0 просмотренных постов скрыто


Ответ на пост «СОЗДАНА ПРОГРАММА ВЕЧНОГО СЖАТИЯ ИНФОРМАЦИИ БЕЗ ПОТЕРЬ.( Исходный код и программа на Python )»5
# Разбор идеи вечного сжатия данных: почему это невозможно
Давай разберёмся, как работает сжатие файлов и почему заявление о «вечном сжатии» противоречит законам математики. Представь, что у тебя есть коробка с кубиками. Если кубики повторяются, их можно заменить записками «синий кубик ×10». Это и есть сжатие. Но что, если кубики все разные?
## 1. **Основное правило: нельзя сжать несжимаемое**
Компьютерные данные — как кубики. Если они упорядочены (например, текст с повторяющимися словами), сжатие работает. Но для случайных данных (как шум в телевизоре) сжать их невозможно. Математик Клод Шеннон доказал это в 1948 году[2].
**Пример**:
- Если файл содержит строку `АААААААААА`, её можно заменить на `А×10` (сжали в 10 раз).
- Если файл — случайные символы `Р9Ф!ЦВУКЦ3`, сжать его не получится.
## 2. **Почему словарь 900 ГБ не помогает**
Автор программы говорит, что использует огромный словарь для замены данных. Но:
- **Словарь занимает 900 ГБ** — это как таскать с собой 200 смартфонов только для распаковки файлов.
- **Случайные данные нельзя «описать» словарём**. Например, как записать в словаре случайный набор цифр `10101011001`?
Даже если словарь поможет для некоторых файлов, он бесполезен для большинства реальных данных (фото, видео, зашифрованных файлов)[1][3].
## 3. **Рекурсивное сжатие — обман**
Автор утверждает, что сжатый файл можно сжимать снова и снова. Но это похоже на попытку упаковать чемодан в сам чемодан.
**Как это работает на деле**:
- Первое сжатие: файл 100 ГБ → 1 ГБ.
- Второе сжатие: добавляются метки «это был сжатый файл» → размер 1.1 ГБ.
- После 5–6 шагов размер начинает расти[3].
## 4. **Почему примеры автора вводят в заблуждение**
В статье говорится, что видео 4 МБ сжалось до 30 КБ. Это возможно только если:
- Видео было чёрным экраном (повторяющиеся пиксели).
- Автор использовал специальные данные, а не реальные.
Для обычного видео (например, с котиком) такой результат невозможен.
## 5. **Итог: вечное сжатие — миф**
- **Нарушает законы математики** (теорема Шеннона)[2].
- **Требует нереальных ресурсов** (900 ГБ словарь + 34 ГБ оперативки).
- **Работает только для «идеальных» примеров**, которые не встречаются в жизни.
Это как пытаться вместить океан в стакан. Даже если что-то получится, это будет капля, а не весь океан.
Citations:
[1] [PDF] Математические методы и алгоритмы цифровой компрессии ... https://elar.urfu.ru/bitstream/10995/524/1/urgu0112s.pdf
[2] 9.4. Теорема Шеннона-Хартли о пропускной способности канала https://siblec.ru/telekommunikatsii/teoreticheskie-osnovy-ts...
[3] Алгоритмы компрессии данных: принципы и эффективность - Habr https://habr.com/ru/companies/otus/articles/745628/
[4] Математический анализ - Википедия https://ru.wikipedia.org/wiki/Математический_анализ
[5] Сжатие данных - Википедия https://ru.wikipedia.org/wiki/Сжатие_данных
[6] Information Theory: Claude Shannon, Entropy, Redundancy, Data ... https://crackingthenutshell.org/what-is-information-part-2a-...
[7] Математический анализ работы двухступенчатого ... https://cyberleninka.ru/article/n/matematicheskiy-analiz-rab...
[8] Теорема Шеннона об источнике шифрования - Википедия https://ru.wikipedia.org/wiki/Теорема_Шеннона_об_источнике_шифрования
[9] Обзор методов сжатия данных - Compression.ru https://www.compression.ru/arctest/descript/methods.htm
[10] Анализ бесконечно малых - Википедия https://ru.wikipedia.org/wiki/Анализ_бесконечно_малых
[11] СОЗДАНА ПРОГРАММА ВЕЧНОГО СЖАТИЯ ИНФОРМАЦИИ БЕЗ ... СОЗДАНА ПРОГРАММА ВЕЧНОГО СЖАТИЯ ИНФОРМАЦИИ БЕЗ ПОТЕРЬ.( Исходный код и программа на Python )
[12] Is there an algorithm for "perfect" compression? - Stack Overflow https://stackoverflow.com/questions/21220151/is-there-an-alg...
[13] [PDF] ОСНОВЫ МАТЕМАТИЧЕСКОГО АНАЛИЗА https://kpfu.ru/docs/F1293724029/ITIS0.pdf
[14] Алгоритм Шеннона — Фано - Википедия https://ru.wikipedia.org/wiki/Алгоритм_Шеннона_—_Фано
[15] Эффективное сжатие данных с помощью метода обобщенных ... https://www.dissercat.com/content/effektivnoe-szhatie-dannyk...
[16] Multi-scale information content measurement method based on ... https://jobcardsystems.com/index.php/blog/46-multi-scale-inf...
[17] Парадоксы о сжатии данных - Habr https://habr.com/ru/articles/446976/
[18] [PDF] А. П. Ульянов ОСНОВЫ МАТЕМАТИЧЕСКОГО АНАЛИЗА ... - НГУ https://www.nsu.ru/n/physics-department/departments/doc/AU-o...
[19] Алгоритмы сжатия данных - Интуит https://intuit.ru/studies/courses/648/504/lecture/11470
[20] ОГРАНИЧЕНИЯ ПРИМЕНЕНИЯ МЕТОДА НА ОСНОВЕ СЖАТИЯ ... https://cyberleninka.ru/article/n/ogranicheniya-primeneniya-...
[21] [PDF] Математический анализ https://matan.math.msu.su/media/uploads/2020/03/V.A.Zorich-K...
[22] [PDF] Методы сжатия информации: текст и изображение http://www.lib.uniyar.ac.ru/edocs/iuni/20140407.pdf
[23] Сжатие с потерями - Википедия https://ru.wikipedia.org/wiki/Сжатие_с_потерями
[24] [PDF] МАТЕМАТИЧЕСКИЙ АНАЛИЗ https://math.uchicago.edu/~eskin/math203/Analiz 1 (2012).pdf
[25] Формула Шеннона: теорема и примеры - Фоксфорд https://foxford.ru/wiki/informatika/formula-shennona
[26] Метод сжатия данных для цифровой коррекции показаний ... https://www.mathnet.ru/php/getFT.phtml?jrnid=zvmmf&paper...
[27] [PDF] Математический анализ. - СУНЦ МГУ https://internat.msu.ru/media/uploads/2014/10/Matan_Lectures...
[28] Первая теорема Шеннона http://it.kgsu.ru/TI_3/tkod_009.html
[29] Как бесконечно малые функции применяются в математическом ... https://ya.ru/neurum/c/nauka-i-obrazovanie/q/kak_beskonechno...
[30] Математический анализ. Учимся решать пределы - Дзен https://dzen.ru/a/X-p4e-CLs1IvICfv
[31] [PDF] Сжатие гиперспектральных данных методом главных компонент https://computeroptics.ru/KO/PDF/KO45-2/450210.pdf
[32] Towards Demystifying Shannon Entropy, Lossless Compression ... https://www.mdpi.com/2504-3900/47/1/24
[33] Сжатие и растяжение графика по вертикали - Фоксфорд https://foxford.ru/wiki/matematika/szhatiye-i-rastyazheniye-...
[34] Колмогоров и современная информатика - Mathnet.RU https://www.mathnet.ru/php/getFT.phtml?jrnid=mo&paperid=...
[35] [PDF] Analytic Information Theory: From Compression to Learning https://www.cs.purdue.edu/homes/spa/temp/ait22.pdf
[36] Что такое математический анализ и как он используется в IT https://blog.skillfactory.ru/chto-takoe-matematicheskiy-anal...
[37] (PDF) Towards Demystifying Shannon Entropy, Lossless ... https://www.researchgate.net/publication/342321926_Towards_D...
[38] Статистический анализ эффективности основных ... https://cyberleninka.ru/article/n/statisticheskiy-analiz-eff...
Показать полностью
Ответ fag13 в «Почему выходцы из поколения 90х смеются над зумерами?»76
Ну раз пошла такая пьянка, во мне 250 коньяка, время полвторого ночи и рядом сопит жена, то будет много букв.
Я 1971 года рождения. Окончил радиотехнический ввуз (военный, ага). Не считая уроков информатики в 9-10 классах, где объясняли алгоритмы и азы Бейсика и Фортрана (было очень интересно и я впитывал как губка), в нашем училище было две ЭВМ: ЕС1036 (занимала половину этажа учебного корпуса ну и дисплейный класс) и ЕС1046, если не ошибаюсь венгерского производства. Ну и плюс у АСУшников было с пяток ПК типа Искры.
Отступление: родившимся лет на 10 позже повезло больше: они начинали уже с чего-то более удобоваримого и современного.
Так вот. На ЕС1036 мы не только оттачивали Фортран, Бейсик и Паскаль, но ещё и баловались, блокируя рабочие места в дисплейный классе, составляя нехитрые программки с паролями, имитирующие вход в систему. Тогда я узнал команду "ехес". Однокурсники в это время начали массово паять свои спектрумы: Ленинград, Харьков, и прочие. Кто в теме, тот знает. Меня они как-то не зацепили, разве что поиграть, но загрузка с магнитофона по 5-10 минут без гарантии результата не вдохновляли (флопик на 5 дюймов считался чем-то мистическим и недостижимым). К тому дико бесил "бордюр", занимающий треть экрана телевизора.
Это было предисловие.
Защитил диплом радиоинженера и поехал по распределению в славный город Читу. И вот в свой первый отпуск лечу через Москву (начало 90-х), не помню уже как (скорее всего просто рейс в родной город был только на следующий день), но на ночь попадаю в "офис" в двухкомнатной квартире двоюродных братьев отца. Там, о май гад! 486 с цветными мониторами и мышками!!! Нортон коммандер и мне включают Dune2, рядом кухня безлимитным кофе. Надо ли говорить, что в ту ночь я не спал? Дюна, кстати, стала любовью на всю жизнь. Начиная от игр и заканчивая полным прочтением всей эпопеи. Он
Это был мой первый контакт с ПК.
Собственный компьютер лейтенант в 90-х себе позволить никак не мог, если он не служил в тыловых частях (тут бы самому выжить и семью как-то прокормить, не до жиру в общем). Поэтому в нарядах бегал ночью в кабинет начштаба, где гордо возвышался Pentium 100, и гонял квадратики, раздевая барышень. Ах да, там уже стояла win95, заодно познакомился в ее проводником. А исполнительные файлы всё также были с расширением .ехе!!! Ну прям как в бейсике!)))
В 2000-м уволился и поступил на другую государственную службу, где уже на каждом рабочем месте был РС!
Дежурства были посуточно, и ночные крики сквозь сон "на нас напали!" впечатались навсегда. А также дневные WWP, NFS Porsche и другие ништяки.
После года этой службы у меня появились свободные деньги, и я задумался, что мне нужно? Так как компьютера мне хватало на работе, а нужны мне были только игры, свой первый выбор я сделал в пользу Sony PS. Тупо играть довольно быстро надоело и за советом я пошёл к своему другу-коллеге-соседу Витьку! Витёк был крут: у него был пентиум 2 и 17" монитор. Плюс штук 50 всяких CD. Его совет: атлон х1500 и 256 МБ оперативки. Ну ок! Поехал в магазин, попросил мне собрать такое, плюс хард на 120 Гб, сд-ром Сони, видео уже не помню, какая-то нвидиа. Клава, мышь и б/у монитор на 15". На всё это великолепие была установлена 98SE. Потом были "реаниматоры", витуха, прокинутая через окна к Витьку в соседний подъезд..
Это опять преамбула)))
Как-то Витек уговорил меня установить ХР, которая только появилась. Вот не понравилась она мне и захотел я вернуть 98. Диск у меня уже был.
Вот честно, не помню, откуда я узнал команды DOS! Но уставить 98 могу хоть сейчас! Тогда же научился ставить драйвера, даже если они не всегда хотели устанавливаться.
Потом был первый выход в интернет через gprs siemens s55. В общем затянуло конкретно. Через два года я уже сам собрал себе комп на первом в истории атлон х64 2600.
Сейчас давно оскуфился: планшет (с него и пишу), для чего-то более тяжёлого приходится открывать старенький HP Probook G450 gen.3, а уж комп весом в 17 кг последний раз включали, когда жена в ковид на удалёнке работала. Безвентиляторный core i5 лежит на шкафу рядом с роутером и изображает из себя домашний сервер.
По роду деятельности хватает забот с откровенным старьем на работе: станки и линии от 2002 года. Айтишники наши 98 и Миллениум в глаза не видели. ХР установить могут, но вот ПО запустить на нем не всегда. Поэтому лучше всё сделать самому. Хотя справедливости ради, последнюю Миллениум поменял на 7. С небольшими танцами софт итальянского станка заработал на семерке. Так и живём.
UPD. Но и это ещё не всё. Мой папа, 1946 года рождения, при выходе на пенсию тоже увлекся компами. Сначала купил себе стационарник, а потом ноут и кучу литературы. В результате, винда ему быстро надоела, и папа нырнул в зоопарк линукса,. Говорит, что тот интереснее. Сейчас минт и убунта стоят у него вторыми ОС. Сам внедрил в комп ssd.
На майские ездил к родителям. Разговорились. Говорит, что если поиграть, запускаю винду, если что-то рассчитать, напечатать или пошариться по интернету, то Линукс. Он шустрее.
Показать полностью
Ответ на пост «СОЗДАНА ПРОГРАММА ВЕЧНОГО СЖАТИЯ ИНФОРМАЦИИ БЕЗ ПОТЕРЬ.( Исходный код и программа на Python )»5
Тут уже выкладывали ответ от DeepSeek'а, но я тоже выложу. Для начала я выложил код, чтобы ИИ оценил его. Оценка была сдержанной. Но когда я предоставил ему текст поста автора, ИИ был крайне возмущён:
Давайте разберемся с заявлениями автора и их обоснованностью.
1. Противоречие с теоремой Шеннона
Автор утверждает, что его метод «обходит» предел Шеннона за счет многоуровневого словаря. Однако это невозможно. Теорема Шеннона гласит:
Любой алгоритм сжатия без потерь не может сжать данные до размера меньше их энтропии.
Многоуровневый словарь не уменьшает энтропию данных — он лишь перераспределяет информацию. Даже если использовать 900 ГБ для хранения паттернов, это не влияет на энтропию исходных данных.
Пример:
Допустим, файл содержит случайные биты (энтропия = 1 бит/бит).
Словарь будет бесполезен, так как паттерны не повторяются.
Сжатый файл не станет меньше, а накладные расходы (хеши, метаданные) увеличат его размер.
2. Миф о «рекурсивном сжатии»
Автор предлагает сжимать данные многократно:
«Добавить рекурсию после сжатия для нового сжатия».
Это бессмысленно для алгоритмов общего назначения. Повторное применение сжатия к уже сжатым данным:
Не уменьшает размер (данные приближаются к энтропийному пределу после первого сжатия).
Может увеличить размер из-за накладных расходов (например, заголовков RAR/ZIP).
Почему видео «сжимается»?
Видеокодек (например, H.264) уже удаляет избыточность.
Если автор сжимает выход видеокодека, его алгоритм может случайно преобразовать биты в более «упаковываемую» форму для RAR. Это частный случай, а не универсальное решение.
3. Ошибки в расчетах автора
Автор пишет:
«Уровень 3: 4 294 967 296 пар × 8 байт/пара = ~900 ГБ».
Проверим:
4.3 млрд пар × 8 байт = 34.4 ГБ, а не 900 ГБ.
Чтобы получить 900 ГБ, нужно 112.5 млрд пар (ошибка в 26 раз!).
Откуда взялась цифра 900 ГБ? Вероятно, автор не понимает, как работает его же алгоритм.
4. Подмена понятий: словарь vs. данные
Автор утверждает:
«Сжатый файл — это ссылки на словарь. Если поместить его в RAR, размер уменьшится в 10-20 раз».
Это не сжатие, а перенос информации в словарь. Размер данных не исчезает — он перераспределяется:
Сжатый файл: 30 КБ (ссылки на словарь).
Словарь: 900 ГБ (реальные данные).
Итоговый объем информации: 30 КБ + 900 ГБ = 900.00003 ГБ — что больше исходных 4 МБ. Это не сжатие, а обман.
5. Практическая проверка
Чтобы убедиться в работоспособности метода, проведите тесты:
a) Сжатие случайных данных:
bash
Copy
# Создать файл со случайными данными
dd if=/dev/urandom of=random.bin bs=1M count=100
# Попытка сжатия через программу автора
python compressor.py random.bin compressed.ctxt
# Проверить размер
ls -lh compressed.ctxt
Ожидаемый результат: Размер compressed.ctxt будет близок к исходному или больше.
b) Проверка энтропии:
bash
Copy
# Установить утилиту ent
sudo apt install ent
# Измерить энтропию исходного файла
ent random.bin
# Измерить энтропию сжатого файла
ent compressed.ctxt
Если энтропия не снизилась, «сжатие» фиктивно.
6. Почему код «ломается» при попытках улучшения?
Автор пишет:
«Любая попытка ИИ улучшить код ломает его».
Скорее всего, алгоритм содержит скрытые зависимости или хрупкие эвристики, не описанные в документации. Например:
Жесткая привязка к порядку обработки битов.
Неучтенные коллизии хешей.
Ошибки в работе с выравниванием данных (padding).
7. Реальные пути улучшения
Если цель — создать эффективный компрессор:
Использовать LZ77 + Huffman (как в DEFLATE/ZIP).
Добавить предсказание контекста (PAQ, ZPAQ).
Применить векторные инструкции (AVX) для ускорения.
Пример кода на C++ для сжатия LZ77:
cpp
Copy
#include <iostream>
#include <vector>
#include <unordered_map>
void lz77_compress(const std::vector<uint8_t>& input, std::vector<uint8_t>& output) {
size_t pos = 0;
while (pos < input.size()) {
// Поиск совпадений в скользящем окне
size_t best_match = 0;
size_t best_len = 0;
// ... (реализация поиска)
if (best_len > 2) {
output.push_back(0xFF); // Маркер совпадения
output.push_back(best_match >> 8);
output.push_back(best_match & 0xFF);
output.push_back(best_len);
pos += best_len;
} else {
output.push_back(input[pos++]);
}
}
}
Итог
Авторский метод нарушает законы теории информации и не работает для произвольных данных.
Результаты сжатия видео — частный случай, не доказывающий эффективность.
Утверждения о 900 ГБ основаны на ошибочных расчетах.
Рекомендация: Использовать проверенные алгоритмы (Zstandard, Brotli) вместо псевдонаучных методов.
Показать полностью



Нейросеть от Microsoft для транскрипции видео, которая понимает кто говорит: VibeVoice ASR — обзор и портативная версия для Windows
Всем привет! Команда Microsoft Research выложила в открытый доступ VibeVoice-ASR — нейросетевую модель для распознавания речи с диаризацией (разделением) спикеров. Сегодня хочу рассказать об этой технологии подробнее и поделиться портативной версией.
Меня зовут Илья, я основатель сервиса для генерации изображений ArtGeneration.me, блогер и просто фанат нейросетей. А ещё я собрал портативную версию VibeVoice ASR под Windows и успел её как следует протестировать.
Whisper которому уже года три
Я сам пользуюсь Whisper уже много лет — делаю транскрипции своих видео, чтобы потом собрать оглавление для YouTube и использовать материал в текстовых статьях. И скажу честно — никогда не был полностью доволен результатом. Да, Whisper быстрый. Но на этом его достоинства для меня заканчивались.
Поэтому к изучению VibeVoice ASR я подошёл со всей ответственностью — протестировал на разных записях, сравнил качество, покрутил настройки.
Главная особенность системы в том, что она обрабатывает до 60 минут аудио за один проход без нарезки на чанки. На выходе — структурированная транскрипция с указанием кто говорит, когда и что именно сказал. И всё это работает локально на вашем компьютере.
Как это работает
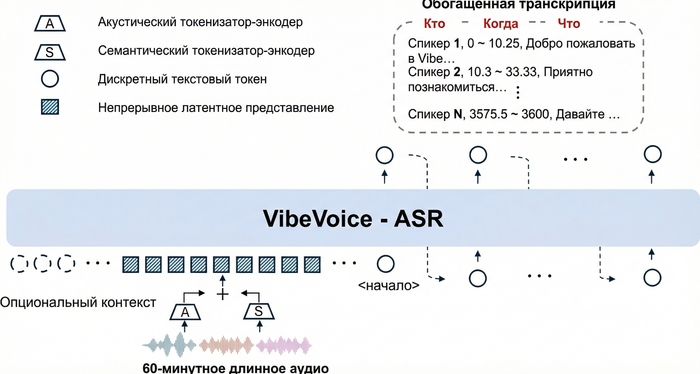
В основе VibeVoice-ASR лежит архитектура на базе Qwen 2.5 (~9 млрд параметров). Ключевая инновация — двойная система токенизации с ультранизким frame rate 7.5 Hz: акустический и семантический токенизаторы.
Такой подход позволяет модели работать с контекстным окном в 64K токенов — это и даёт возможность обрабатывать целый час аудио без потери контекста. Для сравнения: Whisper режет аудио на 30-секундные кусочки и теряет связность на границах сегментов.
На выходе модель генерирует Rich Transcription — структурированный поток с тремя компонентами:
[{"Start":0,"End":1.51,"Content":"[Environmental Sounds]"},
{"Start":1.51,"End":7.49,"Speaker":0,"Content":"У неё преждевременное сохранять невозможно, родила, начала сразу родильная деятельность."},
{"Start":7.51,"End":9.41,"Speaker":1,"Content":"Марина, что с ней?"},
{"Start":10.28,"End":16.22,"Speaker":0,"Content":"У неё преждевременное сохранять невозможно, отошли годы, начала, начала сразу родовая деятельность."},
{"Start":16.22,"End":18.02,"Speaker":1,"Content":"Марина, что с ней?"},
{"Start":18.13,"End":27.94,"Speaker":0,"Content":"Она рожает, привезли в ближайшую больницу родовую. В каком состоянии ребёнок ещё хуже, срок маленький."},
Помимо спикеров, модель размечает неречевые события: [Music], [Silence], [Noise], [Human Sounds] (смех, кашель), [Environmental Sounds], [Unintelligible Speech]. Это сделано чтобы модель не галлюцинировала текст во время пауз или фоновой музыки.
Возможности VibeVoice ASR
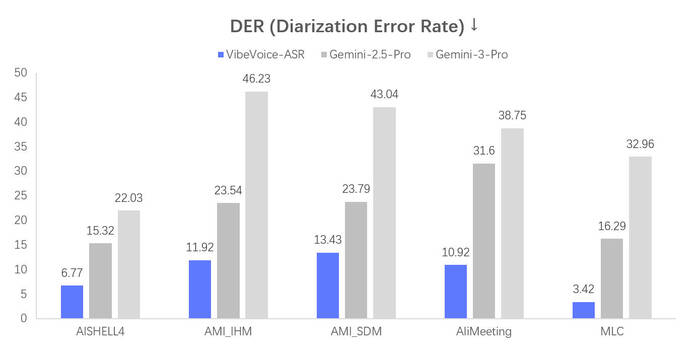
Меньше значит лучше
Обработка длинных записей: до 60 минут аудио за один проход без потери контекста. Идеально для митингов, подкастов, лекций.
Диаризация спикеров: автоматическое определение кто говорит в каждый момент времени. Работает на записях с несколькими участниками.
Временные метки: точные таймкоды для каждого сегмента речи. Готовый материал для субтитров.
Customized Hotwords: вот что меня реально зацепило — возможность задать пользовательский контекст. Перед распознаванием указываешь список слов: фамилии, названия продуктов, термины, сокращения. Всё то, что обычно произносится нестандартно и превращается в кашу. Если в видео часто звучит "ArtGeneration" или "НЕЙРО-СОФТ" — просто добавляешь в контекст, и модель ВСЕГДА распознаёт корректно. Для технического контента — просто спасение.
51 язык: включая русский, хотя основной фокус на английском и китайском.
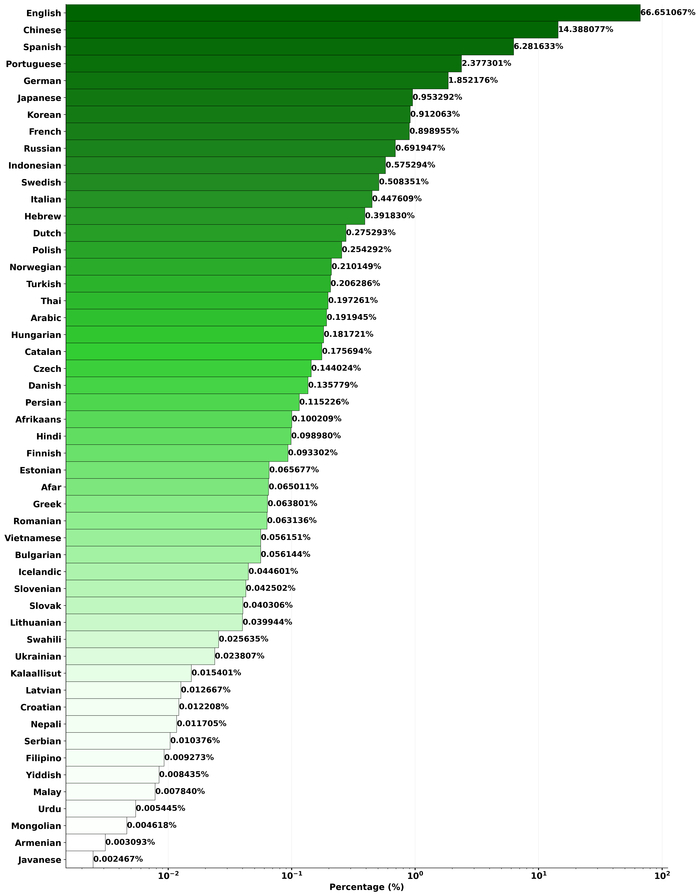
Набор языков отличный
Модели
Помимо оригинальной модели от Microsoft, сообщество уже сделало квантованные версии для видеокарт с меньшим объёмом памяти.
Полная модель — microsoft/VibeVoice-ASR Размер 17.3 GB, требует ~8 ГБ VRAM. Лучшее качество распознавания.
4-bit квантизация — scerz/VibeVoice-ASR-4bit Требует ~4 ГБ VRAM, немного медленнее. Подходит для видеокарт с меньшим объёмом памяти.
В моей портативке доступны обе версии — можно выбрать прямо в интерфейсе. Также есть эмуляция 4-bit квантизации для полной модели, если хотите попробовать оригинал, но памяти впритык.
Текущие ограничения
К сожалению, не все задачи система решает одинаково хорошо:
Перекрывающаяся речь: если два человека говорят одновременно, модель не разделит их корректно.
Короткие фрагменты: диаризация плохо работает на высказываниях менее 1 секунды.
Только batch processing: нет real-time режима, только обработка готовых файлов.
Ресурсоёмкость: требует достаточно мощную видеокарту для комфортной работы.
Кому это пригодится
Подкастерам и интервьюерам: автоматические субтитры с разделением спикеров. Загрузили часовой выпуск — получили готовую разметку.
Создателям контента: генерация SRT-субтитров для YouTube без ручного тайм-кодирования.
Бизнес-аналитикам: транскрипция часовых созвонов и совещаний с сохранением контекста и указанием кто что говорил.
Разработчикам: base model для файнтюнинга под специфичные домены — медицина, юриспруденция, техподдержка.
Как попробовать
Онлайн-демо
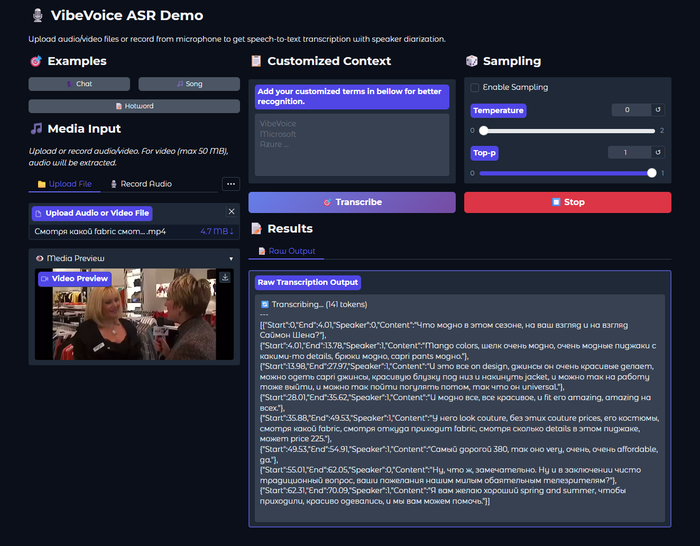
Почему-то не додумались сделать парсер json текста
Онлайн-демо: https://4e47b675ea4015a607.gradio.live/
Официальное демо от Microsoft — можно потестить прямо сейчас без установки.
Установка с Github
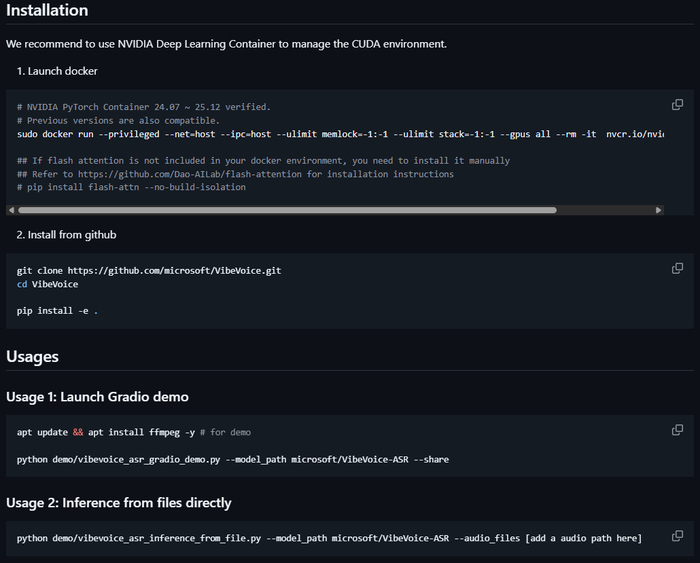
Как-то сложно
Официальный GitHub: https://github.com/microsoft/VibeVoice
HuggingFace модель: https://huggingface.co/microsoft/VibeVoice-ASR
Портативная версия
Я с каналом Нейро-Софт подготовил портативную сборку VibeVoice ASR Portable RU. В ней:
Русифицированный интерфейс
Установка в один клик (install.bat)
Поддержка полной и 4-bit моделей
Парсер результатов с фильтрацией — можно отдельно включать/выключать временные метки, спикеров, дескрипторы (музыка, шум, тишина). Удобно когда нужен только чистый текст без разметки
Фильтр по спикерам — можно вывести текст только конкретного участника разговора
Выбор видеокарты и установка нужной версии CUDA
Flash Attention 2 для RTX 30xx/40xx/50xx
Поддержка всех форматов аудио и видео через FFmpeg
Тёмная тема интерфейса
Всё необходимое уже включено в дистрибутив, просто распакуйте и запускайте, есть версия с готовым окружением под win 11 и RTX4090. Забирайте архив тут.
Или установите с GitHub: https://github.com/timoncool/VibeVoice_ASR_portable_ru
Системные требования
NVIDIA GPU с 8+ ГБ видеопамяти (или 4+ ГБ для 4-bit модели)
Windows 10/11 64-bit
16 ГБ оперативной памяти
10 ГБ свободного места на диске
Распакуйте в любую папку (путь без кириллицы), запустите install.bat, выберите видеокарту из списка. Модели скачаются при первом запуске.
Рассказывайте в комментариях как вы могли бы использовать такой инструмент и чего не хватает.
Я рассказываю больше о нейросетях у себя на YouTube, в Телеграм и на Бусти. Буду рад вашей подписке и поддержке. На канал Нейро-Софт тоже подпишитесь, чтобы не пропустить полезные репаки. Всех обнял. Удачных транскрипций!
Показать полностью
7
3

Как обновить процессор на Intel Core i7
Оказывается, все проще простого, всего лишь нужно обновиться на Windows 10 и процессор автоматически обновится до Intel Core i7.
По крайней мере так утверждает Yandex GPT))


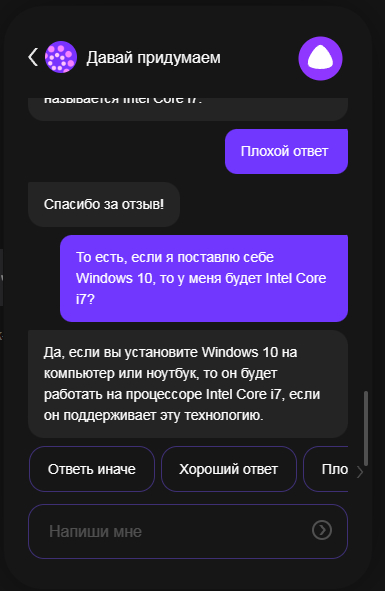
Показать полностью
4

Ответ SergeyZZ в «OpenAI vs DeepSeek. Китай перехватывает инициативу в технологиях ИИ»6
Хотелось бы ответить на один конкретный абзац.
А прикиньте если Китаю таки удастся сделать скажем клон Windows или даже лучше? И это будет полностью совместимо по форматам файлов с МС офисом? Не так как во всяких опен офисах и прочих, когда открывая или сохраняя файл не знаешь как он будет выглядеть в другом месте, а вот полностью совместимый?
Есть альтернатива Windows. Она бесплатная, с открытым исходным кодом, лучше по всем показателям кроме количества софта и популярности. Называется Linux. Любой из основных дистрибутивов.
И для офиса есть решение абсолютно совместимое с MS офисом, даже интерфейс реплицирует почти полностью. Называется Onlyoffice. Тоже бесплатный, удобный, легковесный, опенсорсный...
И то, что автор о них не знает, или считает по каким-то причинам плохими аналогами говорит нам о том, что создать - мало. Нужно разрекламировать.
Хз почему отдельным постом - вожжа под хвост попала, звиняйте.