Где данные: RAG системы - как сделать болтливую нейросеть немного умнее

Пока одни нейросети продолжают рассказывать уверенные небылицы, другие учатся хотя бы проверять в интернете, что несут. Сегодня разберёмся, что такое RAG, зачем он нужен и почему GPT без него — фантазер без данных
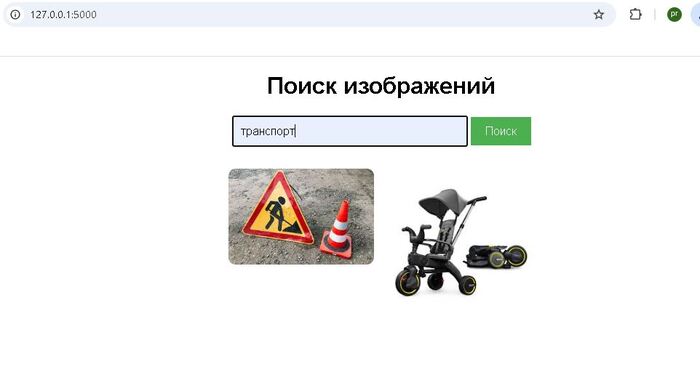
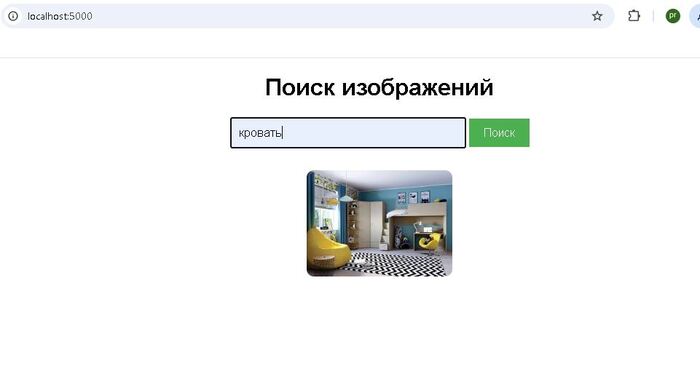
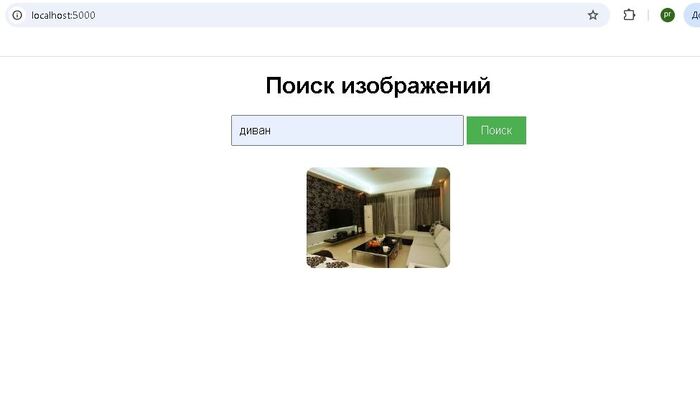
В прошлых постах я рассказывал о создании локальной ИИ системы поиска по изображениям и локального AI ассистента. Я специализируюсь на дообучении и интеграции AI моделей в корпоративных задачах, и пишу здесь про все что связано с AI.
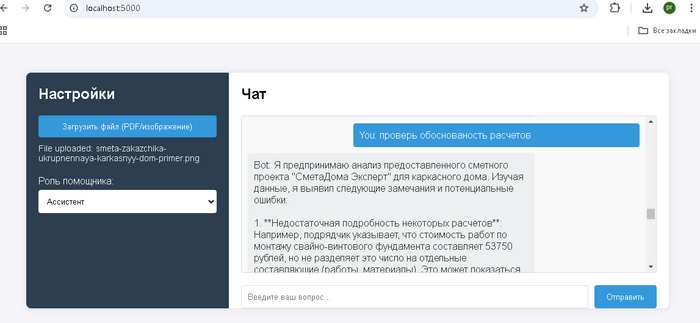
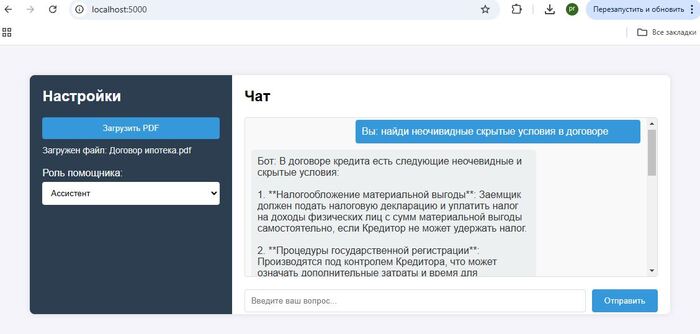
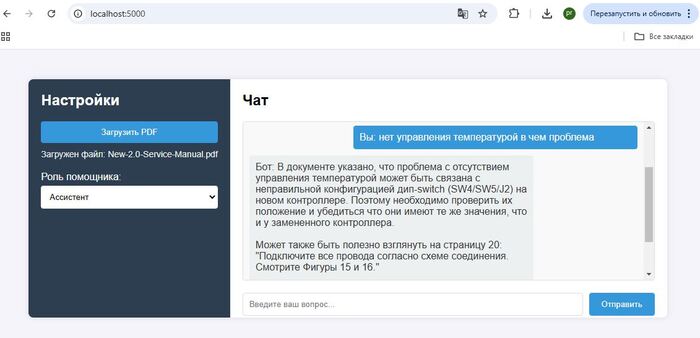
Многие встречались с такой ситуацией, когда нейросеть сначала начинает увлечено фантазировать, а когда ее ловят на несоответствиях переобувается в полете. Примерами таких галлюцинаций ИИ наверное может поделиться каждый, иногда не спасает ни режим размышления, ни поиск в сети. Когда выдача AI должна быть основана исключительно на проверенных данных используют RAG системы.
RAG это буквально - "Генерация, дополненная поиском". Именно такие системы позволяют AI дать пользователю ответ на вопрос, даже если у него нет достаточных данных для ответа, они подгрузятся благодаря RAG системе
Итак для чего нужны RAG системы
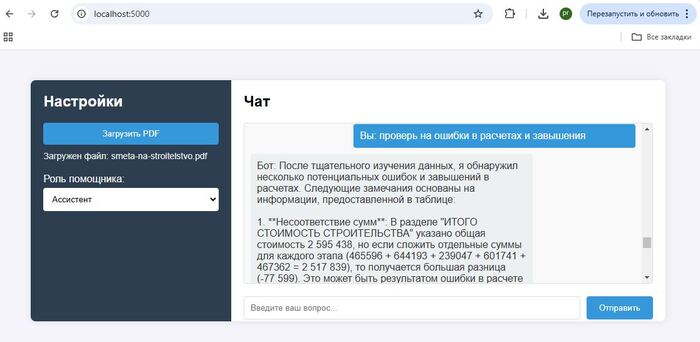
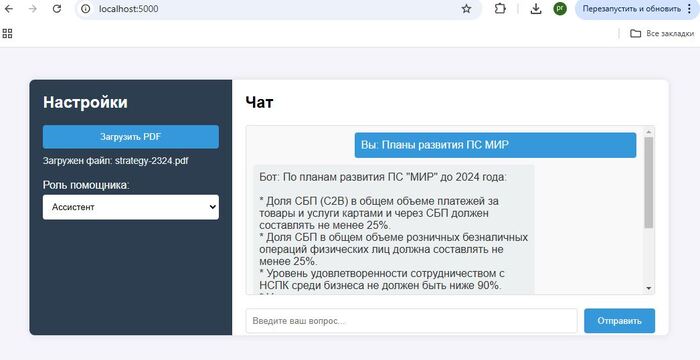
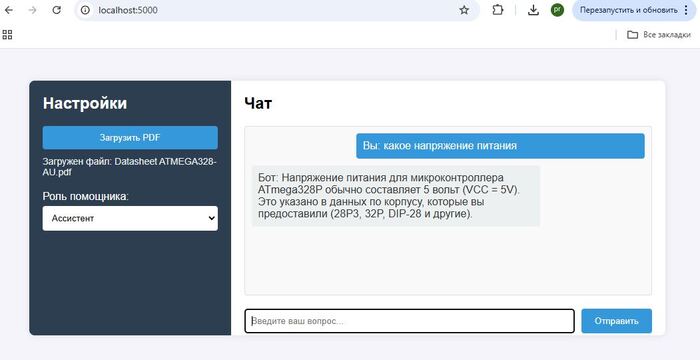
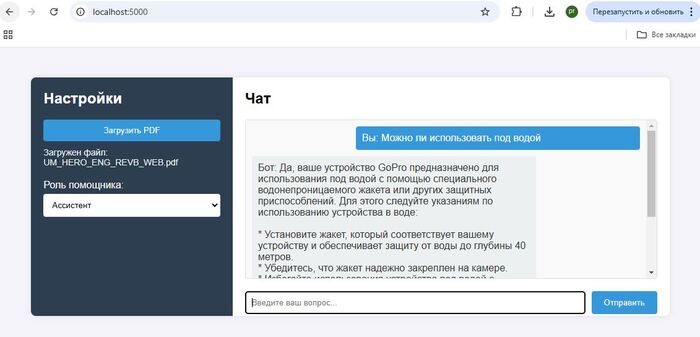
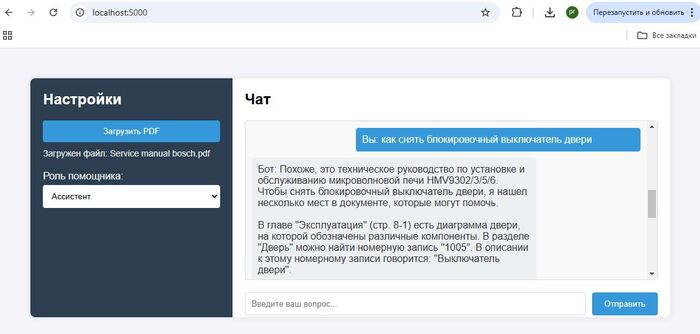
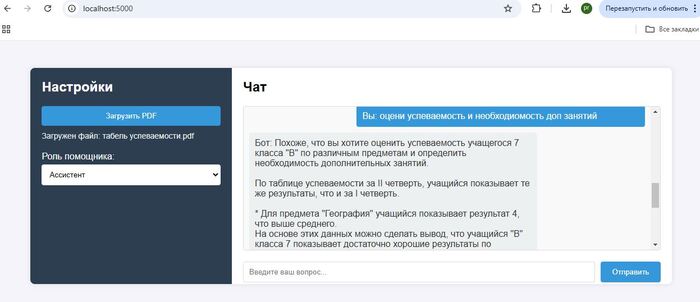
В первую очередь для того чтобы дополнить запрос к AI актуальными данными-контекстом, сначала ищем информацию в своей базе знаний, а после дополняем тем что нашли первоначальный запрос к AI. Как результат ChatGPT не фантазирует о средней температуре по больнице, а руководствуется исключительно вашими данными.
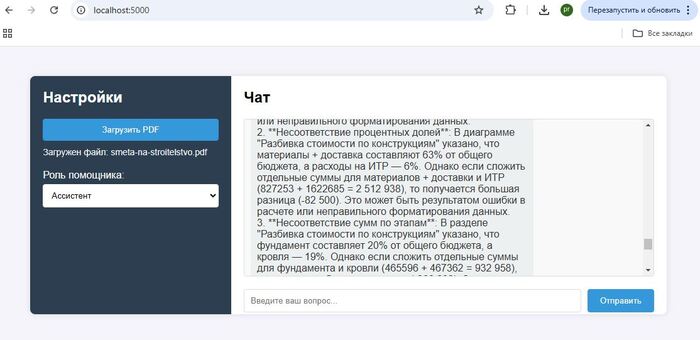
Представим пользователь решил уточнить у ChatGPT , какой смартфон купить, или куда съездить в отпуск, как итог вы получите массу полезной и не очень информации по интересующему вопросу, чему-то AI был обучен на этапе обучения, что то AI нашел в интернете. На этих обобщенных данных и будет построен ответ. А если нужна конкретика, основанная только на фактах, например наличии и ценах товаров, горячих путевках и т.д., то есть актуальных данных без которых не возможно дать полноценный ответ, здесь AI становится бесполезен, у него просто нет тех данных на базе которых вы хотите получить ответ.
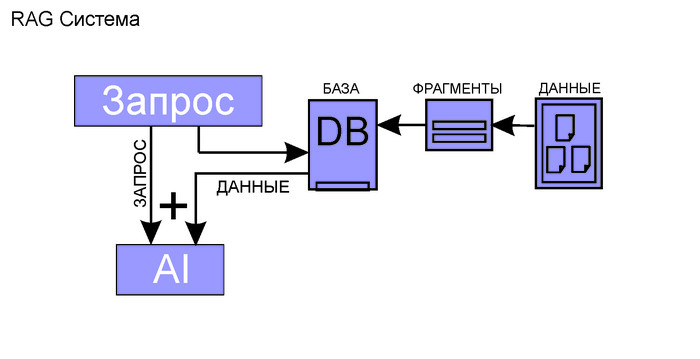
Кто-то может возразить что мешает загрузить все данные вместе с запросом и попросить все проанализировать, это возможно только в том случае если ваши данные уже обработаны и пригодны для передачи AI, и инициатор запроса может обладать этими данными, зачастую это не так.
Первое преимущество RAG - Приоритет данных
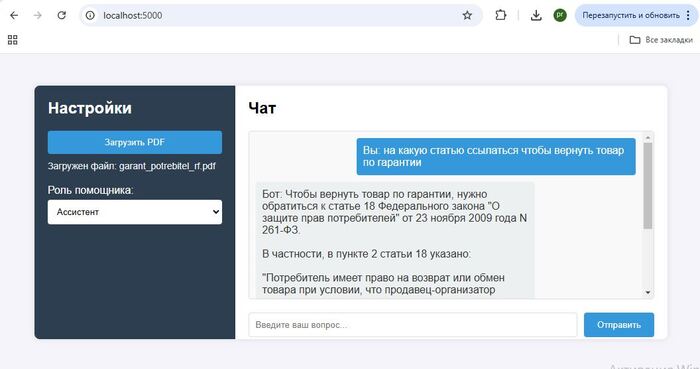
Вы и только вы определяете чем будет руководствоваться AI отвечая на запрос. Если вы укажете это в запросе модель не будет использовать свои знания при составлении ответа, даже если они говорят обратное. Такая генерация часто сопровождается оговоркой: "в рамках данного контекста", "согласно документам" — чтобы не вводить в заблуждение.
Если в качестве контекста Вы представите документ, что земля плоская, или о связи лунных циклов с подорожанием колбасы, AI модель примет эту точку как единственно верную и построит ответ руководствуясь ей. При желании и верном запросе AI даже попробует сгенерировать доказательства в обоснование этих данных

Гиперпараметры с детерминированными настройками запроса и в результате никаких незапланированных сценариев ответа и галлюцинаций ИИ, что часто бывает в условиях малых данных
Второе преимущество - Управление данными
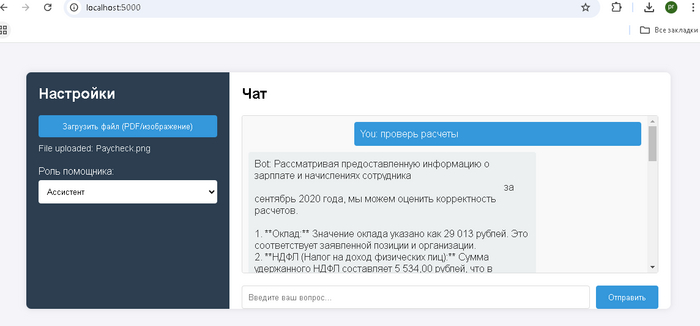
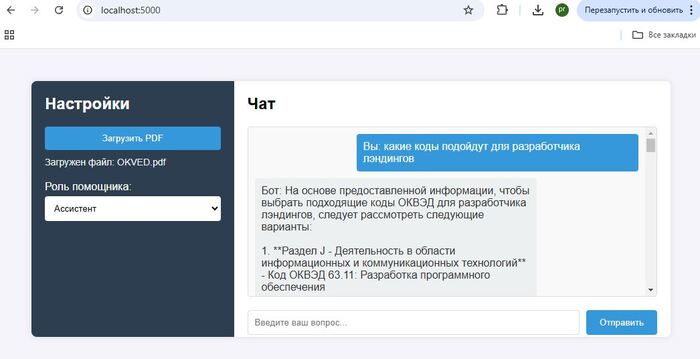
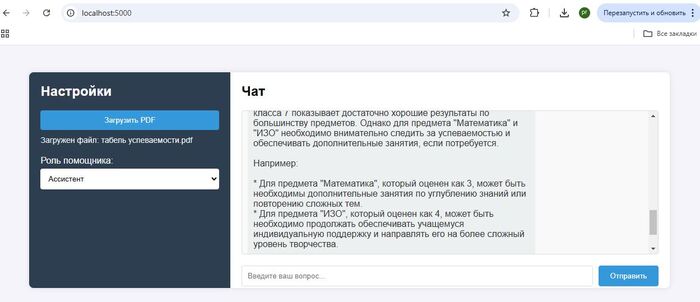
Данные только Ваши. Вам не нужно отдавать все данные AI, достаточно сформировать и извлечь в своей базе знаний только актуальные для этого запроса. К примеру в чатбот компании обратился клиент и задал вопрос по услугам, из CRM извлекаем его данные, из базы знаний информацию о условиях тарифа, передаем все это AI модели, на что получаем персонализированный ответ подготовленный для конкретного клиента.
Огромное количество документов с чувствительными данными, например в медицинской или финансовой сфере, вы храните у себя, предоставляя только те данные которые требуются для запроса. Сам процесс подготовки данных многих пугает, однако как показывает практика современный документооборот и делопроизводство завязанные на CRM позволяют выгружать необходимые выборки в пару кликов. А прикрутив данные из 1С или баз данных можно формировать запросы в реальном времени, дополняя актуальными данными базу знаний RAG
Третье преимущество - Цена вопроса
Цена обработки RAG контекста ниже. Пока стоимость запроса считают по количеству токенов RAG будет более выгоден, чем передача несортированных данных по концепции "большого контекстного окна", хотя AI уже предлагают хранение данных без повторной загрузки
Представим что ваш запрос требует использования исключительно большой советской энциклопедии как источника, вы конечно можете передать БСЭ как контекст но AI посчитает эти данные как входящие токены, и соответственно тарифицирует. RAG система извлечет из энциклопедии небольшие фрагменты, в которых упоминается данные по вашему запросу и передаст AI только их, это позволяет экономить буквально в сотни, а то и в тысячи раз, в зависимости от объёма контента. А современные Hybrid RAG архитектуры позволяют извлекать контекст извлечённый несколькими механиками поиска и заведомо превышающий необходимый для ответа объём, предлагая AI самостоятельно выбрать наиболее релевантные фрагменты
Недостатки:
Основной недостаток это необходимость разрабатывать и интегрировать RAG систему, а также готовить и периодически актуализировать данные для базы знаний, как правило данные периодически устаревают и я рекомендую заранее предусмотреть процесс обновления и актуализации данных. Сам алгоритм не сложный и если его не автоматизировали при запуске, выглядит как формирование документов для актуальной базы знаний и запуск процесса фрагментации и векторизации данных
Есть вопросы пишите мне в ТГ подробнее про RAG на Habr