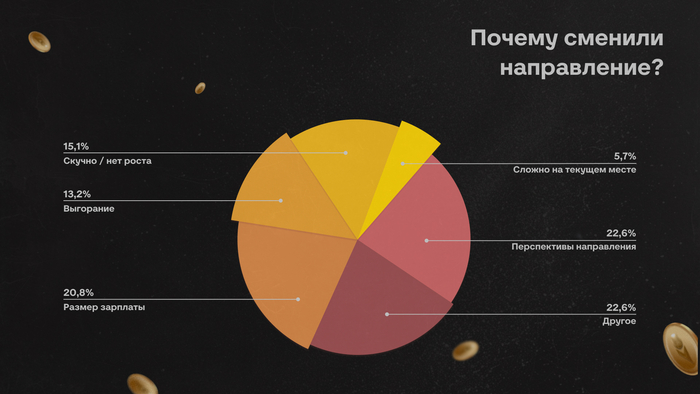
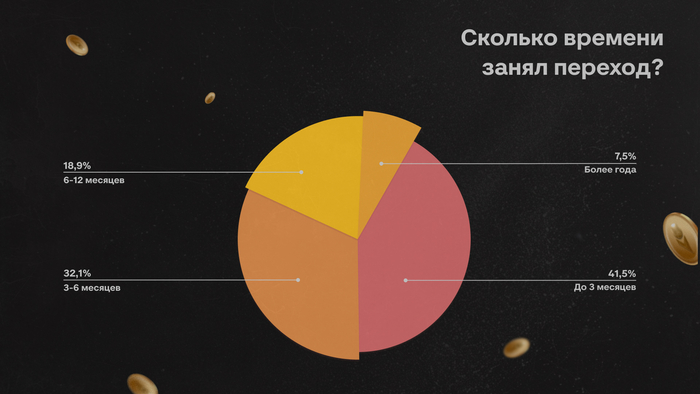
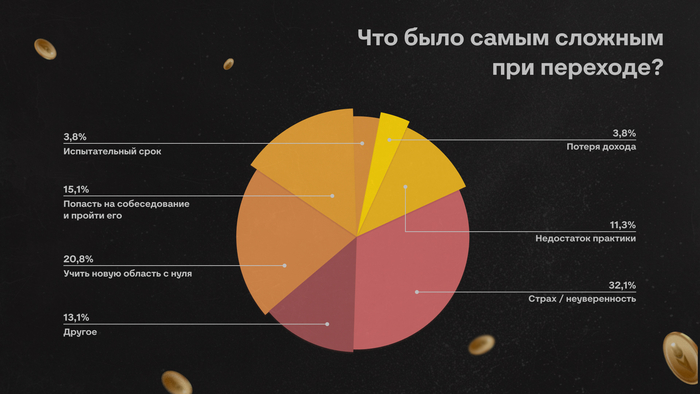
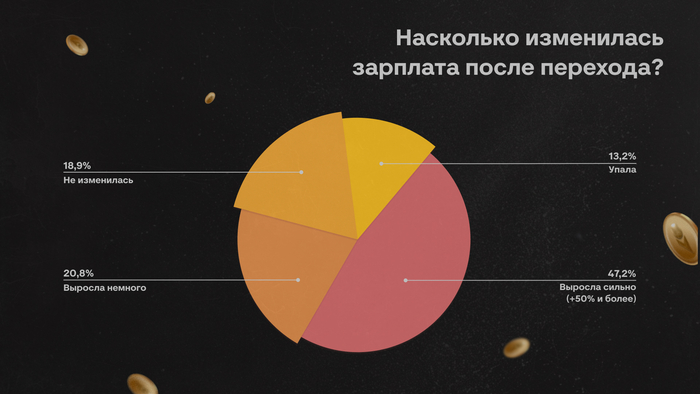
Представьте: заходите вы на GitHub году этак в 2035 году. Всё вроде знакомо. Те же репозитории, папки, pull requests, зелёные квадратики коммитов, ну разве что логотип другой. Старые репозитории давно получили по миллиону звёзд. По-прежнему ещё лежит код: синтаксис, отступы, функции, тесты, миграции, конфиги. Всё вроде на месте. Но что-то не так.
Код всё ещё есть, и он никуда не делся, но на него больше не смотрят как раньше. Его не лелеют и не облизываются над ним. Его не ревьюят, затаив дыхание. Он больше не считается главным местом, где живёт труд разработчика.
Он стал слишком подробным, потным и почти нечитаемым. Слишком низкоуровневым. Слишком утомительным, выжигающим глаза, как минифицированный JavaScript сегодня. Он нужен. Без него ничего не работает. Но вы не будете править его руками, правда?
Разработчик будет смотреть на папку /generated уже со скукой. Да, там код. Да, он исполняется. Да, он важен. Но настоящая работа происходит в другом месте, и главным артефактом становится не код, а промт.
GitHub — это уже не кладбище кода. Это хранилище того, чего мы хотим от LLM.
Код был временным компромиссом и стал обузой.
Думать, что код — это и есть программа, стало излишним. Весь вес перетёк между человеческим желанием и LLM-исполнением.
Разработчик хочет сказать:
Пользователь должен иметь возможность восстановить доступ к аккаунту, но так, чтобы это не светилось наружу и никто не мог украсть учётку через email.
LLM пишет контроллеры, модели, middleware, миграции, токены, таймеры, ретраи, логи, обработку ошибок, тексты писем, тесты и ещё десять скучных вещей, которые имеют уже косвенное отношение.
Код — способ заставить исполнить это поведение.
Вход — простой текстовый ввод, проходящий через LLM-инструкции.
Всё было прозрачно, пока машины понимали только инструкции. Хочешь программу — нужен код. Хочешь надёжную программу — пиши тесты к коду, много тестов и много документации, которая через полгода всё равно устареет, и придётся реализовывать техдолг.
Молодая и наглая LLM, которая умеет работать с более высоким уровнем абстракции. Она может понять не только синтаксис и стиль проекта, но и ограничения, контекст, примеры, антипаттерны, архитектурные решения и уже готовые реализованные модули.
И центр тяжести начинает смещаться в сторону высокой сахарности.
Мы уже видим это в маленьком виде агентов Codex, Claude Code, Cursor. Разработчик всё чаще не пишет функцию с нуля, а пишет промты:
Сделай в стиле модуля авторизации. Добавь тесты. Перепиши без этой магии. Сохрани публичный API, но поменяй внутреннюю реализацию так, чтобы она обросла седой бородой, и найди, где этот сценарий ломается. Объясни, почему этот diff опасен как пчёлы.
Пока это выглядит так, и это покажется странным. Но следующий шаг уже на пороге: такие инструкции перестанут быть одноразовыми и превратятся в структурированные промт-программы. Их начнут хранить. Версионировать. Ревьюить. Переиспользовать.
А где хранить, если не на GitHub?
Репозиторий будущего
Сегодня обычный репозиторий выглядит примерно так:
/src /tests /docs README.md package.json
Репозиторий будущего может выглядеть иначе:
Папка /generated никуда не исчезла, но со временем она уйдёт в .gitignore так же, как не исчез SQL, bash-скрипты, старые PHP и YAML, который все ругают, но продолжают есть этот кактус.
Но /generated больше не священный Грааль.
Это результат сухой компиляции промт-программирования.
Что мы задали модели, то она и написала.
Как мы проверяем, что модель поняла нас правильно? Правильно. Никак.
Нам уже не нужно думать о реализации, нам не нужно думать об оптимизации, нам нужно думать о гарантиях исполнения, тестах и архитектурной реализации.
Промт станет серьёзным документом
Сейчас слово «промт» звучит легкомысленно. Как будто это фраза чат-боту — арбайтен:
Сделай мне как Uber, только для собак и много котиков.
Но промт будущего — магическое заклинание для LLM. Управляемый, кроткий, сильно рамочный, который заставляет выдавливать из модели всё, что она умеет.
Промт будущего — инженерный артефакт.
Смесь технического задания, архитектурного решения, тест-плана, code style guide, security policy и инструкции для другого агента или субагентов. Можно помечтать о параллельных агентах, которые разбивают задачи на подстори и берут свои куски.
Это программирование на другом уровне абстракции.
Сегодня мы пишем код, чтобы получить желаемое исполнение инструкций, когда мы вкладываем в него процессы, которые необходимо реализовать.
Завтра мы будем писать описание в промтах, чтобы получить код — исполняемый, детерминированный код на любых LLM.
Как же будет выглядеть хороший разработчик? Он будет отличаться не тем, что быстрее всех пишет промты, а тем, что умеет точно описывать архитектуру: её цели, границы, исключения, риски и недопустимые состояния, гарантирующие следственную связь входящих запросов в модель и результата, который не нужно ревьюить.
Pull request превратится в спор об архитектуре
Самая интересная часть такой работы не станет скучной рутиной работы с документооборотом.
Любое изменение может привести к проводящим галлюцинациям.
Отпадают споры о реализации, названиях методов, переменных. Куда положить файл. Почему тут null. Почему any. Почему этот тест проверяет не то.
Часть этих споров уйдёт на уровень ниже ответственности LLM. Модель сможет переписать реализацию в нужном стиле за секунды. Поэтому человеческое внимание поднимется выше кода.
Будущее разработки — это не «LLM пишет код, человек отдыхает», а скорее так:
LLM пишет код, а человек строит систему ограничений, которая не даёт LLM впасть в вынужденные галлюцинации.
И чем мощнее модели, тем важнее не сама генерация, а доказательство того, что результат соответствует промту.
README станет исполняемым
Сегодня README часто неточен.
Не специально. Просто проект меняется, а README забывают обновить. Написано — запуск npm run dev, но команда не работает. Там описана старая архитектура, уже давно всё собирается в контейнере.
В мире, где LLM работает с README как с контекстом для генерации, это перестаёт быть мелкой неприятностью. Это принудительные инструкции, которые ставят LLM в одно место, из которого врать не получится.
Проблемы в README становятся блокером.
Документация перерождается. Она становится исполняемым контекстом.
Плохо описал доменную модель — проблема.
Забыл указать ограничение — проблема.
Оставил противоречие в архитектуре — блокер.
Это переворачивает отношение к документации.
LLM не убьют документацию.
Они сделают её опасной и важной, первым правилом, которое грозит пальчиком агенту.
Программист станет редактором контекста
Самая банальная фантазия:
Программисты больше не нужны.
Это слишком плоско, хило и вызывает только раздражение.
Программисты будут не только нужны, они нужны с другим уровнем понимания проблемы. Работа станет меньше похожа на разработку кода и больше — на редакторскую деятельность.
Они будут решать, какие слова имеют значение в контексте, и только их решения могут как ограничивать модель, так и отпускать её в свободные вайбы.
Это не менее инженерная работа, чем писать код. Возможно, даже более инженерная, чем сейчас.
Код хотя бы честно компилируется или не компилируется, тут да или нет: работает — не трогай. А промты могут быть расплывчатыми, противоречивыми, неполными и опасными.
LLM хорошо работает там, где человек ясно сказал, чего хочет. Если ясности нет, LLM должна не говорить, что она хочет, она должна думать в рамках задачи.
Поэтому программист будущего — это не человек, который помнит все методы стандартной библиотеки. Это человек, который умеет превращать мутное желание бизнеса в проверяемую систему.
Тогда GitHub будущего будет не местом, где лежит код.
Он будет местом, где лежит коллективная память о том, чего мы хотели от LLM.
Слишком подробный, чтобы быть главным.
Слишком важный, чтобы исчезнуть.
И слишком утомительный, чтобы писать его руками каждый раз.