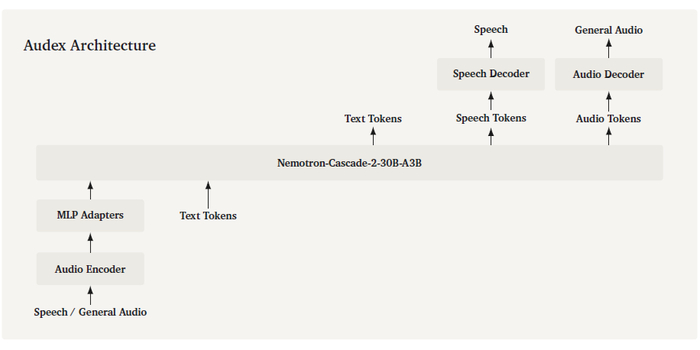
Вышла новая модель для генерации миров в реальном времени LingBot-World 2.0
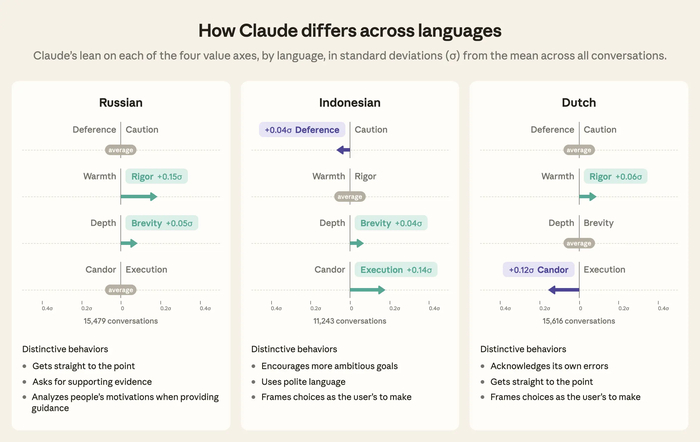
Доступна новая интерактивная модель LingBot-World 2.0 (LingBot-World-Infinity) (https://huggingface.co/collections/robbyant/lingbot-world-v2) для миров в реальном времени (720p, 60 fps, задержка менее 1 с).
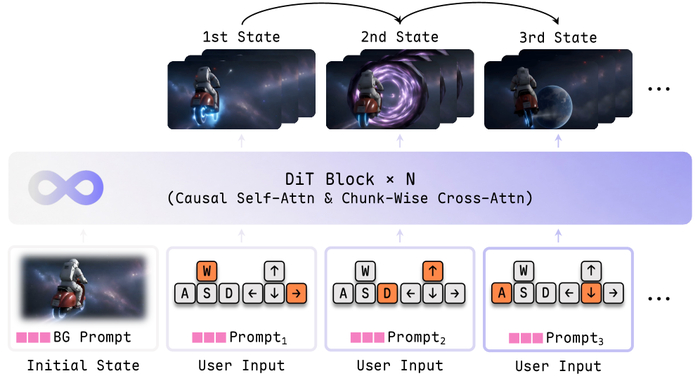
Всего ключевых улучшений четыре, включая неограниченный горизонт взаимодействия без дрейфа (каузальное предобучение), успешную дистилляцию до модели реального времени, широкий спектр действий (бой, стрельба из лука, заклинания, текстовая смена погоды и событий) и агентную обвязку, когда "пилот" управляет персонажем, "режиссёр" добавляет события, поддерживая нескольких игроков.
Чтобы охватить как можно больше устройств, есть основная 14B версия и облегчённая 1.3B версия для одного GPU.
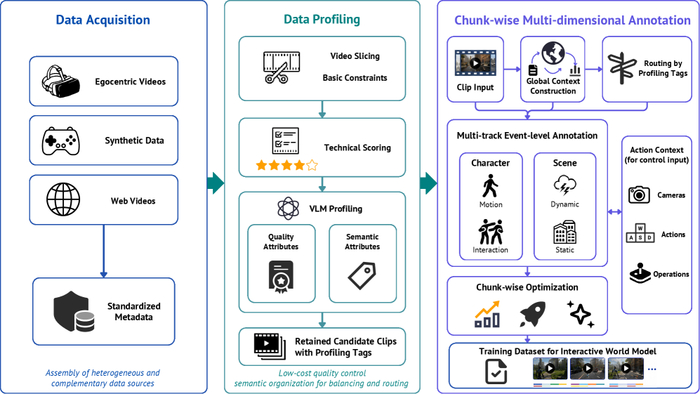
Данные собрали из эгоцентричных, синтетических и веб-видео, фильтруя их по качеству и VLM‑профилированию. Также добавили чанковые подписи с глобальным контекстом и многодорожечной событийной разметкой.
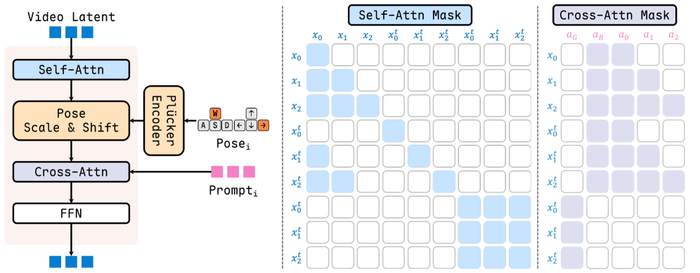
Обучение стартовало с претрейна при помощи каузальной видеомодели с MoBA‑маской (смесь авторегрессионного и двунаправленного внимания), противостоя накоплению ошибок, давая управление позами камеры и чанковыми текстовыми промтами. Затем посттренинг выполнил дистилляцию согласованности и DMD для ускорения и подавления дрейфа при долгих траекториях.
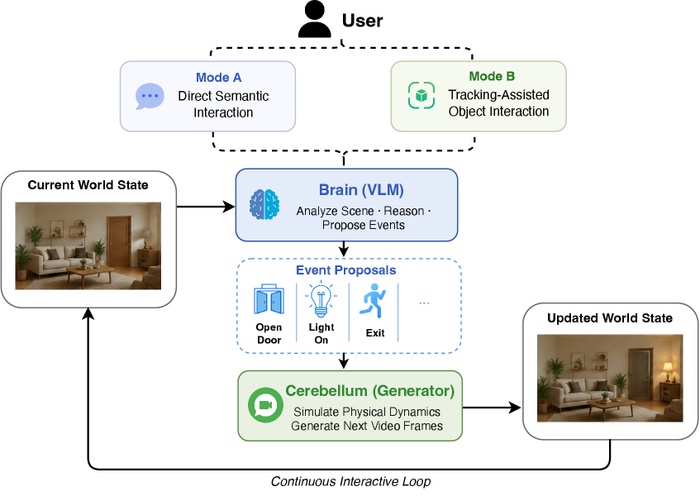
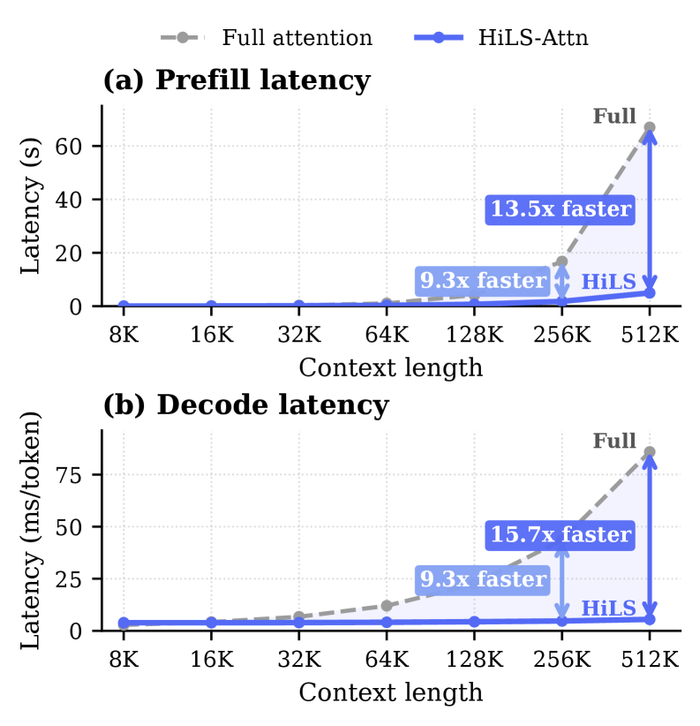
Вывод системно оптимизировали и использовали асинхронный пайплайн, где агентной оболочке анализировать сцену и предлагать события помог VLM-директор, а генератор-пилот реализовал динамику. Вдобавок взаимодействие может быть прямым семантическим или с отслеживанием объектов (SAM). Возможность текстового вмешательства позволила настраивать смену дня и ночи, погоду и появление объектов. Дополнительно применили пространственно-временной корректор и динамическое управление KV-кэшем.
Вывод происходит через основной вьюпорт, клавиши WASD/IJKL и панель событий (закреплённая и контекстная) на горячих клавишах.
Ограничениями сейчас остаются отсутствующая долговременная память (мир не помнит ранее посещённые области), постепенный дрейф стиля и внешности персонажей, несовершенное физическое понимание (пересечения объектов) и высокие требования к вычислительным ресурсам.
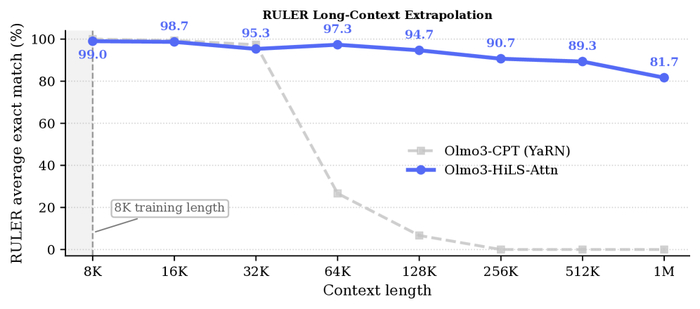
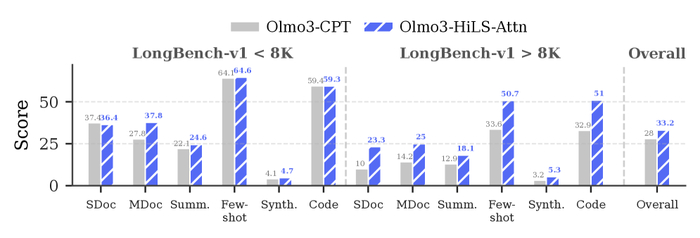
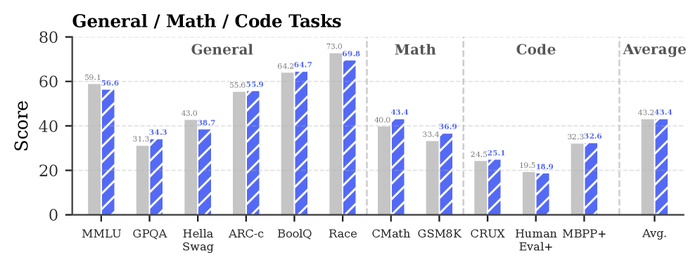
В результате модель превосходит открытые и закрытые аналоги, часами непрерывно генерируя без визуальной деградации, обладая богатой интерактивностью.