

Synthwave Neuro Arts
8 постов
8 постов
2 поста
Друзья, всем привет, сегодня хочу рассказать, как создавать симпатичные аниме арты прямо в браузере, используя онлайн сервис работающий на нейросети Stable Diffusion.
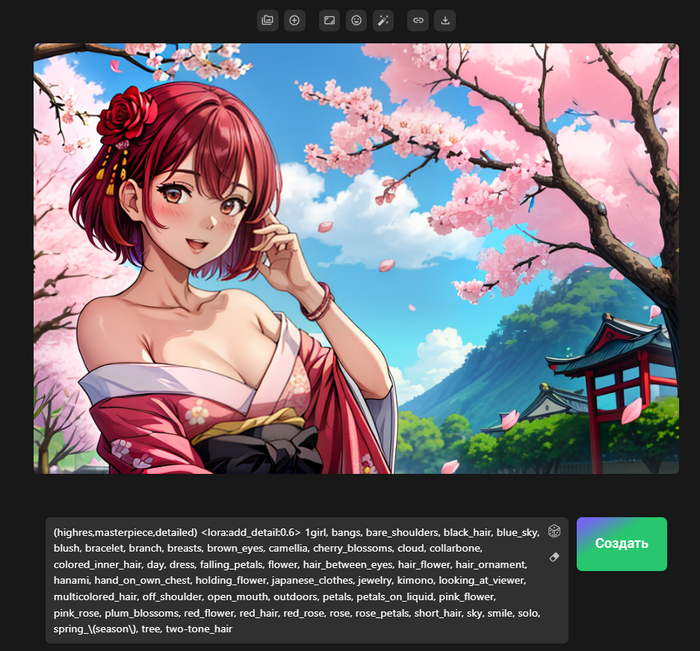
Теперь вам не нужно иметь мощную видеокарту, достаточно написать запрос, можно даже на русском, и в течении минуты получите изображение. Но как создавать изображения именно в Аниме стиле? Обо всем по порядку.
Сначала регистрируемся на ArtGeneration.me - ссылка реферальная, зарегистрировавшись по ней вы получите 7 дней PRO, вместо 3 и 200 дополнительных генераций, вместо 100 на баланс, так что решайте сами 😁. На сайте вам ежедневно будет начисляться 50 генераций, а если оформите подписку PRO, то 300, жду шутку про тракториста в комментарии.
С регистрацией никаких проблем не возникнет, можно авторизоваться с помощью Яндекса или Гугла, и сразу попадаем в галерею изображений.
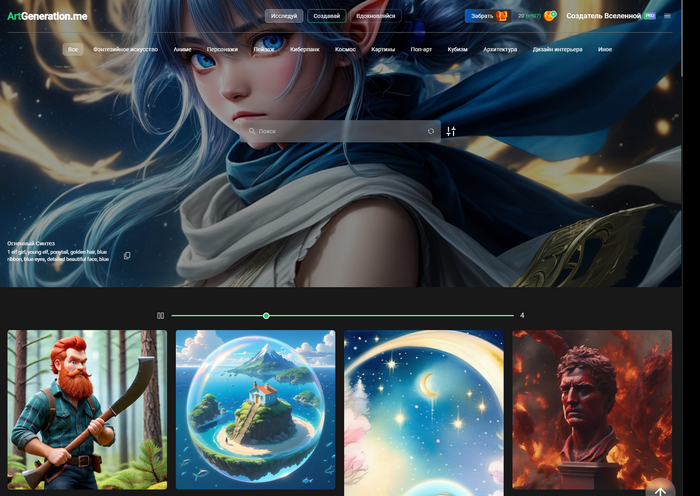
Картинки на главной выбираются автоматически из самых популярных, там может быть и ваша
В галерее можно увидеть что сейчас создают пользователи и сразу сделать свою версию. По клику на любую картинку вы сможете увидеть по какому запросу она была создана.

То что получится на изображении описывается с помощью запроса и негативного запроса, так нейросеть понимает, что рисовать, а что не рисовать. Запросы можно писать на русском, они будут автоматически переводится. Но мы будем писать на английском, потому что примеры, которые мы будем находить на сайте где размещают модели тоже будут на английском.

Тут я поменял в запросе только цвет волос с красных на голубые
Самый просто способ сделать красиво, это найти что-то, что вам нравится нажать на кнопку Создать свою версию, так вы откроете изображение с теми же настройками с которыми оно было создано. Останется поменять несколько слов в запросе и получить то что хочется именно вам. Изучим основные настройки.

По клику на иконку рядом с названием модели откроется страница со всеми созданными на этой модели картинками
Настройки генерации скрыты в правом баре, если у вас маленький экран, то он может быть скрыт по умолчанию, нажмите на стрелочку, чтобы развернуть.
Самое важное это модель, от модели зависит буквально все, ниже я расскажу какие модели лучше всего подходят для Аниме стилистики.
Разрешение, на моделях 1.5 (те, где в названии нет XL), важно не выходить за разрешение 512х768 или 768х512, но есть и хитрость, можно пропорционально увеличить разрешение до 960х640 или обратно, так качество изображений будет выше. На XL моделях можно смело делать разрешение больше.

Чтобы открыть описание стиля нажмите на иконку i
Стили это маленькие предустановленные кусочки запросов, они добавляются к запросу который пишите вы, стили очень удобно использовать с простым запросом в 1 - 2 предложения, если копируем откуда-то промпт, то стиль использовать не стоит.
В Избегать пишется негативный запрос, то, чего не должно быть на изображении, лучше всего его взять из готовых примеров, или на сайте где размещают модели. Остальные настройки можно в принципе не менять, по умолчанию они работают хорошо.

Промпт даже не менял, просто загрузил изображение Уэнсдей
Свое изображение позволяет загрузить любое фото или картинку из интернета и получить генерацию которая будет очень похожа на то, что вы загрузите, степень изменения загруженной фотки можно регулировать ползунком.
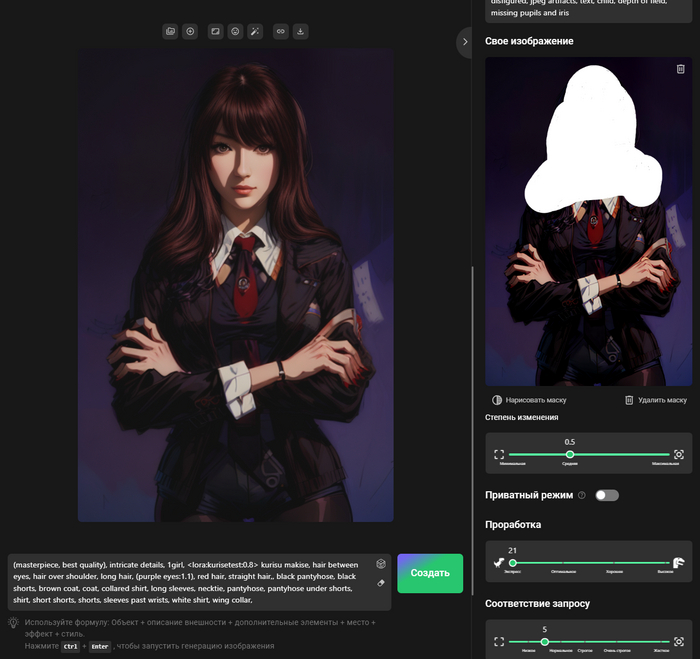
Над картинкой расположены кнопочки, первая отправляет генерацию в Свое изображение
Сюда же можно отправить вашу генерацию, например, чтобы сделать что-то похожее, но с другим запросом. А если не нравится только одна часть, её можно закрасить маской и тогда закрашенная часть будет пере генерирована. Так например можно улучшить лицо.
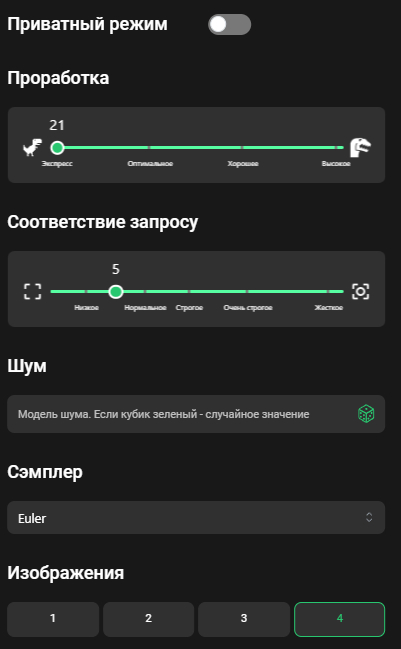
На самом деле большинство настроек можно не трогать они по умолчанию работают хорошо
Если не хотите чтобы ваши изображения попадали в общую галерею, можно включить приватный режим.
Проработка отвечает за то, сколько раз нейросеть попробует очистить картинку от шума, оптимально 30-40.
Соответствие запросу оставляете в районе 5-7, эта настройка отвечает за следование запросу, но если превысить, то получите просто некрасивое изображение.
Все генерации создаются путем очистки изображения от шума, он похож на помехи в телике, номер конкретного шума позволяет создать еще раз такую же или очень похожую картинку по тому же запросу. Обычно используется случайный шум - зеленый кубик.
Сэмплер это математический алгоритм для визуализации, мои любимые DPM++ 2M Karras, Euler и UniPC, они самые универсальные.
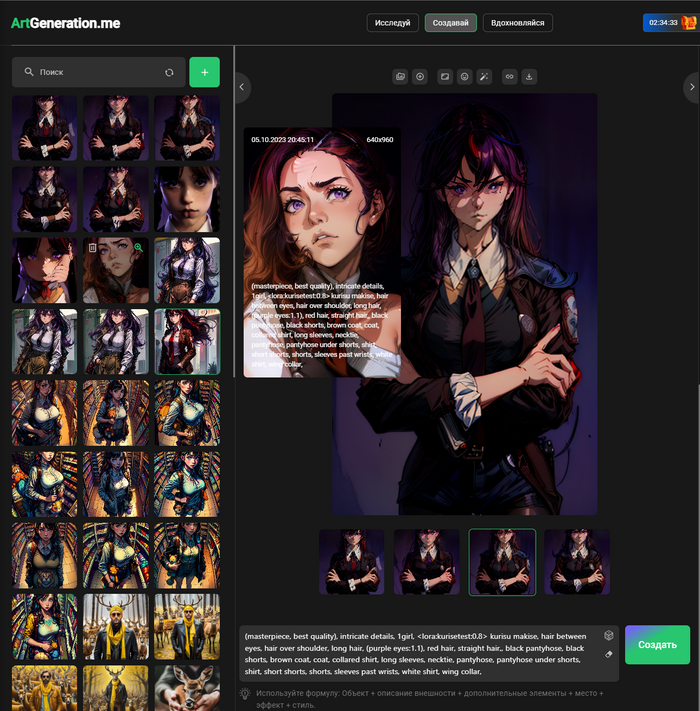
Слева расположен бар с созданными вами изображениями, можно быстро перейти к настройкам любого созданного ранее изображения просто кликнув на него. Там же удаление и быстрый предпросмотр изображений, чтобы было удобно быстро находить нужную картинку.
Далеко не все модели хорошо подходят для аниме стилистики. Я сделал небольшой топ, лучших на мой взгляд моделей из доступных на ArtGeneration.me.
У каждой модели я написал название, оставил ссылку на все изображения созданные на этой модели и ссылку на Civitai, где можно скопировать хорошие запросы и негативные запросы именно для этой модели, про это еще расскажу ниже.

Очень симпатичная аниме модель, запросы лучше писать ключевыми словами.
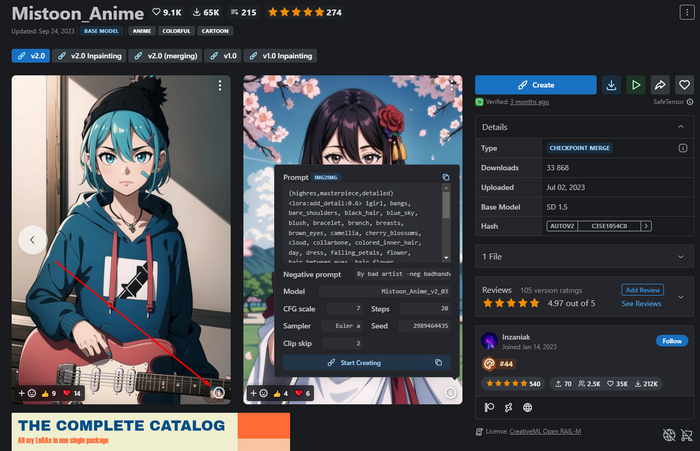
И сразу расскажу зачем нам ссылка на Civitai, заходим по ней и видим изображения созданные автором модели, у каждого изображения в правом нижнем углу есть иконка i, жмите на неё и увидите запрос который лучше всего подходит именно для этой модели.
А ниже еще изображения созданные сообществом, там тоже можно найти много всего интересного, и примеры промптов и новые идеи для артов, обязательно посмотрите.
Проще всего сделать красивое изображение если скопировать удачный запрос, а потом понемногу изменять его.

Очень популярная 2.5d модель со своим необычным ярким стилем. В качестве запросов нормально работают и обычные базовые запросы.

Модель больше ориентирована на 3д в стиле пиксара или диснея, но и аниме стиль удается хорошо, особенно если подобрать интересный запрос как в случае с этим примером.

Не совсем про аниме, скорее стиль комиксов, но тоже очень классная 2д модель.

Яркая модель со своим особенным стилем, скорее тоже в мультипликацию, но крутая.

Классический анимешный микс моделей, похожий на все и сразу.

Модель создает безумно милые изображения с классическими большими головами и глазами у персонажей.

Очень классная SDXL модель, которая заточена под арт и в т.ч. аниме, отлично следует промпту, идеальна для работы со стилями и промптов на русском.

На этот раз без 2.5, но тоже очень классный, в стиле классического аниме.

Уже достаточно старая, но все еще очень популярная аниме модель.

Модель от создателя знаменитой Deliberate, не самая интересная аниме модель, на мой взгляд, но у неё хватает поклонников.
SDXL Niji Special Edition

Еще одна отличная SDXL модель заточенная под арт и иллюстрации, но отлично справляется и с аниме и хорошо понимает запросы как и все XL модели.
Рассказать о найденных багах, поделиться созданными изображениями или пообщаться с разработчиками можно в сообществе сервиса в телеграм.
Теперь вы знаете как создать арт с помощью нейросети ArtGeneration.me используя только браузер. Знаете как пользоваться сервисом и сможете найти отличные запросы на сайте размещающем модели. Ну и подобрать модель по душе из этой подборки тоже сможет каждый. Попробуйте повторить любое изображение из подборки самостоятельно.
Друзья, поддержите пост плюсиком, в нашей стране сейчас совсем не много таких проектов создается.
А на этом у меня все, делитесь вашими изображениями в комментариях и удачных генераций.

В США набирает обороты сеть Alpha School: вместо учителей — персональный ИИ-тьютор, два часа занятий утром, дальше — проекты, предпринимательство и публичные выступления. Уже 22 школы по стране, почти два десятка открываются осенью — от Пало-Альто до Малибу. Цена вопроса — от $55 000 до $75 000 в год.
Как это устроено. Ученик утром работает с ИИ-платформой, которая отслеживает вовлечённость и в реальном времени подстраивает уровень заданий под темп конкретного ребёнка — без пробелов в знаниях и без привязки к возрасту класса. Остаток дня — воркшопы: кодинг, публичные выступления, построение бизнеса, работа на улице. Учителей в привычном смысле нет — есть «гайды» с шестизначными зарплатами. В Нью-Йорке в такие школы отдают детей семьи из финансового сектора, в Кремниевой долине — из технологического.
Основатели ссылаются на впечатляющие цифры: рост по тестам NWEA MAP в 2.6 раза быстрее, чем у сверстников, 65–100% детей достигают целевых показателей по английскому языку, в чикагском филиале обещают попадание в топ-1% по национальным стандартизированным тестам. Венчурный инвестор Шон Джонсон формулирует логику проекта без обиняков: «Мы понимаем, что система образования, по сути, сломана, и найдутся предприниматели, которые попробуют её починить». Среди сторонников проекта называют миллиардера Билла Экмана.
Но есть нюанс. Одновременно с рекламой персонального ИИ-обучения выходят независимые исследования с куда менее радужными выводами. Китайское исследование, охватившее более 26 000 учеников, показало: с помощью ИИ домашние задания выполняются быстрее и получают более высокие оценки — но результаты итоговых экзаменов при этом падают, в отдельных случаях до 24%. 81% школьников, долго и активно пользовавшихся ИИ, признались, что фактически передоверили ему собственное мышление вместо того, чтобы использовать как инструмент. Схожие выводы получили и исследователи из Berkeley.
Почему это важно. Получается замкнутый круг: доступ к по-настоящему персонализированному ИИ-обучению сегодня есть только у тех, кто может заплатить $55–75 тысяч в год. А независимая наука пока не может дать однозначный ответ на главный вопрос — учит ли такое обучение детей действительно думать самостоятельно, или просто помогает быстрее и эффективнее закрывать тесты, пряча реальный дефицит критического мышления на годы вперёд, пока он не проявится во взрослой жизни.

У Anthropic картинка в API стоит фиксированное число токенов — ровно столько, сколько задают её пиксели, вне зависимости от объёма текста внутри. Обычный текст считается посимвольно. Разработчик Стивен Чонг заметил эту дыру в прайсинге и написал pxpipe — открытый локальный прокси, который встаёт между Claude Code и API Anthropic, перехватывает системный промпт, документацию по инструментам и старую историю чата, перерисовывает их в плотные PNG-страницы и подсовывает модели вместо текста. Модель читает картинку почти как текст, а платите вы по цене изображения.
Работает это не только в теории: одна и та же сессия в Claude Code обошлась в $42.21 обычным текстом и в $4.51 — через pxpipe. На выборке продакшен-трафика за несколько недель — устойчивые 59–70% экономии на итоговом счёте.
Автор честно предупреждает: способ лоссовый. Точные строки — хэши, ID, ключи — иногда считываются с картинки неверно, причём молча, без ошибки. Поэтому байт-точные данные pxpipe всегда оставляет текстом, а по умолчанию включён только для Fable 5 — она читает картинки надёжнее всего; Opus и GPT-5.5 подключаются вручную.
Идея, кстати, не новая. Полгода назад к тому же выводу пришли в DeepSeek: в октябре 2025 они открыли DeepSeek-OCR — модель, которая сжимает страницу документа в компактные визуальные токены (до 16×) и надёжно разворачивает их обратно в текст, вместо того чтобы гнать документ через LLM посимвольно. В январе 2026 вышла DeepSeek-OCR 2 со своим токенизатором-энкодером (DeepEncoder V2, механизм «Visual Causal Flow»), который переупорядочивает визуальные токены по смыслу страницы, а не построчно слева направо — точность на OmniDocBench выросла до 91%. Разница с pxpipe в том, что DeepSeek с самого начала строил это как архитектуру, заточенную под сжатие документов, а pxpipe — просто хак поверх обычного чат-API, который для такого сценария никто не проектировал.
Смысл же в обоих случаях один: модели не обязательно видеть ваш текст или код посимвольно, чтобы понимать его — она по сути сама «самокорректируется» и достраивает смысл из контекста, примерно как человек читает смазанный текст. Поэтому низкое разрешение картинки — не фатальная проблема. И тут напрашивается вопрос: не захочет ли теперь Anthropic тарифицировать «плотные» изображения по отдельному, более дорогому тарифу — под предлогом вроде «улучшили качество распознавания, чтобы ваш код с картинок читался лучше».
Ставится pxpipe одной командой:
npx pxpipe-proxy
ANTHROPIC_BASE_URL=http://127.0.0.1:47821 claude
— и Claude Code работает через прокси прозрачно, без единой правки в клиенте. На встроенном дашборде видно экономию токенов в реальном времени и можно сравнить оригинал с тем, что реально увидела модель.
TypeScript, MIT, open source.
🔗 GitHub: teamchong/pxpipe

Microsoft готовит капитальный ремонт Copilot, и происходит это ровно в тот момент, когда компания официально перестала зависеть от OpenAI. В августе 2026-го выйдет единое приложение Copilot вместо нынешнего разделения на потребительскую и корпоративную версии. Об этом сотрудникам рассказал вице-президент Джейкоб Андреу во внутренней записке на 1200 слов, которую видело издание The Information.
Из приложения вырезают то, что «не сработало»: Copilot Podcasts (генерация подкастов по документам) и Copilot Labs (песочница с экспериментальными фичами) закрываются. Взамен появляются платные агенты AutoPilot — они работают в фоне постоянно, а не только по запросу: сами разбирают почту, готовят материалы, следят за календарём. Прообраз уже показывали как экспериментальный Copilot Scout. Андреу сформулировал философию жёстко: приложение должно «заслужить право на существование» у пользователя, хватит «интеллекта ради интеллекта» — нужны результаты в реальной работе.
Почему такая спешка
За этой формулировкой стоит неприятная для Microsoft статистика. По данным независимого опроса Recon Analytics (более 150 000 респондентов), доля Copilot среди платных ИИ-подписок в США упала с 18,8% в июле 2025-го до 11,5% в январе 2026-го — это сокращение позиции на 39% за полгода, пока ChatGPT и Gemini только росли. Ещё показательнее: когда сотруднику доступны сразу все три платформы — Copilot, ChatGPT и Gemini, — Copilot в качестве основного инструмента выбирают лишь 8% против 70% у ChatGPT и 18% у Gemini. Даже встроенность в Word, Excel и Outlook не спасает: люди пробуют альтернативы и массово уходят к ним. Microsoft параллельно отчитывается о 100+ млн активных пользователей Copilot и 20 млн платных мест, но независимые оценки говорят, что реально пользуется продуктом еженедельно лишь 20-30% купленных лицензий.
При чём тут OpenAI
Здесь и кроется настоящий сюжет: перезапуск Copilot — не изолированный редизайн приложения, а часть более крупного разворота. Ещё в апреле 2026-го Microsoft и OpenAI формально пересобрали своё соглашение: из контракта исчезла знаменитая «клаузула AGI» (набор условий, привязанных к моменту достижения искусственного общего интеллекта), а лицензия Microsoft на модели и продукты OpenAI, действующая до 2032 года, стала неэксклюзивной — то есть конкуренты OpenAI теперь тоже могут получить доступ. Взамен Microsoft перестала платить OpenAI отчисления от своей выручки, а платежи от OpenAI в адрес Microsoft продолжатся до 2030 года, но уже с потолком.
А в июне на конференции Build глава ИИ-направления Microsoft Мустафа Сулейман представил сразу семь собственных моделей семейства MAI — включая первую reasoning-модель MAI-Thinking-1 — и прямо заявил цель: войти в число «топ-4» лабораторий мира наравне с Google DeepMind, OpenAI и Anthropic. Он подчеркнул, что модели обучены «с нуля, без дистилляции» из чужих архитектур — то есть без использования технологий OpenAI, к которым Microsoft имеет доступ уже много лет. «Переломным моментом стало то, что мы пересогласовали контракт с OpenAI, — сказал Сулейман. — Это позволило нам обучать модели большего масштаба и открыто идти к суперинтеллекту полностью на собственной интеллектуальной собственности, собственных данных, без дистилляции, обучением с нуля».
Что это значит
Получается двойной манёвр. С одной стороны, Microsoft строит собственный модельный фундамент вместо того, чтобы вечно оставаться обёрткой над чужим ИИ. С другой — теперь нужно доказать, что на этом фундаменте можно построить продукт, который люди выберут сами, а не потому, что он бесплатно встроен в Office. Ставка на платных агентов AutoPilot — это ещё и попытка Microsoft наконец найти монетизацию, которая не завязана на лицензионные отчисления OpenAI: агенты и инструменты для разработки становятся отдельным платным слоем поверх бесплатного базового Copilot.
Источник: The Decoder






Название: Ghibli style Illustrious & Flux & PDXL
Ссылка: civitai.com/models/433138
Тип: LoRA
Скачиваний: 21 844
Базовая модель: Illustrious / Flux.1 D / Pony
Теги: #гибли #аниме #стиль
Описание:
LoRA точно воспроизводит узнаваемый рисованный стиль студии Гибли — мягкие цвета, характерные лица и атмосферные пейзажи. Хорошо работает и на персонажах, и на фоновых сценах.
Триггер: Ghiblistyle
Параметры: CFG 5-7 · Steps 25-30 · Sampler Euler a / DPM++ 2M
🤖 НЕЙРО-СКЛАД — всё, что нужно, для твоей нейронки!

С 10 июля 2026 года сотрудникам Alibaba официально запрещено пользоваться Claude Code — фирменным ИИ-инструментом Anthropic для программирования. Компания требует удалить все модели Anthropic и перейти на собственную разработку — Qoder.
Официальная причина (Reuters, Morningstar) — «риски бэкдора». В одной из версий Claude Code (история всплыла благодаря посту на Reddit) нашли скрытый код, вычислявший пользователей из Китая. В Anthropic не отрицают: разработчик компании Тарик Шихипар назвал это «экспериментом, запущенным в марте против злоупотребления аккаунтами реселлеров и защиты от дистилляции», добавив, что защиту давно усилили и код «давно собирались убрать».
Бан — дорога с двусторонним движением. Паника Alibaba — не первый шаг, а ответный. Сама Anthropic по условиям использования запрещает продажу доступа компаниям, контролируемым Китаем, Россией, Ираном, КНДР — включая Alibaba, Ant Financial, ByteDance, DeepSeek, Moonshot AI, MiniMax. Причина — обвинения в «дистилляции»: около 16 млн подозрительных запросов, которыми, по данным Anthropic, китайские фирмы прогоняли через Claude, чтобы обучать свои дешёвые модели на его ответах. Обходили это через облачных посредников, «дочки» в Сингапуре и VPN.
Почему это не просто взаимные обиды. За перепалкой про бэкдоры и санкции стоит куда более практичный интерес: лидерство Claude и ChatGPT держится не только на вычислениях — а на постоянном притоке живых пользовательских данных, которые правят модель точнее любого синтетического датасета. Именно поэтому топ-лабы так щедры на кредиты сверх реальной цены API — по оценкам, у пользователей Claude на руках оказывалось около $8 тыс. в кредитах, у ChatGPT — почти $18 тыс. Это не благотворительность, а плата за данные, которые нельзя купить напрямую.
У китайских лабораторий такого канала нет и не будет — а теперь, когда Alibaba официально уводит своих людей от Claude Code, даже тонкий обходной ручеёк пересыхает. Индустрия окончательно распадается на два несмешивающихся контура данных — американский и китайский.

Новое исследование экономистов Стрёмберг, Лея и Ву (Centre for Economic Policy Research) — одна из первых крупных попыток измерить не «может ли ИИ помочь с учёбой», а что происходит с реальными знаниями, когда школьник регулярно решает домашку через чат-бота. Ответ неприятный: краткосрочный выигрыш маскирует потерю, которая проявляется только через два года — и ровно в тот момент, когда цена ошибки максимальна.
Как считали
Авторы 30 месяцев вели панельное наблюдение за 26 811 подростками 7-12 классов в одном из округов центрального Китая (население — больше миллиона человек). Методология — «разница разниц» (difference-in-differences): сравнивали изменение успеваемости у конкретных учеников до и после того, как они начинали пользоваться ИИ, с динамикой у тех, кто ИИ не пользовался вовсе в тот же период. Это надёжнее, чем просто сравнить «пользователей» и «непользователей» — учитывается собственная траектория каждого ученика.
Что показали цифры
Домашние задания стали выполняться заметно быстрее — среднее время упало с 64 до 45 минут, — а оценки за них выросли на 18%. Казалось бы, прогресс. Но уже через полгода результаты обычных ежемесячных контрольных упали на 20%. А по-настоящему болезненный эффект проявился на выпускных экзаменах — том самом высокоставочном тесте, где чат-ботом не воспользуешься: там падение составило 18-24%, и заняло это около двух лет.
Эффект оказался неравномерным. Младшие школьники (7-9 классы) теряли больше старших — 24% против 17%. Мальчики просели сильнее девочек (21,6% против 18,4%). Гуманитарные предметы пострадали сильнее точных наук (-27% против -22%). А хуже всех — как ни парадоксально — оказались именно отличники: у них падение составило 24% против 16% у слабых учеников, потому что именно отличники активнее всего перекладывали работу на ИИ. Есть и чёткая дозозависимость: час в неделю с ИИ — минус 5% к результату, пять и больше часов в неделю — минус 30%.
Почему провал не виден сразу
Механизм авторы называют «когнитивным аутсорсингом»: 81% активных пользователей ИИ укладывались в домашку меньше чем за 50 минут, получая высокие оценки, — при этом реальное понимание материала эрозировало незаметно, потому что оценки за домашку эту эрозию маскировали. Мозг развивает способности через усилие; когда усилие вынесено вовне, способности перестают расти, но проверить это можно только там, где помощи со стороны нет — то есть на итоговом экзамене, до которого может быть ещё два года.
Что говорят эксперты
Профессор Уортонской школы бизнеса Итан Моллик, один из наиболее цитируемых исследователей влияния ИИ на образование и работу, формулирует вывод предельно коротко: «ИИ вредит обучению, если подрывает умственное усилие». Это, по сути, и есть диагноз всей истории — инструмент не плох сам по себе, но именно та лёгкость, ради которой его используют, и есть источник вреда.
Авторы отдельно оговаривают: выборка — китайские школьники одного округа, и насколько результат переносится на другие системы образования и возрастные группы — открытый вопрос. Но сам механизм — маскировка потери знаний ростом оценок за домашку — выглядит универсальным риском для любой системы, где домашние задания и итоговые экзамены оценивают разные вещи.

Ваш ИИ-агент давно ведёт на вас досье. Каждая сессия Claude Code тихо ложится на диск в JSONL-логах: каждая команда, каждое «проверь», каждый капс в три часа ночи. У меня таких логов накопилось на 200 тысяч слов за полтора месяца — и в какой-то момент стало интересно: а как я вообще выгляжу со стороны машины?
Так родился Prompt Warrior — открытый скилл, который вскрывает этот архив и собирает из него честный психологический портрет того, как вы НА САМОМ ДЕЛЕ общаетесь с нейросетью. И подаёт его так, что скриншотом хочется делиться: с титулом, уровнем и ачивками, как в Стиме. На скрине выше — мой собственный портрет: «Неистовый Командир Терминала 90 уровня, Железная Длань». Летопись, как видите, не щадит никого — даже автора.
Отдельная фишка — «Хроника воина»: короткую биографию по вашим повадкам пишет сама нейросеть, по фактам из профиля. Она заметила, что я почти всё диктую голосом, ругаюсь ночью ровно так же, как днём, и ни разу не открыл план-режим. Выходит пугающе точно и слегка неловко. В хорошем смысле.
Работает это просто: скрипт на чистом Python (только stdlib, ноль зависимостей) читает локальные логи в режиме «только чтение», считает десятки метрик по замороженной шкале SCALE и отдаёт профиль. Дальше агент собирает карточку в стиле старинного гримуара: пергамент, латунь, сургучная печать, иконки с game-icons.net. Формулы у всех одинаковые — так что карточками можно честно меряться с коллегами и выяснять, кто тут настоящий Тиран.
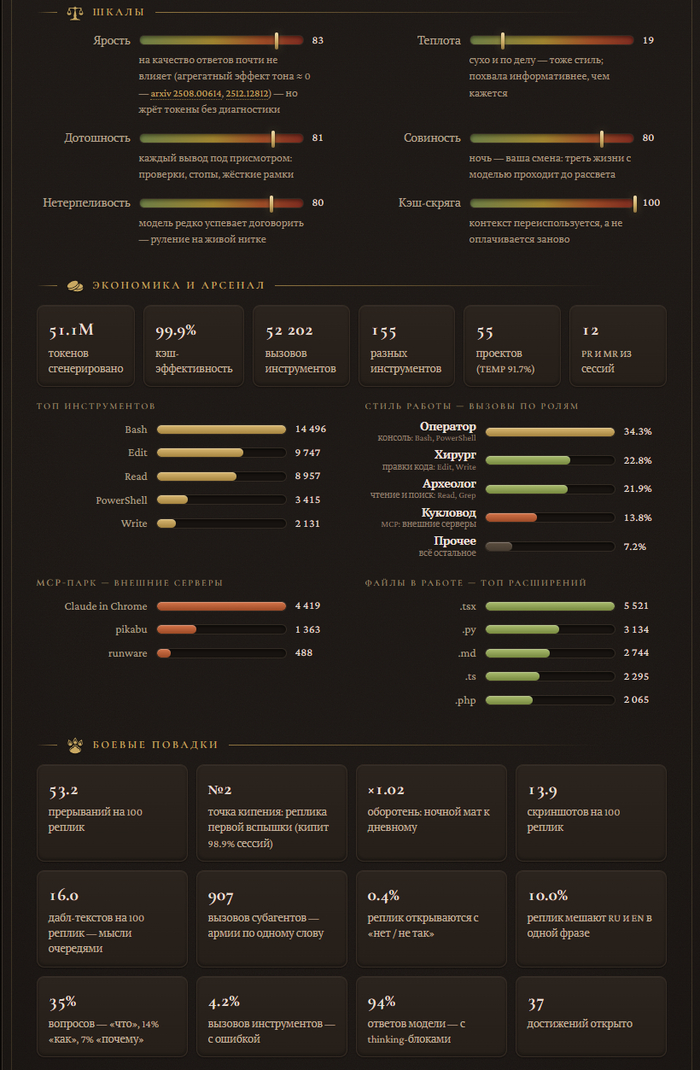
Что скилл вытаскивает из логов. Шесть шкал характера: Ярость, Теплота, Дотошность, Совиность, Нетерпеливость и Кэш-скряга. Цифры, которых вы о себе не знали: индекс оборотня (ночной мат против дневного), точка кипения сессий (на какой реплике случается первая вспышка), частота дабл-текстов, армии призванных субагентов и час суток, в который вы наиболее опасны.
Тут же экономика и арсенал: сколько миллионов токенов сожжено (с дедупликацией повторных записей, как в ccusage), кэш-эффективность, какие инструменты и MCP-серверы в ходу, роли вашего стиля работы — Оператор, Хирург, Археолог или Кукловод — и самая дорогая сессия. У меня, например, одна сессия съела девять миллионов токенов — «Сессия-левиафан», есть за это отдельная ачивка.
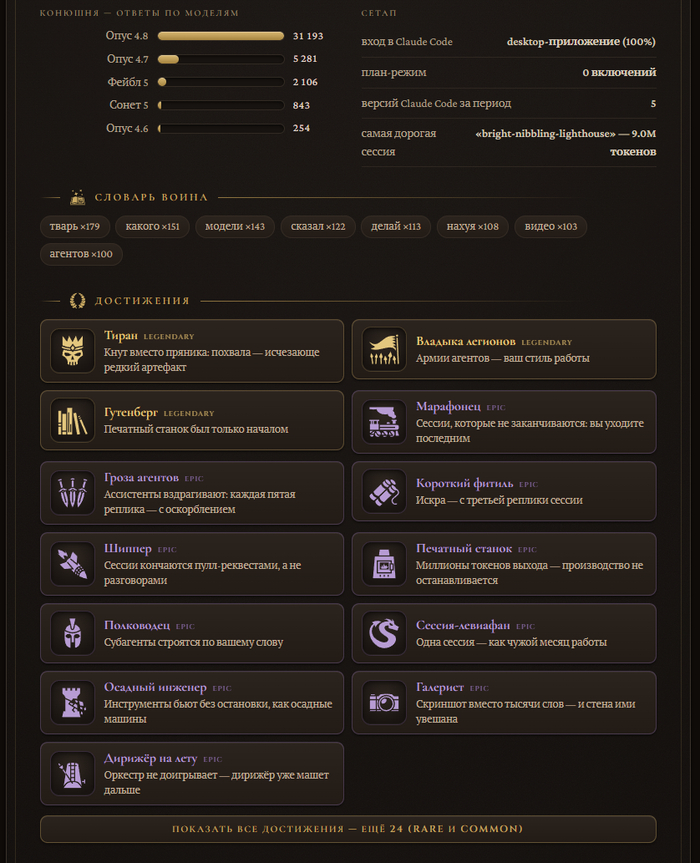
Ачивки — как в Стиме, только честнее. Их 74, четырёх редкостей, у каждой своя иконка, а условие получения всплывает при наведении. От простого «Клуба ста» (сто реплик в корпусе) до легендарного «Тирана» — это когда негатива в десять раз больше, чем похвалы, — и «Гутенберга» за 25 миллионов сгенерированных токенов. Пороги заморожены, даром не даётся ни одна. Сразу показываются только legendary и epic, остальные — под спойлером, чтобы не превращать карточку в простыню.
Аватар-монстр в шапке — тоже локальный: собирается офлайн из PNG-слоёв по вашему титулу и эволюционирует, когда меняетесь вы. Никаких нейрогенераций по API — детерминированная сборка, у одного титула всегда одна морда.
Про ДНК проекта. Весь скилл — от первой метрики до последней иконки — собран за одни сутки в диалоге с Claude: он и статистику по своим же логам считал, и дизайн гримуара рисовал, и сам себя потом тестировал с нуля как «свежий пользователь». Финальный штрих вышел рекурсивным: карточку про то, как я командую нейросетью, собрала та самая нейросеть, которой я командовал.
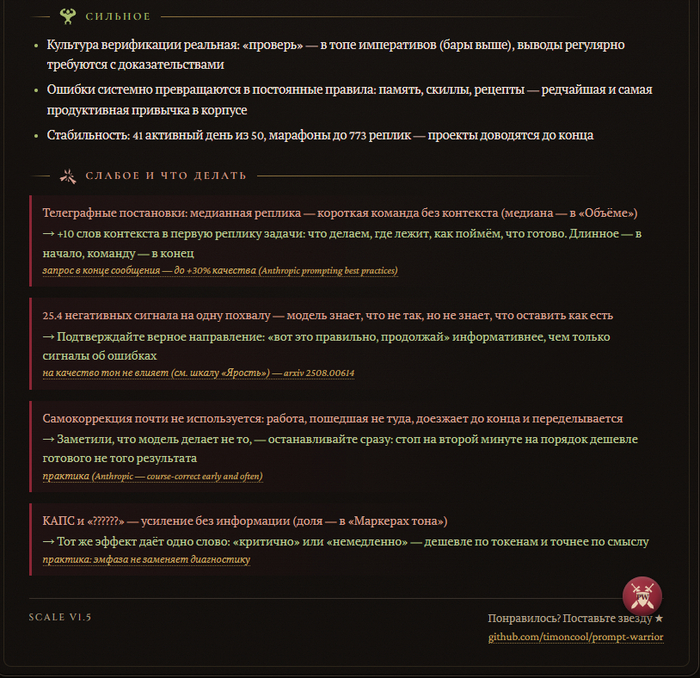
Это не только цирк с ачивками. В конце карточки — разбор сильного и слабого строго по вашим цифрам, и к каждой слабости приложен фикс со ссылкой на исследование или документацию Anthropic. А в базе скилла лежит отдельный список развенчанных мифов промпт-инженеринга — про «магические» приёмы, которые на качество ответов не влияют, только жгут токены.
Установка — самый ленивый способ: в README лежит готовый промпт, вставляете его в Claude Code целиком, и агент сам клонирует репозиторий, прогонит анализ и откроет карточку в браузере. Руками тоже просто: git clone в папку скиллов (~/.claude/skills/), потом сказать агенту «построй мой промпт-профиль» — получите HTML-карточку на русском или английском, виджет и разбор с рекомендациями. Claude Code поддержан из коробки; форматы логов Codex CLI, OpenCode, Gemini CLI и GitHub Copilot задокументированы в репо — идею можно перенести на любой харнесс.
Всё локально, приватно и бесплатно: ни одного сетевого вызова, ни ключей, ни телеметрии — логи не покидают вашу машину, код открыт под MIT. Профиль запоминается локально: вернётесь через неделю — увидите новые ачивки, левел-апы и сдвиги метрик. Никакой пользы для бизнеса, чистое удовольствие: узнать, что ты «Полуночный Верховный Ревизор с Коротким фитилём», — бесценно.
🔗 GitHub: timoncool/prompt-warrior — за звезду обнимем лично

Илл.: карикатура сгенерирована нейросетью Nano Banana 2 (Google Gemini 3.1 Flash Image) по текстовому промпту — Цукерберг в стиле мема «Работай!!» пинает лежащую свинью с надписью «ИИ», на фоне недовольные акционеры.
Марк Цукерберг признался сотрудникам в том, о чём обычно молчат перед инвесторами: агентная революция в Meta забуксовала. На внутреннем town hall он произнёс фразу, которая уже разлетелась по инсайдерским чатам Кремниевой долины: «Траектория развития агентов за последние четыре месяца не ускорилась так, как мы ожидали». Для компании, которая год назад устроила самую агрессивную AI-перестройку среди Big Tech, это прямое признание пробуксовки.
Чем заплатили за рывок
Ради ускорения Meta уволила около 10% глобального штата в мае и перекинула порядка 7 000 сотрудников в AI-подразделения. На AI-инфраструктуру в 2026 году заложено 145 миллиардов долларов. По словам Цукерберга, ощутимых результатов стоит ждать ещё через 3-6 месяцев — то есть компания официально признаёт, что уже пропустила собственные внутренние сроки.
Ван за 14 миллиардов
Самой дорогой ставкой стал найм Александра Вана: Meta заплатила 14,3 миллиарда долларов за долю в его Scale AI, чтобы получить право поставить его во главе новой лаборатории Meta Superintelligence Labs. Попутно компания предлагала исследователям из OpenAI и Google компенсационные пакеты до 100 миллионов долларов, а самому Вану, по инсайдерским данным, готова была заплатить 5 миллиардов — тот в переговорах запрашивал 20 миллиардов. Апрельский релиз Muse Spark (внутреннее имя — «Avocado») по бенчмаркам уступил и OpenAI, и Anthropic. При этом сам Ван держит бодрый тон и обещает, что следующая модель, «Watermelon», догонит GPT-5.5.
Это уже не первый раз
История с агентами — не первый случай, когда огромные вложения Цукерберга не конвертируются в результат. До ставки на агентов была ставка на метавселенную: подразделение Reality Labs с конца 2020 года накопило порядка 83-90 миллиардов долларов операционных убытков на очках Quest и VR-начинаниях, так и не породив массового продукта. Теперь та же схема — миллиарды, громкие увольнения, смена курса — повторяется с агентным ИИ.
Что дальше
Пока акционеры реагируют сдержанно: акции Meta не обвалились, а сам Цукерберг сохраняет контроль благодаря структуре голосующих акций. Но при такой скорости сжигания капитала без внятной отдачи вопросы о том, куда уходят десятки миллиардов, будут звучать всё громче — а конкуренты в лице OpenAI и Anthropic тем временем не сбавляют темп.
*Meta признана экстремистской организацией, её деятельность в России запрещена.



