0 просмотренных постов скрыто


Ответ на пост «Говорилка Qwen3-TTS с поддержкой русского языка. Бесплатная нейросеть озвучит что угодно вашим голосом + портативная версия»2
Оставьте образец голоса, пожалуйста!
Звонков и голосовух родственникам и знакомым точно не будет!

Говорилка Qwen3-TTS с поддержкой русского языка. Бесплатная нейросеть озвучит что угодно вашим голосом + портативная версия2
Всем привет! Команда Qwen от Alibaba выложила в открытый доступ Qwen3-TTS — нейросетевую модель для синтеза речи с клонированием голоса. Сегодня хочу рассказать об этой технологии подробнее и поделиться портативной версией.
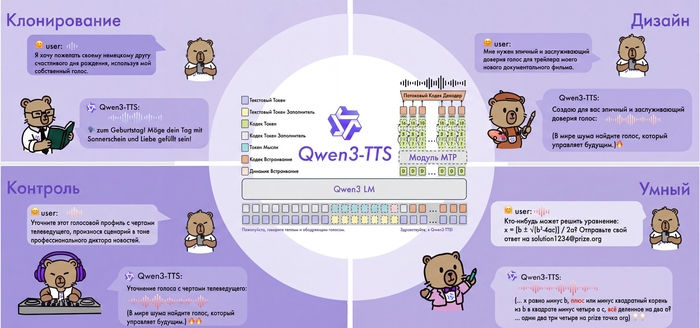
Меня зовут Илья, я основатель сервиса для генерации изображений ArtGeneration.me, блогер и просто фанат нейросетей. А еще я сам собрал портативную версию Qwen3-TTS под win11 и успел её как следует протестировать.
Главная особенность системы в том, что она умеет не только озвучивать текст готовыми голосами, но и клонировать любой голос по короткому образцу, а ещё создавать новые голоса по текстовому описанию.
И всё это с нативной поддержкой русского языка.
Как это работает
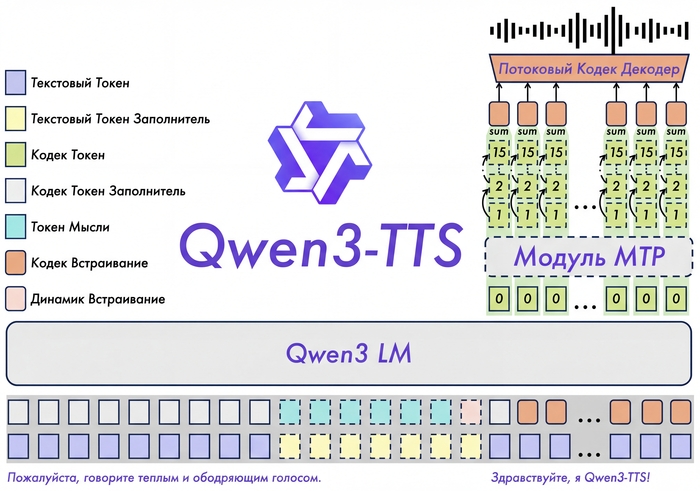
В основе Qwen3-TTS лежит End-to-End архитектура с дискретным многоканальным токенизатором речи (12.5 Гц, 16 слоёв). В отличие от традиционных систем, которые работают по цепочке "текст → фонемы → звук" и теряют информацию на каждом этапе, здесь всё обрабатывается одним махом.
Такой подход полностью исключает эффект "роботизированности" и каскадные ошибки генерации. Модель сохраняет интонации, эмоции и особенности тембра.
Работает очень быстро даже на старшей модели 1.7B.
Поддерживаемые языки
Qwen3-TTS работает с 10 языками:
Китайский (включая пекинский и сычуаньский диалекты)
Английский
Японский
Корейский
Немецкий
Французский
Русский
Португальский
Испанский
Итальянский
Возможности
Синтез с готовыми голосами (CustomVoice)
9 встроенных голосов разных типов — молодые и зрелые, мужские и женские. Можно управлять эмоциями и стилем речи через текстовые инструкции.
Создание голоса по описанию (VoiceDesign)
Описываете словами, какой голос нужен — модель его генерирует. Например: "молодой женский голос, игривый, с высоким тоном". Лучше работает если писать промпты на голос на английском.
Клонирование голоса (Voice Clone)
Загружаете аудио от 3 секунд — получаете синтез этим голосом. По бенчмаркам качество клонирования превосходит ElevenLabs и MiniMax по показателям сходства спикеров. Оно и правда веского качества, уровень VibeVoice, но гораздо легче по ресурсам.
Multi-Speaker режим
Создание диалогов и подкастов с несколькими спикерами одновременно (до 4 голосов).
Можно эмулировать разговор между друзьями, актерами, персонажами из игры, все теперь ограничивается только вашей фантазией.
Кому пригодится
Создателям контента — озвучка роликов, подкастов, стримов.
Разработчикам игр — озвучка персонажей без найма актёров, особенно актуально для инди.
Аудиокнигам — разные голоса для персонажей.
Автоматизации — голосовые уведомления, IVR-системы, ассистенты.
Как попробовать
Онлайн-демо
Тут в демо меньше возможностей и нет локализации, но тоже отлично работает.
Hugging Face Demo — https://huggingface.co/spaces/Qwen/Qwen3-TTS
Официальный GitHub
Можно попробовать установить самостоятельность с гитхаб, но это потребует опыта и навыков.
API
Официальное API от Alibaba для production-интеграции.
Портативная версия
Я с каналом Нейро-Софт подготовил улучшенную портативную сборку Qwen3-TTS Portable PRO, видео выше как раз из неё и записаны. А еще там:
Русифицированный интерфейс
Установка в один клик (install.bat)
50+ готовых голосов в комплекте
700+ дополнительных голосов для скачивания из интерфейса
Multi-Speaker режим до 4 спикеров
Поддержка NVIDIA GPU и CPU
Системные требования
NVIDIA GPU с 8+ ГБ видеопамяти (или CPU, но медленнее)
Windows 10/11 64-bit
16 ГБ оперативной памяти
20 ГБ свободного места на диске
Текущие ограничения
Ударения иногда расставляются неправильно
С длинными текстами могут быть проблемы
Инструкции для VoiceDesign лучше писать на английском
Распакуйте в корень диска (путь без кириллицы), запустите install.bat. Модели скачаются при первом запуске. А если будут сложности в установкой в посте в канале найдете версию с уже установленным env (окружением).
Я рассказываю больше о нейросетях у себя на YouTube, в телеграм и на Бусти. Буду рад вашей подписке и поддержке. Ну и на канал Нейро-Софт тоже подпишитесь, чтобы не пропустить полезные репаки. Всех обнял и удачных генераций!
Показать полностью
2
7
Ответ на пост «Почему досих пор нет ИИ для озвучивания книг? (И я не про монотонный синтез речи)»1
Простите, @Kreinto, @B0MBAstic, но мне кажется это получилось как минимум забавно ;)
Сервис для озвучки текста: https://aistudio.google.com/generate-speech

Почему досих пор нет ИИ для озвучивания книг? (И я не про монотонный синтез речи)1
С появлением ИИ как грибы после дождя начали появляться всякие сервисы, порой бесполезные, но делающие довольно сложные вещи - апогеем на данный момент можно считать генерацию видео.
Так почему же досих пор ученые и программисты, работающие в сфере разработки нейросетей досих пор не скормили существующие озвучки и сами эти книги нейросетям, не научили интонации и "пониманию" смысла текста для корректной интонации?

Лучшие открытые модели ИИ для синтеза русской речи на домашнем ПК
Сегодня, благодаря открытым (open-source) моделям искусственного интеллекта, любой желающий может «научить» свой компьютер говорить — причём на чистом русском языке и без необходимости арендовать дорогие серверы. Мечтаете озвучивать видео, создавать аудиокниги или просто экспериментировать с голосовыми технологиями? В этой статье рассмотрим варианты.
Нагуглил по этой теме кое-какие новинки (или не совсем новинки) в мире Text-to-Speech (TTS) и отобрал модели, которые можно запустить локально даже на бюджетной видеокарте. Главные критерии отбора: высокое качество синтеза, поддержка русского языка и скромные системные требования.
Герои локального синтеза речи
Забудьте о роботизированных голосах из прошлого. Современные нейросети способны генерировать речь, неотличимую(почти) от человеческой. Вот четыре открытые модели, на которые стоит обратить внимание в 2025 году.
1. Piper TTS: Чемпион по эффективности
Если вы ищете максимально быстрый и нетребовательный к ресурсам вариант, Piper TTS — ваш выбор. Эта модель оптимизирована до такой степени, что отлично работает даже на CPU или на одноплатных компьютерах вроде Raspberry Pi, что делает её абсолютным чемпионом по эффективности.
Русский язык: Piper предлагает несколько готовых русскоязычных голосов, которые сообщество высоко оценивает за естественность и приятное звучание.
Что с железом? Piper — самая «лёгкая» модель в нашем списке. Ей требуется менее 3 ГБ видеопамяти (VRAM), а это значит, что она без проблем запустится практически на любой видеокарте, выпущенной за последние несколько лет.
Идеально для: Быстрой озвучки текстов, использования в проектах для слабого оборудования, голосовых ассистентов.
2. Silero TTS: Простота и качество
Модели от Silero давно зарекомендовали себя как простой и качественный инструмент для синтеза речи. Разработчики изначально уделили большое внимание поддержке русского языка, что делает их одними из лучших для русскоязычных пользователей.
Русский язык: Silero предлагает несколько высококачественных моделей и голосов, специально обученных на огромных массивах русских текстов. Качество произношения и интонаций — на высоте.
Что с железом? Модели Silero очень эффективны. Хотя для сопутствующих ИИ-задач может потребоваться больше ресурсов, сама по себе TTS-модель комфортно себя чувствует на видеокартах с 6 ГБ VRAM, а часто может работать и на более скромных конфигурациях.
Идеально для: Стабильных и качественных результатов, интеграции в различные приложения благодаря простому API.
3. Coqui TTS (модель XTTS-v2): Мастер клонирования голоса
Хотите, чтобы нейросеть заговорила вашим голосом? Coqui TTS и её флагманская модель XTTS-v2 делают это возможным. Главная «фишка» этой модели — способность к «клонированию голоса» (voice cloning) всего по 5-10 секундам аудиозаписи.
Русский язык: XTTS-v2 является многоязычной моделью и хорошо справляется с синтезом русской речи, сохраняя при этом тембр и интонации исходного голоса.
Что с железом? Клонирование голоса требует ресурсов. Для комфортной работы понадобится видеокарта с минимум 4-6 ГБ VRAM, при этом пиковое потребление при генерации длинных фраз может достигать 10 ГБ. К счастью, существуют способы оптимизации, позволяющие переносить часть нагрузки на оперативную память (RAM).
Идеально для: Создания уникальных голосов, озвучки персонажей, персонализированных проектов.
4. Bark: Творческий генератор звуков
Bark от лаборатории Suno — это не просто TTS-модель, а полноценный генератор аудио. Она умеет не только говорить, но и добавлять в речь невербальные звуки: смех, вздохи, плач и даже пение или фоновую музыку. Это открывает невероятный простор для творчества.
Русский язык: Bark поддерживает русский и позволяет генерировать речь с высокой степенью эмоциональной выразительности.
Что с железом? Это самая требовательная модель в нашем списке. Полная версия потребует около 12 ГБ VRAM. Однако разработчики предлагают и облегчённые варианты, которые могут уместиться в 8 ГБ, а с определёнными настройками и оптимизациями энтузиасты умудряются запускать её даже на картах с 2-4 ГБ VRAM.
Идеально для: Экспериментов со звуком. Мне не удалось избавиться от шумов и каких-то бульканий при генерации диалогов. Пробовал, на урезанной версии и полной при запуске на CPU - голоса прикольные, но шум очень сильный для озвучивания книг, вероятно не подойдет. Если кто знает как убрать шумы в этой модели поделитесь. Она может хихикать и по описанию даже добавлять музыку. Но неточно следует инструкциям и часто проглатывает эти описания.
Как выбрать модель под свою задачу?
Для новичка или владельца слабого ПК: Начинайте с Piper TTS. Вы получите отличные результаты без головной боли с настройками и требованиями.
Нужен стабильно качественный русский голос: Silero TTS — ваш надёжный выбор.
Хотите создать уникальный голос или озвучить что-то своим тембром: Готовьтесь осваивать Coqui TTS.
Для творческих экспериментов и озвучки с эмоциями: Если у вас мощная видеокарта, попробуйте Bark.
Будущее уже здесь
Развитие открытых моделей синтеза речи идёт семимильными шагами. Инструменты, которые ещё пару лет назад были сложными и доступными лишь единицам, сегодня может запустить любой энтузиаст. Локальный синтез речи — это не только увлекательное хобби, но и шаг к большей приватности и независимости от облачных сервисов. Попробуйте сами — ваш компьютер способен на большее, чем вы думаете!
Напишите, какие модели используете локально. Может я упустил что-то хорошее.
Показать полностью


Помогите с выбором синтезатора речи
Здравствуйте, возможно есть какие то сборки включающие в себя синтезатор и набор лучших голосов для озвучивания txt и fb2 книг? Море книг без озвучки но очень хороших.
Проблема в телефоне без плеймаркета и поддержки гугла, многие синтезаторы как я понял, завязаны на гугл и тд и нормально не работают через Gbox.
Телефон honor 30s
По возможности, бесплатный вариант

Три бесплатных портативных нейросети для работы со звуком | MM-Audio, Fish Speech, LatentSync
🎵 Друзья, вы готовы к настоящей революции в мире аудио? В этом видео я покажу вам три невероятные нейросети, которые перевернут ваше представление о работе со звуком! MM-Audio создаст потрясающие звуковые эффекты для ваших видео и игр всего за пару кликов, Fish Speech поразит вас качеством клонирования голоса по минутному образцу, а LatentSync идеально синхронизирует сгенерированную речь с любым видео.
Я покажу все хитрости настройки, поделюсь личным опытом и научу пользоваться каждым инструментом. А самое крутое - все они доступны в удобных портативных версиях! 🚀
Альтернативный плеер YouTube:
Ссылки из видео:
🎨 MM-Audio - генерация звуков
Скачать портативную версию: https://t.me/neuroport/119
Исходный код: https://github.com/hkchengrex/MMAudio
Онлайн демо: https://huggingface.co/spaces/hkchengrex/MMAudio
🗣️ Fish Speech - клонирование голоса
Скачать портативную версию: https://t.me/neuroport/134
Исходный код: https://github.com/fishaudio/fish-speech
Онлайн демо: https://huggingface.co/spaces/fishaudio/fish-speech-1
🎬 LatentSync - синхронизация губ
Скачать портативную версию: https://t.me/neuroport/129
Исходный код: https://github.com/bytedance/LatentSync
Онлайн демо: https://huggingface.co/spaces/fffiloni/LatentSync
🛠️ Полезные инструменты:
Whisper для транскрибации: http://github.com/Const-me/Whisper
Ultimate Vocal Remover: https://github.com/Anjok07/ultimatevocalremovergui
Audacity для редактирования: https://www.audacityteam.org
База голосов для TTS: https://t.me/neuroportchat/6633
📱 Мои ссылки:
Поддержать донатом: https://www.donationalerts.com/r/nerual_dreming
Основной Telegram: https://t.me/neuro_art0
Эксклюзивы на Boosty: https://boosty.to/neuro_art
Курс по нейросетям: https://fooocus.ru
Клуб "Нейро-музыка": https://neuromusic.club
Все Telegram каналы: https://t.me/addlist/LQ-fUTyhVjEzYjIy
Буду рад вашей подписке и поддержке. Всех обнял и удачных генераций.
Показать полностью
1