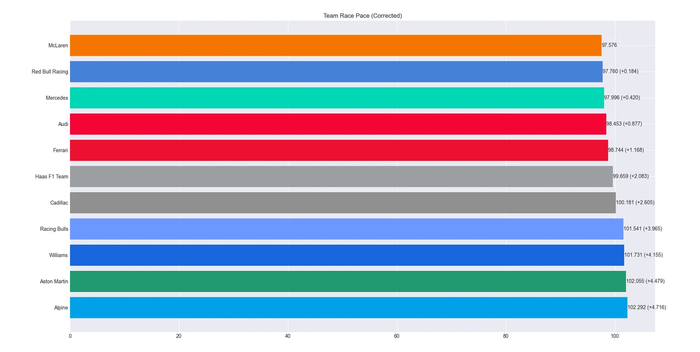
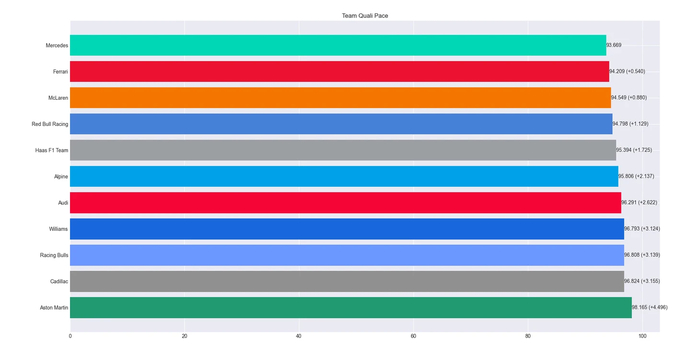
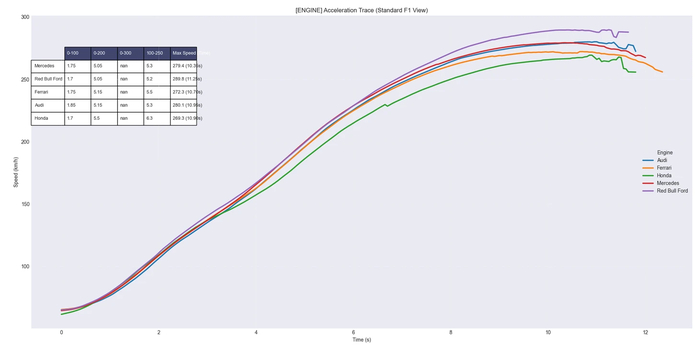
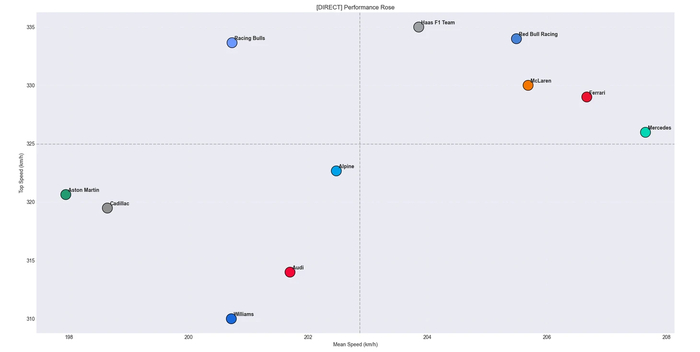
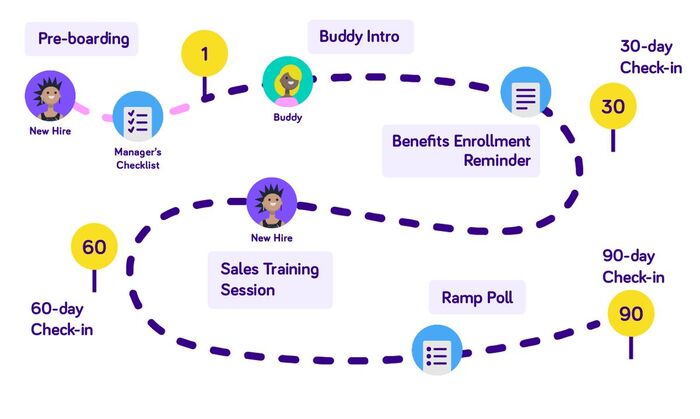
Онбординг. Как и что...
Онбординг - это систематический процесс адаптации нового сотрудника в компании.
В это период решается - человек станет частью системы или останется внешним наблюдателем.
Из здесь всегда есть две стороны:
что важно новичку
что важно работодателю
И они не всегда совпадают.
А в моем канале Аналитика FM выпуски про расчет Retention в разных бизнесах.
Канал я веду с нуля подписчиков, рассказываю про аналитику и разбираю различные кейсы на реальных примерах.
Подписывайся, если интересно как устроен мир аналитика!
Что важно новичку
Новичку в первые недели нужно не "вдохновение", а опора.
Ему важно:
понимать, что считается хорошей работой
понимать, по каким правилам принимаются решения
знать, куда можно задавать вопросы
понимать, что можно ошибаться
Самая частая тревога новичка:
Я не понимаю, правильно ли я делаю.
Если этой ясности нет - человек начинает тратить энергию не на работу, а на догадки.
Что важно работодателю
Работодателю важно другое:
чтобы сотрудник быстрее начал приносить результат
чтобы не отвлекать команду постоянными вопросами
чтобы человек стал самостоятельным
И здесь возникает классический конфликт:
Нужно ли подробно объяснять всё,
или лучше рассказать в общих чертах и “плыви сам”?
Две крайности
1. Гиперопека
Когда новичку:
всё разжёвывают
дают пошаговые инструкции
контролируют каждый шаг
Минус:
человек не учится думать самостоятельно.
Он становится зависимым от системы.
2. "Разбирайся сам"
Когда говорят:
Вот документация
Вот коллеги
У нас всё описано
Минус:
новичок не понимает негласные правила.
А в любой компании именно они самые важные.
Баланс
Хороший онбординг - это не лекция и не квест.
Это:
объяснение принципов
показ реальных кейсов
и постепенное усложнение задач
Важно объяснить:
как устроена логика компании
какие решения типичны
какие ошибки критичны
А дальше - да, человек должен идти и разговаривать с коллегами.
Потому что адаптация - это не только получение знаний.
Это встраивание в живую систему.
Пример условного Google
Представим офис Google. Там множество отделов, направлений, команд, людей.
И сделать программу ондординга, подходящую под каждый отдел/направление - мне кажется нереально. Поддерживать и адаптировать внедренную политику онбординга каждому отделу самостоятельно - тоже видится, что приведет к хаосу.
При зачислении на работу, сотрудникам не проводят инструктаж. В общих чертах вводят в курс, а дальше: иди общайся с коллегами, сам узнавай, как тут все устроено и как тебе эффективнее решить задачу.
Уметь общаться, объяснять и договариваться - базовый минимум для всех в компании. Этот навык здесь как фильтр.
А я до сих пор не понимаю (ну или не принимаю) - почему новичку надо преодолевать все эти круги ада, у него и так стресс - он пришел туда, где ему мало что известно именно про внутренние процессы и "обычаи". Да, он может знать о компании из внешних источников, да, он может знать концепцию бизнеса (и то, опираясь на свой опыт), но он явно не знает как и что устроено именно в этой конкретной компании.
Для такой компании важно:
чтобы сотрудник умел задавать вопросы
чтобы он спорил аргументированно
чтобы он предлагал решения
чтобы он был автономным
Если новичка в такой среде постоянно "ведут за руку" -
он не впишется в культуру.
Но и бросать его в хаос нельзя.
Поэтому в сильных компаниях:
есть чёткие процессы - иногда из четких процессов: Иди и разберись сам
есть наставник - иногда... Документация твой наставник
есть культура обратной связи - О боже, она бывает культурной...
Но при этом от человека ждут роста.
Вот тут важная аналогия
Когда-то динозавры были самыми крупными и доминирующими существами на планете.
Но они не смогли адаптироваться к изменениям среды -
и вымерли.
Размер, сила и масштаб не гарантируют выживания.
Гарантирует только способность адаптироваться.
Онбординг - это первая проверка на адаптацию.
Для сотрудника:
готов ли он учиться
готов ли он задавать вопросы
готов ли он менять привычные способы работы
Для компании:
готова ли она объяснять
готова ли она слышать нового человека
готова ли она меняться вместе с ним
Онбординг — это не про количество информации.
Это про скорость понимания среды.
Новичку важно дать:
ориентиры
ценности
границы
Но дальше он должен расти сам.
Потому что в долгосрочной перспективе
выживают не самые крупные компании
и не самые опытные сотрудники.
Выживают те,
кто умеет адаптироваться.
В канале Аналитика FM рассказываю про аналитику, SQL и аналитическое мышление.
Про особенности работы с данными.
Ну и пост о моем текущем опыте онбординга в новую компанию уже на подходе.
В новой компании я почти месяц уже!
Подписывайся!