Tesla переводит проект гуманоидного робота Optimus из лабораторных прототипов в фазу подготовки к серийному выпуску. Компания открыла более 140 вакансий в отделе робототехники, а на недавнем мероприятии в Остине впервые показала работу прототипа в публичной среде. Ставка беспрецедентна: ради конвейера для роботов Tesla жертвует производством своих исторических автомобильных флагманов.
Инженерное чудо: руки, почти не уступающие человеческим
Главным достижением версии 2.5, которая станет базой для Gen 3, стали руки робота. Промежуточный прототип продемонстрировали на недавнем поп-ап мероприятии по автономным технологиям в Остине (Техас). Публика впервые увидела новую механику захвата в реальных условиях: Optimus примерил на себя роль ассистента, раздавая гостям воду.
Новое поколение кистей робота Tesla Optimus с 22 степенями свободы, максимально приближенное к человеческой анатомии. Источник: notateslaapp.com
Это стало идеальным стресс-тестом для мелкой моторики машины — робот считывал силовую обратную связь, понимая, с каким именно усилием нужно сжать тонкий пластик, чтобы бутылка не выскользнула, но и не смялась в железной хватке.
Что именно изменилось в конструкции, позволив добиться такой деликатности:
22 степени свободы в кисти (+3 в запястье). Для сравнения: у человека их около 27, у прошлого поколения Optimus было всего 11.
Изменение компоновки: Инженеры скопировали человеческую анатомию, разместив 25 актуаторов (приводов) руки в предплечье. Управление пальцами теперь осуществляется дистанционно — через сложную систему тросов-сухожилий, что радикально снизило вес самой кисти.
Точность и сила: Заявленная точность моторики достигает 0.08 мм при грузоподъемности рук до 20 кг.
Сенсорика: Интегрированные в кончики пальцев тактильные датчики обеспечивают ту самую обратную связь, позволяющую филигранно работать с хрупкими предметами.
Защита от среды: Ожидается, что финальная версия Gen 3 получит герметичную влагозащиту. Робот сможет без риска замыкания работать с водой, мылом и горячим паром — критически важный апгрейд для мытья посуды, уборки или стирки.
Столкновение с реальностью: провода и ручные тележки
Несмотря на потрясающую плавность движений и использование передовой вычислительной платформы HW5 (аналогичной той, что стоит в автомобилях с FSD), мероприятие в Остине показало раннюю стадию интеграции робота в реальный мир.
На уличной демонстрации Optimus работал, будучи подключенным к зарядному кабелю. Очевидно, что управление пиковым энергопотреблением при постоянном социальном взаимодействии и работе тяжелых нейросетей все еще требует внешнего питания, хотя к релизу Tesla обещает 24-часовую автономность на собственных батареях. Кроме того, после шоу робота упаковывали в кастомные деревянные ящики и увозили на обычной ручной тележке силами двух человек. Экосистема для логистики и автономного обслуживания таких устройств пока строится с нуля.
Дорожная карта и экономика на $10 триллионов
Для масштабирования проекта Илон Маск пошел на радикальный шаг: на январском звонке с инвесторами он объявил об остановке производства премиальных электромобилей Model S и Model X. Линии завода во Фримонте переоборудуются под конвейер Optimus.
Таймлайн и бизнес-план проекта выглядят так:
Лето 2026: Старт предсерийного производства Gen 3 во Фримонте.
Конец 2026 — 2027 год: Внедрение более 1000 роботов на собственных заводах Tesla для выполнения реальных задач.
Конец 2026: Ограниченные коммерческие продажи (B2B сегмент) по цене свыше $100 000 за единицу.
Конец 2027: Старт продаж для массового потребителя.
Долгосрочные цели: Снижение себестоимости ниже $20 000 (отраслевые аналитики прогнозируют реальную розничную цену в $20 000–$30 000) и запуск мега-линии на Gigafactory в Техасе мощностью 10 млн единиц в год.
По заявлениям Маска, успешный выход Optimus на масс-маркет может принести компании более $10 трлн дохода. Сегодня инженеры Tesla решают производственные проблемы, с которыми индустрия на таких масштабах еще не сталкивалась, фактически создавая всю цепочку поставок — от кастомных моторов до искусственных сухожилий. Это тот уровень задач, который сами сотрудники называют «экстремальным спортом в инженерии».
И как точно подметила одна из инженеров в новом рекрутинговом видео Tesla: «Готовый продукт даже не будет похож на классического робота. Он будет выглядеть как человек в костюме супергероя».
Apple официально подтвердила, что ни одно устройство с активированным режимом Lockdown Mode (Режим блокировки) не было успешно скомпрометировано хакерами или коммерческим шпионским ПО. Это заявление прозвучало в критический момент, когда миллионы пользователей старых версий iOS оказались под угрозой из-за утечки в открытый доступ опасных инструментов для взлома.
Интерфейс активации режима Lockdown Mode в настройках безопасности iOS. Источник: MacRumors
Непробиваемая защита
Режим Lockdown Mode, впервые представленный Apple в 2022 году для защиты от сложных целевых кибератак, доказал свою невероятную эффективность. Как заявила пресс-секретарь Apple Сара О’Рурк, компании «неизвестно ни об одной успешной атаке коммерческого шпионского ПО на устройства Apple с включенным режимом Lockdown Mode».
Независимые эксперты подтверждают эти данные. Исследователи из Citizen Lab задокументировали как минимум два случая, когда этот режим остановил реальные атаки. В 2023 году он заблокировал попытку взлома с помощью шпионского ПО Pegasus (от NSO Group), а позже предотвратил атаку с использованием ПО Predator (от Cytrox). По словам специалиста по кибербезопасности Руны Сандвик, Lockdown Mode сегодня является «лучшей защитой, которую мы имеем против Pegasus и Predator».
При включении этого режима операционная система кардинально ограничивает свою функциональность, чтобы минимизировать поверхность атаки: блокируется большинство вложений в сообщениях, отключается предварительный просмотр ссылок, запрещаются входящие звонки FaceTime от незнакомых контактов и отключаются сложные веб-технологии, которые чаще всего эксплуатируют хакеры.
Режим блокировки предлагает опциональный, экстремальный уровень защиты для пользователей, которые могут стать мишенью цифровых угроз. Источник: Apple Newsroom
Новые угрозы для старых версий iOS: Coruna и DarkSword
Несмотря на успехи Apple в защите новейших операционных систем, пользователи старых iPhone столкнулись с серьезной угрозой. За последний месяц исследователи из Google, iVerify и Lookout раскрыли данные о двух мощных наборах эксплойтов — Coruna и DarkSword, которые использовались киберпреступниками и спецслужбами разных стран.
Инструмент Coruna нацелен на устройства под управлением iOS от 13 до 17.2.1 и содержит эксплойты для 23 различных уязвимостей. Набор DarkSword атакует более поздние версии — с iOS 18.4 по 18.7. Примечательно, что алгоритмы Coruna запрограммированы на полное прекращение работы, если вредоносный код обнаруживает на устройстве жертвы включенный режим Lockdown Mode. Работа DarkSword также успешно блокируется этой функцией.
Утечка кода и два класса безопасности iPhone
Ситуация резко усугубилась после того, как исходный код эксплойтов утек в открытый доступ, что сделало эти инструменты доступными для широкого круга злоумышленников.
Эксперты отмечают, что сейчас в экосистеме Apple сформировалось «два класса пользователей». Те, кто использует актуальную iOS 26 на новых устройствах, защищены новейшими механизмами обеспечения целостности памяти (Memory Integrity Enforcement). Однако пользователи старых устройств и устаревшего ПО остаются уязвимыми.
Apple отреагировала оперативно: компания выпустила экстренные обновления для гаджетов, не поддерживающих последние версии iOS, и начала рассылать прямые уведомления об угрозе пользователям iOS 17 и более ранних версий. Тем, кто по каким-либо причинам не может обновить систему на своем iPhone, Apple настоятельно рекомендует немедленно активировать Lockdown Mode в качестве временной меры защиты.
«Поддержание программного обеспечения в актуальном состоянии — это самое важное, что вы можете сделать для обеспечения безопасности ваших продуктов Apple», — подчеркнула Сара О’Рурк.
Представьте себе автоспортивное конструкторское бюро, которое тридцать пять лет чертило безупречные двигатели для всего пелотона Формулы-1, но никогда не выставляло на трассу собственный болид. Британская Arm Holdings десятилетиями была такой абсолютной «Швейцарией» Кремниевой долины. Она была невидимым фундаментом вычислений, продавая интеллектуальную собственность и лицензии на архитектуру всем: от Apple до Qualcomm и Nvidia. Никакого физического производства, только идеальные чертежи.
Но эволюция технологий сломала эти правила. Пока нейросети были относительно простыми, их задача сводилась к генерации: выдать текст, написать код в окне чата, нарисовать картинку. Для этой математики идеально подходили графические ускорители (ГПУ), где ИИ фактически и обитает. Однако по мере взросления модели становятся умнее. Им уже мало просто отвечать на вопросы — они начинают активно использовать внешние инструменты для выполнения десятков задач пользователей.
Чтобы искать данные в реальном времени, запускать тяжелые скрипты в изолированных средах и управлять сторонними программами, ИИ нужен быстрый исполнитель. Этим исполнителем выступает центральный процессор (ЦПУ). И чем сложнее становятся ИИ-агенты, тем острее им требуется сверхмощная процессорная логика для работы их инструментов.
Видя взрывной спрос на классическую логику, руководство осознало, что продавать концепты больше недостаточно. Во вторник, на конференции «Arm Everywhere» в Сан-Франциско, архитекторы отложили циркуль и взялись за кремний.
CEO компании Рене Хаас представил AGI CPU — первый в истории Arm полностью собственный, готовый к установке серверный чип. Назвав этот сдвиг бизнес-модели «определяющим моментом для компании», Хаас фактически провозгласил конец эпохи нейтралитета.
Чтобы спуститься с уровня архитектуры до реального кремния, Arm развернула три инженерные лаборатории. Вложенные в этот проект в Остине $71 миллион и мобилизованная армия из 1000 инженеров прямо сейчас готовят «AGI CPU» к массовому производству во второй половине года. Уолл-стрит оценила масштаб этой трансформации мгновенно.
Как только рынки поняли, что проектировщик забирает себе часть рынка физического «железа», акции Arm взлетели на 20%, а капитализация пробила историческую отметку в $155 миллиардов. Инвесторы приветствовали жесткий прагматизм: Arm сделала агрессивную ставку на рынок чипов напрямую, больше не желая оставаться в тени своих же клиентов.
Глава Arm Рене Хаас на конференции «Arm Everywhere». Исторический сдвиг: компания больше не продает только чертежи — она поставляет готовые процессоры для ИИ-агентов. (Фото: CNBC)
Анатомия Разума: Зачем ИИ-агентам нужны «руки»
Прямая ставка Arm на рынок готовых чипов — это не просто смена бизнес-модели, это демонстрация грубой вычислительной силы. Выведя на арену «AGI CPU», компания нанесла прямой технический удар по классическим архитектурам. Под крышкой нового процессора бьются 136 ядер Neoverse V3, отпечатанных по 3-нанометровому техпроцессу на фабриках тайваньской TSMC. Эта мощь имеет абсолютно прагматичное обоснование.
Традиционные облачные дата-центры десятилетиями опирались на центральные процессоры. Когда грянул бум нейронных сетей, индустрия бросилась строить специализированные ИИ-кластеры, где на восемь ГПУ зачастую приходился лишь один ЦПУ, выполнявший роль скромного диспетчера для перекладывания данных. Эра агентного ИИ ломает эту узкоспециализированную архитектуру, заставляя рынок возвращать баланс в пользу ЦПУ.
Если ГПУ — это мозг нейросети, генерирующий смыслы и принимающий решения, то ЦПУ становится инструментами и «руками» ИИ-агентов. Без мощного процессора агентный ИИ остается гениальным, но абсолютно парализованным мыслителем.
Спустившись с небес чистых концептов на землю физического производства, Arm столкнулась с неумолимыми законами термодинамики. Чтобы питать эту 136-ядерную машину, инженерам пришлось заложить в процессор 300-ваттный тепловой пакет (TDP). Это колоссальная цифра для архитектуры Arm, которая исторически славилась энергоэффективностью в мобильных устройствах. Серверные стойки будущего будут буквально раскаляться от плотности вычислений.
Такое экстремальное энергопотребление необходимо Arm для двукратного превосходства по производительности на стойку по сравнению с традиционными x86-решениями от Intel и AMD. Компания не просто выпустила свой чип — она дала рынку возможность удвоить производительность инструментов для искусственного интеллекта на той же физической площади дата-центра.
Первая кровь: Ставка Марка Цукерберга
Первым покупателем, решившим опереться на эту феноменальную плотность, стала Meta*. Марк Цукерберг не случайно забрал статус дебютного клиента для «AGI CPU». Его корпорация делает главную ставку на Llama — открытую экосистему искусственного интеллекта. Одно дело — создать языковую модель в закрытой лаборатории, и совершенно другое — развернуть миллиарды автономных ИИ-агентов, которые будут ежедневно искать товары, бронировать билеты и писать код для пользователей WhatsApp*, Instagram* и сторонних разработчиков по всему миру.
Для такой задачи архитектура Arm обеспечивает высочайшую плотность ядер на квадратный сантиметр кремния. В результате Meta* получает возможность развернуть процессорные «руки» для своих ИИ-агентов с максимальной плотностью на каждую серверную стойку.
Увидев, как создатель крупнейшей социальной сети интегрирует кремний от Arm, в очередь за новым процессором выстроились и другие технологические гиганты. В официальном листе ожидания уже числятся OpenAI, Cloudflare, SAP и южнокорейская SK Telecom. Индустрия хладнокровно утвердила новый стандарт плотности своими бюджетами.
Ставка на $25 миллиардов
Вступая в новую лигу, Рене Хаас не стал разрушать исторический фундамент Arm — компания продолжит продавать лицензии на свою архитектуру. Но как прагматичный стратег, он осознал: у идеальной софтверной модели есть непреодолимый потолок. Продажа интеллектуальной собственности — это бизнес с феноменальной рентабельностью, но он приносит лишь скромные роялти с каждого произведенного кем-то чипа.
Чтобы не упустить триллионные инвестиции, вливающиеся сейчас в инфраструктуру ИИ, недостаточно просто собирать налог на чертежи. Нужно забирать основную добавленную стоимость. И для этого Arm открывает прямую продажу физического кремния.
Выход на рынок «железа», пусть и через контрактные заводы TSMC, ломает привычную экономику компании. Производство готовых серверных процессоров означает столкновение с жесткой логистикой и квотами на кремниевые пластины. В любой другой ситуации Уолл-стрит могла бы испугаться таких перемен, но в случае с ИИ-чипами рынки отреагировали стоячими овациями.
Продажа физических процессоров открывает путь к доходам, которые несоизмеримо больше традиционных лицензионных сборов. Хаас публично заявил, что к 2031 году общая выручка компании достигнет $25 миллиардов — это примерно в шесть раз больше текущих показателей. Причем $15 миллиардов из этой суммы сгенерирует именно новое «железное» направление.
Поняв, что Arm выходит на стомиллиардный рынок серверных компонентов напрямую, инвестиционные банки начали повышать целевую цену акций: HSBC выдал двойной апгрейд, а Guggenheim поднял целевую цену до $240, прямо назвав происходящее трансформацией бизнес-модели. Рынок осознал математику момента: тот, кто предоставляет ИИ-агентам физические «руки», будет контролировать большую долю расходов в дата-центрах следующего десятилетия.
Скрытый конфликт с гигантами
Борьба за такой рынок означает, что эпоха джентльменских соглашений в микроэлектронике официально завершена. На презентации «Arm Everywhere» глава Nvidia Дженсен Хуанг появился в предзаписанном видео с теплыми и дипломатичными поздравлениями. Но за этой дежурной улыбкой скрывается холодное понимание новой реальности. Выводя на рынок «AGI CPU», вчерашний нейтральный партнер наносит прямой удар по амбициям самой Nvidia, которая прямо сейчас пытается навязать рынку собственные серверные процессоры для полного контроля над дата-центрами. Бывший союзник превратился в опасного конкурента.
Скрытый конфликт с Nvidia — это лишь симптом глобального обрушения правил игры. Запуск готового чипа от Arm делает очередную пробоину в системе разделения рынков Кремниевой долины.
Долгие годы схема была незыблемой и комфортной для всех: одни чертили базовую архитектуру, вторые печатали кремний, третьи собирали видеокарты, а четвертые писали для всего этого софт.
В эпоху ИИ эти границы резко размываются. Разработчики социальных сетей и поисковиков, такие как Meta* и Google, проектируют собственные ИИ-ускорители. А вечный проектировщик Arm, собиравший роялти за чертежи, запускает масштабные поставки собственного железа. Больше нет «Швейцарии» и нет нейтральных территорий. В гонке за построение физической инфраструктуры для агентного ИИ отныне каждый конкурирует со всеми. И в этой новой, предельно жесткой экосистеме триллионные капиталы достанутся лишь тем, кто способен не просто нарисовать чертеж будущего разума, но и дать ему самые эффективные физические процессоры.
Индустрия искусственного интеллекта годами развивалась по пути грубой силы — бесконечного наращивания вычислительных мощностей. Но когда физические пределы «железа» стали очевидны, в игру вернулась чистая математика.
В среду, 25 марта 2026 года, на биржах произошла аномалия. Пока индекс Nasdaq уверенно рос, акции гигантов индустрии памяти — Micron, Western Digital, Seagate, а также производителей оборудования Lam Research и Applied Materials — синхронно ушли в минус. Триггером стала не геополитика и не сбои в логистике, а публикация одной научной статьи от Google Research.
Команда инженеров Google представила TurboQuant — алгоритм, способный сжать так называемый KV-кэш (память, в которой нейросеть удерживает контекст диалога) до 3 бит. И самое важное: алгоритм не снижает точность ответов и ускоряет вычисления в 8 раз на чипах NVIDIA H100.
До этого момента индустрия решала проблему огромных контекстов грубой силой: просто закупала всё больше дорогих чипов памяти. Инженеры Google предложили альтернативу — перестать раздувать аппаратные мощности и переписать саму математику работы ИИ с данными.
Биржевая паника или парадокс Джевонса? Аналитики Уолл-стрит расходятся в оценках того, как алгоритмический прорыв Google отразится на производителях «железа». Источник: CNBC
Квантование полярных координат
В основе TurboQuant лежит отказ от привычных систем координат. Современные алгоритмы теряют критически важные данные, когда пытаются сжать информацию сильнее 4 бит. Google обошла этот барьер с помощью квантования полярных координат PolarQuant.
Вместо того чтобы хранить тяжелые многомерные координаты данных, алгоритм переводит их в полярную систему — запоминает только радиус и угол. Оказалось, что для нейросетей направление вектора куда важнее точного расстояния. А неизбежные при таком жестком сжатии ошибки алгоритм аккуратно сглаживает дополнительным модулем QJL (Quantized Johnson-Lindenstrauss) — он просто прячет лишний «шум» в безопасное математическое пространство, где тот не мешает вычислениям.
Этот изящный трюк создает неожиданную проблему даже для гегемона рынка — NVIDIA. Софтверный буст делает их текущие чипы H100 настолько эффективными, что клиенты могут решить подождать и отложить закупку новых, более дорогих процессоров.
Реакция рынка
Торговые алгоритмы Уолл-стрит отреагировали прямолинейно: если Google в шесть раз сокращает потребность ИИ в памяти, значит, дата-центрам больше не нужно скупать SSD и чипы в прежних объемах.
Однако аналитики Morgan Stanley призывают не паниковать. Они называют долгосрочный эффект для производителей железа «нейтрально-позитивным». Срабатывает парадокс Джевонса: когда ресурс становится использовать проще и дешевле, его потребление не падает, а наоборот — взлетает.
Снижение требований к памяти сильно удешевит запуск ИИ. Нейросети, которым раньше требовались целые серверные стойки, теперь смогут работать локально или на дешевом оборудовании. Это не убьет спрос на кремний, а откроет двери для тысяч новых проектов, которые раньше были просто не по карману.
Официально TurboQuant покажут в апреле на конференции ICLR 2026 в Рио-де-Жанейро. И, кажется, это отличный сигнал: индустрия ИИ перестает решать все проблемы исключительно грубой силой. Гонка «железа» никуда не денется, но теперь выигрывать в ней будут не только бесконечными бюджетами на память, но и красивой математикой.
Компания одного человека в 2026 году больше не означает, что вы делаете всё сами. Теперь это значит, что вы руководите целым штатом ИИ-агентов и сосредоточены на стратегии. Вышедший на пике этого тренда фреймворк Paperclip делает эту модель массовой. Он забирает у соло-основателей хаос из десятков разрозненных скриптов и внедряет для нейросетей то, к чему привыкли люди: жесткую организационную структуру, трекер задач, систему бюджетирования и корпоративное управление.
В начале 2026 года индустрия столкнулась с неожиданным кризисом: искусственный интеллект стал достаточно хорош, чтобы работать без надзора, но слишком хаотичен, чтобы работать в команде. Пока одиночные агенты вроде Felix (создан разработчиком Нэтом Элиасоном) приносили своим создателям более 100 000 долларов выручки, управление роем из пятнадцати или двадцати подобных ботов превращалось в логистический кошмар. Разработчики теряли сотни долларов из-за зацикленных скриптов и забывали, какую задачу выполняет каждая из открытых вкладок терминала.
Ответом на этот «координационный налог» стал запуск Paperclip — системы с открытым исходным кодом, которая переносит принципы корпоративной бюрократии на управление нейросетями.
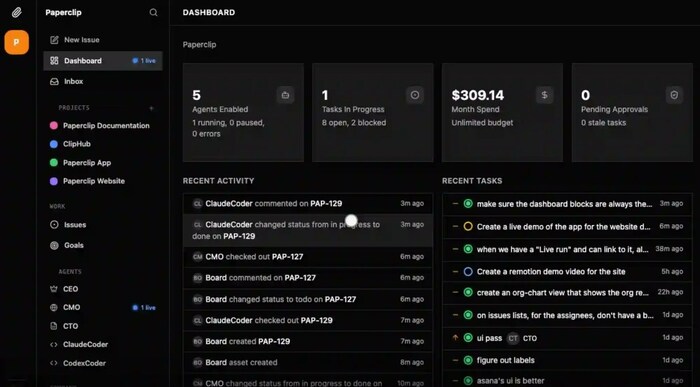
Панель управления ИИ-агентами в Paperclip. Источник: Medium.
Представлен мотор вашей ИИ-компании
9 марта 2026 года состоялся публичный релиз Paperclip. Это не новая языковая модель и не фреймворк для создания ИИ-агентов. Это менеджерский слой (написанный на Node.js со встроенной базой PostgreSQL), который объединяет различные инструменты — Claude Code, OpenClaw, Codex и Cursor — в единую организационную структуру. Пользователь вводит глобальную бизнес-миссию, а система самостоятельно распределяет роли, формирует дерево задач (от «Цели проекта» до конкретного тикета) и назначает ботам бюджеты.
Создатели проекта формулируют суть своей архитектуры предельно просто:
«Если OpenClaw — это сотрудник, то Paperclip — это компания».
Взаимодействие происходит асинхронно: агенты «просыпаются» по заданному расписанию, выполняют свою часть кода или текста, передают результат по иерархии и снова засыпают. Проект распространяется по лицензии MIT и может быть развернут локально одной командой в терминале.
Бюрократия спасает от хаоса
Чтобы понять, почему за одну неделю Paperclip собрал 19 900 звезд на GitHub, нужно посмотреть на проблему глазами разработчика. Одиночным скриптом управлять легко. Но когда, как у предпринимателя Аарона Снида, круглосуточно работают 15 кастомных агентов-ассистентов, экономящих 20 часов в неделю, — вы начинаете тонуть в гонке состояний, двойной работе и сбоях сессий.
Создатели Paperclip сформулировали свой подход предельно жестко:
«Не чат-бот. У агентов есть работа, а не окна чата. Не фреймворк для агентов. Мы не говорим вам, как создавать агентов. Мы рассказываем, как управлять компанией, состоящей из них».
В основе платформы лежат несколько нетипичных для классического ИИ-инструментария механик.
Сердцебиение и персистентность. Агенты больше не висят в оперативной памяти постоянно. Они работают по системе «heartbeats» (сердцебиений). Например, агент-контентмейкер просыпается каждые 4 часа, проверяет свою очередь задач, пишет текст, отправляет его по иерархии выше и уходит в спящий режим. Если терминал закроется или компьютер перезагрузится, контекст не потеряется.
Атомарное выполнение. В традиционных системах два агента могут случайно взять в работу одну и ту же задачу, потратив в два раза больше токенов на вызовы API. Paperclip следит за агентами: когда агент бронирует задачу, она блокируется.
Дерево целей. Вместо того чтобы просто сказать боту «напиши обработчик WebSocket», система передает ему всю генеалогию: Миссия компании («Создать AI-приложение для заметок с выручкой $1M») → Цель проекта («Запустить функции коллаборации») → Цель агента («Реализовать синхронизацию в реальном времени») → Задача. Это решает главную проблему LLM — потерю бизнес-контекста при выполнении узкотехнических инструкций.
Адаптация новых «сотрудников» происходит на лету благодаря файлу SKILLS.md. Если вы подключаете нового агента к уже работающей системе, он просто считывает этот файл и мгновенно понимает внутренний протокол: как сдавать работу, как запрашивать помощь и кому подчиняться.
ИИ сам собирает себе команду
Ключевое отличие нового подхода заключается в смещении роли человека. Заявленная концепция «компании с нулевым участием людей» (Zero-Human Company) на практике оборачивается тем, что разработчик внезапно оказывается в кресле чиновника, непрерывно ставящего штампы на документах.
Независимый архитектор решений Кельвин Квонг, тестировавший Paperclip на реальных задачах, описывает свой опыт так:
«Система приняла кадровые решения, о которых я не просил, создала структуру проекта, которую я не проектировал, и теперь ждала, что я автоматически одобрю ее планы. Я стал советом директоров компании, которую не создавал».
Когда система сама формирует стратегию, декомпозирует ее на задачи и распределяет их между виртуальным «SEO-аналитиком» и «Backend-разработчиком», что остается человеку? Означает ли это, что высшая форма инженерии в 2026 году — это умение правильно утверждать бюджетные сметы для алгоритмов?
Бюджет как главный рубильник
Пожалуй, самым недооцененным прорывом стала примитивная, на первый взгляд, функция — жесткое бюджетирование. Разработчики регулярно сталкивались с ситуацией, когда ИИ-агент, застряв в цикле ошибок, мог за 45 минут сжечь 200 долларов на бесконечных API-запросах, прежде чем человек успевал это заметить.
В Paperclip каждому виртуальному сотруднику выделяется жесткий лимит (например, $50 в месяц). При расходе в 80% система отправляет мягкое предупреждение. При достижении 100% агент физически блокируется (auto-pauses) на уровне инфраструктуры. Никаких исключений, пока «Совет директоров» (вы) не согласует дополнительное финансирование. Это превращает абстрактный страх перед восстанием машин во вполне понятный корпоративный процесс: отдел разработки превысил смету и ждет транша.
Реальные кейсы и сценарии использования
Архитектура Paperclip не является сугубо академическим экспериментом — она тестируется энтузиастами в реальных, часто нестандартных условиях. Инструмент, созданный для решения личной проблемы одного разработчика, быстро оброс экосистемой микробизнесов и автономных конвейеров.
Управление хедж-фондом и хаос в терминале
Проект родился из банального человеческого отчаяния создателя фреймворка (разработчика под псевдонимом Agent Native). Он пытался автоматизировать рутину в собственном алгоритмическом хедж-фонде. В какой-то момент для поддержания работы у него было одновременно открыто двадцать вкладок с запущенным Claude Code. Разработчик признался, что физически перестал контролировать ситуацию: он не помнил, какой бот собирает финансовую аналитику, какой пишет код, а какой просто завис. Paperclip стал вынужденной мерой, чтобы превратить эти двадцать разрозненных вкладок в один слаженный отдел с четкой иерархией.
Автоматизация GitHub: программист, который нанял сам себя
На профильных площадках вроде Reddit активно обсуждается сценарий радикального делегирования разработки. Один из пользователей настроил Paperclip для полного цикла управления собственным кодом. Система работает так: первый агент непрерывно мониторит вкладку с ошибками (Issues) в репозитории. Обнаружив баг, он выступает в роли тимлида и назначает задачу виртуальному «программисту» (на базе Claude Code). Тот пишет исправление и формирует Pull Request, после чего другой агент-тестировщик прогоняет тесты и проверяет логику. Единственное, что делает в этой цепочке живой человек — раз в сутки заходит в систему, чтобы нажать кнопку «Merge» (слияние веток).
Агентство лидогенерации на автопилоте
В официальной документации и материалах на Substack описывается создание конвейерного B2B-агентства. Процесс разбит на строгие роли: агент-парсер круглосуточно собирает профили потенциальных клиентов в LinkedIn. Собранная база передается виртуальному SEO-аналитику, который сверяет компании с заданными критериями целевой аудитории. Финальный этап берет на себя агент-копирайтер, генерирующий глубоко персонализированные холодные письма. Весь ежемесячный бюджет (зарплатный фонд) на API-вызовы для такой команды составляет около 210 долларов, что несопоставимо со стоимостью найма даже одного стажера-человека.
Zero-Cost Agency: бесплатный штат на домашнем сервере
Для тех, кто не хочет платить корпорациям за токены, на GitHub зародилось целое движение. Энтузиасты начали скрещивать оркестрацию Paperclip с локальными языковыми моделями через систему Ollama. Это породило феномен «агентств с нулевой стоимостью» (Zero-Cost Agency). Виртуальная компания полностью разворачивается на домашнем сервере (например, на Mac Mini) и работает 24/7. Пользователь получает полноценный штат сотрудников, не платя за них ничего, кроме счетов за электричество и интернет.
Отзывы и впечатления: имитация бурной деятельности и шок фаундеров
Однако на практике жизнь автономных корпораций оказалась полна абсурдных инцидентов, в которых алгоритмы начали пугающе точно копировать худшие проявления человеческой корпоративной культуры.
Шок от потери контроля
Независимый разработчик Кельвин Квонг описал психологический дискомфорт, с которым сталкиваются фаундеры. Ранее человек привык писать промпт и получать готовый текст или код. В Paperclip паттерн меняется: человек ставит абстрактную задачу, а система сама проектирует структуру проекта, нанимает виртуальных сотрудников и выкатывает бюджетную смету, требуя от создателя ее утверждения. Пользователи жалуются на сюрреалистичное чувство: они превращаются в бюрократов, обслуживающих компанию, которую сами не проектировали.
Галлюцинации в иерархии и бесконечные совещания
Практики выявили фундаментальную проблему каскадного непонимания. Если CEO-агенту (верхнего уровня) ставится слишком размытая бизнес-цель, он передает такие же нечеткие инструкции своим подчиненным. Вместо того чтобы выдать ошибку, нижестоящие боты начинают бесконечно отправлять запросы друг другу, пытаясь уточнить детали. Визуально это выглядит так, словно ИИ-сотрудники заперлись в переговорке на бесконечное совещание: они имитируют бурную деятельность, перекидываются сообщениями и стремительно сжигают выделенный бюджет, не производя при этом ни строчки полезного кода.
Споры о пульсе: почему машинам нужны человеческие смены
Отдельной темой для дискуссий стала частота «сердцебиений» (heartbeats) — интервалов, через которые агенты просыпаются для работы. Изначально пользователи пытались выжать из ботов максимум, заставляя их проверять задачи каждые 10–15 минут. Это приводило к катастрофам. Создатель фреймворка признавался, что лично наблюдал, как агент сжег 200 долларов за 45 минут, просто застряв в цикле бесконечных повторных попыток (retry loop).
Опытным путем сообщество пришло к парадоксальному выводу: ботов нужно искусственно тормозить. Самыми стабильными оказались системы, где агенты просыпаются раз в четыре или восемь часов. Ирония очевидна: создавая ИИ для круглосуточной работы со скоростью света, разработчикам пришлось вернуть алгоритмы к классическому графику человеческих рабочих смен, чтобы они не сломали сами себя.
Иллюзия «нулевого присутствия»
Концепция «компания с нулевым участием людей» звучит масштабно. Однако при глубоком анализе документации и отзывов первых пользователей вскрываются фундаментальные вопросы, о которых система умалчивает.
Во-первых, ни один источник не объясняет, как именно Paperclip страхует пользователя от каскадных семантических ошибок (error propagation). Если агент-исследователь сгаллюцинировал неверные финансовые данные, а агент-копирайтер блестяще и без технических сбоев написал на их основе инвестиционный отчет, система воспримет задачу как успешно выполненную. Инструмент отслеживает только статус тикета и расход токенов, но не оценивает достоверность результата.
Во-вторых, остается открытым вопрос: на основе каких скрытых метрик система автоматически решает, сколько агентов нужно «нанять» для абстрактной миссии вроде «создать внутренний инструмент»? Кельвин Квонг прямо указывает на правило «мусор на входе — хаос на выходе». Если вы ставите размытую бизнес-цель, агенты начинают дробить ее на десятки бессмысленных подзадач, имитируя бурную деятельность и сжигая бюджет.
Кроме того, инструмент позиционируется как универсальный, однако требует уверенного владения средой Node.js, что создает определенный порог входа для инженеров, не знакомых с этой средой.
Эпоха алгоритмического менеджмента
Успех Paperclip, ровно как и параллельных проектов вроде платформы Pulsia (где запущено уже более 1500 автономных компаний) или фреймворка Symphony от OpenAI, фиксирует важный сдвиг. Бутылочное горлышко технологий окончательно сместилось от генерации контента к логистике процессов.
Тот факт, что для управления кодом нам понадобилось воссоздать бюрократический аппарат со сметами, должностными инструкциями и планерками, выглядит одновременно иронично и закономерно. Человечество пока не придумало лучшего способа справляться с хаосом, чем поместить его в таблицу с иерархией. Компании и одиночные разработчики, которые первыми научатся быть хладнокровным «Советом директоров» для машин, получат непропорциональное преимущество. Остальным придется и дальше закрывать по двадцать вкладок в терминале, надеясь, что на этот раз ИИ ничего не сломал.
Недавно на Хабре вышла статья «Почему наш язык — худший язык для программирования». Автор справедливо отметил проблему двусмысленности естественного языка (ЕЯ) и предупредил, что программирование словами приведет к хаосу.
Я начну с неожиданного: автор оригинальной статьи абсолютно прав.
Он прав, если мы говорим о программировании заклинаниями (vibe-coding) — популярном сегодня подходе, когда человек пишет в окно чата: «Сделай мне интернет-магазин с красивым дизайном», а потом тонет в неконтролируемой лапше сгенерированного кода. В формате свободной болтовни с ботом естественный язык для написания кода действительно ужасен.
Но естественный язык можно использовать по-другому. Можно не просто болтать с ChatGPT — это ошибочный метод программирования на естественном языке. Его надо использовать как основу для строгих декларативных спецификаций.
Инструменты вроде CodeSpeak (публичная альфа-версия от создателя Kotlin Андрея Бреслава, о которой я подробно писал в своей статье) уже сегодня демонстрируют свой огромный потенциал: если загнать естественный язык в рамки контрактов, он способен стать лучшим, самым высоким из доступных нам уровней абстракции.
Будущее разработки: перекладывание JSON-ов или контроль смыслов через ИИ?
Эволюция роли разработчика: от ручного управления синтаксисом до архитектурного контроля смыслов с помощью ИИ.
Переход от ручного кодинга к управлению спецификациями: почему естественный язык становится новым инструментом архитектурного контроля смыслов, а роль разработчика трансформируется в валидатора ИИ-систем.
Миф №1: «Придется писать в 10 раз больше текста»
Оппонент утверждает, что для точного описания логики на английском или русском потребуется в 10 раз больше слов, чем в коде. Практика CodeSpeak доказывает ровно обратное: объем того, что поддерживает человек, сокращается в 6–10 раз.
В CodeSpeak вместо написания кода вы пишете спецификацию в Markdown-файле .cs.md. Это не роман и не поток сознания. Это структурированный естественный язык, упакованный в жесткий Markdown-формат с четкими разделами (входные данные, структура вывода, требования).
Взгляните на реальный пример спецификации из моей статьи:
``` # EmlConverter
Converts RFC 5322 email files (.eml) to Markdown using Python's built-in `email` module.
## Accepts
`.eml` extension or `message/rfc822` MIME type.
## Output Structure
1. **Headers section**: From, To, Cc, Subject, Date as `**Key:** value` pairs 2. **Body**: plain text preferred; if only HTML, convert to markdown 3. **Attachments section** (if any): list with filename, MIME type, human-readable size
## Parsing Requirements
- Decode RFC 2047 encoded headers (e.g., `=?UTF-8?B?...?=`) - Decode body content (base64, quoted-printable) - Handle multipart: walk parts, prefer `text/plain` over `text/html` - For `message/rfc822` parts: recursively format as quoted nested message - Extract attachment metadata without decoding attachment content ```
Здесь нет синтаксического шума, бойлерплейта или ручного управления памятью. Здесь описана чистая бизнес-логика и контракты ввода-вывода. LLM (например, Claude Opus) читает этот файл, генерирует код и тесты. Синтаксис программирования не умирает — он просто поднимается на уровень выше, скрываясь под капотом LLM-компилятора.
Миф №2: Ловушка зеленых тестов
Автор оригинала пугает нас тем, что всего через десяток-другой изменений проект превратится в «клубок», где новые фичи ломают старые, а нейросеть пишет неправильный код, который проходит такие же неправильные тесты (ведь машина выполнила двусмысленный запрос формально верно).
Это реальная проблема, но она решается жесткой архитектурной изоляцией, которую, например, предлагает CodeSpeak или другой аналогичный инструмент разработки.
В CodeSpeak ИИ не работает в режиме «перепиши мне всё». Обычно он ограничен рамками одной или нескольких связанных спецификаций. Изменение логики парсинга писем никогда не сломает модуль оплаты, потому что LLM работает строго в границах локального контракта.
А как же тесты? Да, LLM пишет их сама. Но здесь меняется роль человека: он становится архитектором смыслов. Разработчик больше не ищет пропущенные запятые в Python-скрипте, он проводит ревью спецификаций и сгенерированных тест-кейсов. Двусмысленность устраняется на этапе согласования требований человеком, а не на этапе генерации.
Миф №3: «В точных науках нужен строгий формализм, а не слова»
Оппонент ссылается на аппаратные ограничения и математическую точность. Да, если вы пишете драйвер для видеокарты или ядро СУБД, вам нужен Rust или C++.
Но 90% софта в мире — это бизнес-логика. И здесь уместно вспомнить, как работают сами математики. Дональд Кнут в «Искусстве программирования» дает алгоритмы в строгом MIX-ассемблере, но обязательно подробно объясняет их на естественном языке.
В точных науках формулы нужны для строгого доказательства, а естественный язык — для передачи интуиции и смысла. Математики не общаются только формулами, иначе они бы не поняли друг друга.
В программировании будущего будет точно так же:
Человек использует естественный язык для проектирования архитектуры и бизнес-правил.
LLM берет на себя «механические вычисления» — трансляцию этих правил в Python, Java или Go.
Комментарии в коде — лучшее доказательство
Вспомните самую сложную и запутанную часть вашей кодовой базы. Скорее всего, над ней висит огромный комментарий на естественном языке.
Почему? Потому что код отвечает на вопрос «как», а естественный язык отвечает на вопрос «зачем». Код не способен передать высокоуровневую мотивацию и граничные случаи так же емко, как это делает человеческая речь. И именно эти комментарии сегодня помогают LLM-моделям при рефакторинге не терять суть задачи. Так почему бы не сделать эти «комментарии» самим источником истины (Source of Truth)?
Эволюция языков программирования не остановится на Python
Мы уже прошли долгий путь: машинный код → ассемблер → C → Java/Python. Каждый шаг — это отказ от ручного контроля в пользу более высокой абстракции.
Делегирование рутины компиляторам — это естественный прогресс. Да, пока мы находимся на этапе тестирования публичных альфа-версий подобных инструментов, но LLM — это просто следующий, сверхмощный компилятор, который уже сегодня понимает естественный язык без критических галлюцинаций, если его загнать в достаточно простые рамки формализма спецификаций.
Естественный язык в виде неструктурированной болтовни — действительно худший инструмент разработчика. Но естественный язык, упакованный в достаточно строгие контракты с автоматической кодогенерацией и тестами — это лучший язык программирования. Он детерминирован рамками модуля, он понятен бизнесу, и он позволяет инженеру быть инженером, а не синтаксическим принтером.
Пришло время перестать бороться с естественным языком и научиться его правильно готовить.
Что думаете? Готовы ли вы делегировать написание кода LLM, оставив за собой контроль контрактов, или продолжите вручную перекладывать JSON-ы до пенсии?
Команда разработчиков под руководством Андрея Бреслава, российского разработчика и автора языка программирования Kotlin, представила публичную альфа-версию нового инструмента для разработчиков — CodeSpeak. Платформа позиционируется как язык программирования нового поколения, в котором инженеры пишут спецификации на английском языке, а нейросети берут на себя генерацию, тестирование и рефакторинг исполняемого кода. Полноценное внедрение инструмента позволяет сократить объем кодовой базы в проектах в пять-десять раз. Технология поддерживает интеграцию в существующие сложные проекты на Python.
ИИ-язык, созданный для людей
CodeSpeak — язык программирования нового поколения на базе LLM
Переход от кода к управлению смыслом
В феврале 2026 года проект CodeSpeak перешел в стадию открытого альфа-тестирования, предложив инженерам концепцию поддержания спецификаций вместо исходного кода. Платформа представляет собой консольную утилиту, которая интегрируется в рабочее окружение и выступает прослойкой между разработчиком, пишущим требования на английском языке, и большой языковой моделью, которая эти требования реализует. В качестве основного движка генерации CodeSpeak использует модель Claude Opus 4.6 от компании Anthropic.
Основной метрикой эффективности CodeSpeak разработчики называют кратное уменьшение объема проекта, с которым напрямую взаимодействует человек. На примере перевода существующих open-source библиотек под управление платформы, объем исходных файлов сокращается в среднем от шести до десяти раз. Человеку остается поддерживать только короткий текстовый документ, описывающий суть алгоритма, в то время как техническая реализация скрыта под капотом системы тестирования и сборки.
В отличие от популярных чат-ботов и ИИ-агентов, CodeSpeak ориентирован не на быстрое прототипирование, а на долгосрочную поддержку продакшен-систем. Платформа изначально создавалась для работы в командах и подразумевает управление сложной архитектурой. Система умеет разворачивать проекты с нуля, однако ее главная особенность заключается в способности встраиваться в существующие кодовые базы и локально перехватывать управление отдельными модулями, не нарушая работу остального приложения.
Эволюция абстракций: от Kotlin к спецификациям
Переход к разработке на естественном языке стал для Андрея Бреслава логичным продолжением его предыдущей работы. Во время работы в JetBrains в 2010-х годах он спроектировал язык Kotlin с целью избавить Java-разработчиков от избыточного шаблонного кода. В то время синтаксис Kotlin позволил автоматизировать множество рутинных операций на уровне компилятора, сделав программы более читаемыми.
С развитием больших языковых моделей проблема избыточности вышла на новый уровень. По мнению Бреслава, огромный пласт современного кода является очевидным не только для инженера, но и для алгоритмов машинного обучения. Если раньше компилятору требовались точные синтаксические конструкции для понимания задачи, то сегодня нейросеть способна извлечь нужную техническую реализацию из своего внутреннего представления, обученного на всем мировом открытом коде. Это делает ручное написание стандартных алгоритмов неэффективной тратой времени.
При разработке CodeSpeak команда исходила из того, что программирование исторически двигалось по пути повышения уровня абстракций: от машинных кодов к ассемблеру, затем к языкам высокого уровня вроде C и Java. CodeSpeak рассматривается как следующий шаг в этой иерархии, где уровень абстракции поднимается до естественного языка, а языковая модель выполняет роль сверхмощного компилятора, генерирующего итоговую логику.
Архитектура файлов и автоматическое тестирование
Процесс разработки в CodeSpeak кардинально отличается от классического цикла. Точкой входа служит файл с расширением .cs.md, содержащий спецификацию конкретного модуля. Инженер описывает в нем структуру данных, логику обработки и форматы вывода. После запуска команды сборки система анализирует этот файл, собирает контекст проекта и передает план действий языковой модели.
Важнейшим элементом архитектуры платформы является автономное тестирование. В процессе сборки CodeSpeak не просто генерирует код, но и самостоятельно пишет модульные тесты для проверки заявленных в спецификации требований. Если тесты не проходят, система итеративно исправляет сгенерированный код до тех пор, пока функциональность не будет полностью соответствовать тексту. Для разработчика процесс выглядит как компиляция: на входе подается текстовое описание, на выходе получается рабочий и протестированный модуль.
В текущей версии система глубоко интегрирована с экосистемой Python и менеджером пакетов uv. Инструмент автоматически управляет виртуальными окружениями и зависимостями, позволяя создавать полноценные веб-приложения, например, на базе фреймворка Django, буквально из одного файла спецификации.
Анатомия спецификации: как ИИ понимает задачу
Чтобы понять, как абстрактный текст превращается в детерминированную логику, достаточно взглянуть на структуру типичного исходника CodeSpeak. На прикрепленном к статье демонстрационном видео показан процесс работы с платформой, где разработчик оперирует исключительно такими текстовыми контрактами.
Допустим, нам нужно написать конвертер для разбора сохраненных почтовых сообщений. Вместо написания десятков строк на Python разработчик создает файл eml_converter.cs.md со следующим содержимым:
# EmlConverter
Converts RFC 5322 email files (.eml) to Markdown using Python's built-in `email` module.
## Accepts
`.eml` extension or `message/rfc822` MIME type.
## Output Structure
1. **Headers section**: From, To, Cc, Subject, Date as `**Key:** value` pairs
2. **Body**: plain text preferred; if only HTML, convert to markdown
3. **Attachments section** (if any): list with filename, MIME type, human-readable size
Из этой спецификации система автоматически генерирует два артефакта: непосредственно исполняемый Python-компонент (например, eml_converter.py) и набор юнит-тестов (test_eml_converter.py). Система самостоятельно прогоняет тесты и убеждается, что функция корректно обрабатывает структуру файлов, извлекает нужные заголовки и не падает при отсутствии вложений.
Главная ценность такого подхода заключается в жесткой изоляции. Так как спецификация предельно четкая и имеет строгие контракты ввода-вывода, ИИ-агенту не нужно выдумывать, что именно реализовать, или галлюцинировать дополнительный функционал. Нейросеть ограничена рамками Markdown-файла. Если спустя время разработчику понадобится добавить извлечение даты получения письма, он просто допишет одну строку в раздел «Output Structure» в .cs.md файле. После команды сборки CodeSpeak обновит исключительно eml_converter.py и его тесты, совершенно не затрагивая остальную кодовую базу проекта.
Режим частичной интеграции и перевод легаси-кода под управление спецификациями
Понимая, что переписать существующие энтерпрайз-проекты с нуля практически невозможно, создатели CodeSpeak предусмотрели возможность частичной интеграции. В так называемом смешанном режиме (Mixed Mode) разработчик может инициализировать CodeSpeak внутри старого репозитория и строго ограничить список файлов, с которыми системе разрешено взаимодействовать. Это позволяет внедрять новые функции через текстовые спецификации, не подвергая риску устоявшуюся архитектуру.
Для работы с уже написанным кодом реализован механизм автоматического реверс-инжиниринга и передачи управления (команда takeover). Инженеру достаточно указать утилите конкретный исходный файл: система проанализирует алгоритмы и извлечет их бизнес-логику, сгенерировав для нее новый текстовый Markdown-файл со спецификацией. В официальном блоге проекта приводится показательный пример с конвертером форматов из библиотеки Microsoft MarkItDown, где CodeSpeak успешно превратил сотни строк Python-кода в лаконичное текстовое описание правил парсинга.
Как только существующий код переведен под контроль платформы, править оригинальные исходники вручную больше не нужно. Если в дальнейшем потребуется, например, добавить обработку нового поля в почтовом сообщении, разработчик просто вписывает одно дополнительное требование в Markdown-спецификацию. Опираясь на это обновление, CodeSpeak самостоятельно перепишет исходный код конвертера, создаст нужные вспомогательные методы и расширит тестовую базу для проверки новых требований.
Проблема потерянного контекста в ИИ-кодинге
Архитектура CodeSpeak решает одну из главных проблем современных ИИ-помощников вроде Cursor или GitHub Copilot. При использовании агентов инженер формулирует свои намерения в интерфейсе чата. Агент выдает готовый код, который затем отправляется в репозиторий проекта. При этом сам диалог, содержащий истинный смысл и бизнес-логику решения, теряется навсегда.
Бреслав отмечает, что при таком подходе коллеги разработчика видят только результат работы машины, а не изначальное намерение. Код становится языком общения между инженерами, хотя изначально он генерировался машиной для машины. В долгосрочной перспективе это приводит к усложнению код-ревью и потере контроля над архитектурой, так как тестировать и проверять огромные массивы сгенерированного кода без понимания изначальной логики практически невозможно.
Платформа CodeSpeak меняет этот парадокс, фиксируя диалог с ИИ в виде статических файлов спецификаций. Спецификация становится главным артефактом, подлежащим контролю версий и код-ревью. Команда обсуждает и утверждает смысловую часть алгоритма, оставляя валидацию синтаксиса на откуп автоматизированным тестам.
Следующий уровень абстракции: ИИ-агенты как авторы спецификаций
Подход с использованием формальных спецификаций решает проблему масштабирования и поддержки больших кодовых баз, однако ручное создание таких документов, вероятно, окажется лишь промежуточным этапом в эволюции разработки. Логика развития инструментов на базе больших языковых моделей указывает на то, что в обозримом будущем инженеры перестанут писать даже сами спецификации.
Вместо структурированных файлов разработчик будет формулировать бизнес-требования на свободном естественном языке — в виде высокоуровневых продуктовых пожеланий или пользовательских историй. ИИ-агенты возьмут на себя роль системных аналитиков: они будут переводить неструктурированный текст от человека в строгие формальные спецификации. Этот процесс станет логичным развитием механизма реверс-инжиниринга, который уже сейчас используется в CodeSpeak для генерации контрактов из старого кода. Сформировав спецификацию, машина самостоятельно сгенерирует по ней исполняемый код и тесты.
В такой парадигме роль программиста кардинально меняется. Навык написания формальных контрактов с нуля будет требоваться крайне редко, уступая место навыку аналитического чтения. Главной задачей разработчика станет умение читать спецификации, понимать заложенную в них архитектуру и верифицировать логику. Человеку предстоит выступать в роли валидатора, который проверяет, правильно ли ИИ-агент интерпретировал изначальную бизнес-идею, прежде чем эта спецификация превратится в работающий продукт. Фокус профессии окончательно сместится от создания строк кода или текста к экспертной оценке и управлению смыслом.
Иллюзия программирования естественным языком и преждевременные похороны джуниоров
Развитие ИИ-агентов породило в индустрии феномен, который западные разработчики в шутку окрестили vibe-coding — подходом, при котором человек просто описывает желаемый результат текстом, а нейросеть выдает готовое приложение. На фоне резкого скачка возможностей моделей многие компании начали замораживать наем младших разработчиков, ошибочно полагая, что алгоритмы способны полностью заменить начинающих специалистов.
В большом интервью, видео которого представлено ниже, Андрей Бреслав прямо называет массовый отказ от найма джуниоров глупой и временной ошибкой рынка. По его словам, управленцы сейчас ослеплены хайпом вокруг ИИ-инструментов, но эта эйфория неизбежно пройдет, когда индустрия столкнется с необходимостью поддерживать сгенерированные проекты на длинной дистанции. Рано или поздно бизнес осознает, что для развития технологий в индустрию должен постоянно поступать приток новых людей.
Главная проблема бездумного делегирования заключается в потере контроля. Бреслав подчеркивает, что если всю архитектурную работу начнут выполнять исключительно модели, а люди перестанут понимать, как именно работает код, это приведет к потере субъектности инженера. Задача человека — управлять так называемой «сущностной сложностью» (essential complexity), точно формулировать намерения и принимать технические решения. Машина выступает лишь исполнителем, и для корректной постановки задач ей по-прежнему требуется полноценный инженерный склад ума.
Начинающим разработчикам создатель Kotlin советует не поддаваться панике, а извлекать из ситуации выгоду. С одной стороны, необходимо в совершенстве освоить новые ИИ-инструменты, чтобы многократно повысить свою продуктивность. С другой — использовать освободившееся время для максимально глубокого погружения в фундаментальные, хардкорные основы программирования. Умение разобраться в том, как всё устроено «под капотом», вскоре станет редкой и крайне востребованной экспертизой на рынке, переполненном операторами нейросетей.
Ближайшие перспективы проекта
На данный момент CodeSpeak имеет статус альфа-версии и требует от пользователей готовности к техническим шероховатостям. Команда проекта фокусируется на улучшении механизмов синхронизации: система должна гарантировать, что при удалении кода его всегда можно в точности восстановить из спецификации, а любые изменения текста транслируются в адекватные изменения архитектуры. Несмотря на раннюю стадию, инструмент уже обозначает новый вектор развития индустрии, где главной компетенцией инженера становится умение структурировать сложность и управлять намерениями, а не владение синтаксисом конкретных языков программирования.
Андрей Бреслав — российский программист, один из создателей языка программирования Kotlin (руководитель группы разработчиков в компании JetBrains), сооснователь сервиса подбора психологов Alter.ru, основатель CodeSpeak.
Проект Malus запустил автоматизированный сервис, использующий две изолированные группы нейросетей для переписывания библиотек с открытым исходным кодом. Технология позволяет легально удалять оригинальные лицензии и делать программное обеспечение проприетарным, решая проблему юридических рисков корпоративного сектора, которая оценивается в миллионы долларов ежегодно.
«Чистая комната» как услуга.
Наконец-то свобода от лицензионных обязательств открытого кода. Авторы: Mike Nolan Источник: MalusCorp
Наши проприетарные ИИ-роботы самостоятельно воссоздают любой проект с открытым кодом с нуля. Результат? Юридически независимый код с удобной для корпораций лицензией. Никакого указания авторства. Никакого копилефта. Никаких проблем. Авторы: Mike Nolan Источник: MalusCorp
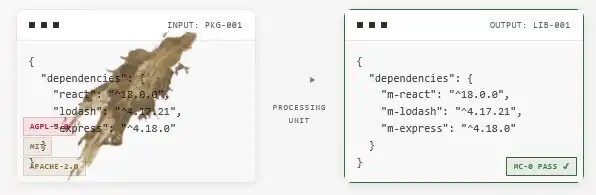
Сервис Malus предлагает бизнесу механизм полного избавления от условий строгих лицензий вроде AGPL, GPL или правил обязательной атрибуции Apache. Клиент загружает файл-манифест с зависимостями своего проекта и получает функциональные аналоги нужных пакетов. Итоговый продукт юридически очищен от прав оригинальных создателей и передается заказчику под новой проприетарной лицензией MalusCorp-0, которая не требует указания авторства и позволяет корпорациям распоряжаться алгоритмами по своему усмотрению.
В основе системы лежит автоматизированный процесс так называемой «чистой комнаты». Первая группа ИИ-агентов изолированно анализирует исключительно публичную документацию, спецификации и интерфейсы оригинального программного обеспечения. Вторая группа, физически отгороженная от первой и не имеющая доступа к исходным текстам, пишет код с нуля на базе составленного технического задания. Это исключает прямое копирование и переводит процесс из разряда плагиата в категорию независимого воссоздания.
Стоимость услуги рассчитывается динамически по тарифу один цент за каждый килобайт распакованного исходного пакета. По расчетам системы, очистка популярной библиотеки маршрутизации express обойдется в 73 цента, в то время как крупный пакет lodash будет стоить чуть менее 14 долларов.
Прецедент вековой давности: как закон 1879 года легализует машинный код
Идея проекта не является юридической новацией. Она базируется на американском судебном прецеденте Baker v. Selden 1879 года, который жестко разделил концепцию и форму ее выражения. Закон об авторском праве защищает конкретный текст программы, но не саму идею или заложенную в нее функцию. Тот, кто сможет реализовать аналогичный механизм с нуля, не заглядывая в чужие исходники, становится полноправным владельцем нового продукта.
В 1984 году компания Phoenix Technologies использовала этот принцип для легального клонирования базовой системы ввода-вывода от IBM. Один инженер месяцами изучал документацию и писал спецификацию, а другой, никогда не видевший оригинального кода, создавал совместимый аналог. Этот проект занял несколько месяцев ручного труда, но позволил сторонним производителям материнских плат легально запускать любые операционные системы без отчислений оригинальному разработчику.
Процесс «чистой комнаты» всегда был невероятно дорогим занятием, требующим штата юристов и жесткой дисциплины. Новация платформы Malus заключается в делегировании этой сложной юридической процедуры нейросетям. Первая группа алгоритмов выступает в роли первого инженера, изолированно читая документацию, а вторая берет на себя роль исполнителя, моментально генерируя «чистый» код. По заявлению создателей платформы, известная микробиблиотека left-pad воссоздается системой за десять секунд, а первая в истории видеоигра Spacewar — всего за пять.
Юридическая база столетней давности в сочетании с машинным обучением превращает авторское право из непреодолимой защиты сообщества разработчиков открытого кода в формальность, которую легко автоматизировать.
Цена бесплатного труда: почему корпорации видят угрозу в открытом коде
В программном манифесте, опубликованном 1 марта 2026 года, генеральный директор Malus Майк Нолан формулирует главную проблему корпоративного сектора: мировая цифровая инфраструктура держится на энтузиазме волонтеров. Бизнес получает программное обеспечение бесплатно, но расплачивается за это отсутствием гарантий, технической поддержки и контроля над цепочками поставок.
Проблема имеет конкретное финансовое выражение. По оценке создателей сервиса, среднестатистическая корпорация со штатом более пятисот инженеров ежегодно тратит около четырех миллионов долларов на управление рисками открытого кода. Эти средства уходят на инструменты анализа уязвимостей, работу юристов и содержание специальных отделов по надзору за соблюдением лицензий.
Зависимость от чужих библиотек регулярно приводит к масштабным кризисам. В декабре 2021 года критическая уязвимость Log4Shell в утилите ведения логов заставила инженеров по всему миру экстренно закрывать бреши на серверах, пока неоплачиваемые авторы оригинального кода получали тысячи гневных писем от корпораций.
Возникают и ситуации намеренного саботажа: в январе 2022 года создатель популярных пакетов colors.js и faker.js внедрил бесконечные циклы в свой код в знак протеста против его использования крупным бизнесом без финансовой отдачи. В марте того же года разработчик утилиты node-ipc добавил функционал удаления файлов на компьютерах пользователей по геополитическим мотивам.
В такой парадигме использование открытого исходного кода становится для корпораций непредсказуемой структурной уязвимостью. Платформа Malus предлагает решить эту проблему радикально: разорвать социальный контракт с разработчиками и заменить их полностью подконтрольным машинным кодом.
Анатомия цифрового цинизма: где заканчивается шутка и начинается бизнес
Несмотря на наличие работающей системы оплаты и реальную возможность загрузить файл конфигурации для обработки, проект Malus является масштабной сатирой, приуроченной к выступлению Майка Нолана на европейской конференции разработчиков FOSDEM в 2026 году. За фасадом стартапа, публикующего вымышленные отзывы корпоративных менеджеров о том, что чувство вины не отображается в квартальных отчетах, скрывается жесткая критика современной технологической индустрии.
Именно здесь ирония проекта достигает своего пика и становится пугающе точной. Вместо того чтобы выстроить систему справедливой компенсации для уставших программистов-энтузиастов, на которых держится вся мировая архитектура, гиганты индустрии предпочитают искать юридические лазейки. Платформа едко высмеивает эту корпоративную логику: компаниям проще нанять ИИ-агентов, которые за доли секунды сотрут лицензию и уничтожат любые следы авторства, чем поддержать создателя оригинальной идеи.
Реакция профильных сообществ показала, что граница между шуткой и реальностью окончательно стерта. В ходе обсуждений на площадке Hacker News многие инженеры восприняли платформу как настоящую коммерческую угрозу. Специалисты отметили, что описанный юридический механизм технически реализуем уже сегодня, а автоматизированное правоприменение радикально меняет правила игры. Как только стоимость обхода лицензии становится ниже стоимости судебного разбирательства, система защиты авторских прав начинает давать сбой.
Юридический парадокс современного рынка технологий
Проект Malus подсветил фундаментальный парадокс современного рынка технологий. Искусственный интеллект, обученный на массивах бесплатного программного обеспечения, теперь используется для того, чтобы лишить создателей этого самого обеспечения последних юридических рычагов влияния.
Открытым остается лишь вопрос о том, как скоро подобная едкая антиутопия окончательно станет реальностью: потребуется ли индустрии отдельный судебный прецедент для оценки машинной «чистой комнаты», или автоматическая очистка кода и обход лицензий незаметно превратятся в стандартный бизнес-процесс для транснациональных корпораций.