


Квантовые компьютеры
22 поста


Жизненный трек про нашу общую летнюю боль: отключение горячей воды. По сюжету хитрый мужик заранее повесил дома огромный бойлер и моментально стал элитой. К нему помыться тут же ломится толпа из бывших, дальних родственников и даже соседа с перфоратором, а за проходку в душ несут крафт и торты. Сначала это звучит как веселый панк-рок угар под баян, где наличие кипятка в кране решает проблему одиночества, но финал неожиданно грустный. Врубайте на фон, пока греете тазики на плите, песня называется "Ах, гигиена".
Яндекс музыка: Ах, гигиена!
ВК музыка: Ах, гигиена!
Автор: Денис Аветисян
В новой работе исследователи объединили возможности квантовых вычислений и диффузионных моделей для повышения точности прогнозирования погоды на локальном уровне.
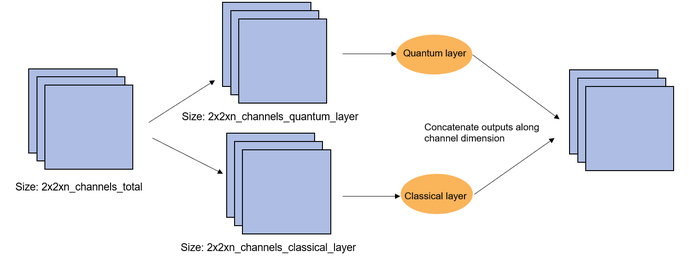
Схема обработки данных предполагает гибридизацию квантовых и классических слоёв, где входная карта признаков разделяется по каналам: первые N//4 каналов, определяемые числом кубитов N в ансатце, обрабатываются квантовым слоем, а оставшиеся проходят через классическую свёрточную сеть, после чего результаты обеих ветвей объединяются по каналам.
Представлен гибридный квантово-классический подход с использованием вариационных квантовых схем для статистической понижающей масштабируемости метеорологических данных.
Восстановление информации о погоде в высоком разрешении из грубых данных представляет собой сложную задачу, требующую значительных вычислительных ресурсов. В работе 'Hybrid Quantum-Classical Corrective Diffusion Modeling for Meteorological Downscaling' исследуется гибридный квантово-классический подход, использующий диффузионные модели для статистической даунскейлинга погодных полей. Показано, что встраивание вариационных квантовых цепей в узкое место диффузионной сети позволяет улучшить точность прогноза ветра по сравнению с чисто классическими моделями, при этом стабильность сохраняется. Какие дальнейшие оптимизации квантово-классической архитектуры и аппаратные улучшения необходимы для реализации потенциала гибридных вычислений в области моделирования погоды?
Глобальные климатические модели обеспечивают долгосрочные прогнозы изменения климата, однако их ограниченное пространственное разрешение не позволяет адекватно воспроизводить локальные погодные явления. Для оценки последствий изменения климата и разработки стратегий адаптации необходимо повышать разрешение этих моделей - процесс, известный как даунскейлинг, - но он требует значительных вычислительных ресурсов. Традиционные статистические методы даунскейлинга часто оказываются неспособны полностью учесть сложность атмосферных процессов, что снижает достоверность прогнозов с высоким пространственным разрешением. Таким образом, поиск эффективных и экономически оправданных методов даунскейлинга остается ключевой задачей в современной климатологии.
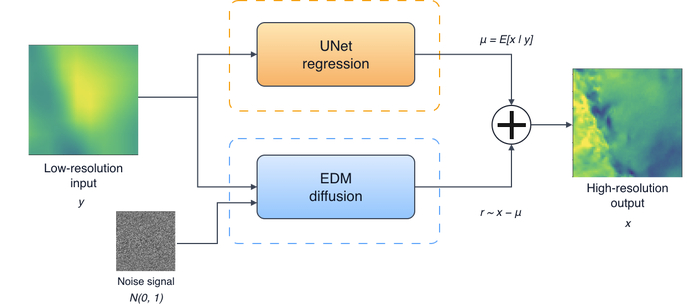
Предложенный Mardani et al.[13] метод CorrDiff использует детерминированный UNet-регрессор для первоначальной обработки изображения низкого разрешения, после чего диффузионная модель предсказывает остаточную коррекцию, добавляемую к результату регрессора для получения финального изображения.
Диффузионные модели открывают новые возможности для восстановления детализации, позволяя создавать реалистичные изображения высокого разрешения на основе исходных данных с низким разрешением. В частности, модель CorrDiff использует этот подход для преобразования грубых данных глобальных климатических моделей в детальные и правдоподобные карты погоды. Архитектура CorrDiff основана на UNet - нейронной сети, которая предсказывает среднее значение изображения с повышенной детализацией, эффективно восстанавливая мелкие атмосферные особенности и обеспечивая высокую точность представления погодных условий. Вместо простого увеличения разрешения, модель учится генерировать недостающие детали, опираясь на сложные закономерности, присущие атмосферным процессам.
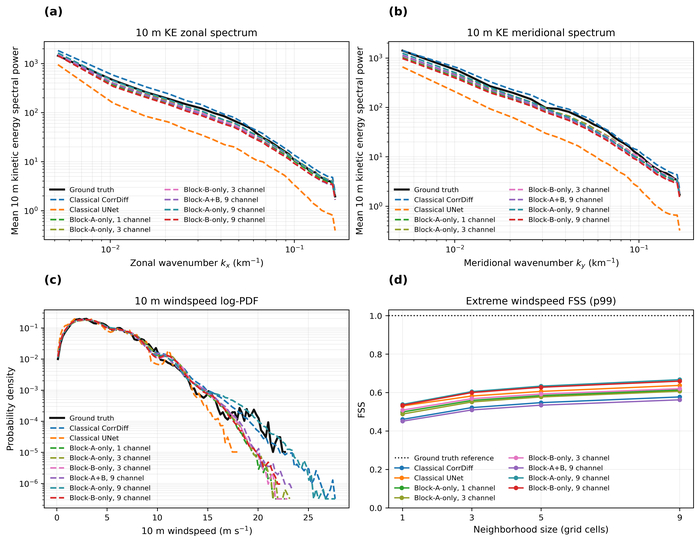
Анализ спектров кинетической энергии и распределений вероятностей скорости ветра показывает, что гибридные модели, сочетая преимущества CorrDiff и UNet, восстанавливают широкий спектр масштабов и улучшают локализацию экстремальных значений скорости ветра по сравнению с классическими подходами.
Разработана новая модель, объединяющая сильные стороны классических диффузионных моделей и квантовых вычислений для улучшения процесса уменьшения разрешения в задачах прогнозирования. Эта гибридная система использует вариационную квантовую схему в качестве нелинейного преобразователя, позволяющего выявлять сложные взаимосвязи в атмосфере, которые трудно уловить традиционными методами. В основе квантовой схемы лежит подход HQConv, обеспечивающий эффективную обработку скрытых характеристик данных внутри диффузионного процесса. Вместо сложных математических вычислений, модель фокусируется на выявлении закономерностей в данных, позволяя получить более детальные и точные прогнозы, даже при работе с ограниченным объемом информации.
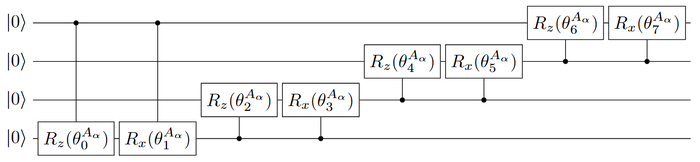
Анзац HQConv, использующий 12 кубитов для обработки трёх каналов входных данных 2 × 2, обобщается на любое кратное четырём число кубитов, позволяя обрабатывать nₘₐₜₕᵣₘ{qᵤbᵢₜₛ}/4 каналов, причём в случае четырёх кубитов применяется только блок A.
Для оценки точности разработанных моделей понижения разрешения использовался компактный набор высокоточных метеорологических наблюдений HRRR-mini. Анализ ключевых параметров, таких как скорость ветра по направлению востока-запада (u10m) и севера-юга (v10m), позволил количественно оценить соответствие между результатами моделирования и реальными данными. Особое внимание уделялось изучению спектра кинетической энергии ветра на различных масштабах, что позволило оценить способность модели адекватно воспроизводить изменчивость ветрового поля. В целом, исследование демонстрирует незначительное повышение производительности гибридной модели по сравнению с классическими подходами. Несмотря на сопоставимую точность, выполнение гибридной квантово-классической модели на реальном оборудовании в настоящее время требует в 10 раз больше времени, чем классические вычисления.
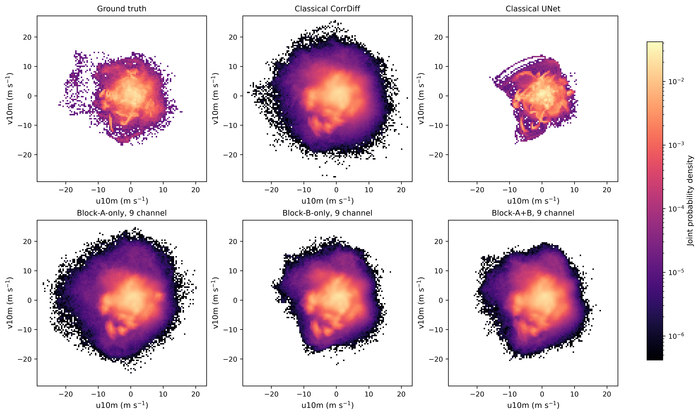
Анализ совместного распределения вероятностей горизонтальных компонентов ветра на высоте 10 м показал, что детерминированная UNet выдает сглаженные прогнозы, в то время как CorrDiff расширяет распределение, но теряет детализацию, а гибридный подход Block-A с 9 каналами обеспечивает наиболее широкое распределение, сохраняя высокую дисперсию и хвост, в то время как Block-B с 9 каналами демонстрирует более компактную и согласованную плотность, лучше отражая взаимосвязь между компонентами ветра.
Исследование, представленное в статье, подчеркивает сложность прогнозирования, рассматривая погоду не как статичную систему, а как развивающуюся экосистему, где каждый архитектурный выбор в моделировании несет в себе потенциал будущих ошибок. Авторы, стремясь к повышению точности статистической даунскейлинга, используют диффузионные модели и квантово-классические вычисления. Как заметила Барбара Лисков: «Программы должны быть спроектированы так, чтобы изменения в одной части не оказывали нежелательного воздействия на другие». Этот принцип особенно актуален в контексте гибридных систем, где взаимодействие квантовых и классических компонентов требует тщательного проектирования, чтобы избежать каскада ошибок и обеспечить надежность прогнозов. Подход, описанный в статье, демонстрирует осознание этой необходимости, акцентируя внимание на оптимизации взаимодействия между различными вычислительными парадигмами.
Предложенное сочетание диффузионных моделей и кван-классических вычислений для статистической спусковой моделировки погоды - не столько решение, сколько обозначение следующего уровня сложности. Архитектура, как известно, - это не структура, а компромисс, застывший во времени, и каждая внедрённая квантовая схема - это пророчество о будущей проблеме масштабируемости. Улучшения производительности, хоть и обнадеживающие, лишь отсрочивают неизбежное: зависимость от постоянно меняющегося ландшафта кванвенных технологий.
Более того, акцент на цифровых двойниках погоды подчёркивает фундаментальную дилемму. Попытка точно воспроизвести хаотическую систему, по сути, - это попытка обуздать случайность. Необходимо сместить фокус с бесконечного увеличения разрешения на понимание пределов предсказуемости, признавая, что некоторые аспекты погоды останутся принципиально непредсказуемыми, независимо от вычислительной мощи.
Технологии сменяются, зависимости остаются. Будущие исследования, вероятно, будут направлены не на создание более сложных моделей, а на разработку более устойчивых к неопределённости алгоритмов, способных извлекать полезную информацию даже из неполных и зашумленных данных. Системы - это не инструменты, а экосистемы. Их нельзя построить, только вырастить.
Полный обзор с формулами: denisavetisyan.com/pogoda-pod-kontrolem-kvantovo-klassicheskoe-modelirovanie-dlya-tochnogo-prognozirovaniya
Оригинал статьи: https://arxiv.org/pdf/2605.23403.pdf
Связаться с автором: linkedin.com/in/avetisyan
Автор: Денис Аветисян
В статье рассматривается необходимость дальнейших наблюдений за массивными звездами с помощью телескопа Hubble для решения ключевых вопросов о звездных ветрах, двойных системах и формировании самых массивных звезд.

На изображении, полученном с помощью инструментов HST/STIS и WFC3/UVIS, представлен анализ скопления R136, где щели спектрографа, протяженностью 52”×0.2”, направлены на изучение центральной области радиусом 4.1” (1 пк) вокруг звезды Мельник 34, при этом активная длина щели для наблюдений MAMA составляет 25 угловых секунд, позволяя детально исследовать интегрированное скопление R136a.
Исследование подчеркивает важность ультрафиолетовой спектроскопии и новых инструментов Hubble для изучения звездных ветров, двойной эволюции и верхней границы начальной массовой функции.
Несмотря на значительный прогресс в понимании эволюции массивных звезд, ключевые вопросы, касающиеся потерь массы, внутреннего смешения и влияния бинарности, остаются без ответа. В работе 'Massive Stars in the Thirties: awaiting new Hubble discoveries' обосновывается необходимость продолжения и расширения исследований в этой области с использованием возможностей космического телескопа Хаббл. Авторы подчеркивают, что ультрафиолетовая спектроскопия является незаменимым инструментом для изучения звездных ветров, идентификации взаимодействующих двойных систем и уточнения верхней границы начальной функции массы. Какие новые открытия ждут нас в 2030-х годах, если объединить многолетние наблюдения Хаббла с данными будущих поколений телескопов и решить фундаментальные загадки звездной астрофизики?
Массивные звезды, превосходящие по массе Солнце в десять и более раз, играют ключевую роль в эволюции галактик благодаря явлению, известному как звездная обратная связь. Их относительно короткая, но яркая жизнь оказывает глубокое влияние на формирование последующих поколений звезд и галактик в целом. Эти гиганты, рождая мощные потоки энергии и вещества, существенно изменяют окружающую межзвездную среду, формируя области, благоприятные или неблагоприятные для рождения новых звезд. Понимание сложного взаимодействия массивных звезд с межзвездной средой имеет решающее значение для создания точных моделей космоса и прояснения процессов, определяющих структуру и развитие Вселенной.
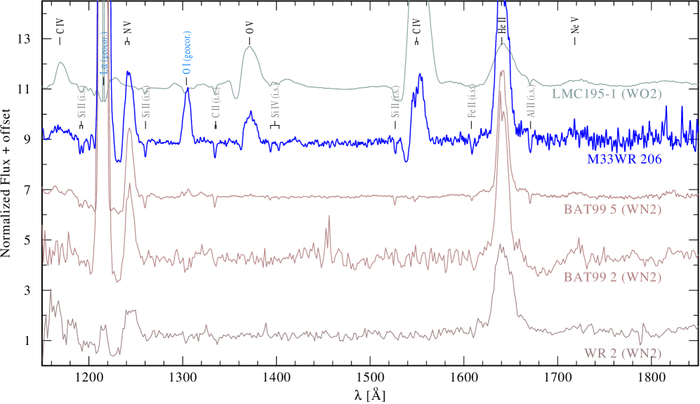
Спектры самых горячих звезд типов WN2/WO1, WN2 и WO2, полученные с помощью HST COS, демонстрируют интенсивное излучение, способное полностью ионизировать гелий, что затрудняет их обнаружение в звездных скоплениях, но делает их важным источником жесткого ионизирующего потока (данные из Sander et al., 2026).
Звездные ветры, возникающие из-за давления света на звездную материю, приводят к значительной потере массы, что влияет на дальнейшую эволюцию звезды и обогащает межзвездную среду новыми элементами. Интенсивность этого процесса, то есть скорость потери массы, тесно связана с химическим составом звезды (ее металличностью) и стадией ее жизненного цикла. Диагностические признаки этих ветров, такие как профили типа P Cygni, позволяют детально изучить их скорость и состав посредством спектрального анализа. Для получения точных измерений скорости звездного ветра требуется высокое спектральное разрешение, превышающее 10000, что обеспечивается, например, космическим телескопом Хаббл и его спектрографом COS.
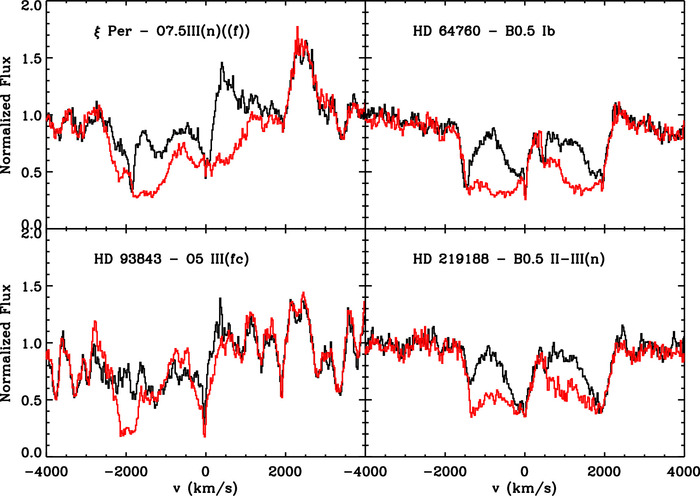
Анализ спектров Siiv λ 1400Å дублета в четырех звездах различных спектральных классов показал повсеместную изменчивость спектральных линий, диагностирующих звездный ветер, при этом моделирование по данным одного наблюдения приводит к 50-100% погрешности в оценке параметров звездного ветра (скорость потери массы, комковатость, поле скоростей).
Массивные звезды проходят через последовательные стадии сверхгигантов - голубую, желтую и красную, - каждая из которых характеризуется уникальными спектральными особенностями и свойствами звездного ветра. Детальное изучение атмосферной структуры и динамики звездного ветра стало возможным благодаря наблюдениям, выполненным с помощью космического телескопа Хаббл и его инструментов, таких как COS и STIS. Для точного определения химического состава звезд требуется высокое спектральное разрешение, превышающее 30000, которое обеспечивает STIS. Анализ изменений в спектре звезды во времени, в сочетании с использованием сложных моделей атмосферы звезд, позволяет понять природу изменчивости и сложного строения атмосфер сверхгигантов. Эти исследования раскрывают процессы, происходящие в недрах массивных звезд на последних этапах их эволюции, вплоть до драматического взрыва сверхновой.

Композитное изображение, полученное на основе данных Keck II и HST, демонстрирует сверхновую iPTF13bvn и ее возможный предшественник - звезду Вольфа-Райе в галактике NGC 5806, сопровождавшуюся γ-всплеском (Cao et al., 2013; Singer et al., 2013).
Эволюция массивных звезд часто завершается драматическим коллапсом ядра, приводящим к образованию нейтронной звезды или, в случае самых тяжелых звезд, черной дыры. В тесных двойных системах, состоящих из компактного объекта (нейтронной звезды или черной дыры) и звезды-компаньона, происходит перетекание вещества, создавая мощные источники рентгеновского излучения. Эти системы, известные как высокомассивные рентгеновские двойные, позволяют изучать процессы аккреции материи на компактные объекты. Более того, обнаружение гравитационных волн, возникающих при слиянии черных дыр, открывает совершенно новое окно в понимание финальных стадий эволюции массивных звезд, позволяя исследовать процессы, происходящие вблизи этих экстремальных объектов и подтверждая теоретические предсказания о существовании и свойствах гравитационных волн.
Наблюдения, полученные с помощью космического телескопа имени Джеймса Уэбба, совершают революцию в понимании формирования массивных звезд в ранней Вселенной, особенно в галактиках с низким содержанием металлов. Для воспроизведения наблюдаемых свойств этих галактик необходимы сложные космологические симуляции, учитывающие процессы обратной связи - влияние энергии, излучаемой звездами, на окружающую среду. Проект ULLYSES, создавший обширную библиотеку ультрафиолетовых спектров, предоставляет важнейшие исходные данные для этих моделей, позволяя получать более точные предсказания. Изучение влияния обратной связи в масштабах около ста световых лет стало возможным благодаря использованию узкополосных фильтров на камере WFC3, что позволяет детально исследовать процессы звездообразования и эволюции галактик в ранней Вселенной.
Изображение, полученное с помощью HST ACS, показывает область вокруг ULX Ho II X-1 и туманности "Foot Nebula", где белый круг отмечает пузырь ионизированного гелия [latex]HeII, образованный рентгеновским излучением ULX, а оптический объект ULX виден как белая точка в центре этого круга; в правом нижнем углу представлена область наблюдения HST COS, охватывающая ULX, пузырь HeII и две яркие ультрафиолетовые звезды, обозначенные красным кругом диаметром 2.5"x2.5" (адаптировано из Reyero Serantes et al., 2024).
Исследование массивных звёзд, представленное в данной работе, словно попытка удержать ускользающий свет. Авторы призывают к продолжению наблюдений с помощью телескопа Хаббл, акцентируя внимание на изучении звёздных ветров и двойных систем. Подобная деятельность напоминает о бренности любого научного построения. Эрнест Резерфорд однажды заметил: «Если бы я не спал, то, возможно, сделал бы больше открытий». Эта фраза отражает постоянную необходимость переоценки данных и признания границ познания. Ведь даже самые мощные инструменты, подобные Хабблу, лишь позволяют заглянуть в бездну, но не покорить её. Изучение верхней границы начальной массовой функции (IMF) - это попытка понять, как формируются самые яркие и короткоживущие звёзды, но эта функция может оказаться столь же неуловимой, как горизонт событий.
Исследование массивных звёзд, как и любое другое стремление постичь бесконечность, неизбежно сталкивается с границами собственного инструментария. Телескоп Хаббл, безусловно, доказал свою ценность, но каждое измерение - это компромисс между желанием понять и реальностью, которая не спешит открываться. Вопросы, связанные с природой звёздных ветров, эволюцией в двойных системах и верхней частью начальной функции массы, остаются открытыми, словно чёрная дыра, поглощающая любые однозначные ответы.
Перспективы дальнейших наблюдений, несомненно, обнадеживают, но необходимо помнить: точность данных не гарантирует полноты картины. Каждое новое открытие лишь подчеркивает, как мало известно, и как легко заблудиться в темноте вселенной. Использование усовершенствованных спектроскопических методов в ультрафиолетовом диапазоне, несомненно, принесёт пользу, однако важно осознавать, что даже самые мощные инструменты не способны обойти фундаментальные ограничения, накладываемые физическими законами.
В конечном счёте, исследование массивных звёзд - это не столько поиск ответов, сколько уточнение вопросов. Чёрная дыра - это не просто объект, это зеркало нашей гордости и заблуждений. И, возможно, главная задача состоит не в том, чтобы проникнуть за горизонт событий, а в том, чтобы не потерять себя в этом путешествии.
Полный обзор с формулами: avetisyanfamily.com/massivnye-zvezdy-v-novom-svete-chego-zhdat-ot-hubble
Оригинал статьи: https://arxiv.org/pdf/2605.28972.pdf
Связаться с автором: linkedin.com/in/avetisyan
Автор: Денис Аветисян
Исследование показывает, что модифицированный спектр первичных возмущений может объяснить аномально высокую массу галактик, обнаруженных телескопом "Джеймс Уэбб".
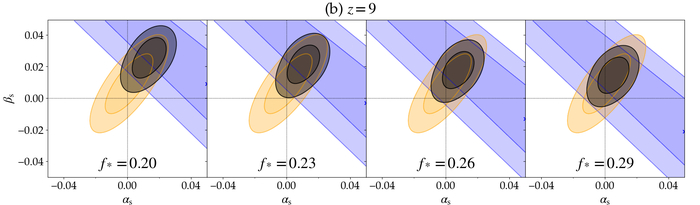
Ограничения на параметры alphaₛ и betaₛ, полученные в данной работе и из данных Planck, согласуются с результатами, полученными на основе объединенных данных JWST и Planck для значений f* равных 0.20, 0.23 и 0.26 при красном смещении z равном 8 и 9, что указывает на согласованность полученных ограничений в различных областях параметров.
В статье рассматривается влияние синего спектра первичной мощности на функцию массы гало и эффективность звездообразования в ранней Вселенной.
Наблюдаемые телескопом "Джеймс Уэбб" обилие массивных галактик на ранних этапах эволюции Вселенной вступает в противоречие с предсказаниями стандартной ΛCDM модели. В работе 'Blue-tilted Runnings and the JWST Early Galaxy Tension' рассматривается возможность разрешения этой напряженности путем введения спектра возмущений плотности с "синим уклоном" и положительным "раннингом". Показано, что при значениях параметров alphaₛ ∼ eq 0.2 и betaₛ ∼ eq 0.2 совместный анализ с данными космического микроволнового фона позволяет снять напряженность на уровне 1σ. Может ли такой "синий" спектр возмущений быть связан с формированием первичных черных дыр в ранней Вселенной и предоставить альтернативное объяснение наблюдаемой аномалии?
Наблюдения, полученные с помощью космического телескопа имени Джеймса Уэбба, указывают на существование неожиданно массивных и плотных галактик, сформировавшихся на ранних этапах существования Вселенной (при красном смещении от 6.5 до 9.0). Эти галактики демонстрируют скорость звездообразования, не согласующуюся с предсказаниями, основанными на общепринятой теории формирования структур во Вселенной - модели ΛCDM. Появление столь крупных и развитых галактик в столь ранние эпохи ставит под вопрос существующие представления о начальных условиях и эволюции Вселенной. Это расхождение требует пересмотра ключевых допущений и, возможно, внесения изменений в модель ΛCDM, чтобы адекватно объяснить наблюдаемое распределение и характеристики галактик в ранней Вселенной.
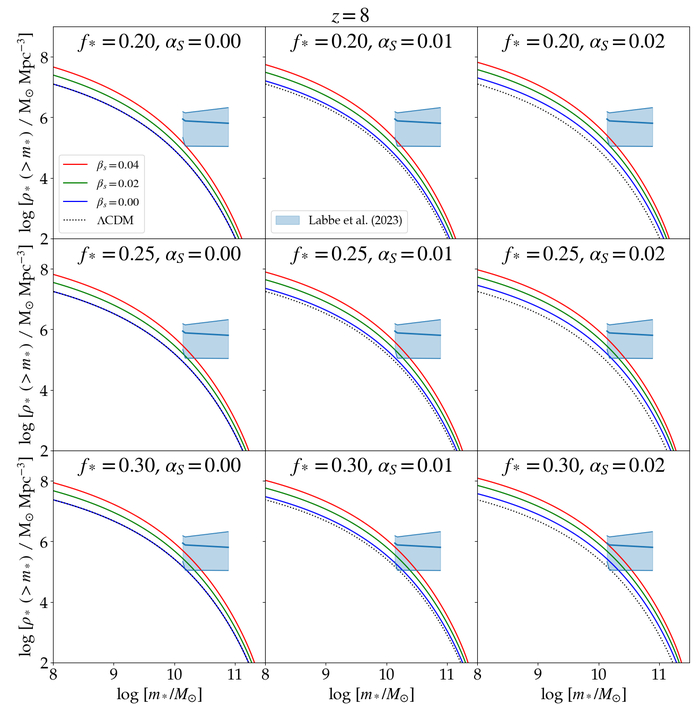
Изменение эффективности звездообразования и параметров моделирования приводит к различным распределениям кумулятивной звездной массы при красном смещении z=8, причем некоторые из этих распределений согласуются с данными JWST о галактиках на больших красных смещениях, в то время как стандартная модель ΛCDM демонстрирует отклонения.
Предлагается модификация стандартной модели первичных флуктуаций плотности Вселенной, известная как "синий сдвиг". Эта модель предполагает усиление мельчайших неоднородностей в ранней Вселенной, что привело к формированию более плотных областей - так называемых гало - на более ранних этапах эволюции космоса. Настройка этого усиления осуществляется посредством двух ключевых параметров: спектрального индекса и скорости его изменения. Для соответствия современным астрономическим наблюдениям, в частности данным, полученным космическим аппаратом Planck, необходимо, чтобы спектральный индекс был не менее 0.01, а скорость его изменения - не менее 0.02. Эти параметры позволяют точно настроить модель, чтобы она соответствовала наблюдаемому распределению материи во Вселенной, предоставляя возможность проверить её справедливость с помощью дальнейших астрономических исследований.
Распределение тёмных гало - то есть, количество областей сконцентрированной тёмной материи различной массы - напрямую связано с мельчайшими флуктуациями плотности в ранней Вселенной, зафиксированными в так называемом первичном спектре мощности. Для точного определения этого распределения требуется моделирование этого спектра, что осуществляется с помощью специализированных программных пакетов, таких как CAMB. Одной из ключевых моделей, позволяющих рассчитать зависимость между массой гало и их обилием, является функция Шет-Тормена. Комбинируя эти инструменты, становится возможным предсказать количество тёмных гало, доступных для формирования галактик, на различных этапах эволюции Вселенной - то есть, при различных красных смещениях.
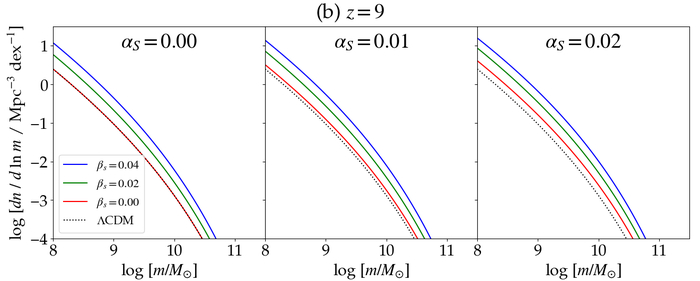
Функции распределения гало по массе (HMF) при alphaₛ = 0.00, 0.01, 0.02 (слева направо) при z=8 и z=9 демонстрируют влияние параметров alphaₛ и betaₛ (красные, зелёные и синие кривые соответствуют betaₛ = 0.00, 0.02, 0.04 соответственно) по сравнению со стандартной Λ CDM моделью (чёрная пунктирная линия).
Эффективность звездообразования, зависящая от количества обычного вещества, определяет общую массу звезд, формирующихся внутри каждой темной гало. Для оценки расстояний до этих галактик и их массы используется метод анализа спектрального распределения энергии. Комбинируя теоретические предсказания о начальных флуктуациях плотности во Вселенной с оценками эффективности звездообразования - в пределах от 20 до 30 процентов - можно проверить, соответствует ли модель наблюдаемым характеристикам галактик, существовавших в ранней Вселенной. Такой подход позволяет напрямую сравнить теоретические расчеты с данными, полученными космическим телескопом "Джеймс Уэбб", и показывает, что модель согласуется с наблюдениями с высокой степенью достоверности, отклоняясь от наблюдаемых данных всего на один-два сигма при значениях параметров αs ≥ 0.01 и βs ≥ 0.02. Это означает, что модель успешно воспроизводит ключевые свойства древних галактик, устраняя противоречия между теорией и наблюдениями.
Теоретические расчеты показывают, что особые флуктуации плотности вещества в ранней Вселенной, возникающие при так называемом “синем спектре мощности”, создавали благоприятные условия для формирования первичных черных дыр посредством изотермического коллапса. Эти первичные черные дыры могли внести значительный вклад в состав темной материи на самых ранних этапах существования Вселенной и, возможно, объяснить некоторые из зарегистрированных событий, связанных с гравитационными волнами. Изучение взаимосвязи между “синим спектром”, процессами формирования структур в ранней Вселенной и рождением первичных черных дыр открывает захватывающие перспективы для дальнейших исследований, предлагая целостный взгляд на эволюцию Вселенной от момента ее зарождения и далее.
Исследование, представленное в данной работе, напоминает о хрупкости любых построений. Попытки разрешить напряженность между наблюдениями высококрасных галактик и предсказаниями стандартной космологической модели требуют пересмотра самых основ - первоначального спектра мощности. Это не просто корректировка параметров, но и признание возможности того, что фундаментальные предположения могут быть неверны. Как говорил Галилей: «Всё, что мы называем законом, может раствориться в горизонте событий». Иными словами, даже кажущиеся незыблемыми принципы, такие как предсказуемость функции массы гало, могут оказаться иллюзией, если горизонт нашего понимания будет расширен новыми наблюдениями, например, данными, полученными с помощью телескопа Джеймса Уэбба. Работа подчеркивает, что открытие - это не триумф, а осознание границ познания.
Представленная работа, исследующая возможность разрешения несоответствия между наблюдениями высококрасных галактик и предсказаниями стандартной ΛCDM модели через модифицированный спектр первичных флуктуаций, поднимает вопросы, выходящие за рамки простой калибровки космологических параметров. Любое упрощение модели, будь то введение синего наклона спектра мощности или изменение функции массы гало, требует строгой математической формализации и постоянной проверки на соответствие существующим данным, полученным из наблюдений космического микроволнового фона. Нельзя забывать, что даже элегантное решение может оказаться лишь временной иллюзией, исчезающей за горизонтом событий наших знаний.
Перспективы дальнейших исследований связаны не только с уточнением параметров модифицированного спектра, но и с изучением альтернативных сценариев, таких как влияние первичных черных дыр на формирование первых галактик. Важно помнить, что любая теория, претендующая на объяснение ранней Вселенной, должна быть способна предсказывать наблюдаемые свойства галактик, включая их массу, размер и скорость звездообразования.
В конечном счете, поиск истины в космологии напоминает попытку удержать воду в кулаке. Чем сильнее мы сжимаем, тем быстрее она ускользает. Чёрная дыра - это не просто объект, это зеркало нашей гордости и заблуждений. И задача науки состоит не в том, чтобы найти окончательный ответ, а в том, чтобы постоянно задавать новые вопросы.
Полный обзор с формулами: avetisyanfamily.com/rannie-galaktiki-jwst-sinij-spektr-kak-reshenie-problemy
Оригинал статьи: https://arxiv.org/pdf/2605.22161.pdf
Связаться с автором: linkedin.com/in/avetisyan
«Красное смещение» — атмосферный электронный трек на стыке melodic techno, ambient и IDM.
В основе — астрофизическая метафора: чем быстрее объекты удаляются друг от друга, тем сильнее их свет смещается в красный спектр. Здесь красное смещение становится аллегорией расставания — когда связь не исчезает мгновенно, а медленно растворяется в тёплом уходящем свете.
Космос, пустота, эфир, затухающие сигналы и ощущение бесконечного расстояния между двумя объектами.
Без подписки можно слушать в Яндексе с компа или в телефоне через браузер в режиме "версия для ПК", но нужно залогиниться: https://music.yandex.ru/album/41885915
Автор: Денис Аветисян
Новое исследование описывает ключевые требования и сложности точного измерения масс экзопланет, находящихся в обитаемой зоне, с использованием комбинированных методов радиусных скоростей и астрометрии.
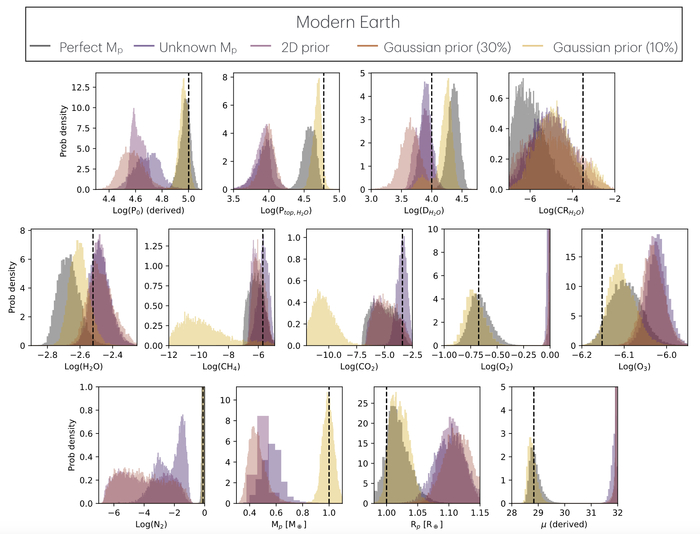
Для точной интерпретации спектра отражённого света от планеты, подобной Земле, необходимо априорное знание о её массе: исследование показывает, что для корректного определения преобладающего газа в атмосфере требуется априорное распределение вероятностей массы планеты в 10%, что подчеркивает важность предварительных данных в анализе экзопланетных спектров.
Точное определение масс потенциально обитаемых экзопланет требует контроля систематических ошибок и высокоточных инструментов для достижения 10% точности.
Определение массы экзопланет, особенно находящихся в обитаемой зоне, остается сложной задачей для подтверждения их пригодности для жизни. В работе 'Masses of Potentially Habitable Planets Characterized by the Habitable Worlds Observatory' рассматриваются требования и ограничения, связанные с измерением масс потенциально обитаемых планет с использованием астрометрических методов, реализуемых в рамках проекта Habitable Worlds Observatory. Авторы показывают, что точность измерений, необходимая для определения состава атмосферы и оценки обитаемости, напрямую зависит от количества и яркости опорных звезд в поле зрения, превосходя вклад шума фотонов. Сможем ли мы достичь требуемой точности в 10% для характеристики масс экзопланет, используя комбинацию астрометрии и высококонтрастной визуализации, и какие стратегии оптимизации наблюдений окажутся наиболее эффективными?
Определение пригодности экзопланет для жизни требует детального изучения состава и структуры их атмосфер. Хотя точные измерения массы и радиуса являются важным первым шагом, они недостаточны для полного понимания атмосферных свойств. Современные методы анализа сталкиваются с ограничениями, связанными с наблюдательными возможностями и сложностью моделирования. Ключевым является детальный анализ света, который экзопланеты излучают и отражают, позволяющий выявить присутствие различных газов и веществ, указывающих на потенциальную обитаемость. Исследование спектрального состава этого света, подобно расшифровке уникального кода, позволяет ученым реконструировать атмосферные условия на этих далеких мирах и оценить вероятность существования там жизни.
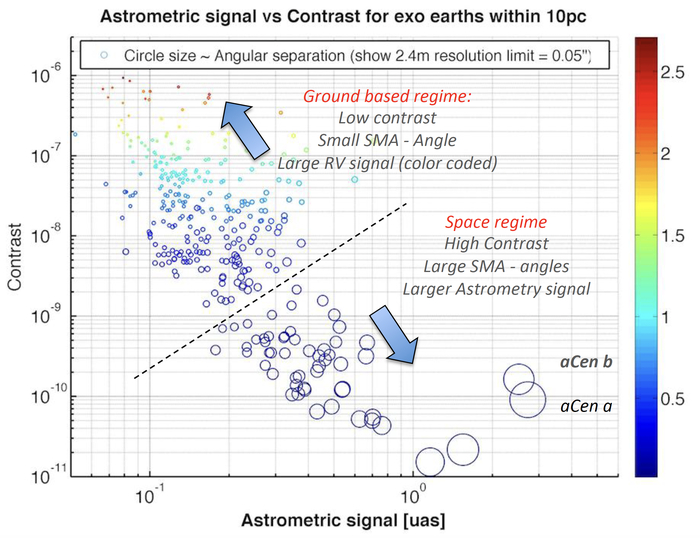
Астрометрические и радиальные скорости сигналов, генерируемых аналогами Земли вокруг близлежащих звезд, малы и находятся за пределами текущих возможностей, при этом амплитуда астрометрического сигнала положительно коррелирует с угловым разделением, но отрицательно - с контрастностью и радиальной скоростью.
Структура атмосферы определяется фундаментальным принципом, известным как гидростатическое равновесие, который устанавливает связь между давлением и плотностью воздуха на разных высотах. Для понимания масштаба и стабильности атмосферы ключевым является расчет плотности воздушного столба - то есть, общей массы воздуха над определенной площадью. Эта плотность напрямую зависит от среднего молярного веса атмосферы, который, в свою очередь, определяется составом воздуха и преобладающими газами. Точный анализ атмосферного состава, осуществляемый с помощью спектрального анализа, позволяет установить эти параметры и, следовательно, получить полное представление о структуре и поведении атмосферы. Определение этих характеристик важно для понимания не только земной атмосферы, но и атмосфер других планет, раскрывая общие принципы формирования и эволюции газовых оболочек в космосе.
Современные методы определения массы экзопланет опираются на прецизионную астрометрию - измерение положения звезд с невероятной точностью, стремясь к 0,3 микроугловой секунды за одно наблюдение. Для этого используются передовые технологии, включая лазерную метрологию, которая позволяет минимизировать систематические ошибки. Параллельно, анализ спектра света, отраженного от экзопланет, дает возможность узнать состав их атмосферы и физические характеристики. Будущие миссии, такие как Обсерватория Обитаемых Миров, планируют использовать эти техники для достижения 10-процентной точности измерения массы экзопланет, что потребует около ста наблюдений. Эти данные будут дополняться измерениями скорости движения звезды, выполненными с точностью до одного сантиметра в секунду, что позволит получить наиболее полную картину экзопланетных систем.
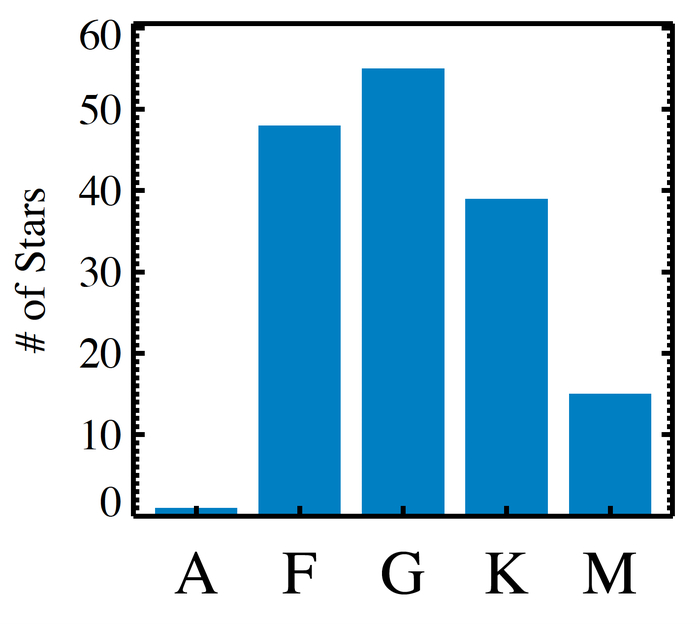
Анализ целевой выборки LUVOIR-B (и, следовательно, HWO) показывает, что около 30% звезд имеют спектральный класс A или F, что может ограничить точность радиусных измерений из-за высокой температуры и/или быстрого вращения, при этом распределение спектральных типов и зависимость светимости от расстояния для 158 ближайших звезд представлена на графиках.
Фундаментальным ограничением в точности астрометрических измерений выступает фотонный шум, обусловленный дискретностью света - чем меньше фотонов регистрируется, тем сложнее определить положение объекта с высокой точностью. К этому добавляются систематические ошибки, возникающие из-за несовершенства инструментов и особенностей процесса наблюдений, которые могут существенно исказить результаты. Определение массы экзопланет, например, напрямую зависит от точного понимания светимости и распределения энергии в спектре звезды-хозяина. Для минимизации влияния этих факторов используются сложные методы анализа данных и тщательная калибровка оборудования, направленные на достижение разрешения в 11 миллисекунд дуги - это соответствует возможности различить объекты, находящиеся на расстоянии нескольких миллиметров на расстоянии одного километра. Такой уровень точности позволяет существенно повысить надежность и достоверность астрометрических наблюдений.
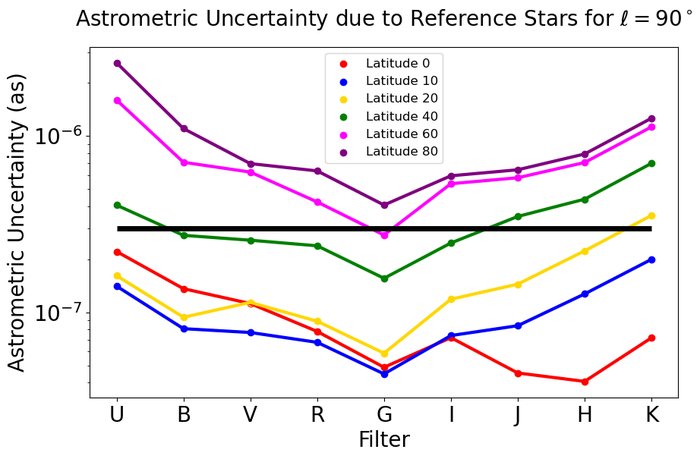
Зависимость кумулятивного числа опорных звезд с магнитудой до 20 от фильтра и галактической широты при поле зрения детектора в 36 квадратных угловых минут демонстрирует, что точность астрометрических измерений напрямую зависит от характеристик опорных звезд и параметров телескопа (время экспозиции 30 минут, диаметр 6 метров, общая пропускная способность 0.25).
Для оценки возможности существования жизни на экзопланетах необходимо сочетать точные измерения массы и радиуса планет с детальным изучением состава их атмосфер. Преодоление ограничений, связанных с наблюдательными возможностями, требует применения передовых методов наблюдения и сложных моделей. Особую надежду возлагают на будущую обсерваторию Habitable Worlds Observatory, которая способна совершить революцию в понимании атмосфер экзопланет и потенциала жизни за пределами Земли. Для достижения этой цели потребуется около 170 дней общего времени наблюдений за 165 отобранными звездами. Эти усилия в конечном итоге изменят представления о формировании планет и распространенности обитаемых миров во Вселенной.
Исследование масс потенциально обитаемых экзопланет, представленное в данной работе, требует не только передовых инструментов, но и глубокого понимания систематических ошибок. Подобная точность в измерениях - задача нетривиальная, ведь любая погрешность может исказить представление о пригодности планеты для жизни. Как заметил Джеймс Максвелл: «Наука - это не сбор фактов, а построение связного представления о мире». Действительно, стремление к десятипроцентной точности в определении массы экзопланет - это попытка построить максимально непротиворечивую картину Вселенной, отсеивая ложные представления и неопределенности. Чёрные дыры учат терпению и скромности; они не принимают ни спешки, ни шумных объявлений, и точно так же, стремление к пониманию экзопланет требует тщательности и внимательности к деталям.
Представленные требования к измерению масс потенциально обитаемых экзопланет звучат, конечно, элегантно. Десять процентов точности - красивая цифра на бумаге. Но физика - это искусство догадок под давлением космоса, и каждое новое поколение телескопов неизменно напоминает о скромности наших амбиций. Систематические ошибки - вот настоящий враг, и борьба с ними - это не инженерная задача, а философский спор о природе измерения.
Чёрная дыра - это не просто объект, это зеркало нашей гордости и заблуждений. Заманчиво строить модели обитаемости, но стоит помнить, что даже самые точные данные - лишь бледное отражение реальности. Астрометрия и радиальная скорость, объединенные в тандеме, дают надежду, но не гарантируют избавления от иллюзий. Ведь вселенная не обязана соответствовать нашим уравнениям.
Следующий шаг - это не просто усовершенствование инструментов, а переосмысление самого понятия "точность". Возможно, стоит признать, что абсолютная точность - это недостижимый идеал, а наша задача - лишь приблизиться к истине настолько, чтобы предсказать следующее затмение. И даже тогда, как справедливо заметил один мудрец, всегда найдется аномалия, которая заставит пересмотреть все наши теории.
Полный обзор с формулами: avetisyanfamily.com/ves-nadezhdy-opredelenie-massy-obitaemyh-ekzoplanet
Оригинал статьи: https://arxiv.org/pdf/2603.11146.pdf
Связаться с автором: linkedin.com/in/avetisyan
Автор: Денис Аветисян
Исследование закладывает теоретические основы для создания алгоритмов машинного обучения, оперирующих с гиперкомплексными числами - кватернионами.
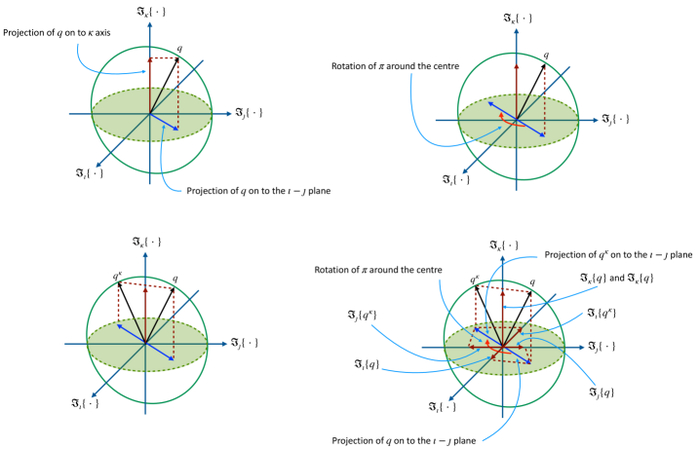
Кватернион q и его инволюция qκ демонстрируют взаимосвязь между проекциями кватерниона на плоскость, образованную мнимыми единицами imath и jmath, и проекцией на ось, определяемую κ, при этом вращение проекции на плоскости вокруг центра на π позволяет восстановить инволюцию из этих проекций, раскрывая геометрическую структуру кватернионных преобразований.
В статье представлены фундаментальные принципы широколинейного моделирования и адаптивного обучения для обработки гиперкомплексных сигналов на основе кватернионного исчисления.
Несмотря на успехи комплексных чисел в различных областях науки и техники, расширение этих методов на другие гиперкомплексные системы, такие как кватернионы, долгое время оставалось сложной задачей. В работе 'Hypercomplex Widely Linear Processing: Fundamentals for Quaternion Machine Learning' предлагается фундаментальный подход к машинному обучению на основе кватернионов, включающий расширенную статистику, широколинейные модели и кватерниональное исчисление. Ключевым результатом является создание теоретической базы для обработки гиперкомплексных сигналов и адаптивного обучения в многомерном пространстве. Открывает ли это новые перспективы для разработки эффективных алгоритмов машинного обучения в задачах, требующих моделирования трехмерных вращений и пространственной ориентации?
Во многих областях, от компьютерной графики до робототехники и навигации, точное и эффективное представление вращений играет ключевую роль. Хотя комплексные числа прекрасно справляются с двумерными вращениями, их возможности ограничены в трехмерном пространстве. Кватернионы предлагают мощную альтернативу, обеспечивая компактный и лишенный особенностей способ описания ориентации объектов в трех измерениях. В отличие от других методов, кватернионы позволяют избежать проблем, связанных с "запиранием оси" и другими нежелательными эффектами, что делает их незаменимым инструментом для адаптивных алгоритмов, требующих прецизионного управления вращениями. Именно эта особенность открывает новые перспективы для развития машинного обучения на основе кватернионов, позволяя создавать более устойчивые и эффективные системы управления и анализа движений.
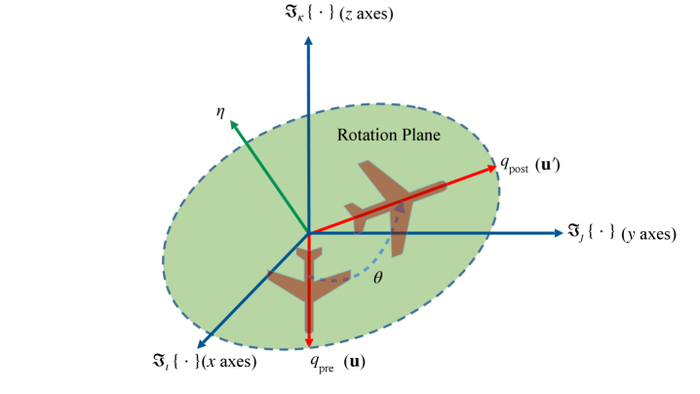
Схема иллюстрирует вращение объекта на угол θ вокруг оси η, определяющее переход от начальной ориентации qₚᵣₑ к конечной ориентации qₚₒₛₜ.
Расширение стандартного математического анализа на функции, значениями которых являются кватернионы, требует особого внимания к правилам умножения, поскольку порядок множителей имеет значение. Для этого используется понятие производной кватерниона, которое строится на основе условий, обеспечивающих математическую согласованность, подобных известному условию Коши-Римана-Фуэнтеса. В результате, привычные правила дифференцирования, такие как правило произведения и правило цепочки, получают своё развитие и применение для анализа и манипулирования динамикой вращений, описываемых кватернионами. Эти правила, адаптированные для кватернионов, становятся ключевыми инструментами в изучении того, как вращения изменяются во времени и как они взаимодействуют друг с другом.
Современные системы, способные к самообучению и адаптации в реальном времени, требуют использования адаптивных алгоритмов, которые постоянно корректируют свои параметры. Для эффективного моделирования сложных динамических процессов, в таких алгоритмах применяются нелинейные функции, основанные на кватернионах - математических объектах, расширяющих понятие комплексных чисел. Использование производных кватернионов позволяет алгоритмам быстро и эффективно находить оптимальные решения в многомерных пространствах параметров, обходя ограничения традиционных линейных моделей. Введение широколинейной модели дополнительно повышает возможности адаптации, позволяя системе реагировать на изменения и находить наиболее подходящие настройки даже в условиях высокой неопределенности и сложности.
Алгоритм QLMS представляет собой усовершенствованную версию широко известного метода наименьших квадратов, расширенную для работы с кватернионами - математическими объектами, эффективно описывающими вращения. В отличие от традиционных подходов, QLMS использует производные кватернионов и гиперболический тангенс для обеспечения быстрой и надежной адаптации системы. Этот метод позволяет динамически настраивать параметры системы, что особенно важно для точного управления вращающимися объектами, например, в системах оценки и контроля ориентации. QLMS служит практическим примером реализации предложенного подхода и демонстрирует его возможности в задачах, требующих высокой точности и оперативности управления вращением.
Работа представляет собой изящное исследование возможностей гиперкомплексной обработки сигналов, закладывая основу для машинного обучения на основе кватернионов. Авторы демонстрируют глубокое понимание принципов широколинейного моделирования и адаптивного обучения в контексте гиперкомплексной алгебры. В этом стремлении к элегантности и точности можно увидеть отголоски идей Томаса Куна: “Научные знания не растут постепенно, а претерпевают революционные изменения.” Подобно тому, как Кун описывал смену парадигм в науке, данное исследование предлагает новый взгляд на обработку данных, потенциально приводящий к фундаментальным изменениям в области машинного обучения. Вместо постепенного улучшения существующих методов, предлагается качественно новый подход, основанный на возможностях, предоставляемых кватернионным исчислением и широколинейным моделированием.
Представленная работа, стремясь к элегантности в обработке гиперкомплексных сигналов, неизбежно обнажает области, требующие дальнейшего осмысления. Основываясь на кватернионной алгебре, исследование, хотя и закладывает прочный фундамент для машинного обучения, оставляет открытым вопрос о практической применимости и вычислительной эффективности предложенных моделей. Как часто бывает, идеальная гармония теории сталкивается с суровой реальностью ограниченных ресурсов и шума в данных.
Особого внимания заслуживает проблема адаптации алгоритмов к нелинейным задачам. Линейность, как известно, - лишь приближение, и истинная сила интеллекта проявляется в способности к обобщению за пределами известных закономерностей. Поиск кватернионных аналогов нелинейных функций, сохраняющих при этом вычислительную эффективность, представляется нетривиальной задачей. Подобно хорошей архитектуре, которая незаметна, пока не рухнет, истинное достоинство этих моделей проявится в их устойчивости к искажениям и способности к самообучению.
В конечном счете, направление развития этой области, вероятно, будет определяться не столько теоретическими изысканиями, сколько потребностью в решении конкретных задач. Разработка специализированных аппаратных средств, оптимизированных для кватернионных вычислений, могла бы стать катализатором для более широкого применения этих моделей. Последовательность в развитии этих подходов - это форма эмпатии к будущим пользователям, которые, возможно, столкнутся с проблемами, о которых авторы еще не подозревают.
Полный обзор с формулами: denisavetisyan.com/kvaterniony-v-mashinnom-obuchenii-novyj-vzglyad-na-obrabotku-dannyh
Оригинал статьи: https://arxiv.org/pdf/2603.11835.pdf
Связаться с автором: linkedin.com/in/avetisyan
Автор: Денис Аветисян
Новые исследования с использованием атомной и молекулярной спектроскопии открывают возможности для проверки фундаментальных физических теорий и поиска признаков новой физики.
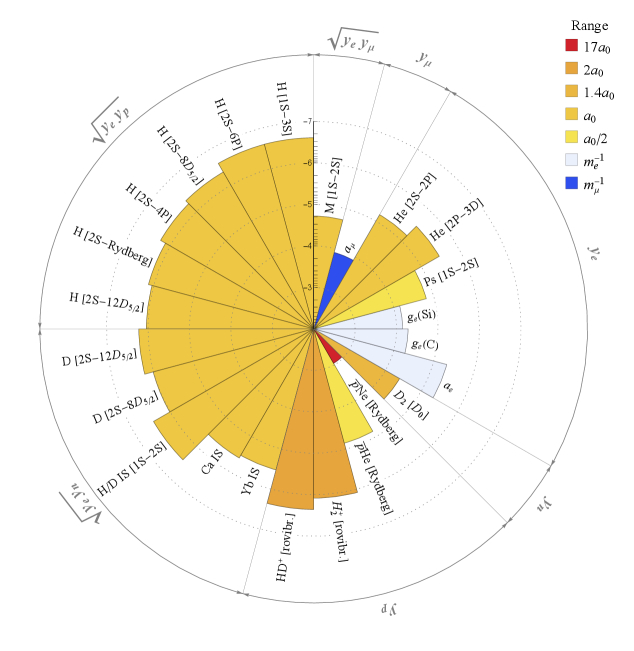
Спектроскопические системы высокой точности демонстрируют различный охват в поиске новой физики, исследуя комбинации эффективных взаимодействий с электронами, мюонами, протонами и нейтронами в атомах, молекулах и экзотических системах, при этом водородоподобные атомы, молекулярные ионы, гелий, позитроний, мюоний и измерения изотопных сдвигов дополняют друг друга в определении силы и дальности этих взаимодействий.
Обзор методов прецизионных измерений в атомной и молекулярной спектроскопии для поиска взаимодействий, выходящих за рамки Стандартной модели, включая ограничения на новые переносчики сил и темную материю.
Несмотря на впечатляющие успехи Стандартной модели, остаются нерешенные вопросы, указывающие на необходимость поиска новой физики. В работе 'Atomic Spectroscopy Probes of New Physics' представлен обзор спектроскопических методов, используемых для поиска отклонений от предсказаний Стандартной модели, в частности, для исследования слабо взаимодействующих частиц, потенциальных кандидатов в темную материю. Полученные ограничения, основанные на прецизионных измерениях в атомных и молекулярных системах, позволяют сузить параметры ряда теоретических моделей, предсказывающих существование новых взаимодействий. Какие возможности открываются для дальнейшего повышения точности спектроскопических исследований и, следовательно, для более глубокого изучения фундаментальных законов природы?
Несмотря на ошеломляющий успех, Стандартная модель физики элементарных частиц оставляет без ответа ряд фундаментальных вопросов, указывая на существование явлений, выходящих за её рамки - так называемой «Новой физики». Поиск этой Новой физики требует всё более точных измерений, подталкивая границы спектроскопических методов к достижению точности вплоть до 10 в минус 15-й или 10 в минус 12-й степени при исследовании атомных и молекулярных переходов. В настоящее время возможности экспериментальных исследований часто ограничены именно точностью измерительных инструментов и чувствительностью применяемых методик. Следовательно, инновации в области прецизионных измерений имеют решающее значение для раскрытия физических законов, лежащих за пределами нашего нынешнего понимания, и углубления знаний о природе Вселенной.
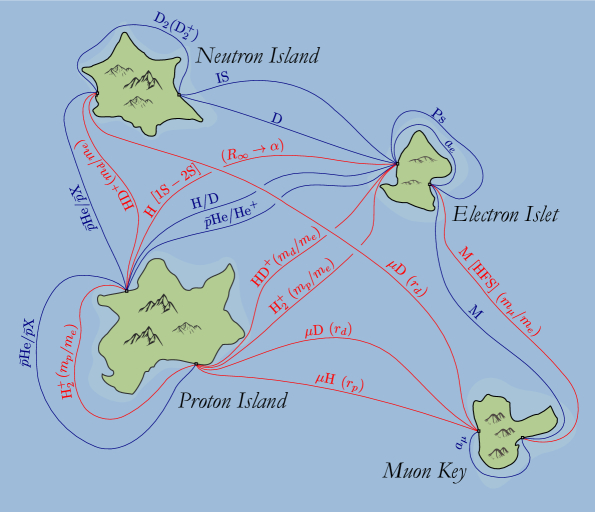
Схематическая карта эффективных взаимодействий новой физики с протоном, нейтроном, электроном и мюоном демонстрирует спектроскопические системы, связывающие эти взаимодействия, при этом системы, критически важные для определения фундаментальных констант, выделены красным цветом с указанием соответствующей константы в скобках.
Спектроскопия, исследующая взаимодействие света и материи на атомном и молекулярном уровнях, представляет собой мощный инструмент для проверки фундаментальных физических констант и поиска отклонений от существующих теоретических моделей. Повышение чувствительности достигается за счет использования ионов с высоким зарядом, усиливающих влияние даже самых слабых взаимодействий. Особую роль в увеличении точности измерений играют изотопы, позволяющие снизить систематические погрешности. Революционным прорывом стало появление оптических и ядерных часов, обеспечивающих беспрецедентное разрешение по времени для высокоточных измерений частоты. Благодаря этим достижениям, ученые могут с невиданной ранее точностью исследовать структуру материи и фундаментальные законы Вселенной, открывая новые горизонты в понимании окружающего мира.
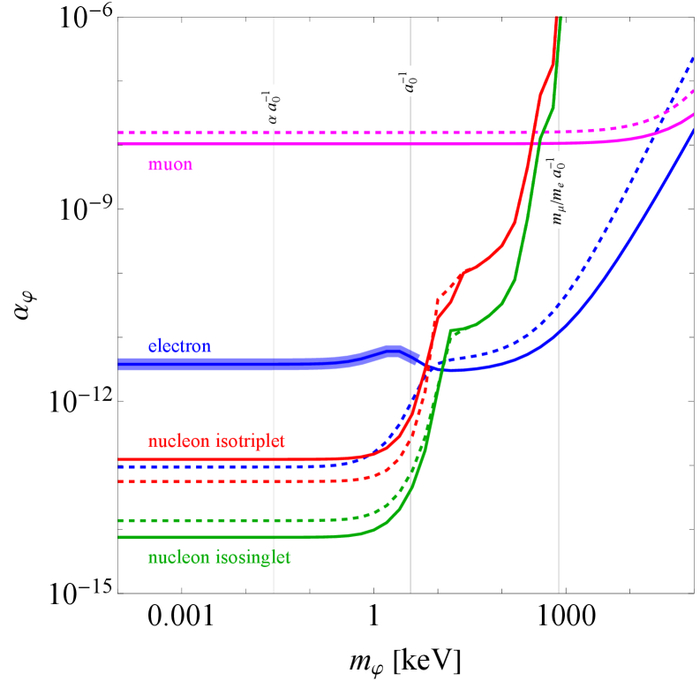
Глобальный анализ прецизионных спектроскопических данных позволил установить ограничения на спин-независимые взаимодействия и одновременно определить фундаментальные константы, демонстрируя, что для моделей тёмного фотона, B−L-бозона, скалярного бозона Хиггса и скалярного "featheron" (соответственно красным, чёрным, синим и фиолетовым цветами) существуют определённые диапазоны масс посредника (сплошные и пунктирные линии), где вероятность обнаружения новой физики выше стандартной модели более чем на 4σ.
Высокоточные спектроскопические измерения служат строгим тестом для теоретических моделей, выходящих за рамки Стандартной модели физики элементарных частиц. Интерпретация этих ограничений осуществляется в рамках эффективной теории поля, которая позволяет связать наблюдаемые эффекты с потенциальными новыми взаимодействиями. Особое внимание уделяется измерениям атомной поляризуемости, предоставляющим дополнительный способ поиска новых частиц и уточнения параметров существующих моделей. Эти исследования значительно сужают область возможных значений для параметров гипотетических частиц, таких как темный фотон, скалярные частицы, взаимодействующие с бозоном Хиггса, и так называемые "перовые" скаляры, а также бозоны, связанные с сохранением барионного и лептонного чисел. Анализ данных выявил потенциальный избыток сигналов в моделях, описывающих взаимодействие со скалярными частицами, связанными с бозоном Хиггса и "перовыми" скалярами, с уровнем статистической значимости 2.6σ, что указывает на необходимость дальнейших исследований.
Нарушение CP-симметрии, фундаментального принципа, гласящего, что физические законы остаются неизменными при одновременном изменении заряда и пространственной четности, представляет собой убедительное свидетельство существования физики за пределами Стандартной модели. В настоящее время, высокоточные спектроскопические исследования используются для поиска едва уловимых эффектов, связанных с нарушением CP-симметрии в предсказанных новыми физическими моделями. Эта непрерывная охота за новыми частицами и взаимодействиями обусловлена стремлением разрешить нерешенные загадки в физике элементарных частиц и космологии. Такие достижения не только расширяют границы точности измерений, но и углубляют понимание фундаментальных законов природы, открывая новые перспективы в изучении Вселенной.
Исследование, представленное в статье, демонстрирует, как точные спектроскопические измерения могут служить инструментом для проверки фундаментальных границ Стандартной модели. Подобно тому, как деконструкция сложной системы позволяет выявить скрытые взаимосвязи, так и анализ спектров атомов и молекул открывает возможности для поиска новых физических явлений. Как заметил Георг Вильгельм Фридрих Гегель: «Всё реальное - рационально, и всё рациональное - реально». Эта фраза отражает стремление учёных найти рациональное объяснение наблюдаемым явлениям, а также указывает на то, что реальность не является статичной, а постоянно развивается и познаётся через призму логики и анализа, что особенно важно в контексте поиска взаимодействий, выходящих за рамки известной физики.
Представленный анализ, как и любая попытка заглянуть за рамки Стандартной модели, обнажает скорее границы инструментария, чем истинные пределы реальности. Точность спектроскопических измерений растет экспоненциально, но фундаментальный вопрос остается: что, если новые взаимодействия проявляются не в виде слабых сигналов, а в систематических ошибках, замаскированных под несовершенство приборов? Погоня за "новой физикой" рискует превратиться в утонченную охоту за артефактами.
Перспективы лежат не только в увеличении точности, но и в расширении спектра исследуемых систем. Молекулярные спектры, будучи сложнее атомных, предлагают больше степеней свободы для проявления скрытых взаимодействий, но и требуют более изощренных методов анализа. Попытки моделирования сложных молекул, подверженных воздействию гипотетических полей, неизбежно наталкиваются на предел вычислительных возможностей, заставляя выбирать между точностью и полнотой картины.
В конечном итоге, задача не в том, чтобы найти подтверждение существующим теориям "темной материи" или "новых сил", а в том, чтобы создать инструменты, способные уловить любое отклонение от предсказанного поведения. Ведь самое интересное часто скрывается не там, где мы ищем, а в тех самых "погрешностях", которые мы привыкли отбрасывать как шум.
Полный обзор с формулами: xpla.ru/za-granyu-standartnoj-modeli-spektroskopiya-na-sluzhbe-novoj-fiziki
Оригинал статьи: https://arxiv.org/pdf/2602.20750.pdf
Связаться с автором: linkedin.com/in/avetisyan




