
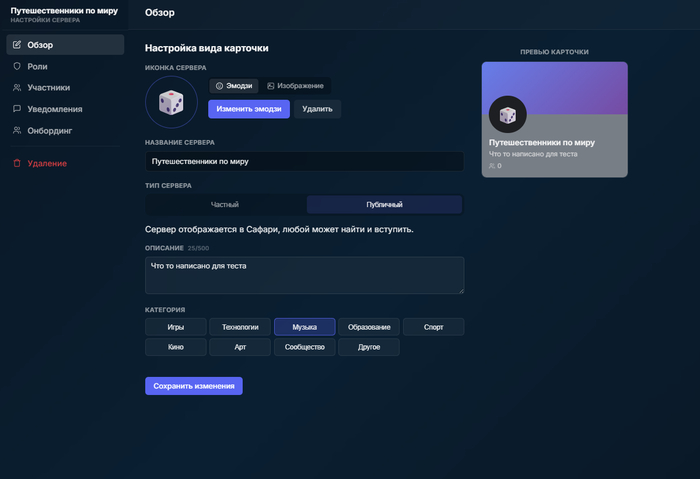
Разработка логистической программы
5 постов
5 постов

Всегда платежки скачиваю с этого приложения. Но теперь, видимо с недавнего времени - они стали требовать что бы я куда то подписался. А в чем собственно проблема МОЕИРЦ? Почему я не могу скачать обычную платежку и должен делать лишние действия?
Если после сегодняшнего дня не будет никаких серьезных ответок в Украине, что бы там даже слова Москва или Россия боялись произносить - то это покажет что у определенных людей не достаточно яйц в тех местах где должно быть. Цена 100р за литр уже близка. Я честно в а**е от всего.

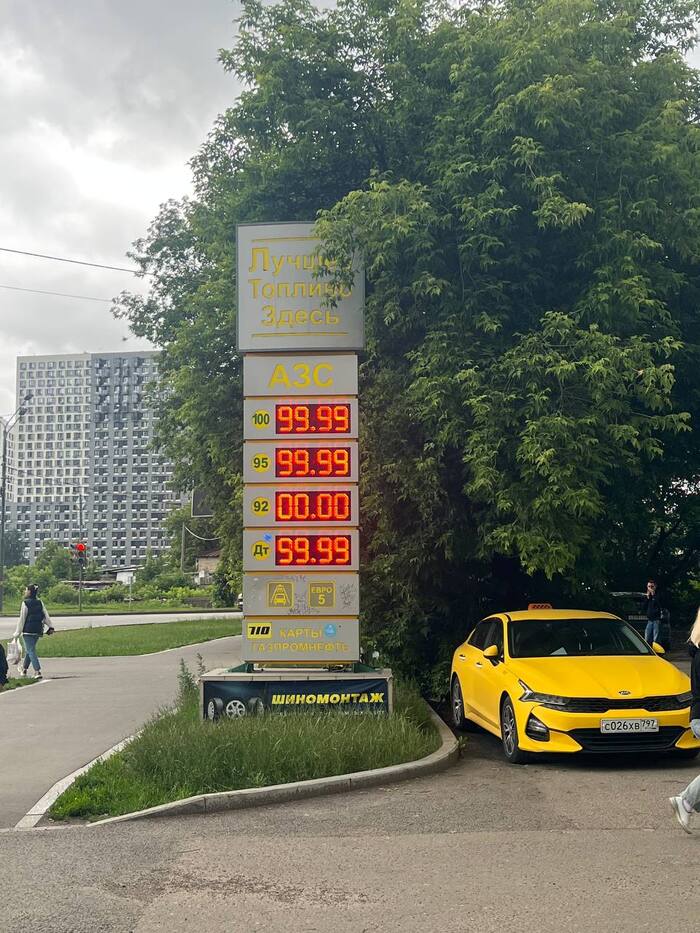
Уверен что в соседних странах бензин явно стоит дешевле, да и гоним мы его в другие страны дошево. Зато у нас полный ппц с ценами. Ну да, уж у нужных людей в карманах явно прибавиться сумма накопления.
Да, может и не популярная заправка, тут всегда на 1-3р выше цена. Но Нефтьмагистраль уже тоже 95р за литр выставили.
Всем привет! Продолжаю свою историю с чат сервисов. Расскажу о болячках и проблемах, и о том как их решали.
У нас прошел еще 30 апреля. Что по конфигурации:
2 CPU
4GB ОЗУ
20GB SSD
OC: Ubuntu
Арендовали у Яндекса, из всех у них был самый дешевый вариант и довольно легкий в настройке. Все встало сразу, без танцев с бубнами. Ценник приемлемый, но зная что яндекс фанаты воровать чей-то код - немного опасаюсь того что слижут (хотя казалось бы вообще должно быть все равно, кому он нафиг сдался).
Что по нагрузке? В статике сервисы не пожирают процессор больше чем на 15-20% (Основной потребитель сервис транскрипции, без него 10%). ОЗУ тоже в порядке, 900мб из 4GB.
Поставили поверх основных сервисов еще дополнительно Portainer (аналог докера десктопа, но с чуть меньшим функционалом), grafana + prometeus для метрик, вместе со всем без сервисы транскрипции сейчас 1.1gb потребление ОЗУ и 16%CPU. Ну это мелочи. Сейчас начнем уже тестировать в открытую с нормальным трафиком.
Ох их было много. Ну кто-же знал что например пути для медийки будут разные. И вот одна картинка аватарки руинила вообще весь UI. Потом пути не правильно парсились - исправили. Часть функционала не хотела работать должным образом - переписали ряд мелких модулей. Например из такого прикольного - система прав пользователей. Запускаешь на локалке под 2 учетками - все работает, сервисы те же самые. Компилируешь прилу, запускаешь с сервера - ну вот не обновляются они в real time и все. А проблема была в одной строке ws, которая за собой тянула просто уйму компонентов. Нашли, разобрались и все заработало. Сейчас 97% примерно функционала работает должным образом. Есть еще проблемы - решаем.
Вот эти твари вообще появились откуда не возьмись. При деплое часть файлов которые были второстепенные и их основной модуль не опрашивал - просто не залились и ошибок не было.
Опять же как пример: Есть у нас сервис Emoji который позволяет создавать свои наборы эмодзи и применять их как в сообщениях, так и в реакциях. Вот rout который отвечает за создание пака - скопировался, а route который отвечает за отправку и получения медия - не перенесся. Долго искал проблему. Тем более интерфейса нету никакого, а в лине я вообще нуб. Нашел, написал скрипт который сам заливает по SSH файлы, проверяет на соответствие, и если нет - дозаливает. Почему так - не знаю, но хотелось бы узнать.
И всякие мелкие тоже повсплывали недочеты, права, Pub\sub события и тп.
Вот тут я вообще офиг и ушел на неделю читать про безопасность и то как порты влияют на доступ извне и бла-бла-бла. В общем, неделю две назад стали замечать что наша база вечно дропается раз в день. Ну казалось бы не жалко, дропайся, посмотрели Volume в докере, все стоит, дропаться не должна, подумали что косяк у яндекса. А вот и нифига. Решил я значит залезть в БД и глянуть логи. Оказалось что кто-то обычным перебором IP и портов залез в БД (Да, я открывал на нее порт, что бы компас подрубить и смотреть данные тестовые). И вот он у себя видимо поставил скрипт на повтор и дропал нам базу. И самое смешное создавал там новую БД с коллекцией README в которой была только 1 запись, цитирую "Кинь биток пожалуйста иначе солью БД". Поржали мы с этого и пошли капать как нам изолировать все. Оказалось что в первоначально версии я задумался о бэк безопасности от эксплойтов, но оставил прямые эксплойти в Compose докера и еще открыл порты. Теперь у нас полная изоляция через NGINX и 3NAT-a. Доступ есть только у нашей команды по нашим IP которые не статичны (Да-да, приходиться раз в сутки менять IP в доступах что бы можно было подключаться). Порты у сервисов теперь проставляет только Docker и автоматически это делает.
Мы сейчас собрали живое приложение, устранили большинство эксплойтов и багов.
Вот так выглядят чаты, все работает, все аккуратное
Добавили лобби для голосовых комнат
При нажатии подключиться - входите в саму комнату
Протестировали звуковой кодек который основан на ИИ модели и я хочу сказать что не зря мы потратили время на обучение модели. Очень хорошо работает. Не уровень дискорда конечно, но шумы отсекаются прилично не влияя на голос.
Доработали "Заметки" к сохраненным сообщениям. И нет они не локальные, все лежит на сервере.
Нажимаете "Заметка", пишите что надо и все, всегда помните об этом.
А что у нас по задержкам ответа:
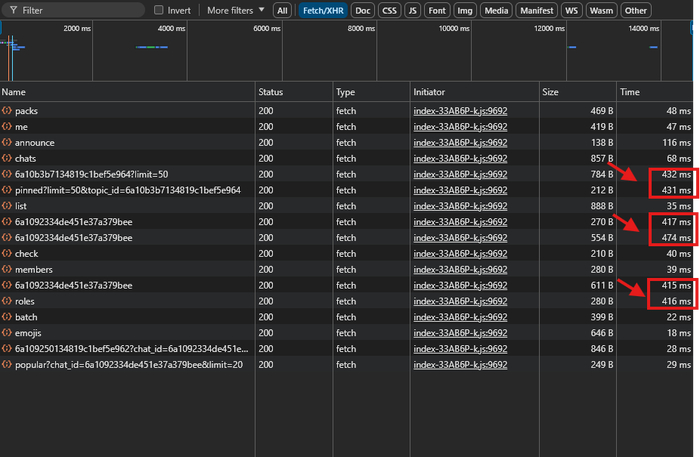
Есть пара мест, но тут мы знаем в чем проблема. Играет 2 вещи:
Это порядок запросов (исправляем). Фронт открывает на эти запросы 2 тоннеля и пока один не отработает второй не начнет гнать данные. Но тут больше архитектурный подход
Куча подкапотных запросов из которых часть так же идет несколькими туннелями вместо одного. Тут не все получиться решить, но сократить где-то на 40% время запроса - думаю сможем.
Задержка в звуке, тестировали на 9 человек - вообще минимальная 30-100мс. Практически говоришь и сразу слышишь собеседника.
Ах, да. Мобилки. Мобилок пока не будет. Т.е. они готовы, но надо стилевые файлы править под новые функции, не делали пока что. Как бы работают нормально, но есть косяки. Да и в ПК версии тоже косяки будут. Но сил самим 100 раз тыкать одно и тоже уже нету.
Шифрование. В коде оно реализовано для 1:1 общения, но мы его выключили. Нам не нужны проблемы в тв.Майором на этапе тестирования.
Сбор данных и метрик. Их нет. Ну точнее как нет, ради безопасности ваших доступов мы собираем только слепок метаданных пк. Но не для их хранения, а для того что бы на этой основе составить пары ключей доступа и вам не приходилось 100 раз в день вводить логи + пароль - получать ключ входа на почту и тд. Т.е. один раз запрашиваем данные при авторизации, создаем пару ключей, далее рефрешим их и проверяем совпадают ли ваши текущие данные с теми что были отправлены заранее. Если нет - релог. Рефреш раз в Х секунд (минут). Больше мы ничего не запрашиваем. За VPN не бойтесь - не смотрим, нам это не надо. Если вдруг будет много возмущений и слов "Да нам не нужна эта защита я хоть 1000 раз в сутки готов вводить код" - таких будет большинство - отключим и пусть любой подменяет ваш токен.
Ну вот и все, спасибо за прочтение. Сейчас мы готовим страницу с информацией о приложении и ссылкой на скачивание, с нашим описание и тп. (Надеюсь) скоро уже сможем дать попробовать пообщаться в новом мессенджере.
Если есть какие-то предложения, вопросы - пишите, с радостью отвечу. А может быть что-то интересное подскажете.
За 25 дней нам удалось добиться довольно больших изменений в нашем проекте.
Мы провели:
Рефакторинг back-end сервисов
Убрали часть легаси кода на фронте
Переработали некоторый UI элементы и добавили плавности
Добавили новый функционал
Чем бы дитя не тешилось, лишь бы не плакало
Именно так мы подумали и решили завершать первый важный этап нашего MVP проекта. Мы подготовили всю инфраструктуру к работе, подбили UI что бы если и есть баги - то которые мы явно упустили за 30 часов тестирования.
Мы добавили в приложение следующее:
Рассылка кодов авторизации
Поиск серверных чатов
Подписка у пользователя в сообщениях какая это роль
Переработали дизайн тредов, теперь у него больше настроек
Сохранение сообщений
Поиск общих чатов
Не есть что конечно, слизано с приложения Discord, но мое виденье его внутри компании немного другого формата.
В чем вообще задумка его для корпоративного мессенджера? Для начала легко найти чаты внутри команд или структур. Группировка - это настраиваемые элементы, мы вывели их в отдельный конфиг, так что поправить под компанию - 5 минут. Настраивается из настроек чата.
Подписка у пользователя в сообщениях какая это роль

Представим что к вам пришел новый сотрудник, а в команде 50 человек. И вот ему надо привыкнуть еще к тому кто разработчик, кто тестировщик, кто стрим лид и тп, а еще же ведь и правильных людей тегать. Эту проблему и позволяет решить данная приписка.
Переработали дизайн тредов, теперь у него больше настроек
Вот тут наверное самое важное, то что плохо реализовано в корпоративных тредах. Долго думали что же нам не хватает и как попытаться уместить все в обычную форму.
Мы расширили настройки на создание тредов

Теперь кроме названия треда и иконки можно:
Проставить теги
Написать нормальное описание
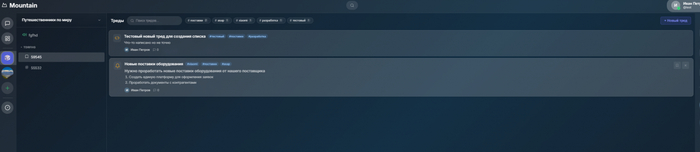
После создания тредов теперь мы можем не только посмотреть их список, но и так же:
Отфильтровать по названию, даже по одному слову в середине текста названия или описания
Отфильтровать по тегам, идет сортировка по часто используемым
Закрепить тред (все закрепленные всегда будут вверху, только потом будут идти не закрепленные, даже при поступлении в них новых сообщений)
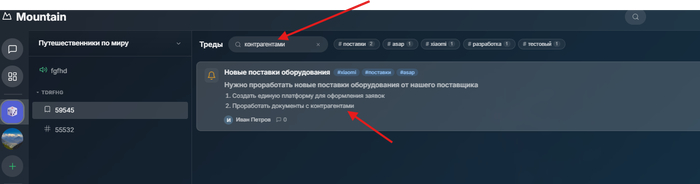
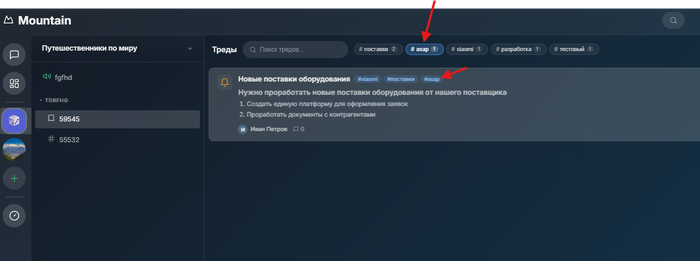
Возможно, предвижу, кому-то удобнее прям внутри сообщений писать, тем самым создавая обсуждения. Потом мы добавим такое, но не в рамки обсуждения, а в рамках внутренних комментариев.
Рассылка кодов авторизации
Инфраструктура под это дело заложена в сервис авторизации. При регистрации или авторизации сервис будет отправлять на почту пользователя сообщение в формате HTML.
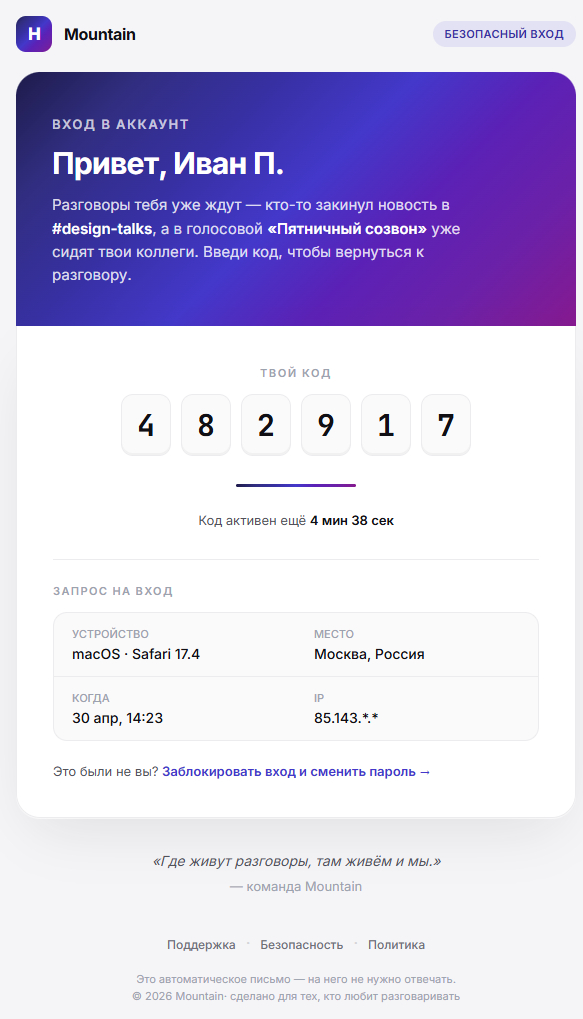
Пока еще не заводили отдельную почту для нашего сервиса.
Мы изменили логику проверки прав, она стала более замудренная, но в тоже время и более правильная.
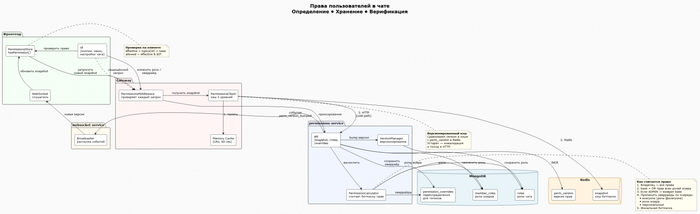
Теперь Gateway (основной сервис который либо пропускает запрос, либо нет) - подключен к redis pub/sub, инвалидирует версию прав и бит маску. Если не было события изменения - берет из мемори, если была - обновляет свой кеш. Кеш одного пользователя занимает 600.B. что не является слишком много. Для тяжелых прав на 2000 пользователей в одном сервер чате это около 4.5мб. В целом - пойдет.
Кеш хранимый в gateway:

Сервис топиков тоже потерпел изменения. теперь он не ходит в Permission сервис что бы уточнить права пользователя на просмотр, а Gateway: ProxyRouter приклеивает заголовки:

А сервис топиков их начинает парсить:

На выход топик сервис уже отдает отфильтрованные темы которые соответствуют правам пользователя внутри его роли:

Наконец то вынесли все коллекции сервис в отдельные базы. Раньше была одна общая БД, делалось для быстрого написания кода, но пораждало много зависимостей и хождений в чужие коллекции. Теперь все сервисы имеют свою БД со своими коллециями. Отдельный инстанс имеет только сервис сообщений.
50% сервисов перевели в режим публикации событий. Т.е. раньше было много HTTP вызовов между ними, что пораждало лишние задержки в 1-4мс. Мелочь, но в рамках 1000 или 10000 пользователей это уже существенная нагрузка. Теперь HTTP вызовы служат только для получения информации от другого сервиса, все события которые раньше были - переложены на Redis. Пример: Пользователь зашел в новый чат. Сервис чата сформирует событие что у него появился новый memories, сервис прав подхватит это событие и присвоит ему права и положит их в Redis, сервис Gateway увидит новые данные и заберет их к себе.
Мы работаем над переводом остальных сервисов, но не все так быстро))
При создании проекта, я вообще ничего не знал о методах разработки фронтенда. Сейчас когда нас несколько уже и мы отходим от AI разработки - начинаем сталкиваться с проблемами. Например тогдлы переключения - так как фронт писал ИИ, он в каждую форму где есть тогл - делал новый стилевый файл, и таких файлов скопилось 15+ ед. Мы перевели их на shared и пере-используем. И таких компонентов было очень много. В итоге нам получилось подчистить примерно 2к стилевых строк кода, сократить в JSX около 150 строк, потому что теперь это общие подключения.
Выделили отдельные сервисы кеша. Тонкие обёртки над универсальным key-value store для кэширования. Не хранят данные сами — только формирует ключи и инкапсулирует логику работы с одним конкретным namespace. Пример ниже:

Аналогично сделали и с WS сервисом, вынесли все WS действия в отдельные сервисы, для сообщений, топиков, прав, тредов и тп. Раньше это были одни монолитные файлы.
Большую часть действующих фронт сервисов перевели на isMobile проверку. Например анимации фона на мобилке - не нужны, мы их не грузим и в сборку они так же не попадут.
Часть изменений и доработок написал выше.
Изменение в тулбаре голосовой комнаты:
Теперь это отдельный виджет. Кнопки анимированные, при наведении на ПК показывают анимацию
Добавили выбор устройства на ПК:
Тоглам кнопкам добавили плавный переход при нажатии, на фото это не будет видно.
Для мобильной версии сделали 2 вида тапа.
Короткий: Открывает меню взаимодействия с сообщениями
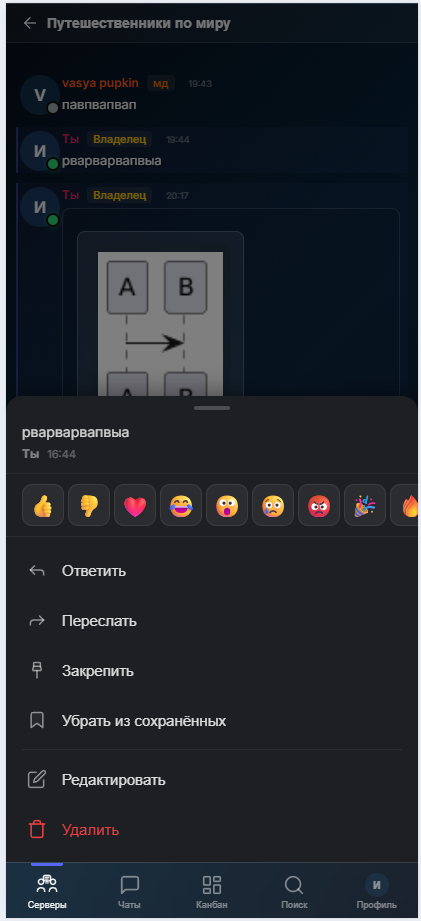
Короткий тап который открывает меню управления
Длинный: позволяет выбрать несколько сообщений сразу. Удалить, переслать или ответить
За 25 дней мы проделали огромную работу над проектом. Работали порой и до часу ночи. Все прошлые выходные провели с утра до ночи в нашем проекте.
Сейчас у нас:
16 микросервисов бэка + 5 инфраструктурных
137 микрофронтенд сервисов. Да и кажется что "Как-то много" - действительно так, много логики.
Что сейчас:
Наши инфраструктурные сервисы готовы. Мы начинаем фазу тестирования. Активно ищем сервер в аренду с простой поддержкой и не очень дорогой. Хотели 20.04 уже запуститься, но не успели, мысли приходили на лету и где то правили, где-то дорабатывали. Плюс еще потратили кучу времени на обучение RNNoise модели. Вроде теперь давит шумы хорошо, не уровень Krisp конечно.
Спасибо за то что прочитали! Задавайте вопросы если интересно. Готовы версии для PC, IOS, Android. Они на WebWiev, но мы старались мобильные версии оптимизировать.
P.s. Если есть небольшая компания со своими мощностями в которую можно запустить тест для сотрудников не Free основе - напиши в ТГ: AN_Cayo. Настроем под вас наши конфиги и поможем расскатиться) (Ну мало ли повезет и найдется такая возможность. Без буллинга плиз)
Upd. Мессенджер не только для корпоративного общения. Для общего с функциями друзья, черные списки, E2E шифрования лс - будет чуть позже.
Приходит мне сегодня уведомление на телефон:
"Доступно свежее обновление"
Нажимаю на него, далее нажимаю скачать обновление.
Иииии... И нифига, не скачивает. Пришлось включить VPN что бы скачать. Одно обновление только 1.2GB весило. Серьезно и за это мне потом еще платить? Да идите то кто это придумал на..... небо за звездами!
Телефон Samsung galaxy s24 ultra.
Так что кто говорил что все это фигня и блокируют только плохие сайты - шах и мат вам. Блокировать будут все.
P.s. Пытался через LTE и WiFi. Никак пока не было обхода.
Показываю итоги разработки. Сейчас к процессу присоединился знакомый Front-end разработчик. Устранили очень большое кол-во проблем в том числе с WS, кешем и прочим, так же убрали эмодзи и переложили их в рендер на JS. Можно было брать готовые референсы из интернета, но везде надо указывать авторов.
Теперь про дизайн / стиль и прочее.
Начнем с прочего и это будет бэк.
Сейчас проект насчитывает 15 основных сервисов и 4 сервиса инфраструктурных, плюс 3 сервиса мониторинга.
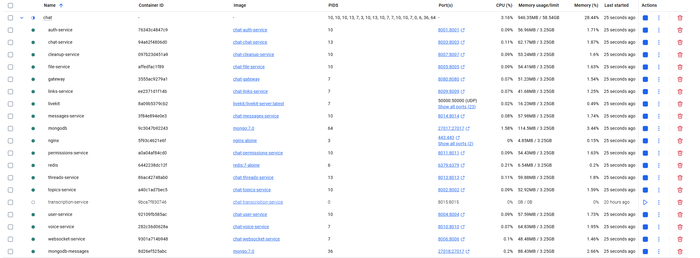
Docker desktop сервисы
Сразу скажу, сервис транскрипции отключен не потому что не работает, а потому что в простое потребляет 200мб выделенных ресурсов. Если судить по описанию либы которую использую и модель - это нормально.
Принцип разработки был построен на максимальной изоляции сервисов друг от друга. Т.е. единственный сервис который имеет между собой какое-либо взаимодействие с другими это сообщения. Сообщения ходят в треды или топики что бы обновить числовые значения или отправить push о том что есть новое сообщение. Если будет интересно разобрать какой то сервис отдельно - напиши в коммент я опишу.
Выделили мы фронт в отдельную монорепу. Раньше весь проект был в одной общей репе.
Auth - сервис отвечающий за авторизацию, выдачу токенов, рефреш токена, создания пары новый / старый токен.
Chat - Отвечает за сами чаты, личные, канбан, серверы.
Cleanup - отдельный воркер который очищает старые данные, проверяет на актуальность
File - отвечает за хранение файлов, создание метаданных, проверка вложенности, проверка что pdf это именно pdf и ничего более, что бы не закинуть вирус. так же занимается шифрацией файлов.
Gateway - сервис шлюз, он отвечает за выдачу пропуска на каждый запрос. Проверяет роли через permission, проверяет что вложено, активный ли токен, кол-во запросов и тп.
Link - сервис гиперссылок. Вынес его отдельно, так как он подгружает информацию на фронт из ссылки и проверяет что внутри ссылки лежит.
Messages - сервис отвечающий за сообщения. Самый нагруженный сервис из всех. Его задача не только получить данные текста, сохранить и отдать. Но так же отвечает за пересылку сообщений между чатами, закрепления, уведомления, реакции на сообщения и тп. В идеальном формате перевести все уведомления в будущем на отдельный сервис. Но пока так
И куча других сервисов. Остановлюсь только на транскрипции. Это не прям сервис, это бот. Бот секретарь в голосовых встречах. При его включении он начинает слушать комнату, производит транскрипцию, собирает всю транскрипцию встречи в т.ч. с информацией какой участник говорил, собирает промт и отправляет в ЛС инициатору, инициатор выбирает что и где подправить, согласует и бот уходит в GigaChat с просьбой произвести перевод из каши на протокол встречи. Бот сейчас больше экспериментальный, на CPU работает тяжеловато, есть артефакты, на GPU работает супер. Понимает контекст голоса на 90% и транскрипт выводит +- хороший.
Отдельно про безопасность. Все данные которые отправляются на сервер имеют валидацию по различным форматам, синтаксис, sql инъекции, html тегирование и прочее. Под это дело зашит отдельный сервис в gateway + часть этого же зашита во все другие сервисы как доп проверка с более обширным функционалом. Средняя латентность ответа на докер десктоп в районе 40-70мс.
Теперь про дизайн и интерфейс.
Как зарождался вообще дизайн? (Мало кому интересно, но все же). Писал его опираясь на discord и mattermost формат. В начале делал отрисовку в Figma частично с набросками основных элементов, потом писал бэк, оборачивал все с один промт на AI, смотрел как получилось и если норм - оставлял, потом переделаю, если нет - переделывал сразу.
В целом, AI создал хорошую базу, но иногда встречаются недочеты в виде спагетти и ошибки в рамках что где-то что-то не учел. Сейчас мы перестаем им пользоваться в рамках разработки, но используем в рамках объяснения кода и связанности слоев.
Первоначально сообщения были в стилистике телеграмм, но я заметил что очень много пространства остается пустым и если я отправлю PlantUML диаграмму то она уходит в лево и отображается как будто визуально под другим пользователем.
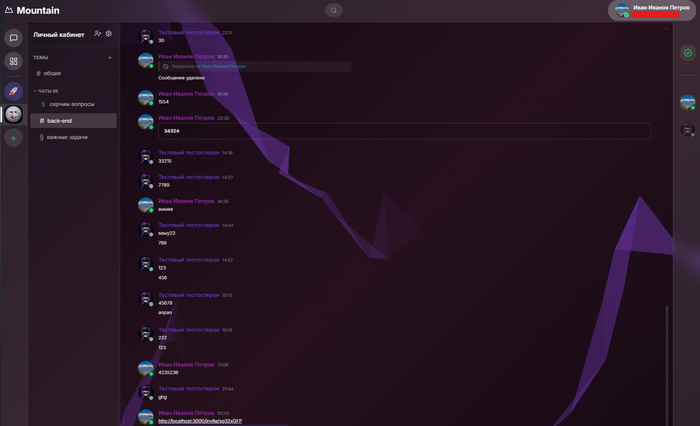
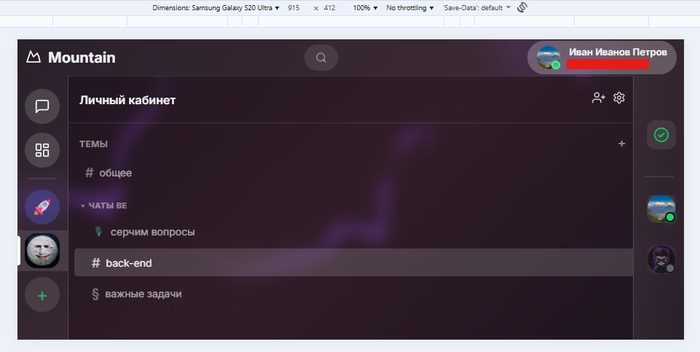
Основное окно диалогов
На фотографии мы видим:
Название программы Mountain
Левая панель с выбором чатов, личные, канбан, сервера
Верхняя панель
Правая панель с ToDo и активными участниками чата
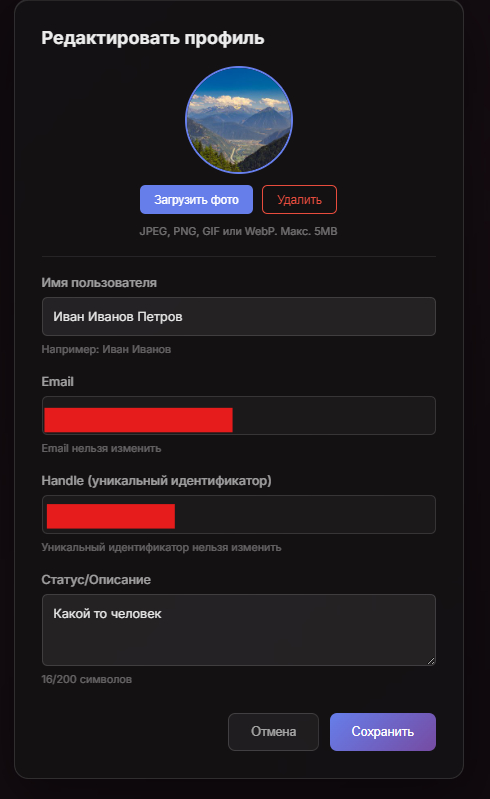
Настройка пользователя

Меню настроек стиля

Вторая часть настроек
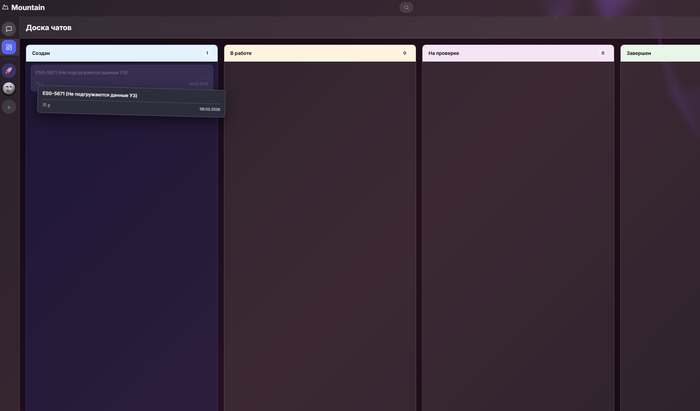
Доска чатов по задачам
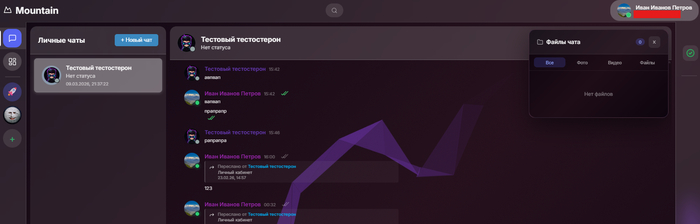
Личные сообщения + список файлов и медиа

Пример личного звонка

Общий голосовой чат
Если вы начали диалог в голосовой комнате, но решили перейти в другой чат ответить на сообщение, звонок не сброситься, перейдет в верхний трей и будет показано что сидите в эфире.

Трей с активным звонков

Быстрый поиск сообщений
Поиск по сообщениям, ищет по буквам и ключевому слову. При клике перенаправит на сообщение и выделит его

Настройка чатов серверов
Серверы, а не чаты названы потому что часть сервисов автоматически масштабируется для распределения нагрузки. Вообще идет 2 слоя от которых происходит масштабирования от кол-ва активных чатов и от потребления ОЗУ и ЦПУ. Уровни настроек чатов такой же как в ДС.
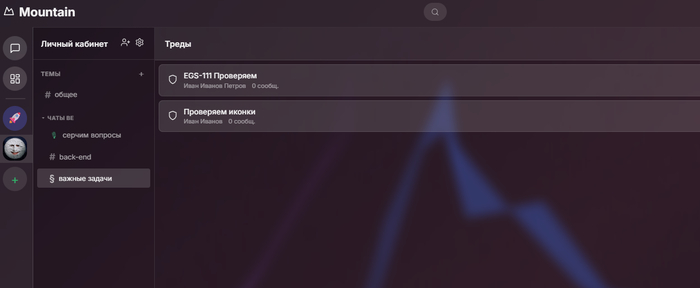
Топик тредов
Вот треды это отдельная тема. Т.е. есть топики (темы) и внутри них как отдельный сервис есть треды. Треды не живут долго, 1 месяц, потом переходят в архив как и сообщения, достаются списки уже через пагинацию.
Значит что мы видим выше - это основные окна с которыми часто придется взаимодействовать пользователям. Стиль - можно менять, у меня выбран тот стиль который мне приятен глазу, да бордовый и ничего страшного. Все цвета сообщений, имена пользователей - подстраиваются под цвет бэкграунда.
Для личного не будет "ToDo, Kanban доски чатов, бот секретарь", но будет раздел "Друзья".
Да, стиль очень схож с дискорд. Считаю не страшно, в этом и была задумка, но это удобнее чем другие корпоративные мессенджеры (slack, mattermost) с пол сотней различных чатов и еще тысячей тредов которые вообще не понять как работают. Для меня смесь стиля discord и функционала mattermost с telegram - получаем что-то между и это более приятное решение. Да и зачем придумывать что-то новое, когда уже есть все, бери и адаптируй.
ToDo делал лично для себя. Но прижился в проекте. Мне удобно прям в момент встречи сделать сразу задачи себе и проставить даты. Это удобнее чем иметь множество различных приложений.
В процессе разработки выпилил интеграцию с такими сервисами как: Google meet, Jitsi и яндекс телемост. Причиной стало наличие своего сервиса для конференций.
Окно ToDo
Написал много, очень размазано. Что писать - честно говоря не знаю, проще отвечать на вопросы. Так же зреет адаптация под мобилки.
В формате для мобилки
В перевернутом формате мобилки
Над чем сейчас ведется работа:
Улучшение шумодава и передачи звука, вынос настроек со звуком в отдельное меню
Паки эмодзи, они есть везде и не надо отставать, но не в приоритете
Адаптация под мобильное устройство
Вынос в отдельные app для личного и для компании.
Оптимизация при работе со сжатыми файлами без потери качества и сжатие добиваться больше чем через обычный архив
Добавление видео передачи с камеры при общих созвонах
SSO авторизация
Unit тесты. Делать будут онли через ИИ, ему проще скормить сервис и что бы он написал тест.
Про будущее говорить очень рано, продукт сырой, признаю это как есть. Нам бы доделать то что имеем, написать тех доку и попробовать зайти в компанию к знакомым для запуска первого релиза внутри их штата.
Пытался я вынести проект на тестирование, и один знакомый выделил мне сервер на 2U. Однако я столкнулся с проблемой: настраивать сеть я не умею. Запустить проект на Ubuntu удалось, но я не понял, как сделать его доступным для других. Нагружать знакомого уже не мог — он и так бесплатно дал мне сервер. Поэтому пока отложил тестирование и рассматриваю аренду виртуальной машины.
С моей стороны уже были открыты карты по новому проекту можно почитать тут : Тестирование - остановка - новый проект
Я немного задержался с выпуском апдейта по программе, работа + правил много мелких дефектов.
Как и говорил бэк пишется онли мной, фронт - не буду греха таить пишется на AI инструментах. Но опять же как пишется, с наборов Front-end файлов в 700 ед AI справляется туго (начал уже на 400 выдавать) в чем определяется? Выдает много багов в итоговой сборке, приходится править вручную и это отнимает время, по сути то на то и выходит :D
Что за программа? Это смесь Mattermost + Discord. Старался взять лучшие фичи от туда и от туда. В основном программа нацелена на коммерческое использование. Зачем я вообще начал делать это? Вот не знаю кому и как - мне не нравиться Mattermost \ Slack. Одни только треды чего стоят, группировка чатов, а звонки? Вот надо же взять, скопировать ссылку, собрать людей, а если они еще не авторизованы в звонилке компании (Такое бывает, выкидывает, SSO плохо работает) - еще впусти всех. Ну это бред. Особенно мне как любителю discord-ы с удобными звонками и тг с удобными чатами.
Так вот, в программу я взял лучшее из наработок в плане пользовательского интерфейса и старался совместить с наилучшими практиками которые нашел на просторах интернета.
В программе есть\будет:
Личные чаты
Сообщения
Звонки
Анализ задач (автоматический поиск главных слов "Сегодня, сделай, завтра, посмотри, не забудь, т.д.) и создание автоматического TODO листа
Канбан доска
Доска привязывается к задачам назначенным Вам или назначенные вами в Jira. И создает автоматически чат, добавляет туда "Автора" и "Исполнителя" если есть человек который подписался на отслеживание - тоже попадает в чат, либо можно добавить в ручную.
Статус чатов = статусам задач
Серверы \ комнаты - аналог общих чатов в Discord и ТГ
Создание тем
Модерация прав
Группировка тем
Создание голосовых комнат
Общий звонок внутри комнаты
Демонстрация экрана
Создание темы "Тред"
Внутри лежат треды, нажимая на определенный тред можно попасть в комнату чата по треду. Это удобнее чем треды в MM которые создаются из простого сообщения.
Создание приглашений в группу
Для чатов:
Полная поддержка PlantUml диаграмм с автоматической конвертацией в SVG. Можно описание посмотреть и картинку
Поддержка синтаксиса кода:
C++
Python
Go
Java
CSS
HTML
C#
PHP
JS
Поддержка MD формата текста (кто-то любит в таком писать, тем более поддерживает таблицы)
Пересыл сообщений
Закрепление
И много других дополнительных функций
TODO лист задач
Создаются автоматически из контекста
Создаются вручную
Отдельный сервис ботов
Преднастроенные будет только 3 бота и то для работы (в будущем возможно пораскину мозгами и придумаю действительно нужных для работы или общего пользования)
Уведомления о встрече из почты
Уведомление о GitLab изменениях при подписке на определенную ветку
Уведомления из Grafana об Alert-ах
Многое еще что в разработке и пока не раскрыто. Но в планах внедрить AI модель на BE для определенных задач.
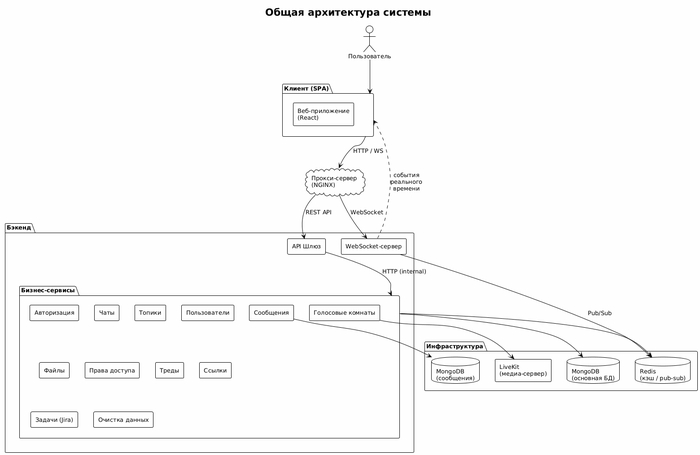
Картинка кстати сформирована внутри чата приложения из PlantUML синтаксиса.
Описана общая структура системы, но подробности я не описываю во всех красках...
Приложение имеет 2 формата для компаний и для личного использования.
Остальное спойлерить не буду, только авторизацию. И пусть все думают что только она и есть)
Компаниям важно иметь все свои данные у себя под рукой, поэтому тут прописывается отдельный URL для подключения к сервисам которые развернуты на их стороне.
Интерфейс так же меняется.
Для обычных пользователей не доступны функции TODO, Канбан доски, привязки к Jira или GitLab. Они им просто не нужны. Поэтому интерфейс немного отличается.
На архитектуре рисунок 1 - указано HTTP, почему так? Сейчас приложение развернуто в докере локально, мне тут не нужно дополнительное шифрование. Когда будет деплой (если будет) на сервер компании - в программе уже все готово к работе по HTTPS.
В чем плюсы приложения? Ему не нужен (МАХ). Все сообщения даже сейчас шифруются и дешифруются только на стороне клиента. Какие для этого использованы технологии - расскажу в сл. посте. Но сама суть в том что Дешифровать если получишь энкриптор получиться максимум один чат. Если пользователь решил переслать из одного чата в другой, то клиент выступает дешифратором и шифратором. Нагрузка есть, но минимальная, по моей задумке нагрузка в 2мс на сообщение из чата с 5к пользователями.
MongoDB для сообщений это временное решение. Мне было проще JSON модели делать и накидывать стиль. Позже она переедет в другую No SQL базу.
Что по звонкам? По звонкам интересно. По документации и оптимизации кода в моменте на комнату может быть 3к пользователей при условии 10 спикеров. Если будет 100 спикеров единомоментно - то 1.6-1.8к. Как будет в действительности покажет только практика. LiveKit почти не ест ресурсы и очень оптимально работает. Но кодек настраивать очень долго.
Защита от бутфорсов - имеется. Учтено сразу 2 формата:
Единомоментный запрос в кол-ве Х
Валидация кол-ва запросов с авто блокировкой последующих
Получается так, если злоумышленник захочет подобрать пароль и отправит 100 или 200 запросов в момент - они просто не пройдут шлюз. Он их не пропустит. Так еще и заберет 4 рандома и наложит ограничение.
От инъекций и прочих ненужных вещей используется санитайзер. Это значит, что все запросы, где потенциально могут быть отправлены данные, проверяются и валидируются.
K8s настроен. Предполагается, что основные сервисы работают на двух-трех чатах, а затем масштабируются в зависимости от нагрузки. Однако, если в чате менее 100 пользователей, одного сервиса хватит на 10–15 чатов. LiveKit масштабируется в зависимости от количества людей и комнат.
Что по ресурсам, сейчас приложение кушает около 450мб ОЗУ. Средняя латентность запросов 50-0мс и это на докере десктоп через WSL. По звуку - работаю над ним. Хочется сделать качественный шумодав.
Определимся с термином «хочу». В контексте разработки это означает «представляю». Я хочу запустить закрытое тестирование приложения на 500 человек в конце марта — середине апреля. Почему закрытое? Всё просто: аренда сервера для этого теста будет полностью за мой счёт, без спонсорской поддержки. Я планирую использовать виртуальный сервер с тарифом в районе 7–9 тысяч рублей (цены, конечно, кусаются).
Если сервер справится с нагрузкой в 500 пользователей и будет работать стабильно, я продолжу тестирование и расширю окно для пользователей. Если же возникнут проблемы, то придётся:
* Оптимизировать код.
* Поработать над улучшением запросов.
На данный момент у меня готовы две версии приложения:
* WEB.
* Windows.
Версии для iOS и Android также будут разработаны, но в первой итерации, скорее всего, они будут представлены в виде веб-вьюшек. Я адаптировал интерфейс под мобильные устройства, но создание отдельных версий пока не в приоритете. Если у вас есть идеи, как сделать текущий код совместимым с мобильными платформами, буду рад обсудить это в личных сообщениях.
Функционал в тестировании будет урезан примерно на 30% от фактически разработанного. Почему так? Некоторые фичи очень тяжелы в описании. Какие успею добить - залью на тест.
Вообще много кому из знакомых показывал функционал и интерфейс - очень довольны. Плавность, логика - все есть. Нету ИИ-ых эмодзи (Я заменил их на прямую отрисовку в коде, вес приложения меньше, нагрузки практически нету). Острые углы от ИИ - тоже сглажены. Подправлена логика и получилось немного сократить код.
Что думаете? Жить проекту или не жить?)) Да, знаю есть куча заменителей и можно сказать "Очередная хрень под копирку". Но как показывает практика в нашей стране - все к чему у людей растет интерес рано или поздно блокируется... А приложений сделанных для людей а не для "маркетинга" - очень мало.
Всем привет! Прошел месяц с последнего поста про программу для логистического анализа, пришло время поделиться тем, что произошло за это время.
В прошлый раз я уже говорил, что программу буду готовить и передавать на тестирование в наш отдел аналитики. Так и случилось, после январских праздников мне удалось созвониться с логистами и показать им свою наработку. Встреча прошла не очень долго и не очень быстро, но смог заинтересовать коллег. Скомпилировал через PyInstaller и отдал на тестирование. За 2 недели получилось собрать некоторые логи, исправить критически важные моменты. Сейчас программу проверяют на качество расчета, сколько будет идти все тестирование — не знаю, но фидбеки получаю часто.

Что будет с проектом?
Наверное оставлю текущий функционал, удалю заглушки которые были, поправлю криты и выложу в общий доступ. Понял что развивать его как бизнес модель - не смогу.
Но многое подчеркнул из проекта и сделал выводы. Если вдруг будут желающие получить доступ к гиту — пишите в ТГ «AN_Cayo», и я выдам доступ к программе.
Теперь настало время поделиться чем-то новым и более живым.
Сейчас активно ведется работа над новым проектом. Раскрывать подробности сейчас не буду. Сделаю мини-презентацию в середине февраля, но поделюсь стеком, на котором ведется разработка.
Back-end
Python
MongoDB
Cassandra
Redis
ElasticSearch
Front-edn
React
JavaScript
Доп либы, библиотеки и прочее
LiveKit
WebSocket
И остальные
Архитектуру, стэк и первые основания я начал закладывать еще когда был в отпуске в ноябре, тогда и созрело виденье окончательного концепта. Но тут я учел все нюансы из прошлой разработки и наконец перешел на клиент-серверную архитектуру с добавлением Web-разработки.

Ну точно ведь интересно)
На какой стадии проект? Бэк написан примерно на 70%. Так как в этом сервисе не закладывается такая тяжелая логика, то я пишу сервисную часть, проверяю ее, оптимизирую и отдаю AI-модели. AI пишет фронт чисто для бэка, далее я смотрю код, оптимизирую, проверяю роуты, правильность, декомпозицию. Если предложенный код не соответствует стилю FSD (featured sliсed design), то уже декомпозирую сам. Но это на порядок быстрее, чем писать всё самому. На сколько? Примерно на 80%. Допустим, один фронт сервиса самому мне пришлось бы писать 2 дня, с таким подходом — 2 часа.
Почему не уйти в вайб-кодинг проекта? Вайб-кодинг — фигня. AI-модели, конечно, развиваются быстро, но за ними нужен глаз да глаз. Проще бэк написать самому, проверить и поправить. Заодно может и код получиться сделать коротким, без лишних подключений.
С чем интересным пришлось столкнуться в новом проекте? Например, более лучше узнал со стороны кода, как работает веб-разработка и уведомления, на тех. доке всё куда проще было)) Аналогично и работа со звуком. Можно было бы пойти по пути «Развернуть Jitsi», но тогда это внешний сервис, лишние переходы, пришлось изучать, как работает передача звука и видео. В изучении мне помогали AI-модели с более детальными описаниями, дока в Git от разработчиков и техническая спецификация.
Программа находится на оооочень глубоком бета-тестировании. По планам развернуть первую бетку уже в конце марта и привлечь хотя бы человек 500–800 для стресс-теста. Писать тестовые программы, которые будут смотреть производительность, — это одно и показывают нормальные тайминги и нагрузки без утечек памяти. Но самое главное — проверить голос и нагрузку на сервер.
Ниже приведена архитектура одного из сервисов в отдельной интерпретации, чтобы не спойлерить всю идею проекта.
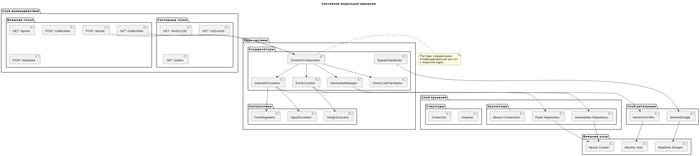
Одна из схем сервиса, в отдельной аллегории, отражает действительность
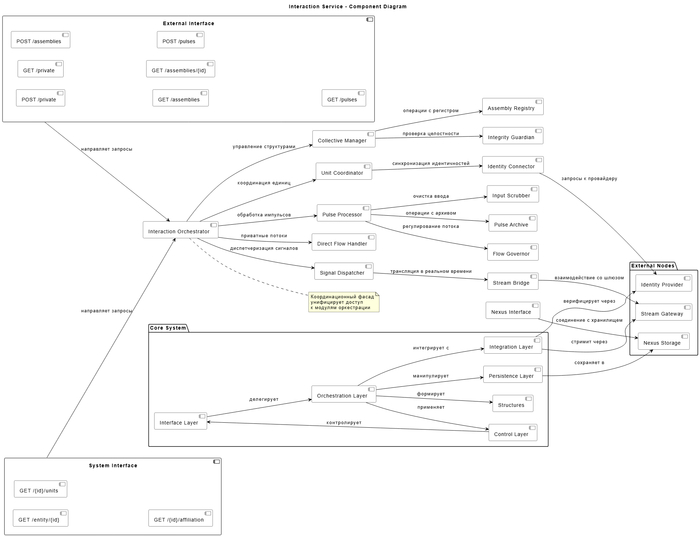
Схемы выше — это аллегории, которые отражают фактическую архитектуру, но названия изменены специально.
Аналоги этого приложения существуют, но разработанных в России нет. Точнее, есть, но они не работают так, как хотелось бы. Когда приложение создаёт человек для других людей, качество обычно выше, чем когда это просто маркетинг. Стараюсь учесть все нюансы, и сейчас интерфейс выглядит интересно и современно.
Один из сервисов, вероятно, будет показан через две недели, когда я доведу его до совершенства.
Кажется, я рассказал достаточно о старом проекте и планах на новый. Новый год начался очень насыщенно. Не понимаю, как жена еще не выгнала меня из дома, ведь порой я сидел над проектом до двух-трех ночи.
Спасибо всем, кто прочитал!


