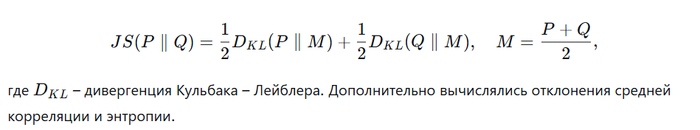Практическое применение цепей Маркова для прогнозирования инцидентов производительности СУБД PostgreSQL
Оригинал — на основном техническом канале (Возможны правки и дополнения).

От хаоса к прогнозу: один шаг вперёд.
В рамках проекта pg_expecto разработана и внедрена система прогнозирования риска возникновения инцидентов производительности на основе цепей Маркова.
Реализация представляет собой полноценное решение, адаптированное к потоковым данным и способное к самонастройке.
Постановка задачи
Производительность СУБД PostgreSQL подвержена влиянию множества факторов, включая характер нагрузки, состояние операционной системы и внутренние события ожидания.
Традиционные подходы к мониторингу, как правило, реагируют на уже возникшие проблемы, тогда как задача проактивного обнаружения предвестников сбоев требует более глубокого анализа динамики системы.
В основу предлагаемого решения положена идея дискретизации непрерывных метрик производительности в конечное множество состояний, переходы между которыми описываются марковским процессом. Это позволяет моделировать эволюцию состояния системы во времени и оценивать вероятности неблагоприятных исходов.
Формализация состояния системы
Непрерывные метрики – операционная скорость, время ожиданий и корреляция между ними – преобразуются в дискретное пространство из 189 состояний.
Каждое состояние характеризуется тремя параметрами:
коэффициентом корреляции (21 градация от –1,0 до +1,0 с шагом 0,1),
трендом операционной скорости
трендом времени ожиданий (каждый принимает значения –1, 0, +1).
Такая дискретизация обеспечивает баланс между детализацией модели и вычислительной эффективностью.
Архитектура системы
Система построена по многослойному принципу:
Слой данных
Включает таблицы:
хранения переходов (transition_log)
накопленных частот (markov_frequencies)
матрицы вероятностей (markov_probabilities)
поглощающей матрицы для многошагового прогноза (markov_absorbing).
Отдельно выделены таблицы:
конфигурации (markov_config), справочник состояний (state_descriptions) и динамический список критических состояний (critical_states).
Слой обучения
Реализует пошаговое обновление модели с частотой одна минута.
На каждом шаге выполняются:
получение текущих метрик,
вычисление идентификатора состояния,
логирование перехода,
обновление частот ,
при необходимости, применение забывания.
Слой прогнозирования
Предоставляет функции для оценки риска на заданном горизонте.
Ключевая функция mchain_predict_risk_k_v2 вычисляет вероятность хотя бы одного попадания в критическое множество за k шагов.
Слой оценки
Включает механизмы расчёта достоверности прогнозов и суточных метрик качества.
Обучение модели и адаптивное забывание
Обучение происходит в реальном времени на потоке данных. По мере поступления новых наблюдений обновляются частоты переходов и пересчитываются вероятности. Ключевой механизм, обеспечивающий адаптацию к изменению характера нагрузки, – забывание.
Коэффициент забывания α определяет скорость, с которой устаревающие наблюдения теряют вес.
В адаптивном режиме α вычисляется по формуле:
α(t) = max(min_alpha, base_alpha · exp(-days_since_last_incident / half_life))
где days_since_last_incident – время, прошедшее с последнего попадания в критическое состояние.
Такой подход позволяет ускорить забывание после инцидентов и замедлить его в стабильные периоды. Дополнительно введён stability_factor, корректирующий α в зависимости от нестабильности вероятностей.
Важным условием применения забывания является достаточность накопленных данных. Функция mchain_check_sufficiency проверяет, что общее число переходов превышает порог min_transitions_for_forgetting (по умолчанию 5000).
Прогнозирование риска
Прогноз риска строится на основе текущего состояния системы и матрицы вероятностей переходов. Для одношагового прогноза используется прямая сумма вероятностей перехода в критические состояния.
Многошаговый прогноз (mchain_predict_risk_k_v2) реализует итеративное умножение вектора распределения вероятностей на матрицу переходов. На каждом шаге вероятности, попавшие в критические состояния, накапливаются в значении риска, а затем обнуляются, чтобы исключить учёт повторных попаданий. Горизонт прогноза задаётся параметром forecast_horizon_minutes в конфигурации (по умолчанию 30 минут).
Сформированные прогнозы сохраняются в таблицу prediction_log. По истечении горизонта выполняется обновление фактических исходов: для каждого прогноза определяется, произошёл ли переход в критическое состояние в течение заданного интервала.
Оценка качества и достоверности
Для оценки качества прогнозов предусмотрен комплекс метрик:
Brier score – среднеквадратичная ошибка вероятностных прогнозов.
Log-loss – логистическая потеря, чувствительная к уверенным неправильным прогнозам.
MAE – средняя абсолютная ошибка.
ECE (Expected Calibration Error) – средневзвешенное отклонение между предсказанными вероятностями и наблюдаемыми частотами.
MCE (Maximum Calibration Error) – максимальное отклонение калибровки.
ROC-AUC – площадь под ROC-кривой, характеризующая дискриминационную способность модели.
Достоверность прогнозов оценивается рейтингом от 0 до 5 на основе трёх факторов: общего числа переходов, стабильности вероятностей и покрытия частых состояний.
Профилирование нагрузки (версия 14)
Начиная с версии 14, система дополнена модулем профилирования нагрузки.
Этот модуль позволяет:
Сохранять оперативные (за последние 60 минут), суточные и недельные профили производительности.
Строить эталонные профили на основе исторических данных с исключением инцидентных окон.
Обнаруживать аномалии путём сравнения текущих профилей с эталонными.
Анализировать связь между отклонениями профилей и возникновением инцидентов.
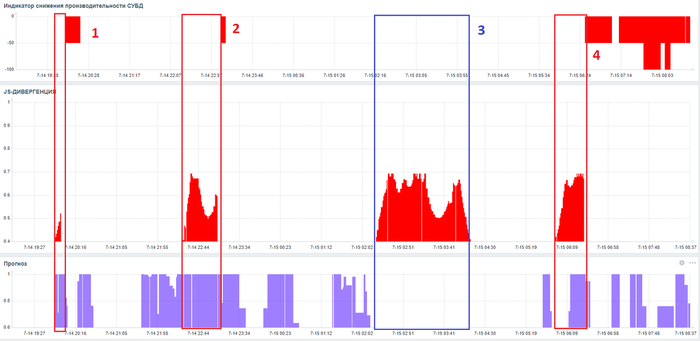
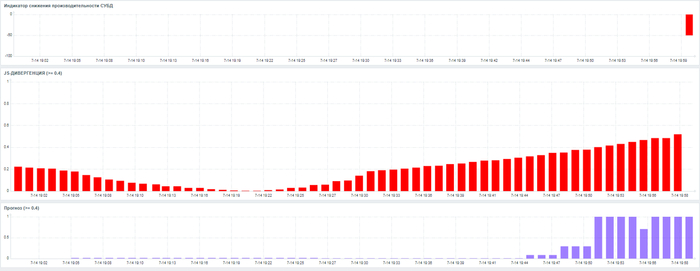
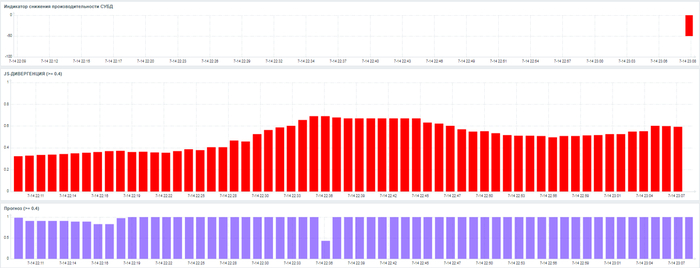
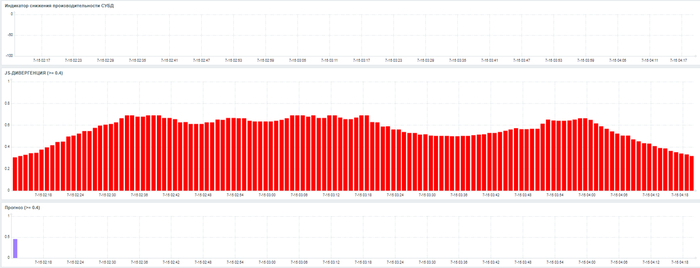
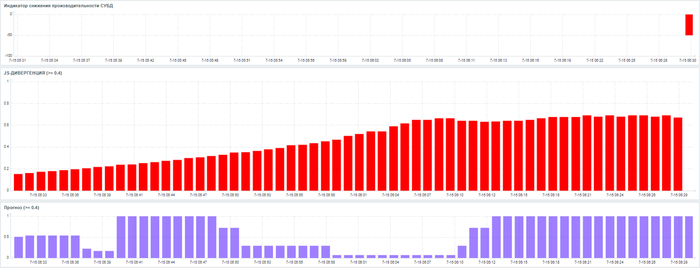
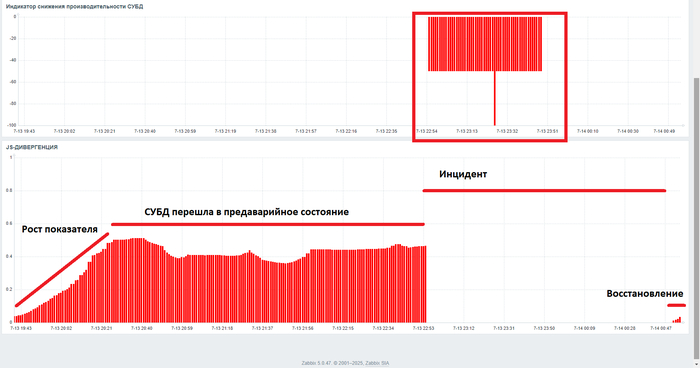
Функция compare_profiles выполняет сравнение текущего профиля с эталонным, вычисляя JS-дивергенцию гистограмм состояний и формируя статус (NORMAL, WARNING, CRITICAL).
Результаты сохраняются в журнал profile_comparison_log, что позволяет проводить ретроспективный анализ.
Историческое обучение
Для первоначального построения модели предусмотрена процедура mchain_initial_train_from_history, которая обучает цепь Маркова на исторических данных, имитируя пошаговое обучение.
Это позволяет развернуть систему на основе уже накопленных метрик без необходимости ждать накопления данных в реальном времени.
Заключение
Представленная реализация цепи Маркова представляет собой законченную систему прогнозирования риска инцидентов производительности, интегрированную в экосистему pg_expecto.
Ключевые преимущества системы:
работа в реальном времени с низкой задержкой;
адаптация к изменению характера нагрузки благодаря механизму забывания;
гибкая настройка горизонта прогноза и параметров обучения;
встроенные механизмы оценки качества и достоверности;
расширяемая архитектура, дополненная модулем профилирования нагрузки.
Система успешно применяется для мониторинга производительности СУБД и предупреждения о возможных сбоях.
Дальнейшее развитие проекта направлено на углубление аналитических возможностей и повышение точности прогнозов.