

Ответ на пост «Советы "Бывалого"»1
Слышала, что такое Метеоризм? Если муж до встречи с тобой не пердел, то скорее всего он правильно питался. А теперь ты его кормишь тем, от чего жопу может разорвать.
Проблема не в муже, а в тебе.
Слышала, что такое Метеоризм? Если муж до встречи с тобой не пердел, то скорее всего он правильно питался. А теперь ты его кормишь тем, от чего жопу может разорвать.
Проблема не в муже, а в тебе.
Уже почти 6 лет прошло со времен моей записи об энергоэффективности - https://pikabu.ru/story/yenergoyeffektivnyiy_dom_klass_yenergosberezheniya_7524301
И вот я решил немного развить данную тему сегодня ;) К тому же дом уже другой xD
Я не стал утеплять стены нашего дома из газобетона.. и мне было интересно, к чему это приведет, сколько мы будет тратить на отопление и насколько дом энергоэффективный. Обо всем этом мы поговорим в данном видеоролике..
VK ВИДЕО:
YouTube:
Ссылка на файл - ОКЭД v1.0 "Определение класса энергоэффективности дома" - https://disk.yandex.ru/i/M6CBe8P4MQbO3Q

Времена, когда ручной разгон процессора мог дать десятки процентов дополнительной производительности, остались в прошлом. Современные ЦП благодаря продвинутым технологиям буста способны выжимать из себя последние мегагерцы — до тех пор, пока не упрутся в лимиты PL2, MTP или PPT. Как работают технологии авторазгона, и как с ними связаны лимиты энергопотребления?
До 2008 года все процессоры под нагрузкой работали на заявленной в спецификациях частоте, снижая ее только при перегреве и сопутствующем включении механизмов троттлинга.
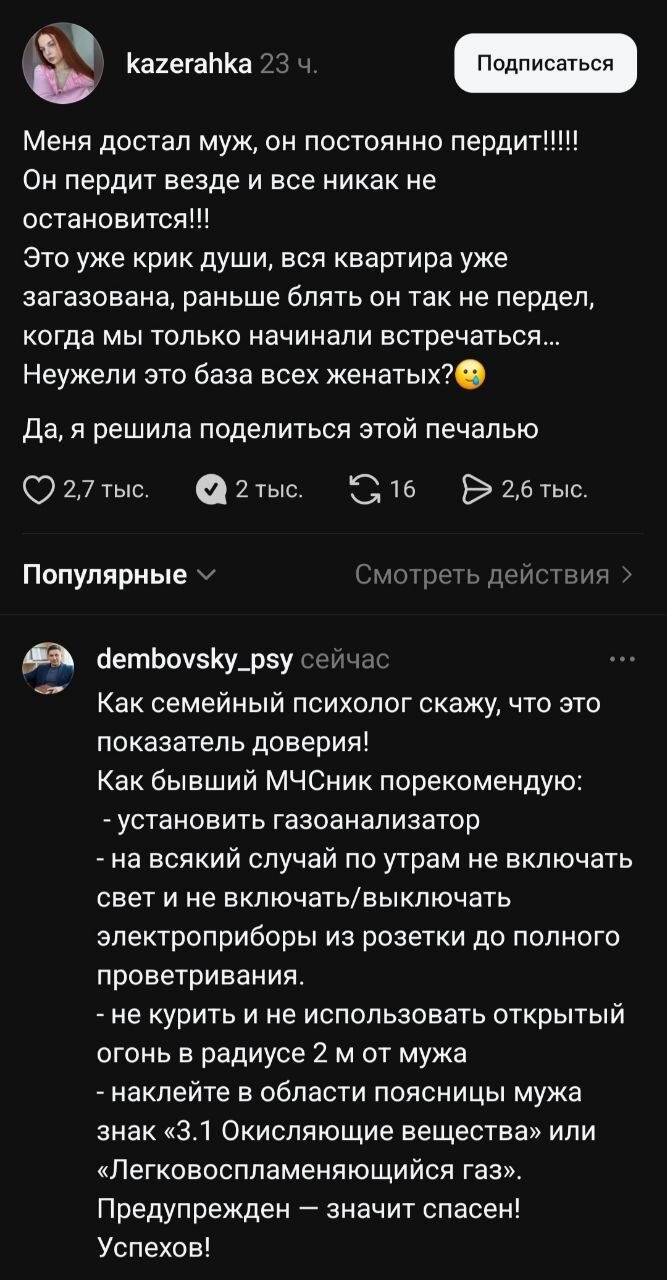
Дебютной технологией автоматического разгона стала Intel Turbo Boost. Изначально она появилась в Core i7 первого поколения для HEDT-платформы LGA 1366, и работала достаточно скромно: при нагрузке на одно ядро множитель ЦП увеличивался на два шага от базового (+266 МГц), при задействовании двух и более ядер — на один (+133 МГц).
В 2009 году с выходом массовой платформы LGA 1156 были представлены более доступные Core i5 и Core i7 первого поколения. В них Turbo Boost стал заметно более агрессивным — при одном-двух активных ядрах новые модели могли увеличивать частоту на 4–5 шагов (533–667 МГц).
Современная глава технологий авторазгона берет свое начало в 2011 году, когда с выходом Core второго поколения Intel представила Turbo Boost 2.0. Логика увеличения частоты множителем сохранилась и здесь: с ее помощью новые ЦП могли прибавлять от 100 до 400 МГц, в зависимости от количества загруженных ядер. Ключевым отличием от предшественника стала другая схема работы, которая основывалась на трех новых величинах:
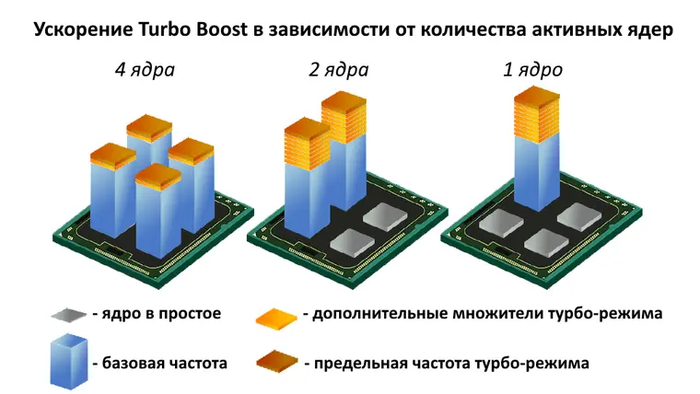
лимите долговременного потребления (Long Duration, PL1),
лимите кратковременного потребления (Short Duration, PL2),
окне работы буста (Time Window, Tau).
Отныне во время буста процессору разрешалось потреблять на 25% больше мощности — за это отвечал параметр PL2. Но если раньше авторазгон мог отключиться только из-за перегрева, то теперь с повышенным потреблением ему было разрешено работать только в пределах окна Tau, которое составляло 28 секунд. После того, как процессор исчерпал это время, его частота возвращалась к базовым значениям и заявленному TDP — чье значение дублирует параметр PL1.
В практически неизменном виде эта технология дожила и до наших дней. Она и поныне остается основной для процессоров Intel — с той разницей, что современные модели переключают частоты быстрее и разгоняются на более высокие величины (2 ГГц и выше). Но за последнее десятилетие компания представила еще несколько технологий, дополняющих Turbo Boost 2.0 и делающих авторазгон еще эффективнее:
Turbo Boost Max 3.0
Дальнейшее развитие идеи Turbo с упором на ускорение однопотока. Для этого на этапе производства ЦП выявляются одно-два наиболее удачных ядра, которые способны работать на более высоких частотах, чем остальные. При малопоточной нагрузке множитель их частоты повышается выше предела Turbo Boost 2.0.
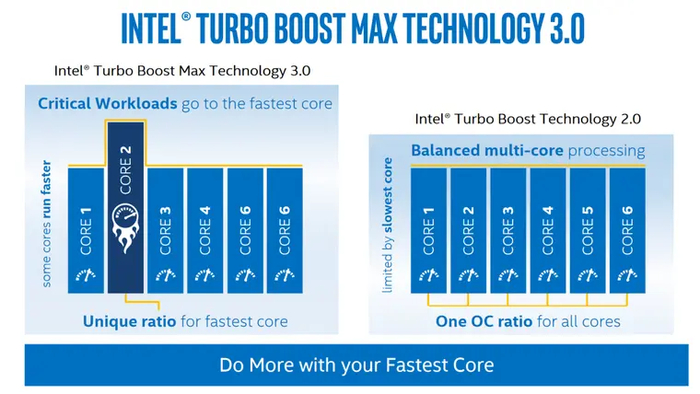
Turbo Boost Max 3.0 дебютировал в 2016 году в высокопроизводительных Core шестого поколения для сокета LGA2011-3, и был доступен во всех последующих процессорах Intel для HEDT-платформ. Именно там им обеспечивалось максимальное ускорение для одного ядра — до 700 МГц. В «гражданских» ЦП технология появилась с 10 поколения Core, и доступна по сей день лишь в Core i7/Ultra 7 и Core i9/Ultra 9. Прирост, обеспечиваемый ей, здесь гораздо скромнее: 100–200 МГц.
Thermal Velocity Boost
Дополнительная «плюшка» к Turbo Boost, появившаяся в Core i9 десятого поколения. Позволяет увеличить частоту одного или нескольких ядер на 100–200 МГц до тех пор, пока какое-то из них не нагреется до 70 °C. Среди десктопных моделей поддерживается всеми «девятками», среди мобильных — еще и Core i7/Ultra 7 с приставкой «HX».
Adaptive Boost
Еще одна надстройка над Turbo Boost, доступная с 11 поколения у топовых Core i9/Ultra 9 с разблокированным множителем. Позволяет увеличить частоту всех ядер на дополнительные 100–300 Мгц, игнорируя температурные ограничения вплоть до точки троттлинга — 100 °C.
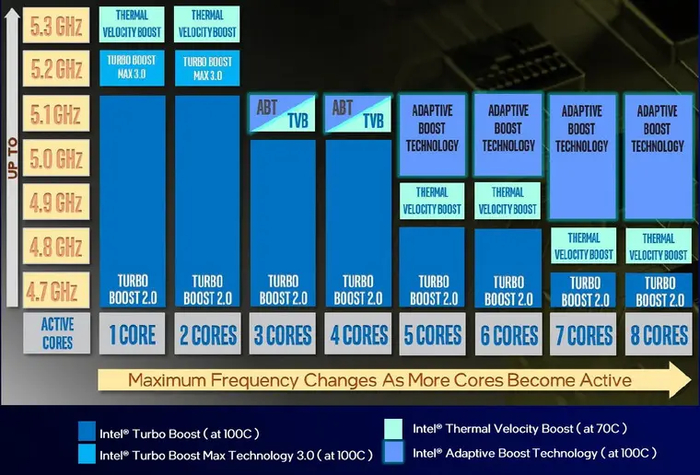
С 12 поколения Core Intel изменила название лимитов энергопотребления: место TDP и PL1 заняло значение Processor Base Power (PBP), а место PL2 — Maximum Turbo Power (MTP).
После появления Turbo Boost у Intel компания AMD задалась целью создать собственную схожую технологию. В 2010 году с выходом процессоров Phenom II X6 она представила свое собственное видение авторазгона — AMD Turbo Core.
Первое поколение Turbo Core работало гораздо примитивнее, чем решение от конкурента. При малопоточной нагрузке оно просто поднимало множитель у половины ядер: у шестиядерных Phenom II X6 — для трех, а у четырехъядерных Phenom II X4 — для двух. В этом случае прибавка составляла 400–500 МГц, но при задействовании всех ядер ее не было вовсе.

В конце 2011 года компания представила процессоры серии FX, оснастив их Turbo Core 2.0. Новая версия буста появилась во всех моделях линейки и стала эффективнее, обзаведясь двумя ступенями работы: All-Core Turbo и Max Turbo. Первый увеличивал частоту при нагрузке всех ядер на 100–300 МГц, а второй — при нагрузке половины ядер еще на 200–600 МГц.

Спустя год обновленные FX получили Turbo Core 3.0, который научился переключать частоту при изменении количества активных ядер более плавно. Но современная история технологий авторазгона у AMD началась лишь в 2017 году, когда были выпущены процессоры Ryzen 1000 серии. Вместе с ними компания представила сразу два дополняющих друг друга метода буста: Precision Boost и Extended Frequency Range (XFR).
Логика работы первого поколения Precision Boost была достаточно схожа с Turbo Core: при нагрузке на все ядра частота увеличивалась на 100–200 МГц, а при работе одного-двух ядер бустила еще на 300–500 МГц. В случае, если температура процессора была ниже 60 °C, то еще на 50–100 МГц пару ядер могла разогнать технология XFR.
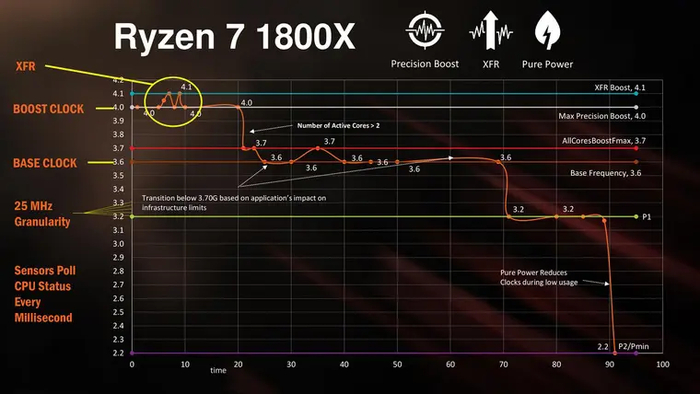
Однако по-настоящему Precision Boost и XFR раскрылись только со второй версии, появившейся в Ryzen 2000. Их работа стала строиться на основе трех ключевых параметров:
отслеживания мощности процессорного пакета (Package Power Tracking, PPT),
расчетного теплового тока (Thermal Design Current, TDC),
расчетного электрического тока (Electrical Design Current, EDC).
PPT дублирует PL2 из Turbo Boost 2.0 — это максимальная мощность, которую разрешено использовать ЦП при авторазгоне. По умолчанию она на 35% выше значения паспортного TDP. А два оставшихся параметра определяют предельную сила тока, которую можно подавать на процессор при долговременных (TDC) и кратковременных (EDC) нагрузках.
Логика буста была заметно перестроена. Вместо того, чтобы фиксировано переключаться между двумя ступенями частот, Precision Boost 2 и XFR 2 старались поддерживать максимальную частоту для любого количества задействованных ядер с шагом в 25 МГц.
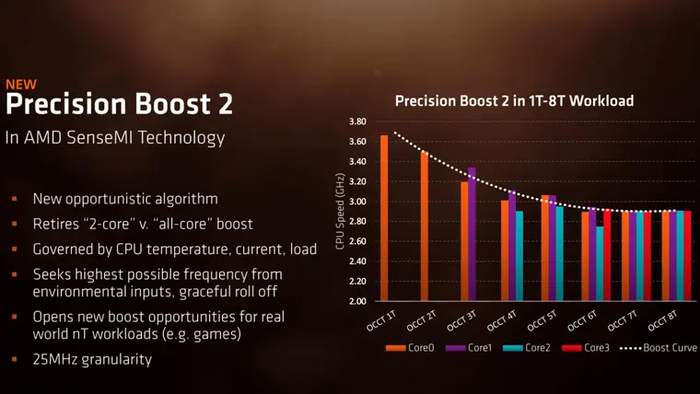
Это происходило до тех пор, пока процессор не упирался в лимит PPT, TDC или EDC — в зависимости от того, порог какого из них достигался раньше.

Буст XFR2 теперь распространялся не на одно-два ядра, а на все — но, как и прежде, лишь до достижения процессором 60°C. Precision Boost 2 продолжал работать и после этой отметки, но снижал частоту на 25 МГц через каждые несколько лишних градусов. В итоге к 85–90°C авторазгон в Ryzen 2000 практически отключался — в отличие от процессоров Intel, которые продолжали бустить вплоть до троттлинга.
Вместе с Precision Boost 2 для Ryzen с приставкой «X» AMD представила функцию Precision Boost Overdrive (PBO). С ее помощью пользователь мог расширить или снять заводские лимиты PPT/TDC/EDC для получения наивысших частот в бусте — для этого требовалась материнская плата с достаточно мощным VRM и эффективное охлаждение ЦП.
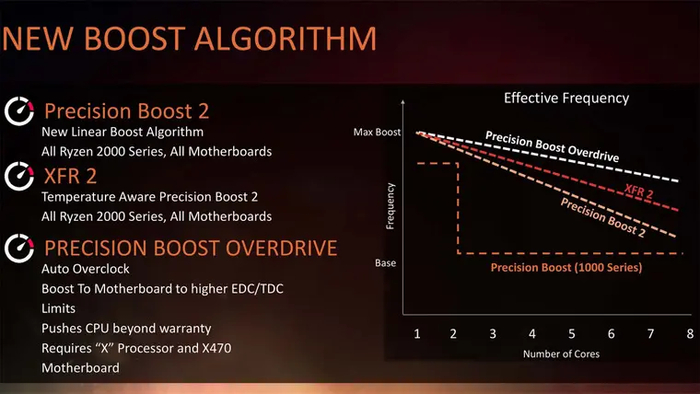
Технология Precision Boost 2 используется и во всех последующих поколениях Ryzen, включая самые современные — у них прирост от ее работы достигает отметки в 1.7 ГГц. Но с течением времени AMD улучшала алгоритм буста, внося в него небольшие изменения:
Ryzen 3000
С выходом этой линейки Precision Boost Overdrive стал доступен для всех новых Ryzen, не ограничиваясь моделями с приставкой «X». А алгоритм XFR2 перестал существовать самостоятельно, став частью Precision Boost 2. Буст отныне подстраивается под нагрузку в несколько раз быстрее — за 1–2 мс против 25–30 мс поколением ранее. Но повысилась и зависимость от температур: алгоритм авторазгона начал понемногу понижать частоты уже с 50 °C.
Ryzen 5000
Логика работы буста сохранилась, но он стал более агрессивным: по мере роста температуры частота теперь снижается заметно медленнее, падая ощутимыми темпами только после достижения 85°C. Технология Precision Boost Overdrive была обновлена до второй версии, позволяющей контролировать зависимость частоты от напряжения с помощью кривой.
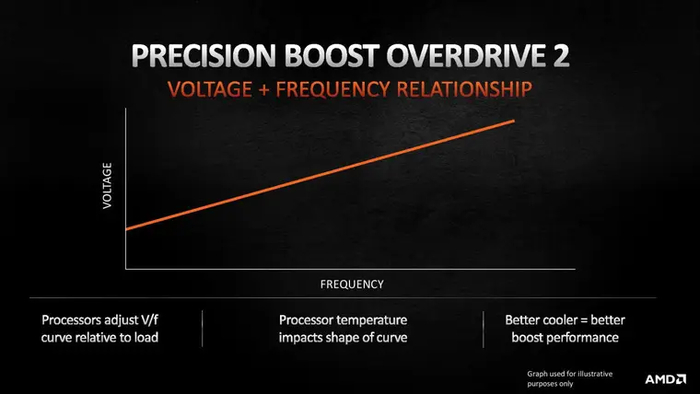
Ryzen 7000
Следующее агрессивное улучшение технологии авторазгона: это поколение старается поддерживать высокую частоту вплоть до точки троттлинга — 95 °C. Но модели с 3D V-Cache здесь все так же консервативны, удерживая высокий буст лишь до 80 °C. Скорость переключения частоты под нагрузкой увеличилась еще больше.
Ryzen 9000
Откат целевой температуры PB2 до 85 °C для обычных моделей, и увеличение его до 95 °C для процессоров с 3D V-Cache.
На заре своего появления технологии автоматического разгона были приятным бонусом, которые не меняли подхода к выбору материнской платы и системы охлаждения. Не изменилось это и с появлением первых поколений процессоров, у которых разгон осуществлялся на основе лимитов: ведь тепловыделение тогда было невысоким, а его превышение при бусте — небольшим и кратковременным. Например, при проектировании Core второго поколения расчеты Intel показали: за 28 секунд буста с тепловыделением 119 Вт боксовые кулеры с медной подошвой, рассчитанные на 95 Вт, продолжают справляться со своей работой без перегрева ЦП.
Но тепловыделение процессоров понемногу росло, да и размеры их кристаллов с уменьшением техпроцессов производства становились все компактнее. При переходе к технологии 14 нм плотность теплового потока заметно возросла, а распространение шестиядерных и восьмиядерных моделей поставило окончательную точку в вопросе выбора систем охлаждения: либо использовать «бокс» и наблюдать снижение производительности, либо переходить на куда более эффективные башенные кулеры.
С выходом Ryzen 2000 и Core 10 поколения данный эффект еще больше усилился. «Красные» за счет лимита Precision Boost 2 научились потреблять на 35% больше, чем расчетный TDP, а «синие» — почти на минуту превышать его до двух раз. Помимо в очередной раз возросших требований к системам охлаждения, это привело к гораздо большей зависимости производительности ЦП от VRM материнской платы — ведь если она могла стабильно обеспечить только базовый минимум мощности, то полной скорости работы от процессора ждать уже не стоило.

Поэтому сегодня значения базовой мощности TDP, PL1 и PBP при выборе материнской платы и системы охлаждения для ЦП не несут какой-то полезной информации — ориентиром стали лимиты максимальной мощности PPT, PL2 и MTP. Более того: если пользователь хочет получить от системы полную производительность без ограничений по времени, то ему надо будет снять и эти лимиты в BIOS материнской платы.
Хорошая новость: сегодня большинство моделей материнских плат позволяют это сделать. Плохая: подсистема питания далеко не любой платы сможет выдержать долговременное повышение мощности без перегрева и троттлинга. То же самое можно сказать о процессорных кулерах и СЖО — если планируется снимать лимиты, то необходимо выбирать из моделей с расчетным TDP минимум на 50 Вт выше, чем значение PPT/PL2/MTP.
К сегодняшнему дню технологии автоматического разгона процессоров прошли большой путь: от простых решений, которые позволяли немного увеличить производительность, до сложных аппаратных комплексов, способных выжать ее последние капли.
В этом есть несомненные плюсы: современные ЦП берут максимум от предоставленных им возможностей питания и охлаждения. Благодаря этому ручной разгон практически исчез, а его место занял андервольт — снижение напряжения питания с целью сделать процессор «холоднее». Но и минусов тоже предостаточно. При работе на лимитах «из коробки» большинство моделей и так снижает производительность под долговременной нагрузкой, а плохое охлаждение или слабый VRM материнской платы способны усугубить эту проблему еще в разы.

Из-за этого времена, когда можно было купить быстрый процессор, а плату и кулер «на сдачу», сегодня остались в далеком прошлом. И смотря на тесты современных ЦП в сети нужно держать в уме, что подобные результаты достижимы только с достаточным питанием и охлаждением — ведь без них даже самый скоростной процессор-карета быстро превратится в тыкву.
Эти ускорители позволяют обесценить большую часть ручного разгона. Купил, поставил и всё сразу быстро работает. Но у всего есть последствия, цена. Часто небольшой прирост быстродействия ведёт к огромному росту энергопотребления, а с ним и тепловыделения кремния.
Доплати за блок питания, материнскую плату, кулер процессора, корпус и вентиляцию. Порой много, иначе шумно и пыльно. Чаще тратить время на очистку, замену термоинтерфейса, будто нам заняться больше нечем. Если сэкономил, то теряешь стабильность и надёжность, сломается быстрее.
Раньше разгон был следствием осознанного риска и добровольного соглашения. BOX кулер справлялся с почти любым ЦП, даже старшими. Теперь он автоматически выставлен, кому не надо будут сами отключать или снижать напряжение для компенсации.
Раньше разгоняли чтобы экономить, теперь наоборот это коммерциализировали. Зарабатывают на нас и изначально не спрашивают, хотим ли буст. Порой люди жалуются, что кулер с заявленной мощностью 150 Вт не может охладить ЦП с TDP 65 Вт. Не понимают что творят, но им помогли запутаться.
Борода названий и хитро преподнесённые характеристики побуждают чаще доплачивать. Не пытаюсь выставить конторы злом. Но их интересы стоят выше наших, поэтому кого не устраивает, те потеряют больше времени на разбирательства. Сами о себе позаботимся, им до нас нет дела.
P.S. Кому интересно сравнят энергопотребление одного ядра при частоте 5 и 5.5 ГГц. Огромная разница стоит прибавки до 10% производительности? Если да, придётся доплатить. Если нет, то придётся терять время на настройку. Кто умеет делает быстро. Кто нет пожертвует кусочком жизни.
Я обожаю строительную тему. И мне особенно интересно наблюдать за обновлениями зданий времен СССР. И если на эспланаде в Перми были действительно интересные методы преобразования зданий в современные. С утеплением и новыми фасадами с остеклением. То здания «контор» меня откровенно поражают.

Кирпичные стены иии никакого утепления

Т.е. можно вложить кучу денег в фасад и забыть про энергоэффективность. Представьте, сколько денег нужно потратить, чтобы протопить эту дуру. И сколько можно экономить в год бюджетных средств, если бы это здание окунули в слой тизола.
Дальше фраза, поданная в роспатент автовазом.
Напомню - есть специальные люди, которые разрабатывают такие проекты, которые делают расчет экономической целесообразности. И они получают за это зарплату.
Пикабушник скажет - «критикуешь? Предлагай».
Был бы я на месте ответственного лица - я бы сделал расчет и защитил бы доп трату банальным расчетом теплового сопротивления и экономией в гигаватах за год.

Словацкая студия Ark-Shelter представила полностью автономный компактный дом площадью всего 20 м². Он рассчитан на комфортное проживание 1–2 человек и расположен в живописном месте — возвышается над виноградниками Златы-Рох создавая атмосферу уединенного оазиса с видом на природу. Причем его можно арендовать (по ссылке) и протестировать такой формат жизни.




Вся система построена вокруг солнечных панелей и аккумуляторов: днем дом накапливает энергию, ночью — использует ее. Если солнечной генерации не хватает, подключается резервная газовая система.

По сути, это не просто маленький дом, а модель энергоэффективной жизни:
меньше потребления ➡️ меньше зависимости от сети ➡️ меньше выбросов.

Больше интересной информации про источники энергии и энергетику в телеграм-канале ЭнергетикУм
Ученные Сиднейского университета создали прототип нанофотонного процессора для искусственного интеллекта, который обрабатывает данные с помощью света вместо электрического тока. В ходе экспериментов чип успешно классифицировал десятки тысяч медицинских изображений с точностью до 99 процентов. Новая архитектура выполняет вычисления за пикосекунды (триллионные доли секунды), полностью исключая проблему тепловыделения, и демонстрирует альтернативу перегревающимся кремниевым серверам современных дата-центров.
Фотография нанофотонного процессора под микроскопом
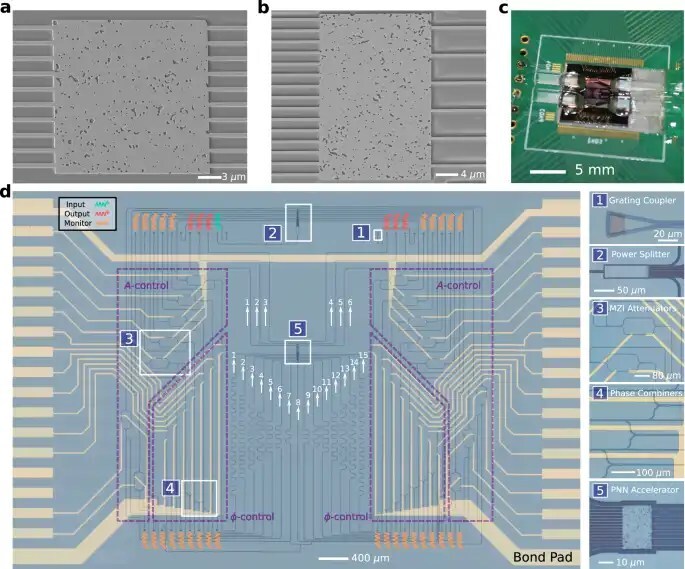
Снимки сканирующего электронного микроскопа чипов MNIST (20×20 мкм) и MedNIST (30×20 мкм), созданных на платформе кремний-на-изоляторе. Авторы: Joel Sved et al. Источник: Nature Communications.
На изображении представлены увеличенные микроскопические снимки нанофотонных ускорителей. Показаны оптические волноводы, подводящие свет к структуре с топологически оптимизированным материалом, где происходят физические вычисления. На нижних фрагментах видна интеграция чипа на печатную плату с золотыми контактами для взаимодействия с управляющей электроникой. Авторы: Joel Sved et al. Источник: Nature Communications.
Исследовательская группа по фотонике Сиднейского университета под руководством профессора Сяокэ И представила работающий прототип сверхкомпактного оптического процессора. Устройство предназначено для выполнения математических операций, лежащих в основе машинного обучения. Особенность разработки заключается в полном отказе от перемещения электронов по металлическим проводникам — процесс обработки информации базируется на управлении фотонами.
Традиционные вычислительные системы при высоких нагрузках неизбежно выделяют колоссальный объем тепла из-за электрического сопротивления. Фотонный чип решает эту проблему на фундаментальном уровне. Свет проходит через наноструктуры без сопротивления, что делает генерацию тепла практически нулевой. Скорость выполнения одной операции при этом сокращается до пикосекундного диапазона — триллионных долей секунды. Это время, за которое свет физически успевает преодолеть структуру чипа.
Разработка была протестирована на базах данных MNIST (рукописные цифры) и MedNIST (более 10 000 биомедицинских изображений, включая МРТ грудной клетки и брюшной полости). В симуляциях система показала точность до 99 процентов. В реальных аппаратных экспериментах чип продемонстрировал точность классификации в 89 процентов для базы MNIST и 90 процентов для MedNIST, уверенно распознавая визуальные паттерны заболеваний на медицинских снимках.
Индустрия искусственного интеллекта стремительно упирается в «энергетическую стену». Вычислительные центры требуют мегаватты электричества и миллионы литров воды для охлаждения серверов. Фотонные нейронные сети рассматриваются как логичный выход из кризиса, однако до сих пор их слабым местом оставались габариты. Создать оптический элемент сложнее, чем вытравить миллиард кремниевых транзисторов на одном квадратном миллиметре.
Австралийские исследователи обошли это ограничение с помощью метода обратного проектирования, основанного на 3D-моделировании электромагнитных полей. Вместо того чтобы строить нейросеть из классических оптических компонентов вроде интерферометра Маха-Цендера, инженеры позволили алгоритму самостоятельно рассчитать оптимальную форму материала.
Получившийся чип представляет собой сложную, визуально хаотичную наноструктуру из кремния и диоксида кремния. Внутри этой структуры световые волны (на длине волны 1550 нанометров) многократно рассеиваются и интерферируют. Проходя через материал, свет физически выполняет операцию умножения матриц. Размеры рабочей зоны составляют всего 20×20 микрометров для задачи распознавания цифр и 30×20 микрометров для медицинских изображений. По оценке создателей, такая архитектура обеспечивает феноменальную вычислительную плотность — около 400 миллионов обучаемых параметров на один квадратный миллиметр.
Успех австралийской команды опирается на десятилетие предшествующих исследований в области физики оптических вычислений. Долгое время главным камнем преткновения для фотоники оставались нелинейные операции — функции активации, которые позволяют нейросети решать нешаблонные задачи и выявлять сложные закономерности. Фотоны практически не взаимодействуют друг с другом, из-за чего создание оптической нелинейности требовало огромных затрат энергии. В ранних системах оптические данные приходилось конвертировать обратно в электрические сигналы, отправлять на цифровой процессор для применения нелинейной функции, а затем снова переводить в свет.
Решение этой проблемы ранее предложила группа ученых из Массачусетского технологического института под руководством Дирка Энглунда и Саумила Бандиопадхьяя. В их архитектуре, описанной в журнале Nature Photonics, были применены нелинейные оптические функциональные блоки. Эти элементы отводят минимальную часть света на фотодиоды для преобразования в слабый ток, управляя нелинейностью без внешних усилителей.
В результате чип MIT смог выполнить весь цикл вычислений глубокой нейросети — как линейные, так и нелинейные операции — исключительно в оптическом домене менее чем за половину наносекунды с точностью выше 92 процентов. Исследователи доказали, что оптические процессоры могут обучаться в режиме реального времени, потребляя лишь малую долю энергии по сравнению с кремниевыми аналогами.
Пока академические группы бьются над повышением точности и миниатюризацией вычислительных ядер, технологические компании уже адаптируют фотонику для нужд гиперскейлеров. Основное узкое место современных ИИ-кластеров — не только скорость самих вычислений, но и скорость передачи данных между видеокартами (GPU).
Компания Lightmatter выводит на рынок технологию 3D Co-Packaged Optics. Их решения, такие как фотонный суперчип Passage M1000, объединяют электронные интегральные схемы с фотонными напрямую в едином компактном модуле. Это снимает классические ограничения пропускной способности медных соединений, возникающие из-за физической нехватки места для контактов по периметру печатных плат. Что критически важно для обучения гигантских языковых моделей.
Фотонные модули Lightmatter способны передавать до 448 гигабит данных в секунду по одному оптическому каналу. Для достижения таких сверхскоростей применяется технология PAM4 — особый формат многоуровневой амплитудной модуляции, который позволяет «упаковывать» в каждый сигнал в два раза больше информации по сравнению с традиционными методами кодирования. Кроме того, архитектура системы позволяет производить горячую замену оптоволокна прямо в серверных стойках дата-центров.
Команда Сиднейского университета уже подала патентную заявку на свою технологию нанофотонных чипов и работает над ее масштабированием. Следующим шагом станет объединение множества подобных блоков в крупные оптические сети для обработки фрагментированных данных по принципу сверточных нейросетей. Архитектура разрабатывается с расчетом на стандартные производственные процессы CMOS-фабрик. Переход индустрии на оптику — процесс не быстрый, однако успешная интеграция света на микроуровне доказывает, что у кремниевой монополии появился фундаментально обоснованный конкурент.
Чтобы понять фундаментальную разницу между классическим и оптическим процессором, достаточно спуститься на уровень элементарных частиц. В основе работы любого современного графического ускорителя лежит направленное движение электронов. Электрон — частица с ненулевой массой покоя и отрицательным электрическим зарядом. Когда миллиарды этих частиц под действием напряжения продираются сквозь кристаллическую решетку полупроводника, они неизбежно сталкиваются с ее атомами.
В физике твердого тела этот процесс называется рассеянием, а на практике он работает как микроскопическое трение. Электроны отдают часть своей кинетической энергии решетке, заставляя атомы вибрировать сильнее. На макроуровне эта вибрация превращается в стремительный нагрев. Именно из-за этого фундаментального физического ограничения современные серверные стойки с видеокартами требуют гигантских радиаторов, мощных вентиляторов и тысяч литров воды для охлаждения.
Фотонная архитектура меняет сами правила игры, отказываясь от заряженных электронов в пользу фотонов. У фотона нет ни электрического заряда, ни массы покоя. Когда инфракрасный луч лазера попадает в наноразмерный кремниевый волновод оптического чипа, он движется по нему, не испытывая классического электрического сопротивления.
Фотоны не взаимодействуют друг с другом так, как это делают заряженные частицы, и не «трутся» об атомы направляющей среды (для длины волны 1550 нанометров кремний абсолютно прозрачен). Они проходят сквозь сложную топологию чипа без передачи паразитной энергии материалу. В результате математические операции — интерференция и рассеяние света, заменяющие умножение матриц — происходят не только с максимально возможной физической скоростью, но и без генерации тепла. Фотонному процессору не нужны системы охлаждения просто потому, что в нем нет трения.
На первый взгляд использование кремния для создания оптического процессора кажется абсурдом. В нашем привычном понимании кремний — это основа классической микроэлектроники, серый кристалл с металлическим блеском, сквозь который невозможно ничего разглядеть. Как материал, абсолютно непрозрачный для человеческого глаза, может стать микроскопической магистралью для лазерных лучей?
Разгадка кроется в длине волны. То, что является непреодолимой стеной для видимого спектра, для инфракрасного излучения оказывается открытой дверью. На длине волны 1550 нанометров (именно она используется в разработке Сиднейского университета и является стандартом для оптоволоконной связи) чистейший кристаллический кремний становится прозрачным, словно высококачественное оконное стекло.
Однако просто пропустить свет сквозь материал недостаточно — физикам нужно заставить луч поворачивать, делиться и интерферировать на площадке размером тоньше человеческого волоса. Для этого инженеры используют технологическую платформу «кремний-на-изоляторе». Тончайший слой кремния укладывается на подложку из диоксида кремния, после чего в верхнем слое вытравливаются микроскопические дорожки — оптические волноводы.
Здесь начинает работать фундаментальный закон оптики — полное внутреннее отражение. Кремний имеет очень высокий показатель преломления по сравнению с окружающим его диоксидом. Когда инфракрасный лазер попадает в такой кремниевый канал, резкий контраст оптических плотностей материалов превращает границы волновода в идеальное зеркало. Свет оказывается запертым внутри: он отскакивает от стенок кремниевой «проволоки» и мчится по извилистому наноразмерному лабиринту чипа, не рассеиваясь наружу. Именно этот физический трюк позволяет ученым использовать традиционное оборудование заводов по производству электроники для создания сложнейших световых процессоров.
Глядя на микроскопический снимок нового нанофотонного процессора, можно заметить, что его рабочая зона совершенно не похожа на строгую прямоугольную геометрию классических электронных микросхем. Она выглядит хаотичной, текучей, почти органической. Подобный подход к управлению светом за счет сложнейшей физической формы ученые давно подсмотрели у самой природы. Самый яркий пример такой оптической инженерии — крылья тропических бабочек рода морфо.
Знаменитый пронзительно-синий цвет их крыльев возникает не благодаря биологическим пигментам или химическим красителям. Если измельчить чешуйку такого крыла в пыль, сияющий оттенок исчезнет, оставив лишь невзрачную серую массу. Секрет кроется в явлении структурной окраски. На поверхности крыла расположены миллионы микроскопических элементов со сложной, напоминающей ветвящиеся деревья, наноструктурой. Когда свет попадает на этот рельеф, он многократно преломляется и интерферирует. Физическая архитектура чешуйки выверена эволюцией так, что световые волны синего спектра накладываются и усиливают друг друга, в то время как волны других цветов взаимно гасятся.
Создавая свой ИИ-чип методом топологической оптимизации, австралийские инженеры применили ровно тот же фундаментальный принцип. Алгоритм буквально «вылепил» из кремния сложнейший нанорельеф, который работает как идеальный оптический лабиринт. Точно так же, как крыло бабочки манипулирует светом для создания безупречного синего цвета, кремниевая структура процессора заставляет инфракрасные лазерные волны интерферировать и рассеиваться по строго заданным математическим векторам. В обоих случаях сложнейший результат — будь то потрясающий визуальный эффект или нейросетевая классификация медицинского снимка — достигается исключительно за счет виртуозной геометрии наноструктур: хитина у бабочки и кремния в процессоре.
Inverse-designed nanophotonic neural network accelerators for ultra-compact optical computing — Nature Communications, авторы: Joel Sved, Shijie Song, Liwei Li, George Li, Debin Meng, Xiaoke Yi
Sydney researchers build ultra-compact AI chip operating at speed of light — EurekAlert!
Sydney researchers build ultra-compact AI chip operating at speed of light — EX2 for Defence Innovators, авторы: Gregor Ferguson
Lightmatter® — The photonic (super)computer company. — Lightmatter
Photonic processor could enable ultrafast AI computations with extreme energy efficiency — MIT News, авторы: Adam Zewe










