История, после которой хочется написать заявление в прокуратуру. И я это сделаю, если деньги не вернут.
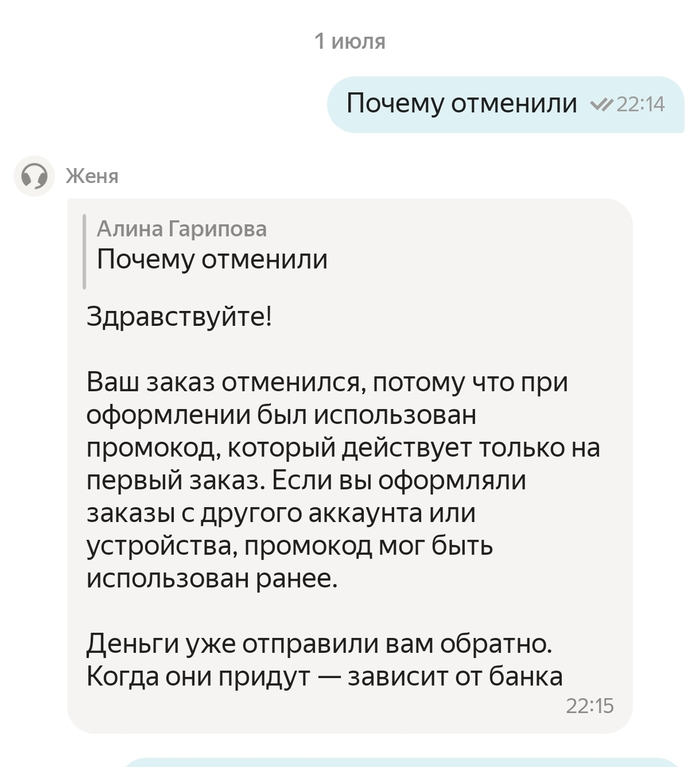
1 июля 2026 года я заказал еду через Яндекс.Доставку (или Еду — сервис Delivery). Применил промокод, всё нормально, нажал «Оплатить». Деньги списались моментально — это я увидел в мобильном банке Т-Банка. Через 5 минут заказ автоматически отменился: система написала, что промокод только для первого заказа. Ок, бывает.
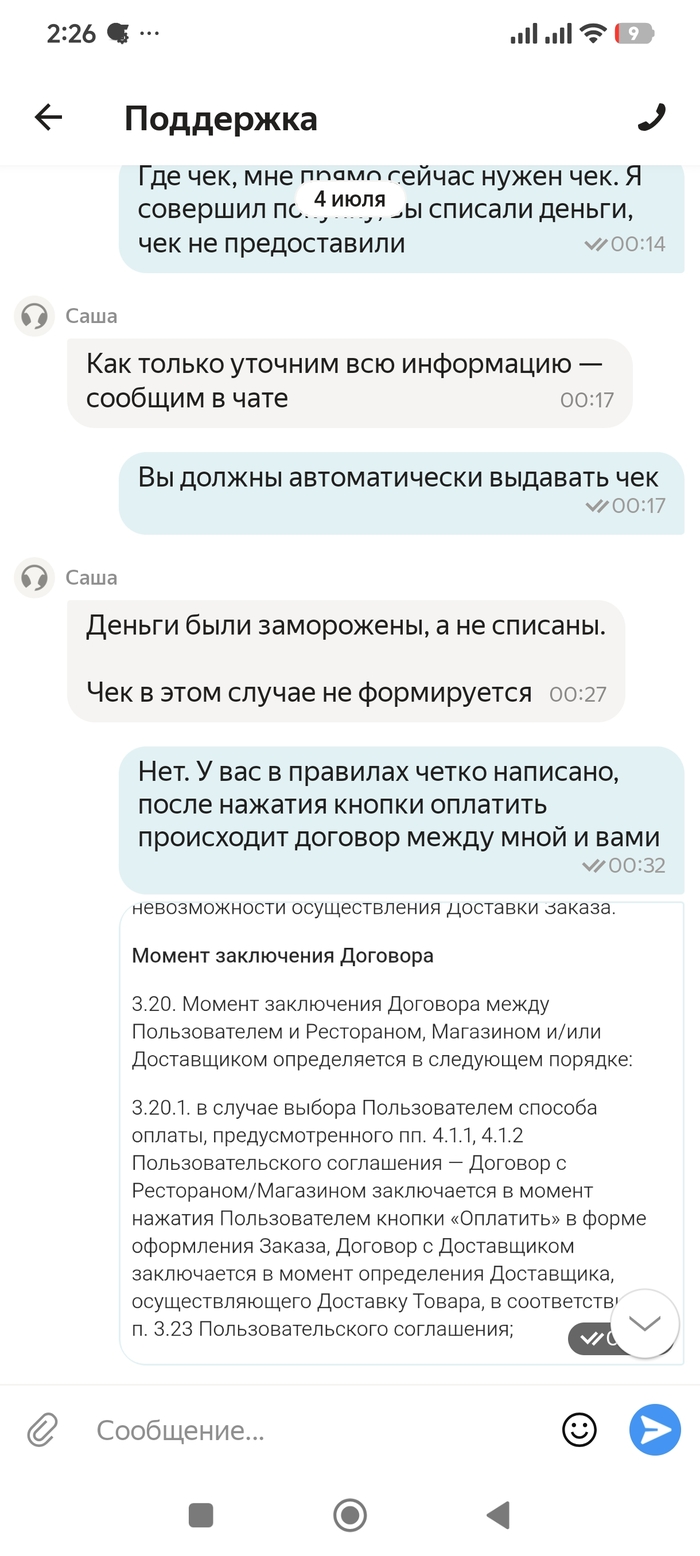
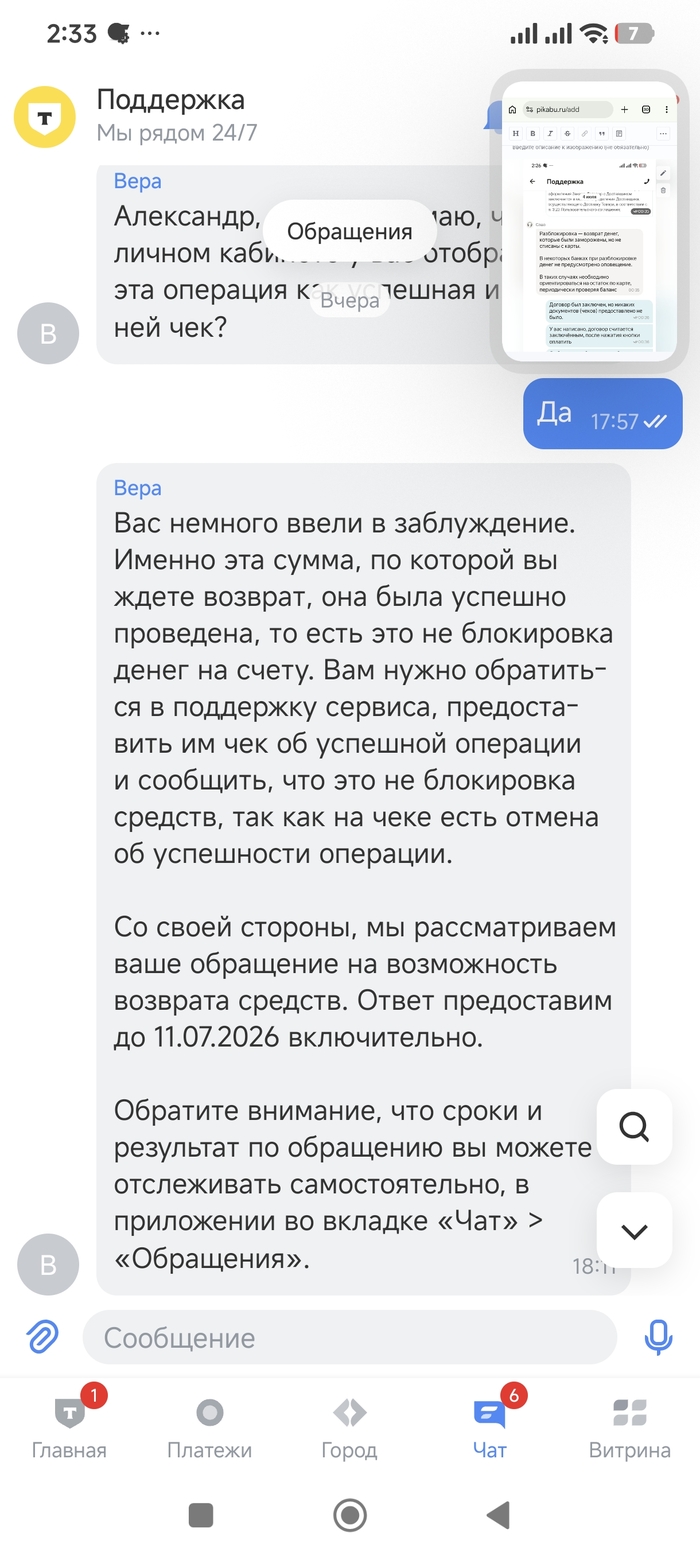
Но дальше начался цирк. В поддержке мне заявили: «Деньги не списаны, а заморожены. После отмены заказа они разблокируются и вернутся в течение нескольких дней». Прошло 10 дней — денег нет. Сегодня 11 июля, я снова пишу в чат. Теперь уже говорят: «Возникла ошибка при возврате средств». Я прошу чек и договор — отказ: «В таком случае чек не формируется».
Я не поленился и запросил официальный ответ у Т-Банка. И вот тут сюрприз: банк письменно подтвердил, что деньги были не заморожены, а успешно списаны. Никакой блокировки (холдирования) не было. Мне просто нагло врали 10 дней.
Теперь Яндекс предлагает заполнить «специальную форму», чтобы они сделали возврат. То есть без лишних телодвижений с моей стороны они свои же ошибки исправлять не хотят.
А теперь — внимание — разбор, какие законы нарушены, и почему это не просто «технический сбой», а полноценный обман потребителя.
1. Нарушение права на достоверную информацию (Закон о защите прав потребителей, ст. 8, 10)
По закону исполнитель обязан предоставить потребителю необходимую и достоверную информацию об услуге и о расчётах. Когда мне говорили «деньги заморожены», а по факту они были списаны — это прямое введение в заблуждение. Мне сообщили ложные сведения о статусе моих же средств. Это мешало мне своевременно принять меры и потребовать возврат. Статья 12 ЗоЗПП прямо говорит: если из-за недостоверной информации потребитель понёс убытки, исполнитель обязан их возместить. Здесь убытки - это как минимум потеря времени и нервы.
2. Невыдача кассового чека - нарушение 54-ФЗ
Согласно Федеральному закону № 54-ФЗ «О применении контрольно-кассовой техники», при каждом расчёте с физическим лицом продавец обязан сформировать кассовый чек и направить его покупателю (ст. 1.2, 4.7). Расчёт произошёл в момент нажатия кнопки «Оплатить» - это факт. То, что заказ позже отменился, не отменяет расчёта. Более того, при возврате должен формироваться чек коррекции или чек возврата. Отказ выдать чек со словами «в таком случае не формируется» - это грубейшее нарушение кассовой дисциплины. По 54-ФЗ за это могут оштрафовать на сумму от 10 000 рублей (для юрлица). И чек мне нужен не просто для галочки - он доказательство факта расчёта.
3. Незаконное удержание денег и просрочка возврата (ст. 31, 28 Закона о защите прав потребителей)
Заказ отменён сервисом в одностороннем порядке. Услуга не оказана. Согласно ст. 32 ЗоЗПП, договор считается расторгнутым, а уплаченная сумма подлежит возврату немедленно. Поддержка обещала возврат в течение «нескольких дней», но прошло 10 суток - это уже просрочка. Статья 31 Закона о защите прав потребителей отсылает к ст. 28 того же закона, где сказано: за нарушение сроков возврата денег исполнитель уплачивает потребителю неустойку в размере 3% от цены заказа за каждый день просрочки. Например, если заказ был на 1000 рублей, за 10 дней просрочки выходит 300 рублей неустойки. И она капает до момента фактического возврата.
4. Неосновательное обогащение и проценты по ст. 395 ГК РФ
Поскольку услуга не оказана, а деньги списаны и удерживаются, это квалифицируется как неосновательное обогащение (ст. 1102 ГК РФ). А если должник неправомерно удерживает чужие денежные средства, на эту сумму начисляются проценты в соответствии со ст. 395 ГК РФ (по ключевой ставке ЦБ). Можно требовать и их.
5. Создание искусственных препятствий для возврата
Требование заполнить «специальную форму» при наличии всех данных и признании ошибки - это уже нарушение духа закона о защите прав потребителей. Нигде не сказано, что для возврата собственных денег я должен танцевать с бубном. Более того, это может быть расценено как уклонение от добровольного удовлетворения требований, что при судебном разбирательстве влечёт штраф в размере 50% от присуждённой суммы (п. 6 ст. 13 ЗоЗПП).
Что я сделал и что советую вам
Я направил досудебную претензию в ООО «Яндекс» с требованием:
· немедленно вернуть деньги,
· выплатить неустойку за каждый день просрочки,
· компенсировать моральный вред.
Также готовлю жалобы в Роспотребнадзор и, если потребуется, в суд. Благо, ответ Т-Банка у меня на руках - он опровергает байки про «заморозку».
Если вы попали в такую же ситуацию:
1. Никогда не верьте словам поддержки на слово - просите письменный ответ.
2. Сразу запрашивайте у своего банка информацию о типе операции (списание или блокировка). Это можно сделать через чат.
3. Требуйте чек. Не дают - фиксируйте отказ (скрин переписки).
4. Помните про неустойку 3% в день - она ваша по закону.
Пусть эта история поможет другим не быть обманутыми. Яндекс, если читаешь - жду деньги, неустойку и чек. Не заставляйте идти в суд.
Буду держать в курсе, чем закончится. Если у кого-то был похожий опыт - делитесь в комментариях. 260701-7491218 номер заказа в деливери (это чтобы Яндекс прочитал пост, и чтобы все посмеялись на их ответ (если ответят)) @Yandex, @Yandex.eda, @Yandex.Go, @tbank.ru,