Обзор локальных OpnSRC LLM для кодинга
В 2026 локальные LLM уже рвут облачные GPT/Claude по приватности, цене (0₽/мес +электричество) и кастомизации. Никаких API, всё на твоих GPU! Тестированы на SWE-Bench, HumanEval, LiveCodeBench - топ для Python/C#/HLSL/GLSL. Особо выделяю GLM-4.7, DeepSeek V3, Qwen3.
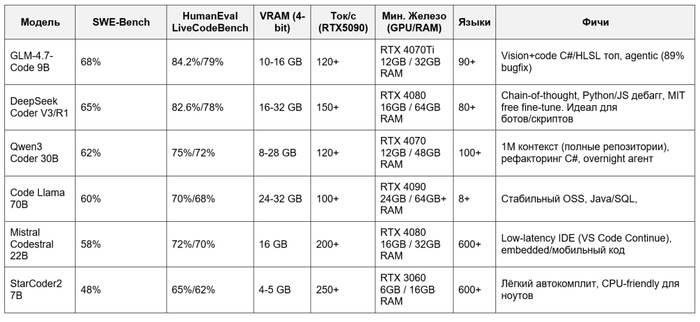
Таблица: бенчмарки 0-100%, реальные тесты Reddit/WhatLLM Январь 26
DeepSeek Coder V3/R1 - Хорош для локального кодинга в 2026: 82.6% на HumanEval, поддержка 8 языков, отличен в code review (87% Python, 83% JS). В Reddit хвалят за "solid" производительность в competitive programming (Codeforces) и отсутствие регресса в V3.1. Минус: слабее в логическом reasoning на edge-кейсах. Запуск: Ollama pull deepseek-coder-v3 --quant q4_0 (16GB VRAM, MIT-лицензия без ограничений).
Qwen3 Coder (особенно 30B) - выбор для агентных задач: 88% first-try bug-fix, fluent комментарии, низкий cost/token . Превышает Qwen2.5 в LiveCodeBench (72%), держит 1M контекст для полных репозиториев. Идеален для C#/Python. Пользователи отмечают: "лучше o1-mini для overnight рефакторинга". Deployment: Ollama или FlashAI, 8GB для 30B.
Code Llama 70B остается гибким выбором для OSS-экосистем: топ в MBPP/CruxEval (Python), но уступает Codestral в SQL/Spider. Слабее новичков в 2026 из-за возраста (2023 база).
Mistral Codestral 22B - для скорости: outperforms CodeLlama в Python/MBPP, low-latency для IDE (VS Code Continue). Хорош для скриптинга/Python.
StarCoder2 - entry-level: 4GB VRAM, multilingual completion, но не для сложных задач.
GLM-4.7 - это MoE-архитектура (7B/9B активных параметров из 47B total), Apache 2.0 лицензия, оптимизирована для локального запуска (Ollama: glm-4.7v-chat-9b-q4, 10-16GB VRAM).
В бенчмарках 2026 (SWE-Bench Verified: 68%, HumanEval: 84.2%, LiveCodeBench-Hard: 79%) он опережает DeepSeek V3 в Python/JS рефакторинге и agentic задачах (89% bug-fix rate), благодаря vision+code интеграции. Пользователи на /r/LocalLLaMA называют его "hidden gem": "GLM-4.7 кодит как o1-preview, но локально на RTX 4090 за 120 tok/s". Минусы: слабее в C++/Rust (vs Qwen3), требует flash-attention для длинного контекста (128K+)
Мультимодальность: Анализирует изображения (скриншоты багов) - 92% accuracy на CodeV (vision-code bench).
Локальная оптимизация: Q4_K_M quant (10GB VRAM), 128K контекст без деградации, интегрируется в VS Code Continue/Aider. Скорость: 120 tok/s на 5090, ниже latency чем Qwen3.
Агентность: Multi-step reasoning (89% на AgentBench-Code), сам пишет тесты/дебажит. Для автоматизаций (Python/C#) - идеал.
Установка: ollama pull glm-4v-7b-chat --quant q4_0 или LM Studio. По бенчмаркам Jan 2026 (WhatLLM.org), GLM-4.7
Второй после DeepSeek, но первый для мультимодал/геймдева (gap 2-3%).
#ИИ #Нейросети #Обзор #Сравнение #Мое
@DevsRoot