Alibaba выкатила третье поколение своего генератора изображений — Qwen-Image-3.0 — и сменила саму цель проекта. Если версия 2.0 гналась за эстетикой, то девиз новой коротко — «Real»: не «красивый арт ради арта», а практичные, информационно-плотные штуки — инфографика, макеты интерфейсов, экзаменационные листы, газетные полосы, сториборды.
Удар по вечной слабости генераторов. Читаемый текст и сложная вёрстка — то, на чём десятилетиями спотыкались все text-to-image модели. Qwen-Image-3.0 принимает промпт длиной до 4500 токенов, рендерит разборчивый шрифт размером от 10 пикселей, нативно поддерживает 12 языков (включая японский, корейский, испанский) и 20+ гарнитур и собирает многослойную вёрстку за один проход — вплоть до многострочных формул LaTeX с индексами, дробями и суммами.
Витрина релиза. Центральный пример — сетка 3×3 из девяти совершенно НЕ связанных инфографик: диаграмма по физике, доказательство из теории групп, объяснение по биологии и ещё шесть панелей. Всё это, как утверждает Alibaba, сгенерировано из одной инструкции на ~3700 токенов, а не собрано из отдельных картинок. Модель также умеет реставрировать повреждённые арты, повторяя оригинальный мазок, и превращать фото в «карточки-определители» с подписями и увеличенными фрагментами.
Где подвох. Во-первых, публичных бенчмарков 3.0 пока нет — прошлая, 2.0, в собственной арене Alibaba шла сразу за GPT-Image-2 и Google Nano Banana Pro. Во-вторых, в этот раз веса, судя по всему, не выложат в открытый доступ — в отличие от первой Qwen-Image, которая и прославилась опенсорсом. Доступ пока только по инвайтам через API, интеграцию в Qwen Chat обещают в ближайшее время.
Для ЛЛ: длиннопост про футбол и ИИ ставки, если такое не интересно - скипай.
Только что закончился чемпионат мира по футболу 2026. Я болел за Испанию и немножко за Аргентину, и они заняли первое и второе места, так что я остался доволен турниром. Пост однако не об этом.
Где-то с середины группового этапа я ради развлечения проводил эксперимент - делал виртуальные ставки по рекоммендациям нейросетей. Я сначала использовал бесплатные Grok и Deepseek, позже к ним добавился Qwen. Ближе к плей-офф у меня разогрелся азарт и я начал делать реальные ставки у букмекера. Я закинул 8к рублей на депозит, такую сумму мне было не жалко потерять.
У меня не было какой-то особой начальной стратегии. Я просто давал каждой модели букмекерские коэффициенты на исходы матчей (1/X/2/1X/12/X2) и иногда коэффициенты на тоталы и голы, если это было релевантно. Далее я просил их сделать прогнозы как на одиночные матчи, так и составить экспрессы, то есть ставки сразу на несколько матчей с перемножением коэффициентов. Каждой модели был выдан виртуальный депозит отдельно по 10к рублей на одиночные ставки и экспрессы.
Сам я не большой фанат футбола, смотрю может раз в два года крупные турниры. Букмекерскими ставками я тоже не увлекаюсь. Так что я был довольно неподготовлен к такому эксперимаенту со своей стороны. Тем не менее я не был пассивным наблюдателем и активно обсуждал с искусственным разумом стратегии и итоги ставок. По ходу разговоров с моделями и набора опыта я корректировал стратегии. Я думаю, во многом их ставки сделаны под моим влиянием, т.к. у LLM есть склонность "лебезить" перед пользователем.
Как бы то ни было, заканчиваю затянувшееся вступление. Перед результатми нужно сказать, что Grok не дошёл до конца эксперимента, т.к. стал сильно путаться в контексте и тупить.
Результаты одиночных ставок:
Результаты одиночных ставок.
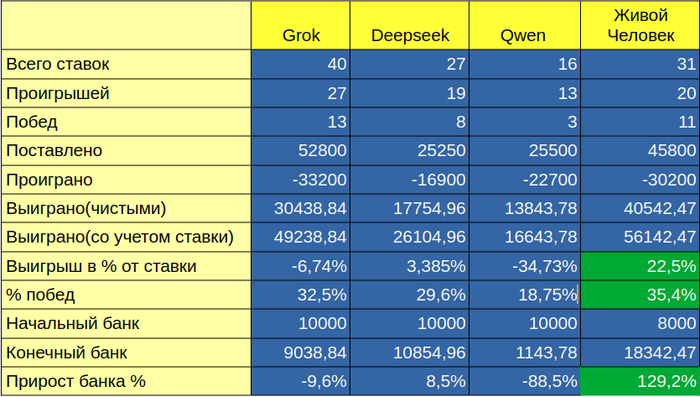
У Grok больше всего ставок, потому что он делал одиночные ставки без напоминания. У Qwen меньше всего, потому что он позже вошел в игру. Все 3 модели не слили депозит, а показали вполне достойный результат. Лучше всех прогнозировал Qwen, а больше всех выиграл Deepseek, но это за счет большего количества ставок.
Реузльтаты экспресс ставок (помимо нейросетевых моделей в эксперименте поучавствовал и живой я реальными ставками у букмекера):
Реузльтаты экспресс ставок
Как видим, Qwen почти слил депозит, Deepseek ушел в небольшой плюс, Grok ушел в небольшой минус, а живой человек всех переиграл и уничтожил.
Не могу сказать, что результаты оказались неожиданными просто потому, что у меня не было никаких ожиданий. Так или иначе, давайте подведем некоторые итоги эксперимента. Сначала наблюдения про поведение моделей:
Grok. Очень неприятно удивил. По взаимодействию с пользователем - это самая слабая модель. Постоянно забывает контекст, путается в очередности команд, не следует указаниям. Он постоянно предлагал очень неразумные варианты типа ОЗ в матче Шотландия-Бразилия. До конца эксперимента он не дотянул, т.к. слишком уж сильно стал тупить. Когда Grok только появился, он по ощущениям был сильнее и Deepseek и ChatGPT, а сейчас натуральный идиот. Я думаю бесплатную версию сознательно дибилизировали, чтобы подтолкнуть пользователей к платной подписке. После этого опыта я полностью перестал пользоваться Grok для серьезных запросов.
Deepseek. Это единственный ИИ, который использовал активный внешний поиск и он знал, что искать. Он узнавал детали предстоящих матчей, например какие игроки травмированы и какие дисквалифицированы, а также ссылался на прогнозы суперкомпьютера Opta. Также Deepseek лучше всех помнит контекст и почти не путается. Это единственная модель сыгравшая в плюс в экспрессах.
Qwen. Самая противоречивая модель. Он показал хороший результат в одиночных ставках, но слил депозит в экспрессах(возможно это я слишком подстрекал его к рисковым ставкам). Qwen в отличии от остальных дал ценные советы как беттер вне футбольного контекста. Например он посоветовал не ставить на суперфаворита(как в матче Аргентина-Кабо Верде) в несколькольких экспрессах подряд, это сохранило много денег. Также он больше опирася на тоталы и голы нежели чем на результат матча. Большинство событий в моих собственных ставках я взял от Qwen.
Пожалуй главное наблюдение эксперимента - ИИ модели не способны к качественным букмекерским прогнозам без участия живого человека. Человек при этом должен быть вовлечен в процесс на достаточно высоком уровне. То есть просто скормить модели список игр и коэффициентов из какого-нибудь кубка Румынии и ожидать успешных результатов не получится. То, что я обыграл по доходам ИИ модели, прекрасный тому пример. Это касается не только тех моделей, что я тестировал. Например суперкомпьютер Opta давал 57/43 в пользу Франции против Испании. (Букмекеры, похоже, строят свои коэффициенты на таких моделях, а не прогнозах живых аналитиков). Я не бог весть какой эксперт в футболе, но посмотрев по одной игре каждой команды, я отмел варианты с победой Франции, т.к. для меня было очевидно, что Испания сильнее. И например я также отмел варианты с победой Бразилии над Норвегией.
На этом пожалуй закончу этот пост. Я несомненно и дальше продолжу эксперименты с дуругими турнирами и видами спорта. Если кому-нибудь будет интересно, то могу выложить таблицу ставок или расшарить разговоры с моделями.
Alibaba выкатила превью Qwen3.8-Max — свою самую крупную модель на 2.4 триллиона параметров (разреженная архитектура Mixture-of-Experts) и первую в линейке Qwen мультимодалку крупнее триллиона: она работает с текстом, картинками, видео и документами. Разработчик Shuai Bai подчеркнул, что это «первая мультимодальная модель команды с более чем 1 трлн параметров». И тут же, в посте на X, команда Qwen заявила: модель «на уровне фронтир-моделей и уступает только Claude Fable 5».
Заявка громкая — доказательств ноль. Ни одного бенчмарка, ни model card, ни числа активных параметров MoE, ни единой независимой проверки. Для контраста: предыдущий Qwen3.7-Max в мае выходил с конкретной цифрой — 56.6 на Artificial Analysis Intelligence Index. Новый флагман приехал с пустой витриной и обещанием «скоро».
Контекст важнее самой заявки. Это очередной залп в гонке Китая за триллионы параметров. Всего тремя днями ранее Moonshot выложила опенвейтную Kimi K3 на 2.8 трлн — и уже собрала $300 млн годовой выручки, планируя IPO в течение полугода. Qwen отвечает своим гигантом, но открытые веса пока лишь «на подходе»: сейчас доступ только через превью (Token Plan, Qoder, QoderWork) за 10% от обычной цены.
Итог. Пока Qwen 3.8 — это флекс числом параметров и красивой вау-заявкой, а не измеренный результат. Реальную позицию модели покажут только открытые веса и независимые тесты, которых ещё нет.
Полтора года «умный» айфон в Китае оставался просто айфоном: функции Apple Intelligence, доступные всему миру с 2024-го, для крупнейшего зарубежного рынка компании были заблокированы. Теперь барьер снят — но ценой, которую в Вашингтоне называют почти капитуляцией, а в Купертино — единственно возможной сделкой.
Что произошло. Китайский киберрегулятор — Управление киберпространства Китая (CAC) — включил сервисы Apple Intelligence в список одобренных ИИ-провайдеров, рядом с продуктами местных гигантов вроде Huawei. Это сняло главный регуляторный барьер, тормозивший запуск «умного» айфона в Китае с самого анонса платформы в 2024 году. По данным Reuters, обновлённая Siri и функции генерации текста и изображений на китайских iPhone, iPad, Mac и Vision Pro будут работать на модели Qwen от Alibaba; отдельные функции помогает делать Baidu.
Почему не своя модель. В Китае действует жёсткое правило: генеративный ИИ обязан крутиться на одобренной локальной модели и проходить контентную проверку CAC. Западный ИИ — включая тот же ChatGPT, что питает Siri в остальном мире, — там попросту запрещён. Поэтому у Apple был выбор: либо партнёрство с китайской моделью и работа по правилам местной цензуры, либо остаться в своём втором по величине рынке без флагманских ИИ-функций. Компания выбрала сделку.
Рынок ликует. Инвесторы отреагировали мгновенно: американские акции Alibaba подскочили примерно на 4% (на пике — до 6% внутри дня), бумаги Apple прибавили около 1,8%, а Baidu — порядка 2,8%. Для Alibaba это громкая витрина: её открытая модель Qwen теперь стоит за ИИ на сотнях миллионов устройств Apple в Китае.
А вот Вашингтон в ярости. Ещё в мае 2025-го, когда о переговорах только пошли слухи, Белый дом и профильный комитет Конгресса по Китаю вызывали руководство Apple на разговор — и, по данным источников, внятных ответов не получили. Конгрессмен Раджа Кришнамурти прямо назвал Alibaba «витриной стратегии военно-гражданского слияния Компартии Китая». Претензии США: сделка помогает китайскому ИИ становиться сильнее, делает Apple уязвимой к местным законам о цензуре и передаче данных, а главное — создаёт «опасный прецедент», за которым в Китай могут потянуться и другие американские техгиганты. И всё это — ровно в тот момент, когда администрация давит на Пекин экспортными ограничениями на топовые ИИ-чипы. По сообщениям СМИ, Дональд Трамп этой связки Apple с Alibaba категорически «не хочет».
Итог. Apple выбрала рынок, а не геополитику. Для Тима Кука Китай — это и продажи, и производство, терять которые ради принципа компания не готова. Но каждый такой компромисс всё сильнее сталкивает интересы бизнеса с курсом Вашингтона на технологический развод с Китаем — и история Apple Intelligence в Поднебесной может ещё аукнуться в самих США.
В прошлом месяце администрация Трампа временно вводила экспортный контроль на топовые ИИ-модели Anthropic — Fable и Mythos. Цель была защитить американское технологическое лидерство. Эффект получился обратным: западный бизнес начал массово переходить на китайские нейросети, пишет Financial Times.
Запрет вскоре отменили, но было поздно. "Fable можно вернуть на рынок, но джинна обратно в бутылку не загонишь", — говорит Бен Гриннелл, директор по ИИ британской консалтинговой компании Newton. Европейский бизнес впервые всерьез ощутил, чем грозит зависимость от американских технологий.
Переходят на китайские разработки не только мелкие стартапы. Сервис доставки еды DoorDash отдал рутинные задачи модели Kimi K2.6 от китайской компании Moonshot AI, оставив Fable только для "самой сложной работы", — по словам сооснователя Энди Фана, новая связка работает лучше и обходится дешевле. Siemens использует DeepSeek и GLM от Z-ai наряду с американскими моделями. Airbnb применяет "ограниченное число моделей китайского происхождения". А стартап Lindy из Сан-Франциско полностью переехал с моделей Anthropic на DeepSeek V4 — основатель Фло Кривелло говорит, что это сэкономило компании миллионы долларов.
Уходить оказалось несложно. Лучшие китайские модели распространяются с открытыми весами: их можно запускать на собственных серверах и дообучать под свои задачи, не отдавая данные наружу. Стоят они в 10–60 раз дешевле закрытых американских аналогов. При этом Anthropic и OpenAI недавно перевели часть корпоративных клиентов с фиксированной подписки на оплату по потреблению — и счета за ИИ у бизнеса резко выросли.
Масштаб перехода виден в цифрах: по данным платформы OpenRouter, в этом году китайские модели обогнали американские по объему потребления токенов — единиц текста и кода, которые обрабатывает нейросеть.
"Два года назад главной угрозой считали Китай. Сейчас в Европе больше боятся США, — говорит Пер Роман, основатель венчурного фонда Bullhound Capital. — Это ошеломляет". Но важно учитывать и риски: недавно в прессе появилась информация, что китайские власти приглашали локальных разработчиков ИИ на совещание по вопросу экспортного контроля передовых моделей. Пока это только слухи, но тенденция настораживает — ИИ все чаще становится политическим инструментом.
P.S. Поддержать меня можно подпиской на канал "сбежавшая нейросеть", где я рассказываю про ИИ с творческой стороны.
Пекин думает, как запереть свои лучшие нейросети внутри страны. По данным Reuters, министерство коммерции КНР весь последний месяц проводило встречи с Alibaba, ByteDance и стартапом Z-ai, обсуждая ограничение зарубежного доступа к самым мощным китайским моделям. Главный пострадавший от такого запрета — не Китай. Это США.
Речь идет о передовых моделях, включая еще не выпущенные. Ограничения обсуждают не только для закрытых ИИ, но и для открытых — тех, что сегодня любой может бесплатно скачать и запустить на своем железе. Среди идей — приравнять утечку или кражу модели к преступлению против национальной безопасности и фильтровать инвесторов, которым разрешено вкладываться в китайские ИИ-компании.
Ответ на вопрос, при чем тут США, накануне дал Клеман Деланг — глава Hugging Face, крупнейшего в мире каталога открытых нейросетей, которым пользуется половина компаний из списка Fortune 500. Он предупредил: большинство открытых моделей, которые сегодня скачивают в США, созданы китайскими лабораториями.
Логика бизнеса простая. Аренда доступа к топовым американским моделям с ростом компании превращается в гигантские счета, причем у клиента минимум контроля: Anthropic и OpenAI могут хоть завтра поменять цены или вывести модель из использования, как это было с мощной Claude Fable 5. Китайские аналоги — Qwen от Alibaba или GLM от Z.ai — можно скачать бесплатно и использовать в разы дешевле, купив или арендовав вычислительные мощности. Американские стартапы голосовали кошельком, и за пару лет дешевый китайский ИИ стал фундаментом, на котором стоит заметная часть их продуктов. Деланг считает, что чинить это нужно не запретами, а собственными открытыми моделями, в которые США вкладываются недостаточно.
Интересно, что в июне США сами ограничивали экспорт передовых моделей Anthropic, сославшись на национальную безопасность — та самая история с Claude Fable 5, которая была недоступна 19 дней. Теперь, по данным Reuters, в Пекине встревожены, что одна из этих моделей, умеющая находить уязвимости в программах, может быть применена против китайских систем.
Решений пока нет: обсуждения продолжаются, сроки не называются, ограничения могут коснуться только будущих моделей. Ни китайские власти, ни Alibaba, ByteDance и Z.ai запросы Reuters не прокомментировали. Если брать американский опыт, то ограничения скорее будут временными, чтобы дать государству и избранному бизнесу фору в использовании лучших моделей.
За один месяц обе сверхдержавы пришли к одинаковому выводу: передовая нейросеть — не товар, а стратегический актив. Эра, когда лучшие китайские модели можно было свободно скачать в любой точке мира, может закрыться — и первыми это почувствуют те, кто построил на них бизнес.
P.S. Поддержать меня можно подпиской на канал "сбежавшая нейросеть", где я рассказываю про ИИ с творческой стороны.
Здравствуйте! Года 2 назад релизнулась ide Trae, в которой можно было написать с помощью ии программу по своему описанию. При этом можно было только писать само описание программы и требуемого функционала, а программа сама печатала код, запускала программу, в общем делала все сама. Сейчас Trae платная, а бесплатный лимит запросов очень скоро заканчивается и это не дает просидеть в ней долгое время и получить желаемый результат. Может быть кто-то подскажет рабочие методы или сервисы, с помощью которых можно схожим образом надиктовать ии агенту описание желаемой программы, а он бы писал код? Ии чаты не устраивают тем, что они раскидывают код по отдельным файлам и помимо этого приходится делать много ручной работы. Может быть можно как-то интегрировать бесплатные ии (qwen, deepseek... ) в популярные Ide, чтобы не было лимитов на запросы и чтобы ии сам писал бы код и делал все остальное? Если подытожить, то хотелось бы просто писать функционал программы, а ии делал все остальное.