


Автоматический полив растений своими руками
Ардуино, два насоса меммбранных, шланги, куча тройникиков, и штырьки от капельного полива ну и большое желание в паре со свободным от работы временем.




Показать полностью
4
Ардуино, два насоса меммбранных, шланги, куча тройникиков, и штырьки от капельного полива ну и большое желание в паре со свободным от работы временем.

Вторая часть работы по моей разработке отказоустойчивых ПЛК.
Кто читает впервые:
Я, автор , независимый исследователь ( тот который не работает за счет фондов, институтов и организаций), разработчик SCADA системы Gatherlog.
А так же автор комплекса по разработке Промышленных Контроллеров под названием 3o|||sheet. Среда, IDE читается как Зошыт - тетрадь, но так как для компилятора и среды выполнения названия не придумал, пока все называю 3o|||sheet.
Приходится, одно и то же видео вставлять, так как люди читают, не переходя на прошлые посты, что и о чем у меня за проекты.
В прошлый раз, показал свой научный метод Дивергентного Многоверсионного Выполнения Программ для усиления ошибок, которые пропускают классические методы типа lockstep\TMR.
Суть моего метода в - декорреляции адресного пространства. Мы компилируем программу N раз (смотря сколько ядер или какую точность детекции выбрать) перемешав в памяти код: функции, блоки, и переменные. То есть, если на первом ядре функция Main будет по адресу 1000 то на втором ядре она будет по адресу 2000. Точно так же с переменными - они перемешиваются по разным местам (но не случайным образом).
В этом посте буду делать скрины из своей научной работы.
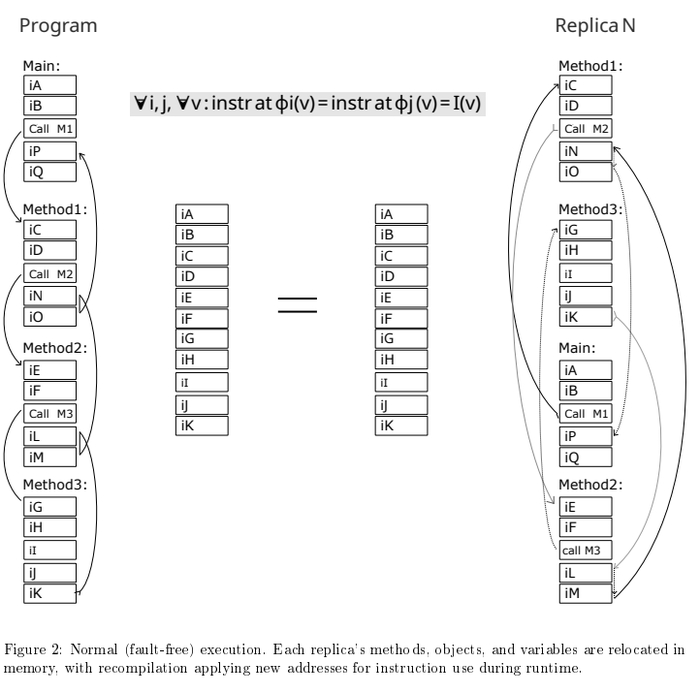
Это совершенно не влияет на ход программы. Каждое ядро, его счетчик команд, будет синхронно прыгать по своим адресам, но траектории программы - будут абсолютно одинаковы.
То есть, при корректной работе, - программы будут идентичны, а при сбое - каждое ядро будет сходить сума по своему из за декорреляции адресов. Это ключевой принцип, так как современные методы lockstep/TMR при сбое (одинаковом сбое всех ядер) сходят сума - одинаково, а значит согласовано, система не заметит сбоя. Это реальная проблема признанная в промышленности. Которую я решил.
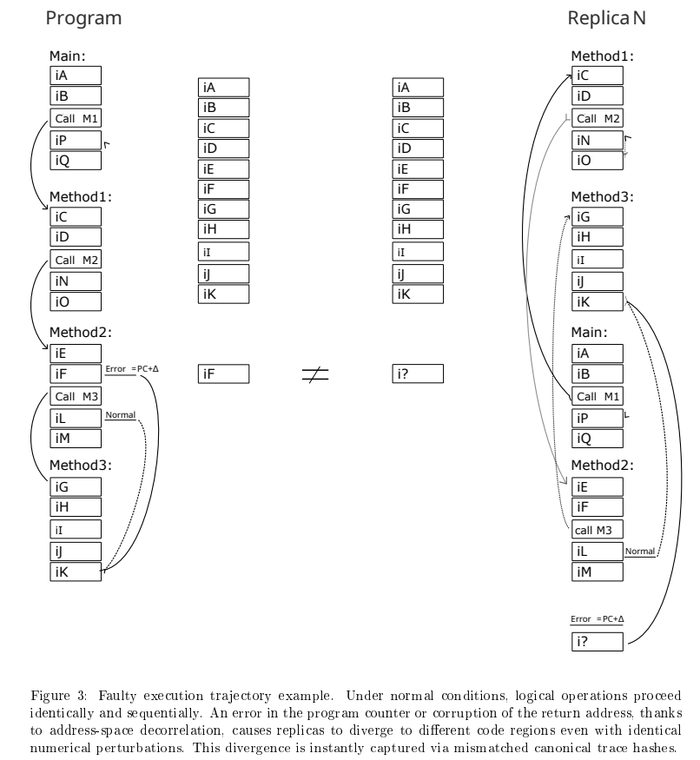
на этом изображении - самый тяжелый случай - обе реплики получили повреждения счетчика команд (переполнение буфера в стеке который затер адрес возврата, или физическая помеха) на одинаковую величину, но из за перемешанных адресов, каждое ядро прыгает в разную область, - мы это ловим.
В прошлом посте, были сообщения, что я все эти ошибки - придумал (радиацию, электромагнитные импульсы), и сам их победил. А в системе достаточно - таймера, который сбросит если все зависло. Так говорит - старая школа, но так было раньше. Почему старые процессоры x386 x486 выпускались 30 лет и до сих пор летают в самолетах? Грубый тех процесс более устойчив к физическим помехам (радиации и электромагнитным полям) на высоте 10 000 метров. Чувствительность современных микроконтроллеров и процессоров к физическим сбоям из за мелкого тех-процесса обсуждается, изучается и все признают эту проблему которая будет только увеличиваться.
Вот группа ученых, которые придумали и даже утверждают , что им в лаборатории удалось доказать , обход системы защиты - пин кода. Своими электромагнитами импульсами они заставили перепрыгнуть счетчик команд через 6 (шесть) инструкций который отвечал за сравнение пароля. Тестировали они на Atmega328 - обычный микроконтроллер.

В своей работе они описывают следующее:

Перевод: «С другими настройками (положением и амплитудой напряжения) мы подтвердили возможность увеличить количество последовательно пропущенных инструкций до шести»
Теперь, когда мы разобрались, что повреждение счетчика команд из за физического воздействия - не моя выдумка, а минимум выдумка еще несколько десятков профессоров,
перехожу к своей научной работе, и то как я предлагаю решать этот вопрос. В моей работе есть есть два раздела, первый - грубая диверсификация кода на уровне функций и логических блоков , о которой я выше упоминал.
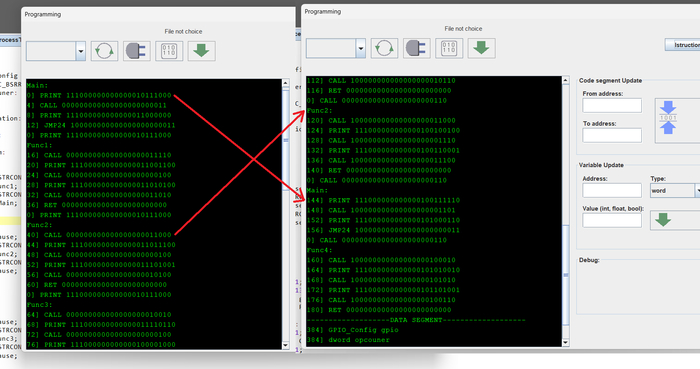
Каждая функция и блок - в перемешанных адресах на каждом ядре.
Второе дополнение под названием: Detection of Small-Magnitude Program Counter Faults. Где я предложил следующий подход. Наш компилятор - вставляет пустые инструкции NOP , периодически, и сдвинуты по фазе в разных репликах(ядрах).
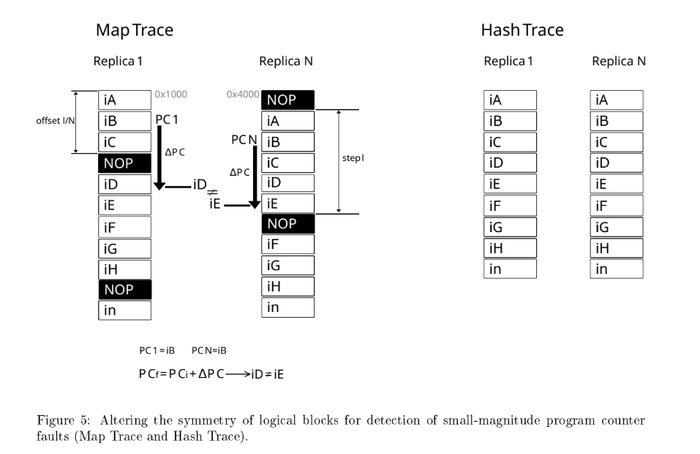
Что это дает, это как раз мешает - пропуску инструкций если физическое влияние "застало" счетчик команд - внутри функций. Формула указан так:

Шаг этих вставок NOP соответствует - детекции пропуску инструкций. То есть, если бы ученые пытались взломать мой ПЛК, а я бы в настройках компилятора установил шаг 6(L)/2(N) - наша система бы зафиксировала пропуск 3 и больше инструкций.
В моем ПЛК в системе есть модуль канонизации инструкций (которая выбирает - что в 32 битной инструкции, какие биты отслеживаем в траектории программы). Этот модуль инструкции NOP просто игнорирует. NOP - инструкция ничего не делает, и их вставка не влияет на программу, но - раздвигает адреса. А теперь хитрость.
Хитрость в том что, если программа идет последовательно - все ядра покажут идентичный ход выполнения. Но , если было физическое воздействие, и счетчик перепрыгнул допустим на 3 три инструкции который вкладывается в формулу :
|∆P C| ≤ l/N
смотри рисунок, одно ядро окажется на инструкции iD а второе на инструкции iE . Пропуск будет детектирован и ошибка наблюдаема.
В моем методе есть недостатки, вставка NOP - увеличивает память, и в моем компиляторе есть возможность выбирать критические участки кода где это используется:
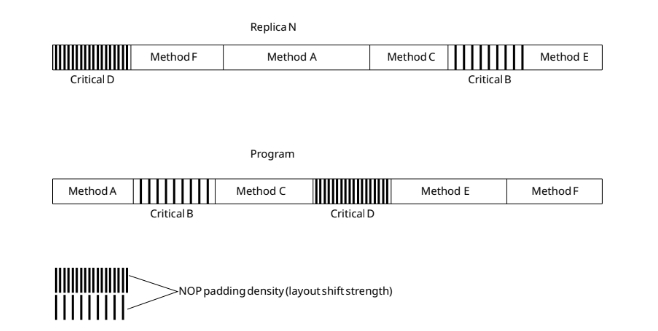
Разная плотность NOP - разная детекция пропуска иснтрукций.
То есть, мы можем перемешать адреса функций и блоков, и получить детекцию целого класса ошибок ( от бага компилятора, до кривой программы и и физических помех которые изменяют ход программы - при переходах между функциями и в стеках).
Но так же усиливаем бдительность в критических участках кода , переводя систему в безопасный режим, даже если будет пропущена 1 инструкция (ПИД регуляторы и другие какие то системы).
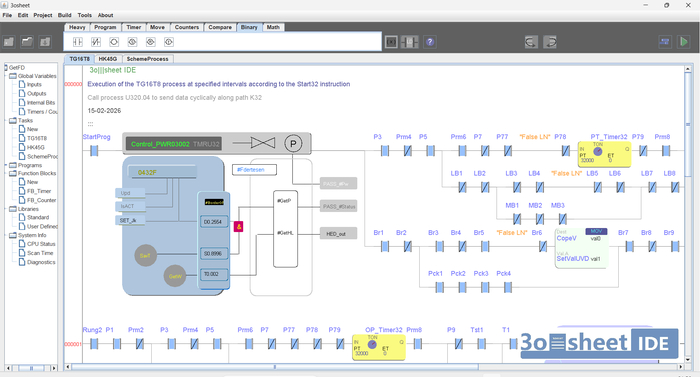
Наш интерфейс. Тяжелые функциональные блоки, в тестах мы выставляли режим Detection of Small-Magnitude Program Counter Faults.
И, что важно, никаких грубых методов типа WDT ( таймера) или выдернуть шнур питания на 10 секунд и перезагрузить. Решается вопрос сбоя программы тонко, а его детекция - быстро , в течении - наносекунд при первом же расхождении программной трассы.
В данный момент, я тестировал эти повреждения указателя программного счетчика - изменяя его программно. Система тестировалась на FPGA и исправно фиксировала каждый пропуск. На микроконтроллере это не имеет смысла так как программный счетчик - виртуальный, а этот метод может работать только в многоядерных системах или FPGA.

Тестируемые.
В следующий раз, когда вернусь к вопросу отказоустойчивости - проведем уже эксперимент с физическим воздействием.
Задавайте вопросы в комментариях и на почту zoshytlogic@gmail.com.
Не забывайте читать прошлые посты.
Часть 2 — LCD-дисплей, камера и первый взгляд робота на хозяина
В первой части я рассказал как решил собрать настольного робота после фильма «Финч» с Томом Хэнксом. Raspberry Pi, мозг на Claude, голос — всё это уже было. Но робот без лица — это сервер с колонкой. А мне нужен был именно робот.
Сегодня приехали запчасти. И Флаппи наконец-то получил глаза.
Что приехало
3,5-дюймовый LCD-дисплей. Втыкается прямо в GPIO Raspberry Pi — никаких HDMI-кабелей, никаких переходников. Маленький, но для мордашки робота — идеально.


В комплекте с монитором шел кулер, который питается от него же. Китайские братmя даже термопрокладки положили.
И камера. Обычная, на 5 мегапикселей. Ничего навороченного — но достаточно чтобы робот мог «видеть».

Подключение дисплея
С дисплеем оказалось просто. В комплекте шла инструкция на одну страницу:
git clone https://github.com/goodtft/LCD-show.git
cd LCD-show/
sudo ./LCD35-show
Три команды, перезагрузка — и на экране появился рабочий стол Raspberry Pi. Всё. Без танцев с бубном, без драйверов из непонятных источников. Приятно когда железо просто работает.
Рисуем лицо
Дисплей работает — но на нём рабочий стол Linux. А мне нужна мордашка.
У меня уже был написан рендерер лица на pygame — 7 эмоций, моргание, движение зрачков, дыхание. Но изначально он был под большой монитор (800×480). Пришлось адаптировать под маленький экран (480×320) и запустить в полноэкранном режиме чтобы убрать системную панель.
Первая версия лица выглядела... криповато.
Анимированные брови на маленьком экране — это не мило, это жутко. Перерисовал в робо-стиле: большие скруглённые глаза с голубым свечением, аниме-блики на зрачках, пульсирующая антенна сверху. Без бровей вообще — эмоции передаются через форму глаз.
Получилось 7 состояний:
• Sleeping — щёлочки вместо глаз, тёмный фон
• Listening — широко открытые глаза, «я весь внимание»
• Thinking — прищур, зрачки вверх
• Speaking — рот анимируется в такт речи
• Happy — глаза-дуги как в аниме, розовые щёчки
• Surprised — огромные глаза, маленькие зрачки
• Sad — опущенные глаза, рот дугой вниз
И они плавно переключаются между собой. Не просто «хоп — другая картинка», а smoothstep-интерполяция всех параметров. Глаза плавно сужаются, зрачки плавно перемещаются, фон плавно меняет цвет. Выглядит живо.
Камера — Флаппи учится видеть
Камера воткнулась шлейфом и сразу определилась. Никаких драйверов — Pi увидел OV5647 и готово.
Написал скрипт: камера делает фото → фото сохраняется на диск → Claude (который уже живёт на этом же Pi) получает команду «прочитай этот файл и расскажи что видишь».
Первый тест — направил камеру в упор на монитор. Claude ответил:
Перенаправил камеру на себя. Второй ответ:

Он меня узнал. Точнее — описал. И сделал это за 10 секунд.
Ну и конечно, как же не сфотографировать любовь всей жизни

Это не заранее записанные фразы. Не распознавание по шаблону. Claude реально смотрит на фотографию и описывает что видит. Своими словами, с юмором, по-русски.
Кнопка «Фото» в админке
У Флаппи есть веб-админка — панель управления где видно температуру процессора, загрузку памяти, статус сервисов. Я добавил туда кнопку «Фото».
Нажимаешь → камера снимает → Claude смотрит → ответ появляется прямо в браузере рядом с фотографией. 10-15 секунд от нажатия до ответа.
Теперь можно сидеть на диване с телефоном, нажимать кнопку и смотреть как робот описывает что происходит в комнате. Это странно увлекательно.
Что дальше
Сейчас камера — это «сделай фото по запросу». Но хочется чтобы Флаппи реагировал сам. Увидел человека — поменял эмоцию на happy. Никого нет — заснул. Увидел что-то необычное — удивился.
Ещё хочу подключить TTS чтобы он не просто писал текст а озвучивал. Фото → Claude → голос из колонки. Полный цикл.
И да — 2 гигабайта оперативки на Pi 4 это боль. Faster-whisper (локальное распознавание речи) + pygame + камера — всё еле помещается. Но пока живём.
Жду до конца недели приход камеры и микрофона, чтобы дать голос Флаппи и начать делать с ним первые проекты.
Как вам идея с камерой? Что бы вы заставили робота делать — охранять квартиру, комментировать что происходит, или может узнавать гостей?

Придумываем, рисуем и запускаем в моей SCADA Gatherlog - какой то тестовый сценарий.
Прошло три месяца с последних постов о ходе разработки, с того времени все кардинально изменилось в плане архитектуры. Это время я занимался - наукой, и определил направление работы дальше.
Сейчас перешел к общению с исследователями и научными руководителями. Пишу собственную научную работу по отказоустойчивым системам, но сам я - независимый исследователь, так как не работаю за счет фондов, институтов или организаций.
Кто читает впервые:
Я, автор , независимый исследователь, разработчик SCADA системы Gatherlog
А так же автор комплекса по разработке Промышленных Контроллеров под названием 3o|||sheet. Среда, IDE читается как Зошыт - тетрадь, но так как для компилятора и среды выполнения названия не придумал, пока все называю 3o|||sheet.
Ни SCADA ни Комплекс ПЛК - для коммерческого применения не готовы, хотя и рабочие как прототип. Остается много мелкой - рутины: кнопка туда - кнопка сюда, текстовые сообщения-предупреждения или ошибках...энтузиазма этим заниматься нет вообще.
3o|||sheet теперь использую для научного звания, по теме нового метода - отказоустойчивых систем. Собственный компилятор предоставляет широкое поле для экспериментов, а среда разработки с графической системой - делает демонстрации по всяким институтам - интереснее. В прошлых постах - есть все (описание компиляторов, и сред, концепций и прочее).
В этом посте расскажу как из простого микроконтроллера типа STM32G030 создать отказоустойчивую исполнительную систему внутри Промышленного Контроллера.
В прошлом посте частично коснулся разработанного мной метода отказоустойчивости -
Дивергентного Многоверсионного Выполнения Программ (DME). Суть ее в множественной N компиляции одной программы. Так называемая - программная (а если это на FPGA или многоядерных CPU) аппаратная избыточность типа Lockstep / TMR.
Чтоб сделать ПЛК который поддерживает много языков и функций (например - замена участков кода на лету и прочее) нужен собственный рантайм и компилятор который будет переводить любые языки ( LD FBD ST) в собственные инструкции. Первая версия моего компилятора давала сбой - то одно не верно посчитает, то другое. Я столкнулся "паразитными" смещениями по адресам, а точнее - в сложных местах программа могла не туда перейти, не то прочитать или не туда записать. Программа слетала, и не понятно в каком месте была ошибка - так как при тихом повреждении данных (silent corruption), и физическим вылетом могло пройти много времени, - замучаешься пошагово следить в отладке.
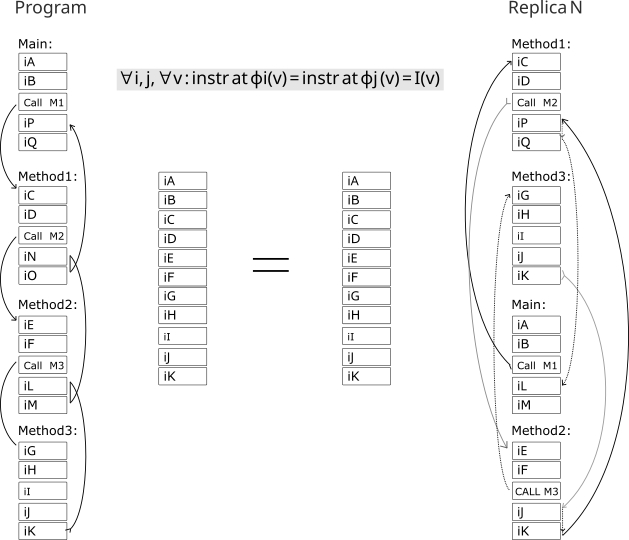
Структурная декорреляция адресного пространства копий одной программы.
Тут я подумал, а что если компилировать одну и ту же программу - два раза? Но вторую копию - перемешивать адреса функциям, блокам, переменным чтоб аналогичные по названиям переменные и функции второго экземпляра были не на том месте как в первой компиляции. Если компилятор все верно считает, нет никаких паразитных смещений, то каждая инструкция будет совпадать во всех копиях. Адреса у них хоть будут разные, но ход программы будет логически идентичен (смотри рисунок выше). А если адрес не верно просчитан - то в каждой копии программа запишет/прочитает или перейдет в логически разные - места. Тем самым детекция ошибки произойдет сразу.
Так и было, - две компиляции но разные структурно в памяти - все паразитные смещения из за бага компилятора - всплывали сразу. Так называемые silent corruption (скрытые ошибки) - стали наблюдаемы. Это позволило точно отточить алгоритмы просчета адресов, и больше компилятор не ошибался. Ну а дальше вы знаете: писал посты, тестировал разные микроконтроллеры как ПЛК.
Тогда я даже сам не понял что я придумал, и широкие возможности применения своего метода DME.
Сделал свой комплекс разработки ПЛК : среда разработки, компилятор, и среда выполнения на железе. Задумался об отказоустойчивости, и познакомился с существующими подходами:
Lockstep - две копии (одинаковые бинарники) программы на двух процессорах работают и сверяют друг друга на каждом шаге.
TMR - три копии (одинаковые бинарники) программы на трех процессорах. Если одна отличается, происходит голосование , кто не прав и работа выполняется дальше.
Оба метода применяются в авиации, атомной энергетике и прочее. Стандарт.
Все хорошо, да только вот Lockstep и TMR - уязвимы к коррелированным сбоям. Методы эффективны только если система замечает разницу между копиями программы, сигналит об этом. Но если оба ядра ошибаются - система не заметит ошибки, и продолжит выполнять ошибочную программу.
И тут я заметил, мой метод с деккореляцией адресного пространства который я применял в отлаживании компилятора - решает эту задачу!
Если система Lockstep и TMR "одинаковость" воспринимают как ОК, мой метод наоборот - одинаковость воспринимает как как - осторожность. А разность - как нормальную работу. Но у моего метода есть два типа разности:
Допустимая разность - это адреса (адреса функций, счетчика команд, переменных и т.д).
Не допустимая разность - в последовательности инструкций ( семантика ).
То есть, в системах Lockstep и TMR сводится к 1/2 :
Либо одна из копий программы ведет себя по другому - это ошибка.
Либо ведут себя одинаково - значит все хорошо. Но тут и проблема одинаковых бинарников, если все копии выполняются одинаково не верно, система будет думать что все хорошо.
В моем методе DME, соотношение 1/3 . Где:
одинаковая логика/инструкции - это Хорошо.
одинаковость адресов -Плохо.
разная логика/инструкции - Плохо.
Я сделал более узким коридор для корректности , и расширил коридор для прохождения ошибок (усилил ошибку).
Lockstep и TMR - совсем не ловят программные ошибки. Если в компиляторе есть специфический баг из за оптимизации или просто программа так написана - это не покрывается. Копии идентичны и поведут себя одинаково , а значит система не заметит. Проблему решают N-Version Programming - когда нанимают две группы программистов, и они пишут программу по разным вариантам (Airbus/Boeing). Очень дорогое, и медленное удовольствие. В общем не для ПЛК за 30$.
В нашем методе DME , при двойной компиляции и перемешиванием адресов, одинаковый баг программы, компилятора, или ошибки из за физики - обязательно приведет к расхождению (Дивергенции).
Создаем - тестовый проект в языке LD. Моя среда поддерживает FBD но так же пока только внутри LD. ST язык я не реализовал в полной мере, но на каком бы языке программа ни была, она переводится в единый виртуальный ассемблер (собственный синтаксис и инструкции, см. прошлые посты) который выполняется внутри на голом железе Микроконтроллера, FPGA или любого CPU.
Интерфейс. Тяжелые функциональные блоки внутри LD прекрасно подходят под тесты отказоустойчивости
Несколько выполняющихся копий, на одном дешевом микроконтроллере, от чего может защитить? Против тяжелого поражения питания, это - не защитит(вопрос к аппаратной части), но стать устойчивее к программным ошибкам, радиации или умеренным временным электромагнитным помехам, сильно компенсируя аппаратную часть - получится.
Настройка компиляции в 3o|||sheet:
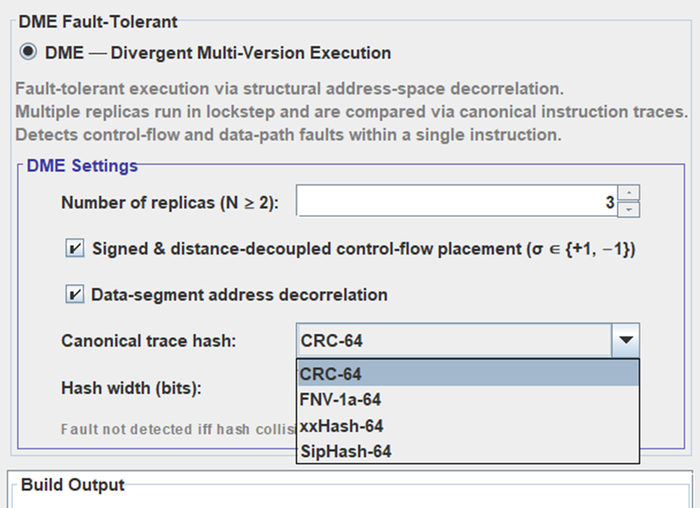
Интерфейс с настройками - компилятору.
N - количество копий программы и количество соответственно компиляций. N Должно соответствовать количеству ядер, или ПЛК если они работают в режиме похожему на Lockstep\TMR. На STM32G030 эти ядра эмулируются, в чем смысл - дальше.
+1 -1 это команда разнесения адресов в разные по знаку стороны. Если в одной копии переход из функции А к функции Б изменяет программный счетчик например PC+=94, то в второй копии компилятор организует этот переход PC-=64. Усиливает декорреляцию адресного пространства, соответственно увеличивает область детектируемых программных багов и программных ошибок из-за физического влияния среды.
Canonical trace hash: Инкрементальный хеш выполнения программы (если есть аппаратный хеш как у Cortex M4) , но на слабом железе вместо хеша может подойти обычное сравнение каждой инструкции (опкода или результата) каждой копии программы простым "=", или хеш может быть банальным XOR с степенью ( за 2 такта, это + 10..20 наносекунд к выполнению инструкции, дешево ).
Тут принцип тот же что и Lockstep\TMR - N копий программы на ядрах, только в Lockstep\TMR сравниваются идентичные бинарники и состояние на каждом такте, у меня только логическая траектория, потому что адреса переменных и инструкций в копиях разные - они (адреса) исключаются из уравнений.
Любая программа, LD ST C++ не важно, состоит из блоков кода и функций. Мой компилятор их и перемешивает по разным адресам и разным знакам (+-) направлениям перехода. Если мы скомпилируем программу, то получим пространственные -разные версии одной программы:
N компиляций, и расположение программы в памяти. Один и тот же блок или функция - по разным адресам.
Если мы присмотримся к адресам функций на скрине, то увидим в одной копии например Main будет по адресу - 0 (ноль) в другой копии она же будет по адресу - 144. Так и со всеми остальными. Выполняется главный принцип DME - усиление ошибки программы через структурную декорреляцию адресного пространства.
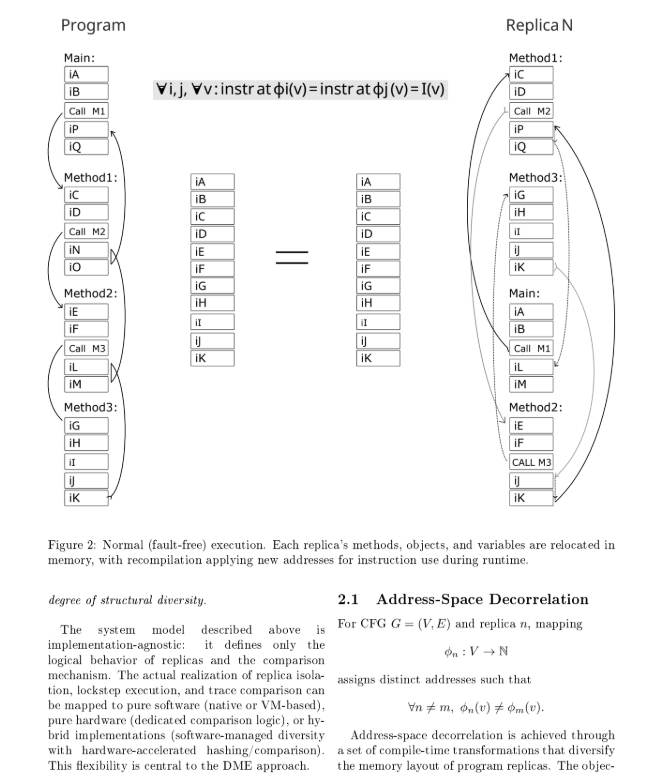
На рисунке видно, несмотря на то что участки кода перемешаны (перемешаны на уровне функций и блоков кода имеется ввиду), и соответственно скомпилированы - траектория программы, логика будет идентичная (в штатном режиме работы).
Теперь, предположим в системе произошел коррелированый сбой, то есть такой который задевает все ядра или все копии программы. Чаще это возможно когда программа криво написана, затерла адрес возврата, или другого участка программы. Проблемы с питанием - тоже может повредить все ядра одинаково. Радиация, или помехи - риск минимален в атмосфере на Земле. В самолете на высоте 10 000м вероятность сильно возрастает, а в космических аппаратах бомбардировка процессоров частицами которые вызывают сбои происходит несколько десятков раз в сутки.
Давайте предположим, что сбой произошел (неважно по какой причине) , адрес возврата или какого либо перехода ветки , установлен в случайное значение 148:
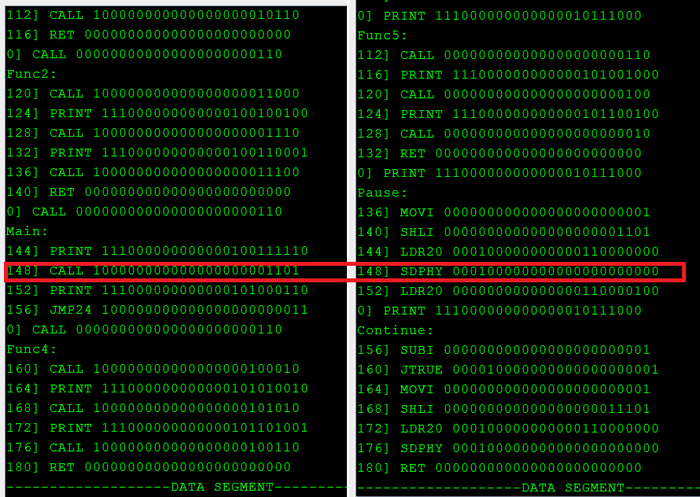
Просмотр результата компиляции в 3o|||sheet. Одна программа - разные адреса ее компонентов.
Был бы это обычный отказоустойчивый ПЛК типа Lockset или TMR за 5000$ , они бы не заметили фатальной ошибки, так как бинарники одинаковы. Система бы увидела у всех копиях одинаковое значение и подумала что все хорошо.
Но наша система декоррелирована по адресам , это вызовет - Дивергенцию. Система фиксирует - две разные инструкции одновременно: CALL и SDPHY. Несовпадение. Компаратор вызовет программу X (типа обработчик ошибки) или осуществит переход в безопасное состояние.
Детекция - сразу, что очень важно, так как обычный ПЛК - слетит с концами и не успеет передать на каком месте авария. Либо вообще может слететь через какое то время долго притворяясь что все хорошо.
Ошибка может быть более сложной, например радиация или электромагнитная помеха может не изменить весь адрес полностью, а только один бит (так называемый bit flip), тем самым добавив к адресу одинаковое - число. То есть, адреса продолжат быть разные, но смещенные на константу. Для этого мой компилятор и делает переходы с разными знаками между функциями и некоторые другие приемы для локальной асимметрии адресов..
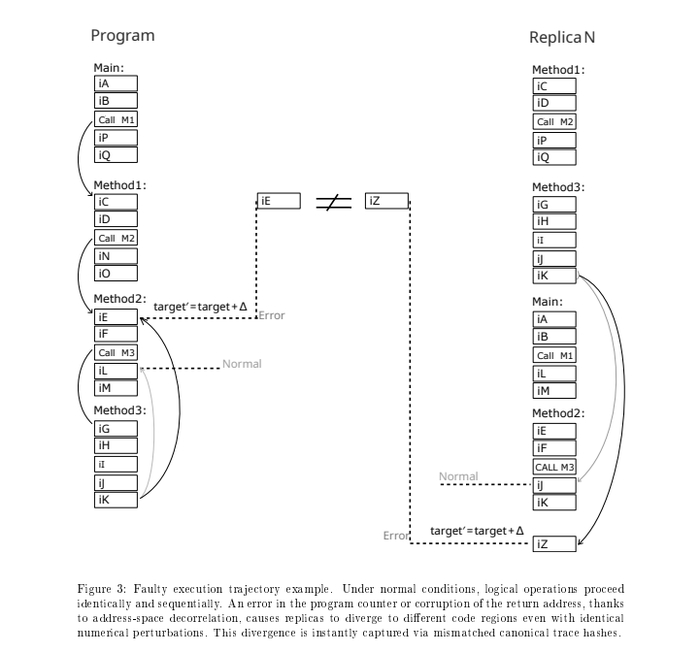
Ошибка из за физических процессов: bit flip может привести к тому что в копиях, адрес изменится на константу. В методе DME это приведет к разным участкам кода, и ошибка будет детектированна.
Codesys, Siemens не имеют компиляторов с декорреляцией адресного пространства, их детекция ошибок сработает только если один ПЛК или ядро и отличаться от другого. А когда оба ошибаются - программа благополучно упадет и до этого может наделать много лишнего.
Одноядерный микроконтроллер выглядит полностью беспомощным, но интерпретация байткода в двух копиях сильно улучшает положение.
В моем методе DME, в одноядерной системе инструкции N копий выполняются по очереди псевдо-параллельно, а следовательно, каждая инструкция выполняется N раз и получается с задержкой по времени.
Есть такой метод отказоустойчивости Time redundancy - выполнения идентичных инструкций с задержкой по времени. Вот как это описывается:
Обнаружение ошибок: Программа или расчет выполняется дважды. Если результаты не совпадают, система фиксирует наличие ошибки.
Тип ошибок: Этот метод наиболее эффективен против кратковременных (перемежающихся) сбоев, вызванных внешними помехами (космические лучи, электромагнитные шумы).
EDDI и SWIFT - известные методы дублирования . Все эти Time redundancy, EDDI/SWIFT являются у нас побочным эффектом из псевдопарралельности нашего ПЛК в одноядерной системе. Наш ПЛК с DME перестаёт быть “чисто структурной” DME защитой с перемешанной памятью, а превращается в гибрид:
time redundancy + DME + семантический анализ и контроль данных
Таким образом, DME защищает программу от программных и коррелированных багов, которые не детектируются вообще Codesys, Siemens, а вторичный эффект Time redundancy, EDDI/SWIFT которые вытекают из псевдо-параллельности дает устойчивость к физическим влияниям на систему. И делает наш ПЛК устойчивым к:
Transient faults (SEU, EMI, glitches) одиночный бит-флип в регистре, кратковременный сбой ALU, помеха на шине. Сработает эффект DME , Time redundancy, EDDI/SWIFT.
Control-flow faults (PC corruption, jump errors) повреждение PC, бит-флип в адресе возврата , неправильная ветка. Сработает DME защита.
Memory corruption (stack/heap, out-of-bounds) переполнение буфера, повреждение указателя , повреждение данных в RAM. Сработает DME защита.
Повреждения данных\ переменных (для дешевых микроконтроллеров у которых нет ECC это критично).
Исследователи указывают что метод SWIFT имеет "чрезвычайный широкий охват детектируемых ошибок" , но SWIFT требует наличие в памяти коррекции ошибок ECC, которого нет в простых микроконтроллерах. Да и ECC поможет только если фзика изменила только один бит, если изменены несколько бит, ECC (а значит и SWIFT ) бессилен, потому что не восстановит данные. А еще, SWIFT в отличии от моего метода DME - не видит ложные переходы программы.
Понятно что никто не вставит дешевый микроконтроллер в управление атомной станцией. Но в космический аппарат, или в другую агрессивную среду - слабые но энергоэффективные микроконтроллеры - подходящее место. Уверен много кому пригодится ПЛК с повышенной отказоустойчивостью за дешево.
У моего метода DME конечно есть недостатки (если он работает на одном ядре) . Дублирование программы на N реплик соответственно замедляет ПЛК в N раз.
Как то видел в домашних производителей ПЛК, STM32G030 использовался просто как микроконтроллер для модулей расширения вводов\выводов . А ведь этот Микроконтроллер производительнее ПК на i486 1992-1994 годов, и гораздо производительнее наверное чем вся электроника корабля летавшего на Луну.

Altera Cyclone |V EP4CE6E22C8, STM32F722, STM32G030C8
Скорость выполнения базовых логических операций в микросекундах:
Mitsubishi (китайский клон) STM32F103------------------------------------2.7---------------математика int 8.6
Allen Bradley Micro 810 -----------------------------------------------------------------2.5---------------математика int 8.5
Siemens LOGO!------------------------------------------------------------------------------ 5.0
Schneider Electric Zelio Logic --------------------------------------------------------10.
====================================3o|||sheet==================================
3o|||sheet STM32G030 (N=2) отказоустойчивый режим---------- 4.5 --------математика int 13.5
3o|||sheet STM32F407(N=2) отказоустойчивый режим------------ 2.1 --математика int/float5.2
3o|||sheet STM32F722(N=2) отказоустойчивый режим-------------0.9 --математика int/float2.3
3o|||sheet Cyclone |V 50 MHz (N=2) отказоустойчивый режим-- 0.1 ---------математика int 0.1
Наш ПЛК, название не придумал , пишу с названия среды моей разработки 3o|||sheet.
В режиме отказоустойчивости, с циклом 10 миллисекунд, наш ПЛК 3o|||sheet STM32G030 отработает примерно 1100 операций: 550 - логические (контакты катушки) + 550 математические. Если брать ST, то математика и булевые операции так и остаются, а каждое условие типа if(a== > < ! b) займет в памяти и по времени выполнения - максимум как две логические операции (в зависимости от "регистрового давления", насколько далеко a, b в программе использовались до этого).
Я бы не сказал что это мало от микроконтроллера который другие компании ставят просто в качестве расширяющего вводы выводы. В этом отказоустойчивом режиме он производительнее обычных программируемых реле Siemens и Schneider .
Какие MCU в реле Siemens и Schneider неизвестно, может и 16 МГц ( в нашем STM32G030 64 MHz) , я только констатирую факт.
3o|||sheet STM32F722х - вытянет в быстрых (по меркам промышленности) ПИД регуляторах в режиме отказоустойчивости.
Altera Cyclone |V EP4CE6E22C8 даже на 50 МНz , в отказоустойчивом режиме, показывает впечатляющий результат, в цикле 1 миллисекунды отработает 8000 логических или математических (целочисленных) операций. .
Часто пишут что - главное не скорость, а надежность. Но чем быстрее выполнение инструкций, тем меньше можно сделать цикл, или тем сложнее программу можно втиснуть в один цикл.
Вернемся к отказоустойчивости. Интерпретируемость байткода дает серьезный отказоустойчивый эффект:
..........................<----- 15 Нативных инструкций ----->
15 тактов : П_П_П_П_П_П__X___П_П_П_П_П_П_П_П
...................<-------1 виртуальная инструкция------->
15 тактов: П_П_П_П_П_П_П_П_П_П__X__П_П_П_П_
Если из за физического воздействия в месте X Нативных инструкций что то произошло в потоке программы, в нативном уровне где каждый такт это аппаратная инструкция - сразу может привести к вылету системы или серьезным последствиям.
В то время, 1 виртуальная инструкция "размазана" по нескольким десяткам или сотням тактов, и состоит соответственно из десятков нативных инструкций. Есть проигрыш в скорости, но воздействие в месте X изменит только логику самой инструкции (например 2+2 станет = 5, и переход на ветку В вместо А) но не повредит программу в целом. А так как у нас еще работает вторая копия программы , наш метод DME - зафиксирует и проконтролирует ошибку.
Из за дополнительного рантайма (например моего 3o|||sheet) память программ увеличивается на 45-50 килобайт, в отличии от программы которая допустим написана на СИ, и с точки зрения вероятности - возрастает событие из за помех которое что то подпортит внутри процессора.
Но, если и подпортит, то последствия не такие катастрофичные как если физика подпортит - нативный код, без контекста рантайма. Потому что "логическая плотность" нативного кода сильно ужата. Как петарда которая при взрыве разбросает плотно стоящие спичечные коробки (логику) возле эпицентра, но имеет меньше влияния если эти коробки далеко друг от друга и по площади дальше от эпицентра. Что то зацепит и упадет, но разрушимость логики не та, потому что 1 виртуальная инструкция, ее логика состоит из десятков нативных инструкций, а результат ее - всего лишь - одно число в конце, и его ошибочность будет замечено дальше.
Это частый вопрос гастролирующего читателя. Вот в каждом комментарии есть такое.
Во первых, китайцев существующие немецкие велосипеды Codesys, Siemens не останавливали, китайцы начали делать свои ПЛК (наверно разработчикам в Китае трудно было всем отвечать, зачем делать ПЛК создавая велосипеды, если уже были готовые где то в Германии).
Что касается домашних существующих конкурентов - то в плане отказоустойчивости я вообще не вижу ни в одной компании ничего особого - обычные ставки на резервирование со всеми вытекающими. В самолет я б лучше сел в котором установлен - мой ПЛК, чем чей то.
Извиняюсь за нескромность, но я не вижу себе конкурентов по инновациям в этом направлении, в первую очередь среди местных производителей. Я видел их сертификаты SIL3 SIL4 , но вряд ли там что то новое чем Lockstep/ TMR.
У меня проработан, конкретный , особенный, нигде ранее не встречающийся метод DME.
Во вторых - в Beremiz , китайских клонах Mitsubishi, и прочих дешевых ПЛК до 100$ ( а может и до 500$) близко нет никакой отказоустойчивости.
Устойчивость к коррелированным сбоям - вообще ни один ПЛК ни одного мирового бренда не имеет , в мире этот вопрос решается - дорогими специальными CPU - разнесением ядер на кристалле максимально удаленно друг от друга. Или N Variant Programming с разными группами программистов. Мой метод первый решает эту задачу структурно/программно (то есть - дешево).
В следующий раз расскажу часть моего метода DME "Periodic Layout Diversity" , который призван бороться с малыми глюками потока программ, тот самый Periodic Layout Diversity , когда из за внешнего воздействия может быть пропуск инструкции или несколько инструкций. Ни одна система в мире такое не детектирует, а это критично если в ПИД регуляторе или каком то автомате будет пропуск команды.
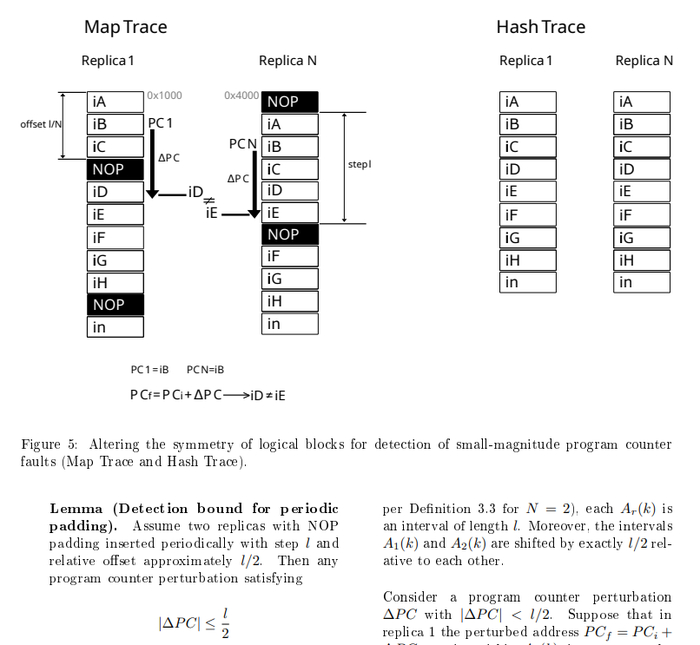
Внесение малой асимметрии адресов в критические участки кода, для гарантированной наблюдаемости ошибки в случае возникновения
В ней четко прописана математика. Больше всего у меня претензии к мировым и домашним брендам, по - доказательствам надежности. У них это - тесты в лабораториях, которые не факт что будут соответствовать на 100% рабочей обстановке. Я подошел к вопросу - математически, что кстати дешевле и легче для сертификации так как легче доказать надежность.
Мой метод DME , гарантирует математически - либо код отработает корректно, либо сразу остановится и контролировано перейдет в безопасное состояние. Но никакого неопределенного поведения.
Еще вопросы можно задавать в комментариях и на почту zoshytlogic@gmail.com
Предыстория, или как Том Хэнкс виноват в том, что я теперь не сплю

Посмотрел на днях фильм «Финч» (2021) — тот, где Том Хэнкс в постапокалипсисе собирает робота, чтобы тот позаботился о его собаке. Робот там учится ходить, водить машину, понимать мир. Снято невероятно душевно и при этом грустно до комка в горле.
Проснулся на следующий день и понял: хочу такого же. Ну, не в смысле постапокалипсис — а именно робота-компаньона, который рядом, который учится, с которым можно разговаривать.
Понятное дело, ходить мой робот не будет — это совсем другой уровень сложности и бюджета. Но вот сделать настольного помощника, с которым можно общаться голосом, который видит меня через камеру и реально помогает в работе — это мне вполне по силам.
Кто я такой и почему думаю, что потяну
Я работаю сисадмином и разработчиком. Разворачиваю сервера, пишу обработки, делаю телеграм-ботов, собираю сайты. У меня дома свой сервер (даже несколько), и целый зоопарк из виртуальных машин и контейнеров. Так что с железом и софтом я на «ты».
Знакомьтесь — Flappy

Пока выглядит не очень, но через 2 недели приедет корпус и монитор.
Назвал его Flappy — от английского «flappy», болтливый. Потому что главное, что он будет делать — это разговаривать со мной и помогать голосом.
Что он из себя представляет на сегодня — это коробочка на базе Raspberry Pi, которая будет стоять у меня на рабочем столе. Вот что я для него заказал:

Список компонентов не окончательный
Всё уже заказано на Алиэкспрессе, ждём.
Что он будет уметь
Вот тут самое интересное. Я хочу, чтобы Flappy был не просто говорящей колонкой, а реальным помощником.
Голосовое общение. Микрофон + динамик — чтобы я мог просто сказать: «Flappy, поставь задачу на завтра: в 9 утра сформировать ОПД и отправить клиенту» — и он поставит. У меня уже есть свой телеграм-бот, куда я наговариваю задачи — осталось прикрутить это к Flappy.
Управление серверами. Мечта — сказать: «Flappy, подключись к Proxmox, создай виртуальную машину, разверни там SSH и пришли мне доступы». Креды у него будут в памяти, API у Proxmox есть — технически это реально.
Камера и узнавание. Хочу, чтобы когда я захожу в комнату, он видел меня и говорил что-нибудь вроде: «Привет, Иван, давно не виделись!» Или мог распознать, что я ему показываю.
Экранчик с эмоциями. На 3,5-дюймовом дисплее будут отображаться эмоции, статусы, может быть какие-то подсказки. Чтобы он был не просто коробкой, а чем-то живым.
Что дальше
Пока жду посылки с Али. Когда всё приедет — начну собирать и буду выкладывать процесс. Если тема зайдёт, сделаю серию постов: от сборки железа до первого «Привет, Иван».
Как вам идея? Стоит делать серию постов, или я один тут сумасшедший, который вдохновился фильмом и решил собрать себе робота-помощника на малинке?
Давно не писал о ходе работы своего комплекса для ПЛК (Промышленных контроллеров).
Несмотря на то что все основные вопросы я решил (графический движок, компилятор, виртуальная машина), но для коммерческого использования тут еще много работы: компилятор не выводит предупреждения или ошибки, среда тоже, и еще куча рутинных вопросов, которые я один в ближайший год не решу, особенно с учетом того что работаю по выходным.
Кто читает впервые:
Я, автор , независимый исследователь, разработчик SCADA системы Gatherlog
А так же автор комплекса по разработке Промышленных Контроллеров под названием 3o|||sheet. Среда, IDE читается как Зошыт - тетрадь, но так как для компилятора и среды выполнения названия не придумал, пока все называю 3o|||sheet.
Что касается среды разработки IDE , последнее что я добавил в нее это небольшую CAD. Я подумал, если инженер может рисовать функциональные блоки и описываеть их поведение на языках, почему бы не добавить в проект возможность сохранять графические схемы? Вся эта математика пригодится и для всяких HMI на маломощных микроконтроллерах:
Неформальная история хода разработки в прошлых постах Моими разработками, соревнуюсь с Брендами в АСУ ТП
Я решил больше не форсировать этот “долгострой” , а заняться научной деятельностью, то что под силу одному человеку - научной работой по теме - разработка нового типа отказоустойчивых систем. В чем суть , упомяну в конце. Для предпринимательства нужны деньги и люди, но для научной работы (докторские и прочее) сделанной работы - с головой хватает, так как это является реальным работающим прототипом, а не теорией.
В прошлых постах (особенно - первых) я тестировал свой ПЛК на микроконтроллере STM32G030, где он с треском проигрывал по производительности аналогам с рынка и даже китайским клонам (в 4 раза! В прошлых постах можно ознакомиться). Но время шло, происходила оптимизация, и сейчас мой ПЛК обгоняет китайцев и базовые ПЛК Allen Bradley.
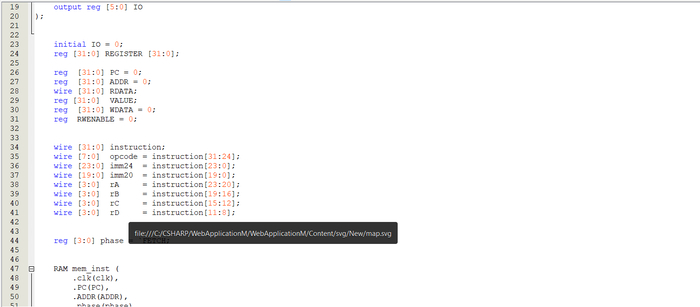
Чтоб не быть голословным, я просто покажу участок кода отвечающий за выборку и выполнение инструкций так как это самое узкое место:
uint8_t memory[SIZE_MEMORY]; // Виртуальная ОЗУ
void (* volatile instruction[255])(void); // Массив указателей на инструкции
Главный цикл:
dec.ui = __builtin_bswap32(*(uint32_t*)&cpu.memory[PC]); // достаем из memory инструкцию
((void (*)(void)) cpu.instruction[dec.b[3]])(); //передаем опкод и вызываем обработку
// Выполняем инструкцию, например ANDM - типичная в LD цепях (контакты катушки)
void ANDM (void)
{
cpu.R[OP_A].ui &= cpu.memory[MASK20]; // Достаем переменную из памяти по адресу
}
MASK20 - immediate значение, адрес переменной или инструкции, прямо в 32 битной инструкции
Конечно, есть много чего другого еще (флаги состояний, и прочее) но это - главное.
Запомните этот код, потому что когда я буду писать что мой ПЛК STM32G030 производительнее Allen Bradley Micro810 и китайских клонов Mitsubishi FX3 на STM32F103 , чтоб каждый мог взять код и протестировать на своих микроконтроллерах если надо для замера. Важно заметить, виртуальная машина все еще написана на СИ без низкоуровневых оптимизаций, так что в коммерческом продукте если до этого дойдет, есть еще запас увеличения производительности на 10-15% от производительности которая будет показана дальше . Я держу проект на СИ для быстрого перехода на разные микроконтроллеры и CPU.
Конкуренты, все-ровно не сделают из этого кода - ПЛК , потому что главное тут - компилятор, его в двух словах не опишешь.
Это должно было случится. Виртуальную машину я реализовал на FPGA, и теперь моя виртуальная машина больше не виртуальная, а так называемый Soft Processor. 3o|||sheet Soft Processor будет работать на такой скорости, как будто бы я его вылил - в кремние на какой нибудь фабрике чипов. По сути - создал свой процессор, с своей архитектурой и набором команд.
Тестовый стенд. 3o|||sheet система выполнения на FPGA Altera EP4CE6E22С8 и микроконтроллере STM32G030.
Замерялась скорость выполнения базовых логических операций LD а так же функциональных блоков с математическими операциями. Важно отметить, что под математическими операциями пока тестировалась - целочисленная арифметика типа сложение вычитание. Деление например не так просто реализовать на FPGA , это не микроконтроллер, тут самому надо описывать сигналы, и пока не тестировал, но потенциал - виден.
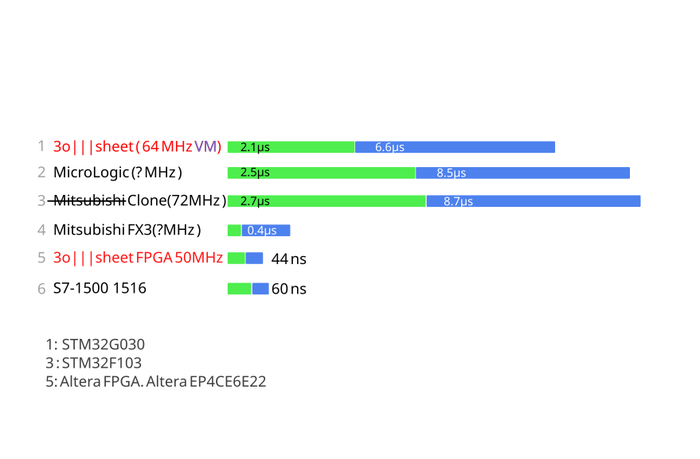
Выполнение базовых логических операций (с загрузкой переменных из памяти) в микросекундах.
Моя система указана красным, 3o|||sheet, данные по результатам замера. Остальные ПЛК , данные взяты из документации. Как видим, моя виртуальная машина на FPGA Altera EP4CE6E22С8 50MHz в десятки раз быстрее чем на микроконтроллере и мой ПЛК находится на уровне Siemens S7 1500. Добиться такой производительности на обычном процессоре пришлось бы использовать CPU в 800 Мгц.
То же самое и с ПЛК Mitsubishi , как видно разница с китайским клоном, несмотря на одну и ту же среду и компилятор - десятки раз.
Что касается Mitsubishi (оригинала) то такие показатели можно достичь и оптимизацией на низкоуровневом программировании, но так как китайцы которые делают клоны (при реверсе) жалуются что им не понятна почему Mitsubishi так неудобно расположила битовые поля в инструкциях, что замедляет их клоны, смею предположить (и это подтверждается в некоторых моделях) что оригинальные Mitsubishi используют собственные процессоры. Например выливают ARM или RISC V на фабриках, но с дополнительными собственными блоками для декодирования инструкций, а может и собственными инструкциями. Но не исключено что они используют и FPGA ( у Allen Bradley были замечены FPGA как сказал мне один электронщик). Если кто то ремонтировал оригиналы ПЛК Mitsubishi , можете поделиться в комментариях, что у них там за CPU.
Секрет FPGA в - параллельности выполнения. Если моя виртуальная машина но микроконтроллере разбирает инструкцию по очереди, тратя на это сотни тактов, то FPGA - все выполняется одновременно за один такт. Это мои первые опыты с FPGA , я не делал никаких конвейеров как в настоящих CPU, и на инструкцию у меня уходит 5 тактов. Но за счет параллельности FPGA в десятки раз быстрее делает большие операции. Можно сравнить с дуршлагом который окунули в воду - вода/логика/ сигналы мгновенно, одновременно пролезает через все дыры и тут же выполняется.
описание логики моей системы выполнения на FPGA.
Но в FPGA я пришел не за скоростью, как упоминал, я являюсь автором научной работы отказоустойчивых систем под названием Дивергентное Многоверсионное выполнение программ. Усиление ошибки, через структурную декорреляцию адресного пространства.
В свой компилятор я внедрил разработано мной систему DME. Суть в том чтоб по особому алгоритму (не случайному) - перемешать функции и блоки в памяти (смотри рисунок вверху), и соответственно выбросить адреса из уравнения, как шум. Отслеживать только семантику.
Компилятор собирает несколько копий одной программы но с разной адресной структурой которые выполняются параллельно (если это многоядерная система, или FPGA) или псевдопараллельно если это микроконтроллер.
Что это дает? а это дает устойчивость к коррелированным ошибкам, ошибки которые бьют сразу по всем копиям программы - одинаково. Первоначально систему разработал для отслеживания багов - собственного компилятора , идея была така - если мой компилятор верно просчитывает адреса, то даже если функции и блоки кода по разным адресам, счетчик инструкций будет сказать по одинаковым командам и переменным, но если компилятор не верно просчитывает и компилирует - то трасса выполнения разойдется сразу (а не через неделю).
Но только через какое то время я понял революционность метода, и его возможное обширное применение: тестирование компиляторов, детектирование ошибок не только компилятора но и программы которая криво написана, детектирование ошибок из за радиации и электрических помех.
Да, все эти системы которые на рынке за десятки тысяч долларов , так называемые TMR (тройное резервирование с голосованием) - не ловят коррелированные ошибки. Если например в стеке произойдет переполнение буфера, и адрес возврата затрется и программа прыгнет не в ту дверь, - хоть 50 ПЛК будет, они все начнут выполнять одинаково неверную программу и не заметят ошибки, система слетит сразу или через - неделю. Потому что существующие методы ловят ошибки на - разности, если вторая копия показывает не то что первая. А если обе ошибаются - то ошибка будет не замечена.
Привет, человеку который (мне писал) что дежурил не производстве , потому что их ПЛК слетал с катушек, и никто не мог понять причину и в каком месте ошибка.
В моей системе это невозможно - ошибка будет выявлена - сразу , а не завтра или через неделю. В классических системах, "одинаковость" результата адресов копий в ядрах или ПЛК - это признак корректности, но если все ПЛК сбиты одинаково - система не заметит ошибки, это легко может произойти при переполнении массива или повреждения адресов в стеках. В моем методе наоборот - одинаковость адресов - воспринимается как ошибка, и если баг в программе приведет все копии одной программы к одинаковому адресу \ месту программы - ошибка будет мгновенно детектирована. Мой метод ловит те ошибки которые ловят обычные ПЛК, но + и те которые не ловятся современными существующими ранее методами. Это не значит что деструктивную разность моя система не заметит, система сравнивает инструкции (опкоды, значения переменных) только не адреса, а саму логику - семантическую траекторию.
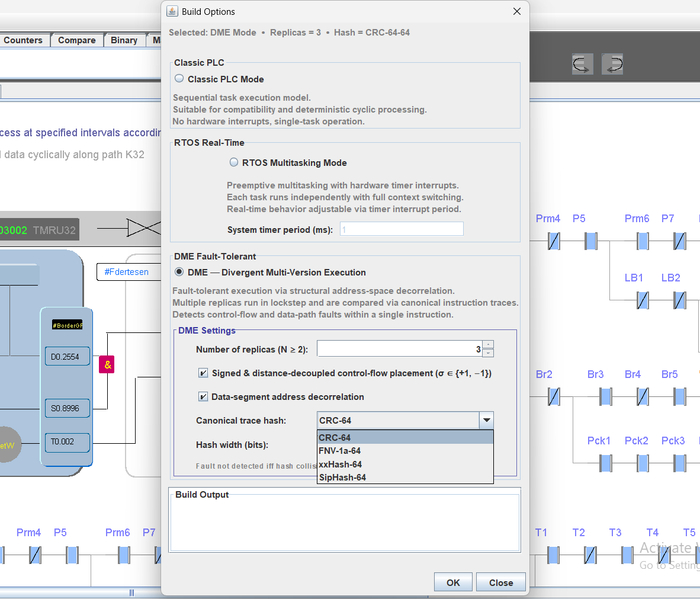
Внедрил в свой компилятор свою отказоустойчивую систему DME
Я начал разработку на FPGA чтоб запустить два ядра работающих в режиме Дивергентного Многоверсионного Режима Выполнения. Так как до этого тестировал только на микроконтроллере. Моя система - прекрасно масштабируется можно запускать N копий программы в режиме DME хоть на микроконтроллере хоть на ядрах, хоть на отдельных ПЛК.
Работа на 20 страниц, с формулами и математическими доказательствами. В то время, существующие методы с рынка в отказоустойчивых ПЛК - их надежность подтверждена - тестированием в лабораторных условиях ( ну и отзывами покупателей). Но насколько эти условия совпадают с условиями эксплуатациями? Вам покажут только лабораторные тесты, что при 10000 итераций, такой то ПЛК пропустил 2% сбоев. Тут надо просто поверить и надеяться что лабораторные условия похожи на рабочие.
У меня ситуация другая, надежность своего метода я доказываю - математически, не важно при каких условиях появится ошибка, но если в проекте инженер внесет такие то настройки , то получит такую то вероятность отказоустойчивости.
Тут конечно нужен отдельный пост про метод, его уже оценили в научных кругах исследователи и разработчики RISC V, и я продолжаю работу.
Если есть какие то вопросы - пишите в комментариях, или на почту zoshytlogic@gmail.com
Задался целью, подружить Arduino Nano с телефоном на Android, через OTG кабель. Да, можно и с wi fi, но было интересно сделать с кабелем. И вот результат.
Скетч
Android Studio, для написания приложения.
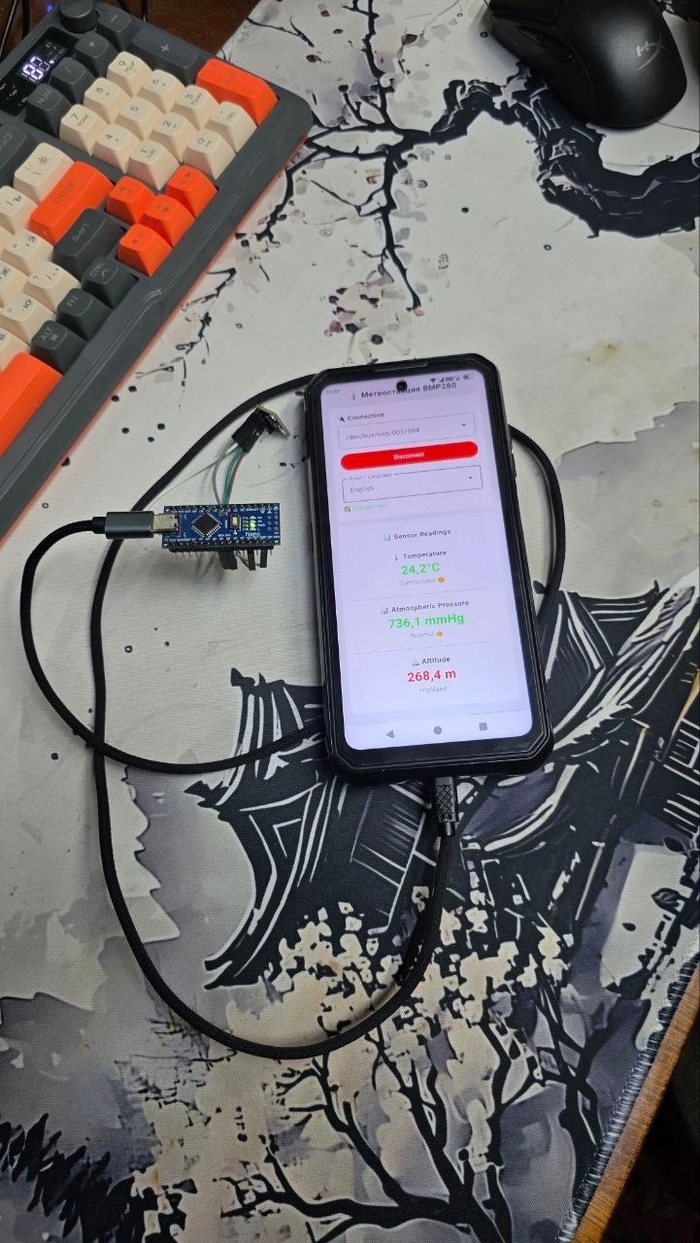
Подключение через OTG type-c/type-c
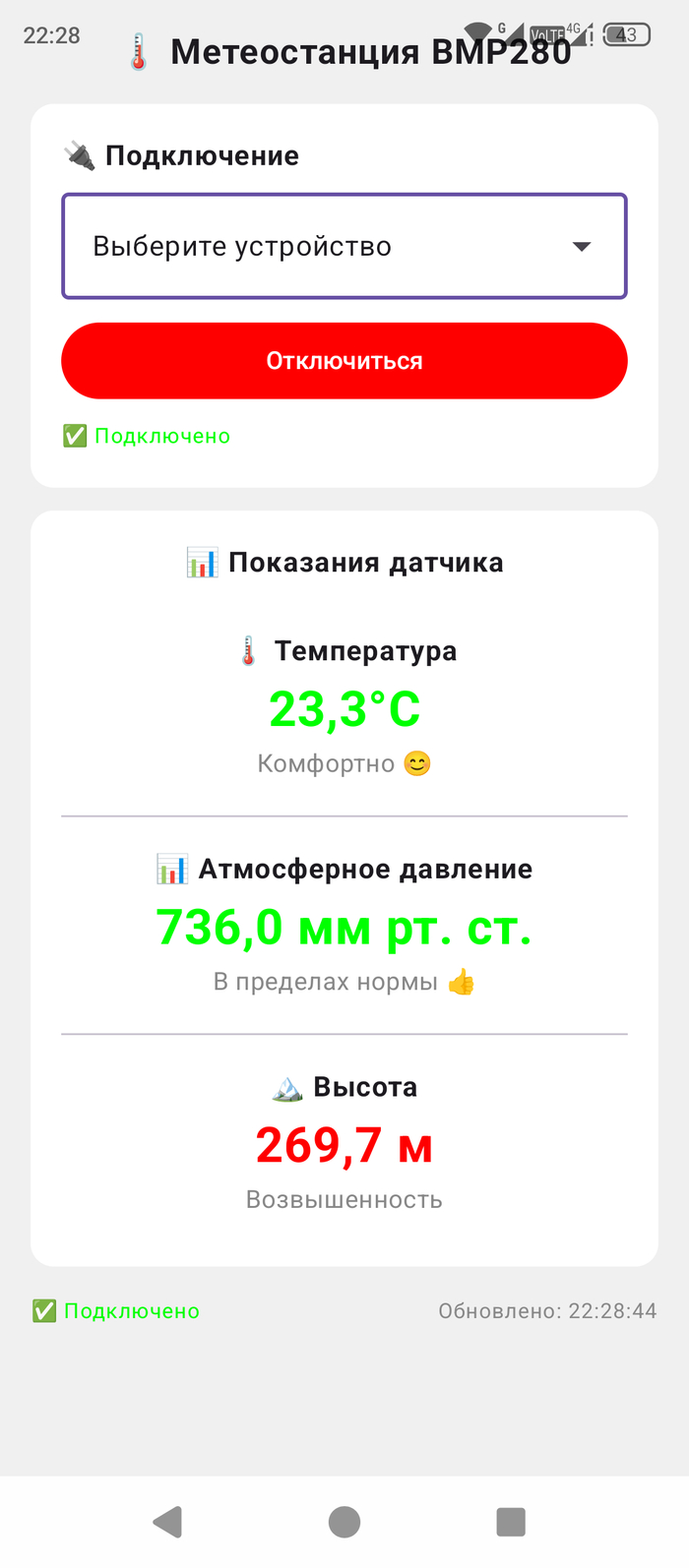
Само приложение на телефоне.
Скетч написан и доработан с помощью ИИ Deepseek.
