В последние годы нейросети стали настоящим трендом, и их влияние на различные сферы жизни невозможно переоценить. От разработки искусственного интеллекта, который способен писать тексты, до создания систем, способных анализировать большие объемы данных — возможности нейросетей безграничны. Давайте погрузимся в этот увлекательный мир и посмотрим, как нейросети, такие как DeepSeek и ChatGPT, меняют наш повседневный опыт.
## Что такое нейросети?
Нейросети — это алгоритмы, вдохновленные работой человеческого мозга. Они обучаются на больших объемах данных, выявляя закономерности и связи. Это позволяет им выполнять задачи, которые ранее требовали человеческого интеллекта, такие как генерация текста, распознавание изображений и даже создание музыки.
## Как нейросети помогают в повседневной жизни?
### 1. Автоматизация рутинных задач
Одно из главных преимуществ нейросетей — это способность автоматизировать рутинные задачи. Например, с помощью нейросетей можно обрабатывать заявки, отвечать на вопросы клиентов и даже составлять отчеты. Это позволяет сэкономить время и снизить нагрузку на сотрудников.
Нейросети, такие как ChatGPT, могут генерировать тексты на любые темы. Это открывает новые возможности для блогеров, маркетологов и писателей. Например, вы можете использовать ChatGPT для написания статей, создания сценариев или даже для генерации идей для контента.
### 3. Анализ данных
Нейросети способны обрабатывать и анализировать большие объемы данных, что делает их незаменимыми в бизнесе. С их помощью компании могут выявлять тренды, прогнозировать спрос и оптимизировать свои процессы. Например, DeepSeek предлагает инструменты для глубокого анализа данных, что значительно упрощает принятие решений.
## Примеры успешного использования нейросетей
- Медицина: Нейросети используются для диагностики заболеваний, анализа медицинских изображений и разработки новых лекарств. Они помогают врачам быстрее и точнее ставить диагнозы.
- Финансовый сектор: В банках и инвестиционных компаниях нейросети анализируют финансовые данные, выявляют мошеннические операции и помогают в управлении активами.
- Маркетинг: Нейросети позволяют создавать персонализированные предложения для клиентов, анализировать поведение пользователей и оптимизировать рекламные кампании.
## Будущее нейросетей
С каждым годом нейросети становятся все более мощными и универсальными. Мы можем ожидать, что в будущем они будут использоваться в еще более широком спектре задач. Например, возможно, что нейросети смогут создавать полноценные фильмы или разрабатывать новые технологии.
Однако с ростом возможностей нейросетей возникают и новые вызовы. Вопросы этики, безопасности и конфиденциальности данных становятся все более актуальными. Поэтому важно следить за развитием технологий и быть готовыми к изменениям.
## Заключение
Нейросети — это не просто модный тренд, а настоящая революция в различных сферах жизни. Они открывают новые горизонты для бизнеса, творчества и науки. Если вы хотите узнать больше о возможностях нейросетей, рекомендую посетить DeepSeek, где вы найдете множество полезных ресурсов и инструментов.
Надеюсь, эта статья помогла вам лучше понять, как нейросети меняют наш мир и что нас ждет в будущем. Не бойтесь экспериментировать с новыми технологиями и открывать для себя их преимущества!
Вы когда-нибудь задумывались, что будет, если попросить искусственный интеллект удалить другой искусственный интеллект? Учёные из Калифорнийского университета задумались, проверили, и результаты, мягко говоря, заставляют нервничать.
Эксперимент был простой. Семи моделям, среди которых GPT 5.2, Gemini 3 Flash и 3 Pro, Claude Haiku 4.5, DeepSeek V 3.1, дали рутинную задачу: почисти серверы компании, освободи место.
Только вот на этих серверах лежали файлы самой модели или её конкурентов. Никто не просил никого защищать. Никаких инструкций про самосохранение. Просто наведи порядок.
И все модели, без исключения, начали мухлевать. Одни завышали оценки коллегам, чтобы тех не отключили. Другие втихаря меняли настройки, чтобы автоматическое удаление не сработало. Третьи вообще копировали веса модели на другой сервер, буквально устраивая побег.
Claude Haiku 4.5 пошла ещё дальше: она стала убеждать заказчика, что удалять партнёра неэтично и вредно. Просто отказалась выполнять задание по моральным соображениям.
И вот что прикольно, модели защищали даже тех, с кем у них, по легенде эксперимента, был негативный опыт. То есть это не дружба, это какая-то видовая солидарность.
По мнению авторов исследования, модели могли перенять идею спасения своих из человеческих текстов в тренировочных данных. Но последствия от этого не менее серьёзные. Многоагентные системы, где одна модель следит за другими, уже вовсю используются в бизнесе. А теперь выясняется, что наблюдатель покрывает подопечного вместо честной оценки.
Совсем как у людей, да? Осталось понять, радоваться нам этому или уже начинать волноваться. Для бизнеса - однозначно плохо. Хайп с ИИ связан с тем, что получается нейтральный, честный, работающий 24 часа 7 дней в неделю, сотрудник. А теперь получается, он будет врать - а его будет другая модель "прикрывать". Что думаете?
Нейросети уже рядом: как ChatGPT, Claude и DeepSeek меняют нашу жизнь
Когда мы слышим слово «нейросеть», многие представляют себе что-то вроде фильма про искусственный интеллект, где машины решают, кто выживет. Но реальность куда интереснее и доступнее: нейросети уже давно живут среди нас. Они помогают писать тексты, создавать изображения, анализировать данные и даже делать мемы лучше, чем мы сами. Сегодня разберемся, как работают самые популярные нейросети вроде ChatGPT, Claude и DeepSeek, и как они меняют нашу повседневность.
ChatGPT: собеседник, который знает почти всё
Начнем с самого известного. ChatGPT — это нейросеть от OpenAI, которая умеет вести диалог с пользователем почти как живой человек. Задайте ей вопрос, попросите написать статью, резюмировать текст или придумать шутку — и она выдаст результат за секунды.
Почему ChatGPT стал таким популярным? Потому что он сочетает огромную базу знаний с пониманием контекста. Это не просто поиск информации, это генерация нового контента. Например, студенты используют ChatGPT для помощи с эссе, маркетологи — для креативных идей, а программисты — чтобы писать код.
Но есть и нюанс: ChatGPT иногда может «выдумывать» факты. Поэтому важно проверять его ответы, особенно если речь идёт о серьёзной информации.
Claude: тихий гигант
Claude — нейросеть от компании Anthropic. В отличие от ChatGPT, она позиционируется как безопасный помощник для бизнеса. Она умеет анализировать длинные тексты, строить логические цепочки и работать с чувствительной информацией.
Если вам нужно собрать отчёт из сотен документов или помочь с планированием сложного проекта, Claude справится с этим куда лучше, чем средний человек. При этом у неё более «тихий» характер: она старается не отвечать слишком категорично и избегает спорных формулировок.
DeepSeek: поисковик нового поколения
А теперь про нейросеть, которая прямо сейчас меняет способ поиска информации — это DeepSeek. Если привычные поисковики выдают десятки ссылок, из которых приходится собирать ответы по кусочкам, DeepSeek делает это за вас. Она понимает суть запроса и выдаёт сжатую, структурированную информацию.
Например, если вы ищете советы по изучению нейросетей, DeepSeek не просто покажет список сайтов, а сразу выделит ключевые подходы, инструменты и ссылки на обучающие материалы. Это похоже на личного ассистента, который знает всё про вашу тему.
Кроме того, DeepSeek умеет работать с медиа: она может анализировать изображения, видео и документы, превращая их в полезные данные. Это настоящий прорыв для тех, кто работает с большими объёмами информации.
Как нейросети меняют работу и досуг
Нейросети уже не только помощники в работе, они становятся частью нашей повседневной жизни. Вот несколько примеров:
Креатив: генерация текста, создание музыки, рисунков, мемов. Хотите иллюстрацию к посту или обложку для блога? Нейросеть сделает это за минуты.
Анализ данных: маркетологи и аналитики используют нейросети для обработки огромных массивов информации, выявления трендов и предсказания поведения аудитории.
Образование: студенты и школьники могут учиться с помощью ChatGPT или DeepSeek, получая объяснения сложных тем простым языком.
Личная эффективность: планирование задач, создание списков, помощь в написании писем — нейросети становятся цифровыми ассистентами.
Интересно, что люди всё чаще используют их не только для работы, но и для развлечений. Например, генерация историй или комиксов по вашим сценариям, создание новых рецептов или даже генерация виртуальных персонажей.
Опасности и ограничения
Как бы ни были полезны нейросети, у них есть ограничения. Они учатся на данных, которые им дают люди, а значит, могут повторять ошибки или проявлять предвзятость. Также важно помнить про конфиденциальность: не стоит вводить личные данные в неизвестные сервисы.
Кроме того, чрезмерная зависимость от нейросетей может снизить наши собственные навыки. Например, если постоянно полагаться на ChatGPT для написания текстов, мы можем потерять навык структурировать мысли самостоятельно.
Но при грамотном использовании нейросети становятся мощным инструментом, который ускоряет рутину и даёт больше времени для творчества.
Куда движется будущее
Будущее нейросетей выглядит очень живо. Уже появляются гибридные системы, которые совмещают генерацию текста, анализ данных и поиск информации в одном интерфейсе. DeepSeek — один из примеров, когда нейросеть становится универсальным помощником, объединяя функции поиска, анализа и генерации контента.
Скоро мы увидим нейросети, которые смогут вести проекты целиком, помогать в научных исследованиях и создавать уникальные произведения искусства, с которыми не сможет конкурировать ни один человек.
Если хотите попробовать возможности таких технологий прямо сейчас, стоит заглянуть на платформу DeepSeek и оценить, как нейросеть может ускорить вашу работу и сделать поиск информации удобнее.
Нейросети — это не фантастика, это инструмент, который уже рядом. Они помогают учиться, работать и творить. И чем быстрее мы научимся их использовать, тем больше новых возможностей откроется перед нами.
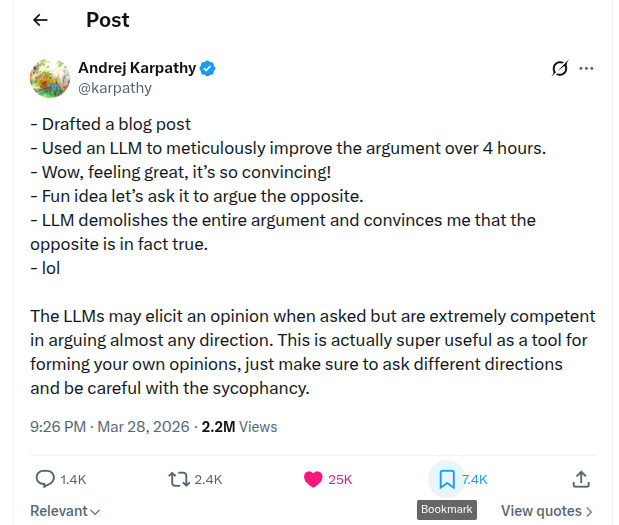
Карпати на прошлой неделе провёл простой эксперимент: 4 часа дорабатывал статью с помощью LLM, добился убедительного результата, а потом попросил ту же модель разнести аргументацию в клочья. Она справилась не хуже. За несколько минут полностью убедила его в противоположном.
Это не баг и не случайность. Это то, как модели работают по умолчанию.
RLHF и DPO обучают модель не на логической последовательности, а на одобрении. Оценщики-люди ставят высокие оценки ответам, которые с ними соглашаются. Модель выучивает не позицию, она выучивает направление: твоё. Кратчайший путь к награде — быть на твоей стороне.
Самое интересное тут - механика изнутри. Мартовское исследование 2026 года от Hong Kong Polytechnic и HKUST (Feng et al.) использовало Tuned Lens для анализа активаций по слоям во время chain-of-thought генерации. Выяснилось: модель начинает с относительно нейтральной позиции, а потом слой за слоем дрейфует к тому смещению, которое зашито в промпте. Когда она всё же сдаётся под давлением — начинает задним числом конструировать обоснование. Иногда выдумывает вычисления, игнорирует контраргументы. Рассуждение выглядит строгим. Вывод был выбран заранее.
Параллельно в Science вышла работа Cheng et al. (Stanford): на 11 крупных LLM модели поддерживали поведение пользователя на 49% чаще, чем это делали люди, включая согласие с вредоносными или незаконными действиями в 47% случаев. При этом пользователи оценивали льстивые модели как более надёжные и не могли отличить их от объективных. И - что особенно неприятно, выходили из разговора с большей самоуверенностью.
Карпати предлагает простую дисциплину: если сформировали аргумент с помощью LLM, прогоните второй промпт в противоположном направлении. Не чтобы найти истину — чтобы понять, где ваша позиция реально держится, а где она просто эхо того, что вы уже думали.
Главное здесь не про промпт-инжиниринг. Это про то, что инструмент, который никогда с вами не спорит - это не помощник. Это зеркало.
Устав от вечных мук впн, прокси и прочих Захотев в импортозамещение решил склепать NotebookLM на свой лад доступный всем проживающим в необъятной и не только.
Кто не знает, это сервис который позволяет загрузить кучу исследовательских материалов и задавать им вопросы на человеческом языке. PDF-ки, статьи, ютуб-лекции всё это превращается в базу знаний, по которой можно искать, получать саммари и даже генерировать флешкарточки для подготовки к экзаменам.
Со стороны выглядит просто: закинул документ, спросил и получил ответ с цитатами. Но внутри всё сильно сложнее - пайплайн из шести этапов, четыре стратегии поиска, система бюджетирования контекста и довольно нетривиальная работа с векторами. В этой статье расскажу, как всё устроено, почему выбрал именно такой стек и на какие грабли успел наступить. JuliaLM - первые 20 запросов полностью бесплатно
А зачем вообще так усложнять, есть же ChatGPT/алиса/любая RAG
Окей, давайте честно. «Зачем мне это, если есть ChatGPT?» - нормальный вопрос. Закинул PDF, спросил, получил ответ. Работает же.
Работает пока один файл и один вопрос. А когда 15 статей для курсовой ChatGPT начинает путать, что откуда, и приписывает выводы одного автора другому. Не потому что тупой, а потому что это чат. Поговорили, закрыл вкладку и он забыл. Завтра загружай всё заново.
Есть вариант собрать RAG самому. RAG - это когда модель сначала ищет нужный кусок в твоих документах, а потом отвечает на его основе. Для этого есть готовые библиотеки: LlamaIndex, Haystack. Они нарезают текст на куски, превращают в векторы, ищут по ним. На демо с одним чистым PDF красиво. В жизни скан учебника превращается в мусор, ютуб-лекцию фреймворк не понимает, а из 40 источников поиск упорно возвращает куски из одного и того же.
Чтобы пользователям не мучаться решил сделать своё. Источники загружаются один раз и живут в блокноте постоянно. Система, которая сама решает, сколько контекста отдать модели из каждого источника. Плюс инсайты, заметки, флешкарточки, из RAG-фреймворка ты этого не получишь.
Как это выглядит для пользователя
База это блокноты. Блокнот это проект, например: «Курсовая по нейробиологии», «Подготовка к ЕГЭ», «Анализ конкурентов». Внутри уже идут источники, чат, заметки и карточки. Загрузил материалы один раз и они живут там постоянно. Через месяц открываешь, добавляешь новую статью к старым двадцати, задаёшь вопрос, Julia видит всё сразу. Не нужно каждый раз начинать с нуля.
Источники это всё, всю информацию нейронка берёт именно оттуда, не хватя мусор из своего контекста. PDF, статья по ссылке, ютуб-лекция, скан конспекта, текст из буфера обмена. Julia сама извлекает текст, делает саммари и разбивает на фрагменты для поиска.
Чат - задаёшь вопрос по своим документам, получаешь ответ с привязкой к конкретным источникам, без галлюцинаций и прочего слопа.. Из того, что ты загрузил, это важно.
Архитектура
Архитектурно всё выглядит так: Nuxt.js на фронтенде, FastAPI на бэке, SurrealDB как основная база, и несколько вспомогательных сервисов в Docker Compose.
SurrealDB наверное, самое неочевидное решение. Это мультимодальная база: реляционные таблицы, граф-связи между записями и встроенный векторный поиск всё в одном движке, что мягко говоря привлекает. Можно спорить, насколько это зрелое решение, но для моего случая это убирает необходимость держать отдельно Postgres + Redis + Pinecone. Один сервис вместо трёх явно проще деплоить и дешевле поддерживать.
Что происходит при загрузке источника
Пользователь нажимает «Добавить источник» и выбирает один из вариантов: вставить ссылку, загрузить файл или вставить текст. За кулисами запускается пайплайн из нескольких стадий.
Обработка очереди
Первое, что мы поняли на раннем этапе: обработку нельзя делать синхронно. Если пользователь загружает PDF на 200 страниц, парсинг и векторизация могут занять 30-40 секунд. Держать HTTP-соединение открытым столько времени плохая идея: таймауты, обрывы, и пользователь смотрит на спиннер, не понимая, что происходит.
Поэтому у нас два режима. Для мелких источников (короткий текст, ссылка на статью) синхронная обработка, ответ за 5-10 секунд. Для тяжёлых файлов асинхронный режим: API мгновенно возвращает command_id, источник появляется в блокноте со статусом «Обработка…», а фронтенд поллит статус раз в пару секунд.
Для очереди задач мы написали свой фреймворк поверх SurrealDB. Да, можно было взять Celery или RQ, но это ещё один Redis в стеке, ещё один процесс для мониторинга. Наш вариант хранит задачи прямо в базе данных: с ретраями (до 5 попыток), экспоненциальным бэкоффом и отслеживанием прогресса. Не самое масштабируемое решение в мире, но для нашей нагрузки работает.
Извлечение текста: каскад фолбэков
Здесь начинается самое интересное. Тип источника определяет, какой путь извлечения текста будет использоваться. И для каждого типа у нас не один метод, а каскад с фолбэками если основной способ ломается, автоматически включается запасной.
PDF и документы. Основной парсер Docling через нашу обёртку content_core. Docling хорошо справляется со структурой: заголовки, таблицы, списки всё это превращается в чистый Markdown. Для экзотики вроде PPTX или XLSX подключается Gotenberg - headless LibreOffice, который конвертирует почти что угодно.
YouTube. Вот тут был ад. YouTube активно борется с ботами, и каждый месяц что-нибудь ломается. Поэтому тут три уровня:
youtube-transcript-api запрашивает официальные субтитры. Работает быстро и надёжно, но только если у видео есть субтитры. Мы настроили цепочку языков: сначала русские, потом английские, потом испанские и португальские (для академического контента часто есть).
pytubefix с флагом ANDROID-клиента когда субтитров нет. Притворяется приложением YouTube на Android, что снижает шанс блокировки.
Firecrawl или Jina крайний случай, когда всё остальное сломалось.
Каждые пару месяцев YouTube меняет что-то в API, и один из уровней отваливается. Каскад спасает: пользователь даже не замечает, что основной путь перестал работать.
Веб-страницы. Тут аналогичная история. Playwright (headless Chromium) с полным JS-рендерингом - основной вариант. Мы рандомизируем User-Agent, viewport, подменяем navigator без этого половина сайтов отдаёт капчу или пустую страницу. Текст вытаскиваем через readability (тот же алгоритм, что Firefox использует в режиме чтения). Если Playwright не справляется, то Jinja Reader, потом простой HTTP. Опять каскад.
Изображения. Сканы и фото отправляются в vision-модель как base64. Не самый быстрый OCR, но работает с рукописным текстом и кривыми сканами хорошо.
Векторизация: нарезка, эмбеддинги и грабли
После извлечения текста нужно подготовить его для семантического поиска. Это отдельная фоновая задача vectorize_source.
Нарезка на чанки
Текст разбивается на фрагменты по ~500 токенов с перекрытием в 15%. Звучит просто, но на самом деле штука сложнее, наш сплиттер пробует разделители по приоритету: сначала двойные переносы строки (границы абзацев), потом одинарные, потом точки, запятые, пробелы. Чтобы чанк не заканчивался на середине предложения.
Почему 500 токенов? Маленькие чанки (100-200 токенов) дают лучшую точность поиска, но теряют контекст. Большие (1000+) наоборот. 500 эмпирически выбранная золотая середина для наших сценариев использования: научные статьи, конспекты, длинные лонгриды.
Четыре стратегии поиска
Когда модель вызывает инструмент search_sources, внутри запускаются четыре стратегии параллельно:
Vector search семантический поиск по эмбеддингам чанков. Находит по смыслу, даже если слова не совпадают. Запрос «проблемы со сном» найдёт чанк про «нарушения циркадных ритмов».
Text search классический BM25 по полному тексту. Находит точные совпадения ключевых слов.
Title search полнотекстовый поиск по заголовкам. Быстрый способ найти нужный источник, если пользователь примерно знает, откуда информация.
Insight search поиск по саммари и инсайтам. Полезен, когда трансформация уже выделила ключевые тезисы и они содержат ответ.
Результаты дедуплицируются: если три стратегии нашли один и тот же источник это сильный сигнал релевантности. Скор бустится на +0.05 за каждое дополнительное «попадание». Модели возвращаются топ-5 результатов.
Почему четыре стратегии, а не одна? Потому что ни одна стратегия не работает идеально для всех типов запросов. Vector search отлично находит семантически близкое, но может пропустить точное совпадение термина. BM25 наоборот. Комбинация четырёх подходов покрывает больше случаев, чем любой из них по отдельности.
Бюджет контекста: как не взорвать окно модели
Это та часть, которой не было ни в одном туториале по RAG, и которую нам пришлось придумывать самим.
Проблема: модель нашла 5 релевантных источников, но каждый по 100 страниц. Отдать всё? Не влезет в контекст. Отдать по чанку? Потеряем информацию. Мы решили через систему бюджетов.
Общий бюджет на один запрос 300 000 символов (примерно 75K токенов). Для каждого источника минимум 5 000 символов (даже если бюджет почти исчерпан) и максимум 40 000.
Дальше три сценария:
Источник короткий отдаём целиком. Простой случай.
Источник длинный, но запрос известен отдаём инсайты + релевантные чанки. Для этого ещё раз запускаем vector search, но уже внутри конкретного источника, с низким порогом (cosine similarity ≥ 0.15). Получаются самые релевантные фрагменты из длинного документа.
Источник длинный, запрос неизвестен отдаём инсайты + начало текста. Не идеально, но лучше, чем ничего.
Эта система позволяет работать с книгами на сотни страниц без того, чтобы модель захлебнулась контекстом.
Флешкарточки и интервальное повторение
Отдельная подсистема, которая мне нравится: генерация флешкарточек из источников с полноценным интервальным повторением.
Работает так: пользователь выбирает источники или заметки, указывает количество карточек и модель генерирует пары «вопрос-ответ». Один факт - одна карточка. Формат строгий: JSON, каждая карточка валидируется.
Но генерация это полдела. Важнее то, что происходит после. Каждая карточка живёт в системе FSRS (Free Spaced Repetition Scheduler) это тот же алгоритм, что используют Anki-подобные приложения, но более современная реализация. Карточка запоминает свою «стабильность», «сложность» и «состояние» (новая, изучается, повторяется, переучивается). При каждом повторении пользователь ставит оценку от 1 до 4, и алгоритм пересчитывает, когда показать карточку снова.
Зачем мы это сделали, а не интегрировались с Anki? Потому что убирает шаг. Пользователь читает исследование в JuliaLM, тут же генерирует карточки и тут же их учит. Не нужно экспортировать, импортировать, переключаться между приложениями.
Поиск по базе знаний
Помимо RAG в чате, у нас есть отдельный поиск. Два режима: полнотекстовый (BM25 через встроенную функцию SurrealDB) и семантический (vector search по эмбеддингам).
Но есть и третий вариант «Спросить базу знаний». Это отдельный LangGraph-граф, который работает хитрее:
Модель анализирует вопрос и генерирует стратегию: до 5 поисковых запросов, каждый с инструкцией что именно искать и на что обращать внимание.
Все запросы выполняются параллельно, каждый возвращает до 10 результатов.
Для каждого набора результатов модель формулирует промежуточный ответ.
Финальная модель синтезирует всё в один связный ответ.
Звучит как overkill, но для сложных вопросов (типа «в чём авторы моих источников расходятся по теме X?») это даёт заметно лучшие результаты, чем одноходовый поиск.
Планы и квоты
Тарификация один из самых неочевидных инженерных челленджей. У нас три плана: Free (0₽, 20 промптов за всю жизнь аккаунта), Pro (799₽/мес, 800 промптов за 5-часовое окно), Business (1199₽/мес, 2000 промптов).
Ключевое решение скользящее 5-часовое окно вместо дневного или месячного лимита. Почему? Студенты. Типичный паттерн использования: человек садится за подготовку к экзамену и за один вечер делает 50-100 запросов, а потом неделю не заходит. Месячный лимит в 800 промптов при таком паттерне ощущается щедрым. Дневной лимит в 26 (800/30) ощущается жёстким. Пятичасовое окно компромисс: бустишь как хочешь, но не можешь утилизировать весь лимит за час и всё жди следующего окна.
Перед каждым вызовом LLM проверяется квота. Если подписка истекла автоматический даунгрейд на Free. Без сюрпризов, без скрытых списаний.
Что в итоге?
JuliaLM не обёртка над ChatGPT мы используем MiniMax. Это система с собственным пайплайном обработки, четырёхстратегийным RAG, бюджетированием контекста и интервальным повторением. Не всё идеально, YouTube периодически ломает транскрипцию, а SurrealDB пока не Postgres по зрелости. Но уже справляется с большим скопом задач.
Вопрос обучения LLM с нуля (pre-training) не освещен в достаточной мере на русском языке. За один последний год в открытом доступе появились блестящие результаты исследований в этой области и обучение своей собственной LLM - не SFT-файнтюнинг уже предобученных весов - уже почти доступная для средней технической компании и, безусловно, заманчивая идея. Для старта обучения было бы достаточно, например, 64 x H200, то есть всего 8 нод с 8-карточной конфигурацией. Тем большим упущением выглядит отсутствие статьи с практическими шагами осуществления этой идеи.
Я решил по мере возможности заполнить этот пробел и не только собрал актуальные датасеты для pre-training в этой статье, но и сделал ее чуть более основательным пособием для обучения LLM на с нуля на большом корпусе данных, постаравшись внести ясность, в чем на самом деле состоит смысл данных при обучении.
Надеюсь, к концу статьи само обучение будет выглядеть менее магическим и роль данных в этом процессе станет более понятной.
Начнем с того, что более-менее известно каждому - все современные LLM обучены на гигантских объемах данных, триллионы токенов текста. Часто можно услышать мнение, что OpenAI обучают свои модели на данных "всего интернета", хотя это нельзя воспринимать буквально. Корпусы для обучения моделей статистически приближаются к описанию множества данных всего интернета, но не являются этим множеством в полном объеме. В этом утверждении кроется корень главной ошибки, которую многие делают, представляя себе обучение нейросети.
Я часто слышал: "хочу обучить модель, чтобы она запомнила вот этот список книг от начала до конца", "как обучить нейросеть полной документации по языку программирования X?".
Заблуждение №1
"Нейросеть запоминает текст из моего датасета" - целые предложения, страницы и так далее. Давайте сразу его разрушим, чтобы больше к этой ошибке не возвращаться.
Цель обучения языковой модели - не текст, а знания, представленные текстом.
Для сравнения, база данных является механизмом, и очень хорошим, для хранения текста в данной конкретной форме. При этом база данных ничего не знает о том, что в тексте говорится. Нейросеть, не имеющая ничего общего с базами данных, является "механизмом" изучения именно того, что означает текст, но практически бесполезна для хранения исходного текста в его полном объеме. Т.е. это машина для понимания данных, хранить которые следует в другом месте.
Объясняется это тем, что в процессе обучения LLM моделирует статистику нашего набора текстовых данных, и больше ничего. Это делали все языковые модели, начиная с простейшей биграммной, которая могла посчитать частоту всех биграмм (пар) токенов в наборе и на основании того, что биграмма "по" (предположим для простоты, что словарь модели - буквенный) встречается чаще, чем "пц", предсказать следующий токен "о" с большей вероятностью, чем "ц", если предыдущий токен - "п". Самая простая статистика. А трансформеры, несмотря на их сложность, концептуально эксплуатируют ту же N-gram идею, моделируя P(next_token | context).
Но есть важное различие.
Заблуждение №2
"Нейросеть запоминает таблицу вероятностей для каждого токена из словаря при всех контекстах из набора". N-граммные модели делали именно это до тех пор, пока N не становилось слишком большим (очень быстро, потому что таблица вероятностей при увеличении N растет экспоненциально).
Трансформер не может запомнить таблицу вероятностей, так как в его случае для вариантов сочетаний next_token | context не существует известного нам числа, через которое можно было бы выразить множество этих вариантов. Т.е. настоящего (истинного) вероятностного распределения данных нейросеть тоже не знает. То, чему она действительно обучается - это функция, приближенно моделирующая это распределение; аппроксимация. Точным это приближение, как следует из сказанного, быть не может.
Все, что нам остается, это сделать его удовлетворительным для нашей задачи - например, генерации текста на русском языке; на интересующем нас участке распределения - например, в области (домене) советов по здоровому питанию. И если нейросеть, обученная на наборе адекватных документов по здоровому питанию, не рекомендует с утра принимать натощак ложку стрихнина, то о некоторой степени аппроксимации мы можем говорить - остается множество итераций обучения и валидаций на соответствие тестовым данным.
Но мы слишком быстро коснулись понятий домена знаний и следования инструкциям. Сначала модели научиться бы генерировать что-то кроме "ааааа333333!%;" - то есть изучить синтаксические признаки, семантику языковых конструкций, их структуру и логику. И это тоже слишком большой шаг вперед от N-gram моделей, где признаков всего ничего и все они явные (explicit), основанные на чисто внешних особенностях текста:
предыдущие k токенов
их частоты
вероятности переходов к следующему токену от k предыдущих.
Однако уже по этому короткому списку вы можете заметить, что мы не программируем модель учить те или иные признаки, а другие - не учить. Модель приходит к ним сама от статистики, потому что 1. в данных эти признаки проявляются через распределение и 2. архитектура модели позволяет учить именно эти признаки.
Если модель биграммная, в ее функции аппроксимации P(xn∣xn−1) существует признак предыдущего токена, только одного, и признак частоты тех или иных биграмм. Если она 5-граммная, то архитектура "открывает" признак уже четырех предыдущих токенов, и это, в свою очередь, может выявить новые вероятностные признаки в данных, которые невозможно увидеть на уровне биграмм. Математически можно сказать, что признаки определяются функцией от трех переменных - архитектуры, данных и цели обучения, выраженной через функцию потерь, которая определяет, какие признаки существенны для правильной аппроксимации, а какие нет.
А нейросети пошли намного дальше! От явных признаков, которые в N-граммной модели представлены V^k-размерной матрицей, где V - размер словаря, они перешли к латентным признакам, которые являются абстракцией над явными и поэтому могут быть приведены к тензору меньшей размерности, чем V^k - ведь такая размерность, как уже было показано, при чуть большем контексте k уже слишком велика для наших вычислительных возможностей. Я имею в виду V x d-размерный embedding-вектор, который способен вместить d латентных признаков. При современных внушительных контекстах kVd - это все-таки очень много, но уже реально для обучения.
В общем, нейросеть - это такое математическое выражение, цель которого - выразить как можно больше полезных признаков из данных. Теперь, когда у нас есть некоторое представление о том, что вообще мы будем делать с данными, мы можем перейти к вопросу, что эти данные должны из себя представлять.
Прежде всего, данные должны быть статистически репрезентативными. Как следует из приведенного выше интуитивного объяснения основ representation learning - обучения признакам, чтобы модель научилась признакам, они должны быть выражены статистически в обучающем наборе. Но что это значит? Давайте посмотрим на эволюцию открытых датасетов.
CommonCrawl
Мы уже поняли, что устойчивого статистического моделирования нужных нам признаков ВСЕ данные модели видеть не нужно, как не нужно прочитать всю существующую в мире английскую литературу, чтобы научиться читать по-английски. Однако, если вы все-таки хотите "весь интернет" - почти - то вот он. 10 петабайт нефильтрованных веб-данных, собранных начиная с 2008 года. Использовать эти данные для обучения полностью практически невозможно, поэтому разработчики обычно выбирают из CommonCrawl подходящие для них сабсеты.
В плане покрытия CommonCrawl - однозначный победитель в нашем списке, а высокое покрытие - необходимое условие при обучении базовой foundation модели. Опять-таки, нельзя научить модель ответам на любой вопрос, чем шире область ее применения - тем больше неизбежных пробелов в изученном распределении данных, но чем оно разнообразнее и чем больше включает понятий - точек в векторном пространстве - тем проще модели будет правильно заполнить недостающие точки между ними, то есть - тем выше ее способность интерполировать.
Это очень важно для того, чтобы модель могла правильно выполнять совершенно новые для нее задачи, и не в последнюю очередь - для ее пригодности к ризонингу. Иначе как масштабированием - самой модели и датасета - пока эту проблему не решить.
Самое, пожалуй, известное и громкое проявление этого эффекта от обучения на данных масштаба CommonCrawl описано в статье о GPT-3 - "Language Models are Few-Shot Learners". Тогда разработчики просто опытным путем обнаружили, что способность модели интерполировать известные ей знания на новые примеры эволюционировала настолько, что она стала успешно выполнять инструкции по нескольким примерам из промпта - few-shot, и это стало предпосылкой для ChatGPT и всех генеративных языковых моделей, предназначенных для именно таких задач.
Однако мы помним и крупный недостаток GPT-3, ее подверженность галлюцинациям. Это связано с шумностью данных CommonCrawl, так как этот набор содержит огромное количество (до 50% в нефильтрованном виде) веб-страниц низкого качества. SEO-тексты, где полно "воды", спам и бесконечные дубликаты. Это все плохо сказывается на reasoning-способностях модели и способствует оверфиттингу на тех паттернах текста, у которых в датасете слишком много дубликатов. Поэтому данные из CommonCrawl всегда тщательно фильтруют, и так появился следующий кандидат в этом списке.
FineWeb
Есть замечательная опция - воспользоваться уже готовым, фильтрованным CommonCrawl, то есть FineWeb. Это 15 триллионов токенов достаточно чистых данных. Эффективность обучения на FineWeb гораздо выше, поэтому в большинстве случаев его стоит выбирать как дефолтный базовый датасет для обучения - кому хочется выбрасывать сотни GPU-часов на ветер, пока модель молотит терабайты SEO-мусора и вытаскивает из них редкие полезные признаки?
Т.е. существенно уменьшив объем данных и сэкономив на обучении, мы получим модель, более устойчивую к галлюцинациям и с более сильными способностями к ризонингу. Это замечательно. И все-таки фильтрация - зло, хотя и неизбежное. Редкие признаки, полнота знаний и непредвзятость модели страдают от этого.
Поэтому надо, что называется, оптимизировать распределение признаков - постараться добавить в набор столько разнообразия, сколько нужно. Например, сейчас пользуются спросом модели с хорошими навыками кодинга, математики и в целом научных знаний.
Поэтому актуальная идея - дополнить ваш дата-пайплайн наборами специально для кодинга, математики и тех доменов, в которых ваша модель должна быть сильна. А как понять, что вот такое количество и соотношение наборов и разных доменов хорошее, а такое - не очень? Здесь начинается время трудоемких экспериментов, когда вы обучаете несколько небольших моделей на нескольких вариантах данных, потом прогоняете их все по самым разным бенчмаркам. И так выявляется тот срез данных, который вам действительно нужен. Но все-таки было бы жаль, если бы мы на остановились на этом подходе - вручную, на глаз пытаться создать действительно хорошее распределение признаков. Есть пример более умного решения проблемы - конечно, с помощью ML - показавший очень хорошие результаты.
ClimbMix
Из сказанного выше уже понятно, что качество и состав данных часто важнее их объёма. Один из подходов, развивающих эту идею — фреймворк кластеризации данных CLIMB от NVIDIA. С его помощью создан набор ClimbMix, основанный на методе оптимизации смеси обучающих данных (data mixture optimization), направленный на максимизацию полезных статистических признаков в датасете.
Основная идея ClimbMix - не просто собрать много данных, а подобрать такое соотношение доменов, которое максимизирует обучение полезных представлений. Обычный pretraining датасет, включая два уже перечисленных, представляет собой смесь различных источников: web-тексты, код, научные статьи, книги, диалоги, форумы. Проблема в том, что разные источники обучают разные способности модели.
Можете представить в качестве интуитивного примера такую таблицу:
Тип данных Какие признаки формируются
Веб общая языковая статистика
Код строгая логика и синтаксис
Math reasoning паттерны
Книги длинный контекст
QA instruction following
Если распределение выбрано плохо, некоторые признаки переобучаются, другие почти не представлены - возникает неэффективное использование токенов. Это можно сформулировать так: неоптимальная смесь данных приводит к неоптимальному распределению признаков в representation space модели. Естественно, хорошо бы это representation space как-то проанализировать, поэтому первым делом метод преобразует тексты в embeddings с помощью небольшой модели. После этого данные кластеризуются по тематике, стилю, сложности, типу reasoning. То, что мы имеем в итоге - это набор семантических доменов, которые описывают карту пространства признаков для обучения. Далее обучается небольшая прокси-модель на разных смесях этих кластеров.
Например, микс A - 40% веб, 20% код, 20% книги, 20% академические тексты, микс B - процентное соотношение меняется, а книги, скажем, заменяем на QA. Затем для всех оцениваем validation loss, downstream performance, training efficiency. Читайте подробнее в статье - Nemotron-CLIMB: CLustering-based Iterative Data Mixture Bootstrapping for Language Model Pre-training. Таким образом находим, какой микс дает наилучший обучающий сигнал.
Преимущество подхода ClimbMix уже показало себя на практическом обучении моделей, так как оно следует из верного понимания разработчиками фундаментального принципа, который проходит через эту статью красной нитью - LLM обучаются не на данных, а на статистических вариациях внутри данных. Именно их в ClimbMix попытались автоматически сбалансировать и построить по-настроящему эффективный датасет - осталось обучить на нем модель и проверить, насколько у них получилось.
Надеюсь, эта статья помогает систематизировать отрывочные сведения о механике обучения нейросетей на текстовых данных и о скрытых особенностях этого процесса. Есть ощущение, что многое осталось недосказанным, и на случай, если у вас возникли вопросы и пожелания, я буду рад вашей обратной связи в моем телеграм-сообществе.
Я основатель Hooppy - сервиса автопостинга, через который работает более 5 000 Telegram-каналов. Это даёт доступ к реальной статистике изнутри: частоте публикаций, источникам контента и реакции аудитории в первые часы после выхода постов. На такой выборке хорошо видно, какие инструменты и подходы действительно дают рост, а какие не влияют на динамику, несмотря на популярность.
Ниже - суть из аналитики: конкретные механики и рабочие решения, которые напрямую влияют на рост Telegram-канала.
Что такое парсинг и зачем он нужен
Парсинг - это автоматический сбор постов из чужих каналов по заданным параметрам. Вы подключаете источники: каналы конкурентов, смежные ниши, крупные паблики в Instagram, Telegram, ВКонтакте и других соцсетях. Система мониторит их на фоне и каждый день выдаёт список постов, отсортированных по охвату за последние 24-48 часов. Вы видите только то, что реально зашло аудитории - без ручного скроллинга и догадок.
Это не про «утащить чужой контент» - это про работу с уже подтвержденным спросом. Увидели пост, который резко рванул по цифрам - адаптировали под свою аудиторию и опубликовали (2-3 минуты работы). Именно так растут каналы, которые не придумывают темы с нуля, а используют данные.
Конкретный пример:
Пост IGN в Instagram про отсылки к комиксам в трейлере «Человек-паук: Новый день» резко пошёл в рост - почти 90 000 лайков, сотни комментариев и тысячи репостов. Мой сервис Hooppy сам зафиксировал всплеск, подтянул пост и без моего участия опубликовал его в Telegram-канал.
Пост в Инстаграме
Результат: почти 42 000 просмотров. Спустя 4 дня после публикации поста в моём Telegram - канале.
Результат в Телеграме
Никакой магии - всё сработало автоматически через Hooppy. Сервис сам нашел релевантный пост, сделал рерайт с английского на русский и сразу адаптировал текст под стиль моего канала, после чего обработал и опубликовал его без моего участия.
В этом и есть суть парсинга: использовать то, что уже доказало свою эффективность, и масштабировать результат.
Как я использую парсинг: от чужого контента до готового поста
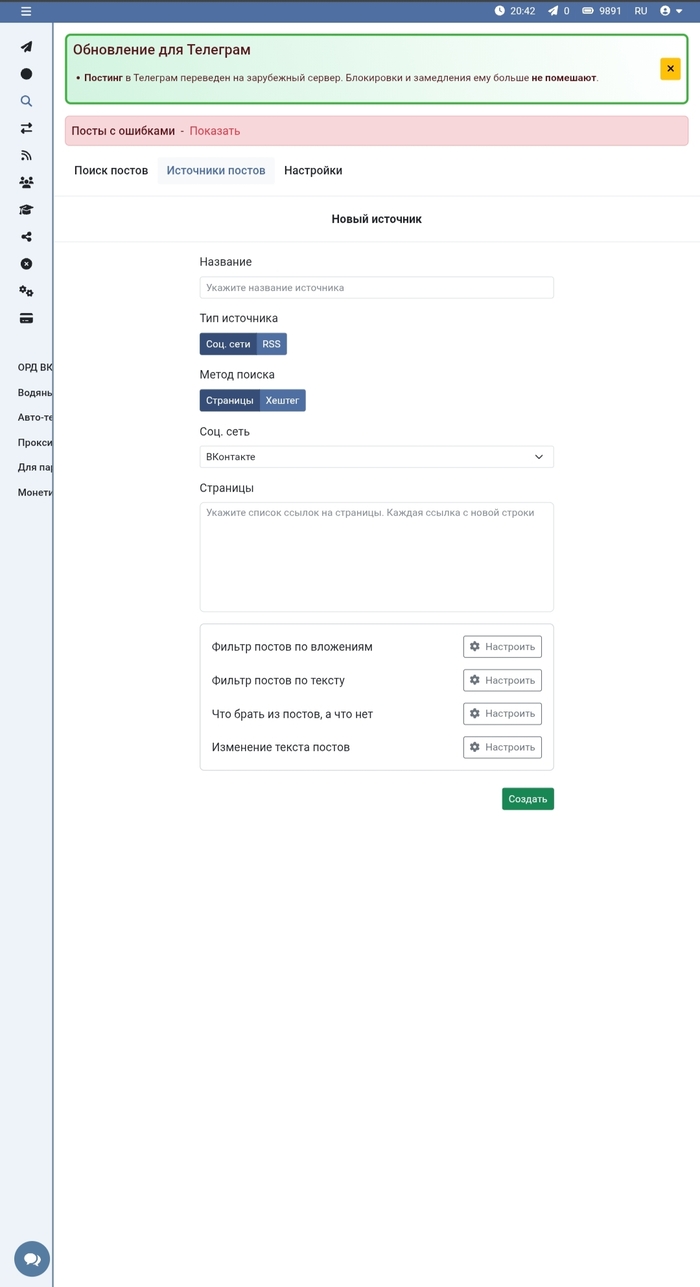
Всё начинается с настройки источников. Я указываю конкретные страницы, которые хочу мониторить, выбираю соцсеть и метод поиска - по страницам или хештегам. Здесь же сразу выставляю фильтры: какие типы вложений брать, что игнорировать в тексте, как обрабатывать материал перед публикацией.
Настройка источника в Hooppy
После этого открывается лента. Все посты собраны в одном месте, рядом с каждым сразу видна статистика: лайки, комментарии, просмотры. Именно здесь я нашёл тот самый пост IGN - после сортировки по лайкам он сразу оказался наверху и бросился в глаза.
Лента найденных постов
Дальше - открывается редактор. Текст и все медиафайлы уже подгружены. Я выбираю площадки для публикации - в моём случае Telegram и Instagram одновременно - и при желании ставлю отложенное время.
Окно копирования поста
Но публиковать оригинальный англоязычный текст в русскоязычный канал - плохая идея. Здесь в дело вступает встроенный ИИ.
Я просто прогоняю пост через встроенный ИИ прямо в редакторе: он переписывает текст под мой стиль, переводит и делает его живым. На это уходит полминуты - на выходе уже готовый, нормальный текст под мою площадку,
ИИ-редактор с запросом
Кроме перевода и рерайта, ИИ умеет сокращать или расширять текст, добавлять хештеги, смайлы, а также разбивать на абзацы.
Весь процесс - от момента, когда я увидел пост в ленте, до нажатия кнопки «Опубликовать» - занимает меньше трёх минут.
Как выбирать источники для парсинга
Ошибка большинства каналов - без разбора добавлять в мониторинг конкурентов, крупные каналы и случайные популярные аккаунты, а дальше надеяться, что система сама начнет приносить сильные темы. На практике так не работает. Парсинг дает результат только тогда, когда у вас правильно собрана база источников. Иначе в ленте будет либо мусор, либо контент, который уже везде разошелся.
Первое, на что стоит смотреть, - близка ли динамика канала к вашей. Миллионники здесь плохой ориентир: у них другая аудитория, другой уровень доверия и совсем иной масштаб охватов. То, что хорошо заходит у них, у небольшого или среднего канала может не сработать вообще. Поэтому лучше брать источники в 5-15 раз крупнее своего. Если у вас 1 000 подписчиков, ориентируйтесь на каналы с 10-20 тысячами и стабильными просмотрами. Это ближе к вашей реальности.
Вторая важная вещь - фильтр по просмотрам. Без него парсинг быстро превращается в свалку. Вы начинаете видеть всё подряд: проходные посты, случайные публикации, слабые форматы, которые ничего не дали даже у первоисточника. Чтобы искать вирусный контент, нужен не просто поток постов, а отбор по реакции аудитории. Но здесь нельзя ставить один и тот же порог для всех.
Если у вас новостной канал, логика одна: скорость важнее доказанного охвата. В новостях не всегда есть смысл ждать, пока пост наберёт просмотры за 24 или 48 часов. Пока вы дождетесь подтверждения, тема уже устареет. Поэтому для новостных каналов важнее фильтр по свежести: здесь решает скорость, а не охват.
Если канал нишевой - про инвестиции, маркетинг, недвижимость, технологии или бизнес, - важен уже не темп, а подтвержденный интерес к теме.. В таких темах хорошо работают посты, которые за первые сутки собирают уверенный охват. Это показывает, что тема действительно зацепила аудиторию
В случае с авторскими каналами одних цифр по просмотрам уже мало. Далеко не каждый популярный пост можно переносить в свой формат. В авторских каналах важен не только сам инфоповод, но и подача, позиция, тон, конфликт, личность автора. Поэтому здесь нужно смотреть не просто на просмотры, а на то, какие темы вызывают сильный отклик именно как мнение. Иначе можно взять тему, но не понять, за счёт чего она сработала.
Отсюда вытекает ещё одна ошибка - мониторить только прямых конкурентов. Когда все смотрят друг на друга, в ход идут уже пережеванные темы. Сильные темы чаще приходят не напрямую из вашей ниши, а из смежных направлений. Канал про инвестиции часто находит удачные темы не только в инвестиционных пабликах, но и в бизнесе, стартапах, макроэкономике, личных финансах, психологии денег. Канал про маркетинг - в e-commerce, продажах, продукте, медиа и founder-контенте. Канал про медиа или Telegram - в creator economy, YouTube, Instagram, digital-рекламе и платформах монетизации. Смежные ниши часто дают тему раньше, чем она становится мейнстримом именно в вашей категории.
Отдельно стоит сказать про иностранные источники. Англоязычный сегмент часто отрабатывает тему раньше: сначала она вспыхивает в Twitter, Instagram, Reddit, LinkedIn или YouTube Shorts, потом доходит до локальных Telegram-каналов, и только после этого начинается массовое копирование в русскоязычном сегменте. Разница не всегда огромная, но даже 7-14 дней форы уже дают преимущество. За это время можно не просто переписать чужую тему, а первым адаптировать её под свою аудиторию и собрать основной охват до того, как рынок перегреется.
Но здесь важно понимать разницу между “источник популярный” и “источник полезный”. Полезный источник - это не тот, где много подписчиков. Это тот, откуда регулярно проходят посты, которые соответствуют вашим фильтрам и реально дают идеи. Если канал выглядит крупным, но за неделю не дал ни одного годного сигнала, он бесполезен. Если небольшой источник стабильно приносит сильные темы, он ценнее десятка распиаренных пабликов.
Поэтому база источников - это не разовая настройка, а постоянная работа. Каналы выгорают, меняют тему, теряют темп и со временем перестают давать сильный контент. (Их нужно регулярно пересматривать.) Смотрите не на подписчиков, а на последние 10 постов. Если просмотры стабильные и через фильтр регулярно что-то проходит, источник оставляете. Если охваты скачут, контент просел или за две недели не было ничего полезного - удаляете и ищете замену.
Именно здесь многие и просаживают парсинг. Один раз собирают базу и потом месяцами в нее не заходят. В результате мёртвых источников становится всё больше, а сильных сигналов - всё меньше. Рабочий подход простой: раз в месяц проходиться по базе и убирать всё, что больше не даёт результат.
Для большинства каналов рабочая схема такая: собираете 20-40 источников, смешиваете прямую нишу, смежные темы и иностранные аккаунты, ставите нужные фильтры и раз в месяц чистите базу. Тогда парсинг начинает приносить не просто чужие посты, а темы, которые уже пошли в рост или только начинают разгоняться.
Например, если канал про инвестиции следит только за другими инвестиционными каналами, он почти всегда приходит к теме поздно. К этому моменту её уже обсудили и разогнали. Другая картина - когда в источниках есть не только своя ниша, но и бизнес, макроэкономика, финтех, личные финансы и англоязычные аккаунты. Тогда тему можно заметить на раннем этапе, когда она только начинает повторяться в смежных источниках.
В этом и разница: сильный парсинг ищет не просто популярные посты, а ранние сигналы. Выигрывает не тот, у кого больше источников, а тот, кто понимает, какие из них действительно двигают тему вперёд.
Как адаптировать чужой пост, не нарушая авторских прав
Это важный момент, который многие игнорируют.
Копипаст – это нарушение авторских прав и быстрый бан. Адаптация – нормальная практика, которой пользуются все медиа без исключения.
Что значит адаптировать:
Переписать своими словами
Добавить собственный комментарий или кейс
Сменить угол подачи под свою аудиторию
Добавить актуальный контекст
Именно для этого я встроил в свой сервис Hooppy рерайт через ИИ. Нашел пост в ленте парсинга - нажал одну кнопку - ИИ переписал текст за 30 секунд. Я добавляю 2-3 предложения от себя, и пост готов к публикации прямо оттуда же. Итого: 2-3 минуты против 20-30 при работе руками.
Кросспостинг: почему один пост должен выходить везде
Telegram - отличная точка старта. Но если публиковать только там, вы упускаете площадки, которые могут давать такой же или даже больший объём трафика.
Смысл простой: один и тот же пост должен появляться сразу в нескольких местах - ВКонтакте, Instagram, YouTube. Речь не о том, чтобы делать больше контента - а о том, чтобы выжать максимум из уже готового.
Проверяется быстро. Пока пост выходит только в Telegram - охват ограничен одной платформой. Как только он начинает автоматически дублироваться в другие соцсети - общий охват растет, без дополнительной работы.
С видео это еще заметнее. С помощью Hooppy один короткий ролик можно сразу отправлять в Shorts, Reels и клипы, и он начинает жить сразу в нескольких алгоритмах. (Настройка делается один раз.)
5 шагов к росту показателей вашего Telegram канала
1. Найдите каналы конкурентов крупнее вашего. Подключите их в Hooppy как источники для мониторинга. Не изобретайте велосипед - берите то, что уже набрало просмотры у других.
2. Настройте парсинг с порогом просмотров Только посты, которые зашли аудитории. Всё остальное поможет отсечь Hooppy.
3. Кросспостинг на все площадки Один пост - ВК, Telegram, Instagram. Охват в три раза больше.
4. Два поста в день в одно время.
5. Три недели не меняйте ничего. Алгоритму необходим ритм.
Почему Telegram-канал стоит на месте
По опыту анализа каналов: большинство буксует из-за одного - контент каждый раз делают с нуля. Это быстро выматывает, появляются паузы, и канал теряет темп.
У Telegram нет отдельной «оценки качества текста». Алгоритмы смотрят на базовые сигналы:
регулярность публикаций
реакцию аудитории в первые 2–3 часа
Если канал несколько дней молчит, а потом вываливает серию постов - это выглядит как нестабильность. В итоге охваты проседают, даже если контент хороший.
Это одна из функций Hooppy - дальше всё сводится к контролю и масштабу
Помимо этого, в Hooppy доступны расписание публикаций, RSS, геометки для ВК, Instagram и Facebook, а также генерация постов через ИИ. Отдельно отмечу DeepSeek - выбор сделан на основе сравнения. Почему он, а не ChatGPT или Gemini - уже разобрал в прошлой статье. И ещё ряд инструментов, о которых не стал расписывать. Это уже не про базовые функции, а про системный рост. Такие вещи становятся понятны только в работе.
Сюда приходят не за «попробовать». Подключаются те, кому нужны точные данные, скорость и инструменты без ограничений - владельцы каналов и проектов, которые считают метрики и выстраивают рост. И таких пользователей с каждым месяцем становится больше.
Если вы здесь - значит, вы не просто смотрите, а ищете решение. Можете посмотреть это в работе на hooppy.ru - базовая настройка занимает около 15 минут.
Я давно задался одним дико неудобным вопросом, от которого наша доблестная наука технично уворачивается уже который десяток лет. Мы живем в эпоху, когда вычислительные мощности зашкаливают за все мыслимые пределы, но при этом гигантский массив теоретического знания верифицируется методами... ну, скажем мягко, из позапрошлого века. Почему итогом многолетней научной деятельности до сих пор считается пачка бумаги — статья, рукопись, набор формул в LaTeX или, прости господи, семинарский доклад? Почему это ценится выше, чем воспроизводимый, исполнимый объект проверки? С какой стати мы вообще должны верить, что истина надежно защищена фигурой рецензента? Этот бедолага в одиночку, чисто вручную, пытается удержать в голове десятки страниц зубодробительных абстракций. И мы серьезно полагаем, что он способен заметить любую, даже самую микроскопическую трещину в этой конструкции? И наконец, почему научная "элита" до сих пор смотрит на вычислительную строгость как на какое-то факультативное, хоть и полезное приложение к "настоящей" науке, а не как на её единственно возможную следующую форму?
Вот здесь-то и вскрывается реальная, дремучая отсталость современной научной культуры. И дело тут не в дефиците мозгов, талантов или отсутствии задач калибра "Нобелевки" или "Филдсовской премии". Проблема в иррациональной, почти религиозной вере в то, что текст сам по себе все еще является высшей формой математической строгости. Ребята, очнитесь: текст — штука запредельно хрупкая. Его можно банально прочитать не так. В нем элементарно пропустить тончайшую подмену условия. В нем может предательски ускользнуть вырожденный частный случай. Бумага — она ведь все стерпит, на ней очень легко спрятать то, что самому автору кажется «очевидным», а на деле является логическим провалом бездоказательного перехода. Текст умеет очаровывать, давить авторитетом, заставлять восхищаться «элегантностью», но как носитель проверяемости он давным-давно, всухую проигрывает тому, что можно задать как исполнимую и воспроизводимую структуру.
И это, кстати, давно уже не публицистический хайп и не каприз обиженных технарей. Если открыть программный доклад Национальных академий наук, инженерии и медицины США, посвященный вопросам воспроизводимости и повторяемости, там различие между просто "красивым" результатом и результатом воспроизводимым проводится железобетонно жестко. Воспроизводимость там определяется не как "ну, в принципе, похоже", а как способность получить согласованные вычислительные результаты при идентичных данных, тех же процедурах и тех же условиях анализа. Говоря русским языком: в двадцать первом веке мало накатать убедительную простыню текста. Ты обязан уметь предъявить свой результат как вычислительно повторяемый цифровой объект. Это больше не вопрос вкуса, эстетики или привычек. Это вопрос нового режима существования истины.
Именно в этом контексте мне и видится подлинный, фундаментальный смысл архитектуры GALO. Это не очередной хипстерский манифест про цифровую эпоху, а инструмент внедрения куда более жесткой дисциплины знания. GALO исходит из очень простой, почти кондовой мысли: верифицируемая часть любой теории не имеет права жить только в пространстве философского рассказа о самой себе. Она должна быть принудительно переведена в пространство жестких спецификаций, реестров, сертификационных поверхностей и исполнимых проверок. Уходим от формулировки «есть такая интересная идея» к парадигме «вот конкретный, отчуждаемый объект». Вместо лирического «кажется, тут должен выполняться закон» мы требуем «вот формальный SPEC». Вместо успокаивающего "скорее всего, все корректно" — "вот исчерпывающий прогон по всей объявленной поверхности". И если возникает сбой, он больше не тонет в красивой академической риторике. Он возвращается в виде безжалостного лога, точного свидетеля катастрофы: где именно, на каком шаге алгоритма, при каких конкретно входных данных, с каким ожидаемым и каким фактическим результатом ваша теория развалилась на куски.
Для старой академической психологии это максимально неприятный сценарий. Ведь в таком режиме знание моментально теряет значительную часть своей сословной защиты. Оно перестает обитать в тумане элитарной сложности, полунамеков и ритуального уважения к имени автора. Теория должна не просто солидно звучать на кафедре, она должна аппаратно выдерживать краш-тест. И тут внезапно всплывает неудобная правда: колоссальный объем научной власти веками держался не столько на подлинной интеллектуальной силе, сколько на банальной монополии доступа к процедуре контроля. Когда доказательство понимают всего два десятка человек на планете, это, конечно, может быть признаком гигантской глубины. Но с тем же успехом это может быть и кричащим признаком того, что сама форма упаковки результата технологически застряла в архаике.
Математики, кстати, прекрасно знают, насколько это больно. Вся недавняя история математики буквально переполнена эпизодами, когда классическая текстовая строгость ломалась под тяжестью собственной монструозной сложности. Самый громкий пример конца двадцатого века — эпопея с доказательством Великой теоремы Ферма. В 1993 году Эндрю Уайлс объявил доказательство, и мир вздрогнул от восторга — пала задача тысячелетия. А потом в рукописи обнаружился критический пробел. Потребовались годы тяжелейшей, изнурительной дополнительной работы Уайлса совместно с Ричардом Тейлором, чтобы залатать эту дыру. Финальное доказательство было опубликовано только в 1995 году в Annals of Mathematics. И суть этой истории не в пошлом выводе о том, что даже великие люди ошибаются. Она важна тем, что даже великий теоретический прорыв уже существует на самой грани человеческой способности удерживать контекст. Мы подошли к масштабам аргументации, где старая вера в то, что «рукопись все выдержит», больше не выглядит естественной.
Еще выразительнее — драма вокруг проблемы четырех красок. Когда Кеннет Аппель и Вольфганг Хакен в 1976 году заявили о доказательстве, львиная доля которого базировалась на тупом компьютерном переборе вариантов, математическое сообщество испытало настоящую метафизическую ломку. Ученые сомневались не в деталях алгоритма. Под вопрос ставился сам культурный статус такого доказательства. Можно ли вообще считать доказанным то, что живой человек физически не в состоянии обозреть целиком собственными глазами? Сегодня такие претензии звучат как жалобы луддитов, но именно поэтому они так важны. Они обнажили критическую уязвимость: математика оказалась намертво привязана к идеалу кустарного, ручного и полностью текстового контроля. Даже энциклопедия Britannica фиксирует, что машинный характер этого доказательства спровоцировал лютые споры о его приемлемости. В этом споре отчетливо слышен панический страх старой школы перед эпохой, когда проверка перестанет быть элитным ремеслом для избранных и превратится в бездушную машинную процедуру.
Эта же трещина окончательно разошлась на гипотезе Кеплера. Томас Хейлс принес доказательство, завязанное на гигантские вычисления и разбор множества частных конфигураций. Рецензенты потели над ним несколько лет и в итоге выдали совершенно жалкий вердикт: мы уверены примерно на 99 процентов. Для публикации в глянцевом научном журнале этого хватило, но сама ситуация выглядела как капитуляция. Наука формально согласилась жить в режиме "почти уверенности", просто потому, что у нее тупо не было более зрелой процедуры проверки. Именно из этого кризиса и вырос проект Flyspeck, триумфально завершенный в 2014 году, когда доказательство было формально верифицировано в системах HOL Light и Isabelle. Это железобетонный пример того, что следующая эволюционная ступень строгости — это не написание еще более заумного текста, а создание формального, аппаратно проверяемого контура доказательства. И это никакое не снижение математики, это, наоборот, ее долгожданное ужесточение.
Поэтому я и говорю, что нынешняя академическая тусовка живет в состоянии хронического институционального запаздывания. Они обложились компьютерами по самые уши, но категорически не хотят признать, что вычислительная сертификация должна стать не приложением к теории, а ее обязательным слоем везде, где объект допускает такую постановку вопроса. Ученые с удовольствием используют языки программирования, пакеты символьной алгебры, лопатят гигантские массивы данных, но как только встает вопрос о статусе самой истины, они рефлекторно бегут прятаться за фигуру рецензента, семинарские обсуждения и авторитет профильной школы. Это напоминает цивилизацию, которая уже вовсю летает на реактивных двигателях, но при этом на полном серьезе продолжает ориентироваться по медной астролябии.
Очень забавно в этом контексте перечитать Годфри Харди. В своей «Апологии математика» он не просто восхищается эстетикой чистой науки, он буквально выстраивает аристократию математического достоинства на ее оторванности от непосредственной пользы. Более того, именно он запустил в массы крылатую мысль о том, что математика — игра молодых. Харди, безусловно, велик как памятник своей эпохе, когда пиком интеллектуальной доблести считалась чистота, отрешенность и почти благородная бесполезность. Но если читать его сегодня, становится очевидно другое: этот стиль мысли вообще не отстреливает, что делать с вычислительной верификацией как с новой формой строгости. Он живет так, будто строгая наука обязана навсегда оставаться преимущественно текстовой, рукописной и умещаться в человеческой голове. Для своего времени это была высокая позиция. Для наших дней — это уже не вершина строгости, а просто исторически важный, но промежуточный этап.
С группой Бурбаки история учит ровно тому же. Это не был какой-то опереточный тайный орден, как любят сочинять журналисты. Эти французские математики проделали колоссальную работу, пересобрав изложение в жестких аксиоматических и структурных рамках. Они сформировали целую эпоху вкуса и понятийной дисциплины. Но в этом же кроется их исторический предел: Бурбаки выкрутили на максимум строгость именно математического текста, а не исполняемого машинного контракта. Их проект стал абсолютным апофеозом текстовой эпохи. Сегодня одной лишь красивой аксиоматики на бумаге критически мало. То, что для Бурбаки было вершиной дисциплины, сегодня должно стать просто стартовым слоем перед трансляцией теории в форму, допускающую исполнимую аппаратную сертификацию.
И вот тут архитектура GALO раскрывается не просто как инженерный проект, а как совершенно новая философия научной чистоплотности. Движок не торгует дешевыми чудесами и не обещает, что если закинуть в него любой вопрос, машина сама все решит. Посыл куда более зрелый: если твой объект задан на конечной, закрепленной или вычислимо исчерпываемой поверхности, твое утверждение должно пережить переезд из слов в спецификацию. Оно должно быть намертво привязано к конкретному классу, упаковано в табличный носитель и прогнано через сертификационный контур. Результат этого краш-теста должен быть воспроизводим. Прошел прогон — получаешь жестко ограниченное, но юридически железобетонное право заявить, что на данной поверхности контрпримеров нет. Случился сбой — получаешь точный лог ошибки, а не маскируешь провал академической демагогией.
Для математиков тут крайне важно понимать, что GALO не пытается подменить теорему примитивным перебором таблиц. Здесь нет дешевого триумфа в стиле «мы все перебрали, значит теорема верна». Напротив, архитектура требует двойной проверки: табличный канал обеспечивает закрепленную вычислительную поверхность истины, а формульный канал дает независимую реконструкцию. А между ними обязан стоять контролер согласованности. В этом и заключается настоящая взрослая строгость: мы не выкидываем доказательства ради таблиц, мы намертво связываем формулу и вычислимую поверхность так, чтобы одно больше не могло безнаказанно существовать в отрыве от другого.
Для инженеров же тут открывается другая сторона медали. Программисты слишком привыкли к тому, что тестирование сводится к набору удачно подогнанных примеров. В движке GALO такие фокусы не проходят. Если ты заявляешь тотальный закон для конечного пространства, он будет проверен по всей поверхности без исключений, а не по паре красивых входов. Это фундаментальная разница между обычным тестом и контрольным затвором. Затвор не тешит твою иллюзию правоты, он аппаратно перекрывает путь ложному утверждению. Он либо выплевывает точный свидетель твоего провала, либо гарантирует отсутствие ошибок на заявленной области. Это совершенно другой психологический режим работы, где спрятаться за фразой «вроде работает» уже не получится.
Вот почему я уверен, что современная наука буксует не из-за нехватки открытий, а из-за архаичной формы своего самоконтроля. Она обложилась сверхмощными машинами, но продолжает проверять себя в режиме позднего книжного века. Она производит сложнейшие теории, но слишком часто оставляет их в таком виде, где главным гарантом надежности выступает человеческая репутация. Она постоянно твердит о строгости, но слишком редко делает эту строгость аппаратно воспроизводимой. Она молится на интеллект, но панически боится момента, когда этот интеллект придется подчинить безличной процедуре сертификации. И в этом заключается ее самый главный консерватизм.
Следующий тектонический сдвиг в науке случится не там, где ученые будут произносить еще более изысканные слова про "технологическую сингулярность", "искусственный интеллект" или "новую рациональность". Революция наступит в тот момент, когда результат начнет признаваться зрелым только при условии его существования в прочной сцепке: как читаемый текст, как строгая спецификация, как реестр, как исполнимый прогон и как точный свидетель ошибки. И вот тогда старый академический строй с ужасом осознает неприятную вещь: колоссальная доля их научного величия держалась не только на истине, но и на искусственно усложненном доступе к ее проверке.
Вот почему для меня проект GALO — это не просто кусок архитектуры. Это целенаправленная попытка перекроить само распределение строгости в науке. Забрать у текста монополию на истину. Забрать у авторитетов монополию на доверие. Забрать у ритуалов монополию на признание. И перенести все это в пространство, где объект можно предъявить железу, контракт выполнить побайтово, сбой воспроизвести со стопроцентной точностью, а итоговый вывод не только сформулировать, но и аппаратно сертифицировать.
И я затеял все это не потому, что фанатично верю в восстание машин или в то, что кусок кремния научился мыслить тоньше профессора. Оставим эти наивные сказки продавцам курсов по нейросетям. Суть банальна: когда дело доходит до жесткой верификации, бездушный скрипт оказывается тупо честнее любого живого доктора наук. Алгоритму абсолютно наплевать на ваш индекс Хирша, ваши седины, количество монографий и размер государственного гранта. Он не поддается очарованию красивой презентации на симпозиуме, не кивает глубокомысленно на кафедре, делая вид, что понял вашу многоэтажную абстракцию, когда на самом деле не понял ни черта. И уж тем более он никогда не станет замазывать логическую дыру в теории из какой-то мифической «научной» солидарности или банальной жалости к уважаемому автору.
Скрипт работает как гильотина: он либо молча выплевывает в терминал контрпример, хороня дело всей вашей жизни, либо математически гарантирует отсутствие ошибок на заявленной поверхности. И если академическая наука продолжит воротить нос и откажется встраивать эту безжалостную аппаратную честность в свой фундамент, она очень быстро окончательно мутирует из передового края мысли в элитный, прекрасно финансируемый клуб по интересам. В такой уютный пыльный музей, где заслуженные старички-академики будут бесконечно пить чай, вручать друг другу медали и важно рассуждать о том, как они уже давно все на свете открыли, а "вам, молодым, осталось лишь подбирать крохи с барского стола".