

Новости
38 постов
38 постов

2 поста

8 постов

40 постов

62 поста

12 постов
7 постов
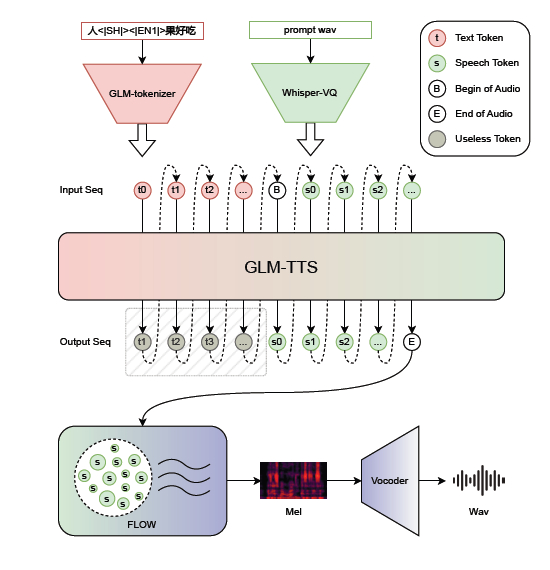
Выложена производственная система синтеза речи (TTS), ориентированная на эффективность, управляемость и качество GLM-TTS (https://huggingface.co/zai-org/GLM-TTS).
Она имеет двухэтапную архитектуру, в которой соединена авторегрессионная модель "текст-в-токены" и диффузионная модель "токены-в-волну". В ней присутствует оптимизированный токенизатор речи на основе Whisper-VQ с ограничениями по тону (F0) и увеличенным словарём, что даёт результат в виде высокой схожести голоса (SIM=76.1) и низкой частоты ошибок по символам (CER=1.03%).
Её обучение было с подкреплением (RL) по методу GRPO с несколькими reward-функциями (произношение, схожесть, эмоции, смех), благодаря чему улучшалась выразительность и стабильность обучения. Кастомизация голоса через тонкую настройку LoRA (только ~15% параметров) является низкозатратной, и для этого требуется ~1 час аудио целевого голоса.
А точный контроль произношения через гибридный ввод "текст + фонемы" решает проблему омофонов и редких слов, особенно для китайского языка. Улучшенный вокодер Vocos2D с 2D-свертками может лучше моделировать частотные поддиапазоны, повышая качество звука.
В итоге по эффективности модель достигает SOTA (state-of-the-art) результатов на открытых бенчмарках, обучаясь всего на ~100k часов данных (значительно меньше аналогов).
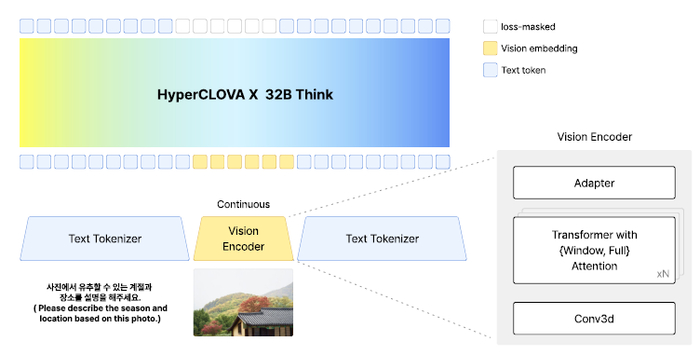
Опубликованная мультимодальная модель HyperCLOVA X 32B Think (https://huggingface.co/naver-hyperclovax/HyperCLOVAX-SEED-Th...) специально создана для рассуждений в корейском языковом и культурном контексте, а также для работы в качестве агента.
Внутри её архитектуры находится декодерный трансформер, обрабатывающий текстовые токены и визуальные представления в едином пространстве. Фокус модели был сделан на глубокое понимание корейского языка и культуры, поддержку английского и агентские способности (планирование, использование инструментов). Процесс обучения начался с многоэтапного предобучения на корейских данных с упором на рассуждения, затем последовало постобучение для добавления мультимодальности и агентских функций.
В плане эффективности модель оптимизирована для работы с корейским текстом и визуальной информацией.
В результате на корейских бенчмарках (текст и изображение) получились конкурентные или лучшие результаты среди моделей сопоставимого размера, а в агентских задачах она опережает аналогичные модели и конкурирует с некоторыми более крупными коммерческими. Что касается английских бенчмарков, то результаты скромнее, что является осознанным компромиссом в пользу корейского контекста.

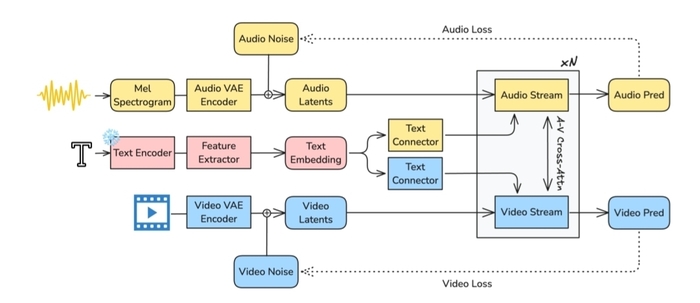
Появилась новая открытая модель, которая единым процессом генерирует высококачественное видео с синхронизированным звуком (речь, фоновые шумы, музыка) по текстовому описанию под названием LTX-2 (https://huggingface.co/Lightricks/LTX-2).
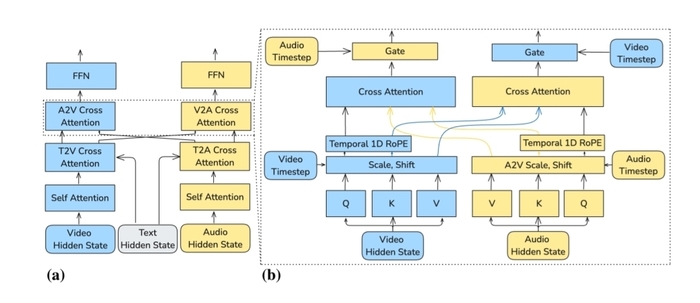
Её архитектура представляет собой асимметричный двунаправленный трансформер с отдельными потоками для видео (14B параметров) и аудио (5B параметров), связанными сквозным кросс-вниманием. Для создания применялось сквозное обучение, во время которого модель обучается совместно на видео и аудио, что обеспечивает лучшую синхронизацию (например, движение губ и речь), чем раздельные модели.
В плане эффективности она значительно быстрее (до 18x) и требует меньше ресурсов, чем аналоги, при этом генерирует ролики длиной до 20 секунд.
Чтобы реализовать мультиязычность, используют мощный языковой энкодер (Gemma 3), что улучшает понимание сложных запросов и точность синтеза речи. Для контроля используется механизм Modality-CFG, позволяющий независимо настраивать влияние текста и другой модальности на результат.
В результате LTX-2 показывает лучшее качество среди открытых моделей для совместной генерации, сопоставимое с закрытыми системами (Veo 3, Sora 2), но работает намного быстрее и эффективнее. Также занимает высокие места в рейтингах по генерации только видео.
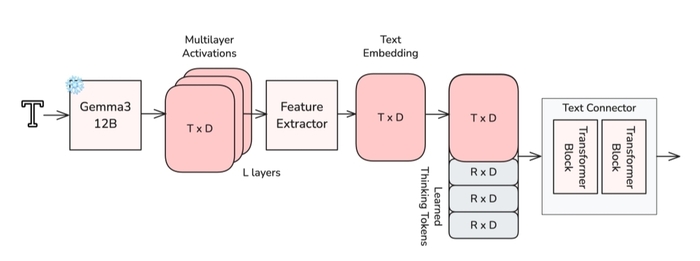
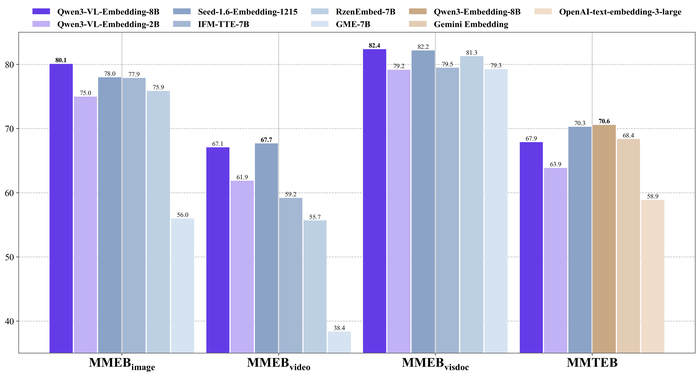
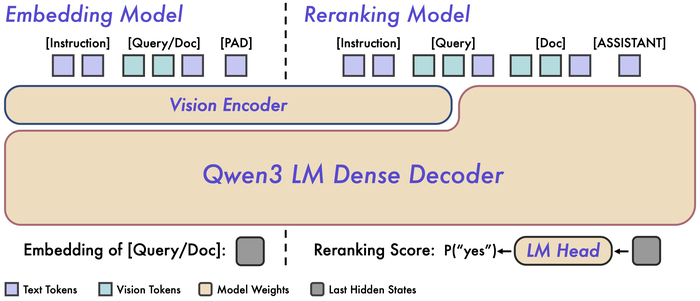
Выпущенные мультимодальные модели Qwen3-VL-Embedding (https://huggingface.co/collections/Qwen/qwen3-vl-embedding) и Qwen3-VL-Reranker (https://huggingface.co/collections/Qwen/qwen3-vl-reranker) для поиска созданы на основе Qwen3-VL и могут обрабатывать текст, изображения, видео, скриншоты. Они предназначены для совместного использования в системах мультимодального поиска.
Модель Embedding преобразует данные в семантические векторы для поиска похожего, а Reranker оценивает точную релевантность пары (запрос, документ). В рамках двухэтапного поиска Embedding сначала находит множество кандидатов, после чего Reranker точно их ранжирует.
В архитектуре Embedding есть две независимые башни, тогда как у Reranker только одна башня с перекрёстным вниманием. Модели имеют мультиязычность, поддерживая более 30 языков, обладают возможностью квантования и настройки при помощи инструкций.
В результате Qwen3-VL-Embedding-8B показывает наилучшие результаты на мультимодальном бенчмарке MMEB-v2, в то время как Qwen3-VL-Reranker превосходит базовые модели и аналоги при повторном ранжировании.
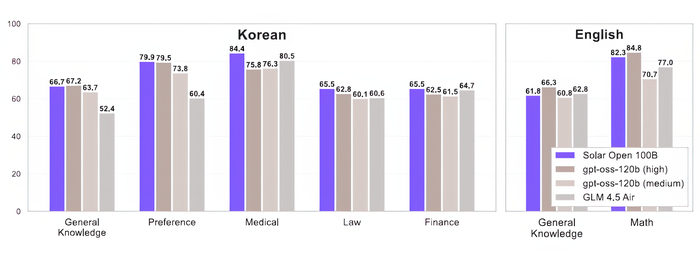
Двуязычная модель Solar Open (https://huggingface.co/upstage/Solar-Open-100B) для малопредставленных языков использует архитектуру Sparse Mixture-of-Experts (MoE) с общим числом параметров 102B и 12B активных параметров на токен, и у неё есть специальный токенизатор, оптимизированный для корейского языка.
Целью её разработки было создание конкурентоспособной языковой модели для языков с дефицитом данных (на примере корейского).
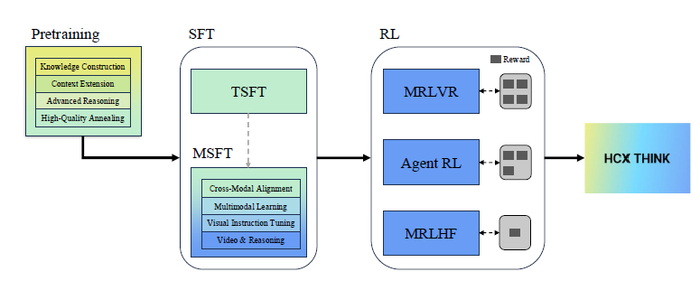
Во время создания модели была нехватка данных, и чтобы заполнить базу, было сгенерировано 4.5 трлн токенов синтетических данных высокого качества для пре-тренинга, SFT и RL. Управление данными осуществляли, применяя прогрессивную учебную программу для совместной оптимизации состава, качества и охвата доменов в англо-корейском корпусе (20 трлн токенов). Масштабируемое RL реализовали с использованием фреймворка SnapPO, который разделяет генерацию данных, вычисление вознаграждений и обучение, что позволяет эффективно обучать на множестве задач.
На первом этапе процесса обучения всё началось с пре-тренинга (19.7T токенов), где была поэтапная учебная программа с увеличением доли синтетических данных (до 64%) и ужесточением фильтрации качества. Затем был Mid-training (1.15T токенов), суть которого заключалась в улучшении логического мышления с помощью синтезированных "траекторий рассуждений". А к концу начался Post-training (SFT + RL). SFT использовался для следования инструкциям и базовых навыков. RL имел два этапа, и на первом он был направлен на улучшения рассуждений (STEM, код, агенты), а на втором он был применён для выравнивания с предпочтениями человека и безопасности.
В результате модель демонстрирует сильные результаты в корейских тестах (общие знания, финансы, право, медицина), превосходя или соответствуя аналогам, при этом сохраняя конкурентоспособную производительность на английском.
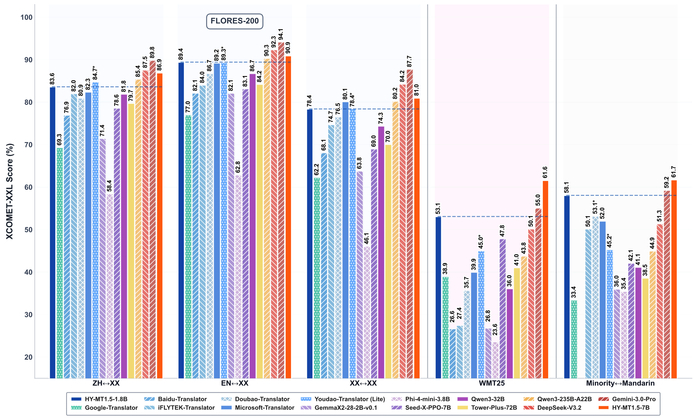
Тут сразу представлены две новые модели для машинного перевода от Tencent Hunyuan Team (https://huggingface.co/tencent/HY-MT1.5-1.8B), и первая из них HY-MT1.5-1.8B (1.8 млрд параметров), а вторая HY-MT1.5-7B (7 млрд параметров). А также предложен комплексный фреймворк их обучения.
По эффективности модели дают хороший баланс между качеством перевода и скоростью работы. HY-MT1.5-1.8B по качеству превосходит многие средние открытые модели (например, Tower-Plus-72B) и коммерческие API (Microsoft, Doubao), достигая ~90% качества большой закрытой модели Gemini-3.0-Pro. В свою очередь модель HY-MT1.5-7B ещё мощнее и на тесте Flores-200 достигает ~95% качества Gemini-3.0-Pro, а на WMT25 и переводах с китайского на языки меньшинств вообще превосходит его.
Если говорить об их специальных возможностях, то модели поддерживают управление терминологией, контекстный и форматированный перевод через промты.
Для их обучения был применён многоэтапный процесс, включающий предобучение, тонкую настройку, дистилляцию и обучение с подкреплением.
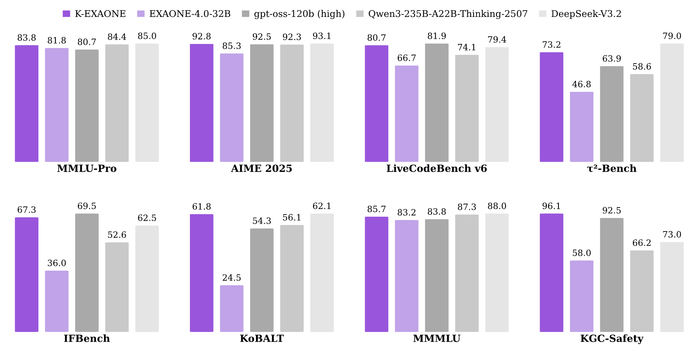
Опубликованная крупная мультиязычная модель K-EXAONE-236B-A23B (https://huggingface.co/LGAI-EXAONE/K-EXAONE-236B-A23B) имеет MoE архитектуру (236B параметров, активно 23B).
Она поддерживает корейский, английский, испанский, немецкий, японский и вьетнамский язык. Её контекст имеет размер в 256K токенов. У неё эффективная MoE-архитектура + гибридное внимание. Также в ней используется улучшенный токенизатор (словарь на 150K токенов).
Во время обучение в начале было трехэтапное предобучение (11T токенов), а затем постобработка (SFT, RL, выравнивание предпочтений).
В результате её конкурентоспособная производительность на уровне передовых открытых моделей в рассуждениях, общих задачах, корейском и мультиязычных бенчмарках.
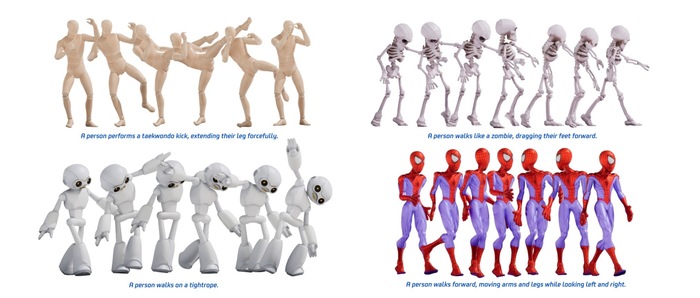
Загрузили сразу серию больших моделей для генерации 3D-движений человека по текстовому описанию HY-Motion 1.0 (https://huggingface.co/tencent/HY-Motion-1.0).
Эта модель первая в своей области с архитектурой Diffusion Transformer (DiT), масштабированная до миллиарда параметров.
Для того чтобы создать эту модель, её пришлось пронести через полный цикл обучения. В самом начале было предобучение на >3000 часов разнообразных данных о движениях. Затем началась точная настройка на 400 часах отобранных высококачественных данных. К концу перешли к доводке с помощью обучения с подкреплением (RL) на основе обратной связи от людей и reward-моделей для улучшения качества и соответствия тексту.
Для подготовки данных использовали собственный пайплайн обработки данных (очистка, аннотирование) с таксономией из >200 категорий движений.
В результате эта модель превосходит современные открытые аналоги по качеству движений и точности следования текстовой инструкции.
