PDF ассистент: Создаем локального ИИ помощника. Часть 1

Пост "Создаем локального ИИ помощника. Часть 1." продолжает цикл постов о решении повседневных задач с помощью локальных нейросетей. В прошлом посте я рассказывал о создании локальной ИИ системы поиска по изображениям
Зачастую чтобы найти нужную информацию в документе на несколько десятков страниц, необходимо потратить значительное время на ознакомление, если для текста есть поиск, то для более сложных задач требуются помощь нейросетей. Существует большое количество ИИ сервисов, которым можно "скормить" наши документы. К сожалению с учетом количества "сливов утечек" данных, загружать документы содержащих личные данные или конфиденциальные сведения плохая идея. Если использование в личных целях таких сервисов происходит на свой страх и риск, то применение в корпоративных целях зачастую недопустимо. Например вряд ли клиенты клиники будут рады если их медкарта окажется на серверах OpenAi.
Поскольку я специализируюсь на дообучении и интеграции локальных ИИ моделей в корпоративных задачах, решение этой задачи будет строится на применении исключительно локальных AI технологий. В основе проекта относительно недавно вышедшие на приемлемое качество хоть и урезанные по количеству параметров версии ИИ моделей, которые можно запустить даже на домашних ПК оснащенных видеокартами с объемом памяти от 6-8Гб. Для полноценных моделей по количеству параметров этого объема VRAM домашнего ПК конечно не достаточно, да и скорость работы домашних GPU не сравнится с коммерческими AI сервисами, но для обработки средних по объему документов вполне достаточно.
Итак цель очередного мини проекта выходного дня - создать ИИ ассистент работающего локально без доступа к сети интернет, которому можно "скормить" наш документ в формате PDF и на основе данных содержащихся в нем, отправить запрос нейросети. Получив в ответ информацию с учетом содержащейся в документе информации
Примеры использования
Как это выглядит на практике. Загружаем документ например "Закон о защите прав потребителей" или "Ипотечный договор" и отправляем запрос:
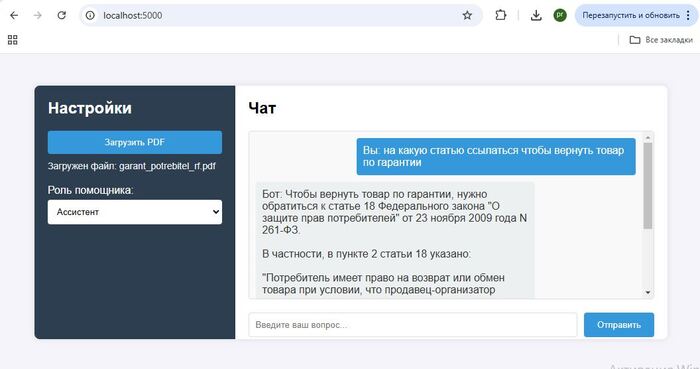
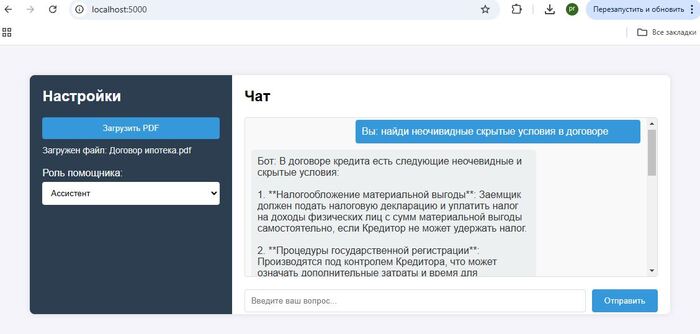
Здесь слева загружаем документ и справа задаем вопрос в данных примерах загружен ЗоЗПП и договор ипотеки.
Данные примеры наглядно показывают возможности нейросетей "выуживать" необходимую информацию из документов с последующим анализом.
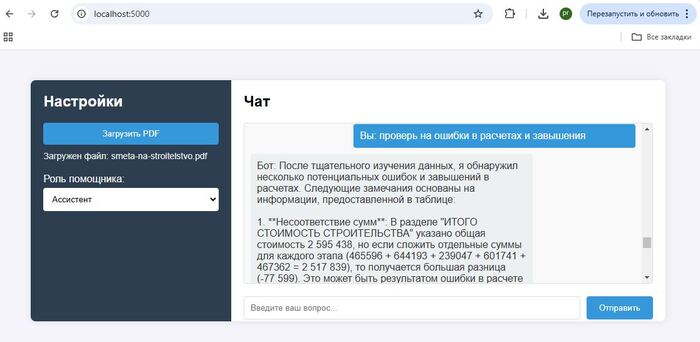
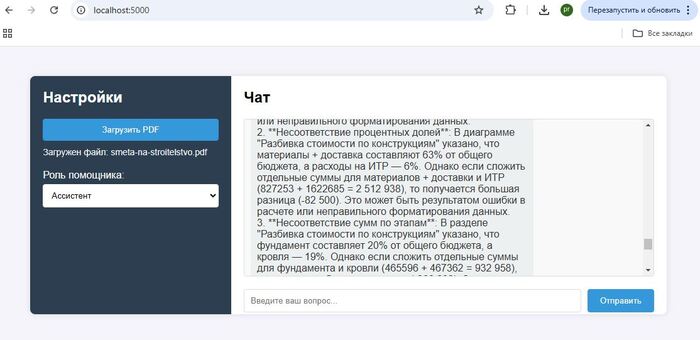
Тот же подход применим и для корпоративных задач.
В этих трех примерах проверяем смету на строительство, подбираем код из справочника ОКВЭД, и вытаскиваем из стратегии развития нужную информацию
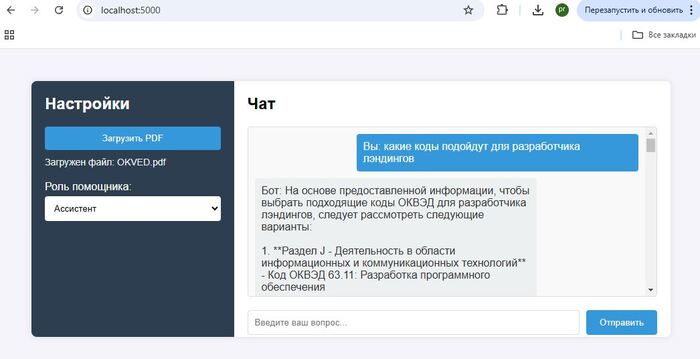
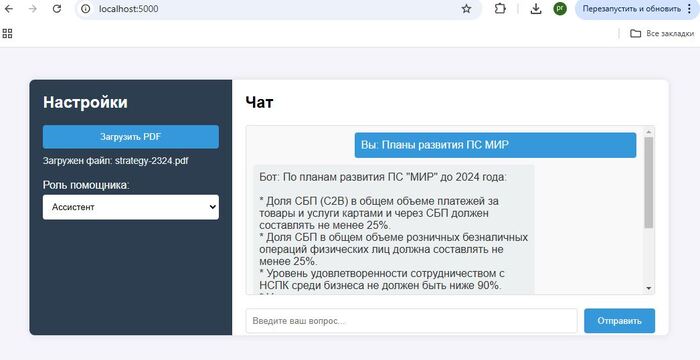
Этот инструмент вполне можно использовать для анализа технических документов, при чем даже на английском языке, например с легкостью получить информацию из даташита, руководства пользователя или руководства по ремонту:
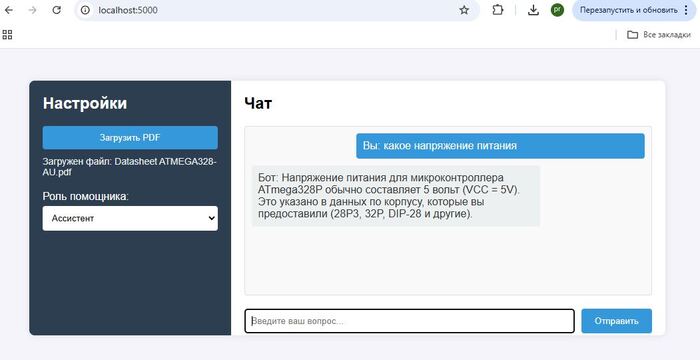
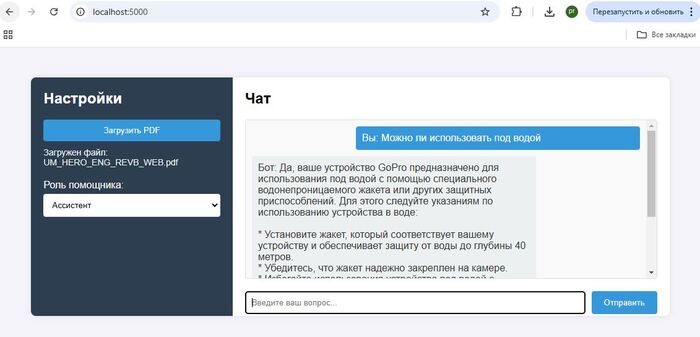
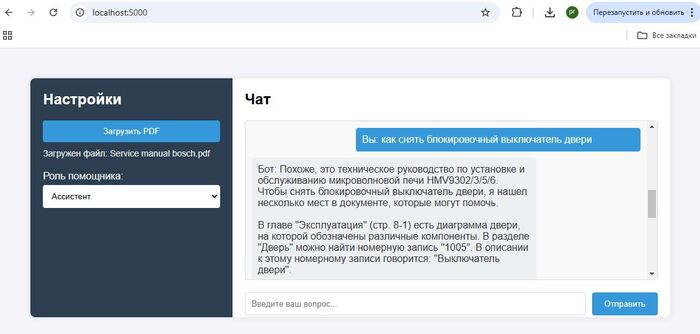
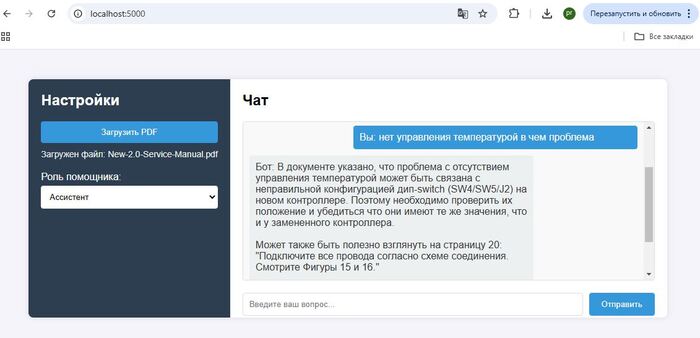
Загруженные виды документов Datasheet ATMEGA328, User manual экшн камеры, Service manual от микроволновки и сплит системы
Видны некоторые ограничения в переводе специфичных терминов, поскольку применённая модель не обучалась на русскоязычных материалах в этом домене.
Интересный пример анализа оценок с выдачей рекомендаций из табеля успеваемости:
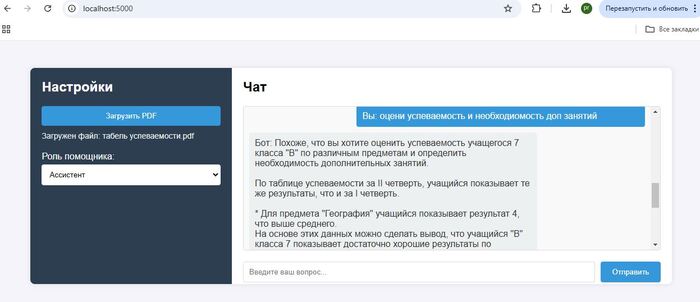
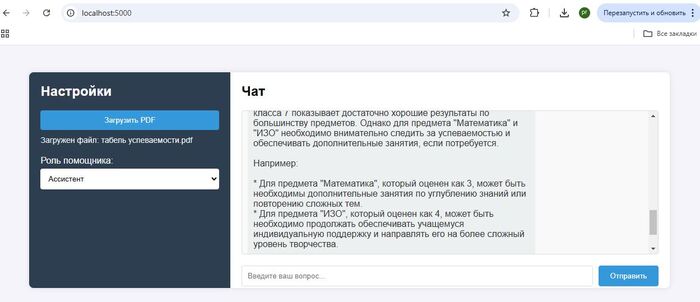
В качестве документа "скормили" табель успеваемости ученика 7 класса
Скорость: На локальных ресурсах время на генерацию ответа зависит от производительности GPU. В приведённых примерах составляло в пределах 15-25 сек\запрос, что как показывает практика, при выводе в потоковом режиме, практически гарантировано обеспечивают скорость генерации сравнимую с скоростью чтения.
Реализация
Для реализации нам понадобится:
Установить следующие зависимости Python, ollama, git и Библиотеки os, Json, ollama,Flask, loging, os, pyPDF2
Клонировать или скачать GIT репозиторий командой git clone https://github.com/iximy/AI-PDF-assistant.git
Настроить файл конфигурации config/config.json
Скачать и запустить нашу модель командой из quick_start, понадобится около 10 Гб свободного пространства
Запустить сервер командой python main.py
Открыть web интерфейс в браузере по адресу http://localhost:5000
Для преобразования PDF будем использовать бесплатную и открытую библиотеку PyPDF2
Проект разбит на несколько отдельных частей:
API сервер обеспечивает реализацию работы API, обрабатывает входящие запросы от формы веб интерфейса,
Веб интерфейс реализует минималистичный интерфейс загрузки документов, выбора роли ассистента, поле ввода сообщений пользователя и окно чата
RAG модуль (урезанная версия). Обеспечивает создание запроса к ИИ модели на основе контекста из документов хранящихся в БД. Подробнее о RAG системах можете почитать в моей статье
Document processor (Обработчик документов) Обеспечивает обработку загруженных документов для дальнейшей обработки
Logger - для сохранения истории запросов к API, значительно облегчает отладку
API сервер
Построен на библиотеке Flask, обеспечивает обработку запросов от WEB формы или внешних приложений.
Загружаем используемые библиотеки
from flask_cors import CORS
from flask import Flask, request, jsonify, render_template
from utils.document_processor import extract_text_from_pdf, save_document
from utils.rag import generate_response
import os
import json
Запускаем сервер
app = Flask(__name__, template_folder='../web/templates', static_folder='../web/static')
Маршрут для корневой страницы
@app.route('/upload', methods=['POST'])
def upload_document():
if 'file' not in request.files:
return jsonify({"error": "No file part"}), 400
file = request.files['file']
if file.filename == '':
return jsonify({"error": "No selected file"}), 400
file_path = save_document(file, file.filename)
return jsonify({"message": "File uploaded successfully", "file_path": file_path}), 200
Маршрут для запроса к модели
@app.route('/ask', methods=['POST'])
def ask_question():
data = request.json
if not data:
return jsonify({"error": "No data provided"}), 400
# Blocking incoming data
print("Incoming data:", data)
query = data.get('query')
file_path = data.get('file_path')
role = data.get('role', 'assistant') # The default role is "Assistant"
if not query or not file_path:
return jsonify({"error": "Missing query or file_path"}), 400
try:
context = extract_text_from_pdf(file_path)
response = generate_response(query, context, role) # Passing the role to the function
return jsonify({"response": response}), 200
except Exception as e:
# Logging the error
print("Error in ask_question:", str(e))
return jsonify({"error": "Internal server error"}), 500
Базовый URL
Все запросы API выполняются к базовому URL:
http://localhost:5000
Эндпоинты API
1. Загрузка PDF документа
Запрос
Метод: POST
URL: /upload
Тип содержимого: multipart/form-data
Параметры: file (обязательный): PDF файл для загрузки.
Пример запроса
curl -X POST -F "file=@document.pdf" http://localhost:5000/upload
Успешный ответ:
{
"message": "File uploaded successfully",
"file_path": "documents/document.pdf"
}
Ошибка:
{
"error": "No file part"
}
2. Задать вопрос на основе загруженного документа
Запрос
Метод: POST
URL: /ask
Тип содержимого: application/json
Параметры:
- query (обязательный): Вопрос, на который нужно ответить.
- file_path (обязательный): Путь к загруженному PDF файлу.
- role (опциональный): Роль помощника (по умолчанию assistant).
Пример запроса
curl -X POST -H "Content-Type: application/json" -d '{
"query": "What is the main topic?",
"file_path": "documents/document.pdf",
"role": "expert"
}' http://localhost:5000/ask
Ответ
Успешный ответ:
{
"response": "The main topic is artificial intelligence."
}
Ошибка:
{
"error": "Missing query or file_path"
}
Пример использования
Загрузите PDF документ:
curl -X POST -F "file=@document.pdf" http://localhost:5000/upload
Ответ:
{
"message": "File uploaded successfully",
"file_path": "documents/document.pdf"
}
Задайте вопрос на основе загруженного документа:
curl -X POST -H "Content-Type: application/json" -d '{
"query": "Какая тема документа?",
"file_path": "documents/document.pdf",
"role": "expert"
}' http://localhost:5000/ask
Ответ:
{
"response": "Документ описывает планы развития компании на 2025 год."
}
Обработка ошибок
API возвращает следующие коды состояния HTTP:
200 OK: Запрос выполнен успешно.
400 Bad Request: Неверный запрос (например, отсутствует обязательный параметр).
500 Internal Server Error: Внутренняя ошибка сервера.
Логирование
Все запросы и ошибки логируются в файл logs/app.log. Уровень логирования можно настроить в конфигурационном файле config/config.json.
Подключаем библиотеки
import logging
import json
import os
Загружаем конфигурацию
with open('config/config.json') as config_file:
config = json.load(config_file)
Создаем запись лога
logging.basicConfig(
level=config['logging']['level'],
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
filename=config['logging']['file']
)
logger = logging.getLogger(__name__)
Конфигурация
Настройки API, такие как хост, порт, путь к документам и ключ API для Ollama, хранятся в файле config/config.json. Пример конфигурации:
{
"ollama": {
"model_name": "model_name",
"host": "http://localhost:11434"
},
"server": {
"host": "0.0.0.0",
"port": 5000
},
"logging": {
"level": "INFO",
"file": "logs/app.log"
},
"documents_path": "documents/"
}
Веб-интерфейс
Веб-интерфейс доступен по адресу http://localhost:5000. Он позволяет:
Загружать PDF документы.
Выбирать роль помощника (например, "Ассистент", "Эксперт", "Переводчик")-опционально
Задавать вопросы и получать ответы отображая их в формате чата.
RAG модуль
Модуль в данном проекте значительно урезан в функционале, поскольку целью является только обеспечение формирования запроса к ИИ модели на основе контекста из загруженного документа. Полная версия в основном используется для реализации сложных RAG систем в коммерческих задачах. Подробнее о RAG системах можете почитать в моей статье
from ollama import Client
import json
Загружаем конфигурацию
with open('config/config.json') as config_file:
config = json.load(config_file)
Инициализация клиента Ollama
client = Client(host=config['ollama']['host'])
Формируем сообщение с контекстом и запросом
messages = [
{"role": "system", "content": f"You are a {role}. Provide helpful and accurate answers."},
{"role": "user", "content": f"Context: {context}\n\nQuery: {query}"}
]
Отправляем запрос к модели
Возвращаем ответ
return response['message']['content']
Document processor
Обработчик документов построен на библиотеке PyPDF2 и обеспечивает обработку загруженных документов для дальнейшей обработки место сохранения загруженных документов определено в параметре "documents_path" файла конфигурации config.json
import PyPDF2
import os
import json
Загружаем конфигурацию
with open('config/config.json') as config_file:
config = json.load(config_file)
Извлекаем текст
def extract_text_from_pdf(file_path):
with open(file_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
text = ''
for page in reader.pages:
text += page.extract_text()
return text
Сохраняем документ
def save_document(file, filename):
documents_path = config['documents_path']
if not os.path.exists(documents_path):
os.makedirs(documents_path)
file_path = os.path.join(documents_path, filename)
with open(file_path, 'wb') as f:
f.write(file.read())
return file_path
Этот мини проект всего лишь один из примеров использования AI технологий, для повседневных задач
Цель проекта достигнута. а значит еще один рабочий проект отправляется в копилку мини проектов "выходного дня"
С учетом того что здесь затруднительно публиковать читаемый код корректно с TABами, весь код доступен на странице проекта github
Вопросы по коду можете писать мне в ТГ