Февраль 12. Погода начинает становится теплее. По ночам еще -5 но днем прогревается до +16. Последние заморозки у меня где то в первой неделе Июня. Но рядом в десяти киллометах есть город, там уже можно будет сажать через месяц. Там где то +5 ночью и за +20 днем. Поскольку многие растеня я выращиваю на продажу, было принято решения начать с посадки семян перцев. Все семена сажаются в стопроцентный компост из конского навоза.
В индивидуальные стаканчики примерно по 10 семян в каждый. В некоторые больше. Зависит от продаж в прошлом году.
Сегодня посадил 60 сортов. Осталось чуть более 100. Сразу под лампу, она дает тепло ну и всходы сразу будут получать питание.
Три стакана с листьями это не марихуана, а кросс вишни и сливы. Марихуану буду сажать позже.
Президент коммуникационного холдинга «Минченко консалтинг» Евгений Минченко на расширенном заседании «Экспертного совета Комитета Государственной Думы по науке и высшему образованию» в рамках Международного конгресса государственного управления провёл параллель между современной практикой управления и символами из книги про Гарри Поттера
Он назвал вице-премьера Правительства РФ, руководителя аппарата Правительства РФ Дмитрия Григоренко «Чистым пуффендуем», а обладателя звания «Губернатор-эколог 2025» Сергея Семеновича Собянина - «Гриффиндором»
Для справки:
Пуффендуй (Hufflepuff) — один из четырех факультетов школы Хогвартс, основанный Пенелопой Пуффендуй (Хельга Хаффлпафф). Факультет ценит трудолюбие, честность, лояльность и терпение, а его талисманом является барсук. Цвета — канареечно-желтый и черный, стихия — земля. Гостиная находится в подвале рядом с кухней, она уютная и теплая, с доступом через коридор.
Гриффиндор (англ. Gryffindor) - один из четырех факультетов ХД, также известный как Дом Огня или обитель сэра Шуша - звезды местного масштаба. Отличительное качество учеников этого факультета: храбрость, благородство, честность.
Зампред правительства выступил на пленарной сессии «Госуправление XXI века: между скоростью и смыслом», которая состоялась в рамках Международного конгресса государственного управления.
«Сегодня система госуправления адаптируется под привычки зумеров, под новые цифровые реалии. Отдельное направление развития — обучение государственных служащих работе с инструментами искусственного интеллекта», — сказал Григоренко.
По словам вице-премьера, искусственный интеллект на площадке аппарата кабмина сегодня применяется для подготовки протоколов и кратких справочных материалов, а также для проверки орфографии.
Он отметил, что изменения коснулись не только процедуры, но и организации работы госслужащих. В частности, в аппарате правительства работает система цифровых поручений, которая создаёт маршрут движения для документов и загружает сведения о сроках и исполнителях задач в аналитическую панель управления.
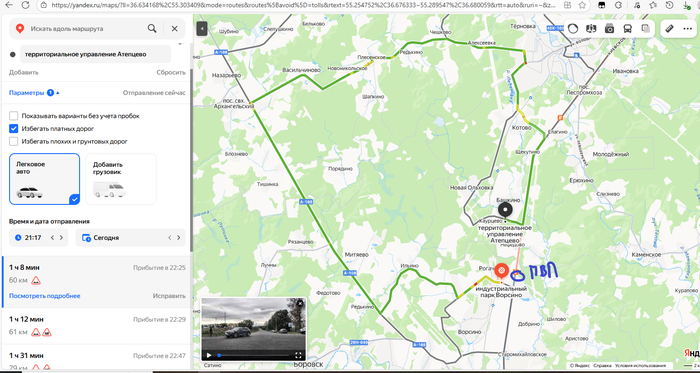
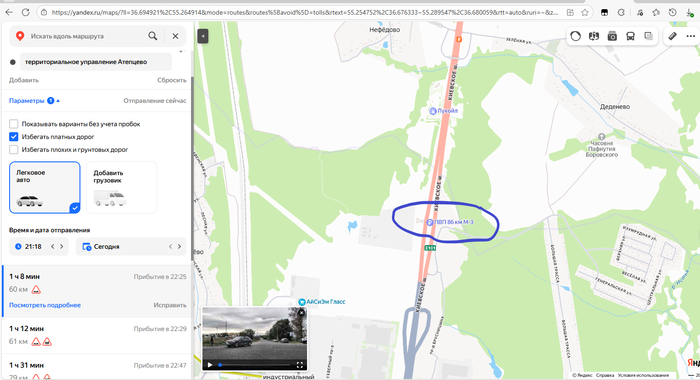
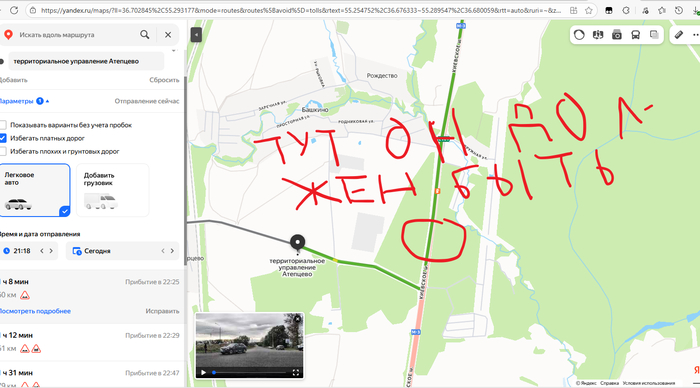
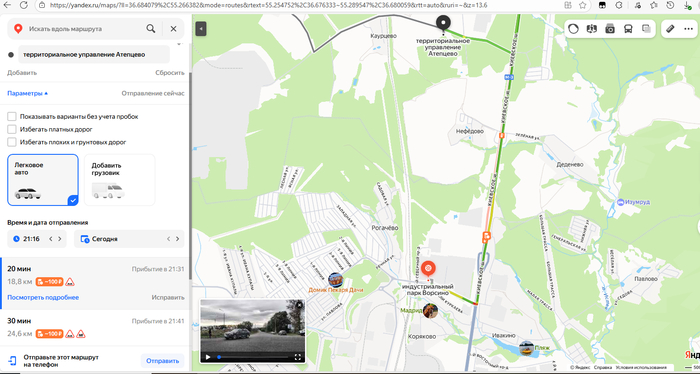
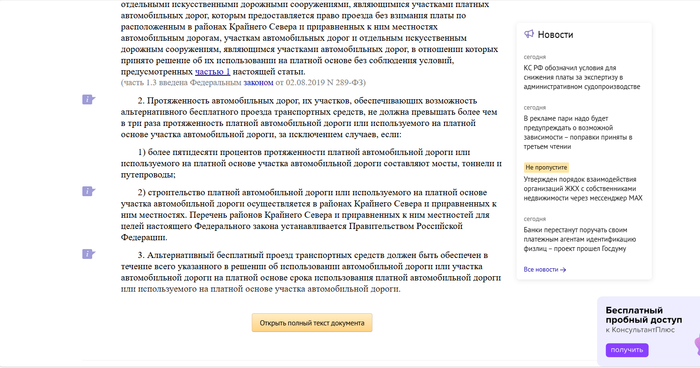
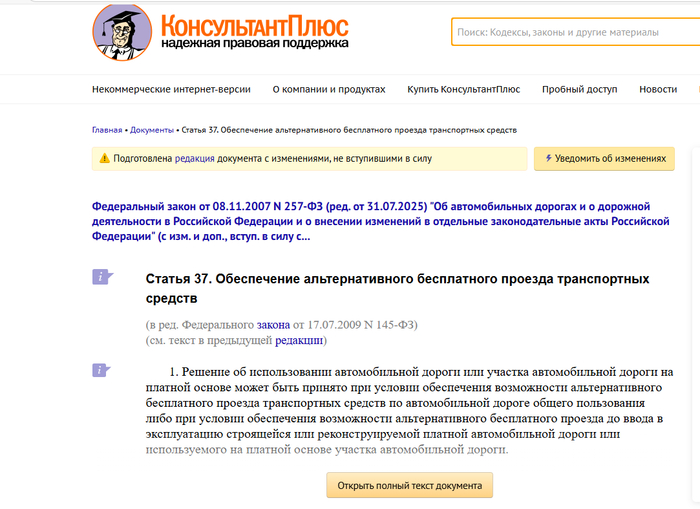
На основание чего ГК Автодор поставил в безальтернативном месте на М-3 пункт оплаты? По закону, альтернативный бесплатный маршрут не должен быть длиннее более чем в 3 раза, даже участок платного пути. Дальше по М-3 на юг перед ПВП была альтернатива по соседней дороге, на М-1 делают хотя бы двухстороннюю бесплатную дорогу кишкой делают, на М-4 по крайней мере пункты оплаты сделаны так, что можно объехать? Нигде в законе не написано откуда считать альтернативный бесплатный маршрут. ГК решила положить болт на федеральный закон, или какая-то тут лазейка? Ту же платную эстакаду на ЦКАД в Голицыно объяснили, что маршрут из любой точки бетонки менее чем в 3 раза длиннее, да и на севере ЦКАД даже не набегает пробег по старой бетонке в 3 раза.
Февраль, давно не было столько снег, да и мороз стоит нешуточный, ночью было -26. К выходным решил затопить баньку, а в голове все мысль крутилась, что при таком холоде минимум полдня будет разогреваться, потом все кайфанут, напарятся, а хозяин, как обычно, чисть печку, сливай воду, убирайся , да как-то не очень то и хочется. Вот летом другое дело, ничего сливать не надо, а тут , скажу прямо, один гемморой, а ну его нафиг, а попариться надо, прогреться, подышать травами, чайку попить, снежком растереться- мило дело. Товарищ сделал неожиданное предложение- поехать в городскую баню. Ну поначалу, как-то мне не очень это предложение понравилось, тем более баня,что недалеко от нас, с парилкой на электрических тенах, и русской баней такую систему назвать нельзя, но тут в голову пришла интересная идея, а что если посетить городскую баню, дровяную, помнится, в студенческие годы мы с ребятами с общаги делали вылазки, и нам эта тема очень нравилась, заодно было интересно посмотреть, а что изменилось с тех пор, ведь прошло почти тридцать лет.
Решение принято, и в пятницу в районе 09.00 мы сели в машину , предварительно подготовив сумки с банными принадлежностями , и направились в городскую баню. Несколько слов скажу о самой бане. Строение помнит времена Саввы Морозова, и , скорее всего, изначально предназначалось именно для бани , судя по размещению залов и самой парилки, точно не барак. Думаю, что основными посетителями были работники местной ткацкой мануфактуры, потому что в самом Орехово-Зуево есть Морозовская баня, которая заслуживает отдельного рассказа, а эта , Ликинская, поменьше, но , на мой взгляд , по качеству пара ничем не уступает. И так, мы приехали , и в моей голове невольно сразу стали всплывать картинки тридцатилетней давности и пошло сравнение. Во-первых, внешний вид здания особо не изменился, даже стал лучше, видно что подмарафетили и крылечко приличное сделали. Заходим и нас встречает интересная табличка ноу-хау, которой, кстати раньше не было « Осторожно, голые люди». В чем смысл этого предупреждения, я , признаюсь, не понимаю, возможно она важна для иностранных гостей ( им лучше сюда не заходить, плохо дело закончится), потому что в Европе и Америке люди в саунах голыми не ходят, но мы в России, и у нас свои правила, на что имеем полное право. Раздевалка та же, все чисто , убрано и лавки шикарные стоят, приятно. Персонал встречает вежливо, все объясняет, персонал- это пожилые женщины, и если мне память не изменяет. одну из них я видел ещё тогда, в студенческие годы.Поднимаемся по леснице на второй этаж где раздевалки, залы для отдыха, помывочная и самое главное- парилка. Стены по лестнице те, старые, краска вздутая, видимо, не успели, видимо, доделать, а вот дальше- это приятное открытие: чистый пол и стены с новым кафелем, пластиковые окна , новые столы и лавки, большая плазма в комнате отдыха, новые шкафы в раздевалке, помывочная вся в новой плитке, краны не текут, душ работает шикарно, а парилка- это браво, все перебрано и пахнет новым деревом. Лично от меня и моего товарища огромное спасибо за сделанную работу по ремонту и обновлению, были приятно удивлены. А теперь перейдём к процессу, который лично меня заставил вспомнить те старые и добрые времена.
Первый раз идём греться, кто-то из парильщиков принёс с собой веники полыни- запах бесподобный, пар мягкий, не обжигает, хотя мужики активно подкидывают, но, скажу , дышать приятно, нетяжело, в удовольствие. Прогрелись, запарили в тазике свой дубовый веник и идем на лавку отдыхать, и тут та самая женщина ( точно она) заходит с тряпкой в раздевалку , где голые люди, точно как тридцать лет назад, а для меня это значит,что живы традиции и слава Богу, а вот и мужики картишки раскидывают , но плюс в том, что никто не бухает, у всех чай, вода, минералка. Лавка и столы в комнате отдыха- это отдельное мерси, очень удобно и практично, чувствуется ,что к делу реновации подошли люди с умом и вкусом, Вкус подчерчивают различные деревянные таблички нигде ничего подобного в других странах я не видел. Идём второй раз с веником - ох ка парок заходит, но не обжигает, а именно пробирает, аж до костей, то, что надо. Мужики еще чаще подкидывают, начинают немного заливать, но не критично- хвала печи, достойная. Душ- воды хоть улейся, и все рядом, вот тебе и лавочка и зеркало. Мне приятно это, потому что в доме нет канализации , и мы воду сильно не льем, а тут- отвал башки, приятно. Третий заход, товарищ начинает сдавать, пар пробрал, не газуем, делаем большую паузу и пьём много чая. Вот оно, настоящее удовольствие, дышит каждая клетка тела, настроение отличное, хочется жить, созидать, это и есть эффект настоящей русской бани, который усиливается, когда выходишь на улицу и начинаешь осторожно вдыхать морозный воздух- красота непередаваемая.
В завершение скажу, что хочется ещё не раз посетить эту замечательную городскую баню, а такое желание возникает только тогда, когда место достойное, притягивает, есть тот самый колорит, который не утерян с годами, а наоборот стал ярче, притягательнее, глубже. Друзья, всем советую посетить, забейте на пятничные посиделки и дайте глоток тёплого , ароматного воздуха вашему здоровью. Всех с лёгким паром!
Сегодня в 11:52 мск с Байконура стартовала ракета-носитель тяжелого класса «Протон-М» с разгонным блоком ДМ-03 и метеоспутником «Электро-Л» № 5.
Примерно через 10 минут после старта разгонный блок с аппаратом отделились от третьей ступени «Протона-М».
▶️ Выведение спутника «Электро-Л» №5 на геостационарную орбиту на высоту более 35 тысяч километров заняло 6 часов 37 минут.
За это время ДМ-03 производства РКК «Энергия» выполнил три включения двигательной установки.
Ракета-носитель «Протон-М» (производства Центра Хруничева) и разгонный блок ДМ-03 оснащены системами управления, созданными в Научно-производственном центре автоматики и приборостроения имени академика Пилюгина.
Озеро Лабынкыр расположено глубоко в сердце Восточной Сибири, в труднодоступном районе Оймяконского улуса Республики Саха (Якутия). Оно знаменито своей суровой природой, экстремально низкими температурами зимой и… слухами о странном существе, живущем в его водах.
Местные жители называют его «лабынкырским чёртом». Это легендарное создание впервые стало известно широкой общественности благодаря рассказам охотников и рыболовов, утверждающих, что видели в озере огромного, тёмного силуэта размером примерно 8-10 метров, иногда показывающего спину над поверхностью воды.
Версии происхождения:
Многие полагают, что это какая-то крупная рыба, возможно неизвестный науке реликтовый вид осётра или огромный сом. Другие утверждают, что это заблудившийся морж, каким-то образом оказавшийся далеко от привычной среды обитания.
Научные исследования пока не подтвердили существование какого-либо животного столь внушительных размеров в Лабынкыре. Однако редкие свидетельства продолжают подогревать интерес к этому месту.
Экспедиции и попытки поймать чудище: За десятилетия десятки экспедиций пытались обнаружить следы легендарного существа. Среди них была экспедиция под руководством профессора Московского университета Игоря Грибова, предпринятая в конце прошлого века. Исследователи использовали гидролокаторы и подводные камеры, однако подтвердить существование монстра не смогли.
Почему эта история интересна именно вам?
Во-первых, потому что это одна из тех редких историй, в которой природа преподносит человечеству настоящую загадку. Мы любим тайны и хотим верить, что где-то там всё-таки живут драконы или йети наших фантазий.
Во-вторых, это повод задуматься о богатстве нашего мира и о том, насколько мы действительно знаем свою собственную природу. Возможно, в удалённых уголках планеты до сих пор существуют удивительные виды животных, которым предстоит стать открытием науки.
Если вас заинтересовала эта история, подписывайтесь на обновления, ведь впереди ждут новые приключения и открытия!
Поделитесь своими мыслями в комментариях ниже: Вы верите в существование лабынкырского чёрта? Или считаете, что это всего лишь городская легенда?
Нейросеть для распознавание текста: Как быстро извлечь текст с картинки через нейросеть и получить готовый документ или конспект
Сфотографировали документ на бегу, получили «кашу» из букв, а текст нужен прямо сейчас — для договора, учебы, отчета или поста? Современные OCR-модели и ИИ-инструменты умеют распознать текст с картинки так, чтобы его можно было копировать, редактировать и сразу использовать в работе. Главное — выбрать правильный подход и не наступить на типовые грабли: качество фото, язык, шрифты, рукопись, PDF-сканы, «тени» и перспектива.
Что вы узнаете
Как работает OCR и почему «нейросеть» часто точнее классических распознавателей.
Чем отличается распознать печатный текст от попытки распознать рукописный текст.
Как распознать текст онлайн без установки программ и не потерять форматирование.
Что делать, если нужно распознать текст из pdf или со скана в плохом качестве.
Как превратить результат в готовый материал: конспект, описание, письмо или даже создать поздравление нейросетью.
Как быстро получить текст по фото онлайн и встроить это в процессы на сайте Ranvik.
Нейросеть для распознавание текста: Как быстро извлечь текст с картинки через нейросеть и получить готовый документ или конспект
Что такое распознавание текста по фото и зачем оно бизнесу
Распознавание текста по фото (OCR, Optical Character Recognition) — это технология, которая преобразует изображение с буквами в редактируемый текст. Проще: вы загружаете фото/скан/картинку, а сервис возвращает «живые» символы, которые можно копировать, править, искать по ним и вставлять в документы.
Для бизнеса и коммерческих сайтов это не «фича ради фичи». Это экономия времени и денег:
Быстрее обработка документов (счета, накладные, заявления).
Ускорение контент-процессов (перенос текста с презентаций, вывесок, упаковок).
Автоматизация поддержки (клиенты шлют фото, вы получаете текст и отвечаете быстрее).
Улучшение качества данных (поиск, сортировка, аналитика).
Мини-вывод: OCR — это мост между «картинкой» и рабочими данными.
Какие задачи закрывает интент «распознать текст по фото онлайн»
Когда человек вводит запрос вроде «распознать текст по фото онлайн», он обычно хочет одно из четырех:
Скопировать текст без ручного набора (быстро и без ошибок).
Восстановить документ: фото/скан → редактируемый текст → Word/Google Docs.
Разобрать сложный источник: рукопись, чек, таблица на фото, PDF-скан.
Сделать дальше действие: конспект, перевод, письмо, описания товаров, пост, шаблон ответа.
Поэтому в хорошей коммерческой статье важно:
показать варианты (фото, JPG, PDF, скан),
объяснить, как добиться точности,
дать понятную инструкцию,
подсказать, как использовать результат на Ranvik в реальном сценарии.
Подходы и варианты: чем распознают текст сегодня
Классический OCR и нейросетевой OCR — в чем разница
Классический OCR опирается на шаблоны символов и правила сегментации строки/буквы. Он неплох для ровных сканов, печатного текста и стандартных шрифтов.
Нейросетевой OCR использует модели, которые «понимают» контекст:
лучше справляются с наклоном, шумом, перспективой;
Мини-вывод: если источник «идеальный» — справится почти любой OCR; если источник «жизненный» (фото с телефона) — нейросетевой подход выигрывает.
Что именно вы распознаете: от этого зависит результат
Печатный текст
Если цель — распознать печатный текст, ориентируйтесь на:
четкость, контраст, отсутствие бликов;
корректный язык (русский/английский);
ровную плоскость (без «дуги» страницы).
Рукопись
Когда нужно распознать рукописный текст, критично:
насколько разборчив почерк;
есть ли клетка/линейка;
нет ли смазанных штрихов, теней от руки.
Рукопись — самый «капризный» режим. Тут важно не только чем распознаете, но и как фотографируете.
Фото текста vs скан
Чтобы распознать текст со скана, обычно проще: скан ровный, без перспективы. Фото — сложнее: наклон, свет, «бочка» объектива, шум.
Изображение, JPG, скриншот
Запросы вроде распознать текст из jpg и «текст по картинке по фото» чаще всего означают обычную картинку. Здесь важно, чтобы:
не было сжатия до «мыла»;
размер шрифта был не микро;
фон не «пестрил».
PDF: отдельная история
Многие думают, что распознать текст из pdf — это всегда просто. Но PDF бывает двух типов:
Текстовый PDF: там уже есть символы, OCR не нужен — можно копировать.
Скан-PDF: внутри картинки страниц. Тогда нужен OCR, и запрос «пдф распознать текст онлайн» становится актуальным.
Если PDF — скан, подход такой же, как со сканом, только по страницам.
Как выбрать решение: онлайн-сервис или программа
Когда лучше распознать текст онлайн
Онлайн-формат удобен, если:
нужно быстро «здесь и сейчас»;
нет желания устанавливать софт;
важны обновления моделей;
вы работаете на разных устройствах.
Если вы хотите сделать это в один шаг, попробуйте на Ranvik: распознать текст по фото онлайн — загрузили изображение и получили текст, который дальше можно редактировать или использовать в задачах.
Когда выгоднее распознать текст программа
Формат «распознать текст программа» обычно выбирают, если:
большой поток файлов и нужен пакетный режим;
есть требования по хранению данных локально;
нужна интеграция с внутренними системами без облаков.
Но у локальных решений часто сложнее старт, а качество зависит от обновлений движка. В реальности многие команды комбинируют: срочные задачи — онлайн, массовые — автоматизация.
Мини-вывод: выбирайте по сценарию, а не по привычке.
Пошаговая инструкция: как распознать текст с изображения и получить чистый результат
Ниже универсальный алгоритм, который работает и для «текст по фото на русском», и для сканов, и для PDF-страниц.
Шаг 1. Определите тип источника
Фото с телефона, скан, скриншот, PDF (текстовый или скан). От этого зависят ожидания по точности.
Шаг 2. Проверьте читаемость глазами
Если вы сами с трудом читаете буквы, сервису будет не легче. При необходимости переснимите.
Шаг 3. Снимайте правильно
держите камеру параллельно листу;
включите хороший свет без бликов;
избегайте теней от рук;
не используйте цифровой зум.
Шаг 4. Уберите «перспективу» и шум
Любая авто-коррекция в телефоне или простая обрезка по краям часто увеличивает точность OCR в разы.
Шаг 5. Выберите язык распознавания
Русский, английский, смешанный. Для «текст по фото письменный» иногда полезно указать язык явно, чтобы модель не путала похожие символы.
Шаг 6. Загрузите файл в сервис
Например, на Ranvik можно получить результат без лишних действий: распознать текст с картинки — загружаете фото/картинку и забираете готовый текст.
Шаг 7. Проверьте «тонкие места»
Обычно ошибки сидят в:
«0/О», «1/І/л», «5/Ѕ»;
дефисах и переносах;
адресах, реквизитах, артикулах;
редких фамилиях/терминах.
Шаг 8. Быстро приведите текст к виду «для работы»
Сделайте базовую чистку:
уберите лишние пробелы;
склейте строки, если они «порвались»;
проверьте кавычки и тире.
Шаг 9. Сохраните в нужном формате
Кому-то нужен «просто текст», кому-то — вставка в Word, кому-то — заметка в CRM.
Шаг 10. Используйте результат по назначению
Например:
«конспект текста по фото» — сжать в тезисы;
«текст описания по фото» — превратить в карточку товара;
«расшифровка текста по фото онлайн» — подготовить к отправке клиенту.
Если ваша команда каждый день делает «слова по фото в текст», имеет смысл закрепить единый регламент (см. чек-лист ниже).
Мини-вывод: точность OCR чаще растет не от «магии сервиса», а от правильной подготовки источника.
Как использовать распознанный текст на сайте Ranvik: практические сценарии
Сценарий 1. Клиент прислал фото — вы отвечаете быстрее
Поддержка получает фото заявления/таблички/этикетки. Вместо ручного набора вы делаете распознавание текста по фото онлайн, вставляете в шаблон ответа и закрываете обращение быстрее.
Сценарий 2. Контент-менеджер переносит текст с упаковки/баннера
Нужно «прочитать текст по фото» и сделать описание товара. Распознали → поправили → оформили карточку.
Сценарий 3. Маркетинг превращает фото-материалы в тексты для сайта
Тексты с презентаций, стендов, флаеров — распознали, отредактировали и получили основу для лендинга.
Сценарий 4. Документы: скан → текст → согласование
Когда важно распознать текст со скана или извлечь из скан-PDF, вы ускоряете согласование: текст становится searchable и редактируемым.
Сценарий 5. «Не просто OCR»: сделать готовый контент
Получили текст и дальше подключили ИИ-помощь: сделать краткий пересказ, подготовить письмо, сформировать тезисы или даже создать поздравление нейросетью на основе исходного текста (например, с открытки/приглашения).
Чтобы быстро получить базу, можно начать с Ranvik: ocr распознать текст — и уже дальше работать с результатом.
Основные ошибки и заблуждения
«Любое фото распознается идеально» Нет. Перспектива, блики и шум убивают точность сильнее, чем «плохой сервис».
«Если PDF, значит текст уже есть» Скан-PDF — это картинки. Для него и нужен сценарий «распознать текст из pdf».
«Рукопись распознается так же, как печатный текст» Рукопись требует качества: резкость, контраст, понятные буквы. «Рукописный текст по фото» может дать отличный результат, но не в условиях «сфоткал в метро».
«Язык не важен — ИИ сам догадается» Смешанные языки и транслит без указания языка часто дают мусор: «А» превращается в «A», «Р» в «P» и т.д.
«Сжатие картинки не влияет» Влияет. Мессенджеры режут качество, и «расшифровать текст по фото» становится сложнее.
«Достаточно один раз распознать — и готово» Для документов всегда нужен контроль: суммы, реквизиты, даты.
«Форматирование восстановится само» OCR возвращает текст, но структуру иногда нужно привести вручную: списки, переносы, абзацы.
«Если не распознало — значит сервис плохой» Часто достаточно переснять под другим углом/светом или обрезать лишний фон.
Мини-вывод: 80% проблем решаются качественным исходником и правильным режимом распознавания.
Чек-лист: быстрый контроль перед загрузкой
Текст в кадре занимает большую часть изображения, без лишнего фона
Нет бликов, теней и «желтизны» от ламп
Камера параллельно листу, нет сильной перспективы
Резкость на буквах, не на столе/руке
Выбран правильный язык (русский/английский/смешанный)
Для PDF понятно: это скан или текстовый файл
Важные места (цифры, даты, адреса) читаемы
После распознавания планируется быстрая вычитка
Сценарии «если… то…»
Если текст на фото мелкий, то подойдите ближе и снимайте без зума, лучше в хорошем свете.
Если нужно распознать текст с изображения с сильным наклоном, то сначала обрежьте и выровняйте перспективу (даже встроенными средствами телефона).
Если задача — распознать рукописный текст онлайн, то сделайте контраст выше и исключите фон (клетку/стол), чтобы модель видела только символы.
Если вы хотите распознать текст на странице в PDF-скане, то работайте постранично и проверяйте результат по ключевым строкам (ФИО, суммы, даты).
Если итог нужен как «написать текст по фото» для публикации, то после OCR прогоните текст через редактуру: заголовки, абзацы, смысловые блоки.
Если распознание постоянно ошибается в одинаковых местах, то заведите мини-словарь (названия, артикулы) и проверяйте их отдельно при вычитке.
Практика: как повысить точность, когда нужно «определить текст по фото» в сложных условиях
Когда фото темное или с шумом
включите свет и переснимите;
избегайте вспышки «в лоб» (дает блики);
лучше дневной рассеянный свет.
Когда лист «волной»
Книга или помятый лист дают искажения. Решение:
прижать страницу (без теней);
снять сверху;
сделать 2–3 дубля и выбрать лучший.
Когда нужно разобрать не только текст, но и смысл
OCR — это только первый этап. Дальше могут понадобиться:
«конспект по фото текста онлайн» (сжать в тезисы);
«составление текста по фото» (оформить как статью/письмо);
«сгенерировать текст по фото нейросеть» (переписать под стиль бренда).
Именно поэтому удобны решения, где распознавание и дальнейшая работа с текстом живут рядом.
Как не допустить переспама и сохранить «человеческий» текст после OCR
Если вы делаете контент для сайта, важно: распознать — не значит опубликовать. Машина часто «ломает» стилистику:
слишком много переносов;
случайные заглавные буквы;
«съехавшие» кавычки;
странные пробелы.
Схема «чистка → структура → смысл» дает быстрый результат:
чистим технический мусор,
выстраиваем абзацы и заголовки,
приводим к стилю бренда.
Мини-вывод: так «текст по фото» превращается в материал, который не стыдно показать клиенту.
Что делать, если нужно распознать текст из PDF или скана: короткий регламент
Проверьте, можно ли копировать текст из PDF. Если нет — это скан.
Разделяйте документ на страницы/развороты.
Для каждой страницы контролируйте «точки риска»: суммы, реквизиты, даты, фамилии.
Если задача частая, заведите шаблон проверки (2–3 минуты на документ).
Если нужен быстрый старт без установки, можно использовать Ranvik: распознать текст онлайн — и дальше сохранять результат в рабочем формате.
Выводы и рекомендации
Делайте ставку на качество исходника: свет, резкость, угол — это половина успеха.
Для сложных фото и рукописи чаще выигрывает нейросетевой OCR.
Всегда различайте текстовый PDF и скан-PDF: подход разный.
Проверяйте «тонкие места»: цифры, даты, имена, артикулы — там больше всего ошибок.
Используйте единый чек-лист для команды, чтобы результат был стабильным.
Не публикуйте OCR «как есть»: 5 минут редактурной чистки резко повышают качество.
Выбирайте инструмент под задачу: разовые задачи — онлайн, поток — автоматизация.
Встраивайте распознавание в процессы: поддержка, контент, документы, маркетинг.
FAQ
1) «Как распознать текст по фото онлайн без регистрации?»
Чаще всего это решается выбором сервиса, который позволяет загрузить изображение и сразу получить результат. Важно подготовить фото: обрезать лишнее, выровнять страницу, убедиться в резкости. После распознавания сделайте быструю вычитку: OCR чаще ошибается в цифрах и коротких аббревиатурах.
2) «Как распознать рукописный текст по фото, если почерк неидеальный?»
Для рукописи ключевое — контраст и чистый кадр. Снимайте при хорошем свете, без теней, лучше на однотонном фоне. Если есть возможность — переснимите ближе и ровнее. После распознавания применяйте здравый смысл: рукопись почти всегда требует ручной проверки спорных слов.
3) «Как распознать текст из PDF, если он не копируется?»
Если не копируется — это, вероятнее всего, скан-PDF. Тогда нужен OCR по страницам. Проверьте каждую страницу на читаемость, уберите перекос, контролируйте «точки риска» (суммы, реквизиты, даты). При больших документах полезно разбивать на блоки и проверять выборочно по ключевым строкам.
4) «Почему OCR путает русские и английские буквы и как это исправить?»
Потому что многие символы визуально похожи: A/А, P/Р, C/С, O/О. Решение: задавайте правильный язык распознавания, следите за качеством изображения и обязательно вычитывайте слова, где критична точность (названия компаний, почта, ссылки, артикулы).
5) «Как из результата OCR быстро сделать готовый текст: конспект, описание или поздравление?»
Сначала получите чистый текст (уберите переносы, лишние пробелы). Затем определите цель:
для конспекта — выделите тезисы и структуру;
для описания — добавьте выгоды, характеристики, призыв к действию;
если нужно написать текст по фото нейросеть используйте распознанный текст как основу и попросите ИИ переформулировать под нужный стиль (официально, дружелюбно, кратко, в формате открытки).