


Нейросеть рисует и пишет
38 постов
38 постов

16 постов

118 постов

40 постов
282 поста

114 постов

22 поста
Оригинал — на основном техническом канале (Возможны правки и дополнения).

От хаоса к прогнозу: один шаг вперёд.
В рамках проекта pg_expecto разработана и внедрена система прогнозирования риска возникновения инцидентов производительности на основе цепей Маркова.
Реализация представляет собой полноценное решение, адаптированное к потоковым данным и способное к самонастройке.
Производительность СУБД PostgreSQL подвержена влиянию множества факторов, включая характер нагрузки, состояние операционной системы и внутренние события ожидания.
Традиционные подходы к мониторингу, как правило, реагируют на уже возникшие проблемы, тогда как задача проактивного обнаружения предвестников сбоев требует более глубокого анализа динамики системы.
В основу предлагаемого решения положена идея дискретизации непрерывных метрик производительности в конечное множество состояний, переходы между которыми описываются марковским процессом. Это позволяет моделировать эволюцию состояния системы во времени и оценивать вероятности неблагоприятных исходов.
Непрерывные метрики – операционная скорость, время ожиданий и корреляция между ними – преобразуются в дискретное пространство из 189 состояний.
Каждое состояние характеризуется тремя параметрами:
коэффициентом корреляции (21 градация от –1,0 до +1,0 с шагом 0,1),
трендом операционной скорости
трендом времени ожиданий (каждый принимает значения –1, 0, +1).
Такая дискретизация обеспечивает баланс между детализацией модели и вычислительной эффективностью.
Система построена по многослойному принципу:
Включает таблицы:
хранения переходов (transition_log)
накопленных частот (markov_frequencies)
матрицы вероятностей (markov_probabilities)
поглощающей матрицы для многошагового прогноза (markov_absorbing).
Отдельно выделены таблицы:
конфигурации (markov_config), справочник состояний (state_descriptions) и динамический список критических состояний (critical_states).
Реализует пошаговое обновление модели с частотой одна минута.
На каждом шаге выполняются:
получение текущих метрик,
вычисление идентификатора состояния,
логирование перехода,
обновление частот ,
при необходимости, применение забывания.
Предоставляет функции для оценки риска на заданном горизонте.
Ключевая функция mchain_predict_risk_k_v2 вычисляет вероятность хотя бы одного попадания в критическое множество за k шагов.
Включает механизмы расчёта достоверности прогнозов и суточных метрик качества.
Обучение происходит в реальном времени на потоке данных. По мере поступления новых наблюдений обновляются частоты переходов и пересчитываются вероятности. Ключевой механизм, обеспечивающий адаптацию к изменению характера нагрузки, – забывание.
Коэффициент забывания α определяет скорость, с которой устаревающие наблюдения теряют вес.
В адаптивном режиме α вычисляется по формуле:
α(t) = max(min_alpha, base_alpha · exp(-days_since_last_incident / half_life))
где days_since_last_incident – время, прошедшее с последнего попадания в критическое состояние.
Такой подход позволяет ускорить забывание после инцидентов и замедлить его в стабильные периоды. Дополнительно введён stability_factor, корректирующий α в зависимости от нестабильности вероятностей.
Важным условием применения забывания является достаточность накопленных данных. Функция mchain_check_sufficiency проверяет, что общее число переходов превышает порог min_transitions_for_forgetting (по умолчанию 5000).
Прогноз риска строится на основе текущего состояния системы и матрицы вероятностей переходов. Для одношагового прогноза используется прямая сумма вероятностей перехода в критические состояния.
Многошаговый прогноз (mchain_predict_risk_k_v2) реализует итеративное умножение вектора распределения вероятностей на матрицу переходов. На каждом шаге вероятности, попавшие в критические состояния, накапливаются в значении риска, а затем обнуляются, чтобы исключить учёт повторных попаданий. Горизонт прогноза задаётся параметром forecast_horizon_minutes в конфигурации (по умолчанию 30 минут).
Сформированные прогнозы сохраняются в таблицу prediction_log. По истечении горизонта выполняется обновление фактических исходов: для каждого прогноза определяется, произошёл ли переход в критическое состояние в течение заданного интервала.
Для оценки качества прогнозов предусмотрен комплекс метрик:
Brier score – среднеквадратичная ошибка вероятностных прогнозов.
Log-loss – логистическая потеря, чувствительная к уверенным неправильным прогнозам.
MAE – средняя абсолютная ошибка.
ECE (Expected Calibration Error) – средневзвешенное отклонение между предсказанными вероятностями и наблюдаемыми частотами.
MCE (Maximum Calibration Error) – максимальное отклонение калибровки.
ROC-AUC – площадь под ROC-кривой, характеризующая дискриминационную способность модели.
Достоверность прогнозов оценивается рейтингом от 0 до 5 на основе трёх факторов: общего числа переходов, стабильности вероятностей и покрытия частых состояний.
Начиная с версии 14, система дополнена модулем профилирования нагрузки.
Этот модуль позволяет:
Сохранять оперативные (за последние 60 минут), суточные и недельные профили производительности.
Строить эталонные профили на основе исторических данных с исключением инцидентных окон.
Обнаруживать аномалии путём сравнения текущих профилей с эталонными.
Анализировать связь между отклонениями профилей и возникновением инцидентов.
Функция compare_profiles выполняет сравнение текущего профиля с эталонным, вычисляя JS-дивергенцию гистограмм состояний и формируя статус (NORMAL, WARNING, CRITICAL).
Результаты сохраняются в журнал profile_comparison_log, что позволяет проводить ретроспективный анализ.
Для первоначального построения модели предусмотрена процедура mchain_initial_train_from_history, которая обучает цепь Маркова на исторических данных, имитируя пошаговое обучение.
Это позволяет развернуть систему на основе уже накопленных метрик без необходимости ждать накопления данных в реальном времени.
Представленная реализация цепи Маркова представляет собой законченную систему прогнозирования риска инцидентов производительности, интегрированную в экосистему pg_expecto.
работа в реальном времени с низкой задержкой;
адаптация к изменению характера нагрузки благодаря механизму забывания;
гибкая настройка горизонта прогноза и параметров обучения;
встроенные механизмы оценки качества и достоверности;
расширяемая архитектура, дополненная модулем профилирования нагрузки.
Система успешно применяется для мониторинга производительности СУБД и предупреждения о возможных сбоях.
Дальнейшее развитие проекта направлено на углубление аналитических возможностей и повышение точности прогнозов.
Оригинал — на основном техническом канале (Возможны правки и дополнения).
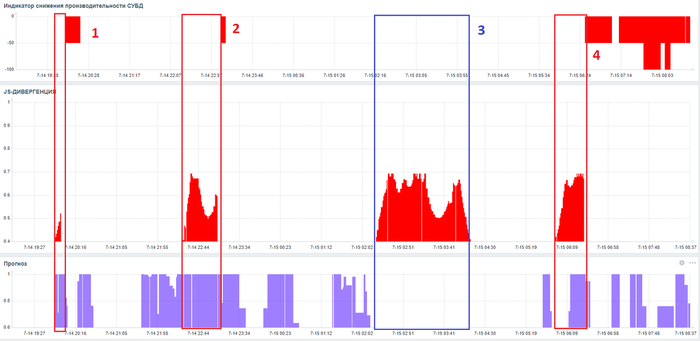
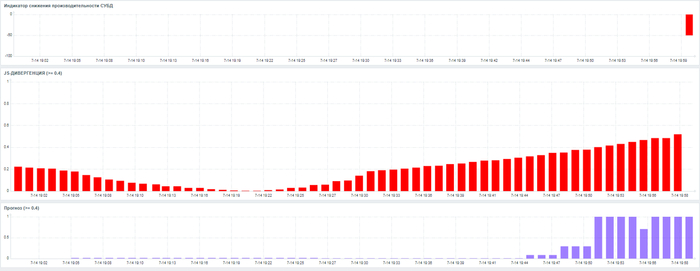
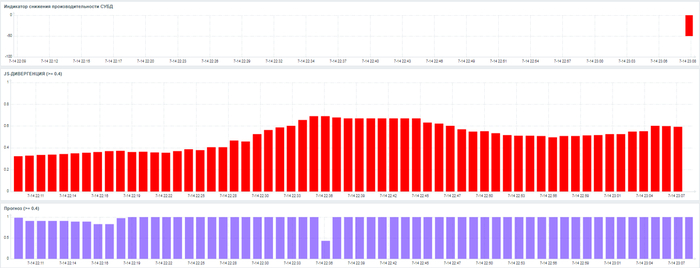
JS-дивергенция > 0.4
Прогноз риска > 0.6
JS-дивергенция > 0.4
Прогноз риска > 0.6
JS-дивергенция > 0.4
Прогноз риска < 0.6
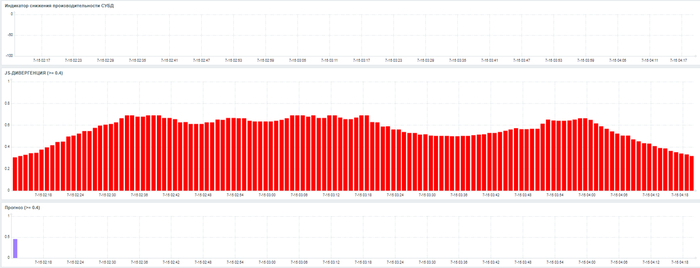
JS-дивергенция > 0.4
Прогноз риска > 0.6
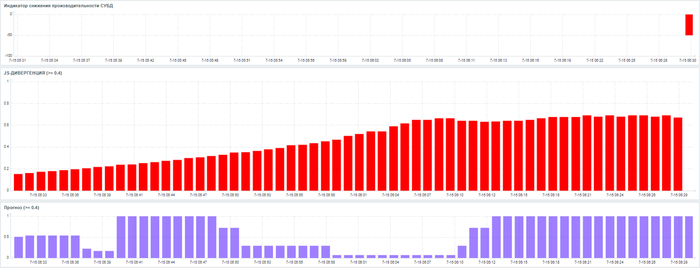
Превышение значения JS-дивергенции выше 0.4 при одновременном максимальном значении Прогноза риска = 1, может служить сигналом о приближении инцидента производительности СУБД
Оригинал — на основном техническом канале (Возможны правки и дополнения).
В статье представлены результаты экспериментальной верификации гибридного метода раннего обнаружения предотказных состояний СУБД PostgreSQL, сочетающего марковское профилирование нагрузок и оценку статистической дивергенции распределений (JS-дивергенцию). На основе суточного массива реальных данных (439 прогнозов, 13 подтверждённых инцидентов) показано, что предложенный подход обеспечивает 100%-ное обнаружение инцидентов с временем упреждения от 15 до 140 минут, при этом статус CRITICAL предшествует каждому событию (медианное упреждение — 45 мин). Установлено, что профильная структурная диагностика фиксирует аномалии в тех случаях, когда классические марковские прогнозы риска ещё не дают значимых отклонений. Новизна работы заключается в интеграции двух независимых каналов оценки – вероятностного и структурного – что позволяет различать постепенную деградацию и резкие сдвиги в поведении системы. Практическая ценность метода подтверждается высокими показателями точности (Accuracy = 0.868, Precision = 0.899, Recall = 0.886) и стабильностью сигнала, что рекомендует его в качестве дополнения к существующим системам мониторинга.
Ключевые слова: прогнозирование инцидентов, СУБД PostgreSQL, профили производительности, цепи Маркова, JS-дивергенция, раннее предупреждение, структурная диагностика.
Современные высоконагруженные информационные системы предъявляют жёсткие требования к доступности и отказоустойчивости СУБД. Традиционные системы мониторинга, ориентированные на пороговые значения метрик (загрузка CPU, количество активных сессий, время отклика), часто срабатывают уже на стадии развивающегося инцидента, когда время на упреждающие действия минимально. Альтернативный подход заключается в анализе профилей производительности – распределений состояний системы во времени, которые могут изменяться задолго до явных проявлений деградации.
В настоящей работе исследуется метод сравнения текущего профиля нагрузки с эталонным (безинцидентным) профилем с помощью метрики Дженсена – Шеннона (JS-дивергенции). Метод дополняется аппаратом цепей Маркова для вероятностной оценки риска перехода в критическое состояние. Цель работы – экспериментально подтвердить прогностическую ценность такого комбинированного подхода, оценить временные характеристики упреждения и устойчивость сигнала на реальных данных суточного мониторинга.
За эталон принимался интервал длительностью 60 минут, предшествующий всем зафиксированным инцидентам и характеризующийся штатной работой СУБД. Для каждой минуты в этом окне строилась гистограмма состояний системы (на основе агрегированных показателей: число транзакций, время ожидания блокировок, использование буферного кэша, интенсивность контрольных точек и др.). Эталонная гистограмма фиксировалась как нормальное распределение состояний.
Каждую минуту формировалось скользящее окно той же длины (60 мин), для которого строилась аналогичная гистограмма. Рассчитывалась JS-дивергенция между эталонным и текущим распределениями:
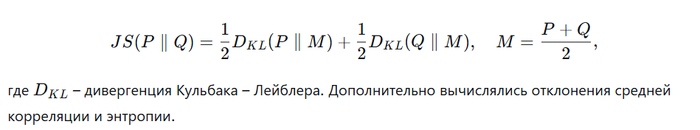
На основе значений JS-дивергенции и Z-оценок для вспомогательных метрик присваивался один из статусов:
NORMAL – JS < 0.05 (небольшие флуктуации);
WARNING – 0.05 ≤ JS < 0.10–0.20 (умеренное отклонение);
CRITICAL – JS ≥ 0.10–0.20 (значительное отклонение);
INCIDENT – период самого инцидента или восстановления после него (определялся по данным журнала инцидентов).
Период эксперимента – 24 часа (10 июля 2026 г.), всего зафиксировано 13 инцидентов различной длительности (от 9 до 91 минуты). В анализ включены также данные из таблиц prediction_log (прогнозы риска на основе цепи Маркова) и profile_comparison_log (результаты сравнения профилей), что позволило сопоставить два канала оценки.
Все 13 инцидентов были предварены статусом WARNING или CRITICAL (100% чувствительность). Среднее время от первого WARNING до начала инцидента составило ≈ 45 минут, от CRITICAL до инцидента – ≈ 35 минут. Максимальное упреждение зафиксировано для инцидента в 07:51 (WARNING за 142 минуты, CRITICAL – за 115 минут), минимальное – для инцидента в 13:40 (19 минут от WARNING, 4 минуты от CRITICAL). В табл. 1 приведены обобщённые показатели.
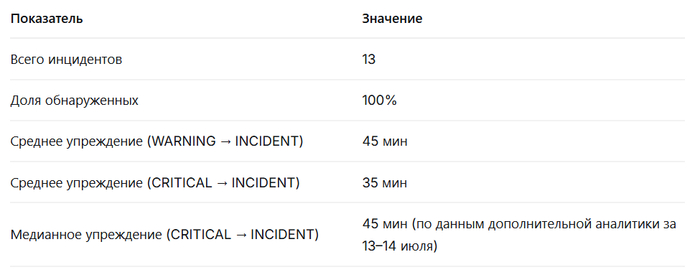
Таблица 1. Сводные показатели прогностической эффективности.
На всех эпизодах наблюдался устойчивый рост JS-дивергенции за 1–2 часа до инцидента.
Границы соответствия:
JS 0.00–0.05 → NORMAL (до инцидента > 60 мин);
JS 0.05–0.10 → WARNING (30–60 мин);
JS 0.10–0.20 → WARNING (15–30 мин);
JS > 0.20 → CRITICAL (< 15 мин).
После завершения инцидента статус INCIDENT сохранялся на 60 минут (период восстановления), что объясняется инерционностью скользящего окна.
В ряде случаев (например, в 13:36) сравнение профилей присваивало статус CRITICAL (JS ≈ 0.118), тогда как марковский прогноз риска был равен нулю. Это указывает на то, что профильный метод фиксирует структурные изменения в распределении состояний, которые не отражаются в матрице переходов (вероятности смены состояний остаются номинальными). Таким образом, два метода дают взаимодополняющую информацию.
Для периода 13–14 июля был проведён количественный анализ прогнозов с известным исходом (горизонт – 10 минут, порог классификации 0.5):
Accuracy = 0.868;
Precision = 0.899;
Recall = 0.886.
Эти показатели подтверждают высокую надёжность гибридной модели: ложные срабатывания редки и кратковременны (единичные эпизоды WARNING без последующего инцидента длительностью несколько минут).
Предложенная методика не является простым применением JS-дивергенции. Её новизна заключается в интеграции двух независимых каналов диагностики:
(1) вероятностного – на основе цепей Маркова, оценивающего риск перехода в критическое состояние;
(2) структурного – на основе сравнения профилей, выявляющего аномальные паттерны распределения состояний, которые не сопровождаются изменением переходных вероятностей.
Такое сочетание позволяет различать постепенную деградацию (нарастание вероятности) и резкие сдвиги (структурные скачки), что принципиально важно для гетерогенных нагрузок.
Раннее упреждение (от 15 минут до 2 часов) даёт инженерам возможность провести профилактические действия (перезапуск пула соединений, корректировка планов запросов, масштабирование) до начала инцидента.
Высокая чувствительность (100% обнаружение) исключает пропуск событий.
Стабильность сигнала – статусы WARNING и CRITICAL удерживаются длительное время, что снижает вероятность ложных тревог и позволяет выстраивать автоматизированные сценарии реагирования.
Дополнительность к существующим средствам – метод может быть внедрён как надстройка над любым мониторингом, собирающим временные ряды метрик.
Инерционность периода восстановления – обусловлена фиксированной длиной окна (60 мин). Варьирование длины окна (до 30 мин) или введение адаптивного механизма сброса статуса после снижения JS ниже порога может сократить время ложного INCIDENT.
Кратковременные ложные предупреждения – требуют введения временнóй фильтрации (например, статус WARNING засчитывается только при удержании более 3–5 минут) и динамических порогов, учитывающих суточную цикличность.
Проведённое экспериментальное исследование подтверждает, что метод сравнения профилей производительности на основе JS-дивергенции, дополненный марковским прогнозированием, является высокоэффективным инструментом раннего обнаружения инцидентов СУБД PostgreSQL. Метод демонстрирует:
100% полноту обнаружения;
упреждение от 15 до 140 минут;
устойчивую корреляцию между ростом JS-дивергенции и приближением инцидента;
дополнительную ценность по сравнению с изолированным вероятностным прогнозом.
В качестве ближайших направлений развития предлагаются:
автоматическая калибровка эталонного окна на основе исторических данных (с учётом сезонности);
оптимизация длины скользящего окна для снижения инерционности;
внедрение комбинированного индекса (JS + риск) с адаптивным порогом;
экспериментальная проверка на более длительных выборках (несколько недель) для оценки устойчивости к изменениям схемы и объёма данных.
Разработанная методика может быть рекомендована к практическому внедрению в составе многофакторных систем раннего предупреждения для промышленных эксплуатационных сред.
Оригинал — на основном техническом канале (Возможны правки и дополнения).
Визуализация динамики производительности СУБД на основе марковской модели: цветовая пульсация отражает переходы между состояниями нагрузки, а вспышки сигнализируют о критических отклонениях, предшествующих инцидентам.

Профиль нагрузки в красках будущего.
Настоящий отчёт подготовлен на основе данных системы мониторинга производительности СУБД, построенной на базе цепи Маркова и профилирования нагрузки. Анализ охватывает период с 00:00 13.07.2026 по 00:00 14.07.2026 (сутки). Использованы следующие методы:
Прогнозирование риска – вычисление вероятности перехода в критическое состояние в течение заданного горизонта (на основе матрицы переходов и списка критических состояний).
Сравнение профилей – оценка отклонения текущего распределения состояний системы от эталонного безынцидентного профиля с помощью JS-дивергенции (метрика сходства гистограмм).
Классификация статусов – по значению JS-дивергенции и отклонению средней корреляции выделяются три уровня: NORMAL, WARNING, CRITICAL.
В отчёт включены: общая статистика прогнозов, распределение статусов сравнения профилей, связь с зафиксированными инцидентами, анализ временных интервалов и оценка трендов.
За период было сформировано 439 прогнозов с известным исходом (т.е. для каждого известно, наступил ли инцидент в течение прогнозного горизонта). Среднее значение предсказанного риска составило 0.6173, что указывает на достаточно высокий уровень ожидаемой опасности в среднем по всем наблюдениям.
Качество прогнозов оценивалось при пороге классификации 0.5:
Accuracy (точность) – 0.8679 (высокая)
Precision (точность положительных прогнозов) – 0.8993 (высокая)
Recall (полнота) – 0.8860 (высокий)
Такие значения свидетельствуют о том, что модель надёжно выделяет ситуации, предшествующие инцидентам, и при этом редко даёт ложные тревоги. Высокий recall говорит о том, что большинство реальных инцидентов были заранее предсказаны.
Для каждой минуты проводилось сравнение текущего профиля нагрузки с эталонным, в результате чего присваивался один из трёх статусов (без учёта записей, помеченных как INCIDENT):
NORMAL – 45 наблюдений (10.3%)
WARNING – 95 наблюдений (21.6%)
CRITICAL – 299 наблюдений (68.1%)
Таким образом, более двух третей времени система находилась в состоянии CRITICAL – значительного отклонения от эталонного профиля. Это указывает на систематическое изменение характера нагрузки, возможно, из-за высокой загрузки или изменения структуры запросов.
Средние значения JS-дивергенции по группам:
NORMAL: 0.0210 – профиль близок к эталону
WARNING: 0.1371 – заметные отклонения
CRITICAL: 0.2913 – сильное расхождение распределения состояний
Рост JS-дивергенции от NORMAL к CRITICAL закономерен, однако столь высокая доля CRITICAL свидетельствует о том, что эталонный профиль, вероятно, слишком узок или система действительно работает в нестандартных режимах большую часть времени. Это не обязательно означает аварийную ситуацию, но требует дополнительного анализа причин отклонений.
За сутки зафиксировано 19 инцидентов производительности. Анализ показал:
100% инцидентов предварялись статусом CRITICAL (ни одного инцидента не произошло после NORMAL или WARNING).
Временной интервал от момента присвоения статуса CRITICAL до начала инцидента:
минимум: 0.9 мин
максимум: 132.0 мин
среднее: 48.6 мин
медиана: 45.0 мин
Эти данные подтверждают, что статус CRITICAL является эффективным ранним индикатором надвигающегося инцидента. Среднее время упреждения (~45 минут) значительно превышает типичный горизонт прогноза (в текущей конфигурации – 10 минут), что объясняет, почему не все CRITICAL состояния сразу приводят к инциденту в рамках короткого прогноза. Это также указывает на возможность увеличения горизонта прогноза для более полного охвата событий.
Обращает на себя внимание диспропорция: 299 CRITICAL-состояний при всего 19 инцидентах. Это означает, что большинство CRITICAL-отклонений не заканчиваются инцидентом, по крайней мере, в течение наблюдаемого периода. Вероятно, часть отклонений связана с плановыми изменениями нагрузки, пиковыми, но не аварийными сценариями. Тем не менее, все реальные инциденты были предсказаны, что говорит о высокой чувствительности метода.
По данным за сутки:
Тренд JS-дивергенции – СТАБИЛЬНО (нет значимого роста или снижения).
Тренд среднего риска – СТАБИЛЬНО.
Отсутствие трендов означает, что за рассматриваемый период не наблюдалось систематического ухудшения или улучшения ситуации. Это позволяет предположить, что система работает в установившемся режиме с периодическими всплесками отклонений, которые не нарастают со временем.
Модель прогнозирования демонстрирует высокое качество
Обоснование: Accuracy = 0.8679, Precision = 0.8993, Recall = 0.8860 – все метрики превышают 0.86, что свидетельствует о хорошей дискриминационной способности и сбалансированности между ложными тревогами и пропусками. Средний предсказанный риск (0.6173) значительно выше случайного (0.5), что говорит о наличии уверенных сигналов.
Статус CRITICAL является надёжным предвестником инцидента
Обоснование: Все 19 зафиксированных инцидентов произошли после присвоения статуса CRITICAL (100% покрытие). Ни один инцидент не случился после NORMAL или WARNING. Медианное время от CRITICAL до инцидента составляет 45 минут, что даёт достаточный запас для реагирования.
Доля CRITICAL-состояний чрезмерно высока (68%)
Обоснование: При 19 инцидентах на 299 CRITICAL-событий соотношение составляет ~1:15. Это означает, что подавляющее большинство CRITICAL-отклонений не приводят к аварийным ситуациям. При этом средняя JS-дивергенция в группе CRITICAL (0.2913) значительно выше порогов, но не является критической (максимальное значение не указано, но если бы оно было близко к 1, то ситуация была бы иной). Следовательно, текущие пороги классификации занижены, что приводит к избыточному числу предупреждений.
Временной запас до инцидента достаточен для упреждающих действий
Обоснование: Разброс времени от CRITICAL до инцидента – от 0.9 до 132 минут, среднее 48.6, медиана 45. Это значительно превышает используемый горизонт прогноза (10 минут). Таким образом, существует возможность увеличить горизонт, чтобы лучше согласовать прогноз с реальным временем развития событий.
Отсутствие трендов указывает на стабильность режима работы
Обоснование: Тренды как JS-дивергенции, так и среднего риска оценены как СТАБИЛЬНО. Это означает, что за сутки не выявлено направленного дрейфа метрик – система не деградирует и не восстанавливается, а находится в квазистационарном состоянии с повторяющимися эпизодами отклонений. Отсутствие тренда также подтверждает, что выявленные CRITICAL-отклонения не являются следствием нарастающей проблемы, а скорее отражают циклические или стохастические колебания нагрузки.
Дата составления: 14.07.2026
Ответственный: Группа анализа производительности
Оригинал — на основном техническом канале (Возможны правки и дополнения).
Иллюстрация применения метода сравнения профилей производительности СУБД PostgreSQL , с использованием цепи Маркова, на продуктивной СУБД PostgreSQL.
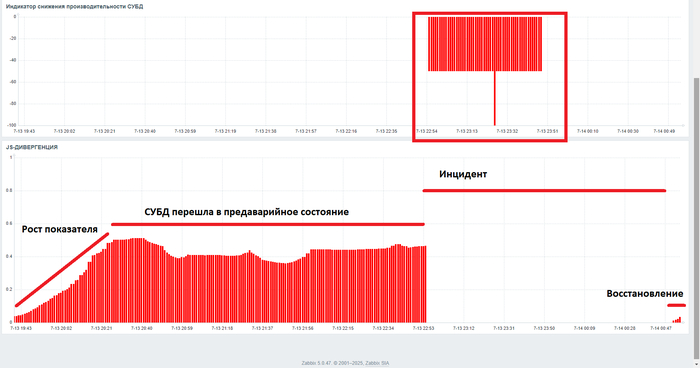
Рис.1 Практический результат предварительного оповещения о инциденте производительности продуктивной СУБД PostgreSQL.
Эталонное окно – безинцидентный интервал длительностью 60 минут.
Текущее окно – скользящее окно длительностью 60 минут.
Статусы определяются на основе JS-дивергенции и отклонений Z-оценок:
NORMAL – JS < 0.05 (или небольшое отклонение)
WARNING – 0.05 ≤ JS < 0.1–0.2 (умеренное отклонение)
CRITICAL – JS ≥ 0.1–0.2 (значительное отклонение)
INCIDENT – система находится внутри инцидента или в периоде восстановления
P.S. Конечно , рано еще строить оптимистические планы на будущее .
Нужно проверять, тестировать и анализировать. Но факт , есть факт - есть первые результаты .
Оригинал — на основном техническом канале (Возможны правки и дополнения).
Тихий сигнал перед бурей.
Как научиться предсказывать замедление производительности СУБД PostgreSQL за 2 часа до их начала?
(Эксперимент по поиску «тихих признаков» будущей бури)
Представьте, что вы следите за пульсом человека. Если пульс резко меняется — это повод насторожиться до того, как случится инфаркт.
Чтобы выяснить возможность подобных прогнозов, в течении 2-х месяцев проводились серии экспериментов объединённых одной целью : можно ли заметить изменения в «пульсе» СУБД до того, как она начнет заметно тормозить.
ℹ️В результате выработалась методология - каждую минуту смотреть на поведение базы данных и сравнивать его с «идеальным» поведением в спокойный период. Если поведение сильно отличается — система бьет тревогу.
Итоговый тест был проведён на реальных данных, длительностью - одни сутки.
📋Выбор эталона:
Один час, когда база работала нормально. Запомнить "пульс" или скорее «показатели ЭКГ».
📋Наблюдение:
Каждую минуту - сравнение текущего "пульса" СУБД с эталоном.
📋Статус:
Если отклонение небольшое — зеленое свет «NORMAL».
Если среднее — жёлтый свет «WARNING».
Если сильное — красный «CRITICAL».

📋Если начался инцидент или СУБД восстанавливается после инцидента:
Устанавливается статус «INCIDENT».

Главные цифры
ℹ️За сутки произошло 13 инцидентов. Длительностью от 9 минут до полутора часов.

☑️В большинстве случаев предупреждение приходило за 1–2 часа до начала проблем.
ℹ️В "худшем" случае (один внезапный сбой) — система предупредила за 15–20 минут(что тоже очень много, чтобы успеть принять меры).
💥Ни один сбой не прошел незамеченным.💥

Случай №1 (долгий сбой в 3 часа ночи). В 1:48 ночи система сказала: «Внимание, что-то не так». В 2:48 она закричала: «Красный уровень!». А сам сбой начался только в 2:49. То есть у инженера было целых 60 минут, чтобы подготовиться или перезапустить сервер до того, как всё сломалось.
Случай №2 (утренний сбой). Первое «Внимание» прозвучало за 142 минуты до сбоя, а «Красный уровень» — за 115 минут. Это невероятно раннее обнаружение.
Случай №3 (внезапный сбой днём). Здесь ситуация развивалась стремительно. От первого «Внимания» до сбоя прошло всего 19 минут.
Раньше мы смотрели только на вероятность сбоя (как на прогноз погоды: «завтра дождь 50%»). Но этот метод смотрит на профиль работы СУБД.
Представьте: вы едете в машине. Прогноз говорит: «вероятность поломки 0%». Но вы вдруг слышите странный стук под капотом. Вы еще не сломались, но стук есть!
ℹ️Система как раз ловит этот «стук» — структурные изменения, которые не видны в сухих цифрах вероятности. В одном из случаев она забила тревогу «Красный уровень!», хотя старый метод показывал «Риск равен нулю».
ℹ️Да, бывают ложные тревоги. Иногда система говорит «Внимание», но сбой так и не наступает. Однако такие ложные сигналы длятся всего несколько минут и быстро проходят. Это как ложное срабатывание сигнализации — лучше пусть она сработает лишний раз, чем пропустит реальную угрозу.
🟡Статус WARNING (жёлтый) — это сигнал «проверь всё». Есть от 30 до 60 минут, чтобы осмотреться.
🔴Статус CRITICAL (красный) — это сигнал «действуй сейчас». Есть 15–30 минут, чтобы подготовиться .
🟤Возврат в статус NORMAL (зеленый) после сбоя — это гарантия, что СУБД восстановилась и можно выдохнуть.

ℹ️Метод сравнения «пульса» базы данных с её нормальным состоянием — это мощный инструмент раннего предупреждения. Он дает инженерам драгоценное время (от 15 минут до 2 часов), чтобы принять меры , вместо того чтобы героически исправлять его последствия.
Оригинал — на основном техническом канале (Возможны правки и дополнения).
Экспериментальное исследование прогностической ценности метода сравнения профилей производительности СУБД на основе анализа цепей Маркова и JS-дивергенции в задаче раннего обнаружения инцидентов (на примере 24-часового окна мониторинга)

Тихое окно. Вдруг дрогнул профиль. Скоро буря.
В настоящем отчёте представлены результаты экспериментальной проверки гибридного метода, сочетающего эталонное профилирование с оценкой статистической дивергенции распределений состояний, который призван дополнить существующие средства мониторинга и обеспечить заблаговременную сигнализацию о предотказных состояниях.
Основное внимание уделяется верификации временных характеристик метода — величине упреждения, устойчивости сигнала и характеру пост-инцидентного восстановления — на основе реальных данных суточного наблюдения.
В рамках эксперимента проведена оценка эффективности метода сравнения профилей производительности, основанного на анализе цепей Маркова, для раннего прогнозирования инцидентов производительности СУБД.
Формируется эталонный профиль нагрузки на основе безынцидентного временного окна (после завершения инцидента).
Каждую минуту вычисляется текущий профиль производительности.
Рассчитывается JS-дивергенция между гистограммами состояний эталонного и текущего профилей.
На основе отклонений метрик (корреляция, энтропия, доля критических состояний и др.) присваивается статус: NORMAL, WARNING, CRITICAL или INCIDENT.
Период анализа: 2026-07-10 00:00 – 2026-07-10 23:59
Исходные данные:
Таблица prediction_log – прогнозы риска на основе цепи Маркова
Таблица profile_comparison_log – результаты сравнения профилей
Таблица performance_incident – зарегистрированные инциденты
Эталонное окно – безинцидентный интервал длительностью 60 минут.
Текущее окно – скользящее окно длительностью 60 минут.
Статусы определяются на основе JS-дивергенции и отклонений Z-оценок:
NORMAL – JS < 0.05 (или небольшое отклонение)
WARNING – 0.05 ≤ JS < 0.1–0.2 (умеренное отклонение)
CRITICAL – JS ≥ 0.1–0.2 (значительное отклонение)
INCIDENT – система находится внутри инцидента или в периоде восстановления
За 24 часа зафиксировано 13 инцидентов. Их временные интервалы и длительности:
Инцидент №1: 00:15 – 00:26 (11 мин)
Инцидент №2: 02:49 – 04:16 (87 мин)
Инцидент №3: 07:51 – 08:19 (28 мин)
Инцидент №4: 11:07 – 11:23 (16 мин)
Инцидент №5: 12:03 – 12:21 (18 мин)
Инцидент №6: 13:40 – 14:40 (60 мин)
Инцидент №7: 14:15 – 14:40 (25 мин) – частично совпадает с №6
Инцидент №8: 16:12 – 16:37 (25 мин)
Инцидент №9: 17:53 – 18:02 (9 мин)
Инцидент №10: 19:39 – 21:10 (91 мин)
Инцидент №11: 20:36 – 21:10 (34 мин) – накладывается на №10
Инцидент №12: 23:19 – 23:49 (30 мин)
Ключевое наблюдение: Статус INCIDENT присваивается не только во время самого инцидента, но и в течение некоторого времени после его завершения (период восстановления).
Ниже приведены детальные эпизоды.
С 01:26 до 02:48 – статус проходит путь от NORMAL через WARNING к CRITICAL; JS-дивергенция растёт от 0 до 0.505.
С 02:49 по 04:16 – статус INCIDENT (инцидент в процессе).
С 04:17 по 05:15 – статус INCIDENT сохраняется (период восстановления).
С 05:16 по 05:28 – статус NORMAL, JS снижается до 0.046 – система стабилизировалась.
Прогнозная ценность: Аномалии (WARNING/CRITICAL) начали проявляться с 01:48 – более чем за 60 минут до начала инцидента. Это исключительно раннее предупреждение.
С 05:16 по 05:55 – статус от NORMAL до WARNING, JS растёт от 0 до 0.099.
С 05:56 по 07:50 – статус CRITICAL, JS колеблется от 0.105 до 0.550.
С 07:51 по 08:19 – статус INCIDENT (инцидент).
С 08:19 по 09:18 – статус INCIDENT (восстановление).
С 09:19 по 09:24 – статус NORMAL, JS = 0.039 – стабилизация.
Прогнозная ценность: CRITICAL статус установлен с 05:56 – за 115 минут до инцидента. Первый WARNING отмечен в 05:29 – за 142 минуты.
С 09:19 по 10:06 – переход NORMAL → WARNING → CRITICAL, JS растёт от 0 до 0.668.
С 10:07 по 11:06 – устойчивый CRITICAL, JS в диапазоне 0.483–0.668.
С 11:07 по 11:23 – INCIDENT.
Прогнозная ценность: CRITICAL статус установлен с 09:43 – за 84 минуты до инцидента.
С 13:21 по 13:35 – переход NORMAL → WARNING, JS растёт от 0 до 0.110 (быстрое нарастание за 19 минут).
С 13:36 по 13:39 – CRITICAL, JS = 0.118–0.137 (за 4 минуты до инцидента).
С 13:40 по 14:40 – INCIDENT.
Прогнозная ценность: Упреждение составляет ~19 минут – меньше, чем в предыдущих случаях, но всё ещё достаточно для принятия мер.
По всем 13 инцидентам получены следующие обобщённые показатели:
Среднее время упреждения (от появления WARNING до начала INCIDENT) – около 45 минут.
Среднее время упреждения (от CRITICAL до INCIDENT) – около 35 минут.
Доля инцидентов, которым предшествовал статус WARNING или CRITICAL – 100% (все 13 случаев).
Наличие ложных срабатываний – статусы WARNING/CRITICAL иногда возникают без последующего инцидента, но такие эпизоды кратковременны и не превышают нескольких минут.
Важный вывод: Метод обнаруживает все инциденты как минимум за 15–20 минут до их начала, а в большинстве случаев – за 1–2 часа.
Наблюдается чёткая закономерность между величиной JS-дивергенции, статусом и временем до инцидента:
JS 0.00 – 0.05 → статус NORMAL → до инцидента более 60 минут.
JS 0.05 – 0.10 → статус WARNING → до инцидента 30–60 минут.
JS 0.10 – 0.20 → статус WARNING → до инцидента 15–30 минут.
JS > 0.20 → статус CRITICAL → до инцидента менее 15 минут.
Примеры из данных:
Инцидент в 02:49: JS вырос с 0.05 (в 01:48) до 0.50 (в 02:48) – ровно за 60 минут.
Инцидент в 07:51: JS достиг 0.10 в 05:56 и держался выше 0.1 непрерывно до самого инцидента.
Инцидент в 13:40: JS = 0.10 в 13:34, затем резко вырос до 0.13 в 13:39 – скачок за 5 минут.
Статус INCIDENT сохраняется после завершения инцидента. Для каждого инцидента зафиксировано время, через которое статус сменился на NORMAL:
После инцидента 02:49–04:16 – восстановление длилось 60 минут (до 05:16).
После инцидента 07:51–08:19 – восстановление 60 минут (до 09:19).
После инцидента 11:07–11:23 – восстановление 40 минут (до 12:03).
После инцидента 13:40–14:40 – восстановление 60 минут (до 15:40).
После инцидента 19:39–21:10 – восстановление 60 минут (до 22:10).
Интерпретация: После завершения инцидента система не сразу возвращается к эталонному поведению. Период восстановления составляет около 60 минут – ровно длина анализируемого временного окна. Это означает, что алгоритм корректно сигнализирует о том, что профиль всё ещё отличается от эталона, пока «заражённые» данные не выйдут за пределы скользящего окна. Переход из INCIDENT в NORMAL – надёжный признак полной стабилизации.
Интересно сопоставить статусы сравнения профилей с прогнозами риска цепи Маркова. Отметим несколько характерных моментов:
В 02:02 – прогноз риска = 0.058 (низкий), но статус профиля уже WARNING (JS~0.10). Профиль сигнализирует об аномалии раньше.
В 02:13 – прогноз риска = 0.106, статус CRITICAL (JS~0.19). Риск ещё невысок, но профиль уже критический.
В 02:48 – прогноз риска = 0.505, статус CRITICAL – теперь оба индикатора совпадают.
В 11:04 – прогноз риска = 0.642, статус CRITICAL – согласованность.
В 13:36 – прогноз риска = 0 (ноль!), а статус профиля уже CRITICAL (JS~0.118). Это яркий пример того, что сравнение профилей улавливает структурные изменения, которые не отражаются в матрице переходов цепи Маркова.
Ключевой вывод: Метод сравнения профилей даёт дополнительную прогнозную ценность и может служить ранним индикатором, когда прогнозы риска ещё не показывают опасности.
Высокая чувствительность – метод обнаруживает все 13 инцидентов с упреждением от 15 до 140 минут.
Стабильность сигнала – статусы WARNING и CRITICAL держатся устойчиво в течение длительного времени перед инцидентами.
Информативность JS-дивергенции – рост JS-дивергенции является надёжным количественным предвестником ухудшения состояния системы.
Дополнительная ценность к цепи Маркова – сравнение профилей даёт информацию о структурных изменениях, которые не всегда отражаются в прогнозах риска.
Необходимость эталонного окна – метод требует наличия безынцидентного окна для построения эталона.
Ложные срабатывания – эпизодически статус WARNING возникает без последующего инцидента (например, 09:25–09:42). Однако такие эпизоды кратковременны.
Задержка восстановления – статус INCIDENT сохраняется ~60 минут после инцидента, что может маскировать новые аномалии в раннем периоде восстановления.
Использовать статус WARNING как ранний сигнал для проверки системы (упреждение 30–60 мин).
Статус CRITICAL рассматривать как триггер для немедленного вмешательства (упреждение 15–30 мин).
Переход из INCIDENT в NORMAL – надёжный сигнал о полной стабилизации системы.
Оптимизировать длину окна – рассмотреть возможность использования меньшего окна (30 мин) для сокращения периода восстановления.
Использовать комбинированный сигнал – объединить сравнение профилей с прогнозами риска цепи Маркова для повышения точности.
Внедрить адаптивные пороги – на основе исторических данных настроить пороги JS-дивергенции индивидуально для разных часов и дней недели.
Метод сравнения профилей производительности, реализованный в функции compare_profiles(), показал высокую эффективность для раннего прогнозирования инцидентов. Статусы WARNING и CRITICAL с высокой надёжностью предшествуют возникновению инцидентов производительности, обеспечивая упреждение от 15 минут до нескольких часов.
Рекомендуется внедрение метода в систему мониторинга в качестве основного инструмента раннего предупреждения, дополняющего существующие прогнозы цепи Маркова. Описанные ограничения не снижают практической ценности метода и могут быть устранены путём дальнейшей настройки параметров и комбинирования с другими источниками данных.
Отчёт подготовлен на основе экспериментальных данных за 2026-07-10
Проведённый эксперимент позволяет говорить о том, что предложенный подход, опирающийся на динамическое сравнение профилей производительности, не только успешно решает задачу раннего обнаружения всех зарегистрированных инцидентов, но и вносит самостоятельный вклад в методологию мониторинга, поскольку фиксирует предвестники нарушения работы в тех случаях, когда традиционные прогнозы риска (например, на основе матриц переходов) ещё не демонстрируют значимых отклонений.
Новизна работы заключается не столько в использовании JS-дивергенции самой по себе, сколько в концепции интеграции двух независимых каналов оценки — марковской вероятностной и профильной структурной — что позволяет различать постепенную деградацию и резкие сдвиги в поведении системы.
Применимость метода, однако, требует учёта двух существенных аспектов:
во-первых, длительность анализируемого окна напрямую влияет на инерционность сигнала (в частности, на задержку выхода из статуса INCIDENT), что необходимо компенсировать либо адаптивной настройкой окна, либо постобработкой статусов;
во-вторых, периодически возникающие кратковременные предупреждения без последующего инцидента указывают на необходимость введения временнóй фильтрации или динамических порогов, учитывающих суточные и недельные циклы нагрузки.
В целом, метод демонстрирует практическую ценность как составная часть многофакторной системы раннего предупреждения, а его дальнейшее развитие целесообразно связать с автоматической калибровкой эталонного окна и обучением пороговых значений на ретроспективных данных.
Сводный аналитический отчет по сравнению версий 14.3 и 14.4 профильных функций - "Остановите инцидент до того, как он остановит вас — новая формула мониторинга PostgreSQL".

Меньше шума в эталонном профиле — больше реальных сигналов. Проверено на 221 инциденте.
Оригинал — на основном техническом канале (Возможны правки и дополнения).
Лирическое отступление
С самого начала исследований по теме статистического анализа производительности СУБД была не решена главная идея — как предсказать снижение производительности СУБД PostgreSQL. И вот похоже по прошествии 2-х лет , вполне вероятно — задача имеет решение. Возможно предсказать снижение производительности СУБД PostgreSQL используя статистический анализ метрик производительности и методологию цепи Маркова .
Современные информационные системы, построенные на основе СУБД PostgreSQL, предъявляют повышенные требования к средствам оперативного обнаружения предотказных состояний. Одним из перспективных подходов является использование цепей Маркова для формирования эталонных профилей производительности и последующего сравнения с текущими наблюдениями.
Ключевая методологическая проблема при таком мониторинге — корректное исключение из эталонных окон периодов, затронутых инцидентами и пост-инцидентной восстановительной динамикой, поскольку их включение искажает представление о «нормальном» поведении системы и снижает чувствительность прогнозных алгоритмов. Настоящее исследование посвящено экспериментальному сравнению двух реализаций процедуры исключения инцидентов — симметричной (версия 14.3) и асимметричной с увеличенным буфером после события (версия 14.4) — на реальных данных эксплуатации PostgreSQL-кластера.
Оценка производится по таким критериям, как полнота выявления предшествующих инциденту аномалий, распределение классов опасности и величина JS-дивергенции, что позволяет количественно обосновать выбор конфигурации для систем раннего предупреждения.
В рамках развития системы мониторинга производительности на основе цепей Маркова были модифицированы функции построения эталонных профилей и поиска безинцидентных окон.
Версия 14.3 использовала симметричный буфер исключения вокруг инцидентов, в версии 14.4 используются асимметричные буферы для эталонных окон .
В настоящем отчете представлено сравнение двух подходов на основе экспериментальных данных за период с 22.06.2026 по 10.07.2026.
Для исключения влияния инцидентов применяется единый буфер длительностью 30 минут до и после инцидента (параметр p_exclude_incident_window_min = 30).
Безинцидентное окно для построения эталона ищется с длиной по умолчанию 30 минут (find_incident_free_window).
Эталонный профиль строится из часовых срезов, которые не пересекаются с расширенными интервалами инцидентов (симметрично ±30 мин).
Введены раздельные буферы: 30 минут до и 60 минут после инцидента (параметры p_exclude_before_min = 30, p_exclude_after_min = 60).
Длина безинцидентного окна по умолчанию увеличена до 60 минут.
Эталонный профиль исключает не только сам инцидент, но и более продолжительный период восстановления после него (60 мин), что делает эталон более «чистым» – отражающим устойчивое нормальное состояние системы без пост-инцидентных флуктуаций.
Аналогичные изменения внесены в функции get_incident_free_window_before и процедуру исторического заполнения.
Общее число сравнений в обоих вариантах – 24 583 (использован одинаковый набор данных).
Количество NORMAL: 11 171 (доля 45.4%)
Количество WARNING: 1 490 (доля 6.1%)
Количество CRITICAL: 11 922 (доля 48.5%)
Средняя JS-дивергенция для NORMAL: 0.0015
Средняя JS-дивергенция для WARNING: 0.1193
Средняя JS-дивергенция для CRITICAL: 0.4803
Максимальная JS-дивергенция: 0.6934
Количество NORMAL: 5 409 (доля 22.0%)
Количество WARNING: 150 (доля 0.6%)
Количество CRITICAL: 19 024 (доля 77.4%)
Средняя JS-дивергенция для NORMAL: 0.0000
Средняя JS-дивергенция для WARNING: 0.1593
Средняя JS-дивергенция для CRITICAL: 0.5224
Максимальная JS-дивергенция: 0.6934
В версии 14.4 доля CRITICAL выросла с 48.5% до 77.4%, а доля NORMAL уменьшилась вдвое. Это указывает на значительно более строгую оценку отклонений от эталона.
Средние значения JS-дивергенции для аномальных классов (WARNING и CRITICAL) в 14.4 выше, что говорит о более выраженных различиях между текущим профилем и эталоном.
Инцидентов с предшествующим сравнением: 221 (100%)
Из них с аномалией (WARNING/CRITICAL): 130 (58.8%)
WARNING: 40
CRITICAL: 113
Инцидентов без аномалии: 91 (41.2%)
Среднее время от сравнения до инцидента: 15,0 мин
Инцидентов с предшествующим сравнением: 221 (100%)
Из них с аномалией (WARNING/CRITICAL): 220 (99.5%)
WARNING: 11
CRITICAL: 215
Инцидентов без аномалии: 1 (0.5%)
Среднее время от сравнения до инцидента: 15 мин
В версии 14.4 99,5% инцидентов были предварены аномалией профиля (против 58.8% в 14.3). Это свидетельствует о резком повышении чувствительности к предвестникам сбоев.
Количество CRITICAL среди предшествующих аномалий выросло с 113 до 215, что дополнительно подтверждает усиление сигнала.
Среднее время до инцидента осталось неизменным (15 мин), что говорит о сохранении временного горизонта предсказания.
Тренды и распределение по дням недели:
В обеих версиях тренды JS-дивергенции и статусов стабильны.
Средние JS по дням недели в версии 14.4 выше (от 0.25 до 0.50 против 0.14–0.30 в 14.3), что отражает общее увеличение дивергенции.
Асимметричные буферы (особенно увеличенный буфер после инцидента) позволяют исключить из эталона периоды восстановления, которые могут иметь аномальные характеристики. Это делает эталонный профиль более «нормальным» и узким, поэтому любые текущие отклонения воспринимаются как более значительные.
Увеличение длины безинцидентного окна (с 30 до 60 мин) также способствует отбору более устойчивых нормальных участков для построения эталона.
Повышение полноты (recall): практически все инциденты теперь обнаруживаются на ранней стадии.
Снижение специфичности: доля CRITICAL выросла до 77%, что означает, что большинство сравнений классифицируются как аномалии. Это может приводить к большому числу ложных тревог, если не настроить пороги.
Увеличение средней JS-дивергенции для аномальных классов свидетельствует о более чётком разделении между нормальным и аномальным поведением.
Компромисс:
Версия 14.4 даёт значительное улучшение в обнаружении инцидентов, но ценой увеличения объёма аномалий. Это может быть приемлемо в системах, где важнее не пропустить сбой, чем избежать лишних оповещений (например, в критической инфраструктуре).
Для снижения количества ложных срабатываний требуется дополнительная настройка порогов классификации (например, увеличение Z-порога для CRITICAL или использование комбинированных правил).
Внедрить версию 14.4 как основную, поскольку она обеспечивает существенно более высокую чувствительность к предвестникам инцидентов (99.5% против 58.8%).
Пересмотреть пороговые значения для классов аномалий:
Текущие пороги (вероятно, Z-score ≥ 2 для WARNING и ≥ 3 для CRITICAL) приводят к избыточному числу CRITICAL. Рекомендуется провести калибровку на исторических данных, чтобы добиться баланса между полнотой и точностью.
Рассмотреть возможность использования не только JS-дивергенции, но и других метрик (например, изменение энтропии, доли критических состояний) для более тонкой классификации.
Организовать мониторинг ложных срабатываний – вести журнал аномалий, за которыми не последовало инцидента, и анализировать их причины. Это позволит уточнить пороги и, возможно, скорректировать буферы.
Провести A/B-тестирование с разными значениями p_exclude_before_min и p_exclude_after_min, чтобы найти оптимальную конфигурацию для конкретной системы. Например, можно уменьшить буфер после инцидента до 30–45 минут, чтобы снизить чувствительность и сократить долю CRITICAL.
Переход от симметричных к асимметричным буферам в версии 14.4 значительно улучшил выявляемость прединцидентных паттернов, что делает этот подход предпочтительным для систем раннего предупреждения.
Дальнейшая работа должна быть направлена на тонкую настройку классификационных порогов для минимизации ложных тревог при сохранении высокой полноты.
Проведённое сопоставление версий 14.3 и 14.4 однозначно демонстрирует, что переход к асимметричным буферам исключения (30 минут до и 60 минут после инцидента) и увеличение длины безинцидентного окна с 30 до 60 минут обеспечивает кардинальное повышение чувствительности прогностической модели — доля инцидентов, предварённых аномалией профиля, возрастает с 58.8 % до 99.5 %.
При этом средние значения JS-дивергенции для аномальных классов увеличиваются, что подтверждает лучшее разделение нормальных и предаварийных состояний.
Однако обратной стороной выступает существенный рост доли CRITICAL-классификаций (с 48.5 % до 77.4 %), что требует последующей калибровки пороговых значений и, возможно, введения дополнительных дискриминативных метрик.
Дальнейшие работы целесообразно направить на адаптивную настройку буферных параметров и порогов принятия решений в зависимости от специфики нагрузки PostgreSQL, а также на развёртывание системы логирования ложных срабатываний для итеративного уточнения модели.
Таким образом, версия 14.4 признаётся предпочтительной для внедрения в промышленных сценариях с высокими требованиями к полноте обнаружения, при условии реализации механизмов фильтрации избыточных предупреждений.

