


Жена укладывает дочку и попросила принести какую-нибудь интересную книгу с приключениями...
Ну я и принёс

Показать полностью
1
Ну я и принёс
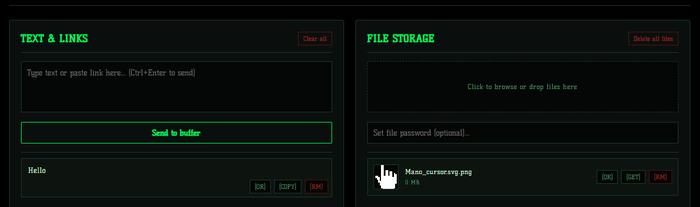
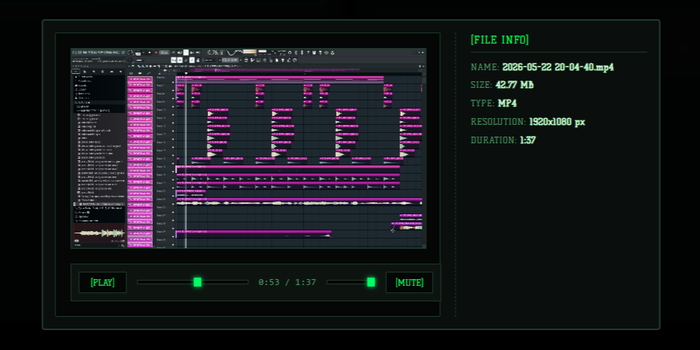
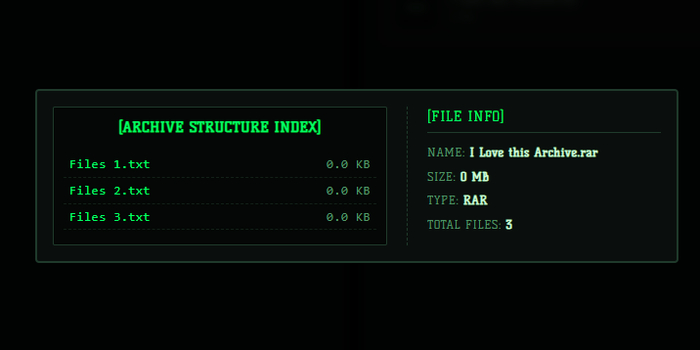
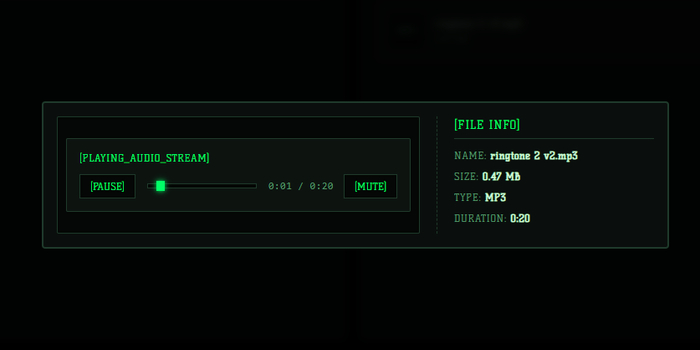

Интерфейс программы FlashStash
Каждый раз, когда нужно перекинуть файл, код или ссылку с ПК на телефон (или другу в той же Wi-Fi сети), начинается классическая возня. Либо гоняешь через «Избранное» в мессенджерах (где режется качество и файлы вечно висят в облаке), либо поднимаешь локальные веб-серверы через консоль. Мне это надоело, и я решил написать свою утилиту — FlashStash.
Основная идея: софт должен запускаться в один клик, работать без интернета внутри локалки, иметь всеядный предпросмотр файлов прямо в браузере и не требовать от пользователя установки Питона или настройки окружения.
После нескольких итераций проект дорос до версии 1.6, и я хочу поделиться тем, как устроена утилита изнутри и с какими техническими проблемами пришлось столкнуться.
Бэкенд написан на Python + Flask, а фронтенд работает на чистом JS. Процесс использования максимально упрощен:
Запускается один исполняемый файл FlashStash.exe.
Программа сама определяет локальный IP-адрес компьютера, поднимает сервер и автоматически открывает веб-интерфейс в браузере хоста.
Чтобы подключить смартфон или другой ПК к общему пространству, нужно просто ввести в адресную строку браузера IP-адрес, который отображается в консоли сервера.
При этом для каждого загруженного файла в интерфейсе генерируется отдельный QR-код — это позволяет мгновенно скачивать конкретные файлы на телефон через камеру, не вбивая ссылки вручную.
Проект собран как Zero-Dependency Portable Build. Внутри архива лежит скомпилированный .exe файл со своей иконкой и встроенное портативное ядро Python. То есть утилиту можно закинуть на абсолютно «голую» Windows (желательно прямо на Рабочий стол), кликнуть, и всё сразу заведётся.
В процессе разработки вылезло несколько неочевидных проблем, которые пришлось оперативно закрывать.
1. Борьба с «одноразовой» безопасностью
Изначально я добавил функцию защиты файлов паролями при загрузке. Но в первых версиях все пароли хранились в обычном Python-словаре в оперативной памяти. Стоило перезапустить сервер, как словарь очищался, файлы оставались в папке, но скачать их мог любой желающий без всякого пароля.
В версии 1.6 я переписал эту логику. Теперь все хэндлы, пароли файлов и история текстового буфера обмена намертво пишутся в локальные JSON-файлы. Данные идеально выдерживают перезапуск сервера и не нагружают систему лишними тяжелыми СУБД.
2. Закрытие уязвимости Path Traversal
Когда пишешь локальный веб-сервер для обмена файлами, легко забыть про базовую безопасность путей. В первых билдах бэкенд принимал имя файла из адресной строки практически «как есть».
Продвинутый пользователь в локальной сети мог провернуть атаку Path Traversal, отправив запрос вида ../, выйти за пределы папки обмена и стянуть системные файлы с хост-машины. Чтобы это исправить, я внедрил жесткую фильтрацию и санитаризацию входных путей через os.path.basename. Теперь бэкенд отсекает любые попытки побега из папки shared_files.
3. Всеядный предпросмотр (All-in-One)
Мне не хотелось, чтобы пользователь скачивал файл только ради того, чтобы узнать, что внутри. Поэтому фронтенд получил встроенные плееры для аудио и видео, просмотрщик картинок и текстовых документов. Из интересного — добавил просмотрщик архивов: структура файлов внутри .zip и .rar отображается прямо на веб-странице до скачивания самого архива.
Поскольку Питон при работе создаёт скрытый кэш (__pycache__), а папка shared_files постепенно забивается реальными файлами, перед заливкой проекта на GitHub или передачей папки другу её нужно как-то чистить. Сам запущенный Питон свои процессы и кэш удалить не может (Windows выдаёт Access Denied).
Для этого я написал отдельный служебный батник Wipe_All_Data.bat на английском (чтобы кодовая база репозитория выглядела аккуратно). Он делает три вещи:
Жестко тушит активные процессы сервера через taskkill.
Под ноль вычищает папки с файлами, паролями и текстами.
Сканирует дерево директорий и сносит весь кэш компилятора Питона, сжимая вес папки до исходного минимума.
Проект получился именно таким, каким я хотел его видеть в повседневной жизни — легким, быстрым и независимым. Исходный код полностью открыт, пощупать портативный билд v1.6 и оценить реализацию можно на гитхабе.
Буду рад конструктивной критике в комментариях. Пишите, каких фич вам не хватает в локальных файлообменниках и как бы вы улучшили текущую архитектуру.

Как я собрал бесплатный домашний кинотеатр без лагов: связка Lampa + TorrServer на сервере
Всем привет! Сегодня хочу поделиться рабочим решением наболевшей проблемы: как смотреть фильмы и сериалы на Smart TV в максимальном качестве (вплоть до тяжелых 4K HDR релизов), не платя за кучу разрозненных подписок и не мучаясь с постоянными тормозами.
Мы соберем связку из двух бесплатных программ: Lampa и TorrServer, но с одним важным нюансом — сам движок TorrServer мы запустим не на слабеньком процессоре телевизора, а вынесем его на домашний сервер (или старый мини-ПК/ноут, который валяется без дела).
Ниже — простая и понятная инструкция, как это сделать и почему это спасет ваш телевизор от тормозов, а роутер — от зависаний.
---
=== В чем проблема настроить всё прямо на телевизоре? ===
Обычно в интернете советуют самый простой путь: поставить Lampa на ТВ, туда же накатить Android-версию TorrServer, запустить его и смотреть.
Я тоже сначала так сделал. Результат — смотреть невозможно. Картинка фризит, звук заикается, а пульт реагирует на нажатия секунд через 5 после того, как ткнешь кнопку.
Почему так происходит?
1. Железо телевизора слишком слабое. Бюджетные Smart TV (типа Xiaomi, Hartens, TCL и прочие) имеют очень слабые процессоры и крошечный объем оперативной памяти (обычно около 1-1.5 ГБ). TorrServer — это полноценный торрент-клиент. На раздаче 4K-фильма он начинает открывать сотни сетевых соединений и активно кушать процессорное время. Телевизор банально перегревается, частота процессора падает (троттлинг), и всё начинает жутко тормозить.
2. Wi-Fi чип захлебывается. Слабый беспроводной модуль телевизора не справляется с одновременным скачиванием торрента от десятков пиров и передачей видеопотока.
3. Android «убивает» плеер. Когда TorrServer забивает всю оперативную память телевизора буфером видео, Android видит нехватку RAM и просто аварийно закрывает видеоплеер прямо посреди просмотра.
Решение: Выгрузить TorrServer с телевизора на домашний сервер или старый компьютер. Пусть сервер делает всю грязную работу (качает торрент, собирает пакеты, держит буфер), а телевизор будет получать чистый, легкий видеопоток по локальной сети, как с обычного YouTube.
---
=== Шаг 1. Запуск TorrServer на домашнем сервере ===
Для сервера подойдет любое устройство, которое работает круглосуточно: домашний NAS, мини-ПК, старый ноутбук или одноплатник типа Raspberry Pi.
В моем случае TorrServer крутится в легковесном Debian LXC-контейнере на сервере виртуализации Proxmox VE. Ему выделено 2 ядра процессора и 2 ГБ оперативной памяти (этого хватает с огромным запасом).
Установить TorrServer на сервер с Linux (Debian/Ubuntu) можно буквально в пару команд.
=== БЛОК КОДА ===
# Скачиваем официальный бинарник
wget -O /usr/bin/TorrServer https://github.com/YouROK/TorrServer/releases/download/Matri...
chmod +x /usr/bin/TorrServer
# Запускаем TorrServer на порту 8090
/usr/bin/TorrServer -d /opt/torrserver -p 8090 &
==============
*(Для постоянной работы лучше оформить запуск через systemd-сервис, чтобы служба автоматически поднималась после перезагрузки сервера).*
---
=== Шаг 2. Важнейшая настройка: Сберегаем диск (RAM-кэш) ===
ВНИМАНИЕ! Этот пункт обязателен для выполнения, иначе вы убьете накопитель вашего сервера.
========================
По умолчанию TorrServer может использовать жесткий диск или SSD для кэширования видео. Если вы посмотрите фильм в 4K объемом 60 ГБ, TorrServer запишет эти 60 ГБ на ваш SSD. При частом просмотре за пару месяцев вы легко накрутите несколько терабайт перезаписи, что быстро прикончит накопитель.
Нам нужно настроить TorrServer так, чтобы он кэшировал данные только в оперативную память (RAM). Оперативка рассчитана на бесконечное количество циклов перезаписи и работает в сотни раз быстрее любого диска.
Открываем браузер на компьютере и переходим в настройки TorrServer: http://<IP-вашего-сервера>:8090 (в моем случае это http://192.168.188.65:8090).
Переходим в раздел настроек и выставляем следующие параметры:
- Тип кэша: Выбираем Memory (Оперативная память). Никаких дисков!
- Размер кэша: Ставим 512 МБ (536870912 байт). Этого буфера идеально хватает, чтобы сглаживать любые просадки скорости интернета во время воспроизведения.
- Буфер предзагрузки: Ставим 30%. Плеер начнет играть кино только тогда, когда скачает первые 150 МБ фильма в оперативку. Это гарантирует отсутствие заиканий на старте.
- Лимит соединений: Ставим 200. Больше не нужно, иначе слабый домашний роутер начнет перегружаться от обилия торрент-сессий и вешать интернет остальным домочадцам.
Нажимаем «Сохранить». Всё, сервер готов к работе и находится в полной безопасности.
---
=== Шаг 3. Установка и настройка Lampa на Android TV ===
Теперь переходим к телевизору.
1. Устанавливаем официальное приложение Lampa на телевизор (его можно найти в RuStore, Android TV Market или скачать APK-файл напрямую с GitHub).
2. Запускаем Lampa, заходим в Настройки (значок шестеренки) -> TorrServer.
3. Меняем Тип подключения на Основное.
4. В строке Адрес TorrServer вписываем сетевой адрес нашего сервера: http://<IP-сервера>:8090 (например, http://192.168.188.65:8090).
5. Нажимаем кнопку Проверить. Если всё сделано верно, статус сменится на зеленый «Подключено», и покажется версия сервера.
---
=== Шаг 4. Настраиваем поиск фильмов (Парсер) ===
Lampa сама по себе — это просто красивая афиша с описанием фильмов и актерским составом. Чтобы внутри карточки фильма появились кнопки для просмотра торрентов, нужно включить парсер (поисковик по торрент-трекерам).
1. В Lampa заходим в Настройки -> Парсер.
2. Включаем пункт Использовать парсер (ставим галочку «Да»).
3. В поле Адрес парсера вписываем проверенное рабочее зеркало Jackett-поисковика: jac.red (это бесплатный публичный враппер, который ищет раздачи по всем популярным трекерам).
4. Убеждаемся, что включен поиск торрентов по всем доступным категориям.
---
=== Проверяем результат ===
Возвращаемся на главный экран Lampa, выбираем любой фильм, который хотели посмотреть. Заходим в его карточку. Снизу под описанием, рядом с кнопками трейлеров, у нас появится новая вкладка «Торренты».
Кликаем на нее — Lampa мгновенно выдает список доступных раздач с указанием качества (1080p, 4K, HDR, Dolby Vision), размера файла и количества раздающих (сидов).
Выбираем нужную раздачу (например, 4K HDR на 45 ГБ), нажимаем ОК. Проходит 3–5 секунд (сервер забивает буфер в оперативную память), и начинается фильм. Перемотка вперед-назад работает плавно и без зависаний. Телевизор при этом абсолютно холодный, интерфейс летает, а качество картинки — максимальное, без какого-либо пересжатия.
Для надежности мы также настроили на сервере простой watchdog-скрипт. Если служба TorrServer по какой-то причине зависнет из-за битого торрент-файла, сервер сам автоматически перезапустит ее в течение 2 минут. Всё работает полностью автономно по принципу «один раз настроил и забыл».
Делитесь в комментариях, как вы организовали домашний просмотр фильмов и какие плееры/сервисы используете! Если возникнут трудности с настройкой — пишите, постараюсь помочь в комментариях.
Пишите на какие темы еще бы хотели увидеть статьи - с радостью с вами поделюсь и отвечу на ваши комменты !

Знакомая ситуация? Скопировал на телефоне код из СМС - надо вставить в терминал на ноуте. Скопировал ссылку на компе - хочешь открыть на телефоне. И каждый раз одно и то же: отправляешь сам себе в Telegram, в «Избранное».
У меня этих «Избранных» сообщений уже на пару тысяч накопилось. Свалка из ссылок, кодов, кусков текста и паролей.
Вот на слове «паролей» я и притормозил.
Сначала я пошёл искать готовое решение - таких сервисов хватает. Поставил один, попользовался неделю. А потом поймал себя на мысли: я только что прогнал через этот буфер пароль от рабочей базы. И он улетел на чей-то чужой сервер.
Полез читать, как эти штуки устроены. И почти везде одно и то же: ваш буфер обмена уезжает на сервер компании, там лежит, оттуда раздаётся на другие ваши устройства. Шифрование «по дороге» есть почти у всех - но на самом сервере данные лежат как есть. Открытым текстом.
То есть весь вопрос «читает ли кто-то мой буфер» сводится к «доверяю ли я этой компании». А я не хотел доверять на слово. Даже самому себе.
Сел и написал свой сервис. Называется Copy Sync. Идея в одной фразе:
Сервер устроен так, что ему физически нечего у вас украсть.
Это не «мы обещаем не смотреть». Это «мы технически не можем посмотреть, даже если очень захотим». Разница примерно как между «сосед обещал не читать ваши письма» и «письмо вообще не попадает соседу в руки».
Как это работает на человеческом языке:
Ваш текст шифруется прямо на вашем устройстве, ещё до отправки.
На сервер уезжает уже не текст, а зашифрованная каша. Ключа от неё у сервера нет - ключ остаётся у вас.
Получатель (другое ваше устройство) расшифровывает кашу обратно у себя.
Сервер в этой схеме - просто труба. Он передаёт мешок, не зная, что внутри. Сами данные не хранятся - улетели и удалились.
Если кто-то завтра украдёт мой сервер целиком и заглянет в базу - он увидит столбец со случайным шумом. Ни паролей, ни ссылок, ни ключей. Их там нет не потому, что я их спрятал. Их там нет по конструкции.
Потому что «доверьтесь мне, я честный» - это ровно то, от чего я бежал. Поэтому весь код открыт. Любой, кто умеет читать программу, может проверить.
И честно про минусы, без маркетинга: проект ещё сырой. Пока работает веб-версия, расширение для браузера и приложения на телефон - в планах. Пара важных штук по безопасности ещё не доделана. Это пет-проект одного человека, а не продукт корпорации.
Сайт: copysync.ru
Исходники (для тех, кому интересно заглянуть под капот): gitlab.com/razgiva/copy-sync
Буду рад вопросам и критике в комментах - особенно если кто-то шарит в безопасности и найдёт, что я сделал не так. Для того и выкладываю.
А ещё расскажите: вы сами-то как ссылки между телефоном и компом гоняете? Неужели тоже «Избранное»?
В начале 2000-ых я слушал музыку на своём Sony Walkman и даже не представлял что спустя почти 15-20 лет я разработаю свой собственный продукт.
Прошли годы: плееры постепенно исчезли, на смену им пришли смартфоны и стриминговые сервисы, однако проблемы с музыкальным контентом сохранялись. Сообщения вроде «Трек недоступен в вашей стране» или банальное отсутствие редких треков и ремиксов в каталоге исполнителя заставили меня задуматься. А что, если создать плеер, доступный на любом устройстве через браузер? В нём можно будет хранить все треки и пользоваться ими с любого гаджета, будучи уверенным, что контент не пропадёт с площадок, не подвергнется цензуре или региональным ограничениям.
Я вспомнил свой первый плеер от Sony, потому что он давал свободу и не накладывал ограничений. Здесь та же идея: все треки, которые загружаются в LIMB, остаются вашими. Только теперь они хранятся не на самом устройстве, а в облаке. Благодаря этому доступ к своей музыкальной коллекции можно получить практически откуда угодно: ПК и браузер, смартфон и браузер или даже ТЕЛЕВИЗЕР😯 с браузером.
Вот, собственно, и вся история. Сейчас я ищу первых пользователей и буду рад, если кто-то захочет протестировать проект. Любая обратная связь будет полезна.
В проекте полностью отсутствует реклама.

От Sony до LIMB
Microsoft сделала общедоступным пакет Coreutils для Windows, который добавляет более 75 популярных UNIX-команд, включая ls, cp, grep и find. Утилиты работают нативно в Windows без WSL, виртуальных машин и сторонних оболочек, упрощая перенос сценариев между Linux, macOS и Windows
Набор включает более 75 утилит. Среди них привычные команды Linux:
работа с файлами и каталогами: ls, cp, mv, rm, cat, pwd;
поиск и обработка текста: grep, find, xargs, sort, more;
системные команды: date, kill, uptime.
Разработчики постоянно переключаются между платформами, но привычные команды ведут себя по-разному, что заставляет искать обходные пути, тратить время и переключать контекст. Coreutils для Windows убирает это трение: одни и те же команды, флаги и конвейеры работают одинаково, поэтому готовые сценарии и наработанные привычки переносятся без перевода.
По словам главы Windows Павана Давулури, какой бы средой ни пользовался разработчик – Linux, macOS, WSL, контейнеры или облако, – команды и рабочие процессы, отлаженные за годы, продолжают работать и в Windows.
Подробности: https://github.com/microsoft/coreutils
YouTube начал активнее закручивать гайки пользователям с включённым VPN. Россияне столкнулись с тем, что часть видео либо не открывается, либо вообще пропадает из раздела «Новые». В некоторых случаях платформа прямо просит отключить VPN или прокси, чтобы «предлагать наиболее подходящий контент». Речь идёт не обо всём YouTube сразу, а прежде всего о роликах с жёсткой привязкой к региональным правам. Под удар попали каналы с международными спортивными трансляциями, «Формулой-1», Олимпийскими играми и отдельными ТВ-премьерами. Там права продаются по странам, платформам и форматам, так что лишний зритель не из того региона для правообладателей — не просто мелочь, а потенциальная головная боль. По сути, YouTube борется не с VPN как таковыми, а с обходом географических ограничений. Если пользователь включает VPN, для платформы он как бы переезжает в другую страну и может получить доступ к контенту, права на который в его регионе не куплены или принадлежат другому дистрибьютору. Эксперты считают, что массовой блокировки всего контента для пользователей с VPN ждать не стоит: для YouTube это было бы слишком рискованно. Но точечный контроль за спортивными трансляциями, эксклюзивами и другим дорогим лицензионным контентом, судя по всему, будет только усиливаться. И это не первый звоночек. Ещё в 2024 году YouTube начал бороться с пользователями, которые оформляли Premium через VPN в странах, где подписка стоит заметно дешевле. Теперь очередь дошла до контента с региональными правами. Платформа может учитывать не только IP-адрес, но и страну аккаунта, платёжные данные, историю локаций и признаки использования VPN. Поэтому у одного пользователя видео открывается, а у другого — внезапно нет. Добро пожаловать в мир территориальных лицензий.
Всем привет и лучи добра!
Хочу поделиться своими личными достижениями!
Собрал, установил и настроил свой сервер!)
Отдали старую машинку:
ASUSTeK Computer INC. P8Z68-M PRO
CPU: i7-2700K (8) @ 3.9GHz [38.0°on]
Memory: 16GB DDR3
Добавил ещё 16 GB памяти.
Установил диски:
Smartbuy SSD NVMe 256GB
AMD SSD Sata R5SL128G
Seagate HDD ST1000DL002-9TT1 1000GB
M3D B16A SSD Sata 111 GB
2 диска Seagate HDD ST6000DM003-2CY1 6TB
Так как в этой материнской плате нет NVMe слота, купил переходник на PCI-E x4
Установил Debian 11 Bullseye, 3 года назад обновился на 12 Bookworm, а год назад на 13 Trixie.
Зарегистрировал доменное имя в зоне .ru, взял у провайдера постоянный фиксированный ip адрес, настроил AAA записи домена на свой ip адрес, на роутере переадресацию портов.
На сервере запустил следующие сервисы:
Nextcloud
XMPP сервер со звонками и web интерфейсом для управления
Почтовый сервер postfix+dovecot
rtorrent
mysql+phpmyadmin
Сервер World of Warcraft Legion(win версия через Wine)
webmin
Web интерфейс nginx
Сервер RustDesk
Home Assistant (виртуальная машина kvm)
Автообновление ssl wildcard сертификата для моего доменного имени
Автоматическое резервное копирование системы на отдельный диск и нужных данных сервисов.
Диски разбиты и смонтированы так:
sda 8:0 0 5,5T 0 disk
└─sda1 8:1 0 5,5T 0 part
└─md0 9:0 0 10,9T 0 raid0
└─d3-d3 253:0 0 10,9T 0 lvm /z/n
/z/z
sdb 8:16 0 5,5T 0 disk
└─sdb1 8:17 0 5,5T 0 part
└─md0 9:0 0 10,9T 0 raid0
└─d3-d3 253:0 0 10,9T 0 lvm /z/n
/z/z
sdc 8:32 0 931,5G 0 disk
└─sdc1 8:33 0 931,5G 0 part /z/R
sdd 8:48 0 119,2G 0 disk
├─sdd1 8:49 0 50G 0 part /usr
├─sdd2 8:50 0 40G 0 part /var
├─sdd3 8:51 0 10G 0 part /tmp
└─sdd4 8:52 0 19,2G 0 part /z/R/ressyst
sde 8:64 0 111,8G 0 disk
├─sde1 8:65 0 1G 0 part /boot/efi
└─sde2 8:66 0 110,8G 0 part /root
nvme0n1 259:0 0 238,5G 0 disk
├─nvme0n1p1 259:1 0 100G 0 part /
├─nvme0n1p2 259:2 0 100G 0 part /y
└─nvme0n1p3 259:3 0 38,5G 0 part [SWAP]
Жду комментарии, советы, критику, вопросы.
Подскажу, что как настроил!)









