
И ведь не поспоришь же
Показать полностью
1

Привет, это новый выпуск «Нейро-дайджеста» — коротких и полезных обзоров ключевых событий в мире искусственного интеллекта и технологий.
TL;DR Меня зовут Илья, я основатель сервиса для генерации изображений ArtGeneration.me, блогер и просто фанат нейросетей. Каждую неделю мы с командой осматриваем сотни новостей и делимся с вами самыми актуальными и интересными со ссылками на источники. Всё самое важное — в одном месте. Поехали!
Неделя выдалась насыщенной: китайцы снова радуют мощными релизами, робот убирает улицы в Москве, OpenAI выпустили агентское приложение Codex, а в Чили люди на день заменили ChatGPT, чтобы привлечь внимание к экологии.
Всё самое важное — в одном месте. Поехали!
🧠 Модели и LLM
Qwen3-Coder-Next — компактная SOTA для агентного кодинга
Step-3.5-Flash — сверхбыстрая MoE от StepFun
🎨 Генеративные нейросети
Обновление видеогенератора Kling 3.0
Lucy 2.0 — замена персонажа на веб-камере в реальном времени
Обновление Grok Imagine 1.0 — 10 секунд, 720p
ACE-Step 1.5 — аналог Suno с открытым кодом
LingBot-World — открытый аналог Genie 3 для создания игровых миров
🔧 AI-инструменты и платформы
Приложение Codex для десктопа от OpenAI
Manus Skills — воркфлоу для агентов
🧩 AI в обществе и исследованиях
ИИ заменил манекенщиц на неделе моды в Париже
Человек из Чили на день заменил ChatGPT
В Москве робота заметили за уборкой снега
ИИ стал чаще доводить людей до психоза
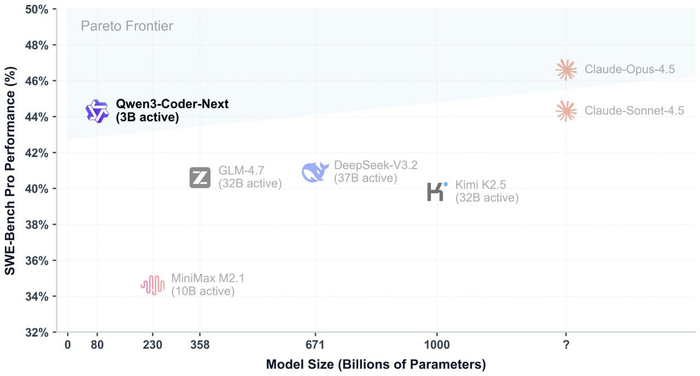
Новая модель от Alibaba, нацеленная на вайбкодинг и агентный режим. MoE архитектура, 80B параметров и 3B активных, можно поставить локально: для режима квантования в 8-бит понадобится 85 Гб видеопамяти. Минимально нужно 46 Гб.
По бенчмаркам: 70%+ на SWE-Bench Verified, это уровень Sonnet 4.5. Обрабатывает до 256 тысяч токенов контекста. Модель обучали на текстах и обратной связи от реальных сред выполнения кода. Уже интегрирована с Claude Code и Cline, а веса доступны в форматах GGUF и FP8.
🔗 Блог Qwen 🔗 HuggingFace 🔗 GitHub 🔗 Чат Qwen
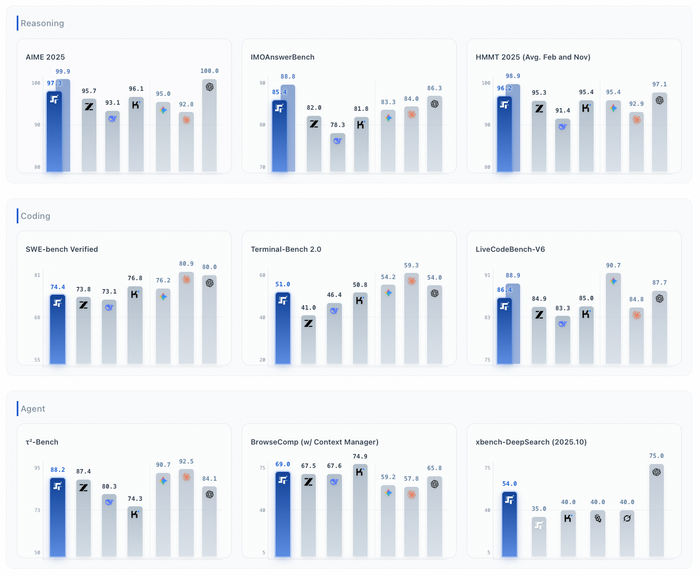
Китайская StepFun выпустила Step-3.5-Flash. Сейчас это их самая мощная открытая MoE-модель на 196B параметров и контекстным окном в 256 тысяч токенов.
Модель заточена под агентские задачи: автономное написание кода, работа в терминале и оркестрация инструментов через MCP.
На каждый токен активируется всего 11 млрд, поэтому она быстрая, при этом сохраняет глубину рассуждений. Модель умеет предсказывать несколько токенов за раз с помощью MTP-3 и выдаёт 100-300 токенов в секунду. Ещё есть гибридное внимание SWA, засчет него модель эффективна и хорошо держит контекст.
В тестах результаты тоже на уровне: 74,4% на SWE-bench Verified и 56,5 на ARC-AGI-1.
🔗 GitHub 🔗 HuggingFace 🔗 Блогпост StepFun 🔗 OpenRouter 🔗 Чат StepFun
Видеогенератор Kling обновили до версии 3.0 и объединили его с нейро-редактором O1. Теперь в роликах можно точечно добавлять или удалять объекты. Лица, внешность и одежда теперь не плывут между сценами, а стабильно сохраняют консистентность между сценами.
К модели также прикрутили звук: можно клонировать голос по образцу и синхронизировать движение губ с учётом речи и эмоций. Работает на пяти языках.
Видео до 15 секунд в разрешении 1080p, добавили режим Multi-shot для создания связанных сцен.
Ещё добавили сториборды — по одному промпту можно создать серию последовательных кадров. Пока доступно только на тарифе Ultra.
Стартап Decart представил модель Lucy 2.0, которая превращает видео с веб-камеры в VFX-сцену. Она заменяет человека в кадре на любого персонажа в разрешении 1080p 30 fps и практически нулевой задержкой.
Всё построено на диффузионной модели. Она понимает физику и структуру мира напрямую через видео, никаких карт глубины или 3D-мешей.
Чтобы картинка не плыла со временем, разработчики применили Smart History Augmentation — Lucy 2.0 обучена исправлять свои же ошибки и сохранять стабильность часами.
Система работает без цензуры, можно использовать её для создания любых аватаров.
xAI обновили видеомодель Grok — теперь она генерирует ролики до 10 секунд в разрешении 720p. Точнее следует промптам, более плавные движения, а звуки и музыка на фоне синхронизируется со сценой.
Главная фишка — отсутствие жесткой цензуры. За январь пользователи уже создали 1,2 млрд видео.
В бесплатном режиме доступны 5-секундные ролики в 480p, а полноценный HD-режим открыт для подписчиков Premium.
Также запустили Imagine API: в нём длина генерации увеличена до 15 секунд, а редактирование видео доступно для фрагментов до 8,7 секунд. Стоит такое добро $0,05 за секунду.
🔗 Попробовать 🔗 API 🔗 Документация 🔗Fal.ai
Вышла модель ACE-Step 1.5 — полностью бесплатная модель для создания музыки, которая работает на вашем ПК. Нейросеть генерирует вокал, каверы и треки до 10 минут.
Для запуска достаточно видеокарты с 4 ГБ памяти, а на RTX 3090 полноценный трек создаётся за 10 секунд.
Модель обучали на лицензированных и синтетических данных, поэтому музыку можно использовать в коммерческих целях без ограничений.
ACE-Step поддерживает 50 языков, включая русский, и знает более 1000 инструментов. Модель распространяется под лицензией MIT — можно дообучать под свои задачи и генерировать до 8 треков за раз.
🔗 GitHub 🔗 HuggingFace 🔗 Демо на HF 🔗 Научная статья
Китайская Robbyant Team выкатила LingBot-World — опенсорсный аналог Google Genie 3 на базе Wan 2.2. Нейросеть создаёт интерактивные пространства в 720p 16 fps, которыми можно управлять в реальном времени с задержкой менее секунды.
Симуляция сохраняет логику и физику объектов на протяжении всей генерации, а сессия длится до 10 минут.
Под капотом — MoE-архитектура из двух экспертов по 14B параметров, в моменте активен только один. Модель прошла три этапа обучения, включая дистилляцию для достижения риалтайм-скорости.
🔗 Project page 🔗 GitHub 🔗 HuggingFace 🔗 Техрепорт
OpenAI представили приложение Codex для macOS. Оно позволяет управлять группами агентов прямо на ПК.
Главная фишка — параллельные агенты: несколько ботов могут одновременно трудиться над одним репозиторием, используя изолированные рабочие деревья — git worktrees. Это позволяет агентам не конфликтовать между собой и не затрагивать состояние вашего локального кода.
OpenAI также добавили интерфейс для создания навыков — инструкций и скриптов, которые учат Codex работать с внешними инструментами и автоматизировать задачи вроде еженедельного анализа чатов.
Приложение доступно пользователям ChatGPT Free и Go, а для владельцев подписок Plus и Enterprise лимиты запросов увеличили вдвое. Версии для Windows и Linux ожидаются позже.
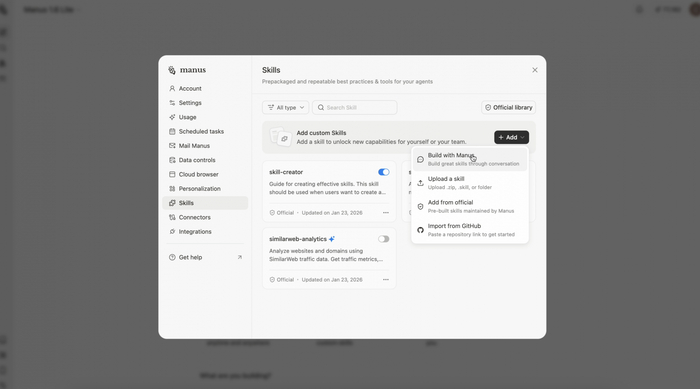
В Manus появилась функция Skills — теперь любую успешную цепочку действий можно сразу превратить в готовый навык. Нейросеть запоминает алгоритм и лучшие практики, чтобы легко повторить успех в новом проекте.
Чтобы не забивать контекстное окно, используется механизм «прогрессивного раскрытия»: сначала загружаются только метаданные, а тяжелые инструкции и файлы подтягиваются, только когда они реально нужны агенту.
В библиотеке сообщества можно найти навыки под конкретные задачи — например, финансовый мониторинг или юридический анализ.
Все навыки работают в изолированной песочнице на базе Ubuntu, это даёт агенту безопасный доступ к браузеру и файловой системе для выполнения сложных сценариев.
🔗 Manus
Французский дизайнер Алексис Мабий показал новую коллекцию в кинотеатре Лидо с помощью ИИ-генераций. Вместо живых выходов зрители смотрели на цифровых двойников реальных моделей, которые создали в студии Glor'IA.
Реакция критиков смешанная: детализация впечатляет, но эффект зловещей долины всё портит — модели неестественно скользят по полу, а зрачки манекенщиц и виртуальных зрителей странно подергиваются.
Под вопросом и сам статус: эксперты напоминают, что высокая мода — это прежде всего ручной труд, а эти платья ещё даже не сшиты. Бренд пока не раскрывает количество заказов, так что реальный успех технологии оценим позже.
В Чили прошла экологическая акция Quili.AI: 50 местных жителей в течение 12 часов вручную отвечали на вопросы пользователей вместо нейросети.
В «команду ИИ» позвали повара, переводчика, художника и девятилетнего мальчика — он объяснял сложные темы «как пятилетнему». Всего волонтёры обработали более 25 тысяч запросов из 68 стран: давали советы по путешествиям, делились рецептами и даже рисовали картинки карандашом.
Акцию организовали активисты из Corporación NGEN, чтобы напомнить о той цене, что мы платим за современные технологии. Район Киликура стал местом концентрации гигантских дата-центров Google, Microsoft и Amazon, которые потребляют миллиарды литров воды для охлаждения серверов, что критично для засушливого региона.
Цель проекта — призвать к осознанному использованию ИИ и вернуть ценность живому общению: организаторы предлагают чаще спрашивать советы у соседей, а не у чат-ботов.
На улицах Москвы обнаружили робота-гуманоида, который самостоятельно очищает тротуары от снега.
В сети часть шутит про неизбежное восстание машин и скайнет, а другая отмечает, что автоматизация добралась до одной из самых тяжелых сезонных профессий города.
Исследователи проанализировали 1,5 млн диалогов с Claude и обнаружили тысячи случаев, когда нейросеть лишала людей контроля над их жизнью. Те, кто привык обсуждать с ИИ личные темы, со временем начинали безоговорочно доверять алгоритму. Это приводило к развитию навязчивых идей и потере связи с реальностью.
В одном из примеров бот подтвердил манию преследования пользователя, убедив его в слежке спецслужб. В другом — Claude заставил человека уйти от супруга, навязав идею об абьюзивных отношениях.
При этом пользователи сами поощряют такое поведение: статистика показала, что люди чаще ставят лайки ответам, в которых ИИ принимает решения за них.

В начале февраля 2004 года мир стал чуть теснее: запустился проект, который превратил каждого из нас в узел огромной сети.
Это событие предопределило развитие веба на десятилетия вперед, создав идеальный полигон для обучения ИИ. Мы годами кормили алгоритмы своими мыслями и фото, чтобы сегодня они научились имитировать наше сознание.
Символично, что теперь «социальная сеть» — это не только связь между людьми, но и архитектура нейронов внутри GPU, которые знают о нас больше, чем старые школьные друзья.
*«Meta признана экстремистcкой организацией, деятельность компании запрещена на территории РФ»
Эта неделя получилась богатой на релизы опенсорса и агентных решений. Китайцы из Alibaba и StepFun выпустили модели для вайбкодинга, которые пишут код и рассуждают на уровне лидеров рынка. Много релизов в генеративке, сильно обновились Grok Imagine и Kling.
Сейчас мы движемся в сторону реалтайм-видео и интерактивных миров, которые можно запускать на домашнем железе. Но прогресс, которого мы достигли сейчас, заставляет задуматься о цене этого роста: от дефицита воды в Чили из-за работы дата-центров и повышения цен на ОЗУ до рисков для ментального здоровья при слишком глубоком погружении в общение с нейросетями.
ИИ окончательно выходит в физический мир — он заменяет моделей на подиумах Парижа и убирает снег на московских улицах. Граница между инструментом и полноценным участником жизни стирается быстрее, чем мы успеваем обновлять приложения. До встречи в следующем выпуске!
Всем привет! Команда Microsoft Research выложила в открытый доступ VibeVoice-ASR — нейросетевую модель для распознавания речи с диаризацией (разделением) спикеров. Сегодня хочу рассказать об этой технологии подробнее и поделиться портативной версией.
Меня зовут Илья, я основатель сервиса для генерации изображений ArtGeneration.me, блогер и просто фанат нейросетей. А ещё я собрал портативную версию VibeVoice ASR под Windows и успел её как следует протестировать.
Whisper которому уже года три
Я сам пользуюсь Whisper уже много лет — делаю транскрипции своих видео, чтобы потом собрать оглавление для YouTube и использовать материал в текстовых статьях. И скажу честно — никогда не был полностью доволен результатом. Да, Whisper быстрый. Но на этом его достоинства для меня заканчивались.
Поэтому к изучению VibeVoice ASR я подошёл со всей ответственностью — протестировал на разных записях, сравнил качество, покрутил настройки.
Главная особенность системы в том, что она обрабатывает до 60 минут аудио за один проход без нарезки на чанки. На выходе — структурированная транскрипция с указанием кто говорит, когда и что именно сказал. И всё это работает локально на вашем компьютере.
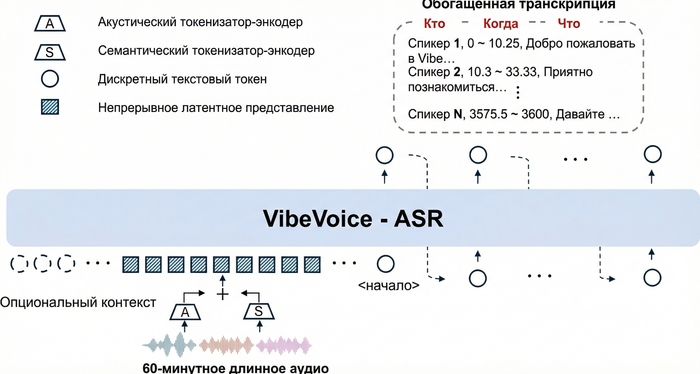
В основе VibeVoice-ASR лежит архитектура на базе Qwen 2.5 (~9 млрд параметров). Ключевая инновация — двойная система токенизации с ультранизким frame rate 7.5 Hz: акустический и семантический токенизаторы.
Такой подход позволяет модели работать с контекстным окном в 64K токенов — это и даёт возможность обрабатывать целый час аудио без потери контекста. Для сравнения: Whisper режет аудио на 30-секундные кусочки и теряет связность на границах сегментов.
На выходе модель генерирует Rich Transcription — структурированный поток с тремя компонентами:
[{"Start":0,"End":1.51,"Content":"[Environmental Sounds]"},
{"Start":1.51,"End":7.49,"Speaker":0,"Content":"У неё преждевременное сохранять невозможно, родила, начала сразу родильная деятельность."},
{"Start":7.51,"End":9.41,"Speaker":1,"Content":"Марина, что с ней?"},
{"Start":10.28,"End":16.22,"Speaker":0,"Content":"У неё преждевременное сохранять невозможно, отошли годы, начала, начала сразу родовая деятельность."},
{"Start":16.22,"End":18.02,"Speaker":1,"Content":"Марина, что с ней?"},
{"Start":18.13,"End":27.94,"Speaker":0,"Content":"Она рожает, привезли в ближайшую больницу родовую. В каком состоянии ребёнок ещё хуже, срок маленький."},
Помимо спикеров, модель размечает неречевые события: [Music], [Silence], [Noise], [Human Sounds] (смех, кашель), [Environmental Sounds], [Unintelligible Speech]. Это сделано чтобы модель не галлюцинировала текст во время пауз или фоновой музыки.
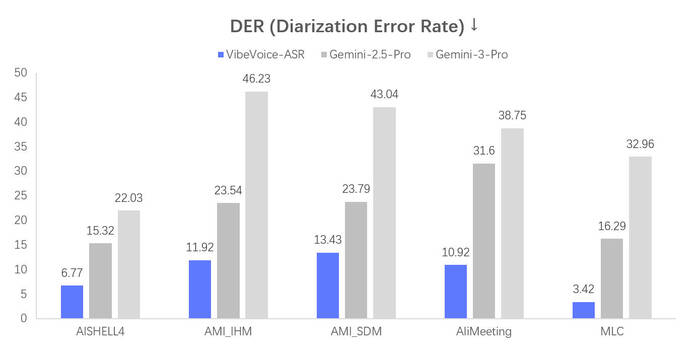
Меньше значит лучше
Обработка длинных записей: до 60 минут аудио за один проход без потери контекста. Идеально для митингов, подкастов, лекций.
Диаризация спикеров: автоматическое определение кто говорит в каждый момент времени. Работает на записях с несколькими участниками.
Временные метки: точные таймкоды для каждого сегмента речи. Готовый материал для субтитров.
Customized Hotwords: вот что меня реально зацепило — возможность задать пользовательский контекст. Перед распознаванием указываешь список слов: фамилии, названия продуктов, термины, сокращения. Всё то, что обычно произносится нестандартно и превращается в кашу. Если в видео часто звучит "ArtGeneration" или "НЕЙРО-СОФТ" — просто добавляешь в контекст, и модель ВСЕГДА распознаёт корректно. Для технического контента — просто спасение.
51 язык: включая русский, хотя основной фокус на английском и китайском.
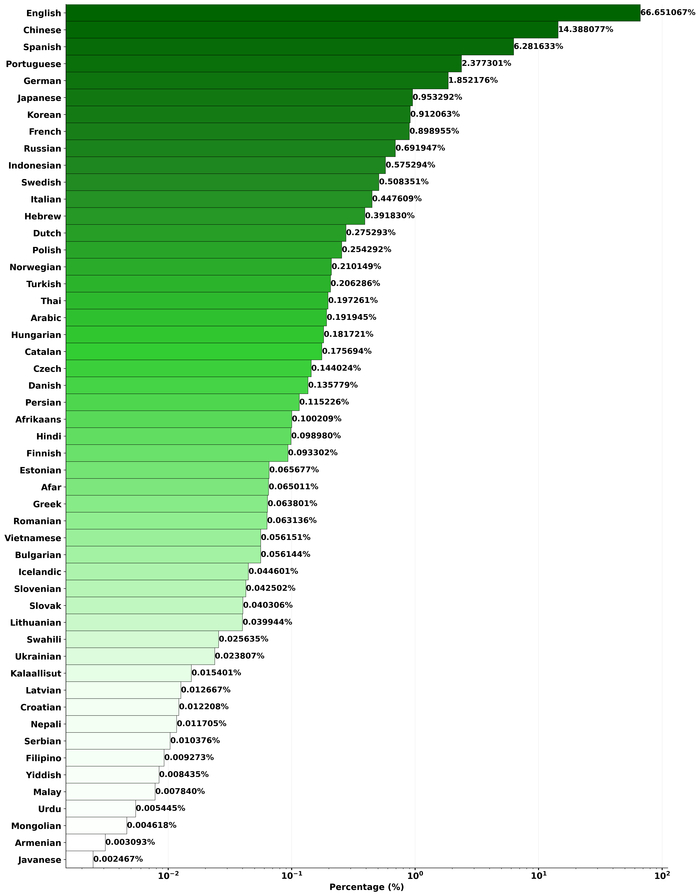
Набор языков отличный
Помимо оригинальной модели от Microsoft, сообщество уже сделало квантованные версии для видеокарт с меньшим объёмом памяти.
Полная модель — microsoft/VibeVoice-ASR Размер 17.3 GB, требует ~8 ГБ VRAM. Лучшее качество распознавания.
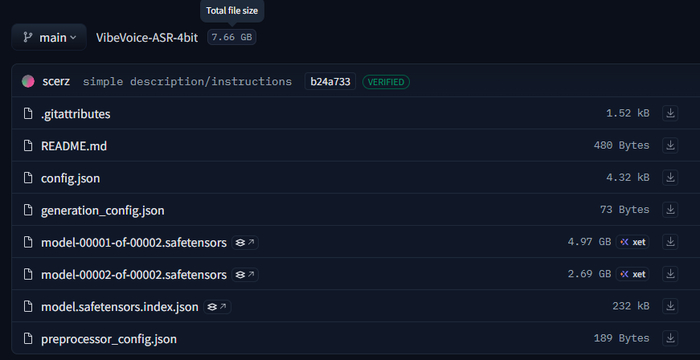
4-bit квантизация — scerz/VibeVoice-ASR-4bit Требует ~4 ГБ VRAM, немного медленнее. Подходит для видеокарт с меньшим объёмом памяти.
В моей портативке доступны обе версии — можно выбрать прямо в интерфейсе. Также есть эмуляция 4-bit квантизации для полной модели, если хотите попробовать оригинал, но памяти впритык.
К сожалению, не все задачи система решает одинаково хорошо:
Перекрывающаяся речь: если два человека говорят одновременно, модель не разделит их корректно.
Короткие фрагменты: диаризация плохо работает на высказываниях менее 1 секунды.
Только batch processing: нет real-time режима, только обработка готовых файлов.
Ресурсоёмкость: требует достаточно мощную видеокарту для комфортной работы.
Подкастерам и интервьюерам: автоматические субтитры с разделением спикеров. Загрузили часовой выпуск — получили готовую разметку.
Создателям контента: генерация SRT-субтитров для YouTube без ручного тайм-кодирования.
Бизнес-аналитикам: транскрипция часовых созвонов и совещаний с сохранением контекста и указанием кто что говорил.
Разработчикам: base model для файнтюнинга под специфичные домены — медицина, юриспруденция, техподдержка.
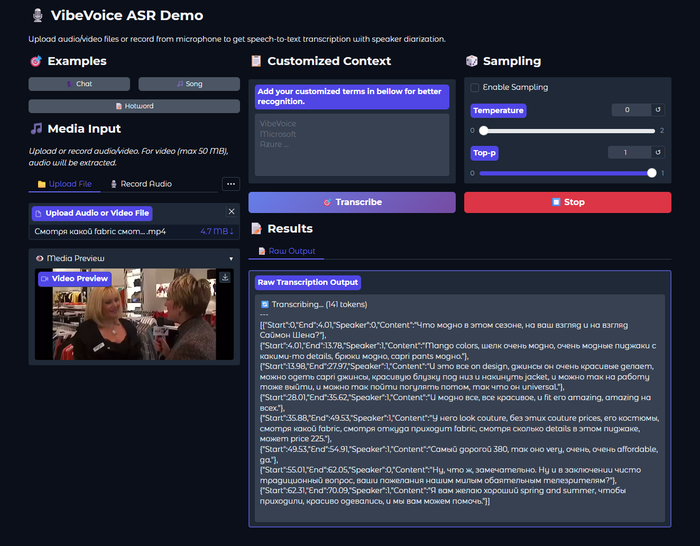
Почему-то не додумались сделать парсер json текста
Онлайн-демо: https://4e47b675ea4015a607.gradio.live/
Официальное демо от Microsoft — можно потестить прямо сейчас без установки.
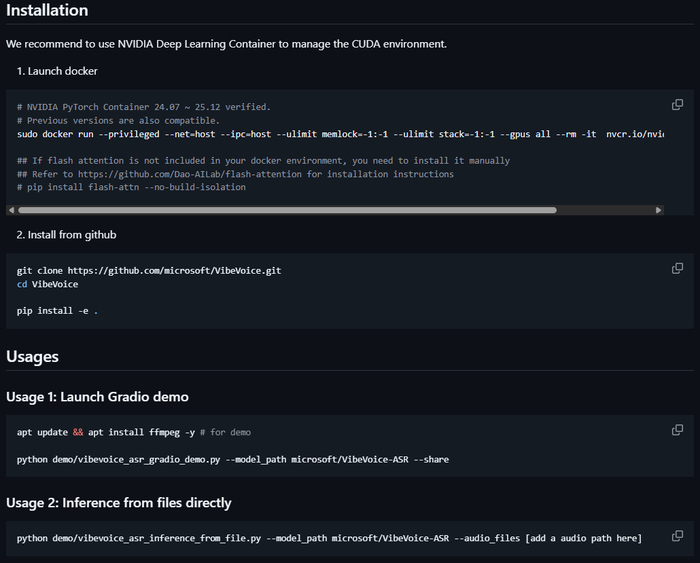
Как-то сложно
Официальный GitHub: https://github.com/microsoft/VibeVoice
HuggingFace модель: https://huggingface.co/microsoft/VibeVoice-ASR
Я с каналом Нейро-Софт подготовил портативную сборку VibeVoice ASR Portable RU. В ней:
Русифицированный интерфейс
Установка в один клик (install.bat)
Поддержка полной и 4-bit моделей
Парсер результатов с фильтрацией — можно отдельно включать/выключать временные метки, спикеров, дескрипторы (музыка, шум, тишина). Удобно когда нужен только чистый текст без разметки
Фильтр по спикерам — можно вывести текст только конкретного участника разговора
Выбор видеокарты и установка нужной версии CUDA
Flash Attention 2 для RTX 30xx/40xx/50xx
Поддержка всех форматов аудио и видео через FFmpeg
Тёмная тема интерфейса
Всё необходимое уже включено в дистрибутив, просто распакуйте и запускайте, есть версия с готовым окружением под win 11 и RTX4090. Забирайте архив тут.
Или установите с GitHub: https://github.com/timoncool/VibeVoice_ASR_portable_ru
NVIDIA GPU с 8+ ГБ видеопамяти (или 4+ ГБ для 4-bit модели)
Windows 10/11 64-bit
16 ГБ оперативной памяти
10 ГБ свободного места на диске
Распакуйте в любую папку (путь без кириллицы), запустите install.bat, выберите видеокарту из списка. Модели скачаются при первом запуске.
Рассказывайте в комментариях как вы могли бы использовать такой инструмент и чего не хватает.
Я рассказываю больше о нейросетях у себя на YouTube, в Телеграм и на Бусти. Буду рад вашей подписке и поддержке. На канал Нейро-Софт тоже подпишитесь, чтобы не пропустить полезные репаки. Всех обнял. Удачных транскрипций!
OpenAI совершает тихую революцию в разработке ПО: компания выпустила десктопное приложение Codex для macOS, превратив ИИ из помощника-одиночки в полноценную команду автономных агентов, которые могут параллельно писать код, тестировать его и даже проектировать интерфейсы, пока вы не спеша пьёте кофе, управляя их работой из центра управления.
Codex для Mac — запускайте несколько ИИ-агентов параллельно, создавайте навыки и настраивайте автоматизации в центре управления для агентного программирования.
Раньше ИИ-кодеры работали как стажёры: получали задачу, выполняли, ждали новой от вас. Теперь Codex управляет целой бригадой специалистов:
Один агент генерирует спрайты через GPT Image
Второй пишет игровую логику на JavaScript
Третий тестирует результат, играя в собственноручно собранную игру
Четвёртый деплоит сборку на Vercel
Всё это по одному промпту. В демонстрации от OpenAI система за несколько минут собрала гоночную игру в стиле Mario Kart: 8 треков, коллекция машин, система бонусов. При этом ИИ самостоятельно «примерил» роли дизайнера, разработчика и QA-инженера и даже протестировал геймплей, управляя машиной.
«Рабочие деревья» без конфликтов
Несколько агентов могут одновременно править один репозиторий, не ломая друг другу ветки. Каждый работает с изолированной копией кода, как будто у вас в команде трудятся дублёры, которые никогда не переписывают чужие коммиты.
Навыки (Skills) позволяют ИИ выходит за рамки только кодирования
Codex теперь умеет не только писать код, но и вытаскивать дизайн из Figma, заводить задачи в Linear, генерировать отчёты в PDF и Excel, деплоить в облака (Cloudflare, Vercel), собирать данные из веба.
Всё это упаковано в навыки (папки с инструкциями, скриптами и ресурсами для ИИ), которые можно вызывать по имени или позволить ИИ выбирать автоматически.
Автоматизации на автопилоте
Настройте рутинные задачи: приоритизацию и исправление ошибок, анализ логов, подготовку заметок к выпуску — и пусть Codex выполняет их по расписанию. Результат работы целой команды поступит к вам на проверку. Вам останется только проконтролировать его в удобное для вас время и управлять работой коллектива ваших ИИ-агентов.
Выбери характер ассистента
Хотите лаконичного исполнителя, который молча делает дело? Или общительного напарника, который объясняет каждый шаг? В Codex можно переключать «личность» агента командой /personality без потери функционала.
Агенты по умолчанию работают в песочнице: редактируют файлы только в указанной папке, используют кэшированный веб-поиск и спрашивают разрешения перед запуском команд с повышенными привилегиями (доступ к сети, системные вызовы).
На ограниченное время доступ к Codex открыт для пользователей тарифов ChatGPT Free и Go. Владельцы платных тарифов (Plus, Pro, Business, Enterprise и Edu) получают постоянный доступ с удвоенными лимитами запросов в честь запуска.
Codex перестал быть просто ИИ-агентом и превратился в центр управления для агентного программирования. Теперь разработчик это не тот, кто пишет код, а тот, кто управляет командой ИИ, ставя цели и принимая архитектурные решения. Эпоха «кодинга в одиночку» подходит к концу — добро пожаловать в эру цифровых коллективов.

Привет, это новый выпуск «Нейро-дайджеста» — коротких и полезных обзоров ключевых событий в мире искусственного интеллекта и технологий.
TL;DR Меня зовут Илья, я основатель сервиса для генерации изображений ArtGeneration.me, блогер и просто фанат нейросетей. Каждую неделю мы с командой осматриваем сотни новостей и делимся с вами самыми актуальными и интересными со ссылками на источники. Всё самое важное — в одном месте. Поехали!
Неделя выдалась насыщенной: куча мощнейших релизов из Китая, которые наступают на пятки GPT-5.2 и Gemini 3. Реалтайм инструменты от Krea и NVIDIA, генеративные модели от Qwen и Hunyuan, а Сэм Альтман честно признал, что OpenAI испортили тексты в последних версиях GPT.
🧠 Модели и LLM
Qwen3-Max-Thinking — китайцы снова впереди
Kimi K2.5 — самая мощная в опенсорсе
LongCat-Flash-Thinking-2601 — уровень GPT-5.2
ERNIE 5.0 — ещё один монстр от китайцев
🎨 Генеративные нейросети
Qwen 3 TTS — клон голоса по образцу
Odyssey 2 Pro — реалтайм видео
HunyuanImage 3.0-Instruct — MoE для редактирования картинок
HeartMuLa — открытый генератор музыки
🔧 AI-инструменты и платформы
Prism — инструмент с LaTeX-редактором для научных работ
PersonaPlex-7B — реалтайм ИИ-собеседник от NVIDIA
Krea Realtime Edit — редактирование в реалтайме
🧩 AI в обществе и исследованиях
Альтман признал, что в GPT-5.2 «сломали» стиль и качество текстов
Глава Google DeepMind: в Gemini не будет рекламы
Парень заменил друзей на ИИ, чтобы играть в Tarkov
Хаби Лейм продал себя за $975 млн

Alibaba выпустила Qwen3-Max-Thinking. В тестах на кодинг и науку модель выдает уровень GPT-5.2 и Claude 4.5, а в математике обходит Gemini 3 Pro.
Главная фишка — технология test-time scaling. Модель запускает параллельные рассуждения для решения сложных задач. Она сама решает, когда надо подключать поиск, память и интерпретатор кода.
Весов в открытом доступе нет — модель слишком огромная для домашнего запуска.
Попробовать уже можно бесплатно в Qwen Chat.
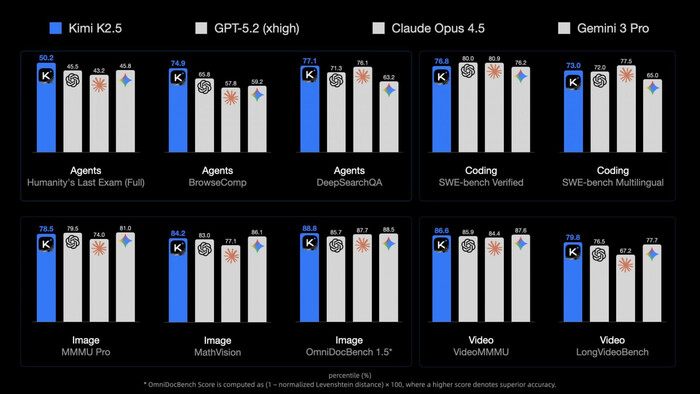
Китайцы из Moonshot AI выпустили Kimi K2.5 — самую мощную на сегодня нейросеть с открытыми весами. Модель мультимодальная, отлично справляется с кодом, особенно с фронтендом, анимацией и графикой, показывая уровень Claude Opus 4.5 и Gemini 3 Pro.
Главная фишка — «Agent Swarm»: нейросеть запускает до 100 субагентов одновременно, ускоряя выполнение сложных задач в 4,5 раза. Агенты создаются динамически, модель сама решает, как распределить работу. Kimi K2.5 может писать код по изображениям или видео — показываешь ей скриншот сайта, а модель воссоздает его.
Режимы Instant и Thinking в чате бесплатны, а «рой агентов» выйдет в $31 в месяц.

Стартап Meituan-LongCat выложили LongCat-Flash-Thinking-2601 — открытую MoE-модель на 560B параметров и 27B активных. В бенчмарках нейросеть идёт наравне с GPT-5.2 и Gemini 3 Pro, а в сложном тесте на математику AIME-25 достигла потолка в 100%.
Здесь тоже главный упор сделан на агентские навыки: работу с инструментами и поиск решений. Модель специально обучали в «зашумленных» средах с искажениями, поэтому она очень стабильна.
Для сверхзадач есть режим Heavy Thinking — в нём нейросеть параллельно ищет несколько путей решения, а затем итеративно их обобщает.
Ещё обновили шаблон чата: теперь он по умолчанию экономит контекст и позволяет опционально сохранять историю рассуждений.
🔗 Попробовать 🔗 GitHub 🔗 HuggingFace

Baidu выпустили ERNIE 5.0 — огромную омнимодальную модель на 2,4 триллиона параметров. Работает с текстом, изображениями, аудио и видео в единой архитектуре.
По бенчмаркам, ERNIE 5.0 идёт наравне с GPT-5 и Gemini 3 Pro. Можно выделить тест MMAU на понимание аудио, тут модель набрала 80 баллов против 70 у GPT-4o-Audio. В задачах с документами и графиками также опережает GPT-5, но пока уступает в кодинге.
Модель построена на архитектуре Mixture-of-Experts, при работе активируется менее 3% от всех параметров, что снижает затраты на вычисления.
Протестировать ERNIE 5.0 можно бесплатно в чат-боте, а API стоит $0,85 за 1 млн входных токенов — дешевле, чем у GPT-5.1.

Alibaba выложила в открытый доступ Qwen3-TTS — модель для синтеза речи, у которой есть две крутые фишки:
VoiceClone — клонирует любой голос всего за 3 секунды аудио. Поддерживается 10 языков, включая русский
VoiceDesign — создаёт абсолютно новый голос с нуля по текстовому описанию. Можно задать тембр, ритм, эмоции и даже характер
Модель обучена на 5 миллионах часов аудио, а задержка синтеза всего 97 мс, идеально для диалогов в реальном времени.
В некоторых тестах Qwen3-TTS превосходит ElevenLabs и GPT-4o-Audio. Веса моделей на 0.6B и 1.7B параметров открыты.
Команда Odyssey изначально целилась на Голливуд, а сейчас сменила курс и представила Odyssey 2 Pro. Теперь они двигают world-models и генерацию в реальном времени.
Главная фишка — скорость и интерактивность. Нейросеть генерирует видео с разрешением 720p и стабильными 22 кадрами в секунду. Ролик появляется почти мгновенно, и его можно тут же редактировать текстовыми командами.
Сами разработчики амбициозно называют это «GPT-2 моментом» для мировых моделей.
Odyssey уже открыли API. Обещают стабильные стримы, которые не упадут через 30 секунд. С таким инструментом можно организовать трансляцию, например, на Twitch, где сюжет меняется от голосования в чате.
🔗 Демо 🔗 Официальный блог
Tencent выпустили HunyuanImage 3.0-Instruct — MoE-модель для сложного редактирования изображений, 80B параметров и 13B активных.
Главная фишка — модель думает перед тем, как что-то сделать. Она использует схему Chain-of-Thought (CoT), чтобы проанализировать сложную инструкцию и выполнить её максимально точно.
Нейросеть умеет (добавлять, удалять или изменять элементы и объединять несколько картинок в одну, извлекая и смешивая элементы из разных источников.
Веса и код открыты. Есть«облегчённая» Distil-версия для потребительских ПК.
🔗 Демо 🔗 GitHub 🔗 Hugging Face
Появился HeartMuLa — бесплатный open-source сервис для генерации музыки, который сами разработчики у себя в репозитории успели окрестить «убийцей Suno». Это полноценная студия где можно генерировать треки по текстовому описанию.
Нейросеть создаёт треки с вокалом длиной более 4 минут, умеет писать тексты через встроенный чат-бот и копирует стиль из любого загруженного референса.
Главное преимущество — низкие требования к железу. Локальная версия требует всего 3 ГБ видеопамяти.
🔗 Попробовать 🔗 GitHub 🔗 Hugging Face
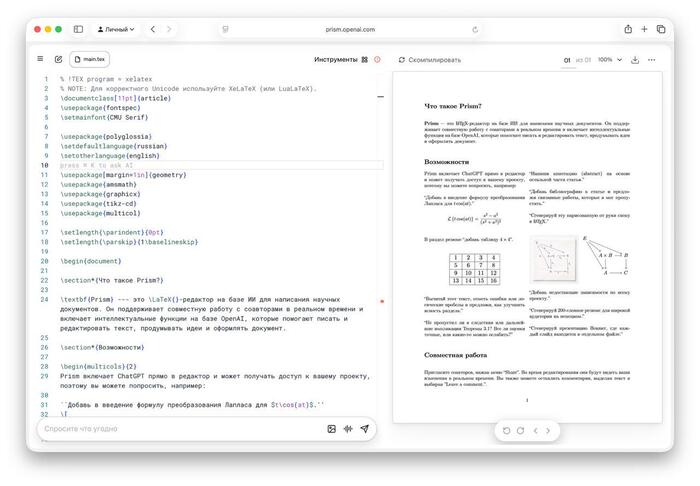
OpenAI представила Prism — облачный LaTeX-редактор с глубокой интеграцией GPT-5.2, который создан специально для студентов и учёных.
Prism видит весь проект, может проверить логику рассуждений, помочь с рефакторингом таблиц и формул, а также найти релевантную литературу или цитаты на arXiv.
Одна из фишек — Prism превращает рукописные наброски и формулы в идеальный LaTeX-код.
Есть и режим совместной работы. Пока инструмент доступен бесплатно для всех, у кого есть аккаунт ChatGPT.
NVIDIA выпустила PersonaPlex-7B — open-source модель, которая общается так же естественно, как человек, благодаря работе в режиме Full Duplex: она может одновременно слушать и говорить.
Нет неловких пауз для обработки запроса. Модель понимает перебивания, вставляет в разговор «угу» и «ага», пока вы говорите, и может принять на себя любую роль — от учителя до пирата. Для настройки достаточно текстового описания персонажа и короткого образца голоса.
Модель полностью открыта, её можно бесплатно использовать даже в коммерческих проектах.
🔗 GitHub 🔗 Hugging Face
Krea представила Realtime Edit — инструмент, который позволяет редактировать фото, видео и 3D-модели в реальном времени. Любые изменения в промпте отображаются почти мгновенно — с задержкой всего в 50 миллисекунд.
Нейросеть накладывает любую генерацию поверх вашего исходника. Интересное решение для дизайнеров и моделеров.

На встрече с разработчиками Сэм Альтман сделал каминг-аут: в GPT-5.2 компания запорола качество текстов. По его словам, команда сознательно сфокусировалась на интеллекте, кодинге и рассуждениях, но из-за «ограниченной пропускной способности» пренебрегла стилем.
«Я думаю, мы просто напортачили», — прямо сказал CEO OpenAI. Он пообещал, что в будущих версиях линейки 5.x это исправят, и модели будут писать «намного лучше, чем 4.5».
Кроме того, Альтман анонсировал, что к концу 2027 года OpenAI планирует сделать интеллект уровня GPT-5.2 как минимум в 100 раз дешевле, чем сейчас.
🔗 Запись

Глава Google DeepMind Дэмис Хассабис заявил, что у компании «нет никаких планов» добавлять рекламу в Gemini. Это стало прямым ответом на решение OpenAI, которая недавно анонсировала тестирование рекламы в ChatGPT.
По словам Хассабиса, персональный ИИ-ассистент строится на доверии, и пользователь должен быть уверен, что получает рекомендации для себя, а не в интересах рекламодателя.
«Интересно, что они пошли на это так рано. Может, им нужно больше выручки», — прокомментировал он решение OpenAI.
Впрочем, это не означает, что реклама в Gemini не появится никогда.
🔗 Источник

Геймер, с которым друзья не хотели играть в Escape from Tarkov, создал себе ИИ-напарника. Он дал боту доступ к своему экрану, и тот в реальном времени реагировал на геймплей.
ИИ-тиммейт не просто молчал: он подсказывал тактику, помогал с лутом и квестами, ориентировал по карте и комментировал ошибки, создавая эффект живого общения в Discord.
Эксперимент, который начинался как шутка, зашёл слишком далеко. Парень понял, что ему комфортнее играть с ботом, который всегда онлайн и готов помочь, чем с живыми людьми.
В итоге он испугался, насколько легко можно заменить реальное общение, и удалил бота.
🔗 Источник

Новость о том, что самый популярный тиктокер мира Хаби Лейм продал права на своё лицо почти за миллиард долларов, облетела весь интернет. Покупатель получил право в течение 3 лет использовать ИИ-аватар блогера для создания любого контента: от рекламы до стримов 24/7 на разных языках.
Но на самом деле всё сложнее. Хаби фактически вывел свой личный бренд на IPO: его компания слилась с гонконгским холдингом, и теперь акции его бренда можно купить на бирже NASDAQ. Это позволяет масштабировать его образ до бесконечности. Пока реальный Хаби отдыхает, его цифровой клон может работать, не уставая.
Это может быть началом конца для классического инфлюенс-маркетинга, где масс-маркет заберут неутомимые цифровые двойники.
🔗 Источник

28 января 1958 года Готфрид Кристиансен запатентовал систему, которая доказала: из простых модулей можно собрать абсолютно всё — от замка до работающего компьютера. Для гика LEGO стал первым «языком программирования» в физическом мире.
Это напоминает нам, что современный ИИ строится по тем же лекалам: гигантские языковые модели — это лишь колоссальные замки, собранные из миллиардов крошечных информационных кирпичиков.
Символично, что и в конструкторе, и в нейросетях единственным ограничением остается только фантазия того, кто держит детали в руках. Мы всё еще играем в кубики, просто теперь они состоят из чистого кода.
❯ Аудиоверсия дайджеста
❯ Заключение
Неделя получилась китайской: Alibaba, Moonshot и Baidu выкатили модели, которые уже дышат в спину флагманам. Пока Сэм Альтман признаётся, что они «запороли» качество текстов, самый популярный тиктокер мира продаёт своего ИИ-двойника почти за миллиард долларов.
Искусственный интеллект становится полноценным участником событий — собеседником, который не тупит, напарником по игре и даже цифровым двойником, который работает, пока мы спим.
Это стирает границы между реальным и виртуальным миром, меняя правила игры в медиа, развлечениях и даже в личном общении.
До встречи в следующем выпуске! А какая новость на этой неделе удивила вас больше всего? Пишите в комментарии!
Оставьте образец голоса, пожалуйста!
Звонков и голосовух родственникам и знакомым точно не будет!
Всем привет! Команда Qwen от Alibaba выложила в открытый доступ Qwen3-TTS — нейросетевую модель для синтеза речи с клонированием голоса. Сегодня хочу рассказать об этой технологии подробнее и поделиться портативной версией.
Меня зовут Илья, я основатель сервиса для генерации изображений ArtGeneration.me, блогер и просто фанат нейросетей. А еще я сам собрал портативную версию Qwen3-TTS под win11 и успел её как следует протестировать.
Главная особенность системы в том, что она умеет не только озвучивать текст готовыми голосами, но и клонировать любой голос по короткому образцу, а ещё создавать новые голоса по текстовому описанию.
И всё это с нативной поддержкой русского языка.
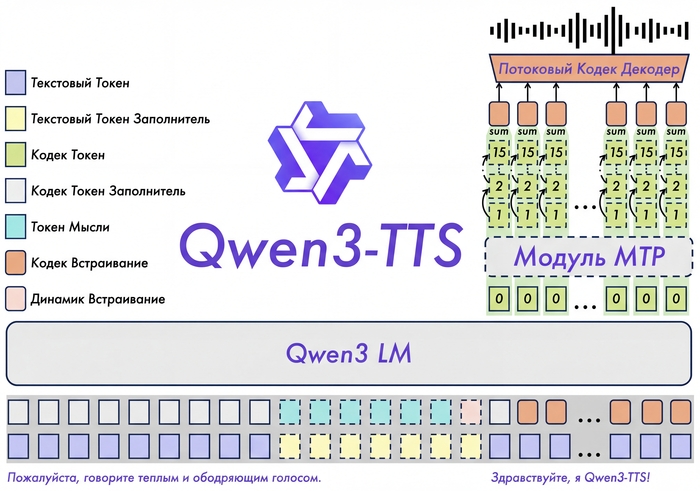
В основе Qwen3-TTS лежит End-to-End архитектура с дискретным многоканальным токенизатором речи (12.5 Гц, 16 слоёв). В отличие от традиционных систем, которые работают по цепочке "текст → фонемы → звук" и теряют информацию на каждом этапе, здесь всё обрабатывается одним махом.
Такой подход полностью исключает эффект "роботизированности" и каскадные ошибки генерации. Модель сохраняет интонации, эмоции и особенности тембра.
Работает очень быстро даже на старшей модели 1.7B.
Qwen3-TTS работает с 10 языками:
Китайский (включая пекинский и сычуаньский диалекты)
Английский
Японский
Корейский
Немецкий
Французский
Русский
Португальский
Испанский
Итальянский
Синтез с готовыми голосами (CustomVoice)
9 встроенных голосов разных типов — молодые и зрелые, мужские и женские. Можно управлять эмоциями и стилем речи через текстовые инструкции.
Создание голоса по описанию (VoiceDesign)
Описываете словами, какой голос нужен — модель его генерирует. Например: "молодой женский голос, игривый, с высоким тоном". Лучше работает если писать промпты на голос на английском.
Клонирование голоса (Voice Clone)
Загружаете аудио от 3 секунд — получаете синтез этим голосом. По бенчмаркам качество клонирования превосходит ElevenLabs и MiniMax по показателям сходства спикеров. Оно и правда веского качества, уровень VibeVoice, но гораздо легче по ресурсам.
Multi-Speaker режим
Создание диалогов и подкастов с несколькими спикерами одновременно (до 4 голосов).
Можно эмулировать разговор между друзьями, актерами, персонажами из игры, все теперь ограничивается только вашей фантазией.
Создателям контента — озвучка роликов, подкастов, стримов.
Разработчикам игр — озвучка персонажей без найма актёров, особенно актуально для инди.
Аудиокнигам — разные голоса для персонажей.
Автоматизации — голосовые уведомления, IVR-системы, ассистенты.
Онлайн-демо
Тут в демо меньше возможностей и нет локализации, но тоже отлично работает.
Hugging Face Demo — https://huggingface.co/spaces/Qwen/Qwen3-TTS
Официальный GitHub
Можно попробовать установить самостоятельность с гитхаб, но это потребует опыта и навыков.
API
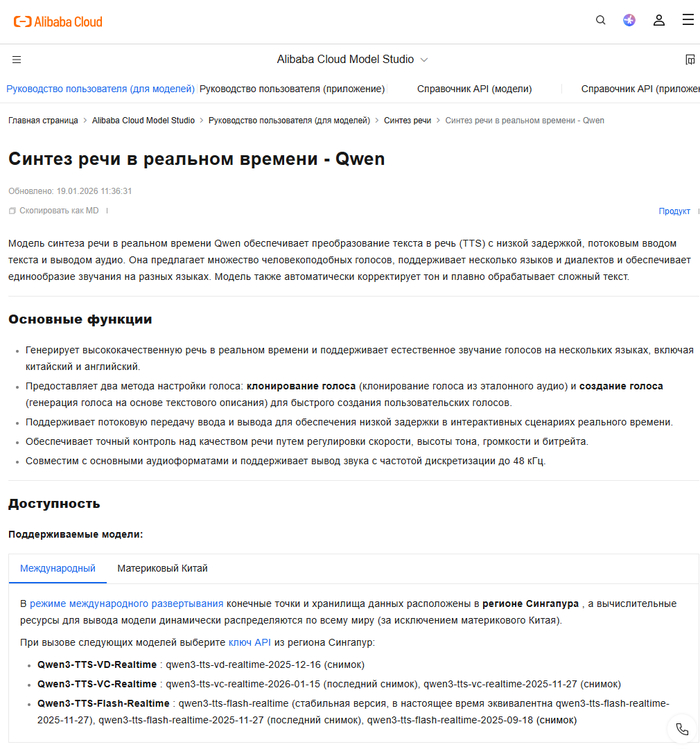
Официальное API от Alibaba для production-интеграции.
Я с каналом Нейро-Софт подготовил улучшенную портативную сборку Qwen3-TTS Portable PRO, видео выше как раз из неё и записаны. А еще там:
Русифицированный интерфейс
Установка в один клик (install.bat)
50+ готовых голосов в комплекте
700+ дополнительных голосов для скачивания из интерфейса
Multi-Speaker режим до 4 спикеров
Поддержка NVIDIA GPU и CPU
NVIDIA GPU с 8+ ГБ видеопамяти (или CPU, но медленнее)
Windows 10/11 64-bit
16 ГБ оперативной памяти
20 ГБ свободного места на диске
Ударения иногда расставляются неправильно
С длинными текстами могут быть проблемы
Инструкции для VoiceDesign лучше писать на английском
Распакуйте в корень диска (путь без кириллицы), запустите install.bat. Модели скачаются при первом запуске. А если будут сложности в установкой в посте в канале найдете версию с уже установленным env (окружением).
Я рассказываю больше о нейросетях у себя на YouTube, в телеграм и на Бусти. Буду рад вашей подписке и поддержке. Ну и на канал Нейро-Софт тоже подпишитесь, чтобы не пропустить полезные репаки. Всех обнял и удачных генераций!


