужно поймать момент “машина реально оторвалась”, а не “дорога пошла вверх”.
Прыжок как подтвержденный полет, а не просто подъем
const takeoffOk =
(recentMaxVy >= minTakeoffVy) ||
(verticalSpeedGain >= minVyGain) ||
(recentRise >= minRise && recentMaxVy >= minTakeoffVy * .55);
const fallingOk =
(fallingSamples.length >= minFallSamples || Number(vy) <= fallingLimit) &&
(fallDuration >= minFallDuration || confirmDrop >= minApexDrop * .55) &&
accelOk;
if(takeoffOk && fallingOk && notRoadSlope && dropFromApex >= minApexDrop){
playMemeEvent('jump_takeoff');
}
На этом этапе проект перестал быть “просто картой на телефоне”. Он стал companion app:
- основной слой - позиция машины и карта;
- навигационный слой - route, distance, heading-up, reroute;
- приборный слой - speed, gear, rpm, TRIP A, мини-карта;
- event layer - столкновения, прыжки, mega fail и звуковые реакции;
- будущий слой - Z-логгер для развязок и уточнение 3D-логики маршрутов.
И самое смешное: все это началось с очень простой мысли “хочу убрать мини-карту из игры и не потеряться”.
Я надеюсь, что вдохновение ко мне вернётся, и я сделаю что-то подобное для другой игры (напишите, кстати, какую игру еще можно было попробовать также снабдить навигатором?), или ещё что нибудь. Спасибо, что читали и ставили плюсы, всем добра!

Главное окно программы
Всем привет! Хочу поделиться личной историей о том, как наболевшие бытовые проблемы с компьютером и капелька упорства (вместе с ИИ-помощником) помогли мне создать программу, которой я теперь пользуюсь каждый день.
Началось всё с трёх простых, но жутко раздражающих проблем в моей повседневной жизни:
1. Хаос в загрузках. Я постоянно скачиваю кучу картинок, видео, мемчиков и документов. Плюс бэкапы с флешек, старых жестких дисков и прочее. Разбирать всё это сразу не всегда есть время и желание, поэтому мусор годами копится мертвым грузом. И чем дальше, тем страшнее браться за наведение порядка. Существующие программы для сортировки требовали изучения тонны настроек или выглядели как привет из 90-х. Хотелось простого: без установок, без взломов, без лишней сложности. Просто открыл программу, по превью или фильтрам быстро раскидал файлы по нужным каталогам, не копаясь часами в бесконечных иерархиях папок.
2. Сжатие видео для Discord. Постоянная боль аккаунтов без премиума: хочешь скинуть другу смешной ролик весом в 12–15 мегабайт, а ограничение на загрузку — ровно 10. И начинается: заходи на онлайн-конвертеры (которые пережимают видео по полчаса и пичкают рекламой) или открывай тяжелый видеоредактор. Мне нужен был инструмент, который сожмет ролик под лимит мессенджера в один клик. Плюс иногда требовалось на месте обрезать видео, кадрировать, повернуть, убрать звук или быстро вытащить аудиодорожку из подкаста.
3. Анализ забитого диска. Чтобы понять, куда делось место на диске или флешке, я много лет использовал старую утилиту Scaner на 200 КБ. Да, она работала, но была жутко неудобной и устаревшей: ни красивой интерактивности, ни нормальной группировки файлов, ни возможности быстро выкинуть мусор прямо из графика. А изучать новые сложные комбайны было банально лень.
Раньше я бы просто вздохнул и продолжил мучиться, ведь в программировании я не разбираюсь от слова «совсем» (максимум — писал простейшие скрипты на Python для себя). Я даже с технологией Git не был знаком и начал использовать её уже в самом конце разработки. Но с появлением нейросетей всё изменилось. Я решил: почему бы не попробовать сделать такой инструмент для себя, раз мне это интересно, а готового идеала под мои нужды не существует?
Да, возможно, это эгоцентрично — думать, что я лучше других знаю, как всё должно работать. Но меня всегда удивляло: почему вокруг так много крутых программистов и экспертов, а большинство софта в итоге получается кривым и неудобным? И я решил попробовать сам.
Справедливости ради, начинал я не с удобных агентных систем, как все нормальные люди, а напрямую в веб-интерфейсе Google AI Studio. И это был сущий кошмар. Система не поддерживала прямое создание файлов проекта на компьютере. Мне приходилось прописывать правила, по которым ИИ писал код в виде текста, я скачивал его в `.txt`, а потом конвертировал на своем компьютере в рабочий Python-код скриптом. Это было сплошное мучение, продуктивность стремилась к нулю. Скорее всего, отголоски этого «костыльного» старта до сих пор живут где-то в архитектуре проекта.
Позже я узнал об агентных нейросетях и открыл для себя агентного ИИ-помощника от Google. Я знал, что есть другие аналоги, но с ходу не смог быстро разобраться с их установкой и настройкой, а в этом разобрался и остановился на нем. Во мне горел энтузиазм, нужно было поскорее воплотить свою идею в жизнь.
Спойлер: в итоге всё это заняло больше полугода. В течение этого времени я много раз хотел всё бросить и забыть как страшный сон. Но раз вы читаете эту статью, значит, всё-таки не бросил.
Сказать, что всё заработало сразу — соврать. Это была настоящая битва! Нейросеть писала код на Python, а я выступал в роли тестировщика, дизайнера, QA-инженера, идейного вдохновителя и строгого начальника. И это с учетом того, что опыта ни в одной из этих ролей у меня не было до этого момента.
Мы наткнулись на кучу подводных камней, о существовании которых я даже не догадывался:
Длинные пути в Windows: Вы знали, что система начинает сходить с ума и выдавать ошибки, если полный путь к файлу превышает 260 символов? Нам пришлось писать специальный обходной код, чтобы программа не вылетала при переносе файлов из глубоких папок.
Блокировки файлов: Программа намертво зависала, если я пытался переместить видео, пока встроенный плеер его воспроизводил. Мы учили плеер вовремя «отпускать» файлы перед переносом.
Спор с ИИ из-за дизайна и расположения элементов: Нейросеть упорно пыталась сделать всё не так, как я считал удобным и правильным. Я заставлял её по многу раз переписывать интерфейс и элементы программы, чтобы получить то, что соответствовало моему представлению об удобстве. В итоге вроде получился стильный интерфейс с легким закосом под эстетику игры Graveyard Keeper на начальном экране. (Капля забавы никогда не повредит)
Тормоза программы при отрисовке тысяч данных: при нахождении тысяч категорий дубликатов или попытке вывести в список 8 тысяч файлов рисунков всё падало, приходилось изучать механизмы решения этих проблем. (скорей всего не все решены)
Бесконечные баги: Они были на каждом шагу — в дизайне, в производительности, в расположении элементов. Казалось, не было места, где хотя бы что-то работало нормально.
В итоге для стабильности мы написали 85 автоматических тестов, чтобы после каждого нового исправления у нас не ломалось то, что уже работало. И, скорее всего, это ещё не конец.
Программа состоит из четырех модулей, которые полностью закрыли мои потребности:
Сортировщик (Sorter): Поддерживает drag&drop для настройки каталогов. Показывает файлы из папки «Входящие». В один клик (или по горячим клавишам) я раскидываю файлы из входящей директории по удобному визуальному дереву папок. Есть быстрый предпросмотр картинок, видео и звуков прямо при наведении мышки, а также безопасное индивидуальное и групповое переименование с защитой от конфликтов имен. Поддерживается автопереименование файлов по шаблону при добавлении в каталоги.
Анализатор диска (Analyzer): Строит красивую интерактивную плиточную диаграмму TreeMap или круговую Sunburst. Наводишь на сектор — видишь размер папки и её содержимое. Можно «провалиться» вглубь каталогов и перемещать или удалять тяжелый мусор прямо на месте. И, конечно, есть интеграция с другими функциями программы.
Поиск дубликатов (Cleaner): Находит одинаковые файлы по их хэш-суммам (даже если они переименованы). И тут действует «железобетонное» правило безопасности: программа физически не позволит вам случайно удалить все копии файла — как минимум один оригинал («выживший») всегда останется нетронутым. А также реализован поиск по образцу (функция, которой мне всегда не хватало): можно искать дубликаты только тех файлов, которые лежат в конкретной папке, среди всех остальных директорий.
Редактор и Конвертеры (Editor): Быстрая обрезка видео, наложение размытия (блюра) на область экрана, пакетные конвертеры картинок, аудио и видео и многое другое. И да — то самое сжатие под лимит мессенджеров (до 10 МБ) теперь делается парой кликов.
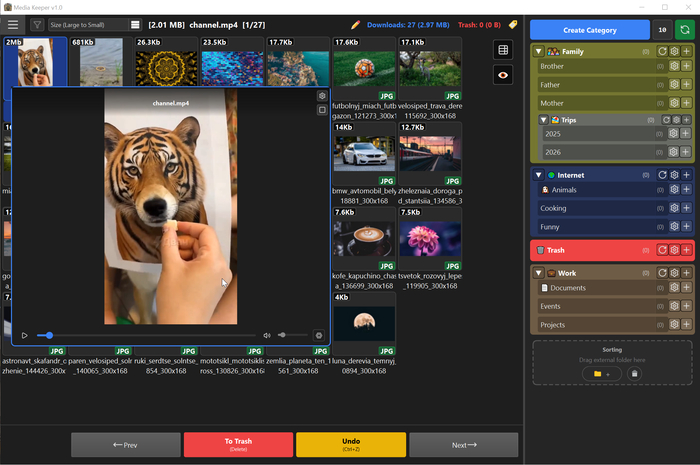
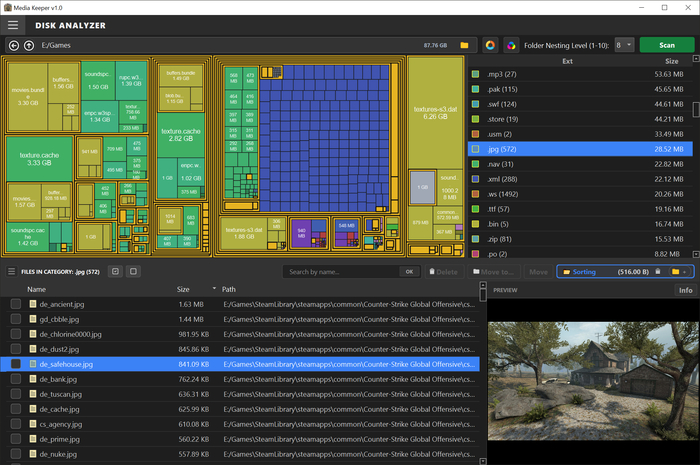
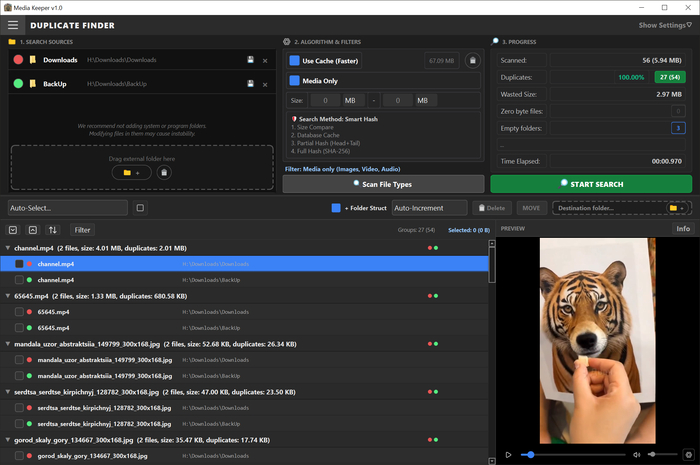
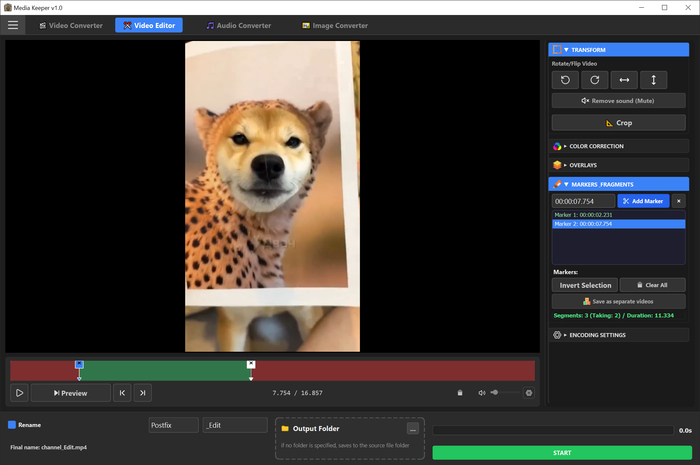
Подули программы: Сортировка, Анализатор, Поиск дубликатов, Редактор и конвертер.
Для меня было критически важно, чтобы программа не лезла в интернет. Media Keeper работает на 100% локально. Она не собирает метаданные, не отправляет логи на сторонние сервера и вообще не требует сети (интернет нужен только один раз при первом запуске, чтобы скачать библиотеки FFmpeg для видеоредактора, если их у вас нет, но их можно установить и вручную).
Программа полностью бесплатна, в ней нет рекламы и скрытых подписок. Она не требует установки в систему — её можно спокойно переносить на флешке, запускать на любом компьютере, и всё будет работать из коробки (очень на это надеюсь).
Я выложил весь исходный код на GitHub — проект полностью открыт для всех. Надеюсь, кому-то из вас он будет полезен и тоже сэкономит кучу времени и нервов при наведении порядка на компьютере!
Программа переведена на русский и английский язык.
👉 Ссылка на исходный код и скачивание готовой версии: [Ссылка]
Буду рад вашим отзывам, конструктивной критике и идеям, что еще можно улучшить!







