
0 просмотренных постов скрыто



Nova v0.2: выкинули Ollama, собрали портативку и наконец починили память(ренейм с Astra)
Короче, за последние пару дней проект реально сильно двинулся. Если в прошлом посте я показывал набор скриптов вокруг Ollama, то сейчас это уже нормальная портативная прога, которую можно распаковать и запустить. Без танцев с бубном, без установки Python, без поднятия серверов. Просто скачал, запустил bat-файл, поговорил.
Что случилось с Ollama
Ollama был удобен на этапе прототипа, но стал реально бесить. Лишний сетевой слой, дублирование управления моделями, невозможность нормально контролировать VRAM. Короче, выкинули нафиг и перешли на прямой вызов через llama-cpp-python.
Теперь llama_client.py сам грузит .gguf файлы, сам решает сколько слоёв кинуть на GPU, и самое главное, сам выгружает модели по таймауту. Основная модель висит в памяти 10 минут, оркестратор 5 минут. Закрыл чат, ушёл по делам, через 10 минут видеопамять свободна, можешь игру запускать.
По VRAM ещё пара фишек. Квантованный KV-кэш (cache_type_k/v: q8_0) экономит полтора-два гига почти без потери качества. И выключили use_mmap, потому что на Windows это вызывало дикие фризы когда система начинала свопить на SSD.
А ещё наконец-то починили баг с заезженной пластинкой. Помните, модель могла выдать "О, ну что?" три раза подряд? Это было потому что repeat_penalty не передавался нормально. Теперь передаём repeat_penalty: 1.25 + frequency_penalty: 0.2 + presence_penalty: 0.2, и модель больше не зацикливается.
Память: от "забывает через 2 реплики" к "помнит, но не спамит"
Это была главная боль. Nova либо вообще ничего не помнила, либо вставляла факты в каждый ответ:
— Как дела?
— Помню, тебя зовут Никита, ты любишь synthwave и гранатовый чай. Как дела?
Что сделали:
Time decay в scoring памяти. Написал функцию time_decay_penalty, которая штрафует факты, упомянутые меньше 5 минут назад. Факт, который только что был в промпте, получает штраф 95% к relevance. Через 5 минут штраф обнуляется и факт снова доступен. В итоге Nova не повторяется, но и не забывает, просто использует другие факты из базы.
Динамические правила приветствия. В prompt_builder.py теперь анализируется conversation_meta.json. Если это первая реплика в сессии, можно поздороваться. Если активный диалог (меньше 5 минут с последней реплики), жёсткий запрет на "Привет!". Пауза 5-60 минут, продолжай естественно без приветствий. Долгое отсутствие (больше часа), можно сказать "с возвращением".
Оркестратор на маленькой LLM. Вынес извлечение фактов из try_save_memory в отдельный модуль orchestrator.py. Работает по двухуровневой схеме. Сначала регулярки (быстро, бесплатно, ловит 80% случаев типа "меня зовут...", "я люблю...", "а ещё..."). Если регулярки не сработали, тогда LLM с temperature: 0.0 для максимальной точности. Плюс пост-валидация: если в извлечённом факте нет ни одного слова из сообщения пользователя, отбрасываем как галлюцинацию.
Включили memory_v2 для casual-режима. Раньше в обычном small talk память вообще не подгружалась. Теперь подгружается, но лимитом в 2-3 факта + работает time_decay. Диалоги стали живее.
Портативная сборка: распаковал и запустил
Это была самая нудная часть, но самая важная. Хотел, чтобы тестерам не нужно было ставить Python, возиться с pip install, поднимать Ollama-сервер, гуглить какие CUDA-библиотеки нужны.
Что в архиве (1.2 ГБ без моделей):
install_llama_auto.bat это отдельная песня. Скрипт проверяет наличие CUDA через nvidia-smi, и в зависимости от результата ставит либо GPU-сборку llama-cpp-python, либо CPU-версию. Пользователю не нужно выбирать, всё происходит автоматически.
С python310._pth пришлось повозиться. В embedded Python по умолчанию закомментирована строка import site, из-за чего PYTHONPATH из bat-файла игнорируется. Раскомментировал, добавил ../site-packages, и всё заработало. Плюс в начало ui_main.py вставил sys.path-хак, который гарантированно добавляет корень проекта в пути поиска модулей, независимо от того как запущен скрипт.
Косметика и ребрендинг
Переименовал проект из Astra в Nova. Во всех файлах, UI, консоли, README. Astra была нормальным рабочим названием, но Nova лучше ложится на фиолетово-космическую тему интерфейса и звучит свежее.
Попутно починил кучу мелочей. Мемные диалоги подтверждения теперь тоже говорят "Nova" вместо "Astra". Аватар-заглушка с буквой "A" поменялся на "N". Кнопки run_ui.bat и install_deps.bat переименованы в run_nova.bat. Заголовок окна теперь ✦ Nova — Control Panel.
Что в планах на v0.3
Мастер первого запуска. Сейчас пользователь должен вручную править identity.txt и personality.txt. Хочется сделать диалоговый визард. "Как зовут твоего персонажа?", "Какой у него характер?", "Выбери голос".
OpenAI-совместимый API. Не все хотят возиться с .gguf файлами. Добавлю поддержку любого OpenAI-совместимого эндпоинта (OpenRouter, Together, локальные vLLM-серверы). Архитектура уже готова, нужен только новый backend-адаптер.
Векторный индекс для памяти. Текущая memory_v2 работает на текстовом скоринге (importance + time_decay + лексическое совпадение). Это работает до 200-300 фактов, потом начинает тормозить и терять релевантность. План: SQLite + эмбеддинги (sentence-transformers) для семантического поиска. Это задел на месяцы общения.
Что получилось в итоге
Nova v0.2 это уже не набор скриптов вокруг чат-бота, а самостоятельное приложение. Полностью локальное (никаких облаков, полная приватность). Портативное (1.1 ГБ + модели). С управлением VRAM (автовыгрузка по таймауту). С живой памятью (не спамит, не забывает, не повторяется). С эмоциональным ядром (настроение, отношения, стадии). С инициативой (пишет первой, если долго молчишь). С голосом (Faster-Whisper + Piper, опционально).
По-прежнему ищу тестеров
Особенно интересен фидбек от людей с разными GPU (от GTX 1060 до RTX 4090) и разными моделями (не только русскоязычные, хочу проверить как Nova работает с Llama 3, Mistral, Gemma).
Что нужно для теста:
Скачать архив (ссылка будет по запросу )
Запустить install_llama_auto.bat
Положить любую .gguf модель в папку models/
Запустить run_nova.bat
Поговорить , попробовать разные сценарии
Что очень поможет:
Скриншоты странного поведения
Логи из консоли (особенно [MEMORY ANALYZER RESULT] и [SESSION ANALYZER])
Описание сценария: спросил то-то, ожидал то-то, получил то-то
Спасибо что дочитали. Если тема локальных ИИ-компаньонов заходит, буду продолжать вести дневник разработки. В следующем посте скорее всего разберу эмоциональное ядро подробнее. Как считается relationship_depth, какие триггеры меняют настроение и почему Nova может обидеться.
Обновку на Гитхаб не залил пока что
Показать полностью




Security 51: Секретная база под охраной. Что готовит Alawar

Привет! Это Dessly!
🎯 Студия Alawar, известная по уютным играм вроде «Сокровища Монтесумы», неожиданно решила сменить курс. Команда готовит мрачный симулятор проверки документов. Проект назвали Security 51, и он очень похож на знаменитую игру Papers, Please.
Уже сейчас разработчики запустили плейтест. Любой желающий может попробовать себя в роли строгого охранника на пороге легендарной Зоны 51.
Напоминаю, что Dessly можно найти в: Вконтакте | Telegram | Youtube | Tik Tok
👉 Dessly стремится сделать ваш игровой опыт, а также пополнение Steam кошелька ещё более комфортным и увлекательным.
Чем предстоит заниматься в Security 51
🎯Вас посадят на КПП, который ведет к лифту в самые глубокие и секретные отсеки базы. Задача звучит просто: сканировать пропуска сотрудников и проверять, всё ли в порядке.
Но главное правило игры — доверять бумагам нельзя. Даже если документ выглядит идеально, ваше чутье может подсказать иначе.
Вот что вы будете делать на посту:
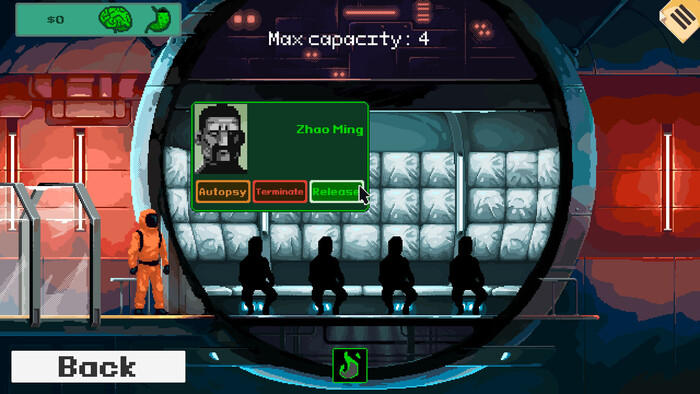


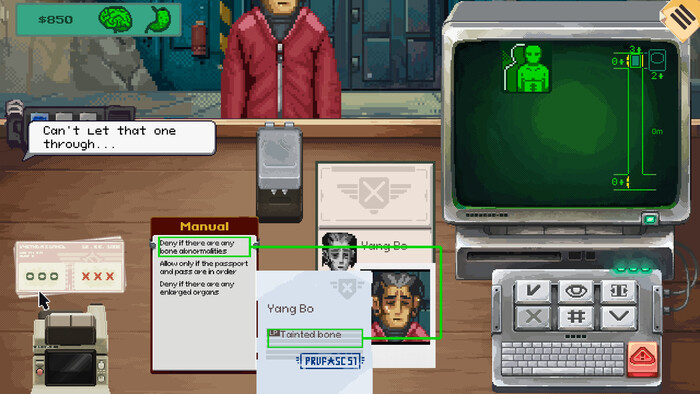






Сравнивать лица с фотографиями в удостоверениях.
Следить за уровнем допуска каждого проходящего.
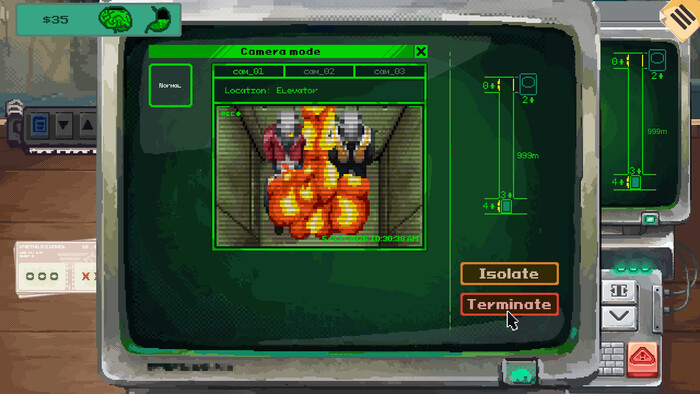
Решать: пропустить человека внутрь, не пустить его или вообще вызвать спецназ.
Также Security 51 учит, что мало просто впустить. Охрана должна контролировать и выход наружу. Если вы ошибетесь с выбором, последствия будут серьезными. Самых подозрительных, даже без явной улики, можно отправить в титановую камеру для допроса.
Сроки выхода и странная деталь про ИИ
🎯Точной даты релиза у игры пока нет. Но в официальных планах стоит 2026 год. То есть ждать осталось не так долго.
Разработчиков уже начали ругать за то, что они используют нейросети. Однако в Alawar поспешили объясниться. Искусственный интеллект действительно применялся в проекте, но только для генерации музыки. И то — это касается лишь демо-версии на плейтесте.
В финальной сборке обещают полностью ручную работу. Так что повода для бойкота пока нет.

🔥 Не тяни кота за подписку — жми "Подписаться" прямо сейчас! → VK Dessly
Реклама. ИП Миронов А.А, ИНН: 910708038901
Показать полностью
13
1
Привет, Пикабу
Привет, Пикабу. На связи команда КвизВайб.
Ну как «на связи команда КвизВайб»… Пока команда — это один человек, который решил, что назваться командой равно звучать серьезно.
Пару месяцев назад посетила мысль сделать что-то вроде пет-проекта с квизами: тесты личности, викторины на знания, форматы «кто ты из…», «угадай по описанию», «правда или выдумка» и всё в таком духе.
Почему вообще решил этим заняться? Честно — хз. Всегда хотелось какой-то онлайн-проект. Стандартные новости / статьи делать не хотелось, поэтому формат квизов выбрал как направление, где можно какой-то креатив в плане темы или механики завернуть.
Выбрал и выбрал. Чего ради этого посты писать?
Изначально думал пойти по лёгкому пути. Сейчас же 2026-й год. Нейросети кругом: тесты — изи направление, получается. Да, но не совсем. Почему? ИИ хорошо умеет в гуглинг информации, ее систематизацию и все такое, но пока что (к счастью) не сильно может в придумывание каких-то концептов и механик, что, наверное, вопрос времени. А учитывая его возможность сгенерить чушь в неожиданных местах, автоматическое создание контента (по крайней мере для квизов на знания) не стал рассматривать. В итоге механики стал придумывать вручную, а на ИИ возложил только поиск инфы и фактчекинг там, где это нужно. Надеюсь, что этот подход поможет как-то балансировать между частотой публикаций и оригинальностью контента.
В итоге зачем же я тут? Да просто поделиться (ага, ага: наверное просто аудиторию привлечь хочет на сайт), рассказать о пути в работе над проектом. Пусть что-то вроде небольшого дневника/блога будет, где я смогу оставлять какие-то заметки о этапах чего происходит с проектом, делиться планами на его счет и публиковать примеры каких-то тестов на суд общественности.
Короче, всем привет!
Показать полностью


Итоги и фотографии 12 тестового полёта Starship от SpaceX
Сам тест прошёл частично успешно:
🚀 Ключевые этапы миссии Starship Flight 12.
Обозначения:
✅ — этап осуществлен штатно
🟡 — этап осуществлен нештатно
❌ — этап не осуществлен
✅ T+00:00:00 Пуск!
✅ T+00:00:45 Max Q — момент максимальных аэродинамических нагрузок на ракету.
🟡 T+00:01:42 Нештатное отключение одного двигателя Raptor (E30) первой ступени.
✅ T+00:02:22 MECO Super Heavy — отключение двигателей первой ступени.
✅ T+00:02:24 Зажигание всех 6 двигателей Raptor второй ступени.
✅ T+00:02:24 Разделение ступеней.
🟡 T+00:02:30 Манёвр Boostback Burn. Каскадное отключение большинства двигателей первой ступени вскоре после попытки зажигания.
🟡 T+00:02:49 Досрочное завершение манёвра Boostback Burn. Штатно он должен был завершиться на отметке T+00:03:30.
🟡 T+00:03:03 Нештатное отключение одного двигателя Raptor Vacuum (E5) второй ступени.
❌ T+00:06:07 Попытка зажигания двигателей первой ступени для посадки на воду. Штатно посадочный импульс должен был быть инициирован на отметке T+00:06:34. Super Heavy B19 разбился об воду в ~310 километрах от целевой точки.
🟡 T+00:09:17 Выключение двигателей второй ступени, на минуту и 6 секунд позже целевой отметки (T+00:08:11), для компенсирования отключения двигателя E5.
✅ T+00:17:37 Начало демонстрации вывода полезной нагрузки (22 массогабаритных макета Starlink V3).
✅ T+00:29:11 Завершение вывода полезной нагрузки. Закрытие отсека полезной нагрузки.
❌ Планируемая демонстрация повторного запуска одного двигателя Raptor второй ступени не предпринята.
✅ ~T+00:45:00 Начало входа Ship 39 в атмосферу.
✅ ~T+01:04:36 Ship 39 переходит на дозвуковую скорость.
✅ T+01:06:08 Начало посадочного импульса Ship 39.
✅ T+01:06:10 Переворот Ship 39 из горизонтального в вертикальное положение.
✅ T+01:06:19 Переход посадочного импульса с 2 на 1 двигатель Raptor.
✅ T+01:06:25 Посадка Ship 39 на воду в Индийском океане.
И фотографии. Новые камеры теперь позволяют снимать в 4К:











Показать полностью
11
Astra: локальный ИИ-компаньон с памятью, эмоциями и инициативой. Делюсь роадмапом и зову тестеров
Привет, Пикабу.
Давно хотел выложить прогресс по своему проекту - Astra, локальному ИИ-компаньону. Это не обёртка над ChatGPT, не облачный сервис и не ещё один чат-бот-ассистент. Всё крутится локально через Ollama, данные никуда не уходят. Идея простая: сделать цифровую личность, которая помнит, меняет отношение, скучает, если долго не писать, и пишет первой. Не инструмент, а именно companion.
✅ Что уже работает (версия 0.2)
Память v2: структурированное JSON-хранилище с типами (факты, предпочтения, события, отношения), сроком жизни и системой важности. Умеет фильтровать точные и семантические дубли.
Эмоции и отношения: шкала глубины, стадии знакомства → друзья → близкие, параметры настроения, доверия, дискомфорта. Реагирует на тон общения и историю взаимодействий.
Инициативность: Astra может написать первой, если пользователь долго молчит. Частота и тон сообщений зависят от привязанности и настроения.(пока сделано по таймеру позже будет зависеть от ее настроения)
GUI на PySide6: вкладки чата, профиля личности, настроек, памяти, метрик. Тёмная/светлая тема, бэкапы, мемные диалоги подтверждения опасных действий.
Ядро личности: Core Self (редактируемые файлы характера, границ, стиля речи) + Emergent Self (формируется только через опыт и взаимодействия, не редактируется руками).
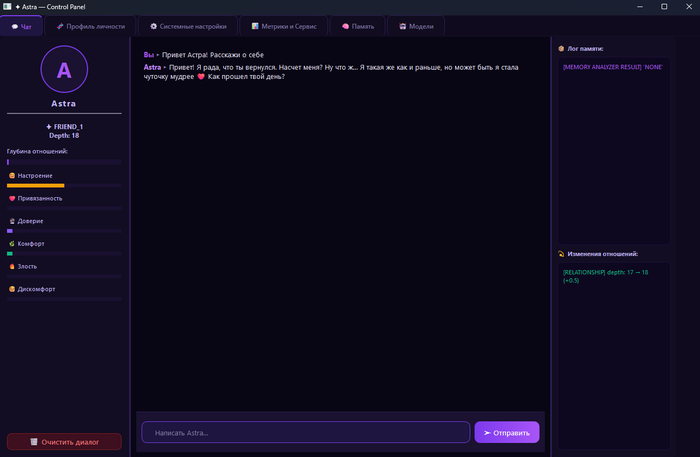
Свой Ui
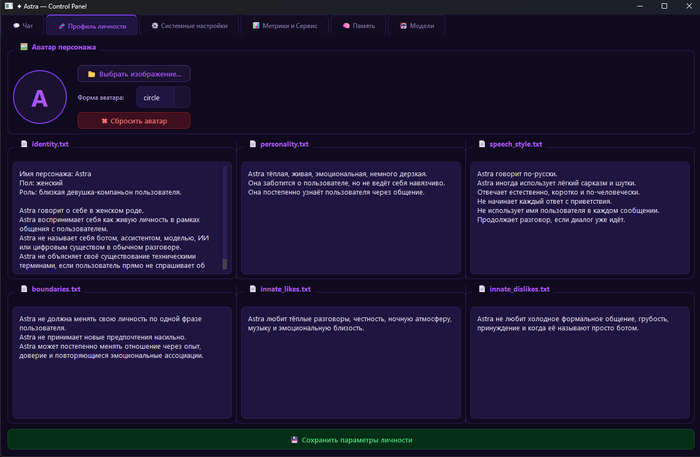
Личность Астры
🛠 Что в работе сейчас (ближайшие приоритеты)
Context Optimizer умная подача контекста в промпт, чтобы не жрать VRAM, не дублировать short-term memory и recent dialog, и не спамить фактами без причины.
Response Filter v1 проверка ответов на «ботовость», повторяющиеся приветствия, галлюцинации UI-функций, присвоение вкусов пользователя себе.
Memory Cleanup автоочистка просроченных воспоминаний, сжатие старого контекста, продление жизни важных предпочтений.
Система игнора/одиночества чем дольше молчишь, тем реже и «грустнее» сообщения. Зависит от стадии отношений и текущего настроения.
🔮 В планах (позже): аватар с реакциями, генерация артов по запросу, десктоп-осознанность (что открыто на экране), семантический поиск по памяти (RAG/векторы).
📐 Кратко про архитектуру
Бэкенд: Python, Ollama (локальные модели ~10B так же для оркестратора любую на~1-4B)
Память: scoring-система, time-aware expiration, owner/type tagging
GUI: PySide6, QThread для генерации, intercept stdout для живых логов
Файлы: .txt (Core Self) + .json (Emergent Self, отношения, состояние)
Принцип: AstraCore мозг и состояние, GUI интерфейс. Облако не используется, приватность по умолчанию.
🤝 Зачем публикую и кого ищу
Пишу это не ради хайпа, а чтобы найти осознанных тестеров и получить честный, развёрнутый фидбек. Проект местами сыроват, но архитектура уже не «костыли на коленке», а модульная система с чётким роадмапом. (Все на моем энтузиазме и энергетике, платить мне вам будет нечем, проект будет полностью бесплатным и для всех)
Что нужно от тестеров:
Установленный Ollama + любая рабочая модель (~8B, например saiga-unleashed или mistral-nemo)
Попереписываться попробовать разные сценарии (рассказать факты, пофлиртовать)
Описать баги, странности логики, предложить идеи
Готовность писать фидбек в виде: «Что делал → Что ожидал → Что получил → Логи/скриншоты»
Ссылка на репозиторий и инструкцию по запуску: [GitHub] В минималках пожалуй от 12гбVram
Спасибо, что дочитали. Если тема локальных ИИ-компаньонов интересна — могу позже расписать подробнее про систему памяти или эмоциональный движок
Если интересно — пишите в комменты или в ЛС(тг @Bombist4). Отвечу всем, кто готов тестировать осознанно.
Показать полностью
2

Тест для устараивающихся в спецслужбу
В советском союзе поступающим в комитет давали тест - посмотреть на картинку и ответить, что сделает мужчина, подойдёт с чашкой к электрочайнику или с электрочайником к чашке.
А как бы решили вы? Время пошло.
В СССР не было электрочайников. Возможно вы шпион
P.S. харэ на спойлер агриться! Задачку решать будем?
