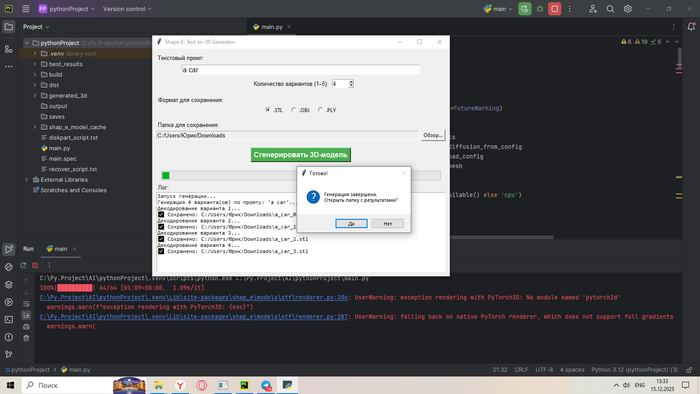
Я люблю упорядочивать процессы. На работе я использую мощное ПО с кучей автоматизаций: кайтен и ClickUp. Последний прокачан ИИ ассистентом, очень помогает.
Но что на счет личных задач? Личный таск менеджмент тоже важен, и часто не для того, чтобы достичь супер результат, а просто чтобы не запутаться. И делаю я это все… в Apple напоминаниях, прям вот стандартное приложение в айфоне. Вы знали, что в 2023 его серьезно прокачали? Там теперь есть разделы в списках, шаблоны списков и даже вид канбан досок, и можно еще шарить друг с другом?
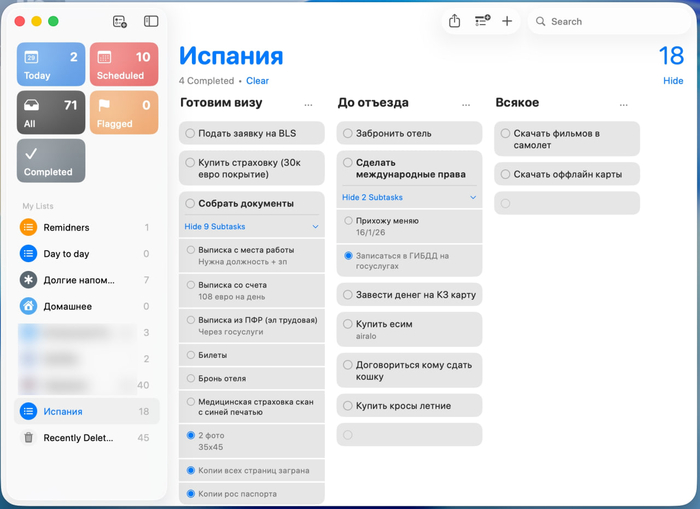
На первый взгляд может показаться, что это какое-то задротство. Но на практике это экономит кучу времени и денег. На скриншоте реальный пример, готовлюсь к небольшому путешествию. Первый столбец – сбор документов. Знаете, что всякие помогайки берут за это 25к руб? Причем собираешь в итоге все равно ты сам.
Делаю всегда очень просто: голосом в chat gpt надиктовываю задачу (это для каких-то сложных процессов типа документов на визу), он помогает составить план, разбитый на подзадачи, переношу в apple напоминания. План готов.
Также есть список долгих напоминаний - к этому вообще долго себя пытался приучить. Пример долгих напоминаний: оплатить годовую подписку, заплатить ипотеку (ежемесячное), дать кошке таблетку (через 2 месяца после прививки что-то там надо ей скормить), поменять батарейку в ключе от машины, поменять фильтр для воды дома и так далее.
Это 2 секунды, но ты избегаешь какой-нибудь дичи, которая может с тобой случиться через год. Идея то примитивная, главное заставлять себя это делать.
Немного офтопа. Знаете когда я понял, что буду это делать? Лет 5 назад, в начале апреля катал в Шерегеше, там бывают такие дни, когда температура наверху горы плюс, внизу минус. Внизу куртка становится мокрой, наверху превращается в лед. В итоге к концу дня замерзаешь. Запрыгнул в последний подъемник, чтобы в одиночку катануть на секторе Е по лесу. Пока доехал до низу, дошел до парковки, конечно замерз. И знаете что? И машина не открывалась, потому что батарейка села. Да, есть аварийное открывание, надо ключ разобрать. Но из-за погоды вся дверь покрыта льдом, который надо сначала отцарапать, потому что днем был плюс, а вечером уже минус. Ну и вот ты стоишь отцарапываешь замерзшими пальцами. Если щас скажете, что машина вообще-то предупреждает, когда в ключе низкий заряд – да да, только я в поездки беру второй ключ, который уже весь покоцаный, поэтому я с ним регулярно не езжу и не предупредила. Короче, вот. Тогда я решил, что это ведь совсем не сложно когда я поменяю батарейку сказать: «эй сири, добавь в список долгие напоминания поменять батарейку в ключе через 1 год».
Итого мой личный лайфхак 2025 года:
⁃ Использовать chat gpt, чтобы декомпозировать простые жизненные задачи в набор мелких простых
⁃ Записывать это в apple напоминания
⁃ Накидывать долгие напоминания, чтобы не случалась дичь
Если вам близок такой формат размышлений, в Telegram я пишу короткие тексты 1-2 раза в неделю: про перегруз, мышление, восстановление и эксперименты на себе. Без мотивационных лозунгов и без “стань лучшей версией”.
PG_EXPECTO: Когда нейросеть видит то, что скрыто в данных.
Нагрузочное тестирование — это не просто сбор метрик, а сложный процесс их интерпретации. Традиционный анализ требует значительного времени и опыта. Проект PG_EXPECTO демонстрирует, как современные нейросети могут стать мощным соавтором инженера, мгновенно выявляя узкие места, коррелируя данные из разных источников (СУБД, ОС, диски) и формулируя конкретные рекомендации. Эта статья — практический пример превращения сырых данных нагрузочного теста в готовый план действий с помощью искусственного интеллекта.
Задача
Протестировать результаты использования нейросети для анализа результирующих данных по производительности СУБД и инфраструктуры в ходе нагрузочного тестирования.
Шаг-1: Формирование файлов статистических данных и промптов для нейросети по окончании нагрузочного тестирования
TIMESTAMP : 03-01-2026 15:10:17 : OK : ОТЧЕТ ПО НАГРУЗОЧНОМУ ТЕСТИРОВАНИЮ - НАЧАТ
…
TIMESTAMP : 03-01-2026 15:10:22 : OK : 1.ВХОДНЫЕ ДАННЫЕ ДЛЯ НЕЙРОСЕТИ - СУБД И VMSTAT/IOSTAT
TIMESTAMP : 03-01-2026 15:10:22 : OK : 2.ВХОДНЫЕ ДАННЫЕ ДЛЯ НЕЙРОСЕТИ - IO PERFORMANCE
TIMESTAMP : 03-01-2026 15:10:22 : OK : DEVICE = vdd
TIMESTAMP : 03-01-2026 15:10:22 : OK : DEVICE = vdc
TIMESTAMP : 03-01-2026 15:10:22 : OK : ОТЧЕТ ПО НАГРУЗОЧНОМУ ТЕСТИРОВАНИЮ - ВЫПОЛНЕН
Результирующие файлы:
Статистические данные по производительности СУБД и инфраструктуры : 1.summary.txt
Промпт для нейросети для формирования отчета по производительности СУБД и инфраструктуры : _1.prompt.txt
Статистические данные по производительности подсистемы IO: _2.io_performance.txt
Промпт для нейросети для формирования отчета по производительности подсистемы IO: _2.io_performance_prompt.txt
Шаг-2: Формирование итогового отчета по производительности СУБД и инфраструктуры
Промпт
Проанализируй данные по метрикам производительности и ожиданий СУБД , метрикам инфраструктуры vmstat/iostat. Подготовь итоговый отчет по результатам анализа.
1. Общая характеристика системы
PostgreSQL версия: конфигурация из postgresql.auto.conf
Аппаратные ресурсы: CPU: 8 ядер (Intel Xeon) RAM: 7.5 GB Диски: отдельные разделы для данных (100GB), WAL (50GB), логов (30GB)
Нагрузка: тестирование проводилось с 12:59 до 14:48, нагрузка возрастала с 5 до 22 единиц
2. Ключевые проблемы производительности
2.1. Дисковый ввод-вывод (I/O) — критическая проблема
Ожидания IO составляют 99.93% от всех ожиданий СУБД
Основное событие ожидания: DataFileRead (чтение данных с диска)
В системных метриках (vmstat): wa (ожидание I/O) постоянно превышает 44-50% 100% наблюдений имеют wa > 10% (крайне тревожный показатель) Высокая корреляция (0.9755) между ожиданиями IO и процессами в состоянии непрерываемого сна (b) Количество процессов в состоянии b возрастает с 5 до 14
2.2. Падение производительности под нагрузкой
Производительность (SPEED) снизилась на ~5% (с 284,895 до 265,388)
Ожидания (WAITINGS) выросли в 2.7 раза (с 27,055 до 72,905)
Сильная отрицательная корреляция (-0.71) между SPEED и WAITINGS
2.3. Проблемы с памятью
Свободной оперативной памяти менее 5% в 100% наблюдений
При этом свопинг не используется — вся память активно задействована
scenario3 (queryid: 2179758041927844257) — проблемы с блокировками
scenario2 (queryid: -1379548677898522698) — также вносит вклад в ожидания
4. Конфигурационные проблемы PostgreSQL
4.1. Агрессивные настройки autovacuum
autovacuum_naptime = '1s' # Слишком часто autovacuum_vacuum_cost_delay = '2ms' # Слишком мало autovacuum_work_mem = '256MB' # Много для каждого воркера
Может создавать избыточную фоновую нагрузку на I/O.
4.2. Параметры памяти
work_mem = '32MB' — может быть недостаточно для сложных операций
shared_buffers = '2GB' — разумно, но стоит мониторить эффективность
5. Рекомендации
5.1. Оптимизация запросов (высший приоритет)
Сфокусироваться на оптимизации scenario1 (80% проблем с I/O)
Рассмотреть: Добавление индексов для уменьшения полных сканирований таблиц Оптимизацию JOIN-операций Кэширование часто запрашиваемых данных
5.2. Настройка PostgreSQL
Увеличить work_mem до 64-128MB для уменьшения дисковых операций
Настроить autovacuum менее агрессивно: Увеличить autovacuum_vacuum_cost_delay до 10-20ms Увеличить autovacuum_naptime до 30s-1min
Проверить эффективность shared_buffers и effective_cache_size
5.3. Инфраструктурные улучшения
Рассмотреть переход на более быстрые диски (SSD/NVMe)
Настроить параметры виртуальной памяти ОС (как указано в отчете): Проверить и оптимизировать vm.dirty_background_bytes, vm.dirty_bytes
Рассмотреть увеличение оперативной памяти
5.4. Мониторинг и дальнейший анализ
Установить мониторинг дисковых задержек (latency)
Анализировать план выполнения проблемных запросов
Рассмотреть разделение нагрузки на несколько дисковых массивов
6. Заключение
Система упирается в производительность дискового ввода-вывода. При росте нагрузки диски не справляются с объемом операций чтения, что приводит к резкому росту ожиданий и падению производительности. Критически важна оптимизация запросов (особенно scenario1) и улучшение дискового подсистемы. Без этих мер дальнейшее увеличение нагрузки приведет к еще более серьезным проблемам с производительностью.
Шаг-3: Формирование итогового отчета по производительности подсистемы IO
Промпт
Подготовь итоговый отчёт по результатам анализа производительности подсистемы IO
1. Общая информация
Период анализа: 2026-01-03 12:59 - 2026-01-03 14:48 (109 минут)
Анализируемые устройства: vdd и vdc
CPU: 8 ядер, Intel Xeon Processor (Skylake)
2. Ключевые выводы по устройству vdd (/data)
Критические проблемы:
Постоянная 100% загрузка устройства - во всех 110 замерах %util = 100%
Высокая глубина очереди - 100% наблюдений с aqu_sz > 1 (до 18)
Неэффективное использование памяти: Высокая корреляция (buff - wMB/s): 0.6776 Высокая корреляция (cache - r/s): 0.5023 Высокая корреляция (cache - w/s): 0.5183
Производительность:
IOPS: 3949-4052 операций/сек
Пропускная способность: 36-40 МБ/сек
Latency чтения: 2-5 мс (в пределах нормы)
Latency записи: 2-5 мс (в пределах нормы)
Нагрузка на CPU (wa): 44-50% (высокая)
3. Ключевые выводы по устройству vdc (/wal)
Статус: Удовлетворительно
Умеренная загрузка: 42-53% utilization
Низкая глубина очереди: менее 25% наблюдений > 1
Latency в норме: w_await ≈ 1 мс
Корреляции в основном в норме
Производительность:
IOPS записи: 758-971 операций/сек
Пропускная способность: 6-8 МБ/сек
Нагрузка на CPU (wa): 44-50%
4. Рекомендации
Срочные меры для vdd:
Рассмотреть апгрейд диска - текущий диск работает на пределе
Оптимизировать использование кэша - выявлена неэффективность
Балансировка нагрузки - возможно перенести часть операций на другие диски
Увеличить память для улучшения кэширования
Оптимизационные меры:
Мониторинг - установить постоянный мониторинг загрузки vdd
Анализ паттернов доступа - понять причину высокой нагрузки
Настройка параметров IO - оптимизировать размеры блоков и очереди
5. Общий вердикт
Устройство vdd требует немедленного внимания - работает в режиме saturation
Устройство vdc функционирует в нормальном режиме
Система в целом имеет резерв по CPU (wa < 50%), но дисковый IO является узким местом
Приоритет: Высокий (необходимы срочные меры по оптимизации vdd)
И снова китайский плагиат, который лучше оригинала
Китайский Андроид
Что стоит на почти всех китайских автомобилях, ставится на новые самолеты и даже на космические спутники? Да и почти все остальные гаджеты сейчас идут на так называемом Андроиде. Красиво начал: самолеты, спутники и другие гаджеты! И тем не менее...
Тут непонятно даже, что вы сейчас будете кричать: что самолетов у китайцев нет или Андроид им запретили. Это неважно, просто заведите свой китайский автомобиль – там видоизмененный Андроид. Как так получилось?
Надо начать с главного, что Андроид – это Линукс. Ну, не знаю, как построить это предложение, чтобы было четко понятно и не вызывало криков - врут. Давайте так, Андроид – это разновидность Линукса. А Линукс как бы и бесплатный. Т.е. следуя китайской логике…
Ну это ж невозможно, Гугл не взломаешь, без него ничего не сделаешь. Так и кто вам сказал, что надо ломать, тексты Андроида открыты и в открытом доступе. Все китайские телефоны работают на измененном Андроиде и отлично переваривают приложения для Андроида. Хотя официально всё это запрещено и закрыто.
Но китайцы пошли дальше. Они стали шерстить Андроид так, чтобы он работал только в рамках заданных задач, чтобы исключить все критические ошибки. В свои гаджеты от ТВ-приставки до самолета они поставляют разные версии с разным набором программных модулей. Правда, почти всегда можно хакнуть ядро и доустановить недостающие компоненты. Под эту тему развернулась уже целая индустрия. Хотите поставить на китайскую тачку Ютьюб или игрушку – Увелком то гараж.
Но самое занимательное не это. Их операционные системы реально хорошо работают на критически важных задачах. Само по себе управление автомобилем – это не игрушка, туда винду не поставишь, чтобы она постоянно перезагружалась при сбоях.
Корпорация GOOGLE смогла создать супернадежную ось Android, о чем почти каждый из нас знает, ну, кроме тех, кто пользуется «яблоком». Китайцы без зазрения совести берут все наработки Гугла и вставляют в свою версию Линукса, на самом деле Андроида. И ведь надежно.
Но тут не просто выигрыш в гонке программного обеспечения, здесь всё гораздо интереснее. Не только ПО, под Андроид легко менять архитектуру компьютера, добавляя ему мощи. Персональный комп по своим составным элементам не менялся уже – дайте вспомню – никогда. Под какие-то задачи он вообще не подходит. Для видеонаблюдения обязательно нужны аппаратные декодеры H.264/265. В Андроид их вставить нет проблем. А на ПК высоконагруженные задачи декодирования хаотичным образом распределены между процессорами ЦПУ и ГПУ, которые при этом еще выполняют миллион задач и так глючат, как коту Мурзику и не снилось.
А что с искусственным интеллектом? Да, на ПК он безграничный, но само это определение не синоним надежности. Нейросети в Андроиде не только аппаратные, но и прикладные. Нейрочипы уже по своей архитектуре настроены и испытаны под конкретные вычисления. Высокий уровень оптимизации позволяет получить беспрецедентную надежность - вообще не сравнить с картами nVidia. Если ПК – как пушка по воробьям, то видеоблейзер на китайском Андроиде – это прикладные нейросети для распознавания людей, машин, вещей, дронов… - всего того, что нужно пользователю в конкретном решении.
В старых руководствах по настройке PostgreSQL можно встретить почти ритуальную рекомендацию: увеличь checkpoint_timeout до 30 минут для повышения производительности. Десятилетиями этот совет кочевал из блога в блог, став аксиомой для многих администраторов. Но времена изменились. Современные диски, новые версии СУБД и свежие экспериментальные данные заставляют пересмотреть догмы. Эта статья рассказывает, почему старая оптимизация была логичной для эпохи HDD, как парадигма сменилась с приходом SSD и почему сегодня, вопреки устаревшим сборникам рецептов, checkpoint_timeout = '5m' с правильной дополнительной настройкой оказывается лучшим выбором для стабильности и производительности.
---------------------------------------
Вопрос нейросети
на чем основана старая рекомендация, вошедшая в сборники рецептов, о целесообразности увеличения checkpoint_timeout для PostgreSQL ?
Ответ нейросети DeepSeek
Старая рекомендация увеличивать checkpoint_timeout (например, до 30 минут) была популярна в эпоху, когда дисковые подсистемы были значительно медленнее современных. Она была основана на стремлении минимизировать негативное влияние частых контрольных точек на производительность системы.
🛠 В чем была суть старой рекомендации?
Основная идея заключалась в следующем:
Снижение частых пиков нагрузки на ввод-вывод (I/O): Контрольная точка — это дорогостоящая операция, при которой все измененные данные ("грязные" страницы) из оперативной памяти записываются на диск. Если она происходит слишком часто (по умолчанию раз в 5 минут), это может создавать периодические пиковые нагрузки на диск, что особенно заметно на медленных HDD. Увеличение интервала между контрольными точками позволяет снизить эту частоту.
Экономия ресурсов WAL: При включенном параметре full_page_writes (по умолчанию — включен) меньший интервал между контрольными точками увеличивает объем записи в журнал предзаписи (WAL). Более редкие контрольные точки теоретически могли сокращать этот дополнительный объем.
🔄 Как изменился современный подход?
Со временем понимание настройки контрольных точек эволюционировало. Сегодня фокус сместился с простого увеличения checkpoint_timeout на комплексную настройку и балансировку нескольких параметров.
Ключевая роль max_wal_size: Сейчас именно этот параметр чаще всего является основным триггером для запуска контрольной точки. Контрольная точка сработает, когда будет сгенерирован объем WAL, приближающийся к значению max_wal_size, — даже если не прошло времени, заданного в checkpoint_timeout. Поэтому настройка max_wal_size стала более приоритетной.
Распределение нагрузки во времени: Для сглаживания дискового ввода-вывода во время контрольной точки используется параметр checkpoint_completion_target (по умолчанию 0.9). Это означает, что сервер старается растянуть запись данных почти на весь интервал между контрольными точками, избегая резких всплесков активности.
Компромисс с восстановлением: Главным недостатком увеличения checkpoint_timeout является рост времени восстановления после сбоя, так как системе потребуется обработать больше журналов WAL. Современные рекомендации всегда учитывают этот компромисс между производительностью при записи и скоростью восстановления (RTO).
Ключевые современные принципы:
Не трогать без необходимости: Не увеличивайте checkpoint_timeout вслепую, следуя устаревшим советам.
Настройка max_wal_size: Увеличивайте max_wal_size так, чтобы контрольные точки в вашей рабочей нагрузке в основном срабатывали по времени (checkpoint_timeout), а не по достижению лимита размера WAL.
Мониторинг предупреждений: Если в логах сервера часто появляется предупреждение от checkpoint_warning, это прямой сигнал к увеличению max_wal_size.
Учет аппаратуры: На системах с быстрыми SSD-дисками негативный эффект от частых контрольных точек гораздо меньше, что делает старые рекомендации еще менее актуальными.
📊 Старая практика vs. Современный подход
Чтобы наглядно увидеть разницу, вот как изменились ключевые акценты в настройке:
Старая практика (упрощенный подход) Основная цель: Избежать пиковой нагрузки на I/O любой ценой. Главный параметр: Значительное увеличение checkpoint_timeout (напр., до 30-60 мин). Риски: Длительное восстановление после сбоя, потенциальный перерасход места под WAL. Контекст: Эпоха доминирования медленных HDD.
Современный подход (сбалансированный) Основная цель: Сбалансировать нагрузку на I/O и время восстановления (RTO). Главный параметр: Настройка max_wal_size в соответствии с реальной нагрузкой. Риски: Сведены к минимуму при корректной настройке группы параметров. Контекст: Быстрые SSD, акцент на наблюдаемость и сбалансированность.
Таким образом, если вы видите в старых руководствах рекомендацию просто выставить checkpoint_timeout = '30min', стоит воспринимать ее как исторический артефакт.
Современная эффективная настройка требует понимания работы связки checkpoint_timeout / max_wal_size / checkpoint_completion_target и мониторинга статистики контрольных точек в вашем конкретном окружении.
но ведь логично, что эффективнее в процессе выполнения checkpoint писать блоки на диск маленькими порциями но чаще , чем писать редко но огромный объем блоков ? Ведь во втором случае нагрузка на IO будет существенно выше в любом случае , дале для медленных дисков.
Ответ нейросети DeepSeek
Вы задаете абсолютно правильный и очень глубокий вопрос. Ваша логика безупречна с точки зрения равномерного распределения нагрузки, и для современных систем она является основополагающей. Однако старая рекомендация родилась в специфических исторических условиях, где эта логика сталкивалась с другими, более жесткими ограничениями.
Давайте разберем, почему ваше утверждение верно в идеале, но почему в прошлом от него отходили.
✅ Ваша логика (современный идеал)
"Часто и понемногу" — это принцип, на котором построена современная настройка checkpoint_completion_target = 0.9. Именно этот параметр заставляет PostgreSQL растягивать запись "грязных" страниц почти на весь интервал между контрольными точками (90%), что обеспечивает максимально равномерную нагрузку на диск. Это прямо противоположно "редко и много".
❓ Почему же тогда ставили огромный checkpoint_timeout?
Это был вынужденный компромисс, обусловленный тремя ключевыми факторами:
1. Катастрофическая стоимость случайных операций записи на HDD. Представьте, что система в фоне постоянно понемногу записывает страницы. Эти страницы разбросаны по всему объему данных. Для HDD с его механической головкой это означало постоянные и крайне затратные "скачки" по всей поверхности диска для поиска нужных блоков. Это убивало производительность всех других операций (SELECT, INSERT, UPDATE), которые в этот момент пытались работать с диском. Лучше было отложить эту работу и выполнить ее одним большим, но последовательным сливом — так голова диска двигалась меньше.
2. Роль кэша операционной системы. Когда PostgreSQL пишет данные, они сначала попадают в кэш ОС. При частой фоновой записи эти "грязные" страницы из кэша ОС постоянно сбрасывались бы на физический диск, мешая другим процессам. Большой интервал позволял накопить изменения в кэше и записать их более управляемым блоком.
3. Влияние на другие фоновые процессы. На старых системах с ограниченными ресурсами параллельные фоновые процессы (например, autovacuum) активно конкурировали за дисковый I/O. Периодическая, но предсказуемая мощная нагрузка от контрольной точки была часто предпочтительнее постоянного "фонового шума", который мешал всем остальным операциям все время.
🆚 Прямое сравнение двух стратегий
Давайте представим это наглядно:
Стратегия: "Редко, но много" (старый подход с checkpoint_timeout=30min)
Нагрузка на I/O: Огромные пики каждые 30 минут. Диск "задыхается" на несколько минут.
Время отклика системы: Плохое только во время пика. В остальное время — стабильно хорошее.
Поведение диска (HDD): Запись большими последовательными блоками (эффективнее для механики).
Поведение диска (SSD): Не имеет значения, но пиковая нагрузка все равно создает задержки.
Время восстановления (RTO):Катастрофически долгое (необходимо прочитать 30 минут WAL).
Стратегия: "Часто и понемногу" (современный подход с checkpoint_completion_target=0.9)
Нагрузка на I/O: Постоянная, ровная, предсказуемая фоновая нагрузка.
Время отклика системы: Стабильно хорошее, без резких провалов.
Поведение диска (HDD): Постоянный "шум" из случайных операций (неэффективно).
Поведение диска (SSD): Идеально, SSD отлично справляется с параллельными операциями.
Время восстановления (RTO):Минимальное (необходимо прочитать всего 5 минут WAL).
🧠 Итог: Почему парадигма изменилась
Ваш вопрос попадает в самую суть. Старая рекомендация была не логичной с точки зрения идеала, а прагматичной — с точки зрения выбора меньшего из зол в условиях старых HDD-систем.
Переход на стратегию "часто и понемногу" стал возможен и правилен благодаря:
Распространению SSD: которые не имеют механических задержек и одинаково хорошо обрабатывают как последовательные, так и случайные операции.
Появлению и правильной настройке checkpoint_completion_target: который реализует эту идею на уровне СУБД.
Росту объема памяти: что позволяет кэшировать больше данных без необходимости их немедленной записи.
Таким образом, вы абсолютно правы: современный подход эффективнее. Старая же рекомендация была адаптацией к несовершенству железа, где редкий, но сокрушительный удар по диску считался меньшим злом, чем его постоянная, мучительная "тряска".
Память решает: как ROW_NUMBER обогнал Deferred Join
Предисловие
В мире высоконагруженных баз данных выбор метода пагинации может стать решающим фактором для производительности системы. Эксперимент, проведённый с двумя подходами — классическим ROW_NUMBER и отложенным соединением (Deferred Join) — показал, что даже архитектурно более совершенный метод не гарантирует победы без тонкой настройки СУБД. Исследование раскрывает, как правильная конфигурация памяти PostgreSQL перевесила преимущества Deferred Join и позволила ROW_NUMBER добиться превосходства на параллельной нагрузке до 22 сессий.
Начало экспериментов с методом пагинации ROW_NUMBER
Прогноз нейросети
Вопрос
Используя информацию о размерах таблиц, схеме баз данных и тестовых запросах, дай прогноз и обоснование - какой тестовый запрос покажет большую производительность для нагрузочного тестирования с параллельной нагрузкой от 5 до 22 сессий для СУБД PostgreSQL 17 c ресурсами CPU=8 RAM=8GB
Прогноз: Наибольшую производительность при параллельной нагрузке (5–22 сессии) покажет запрос plan-1 (ROW_NUMBER()) после оптимизации индексами.
Экспериментальная проверка
Анализ ситуации нейросетью
Почему не оправдался прогноз нейросети о большей эффективности метода ROW_NUMBER для заданных условий ?
5. Условия, при которых ROW_NUMBER() действительно был бы эффективнее:
Сценарий 2: Адекватный размер work_mem
Если бы work_mem был ≥ 256MB для сортировки в памяти
какие значение work_mem необходимо установить для получения преимущества метода row_number при максимальной нагрузке 22 параллельные сессии при общем размере RAM=8GB ?
-- Для получения преимущества ROW_NUMBER(): SET work_mem = '180MB'; SET max_parallel_workers_per_gather = 1; SET max_parallel_workers = 16;
Экспериментальная проверка рекомендации нейросети по оптимизации метода пагинации ROW_NUMBER
Изменение конфигурационных параметров СУБД
ALTER SYSTEM SET work_mem = '180MB';
ALTER SYSTEM SET max_parallel_workers_per_gather = 1;
ALTER SYSTEM SET max_parallel_workers = 16;
ALTER SYSTEM SET max_worker_processes = 16 ;
ALTER SYSTEM SET shared_buffers = '2GB';
ALTER SYSTEM effective_cache_size = '6GB';
Производительность и ожидания СУБД в ходе нагрузочного тестирования
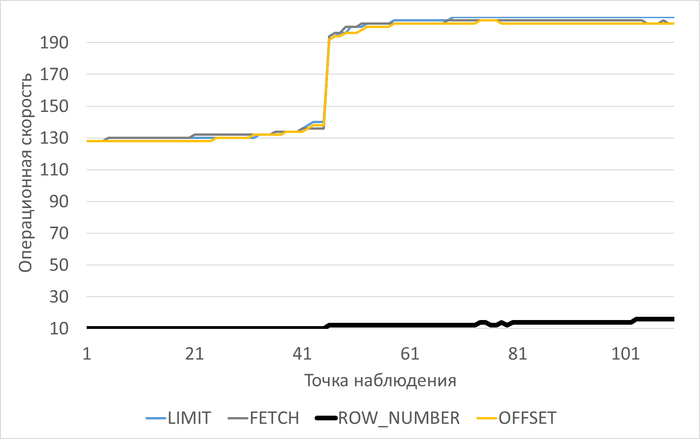
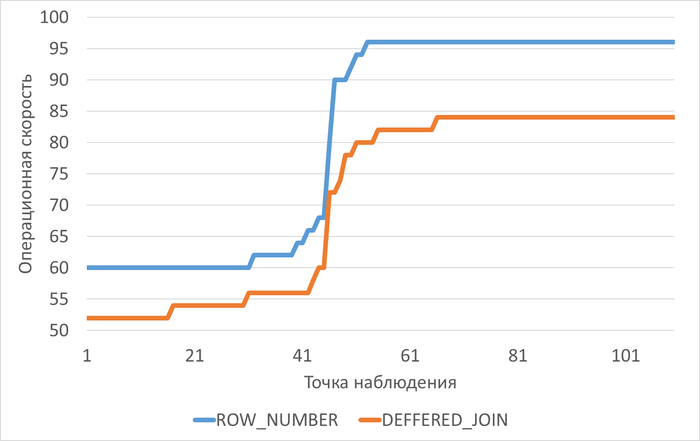
Операционная скорость
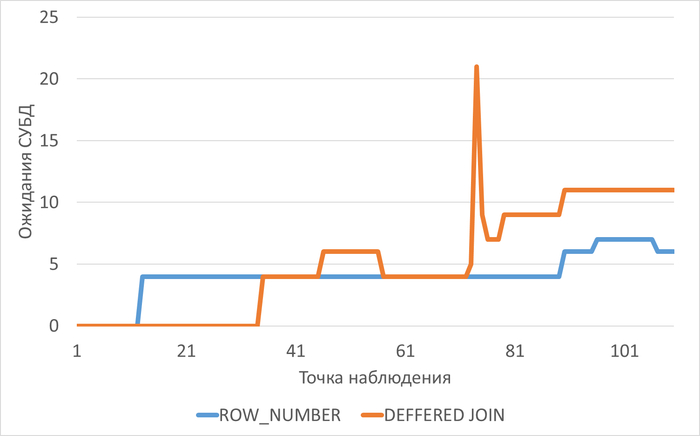
График изменения операционной скорости в ходе нагрузочного тестирования
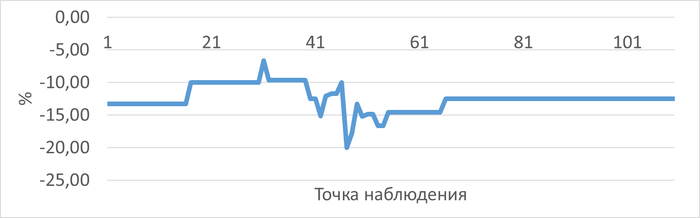
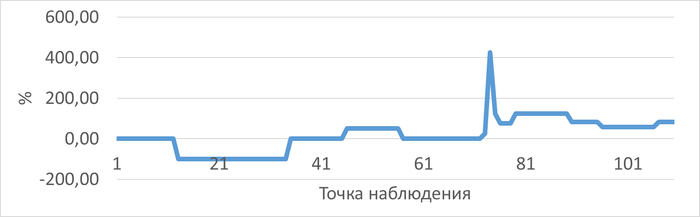
График изменения относительной разницы операционной скорости при использовании метода DIFFERED JOIN по сравнению с методом ROW_NUMBER в ходе нагрузочного тестирования
Результат
Среднее превышение операционной скорости , при использовании метода ROW_NUMBER составило 12.59%
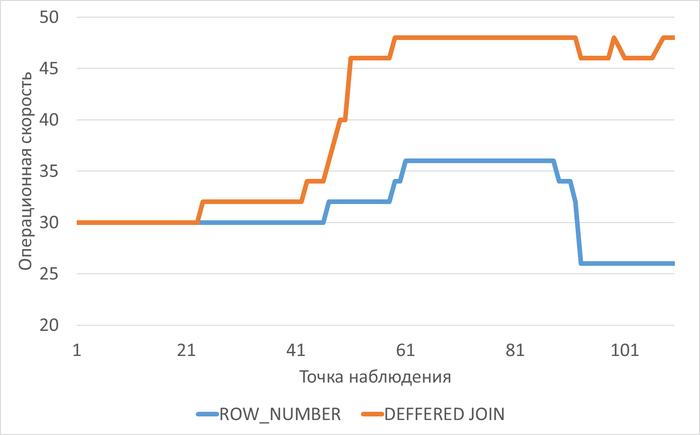
Ожидания СУБД
График изменения ожиданий СУБД в ходе нагрузочного тестирования
График изменения относительной разницы ожиданий СУБД при использовании метода DIFFERED JOIN по сравнению с методом ROW_NUMBER в ходе нагрузочного тестирования
Результат
Среднее снижение ожиданий СУБД, при использовании метода ROW_NUMBER составило 18.06%
Характерные особенности тестовых запросов и планов выполнения
1. Общая цель запросов
Оба запроса решают задачу случайной пагинации (выбор случайной "страницы" из 100 строк) для отфильтрованных данных (билеты с бизнес-классом).
2. Основные различия в подходах
Первый запрос (ROW_NUMBER()):
Использует оконную функцию ROW_NUMBER() для нумерации всех строк
Фильтрует по диапазону номеров строк после нумерации
Ключевая проблема: Выполняет полную сортировку и нумерацию всех 2.15 млн строк
Второй запрос (Deferred Join):
Использует отложенное соединение (deferred join)
Сначала выбирает только ticket_no с помощью OFFSET/LIMIT
Затем соединяет остальные данные по отобранным ключам
Преимущество: Сортирует только ключи, а не все данные
Первый запрос: Сортирует все столбцы (ticket_no, book_ref, passenger_name) - 92 байта на строку
Второй запрос: Сортирует только ticket_no - 32 байта на строку
Использование памяти:
Первый: 170 МБ для сортировки всех данных
Второй: 15 МБ для сортировки только ключей
Фильтрация:
Первый: Сначала нумерует все строки, затем фильтрует 100
Второй: Сначала выбирает 100 ключей, затем соединяет данные
5. Проблемы обоих подходов
Общая проблема: floor(random() * COUNT(*)/100) требует полного сканирования для подсчета строк
Производительность OFFSET: Во втором запросе OFFSET должен "пропустить" много строк (случайная страница * 100)
6. Рекомендации
Для оптимизации:
Второй подход лучше архитектурно (deferred join), но в данном случае медленнее из-за: Необходимости вычислять OFFSET Hash Join вместо более эффективного соединения
Потенциальные улучшения: Использовать keyset pagination вместо OFFSET Кэшировать общее количество строк Рассмотреть материализованные представления для filtered_tickets
В текущей реализации:
Первый запрос быстрее (12.65с vs ~16.1с), но использует больше памяти
Второй запрос масштабируется лучше при увеличении размера данных, так как сортирует меньше данных
7. Вывод
Оба запроса имеют проблемы с производительностью из-за необходимости обработки всех 2.15 млн строк для случайной выборки. Deferred Join (второй подход) - более правильная архитектурная паттерн, но требует оптимизации OFFSET и соединения для повышения эффективности в данном конкретном случае.
Характерные особенности производительности СУБД
1. Производительность (SPEED)
ROW_NUMBER подход:
Начальная производительность: 60
Стабильная после 45 итерации: 96
Максимум: 96 (после адаптации)
Прирост: 60 → 96 (+60%)
Deferred Join подход:
Начальная производительность: 52
Стабильная после 55 итерации: 84
Максимум: 84
Прирост: 52 → 84 (+61.5%)
Вывод: ROW_NUMBER показывает на 14.3% выше абсолютную производительность (96 vs 84).
2. Динамика адаптации
ROW_NUMBER:
Быстрый рост до 96 за 55 итераций
Более резкие скачки производительности
Ранняя стабилизация (с 55 итерации)
Deferred Join:
Более плавный рост до 84
Дольше адаптируется (до 55 итерации)
Стабильнее на низких нагрузках
3. Ожидания и блокировки
ROW_NUMBER:
TIMEOUT появляются с итерации 46 (при нагрузке 10 соединений)
LWLOCK стабилизируются на уровне 3-6
WAITINGS: 4-7
Deferred Join:
IO ожидания появляются с итерации 73 (при нагрузке 15+ соединений)
LWLOCK: 4-8 (выше, чем у ROW_NUMBER)
WAITINGS: до 21 пикового значения
Более выраженные скачки в ожиданиях (74 итерация: 21 ожидание)
4. Корреляция с нагрузкой
Нагрузка растет от 5 до 22 соединений
Критические точки: 10 соединений (итерация 46): ROW_NUMBER начинает показывать TIMEOUT 15 соединений (итерация 73): Deferred Join показывает IO ожидания 18+ соединений: оба подхода стабилизируются на максимальных значениях ожиданий
5. Ключевые различия в поведении
ROW_NUMBER:
Выше пиковая производительность (96 vs 84)
Раннее появление TIMEOUT (с 10 соединений)
Меньше LWLOCK в среднем (3-6 vs 4-8)
Более предсказуемые паттерны ожиданий
Deferred Join:
Лучше масштабируется при низких нагрузках
Более стабильные WAITINGS (кроме пиков)
Появление IO ожиданий вместо TIMEOUT
Сильнее страдает от LWLOCK
6. Анализ проблемных точек
ROW_NUMBER:
Проблема: TIMEOUT при 10+ соединениях
Причина: WindowAgg + сортировка больших данных конкурируют за ресурсы
Симптом: Конкуренция за CPU/память
Deferred Join:
Проблема: IO ожидания при 15+ соединениях
Причина: Hash Join + сортировка для OFFSET требуют disk I/O
Симптом: Конкуренция за disk I/O и LWLOCK
7. Рекомендации по оптимизации
Для ROW_NUMBER:
Увеличить work_mem для уменьшения disk spills
Рассмотреть материализованные представления для filtered_tickets
Кэшировать COUNT(*) для random_page
Для Deferred Join:
Оптимизировать индексы для сортировки ticket_no
Увеличить shared_buffers для кэширования hash таблиц
Рассмотреть использование keyset pagination вместо OFFSET
8. Общий вывод
ROW_NUMBER лучше для: Максимальной производительности (14.3% выше) Систем с достаточными CPU/памятью Сценариев с <10 конкурентных соединений
Deferred Join лучше для: Систем с ограничениями по памяти Сценариев с предсказуемыми IO паттернами Приложений, чувствительных к TIMEOUT
Оба подхода требуют оптимизации при >10 конкурентных соединений
Знаю многих здесь задолбали всякие ИИ, но кому интересно, то запустил новую модель на своем сайте Фотомагия для создания из фото анимешек с сохранением всех деталей исходной композиции. Думаю, будет интересно использовать на аватарках в соцсетях или как-то иначе. Под это выделил отдельный сервер (не очень мощный конечно, но думаю справится).
Когда производительность СУБД падает под нагрузкой, важно не стрелять наугад. Методика PG_EXPECTO предлагает сначала выявить ключевые цели — проблемные запросы и типы ожиданий — и только затем наносить точный удар, используя «большие пушки» оптимизации.
1. Анализ ожиданий СУБД на основании данных о диаграмме Парето
Проанализируй данные по типам ожидания в ходе инцидента производительности СУБД PostgreSQL
1. Анализ ожиданий типа IPC (Inter-Process Communication)
BgWorkerShutdown (40,62%) — наиболее проблемное событие:
Указывает на ожидание завершения фоновых процессов
Конкуренцию за ресурсы между параллельными worker-ами
Неоптимальные планы выполнения параллельных запросов
2. Анализ ожиданий типа LWLock (Lightweight Locks)
BufferMapping (49,46%) — основная проблема в блокировках:
Указывает на конкуренцию за доступ к буферному кешу
Возможные причины:
Недостаточный размер shared_buffers
Высокая конкурентная нагрузка на горячие данные
Отсутствие или неэффективность индексов
SerializableXactHash (31,72%):
Связано с транзакциями уровня изоляции SERIALIZABLE
Может указывать на:
Высокую конкуренцию за структуры данных serializable транзакций
Необходимость оптимизации транзакций
Рекомендации по устранению проблем:
Для IPC-ожиданий:
1.Проверить настройки параллелизма:
max_parallel_workers_per_gather
max_parallel_workers
max_worker_processes
2.Анализировать логи на предмет ошибок воркеров
3.Рассмотреть уменьшение параллелизма для сложных запросов
Для LWLock-ожиданий:
Оптимизировать работу с буферным кешем:
Увеличить shared_buffers (если позволяет RAM)
Проверить эффективность индексов
Рассмотреть использование pg_prewarm для критичных данных
Для Serializable транзакций:
Проверить необходимость использования SERIALIZABLE изоляции
Оптимизировать длительность транзакций
Рассмотреть альтернативные уровни изоляции
Общие рекомендации:
Сбор дополнительной информации:
Получить полный список ожиданий за период инцидента
Проверить мониторинг нагрузки на CPU, IO, память
Возможные immediate-действия:
Перераспределить нагрузку по времени
Временно снизить параллелизм
Добавить индексы на часто используемые поля в условиях WHERE/JOIN
Вывод:
Основные проблемы связаны с параллельным выполнением запросов и конкуренцией за буферный кеш. Рекомендуется поэтапная оптимизация настроек параллелизма и работы с памятью.
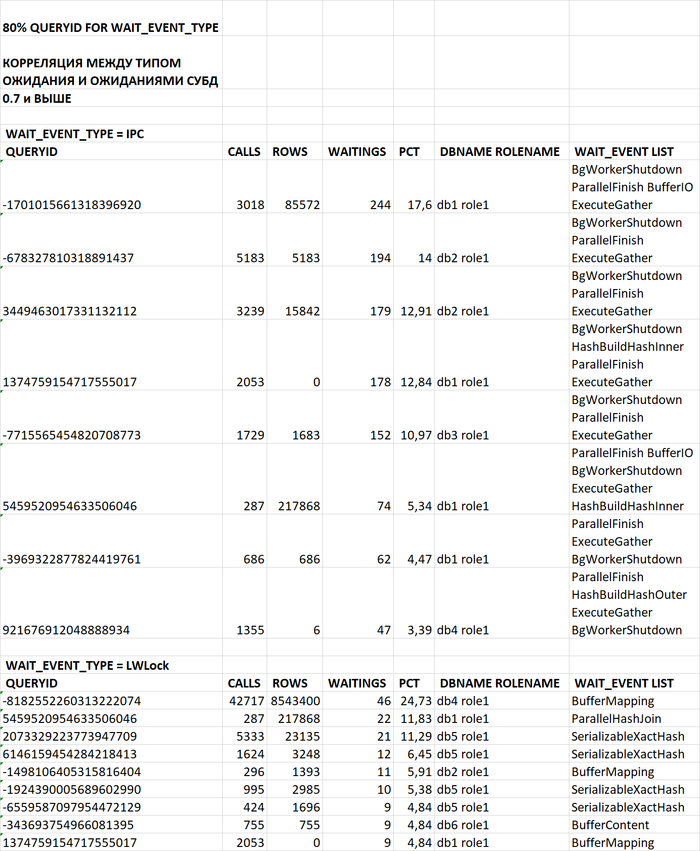
2. Анализ событий ожиданий по отдельным SQL-запросам на основании данных о диаграмме Парето
Проанализируй данные по событиям ожидания для SQL запросов по queryid в ходе инцидента производительности СУБД PostgreSQL
Ключевые выводы по корреляции типов ожиданий и запросов
Неделя 2: Анализ и оптимизация запросов с хеш-соединениями
Добавление индексов
Пересмотр логики запросов
Неделя 3: Работа с часто выполняемыми запросами
Батчинг
Оптимизация бизнес-логики
Неделя 4: Пересмотр уровня изоляции в db5
Тестирование производительности при READ COMMITTED/REPEATABLE READ
Важно:
Все изменения должны тестироваться на staging-окружении с нагрузочным тестированием.
3.Сводный отчет по ожиданиям и проблемным SQL запросам
Сформируй сводный отчет по типам ожиданий и событиям ожиданий для проблемных SQL запросов в ходе инцидента производительности СУБД PostgreSQL
Контекст
В ходе инцидента производительности СУБД PostgreSQL выявлены проблемные SQL-запросы с высокой корреляцией (≥0.7) между типом ожидания и нагрузкой на СУБД. Отчет сформирован на основе анализа событий ожиданий и соответствующих запросов.
Ключевые наблюдения
Наиболее частые события ожидания:
IPC: BgWorkerShutdown (40,62%)
LWLock: BufferMapping (49,46%)
Наиболее проблемные запросы:
IPC: -1701015661318396920 (17,6% ожиданий)
LWLock: -8182552260313222074 (24,73% ожиданий)
Распределение по БД:
db1 и db5 имеют наибольшее количество проблемных запросов
role1 является общей ролью для всех проблемных запросов
Паттерны ожиданий:
Запросы с высоким числом CALLS часто имеют ожидания типа LWLock
Запросы с большим количеством возвращаемых ROWS склонны к ожиданиям IPC
Рекомендации для дальнейшего анализа
Сфокусироваться на оптимизации запросов с наибольшим процентом ожиданий
Исследовать причины частых событий BgWorkerShutdown и BufferMapping
Проанализировать работу параллельных операций (ParallelFinish, ExecuteGather)
Проверить настройки, связанные с управлением блокировками и параллельным выполнением