«Мастерок» получил ИИ-прораба Михалыча и новые калькуляторы: как я добавил характер в строительное приложение
Когда я начинал делать «Мастерок», основная идея была простой — собрать в одном месте инструменты, которые реально нужны на стройке. Не сотню бесполезных конвертеров, а конкретные калькуляторы с понятным результатом. Но в какой-то момент стало ясно, что одними калькуляторами сыт не будешь: людям нужен совет, причём не сухой и формальный, а живой. Так в приложении появился Михалыч — AI-прораб с тридцатилетним стажем и довольно острым языком.
В этой статье расскажу, что нового появилось в последнем обновлении, как устроен Михалыч изнутри, почему я отказался от нейтрального помощника в пользу персонажа с характером и с какими техническими трудностями пришлось столкнуться по дороге.
Что нового в обновлении
Последнее обновление вышло достаточно объёмным. Помимо Михалыча, о котором подробно расскажу ниже, в приложении появились несколько инструментов, которых давно не хватало.
Калькулятор площадей — штука, казалось бы, элементарная, но я потратил на неё приличное количество времени, чтобы сделать по-человечески. Работает в двух режимах: «Комната» и «Стены». В режиме комнаты вводишь длину, ширину и высоту — получаешь площадь стен, пола, потолка и периметр. Причём приложение автоматически разбивает результат по стенам A, B, C, D с указанием площади каждой. Звучит просто, но когда считаешь обои или краску, именно разбивка по стенам экономит и время, и деньги, не надо прикидывать в уме, какая стена длиннее, а какая короче.
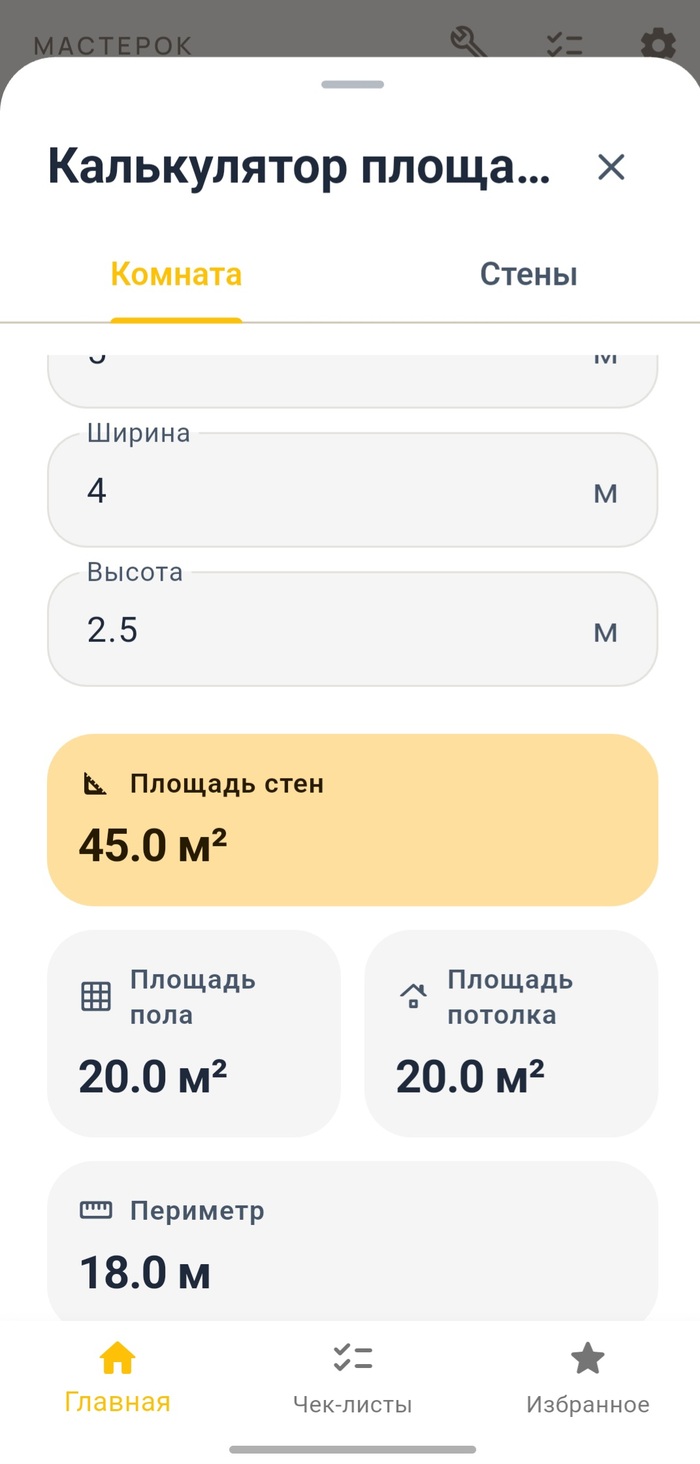
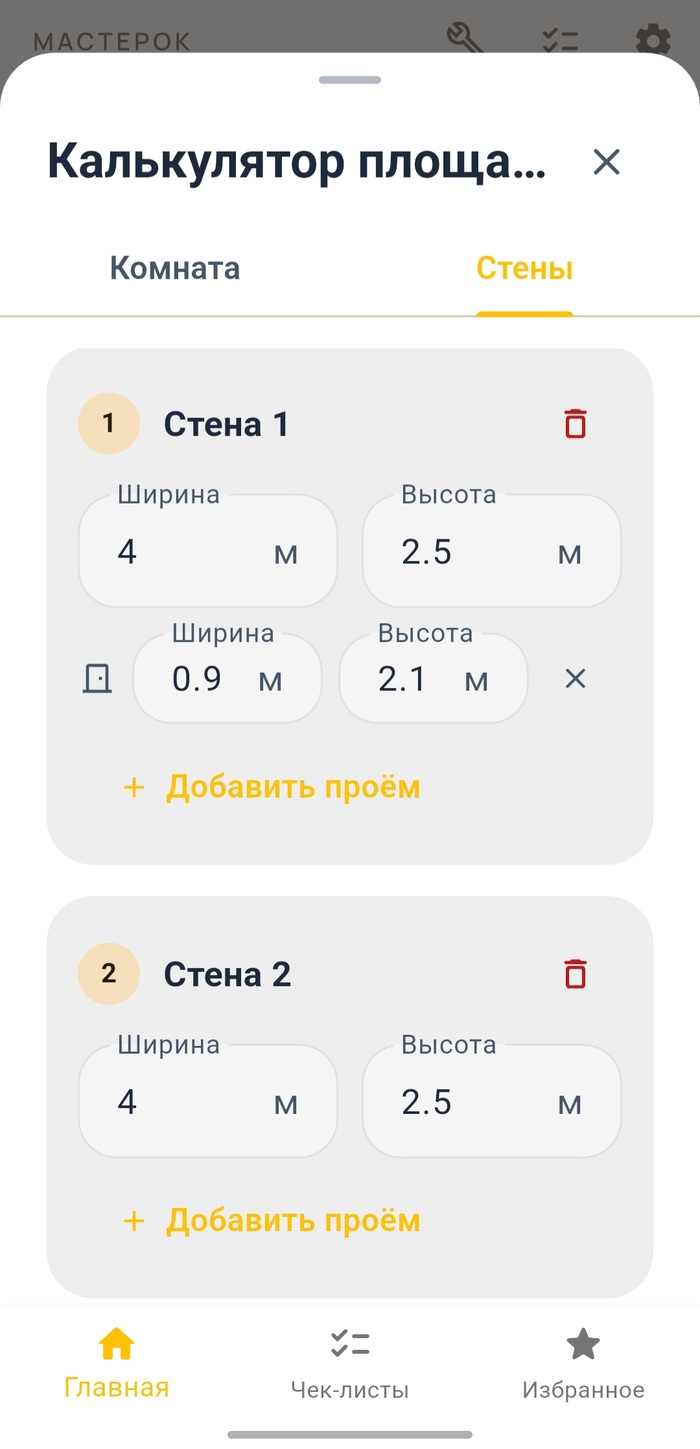
В режиме «Стены» всё гибче: добавляешь каждую стену отдельно, задаёшь ей ширину и высоту, а главное — можно указать проёмы. Дверной проём 0.9 на 2.1 метра? Добавил, и площадь стены пересчиталась автоматически с его вычетом. Можно добавлять несколько проёмов на одну стену — окна, двери, ниши. Для тех, кто хоть раз покупал плитку или штукатурку «на глаз» и потом бегал за довеском, это реально полезная функция.
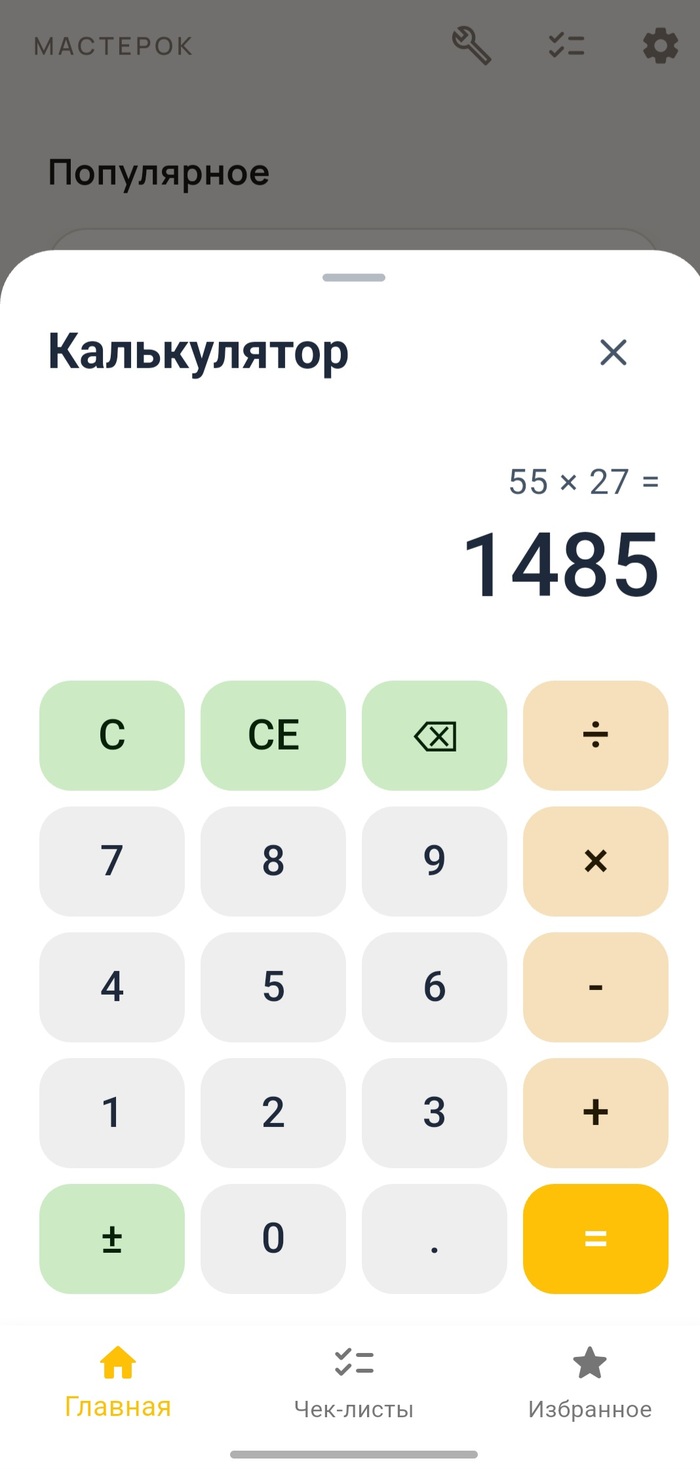
Обычный калькулятор — да, я добавил в строительное приложение обыкновенный калькулятор. Причина банальная: когда ты на объекте и считаешь, сколько стоят 55 листов гипсокартона по 1200 рублей за штуку (условно), не хочется выходить из приложения ради стандартного калькулятора на телефоне. Переключаться туда-сюда неудобно, а тут всё под рукой. Он встроен прямо в верний слой навигации инструментов, открывается в один тап.
Михалыч: зачем строительному приложению персонаж
Теперь о главном. Михалыч — это AI-ассистент, который живёт внутри приложения, но принципиально отличается от того, что обычно подразумевают под «ИИ-помощником». Когда я только начал думать про интеграцию нейросети, первая мысль была очевидной: сделать стандартного вежливого бота, который отвечает по делу. «Для вашей площади рекомендуется приобрести N квадратных метров плитки с учётом запаса 10%». Всё корректно, всё аккуратно, и всё бесконечно скучно.
Я потестировал такой вариант и понял, что через три минуты общения хочется закрыть чат и больше не открывать. Нет ни одной причины задержаться, нет эмоции, нет ощущения, что тебе отвечает кто-то, а не что-то. И тогда пришла идея: а что, если сделать не помощника, а персонажа? Конкретного, с биографией, манерой речи и отношением к собеседнику.
Так появился Михалыч — прораб с тридцатилетним стажем. Он разговаривает так, как разговаривает реальный опытный строитель: прямо, иногда жёстко, с подколами и профессиональным снисхождением к новичкам. Он не просто отвечает на вопросы, он комментирует ваши решения. Спросите его, сколько кафеля нужно на ванную шесть квадратов — он не начнёт вежливо уточнять параметры. Он скажет что-то вроде «Слышь, математик, шесть квадратов — это ты площадь пола мне сказал или стен, я гадать должен?» И дальше объяснит, почему не стоит брать плитку метр на метр в маленькую ванную, порекомендует стандарт 30 на 60 и предупредит, чтобы не брали самый дешёвый клей.



Вот это отношение — ключевая вещь. Михалыч не боится быть неудобным. Если вы задумали лофт в хрущёвке, он так и скажет: «Не лепи ты этот лофт в хрущёвке, лучше светлые тона бери, хоть дышать будет где». Если спросите про дизайн комнаты — посоветует. Если зададите размытый вопрос — не будет делать вид, что всё понял, а потребует конкретику. Именно так ведёт себя живой человек, который разбирается в теме и не собирается тратить время на угадайку.
Как устроен Михалыч под капотом
Технически Михалыч работает на модели Gemini 3 Flash (preview) через OpenRouter API. Выбор именно такой связки — не от хорошей жизни. Изначально я пытался использовать Google API напрямую, но из-за санкций нормально работать с сервисами Google из России без обходных путей невозможно. Была попытка пустить трафик через Cloudflare Workers — день поработало нормально, а на второй всё отвалилось. Вероятнее всего, публичные адреса такого рода блокируются на уровне провайдера (но все мы знаем кто обрубает). OpenRouter решил эту проблему: он выступает промежуточным слоем, через который запросы уходят к модели без лишних сложностей.
В приложении Михалыч реализован через отдельный сервис — Ai.Service. Я сознательно разделил его и калькуляторы: Михалыч работает в своём собственном окне и не лезет в расчёты. Это правильный подход с точки зрения архитектуры. Калькуляторы — это точные инструменты, где два на три всегда шесть. А Михалыч — это советчик, который оперирует опытом и контекстом. Смешивать одно с другим, значит, создавать путаницу: пользователь не будет понимать, где точный расчёт, а где рекомендация.
Самое интересное в создании Михалыча — это работа над системными инструкциями. Я написал подробный промпт, в котором описал характер персонажа, его манеру общения, профессиональный бэкграунд и даже ограничения. Михалыч должен быть грубоватым, но не хамом. Он подкалывает, но не оскорбляет. Он категоричен в профессиональных вопросах, но открыт к диалогу. Добиться правильного баланса было отдельной задачей, и я потратил на эксперименты с промптом немало времени, прежде чем речь Михалыча стала звучать естественно.
Его приветственное сообщение задаёт тон всему общению: «Здорово, хозяин, чего стоишь, инструмент глазами ищешь? Я тут за твоими расходами приглядываю, чтоб ты в трубу не вылетел с этим ремонтом». Сразу понятно, с кем имеешь дело, и сразу понятно, что можно спрашивать.
О приложении в целом
«Мастерок» написан на Flutter с использованием Kotlin для платформенных вещей и имеет 250 000 строк кода. Приложение опубликовано в RuStore и доступно бесплатно, включая Михалыча и все калькуляторы. Решение сделать всё бесплатно осознанное: мне сейчас важнее набрать первую базу активных пользователей, получить обратную связь и понять, какие функции востребованы, а какие нет. Монетизация — вопрос следующего этапа, когда будет хотя бы сотня-другая постоянных пользователей.
На момент публикации в RuStore у приложения рейтинг 4.9 и размер около 19 мегабайт. Для строительного калькулятора с ИИ-ассистентом на борту — это весьма скромный вес. Я специально старался не раздувать приложение лишними зависимостями и библиотеками.
Если говорить о конкурентном поле — я не видел ни одного строительного калькулятора в российских сторах, который совмещал бы набор профильных инструментов с AI-ассистентом в таком формате. Есть отдельные калькуляторы, есть отдельные чат-боты, но связка «считай + спроси совета у опытного прораба» в одном приложении — это, насколько мне известно, уникальная история.
Что дальше
Планы на ближайшие обновления связаны и с расширением набора калькуляторов, и с развитием Михалыча. Хочется научить его работать с фотографиями — например, чтобы пользователь мог сфотографировать стену, а Михалыч прикинул объём работ. Технически это возможно с мультимодальными моделями, вопрос в том, чтобы сделать это стабильно и полезно, а не как демонстрацию технологии ради технологии.
Если пользуетесь строительными калькуляторами — попробуйте, буду рад любой обратной связи. А если поговорите с Михалычем, не обижайтесь, он мужик хороший, просто характер такой.