Открытый проект RuView на GitHub уже набрал 50 000+ звёзд, просто взорвался!
Полностью без камер, без ношения каких-либо устройств, только за счёт обычного Wi-Fi-сигнала дома, можно видеть сквозь стены:
- Сколько человек в соседней комнате, где они находятся, ходят они или лежат — всё видно - Реальное время отслеживания позы человека (17 ключевых точек)
- Во время сна автоматически измеряет дыхание и пульс
- При падении человека мгновенно срабатывает тревога, распознавание движений сверхточное
С помощью WiFi CSI + ИИ ваш домашний роутер превращается в невидимый радар! Без видео, без записи, приватность на максимуме, полностью соответствует GDPR, работает локально, без облака. ESP32 за несколько долларов — и можно играть, Docker без аппаратной части тоже позволяет сразу протестировать.
Депутат Госдумы и член комитета по информационной политике, информационным технологиям и связи — Антон Горелкин, прокомментировал сбои GitHub у части пользователей из России:
1/2
Какие выводы мы можем сделать из заявления Антона Горелкина в его Telegram-канале?
GitHub в России в обозримом будущем будет почти наверняка 100% заблокирован под любым высосанным предлогом (как LinkedIn в своё время).
Если РКН говорит, что он тут ни при чём, то значит почти наверняка причём, ведь он же не ложил половину Рунета и банковскую систему в попытках поймать Telegram за IP-шники.
Очередное бездумное кивание в сторону опыта Китая, у которого и опыт иной, и культурно-исторический контекст, контингент и среда конкуренции.
Нам постепенно подкручивают ручку на плите, прогревая лягушек, что жить под железным колпаком неплохо и вообще вон мировая практика (правда, практика эта пока что распространяется на Иран, Китай и Северную Корею).
Интересно, конечно, Microsoft россиян дискриминирует. Активацию Windows в регионе оставляет, сервисы и Copilot работоспособные и 16% пользователей на GitHub дискриминирует, а остальные 84 — нет.
Разумеется, всё вышесказанное до последнего слова — спекуляции и грязные инсинуации, порочащие доброе имя и репутацию порядочных людей и организаций. Вы люди достаточно неглупые для того, чтобы оглядеться вокруг и понять, что к чему.
"Российские разработчики заметили, что GitHub всё чаще оказывается недоступен. Процент неудачных соединений с платформой, которую многие отечественные программисты используют для совместной работы с кодом, превысил 16%. Интересно, что проблема коснулась только пользователей из РФ - и поскольку РКН сообщает, что не ограничивает работу GitHub, остается лишь один вариант: сознательная дискриминация российских пользователей администрацией платформы. Понятно, что большинство программистов от политики далеки. Возможно, они не в курсе, что Git Hub уже давно принадлежит Microsoft. Эта компания не просто ушла из России, но занимается откровенным вредительством (чего, например, стоит тенденциозное «исследование» уровня внедрения ИИ). Так что не нужно удивляться проблемам с доступом к GitHub с территории РФ – думаю, что количество неудачных соединений с 16% уже скоро достигнет всех 100%. Поэтому я бы рекомендовал нашим разработчикам срочно переносить свои проекты на другие Git-репозитории. Да, за многие годы (и задолго до прихода Microsoft) GitHub стал не просто отраслевым стандартом, а центральной точкой многих систем. Но от этой зависимости пора уходить – тем более есть хорошие отечественные аналоги (в том числе с нейросетевыми ассистентами не хуже, чем Copilot)."
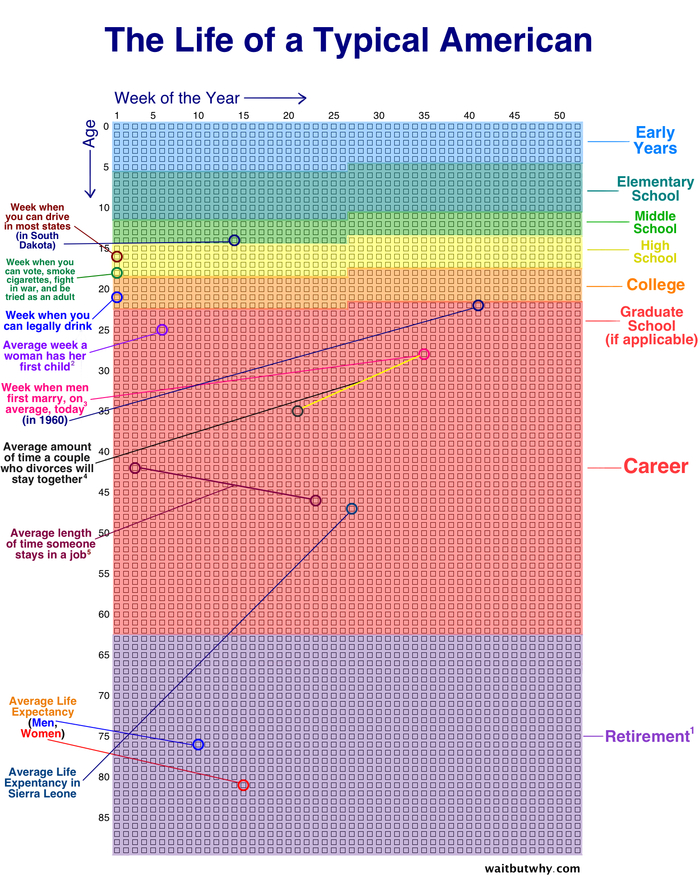
Всем привет! У человека в среднем около 4000 недель жизни. Четыре тысячи. Если нарисовать каждую неделю как маленькую клеточку — вся ваша жизнь поместится на один экран. Вот прям вся. От рождения до смерти. Мне 37 — значит примерно 1900 клеток уже закрашены, а оставшиеся… ну, это мы ещё посчитаем.
Вся жизнь на одной картинке
Эта концепция не моя и не новая — но на днях она всплыла в одном бизнес‑чате. Товарищ скинул скриншот из бота который как раз рисует такой grid. Закрашивает прожитые недели, оставляет пустые те что впереди. Красиво, минималистично, грустно. И я спросил: «А тебя это не тревожит?»
Тот самый скриншот из бота
Потому что у меня такие штуки вызывают именно неврозность. Смотри — ты получаешь ровно один сигнал и он негативный. Осталось мало. Прошло много. Тик‑так. Не знаю как у вас, но у меня от этого не мотивация появляется, а скорее лёгкая паника. Вазы с шариками из которых каждый день вынимаешь один, календари с крестиками, обратные отсчётики — всё одно и то же. Тебе показывают что уходит, но не показывают что ты сделал.
И я подумал — может проблема в том, что нет позитивного подкрепления? Я хочу видеть не только сколько прошло и сколько осталось в лучшем случае, но и что хорошего я сделал. Чтобы прожитые клетки были не «потрачено», а «сделано».
Меня зовут Илья, я блогер, основатель сервиса для генерации изображений ArtGeneration.me и просто фанат нейросетей. То что я не разработчик — звучит всё менее убедительно, поэтому скажу иначе: я не разработчик в традиционном понимании этого слова. Я действительно разрабатываю, но делаю это с помощью нейросетей. А 20 лет в роли PM и продакта дают достаточно навыков чтобы вайбкодить — не боюсь этого слова — более‑менее разумно. И вот за последние полгода у меня не прошло ни дня без коммита в GitHub. Буквально каждый день. И тут щёлкнуло — у GitHub ведь уже есть contribution graph, похожая зелёная сетка в профиле. А что если совместить? Взять эти клеточки жизни и закрасить их не «прожил», а «закоммитил»?
Через полчаса я уже думал как разместить 4000 ячеек в браузере и не повесить его. Оказалось — не так чтобы очень просто.
❯ 4000 недель — откуда вообще эта идея
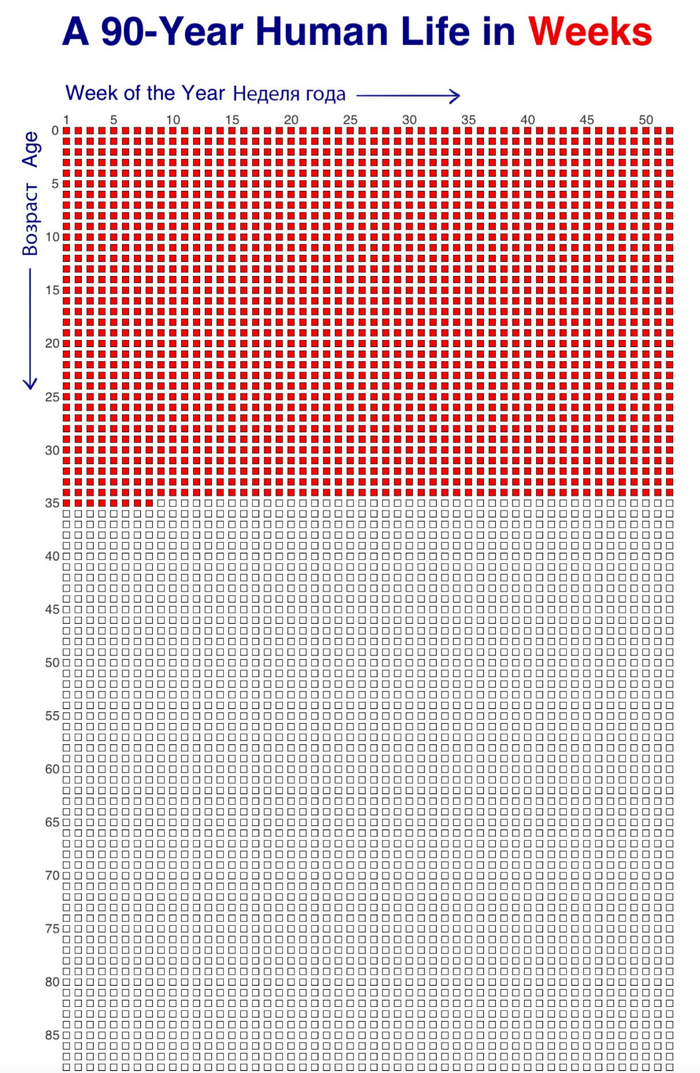
Концепцию «Your Life in Weeks» придумал не я. Её популяризировал Tim Urban в своём блоге WaitButWhy в 2014 году. Пост простой: берём среднюю продолжительность жизни в 90 лет, умножаем на 52 недели — получаем примерно 4680 клеток. Рисуем их сеткой. Одна клетка — одна неделя. И вот ваша жизнь.
Оригинальная визуализация из WaitButWhy — каждая точка это одна неделя жизни
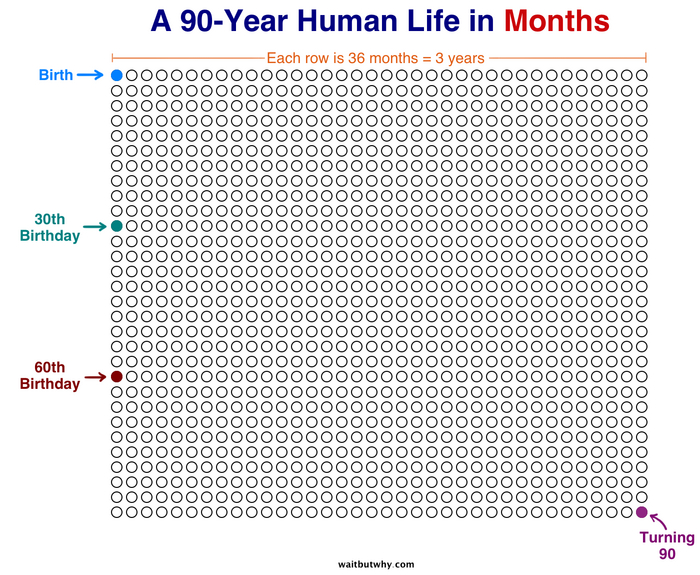
Пост стал вирусным, и не спроста. Есть что‑то пугающе отрезвляющее в том чтобы увидеть всю свою жизнь целиком. На одной картинке. Особенно когда половина уже закрашена. Тим нарисовал ту же сетку для разных периодов — сколько недель ты уже провёл в школе, сколько осталось до пенсии, сколько твоим родителям. Каждая версия бьёт по‑своему.
Рабочего времени не так уж и много, если учесть юность
С тех пор появилась куча мутаций. Постеры на стену, боты в телеграме, мобильные приложеня, даже физические штуки с шариками и песочницами. Идея одна и та же, обёртки разные.
И у всех одна проблема. Они показывают только расход. Клетка закрашена — неделя прошла. Точка. Никакой разницы между неделей когда ты запустил проект и неделей когда лежал на диване. Обе одинаково «потрачены».
Я вообще человек тревожный. И мне не нужно каждый день напоминание о смерти. Серьёзно. У меня от таких штук не появляется желание «ценить каждый момент» и «жить на полную». У меня появляется желание всё бросить и ничего не делать, потому что какой смысл если всё равно всё конечно. Знакомо? Если нет — вам повезло. А если да — вы понимаете зачем я полез делать свою версию.
❯ 4000 клеточек в браузере — не так просто как кажется
Ок, идея есть — берём сетку жизни и накладываем GitHub‑коммиты. Звучит просто. Вбил username, получил данные из API, нарисовал клеточкии. Что может пойти не так?
Ну, для начала — попробуйте нарисовать 4000 элементов так, чтобы они все помещались на экран, были различимы, не тормозили и при этом хорошо выглядели на мобилке. Я серьёзно, попробуйте. Это 52 столбца на 80 строк. На десктопе ещё ладно — 8 пикселей на клетку, всё влезает. А на телефоне? 5 пикселей, и ты крутишь размеры туда‑сюда пытаясь найти баланс между «вижу отдельные клетки» и «вижу общую картину».
Сетка GitLife — каждая зелёная клетка это неделя когда ты коммитил
Потом цвета. Казалось бы — возьми зелёный и покрась. Но у GitHub пять уровней интенсивности, и они разные для тёмной и светлой темы. И если ты хочешь чтобы это выглядело как настоящий contribution graph а не как самоделка — приходится подбирать. Текущую неделю я подсветил рамкой — чтобы было видно где ты сейчас находишься на этой карте. Такой маркер «вы здесь». Добавил переключатель масштаба — недели, месяцы, годы. На неделях видно детали, на годах — общую картину жизни. Крутил это всё наверное дольше чем саму логику писал, потому что хотелось чтобы было не просто функционально, а чтобы хотелось туда возвращаться.
Отдельная история — как это работает без регистрации. Вбиваешь любой GitHub username в поиск — и сразу видишь результат. Никаких логинов, никаких форм. Хочешь чтобы учлись приватные коммиты — тогда да, залогинься через GitHub. Заодно профиль сохранится и попадёшь в лидерборд.
Стек для тех кому интересно: Next.js 16, Better Auth для GitHub OAuth, Neon Postgres + Drizzle ORM, shadcn/ui v4, Tailwind v4, next‑intl на 7 языков. Без рекламы, без трекинга.
❯ Сколько тебе осталось — считает наука, не я
Ладно, сетка есть, коммиты наложены. Но сколько клеток рисовать‑то? До какого возраста? Средний по стране? Мне стало интересно — а можно ли посчитать точнее?
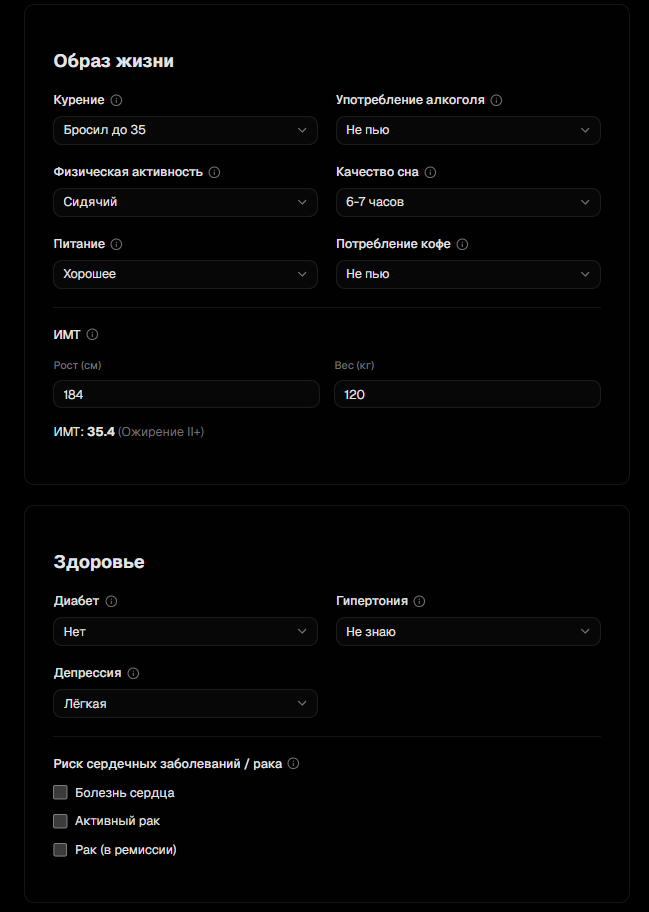
Оказалось — можно. Есть куча исследований которые считают как разные факторы влияют на продолжительность жизни. Не гадалки, не гороскопы — рецензируемые научные работы с выборками в сотни тысчя человек. Я собрал 21 такой фактор и сделал из них калькулятор. Каждый фактор ссылается на конкретную публикацию с DOI — можете проверить каждую цифру.
❯ Вот что учитывается
Курение — бросил до 40 лет? Снизил лишнюю смертность на ~90%. Куришь сейчас? Минус 11 лет. (Jha P. et al., NEJM 2013)
Алкоголь — «безопасной дозы» не существует. Тяжёлое употребление — минус 7 лет. (GBD 2016, Lancet 2018)
Физическая активность — 150 минут в неделю умеренной нагрузки добавляют ~3.4 года. (Arem H. et al., JAMA 2015)
Сон — и слишком мало и слишком много ассоциируется с повышенной смертностью. Золотая середина — 7–8 часов. (Cappuccio F. et al., Sleep 2010)
Социальные связи — и вот тут мой любимый факт. Социальная изоляция сопоставима с выкуриванием 15 сигарет в день. Пятнадцати. Одиночество буквально убивает. (Holt‑Lunstad J. et al., PLoS Med 2010)
Стресс — хронический стресс увеличивает смертность от сердечно‑сосудистых на 40%. (Kivimaki M. et al., BMJ 2012)
Давление, депрессия, сидячий образ жизни, оптимизм, наличие цели в жизни, загрязнение воздуха, диабет, BMI, семейная история, хронические заболевания — ещё 12 факторов, каждый со своим DOI.
И отдельно — кофе. 2–3 чашки в день ассоциируются со сниженной смертностью. Да‑да, кофе вам не враг. (Loftfield E. et al., JAMA 2018)
А ещё — оптимизм. Высокий уровень оптимизма ассоциируется с увеличением продолжительности жизни на 11–15%. (Lee L. et al., PNAS 2019). Так что пессимизм — это не только неприятно, это ещё и статистически вредно для здоровья. Такие дела.
Базовая продолжительность жизни берётся из данных World Bank по 217 странам. Россия, кстати, не самая оптимистичная в этом списке. Сверху накладываются модификаторы от ваших ответов — ограничены ±25 лет от базы, чтобы калькулятор не выдавал совсем уж безумнеы цифры.
Мопед не мой — я просто собрал калькулятор к научным работам. Если не согласны с цифрами — претензии к британским учёным. Ну, не ко всем британским, там и американские, и шведские, и много каких. Но вы поняли. А если серъёзно — исправьте калькулятор и закоммитьте, обновлю. Придумаете алгоритм лучше — отлично. Это же опенсорс.
❯ Торвальдс — машина, а я нет
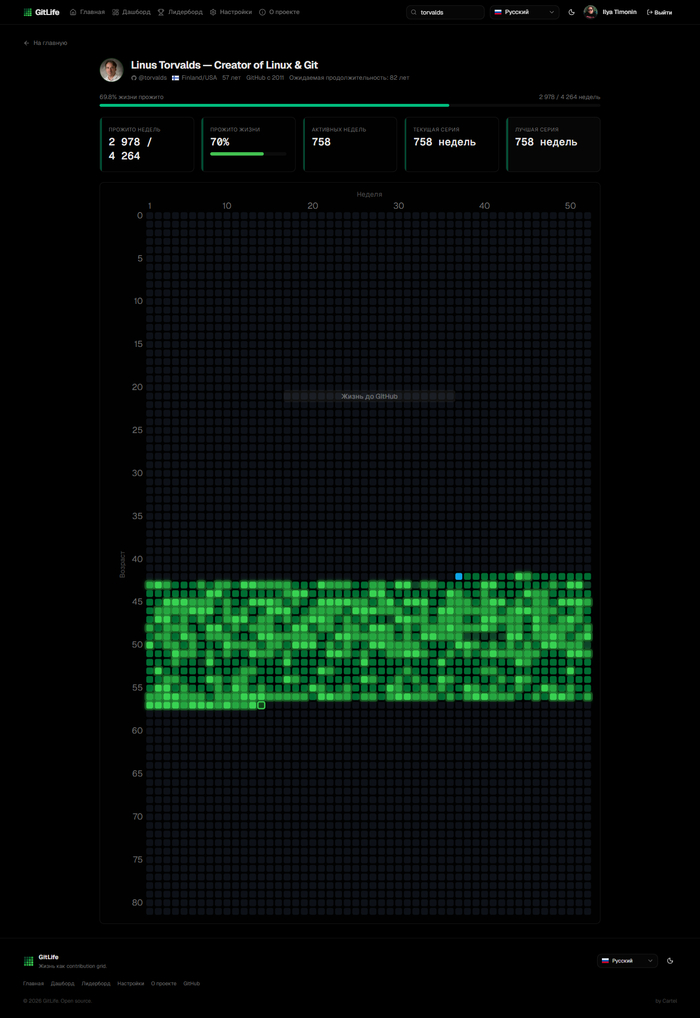
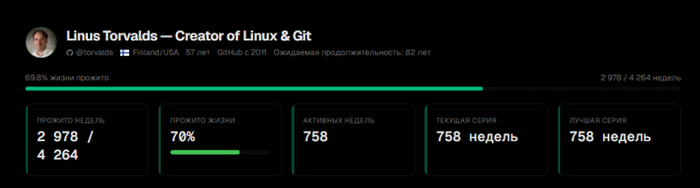
Когда сетка заработала — я первым делом вбил Торвальдса. Ну а кого ещё? И знаете что — у человека серия 794 недели коммитов без перерыва. Семьсот девяноста четыре. Это больше 15 лет без единой пустой недели. Каждую неделю что‑то коммитил. Каждую. Вы представляете? 11 618 коммитов, ни одного пропуска. Человек создал Linux и Git, ему 55 лет — и он до сих пор не останавливается.
Linus Torvalds — 758 недели подряд без единого пробела
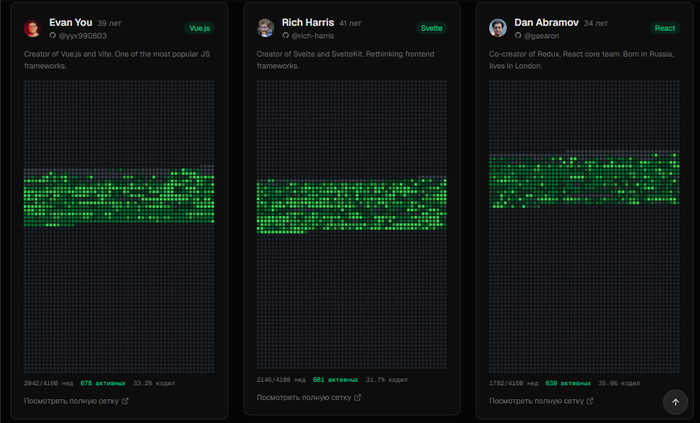
Я собрал 30 известных разработчиков. Создатели Linux, Vue.js, Redis, Node.js, Svelte, Docker, Terraform — можно открыть каждого на сайте и посмотреть сетку со статистикой. У Sindre Sorhus (1000+ npm‑пакетов) — 775 активных недель и серия в 691 неделю подряд, 10 009 коммитов. Почти как Торвальдс. У Evan You (Vue.js, Vite) — 679 активных недель, 9705 коммитов. У Rich Harris (Svelte) — 682 активных недели и 10 265 коммитов. У Salvatore Sanfilippo (Redis) — 654 активных недели, 10 477 коммитов, но самая длинная серия всего 47 недель — и на графике чётко видно момент когда он передал проект, зелёное просто обрывается.
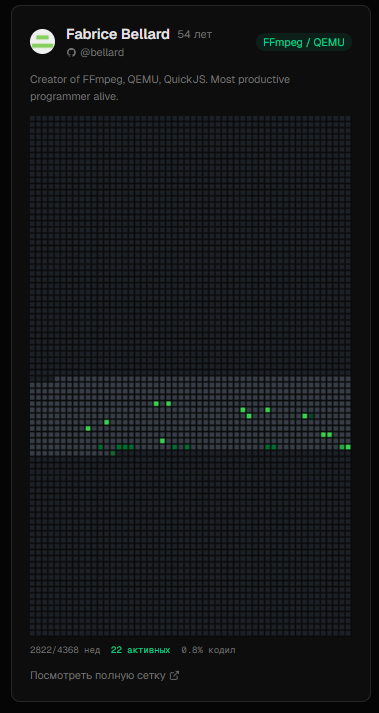
Создатель FFmpeg почти не пользуется гитхабом
Но не все так активны — по крайней мере в гите. Есть и золотые лентяи среди знаменитостей. Хотя может они просто используют другие системы вместо GitHub, или коммитят в приватные репозитории которые мы не видим. У Dan Abramov (React) например всего 55 активных недель и 568 коммитов на GitHub. Brendan Eich создал JavaScript за 10 дней, а в GitHub у него — скажем, скромно. Не значит же что человек ничего не делает.
В лидерборде можно сравнить себя с легендами и другими пользователями. По длине серии, по активным неделям, по коммитам. Залогинился — попал в рейтинг.
❯ Экзистенциальный кризис как фича
Тема сложная. Мне 37 лет, и я до сих пор не уверен что понял и принял одну простую вещь — в лучшем случае осталась половина. В лучшем. А калькулятор мне выдал 57. Базовая для России — 68, а у меня минус 11.5 лет сверху. BMI забрал сразу 8 лет. Физическая активность — минус 3. Сидячий образ жизни — ещё минус 2. Стресс, оптимизм, курение, давление, депрессия — по минус единичке‑полторе каждый. И вот ты смотришь на этот список и думаешь — ну ладно, спортом мне надо заняться, это я и так знал. Но что BMI настолько бьёт — я честно не ожидал.
Мои результаты. 57 лет. Есть над чем работать
Смотришь на свою сетку и видишь — у ровесников‑разработчиков в 2–3 раза больше активных недель. Или выше продолжительность жизни. Не то чтобы это было откровение. Я и сам всё знал и понимал. Но одно дело знать, а другое — сравнить с Торвальдсом.
Наверное этот пет‑проект — мой способ договориться с мыслью что всё конечно. Не спрятать её, не заглушить, а посмотреть ей в лицо и спросить — ок, и что я собираюсь с этим делать?
Я не знаю правильного ответа. Но мне стало спокойнее когда я перестал считать пустые клетки и начал смотреть на заполненные. Это не мотивационный плакат и не терапия — просто другой угол зрения. Который лично мне помогает не скатываться в «всё бессмысленно».
Так что питание и активность — это то что мне надо подтянуть. Если хочу оставить побольше зелёных клеточек.
❯ Что ещё можно сделать
GitLife сейчас работает только с GitHub. Но идея‑то шире — видеть каждый день который был полезен. Не важно где именно ты был полезен.
Подключить GitLab, Bitbucket — чтобы видеть всю свою активнсоть, а не только то что на GitHub. Прикрутить таск‑трекеры — Jira, Linear, Notion — каждая закрытая задача это тоже полезный день, даже если ты ни строчки не закоммитил. А может быть даже совместить с трекером эмоций. Представляете как классно было бы видеть дни когда вы были счастливы в жизни? Не продуктивны, не полезны — а именно счастливы. На той же сетке, рядом с коммитами.
Вообщем идея действительно крутая и из неё можно вытащить гораздо больше чем я успел сделать. Давайте вместе что‑то из неё может быть сделаем. Знаменитые разработчики, переводы, факторы здоровья — всё обычный JSON. Форкни, поправь, пришли PR. Или просто зайди и сравни себя с Торвальдсом. Тоже полезно. Для смирения. Ну и звёздочку на GitHub поставьте, чтобы мои зелёные клеточки были не бесполезны.
Взято с основного технического канала Postgres DBA (Возможны исправления в исходной статье).
Экспериментальная верификация эффективности текстовых подсказок для нейросетевой модели DeepSeek при анализе производительности СУБД PostgreSQL на основе отчётов pgpro_pwr
Hit ratio падает: когда планировщик выбирает не ту дорогу
Предисловие
В работе представлены результаты применения коллекции специализированных промптов на русском языке, разработанных для нейросетевой модели DeepSeek, с целью выявления причин деградации производительности PostgreSQL при переходе с версии 15.14 на 17.7 и изменении ряда конфигурационных параметров. В условиях невозможности использования разностного отчёта pgpro_pwr из-за несовместимости идентификаторов запросов (Query ID) был реализован подход к сравнительному анализу двух независимых отчётных периодов путём ручного сопоставления метрик нагрузки, конфигурации и планов выполнения. Основное внимание уделено проверке гипотезы о влиянии настроек планировщика (online_analyze, generic_plan_fuzz_factor, JIT) на рост времени ввода-вывода и снижение эффективности буферного кеша.
Задача
Проведение экспериментальной верификации набора текстовых подсказок (промптов) для нейросетевой модели DeepSeek, применяемых с целью анализа отчётных данных, формируемых системой pgpro_pwr.
Входные данные для анализа
Период 1 : pgpro_pwr_5635_5636.clear.html - 2026-04-10 09:00-10:00 : Версия 15
Период 2 : pgpro_pwr.93-94.clear.html - 2026-04-24 09:00-10:00 : Версия 17
Уточнение:
Использование разностного отчета pgpro_pwr невозможно по причине смены хеш-значений для "Query ID"
Коллекция промптов для нейросети DeepSeek (на русском языке), предназначенных для анализа и оптимизации производительности СУБД PostgreSQL.
3.Анализ конфигурационных параметров СУБД и распределения нагрузки (pgpro_pwr): analyze.txt
1. Ключевые отличия конфигурационных параметров СУБД
Сравниваются значения параметров из раздела «Cluster settings during the report interval». Представлены только параметры, зафиксированные в отчётах (не все возможные). Важнейшие для производительности изменения:
wal_compression: pglz → lz4 (изменён алгоритм сжатия полных страниц; на метрику wal_bytes в load distribution не влияет, т.к. она считает несжатый объём).
wal_keep_size: 128 МБ → 30720 МБ (многократный рост удержания WAL-файлов; прямо не влияет на производительность операторов).
max_parallel_autovacuum_workers: отсутствует (по умолчанию) → 0 (параллельный автовакуум отключён).
vacuum_buffer_usage_limit: отсутствует → 2048 кБ (ограничение буферного кеша для vacuum).
huge_pages_status: не указан → off (прозрачные огромные страницы отключены).
Влияние на планировщик и выполнение запросов
plan_cache_lru_memsize: 8192 кБ → 102400 кБ (существенно вырос кеш планов).
generic_plan_fuzz_factor: 1 → 0.9 (снижение штрафа для обобщённых планов).
jit: on → off (JIT-компиляция выключена).
online_analyze.enable: on → off (автоматический сбор статистики при загрузке данных отключён).
autoprepare_for_protocol: all → simple (изменено поведение авто-подготовки запросов).
autoprepare_threshold: 0 → 2.
enable_alternative_sorting_cost_model: on → отсутствует (не задан, вероятно off).
enable_sorted_merge_join: отсутствует → off (но в первом отчёте мог быть on по умолчанию).
track_activity_query_size: 1024 Б → 10240 Б (больше текста запроса сохраняется, косвенно может влиять на память).
log_lock_waits: off → on.
session_preload_libraries: пусто → auto_explain (загрузка auto_explain, но min_duration = -1, т.е. все запросы логируются – потенциально нагрузка на IO лога).
Прочее
Версия СУБД: 15.14 → 17.7 (существенные изменения в оптимизаторе и исполнителе).
shared_memory_size: ~13017 МБ → 12916 МБ (общая разделяемая память практически не изменилась; значение shared_buffers отдельно не зафиксировано).
*Уровень-1:Подтверждено данными –* все указанные значения взяты из table.result.txt.
2. Ключевые отличия показателей Load distribution
Сравнение проводится по базам, но основная нагрузка (>99% запросов) приходится на DB-4. Далее анализируется преимущественно DB-4.
2.1. Общая характеристика DB-4
Executed count: 6 661 587 → 6 706 321 (+0.7%) – практически не изменилось.
Total time: 6 808.58 с → 22 384.31 с (рост в 3.3 раза). Среднее время одного выполнения выросло с ~1.02 мс до ~3.34 мс.
I/O time: 1 034.72 с → 13 879.71 с (рост в 13.4 раза). Доля I/O в общем времени подскочила с 15% до 62%.
2.2. Буферный кеш и чтения
Blocks fetched (hit+read): 1 107.7 млн → 1 061.1 млн (-4%).
Shared blocks read (физические чтения): 72.0 млн → 192.6 млн (+167%).
Cache hit ratio для DB-4 (вычислено): 1-й период: hit blocks ≈ 1 035.7 млн, hit ratio ≈ 93.5%. 2-й период: hit blocks ≈ 868.5 млн, hit ratio ≈ 81.8%. Снижение доли попаданий в кеш на 11.7 процентных пункта. *Уровень-1:Подтверждено данными –* величины получены математически из предоставленных метрик.
2.3. WAL и операции записи
WAL generated: 6 875.7 млн байт → 11 895.5 млн байт (+73%).
Shared blocks dirtied: 1.35 млн → 2.03 млн (+50%).
Shared blocks written: 79 746 → 76 646 (-4%).
При практически неизменном числе запросов объём сгенерированного WAL значительно вырос, что указывает на увеличение объёма изменяемых данных (в предположении о неизменной нагрузке — противоречие, см. раздел 3).
2.4. Временные блоки
Temp blocks written: 3.70 млн → 2.37 млн (-36%).
Temp blocks read: 2.27 млн → 1.02 млн (-55%).
Сокращение использования временного пространства может указывать на изменение планов (меньше сортировок/хешей на диске).
2.5. Прочие базы
DB-7: значительный рост Blocks fetched (с 4.0 млн до 12.9 млн) при стабильном Executed count (56→57), рост I/O time.
DB-5: Executed count немного снизился, I/O time вырос.
Остальные – незначительная активность.
*Уровень-2:Вероятно, но требует проверки –* сравнение абсолютных величин может быть искажено разной длительностью интервалов накопления. Тем не менее, пропорции (hit ratio, доля I/O) инвариантны к длительности и указывают на реальное ухудшение.
3. Гипотеза о влиянии конфигурации на показатели Load distribution
Принятое допущение: характер нагрузки (типы запросов, их распределение, интенсивность) в периоды отчётов кардинально не изменился.
Гипотеза (основная): Сочетание отключения online_analyze, выключения JIT-компиляции, изменения generic_plan_fuzz_factor и перехода на версию 17.7 с иной моделью стоимости привело к выбору планировщиком менее оптимальных планов запросов – в частности, к более частому использованию последовательных сканирований вместо индексных. Это вызвало резкое увеличение физических чтений (shared blocks read), падение hit ratio, рост времени ввода-вывода и, как следствие, общего времени выполнения. Рост объёма WAL может частично объясняться тем, что возросшее количество физических чтений вынуждает чаще вытеснять «грязные» страницы из буферного кеша, генерируя дополнительный WAL, либо указывает на то, что фактическая нагрузка всё же изменилась.
Последовательность рассуждений и тезисов
При практически неизменном количестве выполнений (Executed count) среднее время запроса выросло более чем втрое. Основной вклад – лавинообразный рост времени ввода-вывода (I/O time). (Уровень-1)
Доля попаданий в буферный кеш (hit ratio) снизилась с 93.5% до 81.8%, что прямо коррелирует с ростом физических чтений. (Уровень-1)
Снижение hit ratio не может быть объяснено уменьшением shared_buffers: значение shared_memory_size практически одинаково (хотя точный размер shared_buffers неизвестен; Уровень-3:Недостаточно данных). Следовательно, причина – изменение паттернов доступа к данным. (Уровень-2)
Изменённые параметры планирования (online_analyze=off, generic_plan_fuzz_factor=0.9, отключённая JIT, новая версия PG) способны изменить выбор планов в пользу менее селективных сканирований. (Уровень-2: косвенный признак – резкое сокращение использования временных блоков при одновременном росте чтений, что может указывать на замену хеш-соединений с временными файлами на сортировку или merge join с активным чтением данных).
Рост WAL generated на 73% при том же количестве запросов противоречит допущению о неизменной нагрузке, но может быть следствием увеличения фоновой записи dirty-страниц при вытеснении, хотя точный механизм требует дополнительного анализа. (Уровень-2)
Альтернативные причины (например, деградация дисковой подсистемы, рост конкуренции за блокировки) не могут быть оценены из-за отсутствия соответствующих метрик (pg_stat_database, pg_locks, данные ОС). (Уровень-3)
Таким образом, гипотеза объединяет наблюдаемое падение hit ratio, рост физических чтений и изменение конфигурации оптимизатора.
4. Способы подтверждения и опровержения гипотезы
Для подтверждения
Включить auto_explain.log_analyze = on, auto_explain.log_buffers = on (оба уже on во втором отчёте) и проанализировать планы типичных «тяжёлых» запросов до и после изменения конфигурации. Сравнить доли seq scan и index scan, объём фактически прочитанных буферов.
Снять pg_stat_user_tables в обоих периодах (или из отчётов pgpro_pwr, если доступен раздел статистики таблиц) – сравнить seq_scan, idx_scan, n_tup_upd, n_tup_hot_upd для ключевых таблиц. Резкое увеличение seq_scan подтвердит версию о смене планов.
Временно включить online_analyze.enable = on, jit = on (по возможности) и проверить, возвращаются ли hit ratio и I/O time к прежним значениям (А/В-тестирование с идентичной нагрузкой).
Проверить, изменился ли объём данных (pg_total_relation_size) и уровень bloat’а (pgstattuple) – исключить влияние физического роста таблиц или мёртвых строк, способных увеличить чтения.
Для опровержения
Если планы запросов показывают аналогичное соотношение сканирований и индексных доступов в обоих периодах, гипотеза о влиянии планировщика несостоятельна.
Если pg_stat_user_tables показывает значительный рост объёма данных (чистый прирост строк) или интенсивные DML-операции, то рост физических чтений и WAL объясняется изменением фактической нагрузки, а не параметрами.
Если мониторинг дисковой подсистемы (iostat) в период второго отчёта показывает аномально высокие задержки (await, r_await), это указывает на проблемы с IO-подсистемой, а не с планировщиком.
Если при возврате конфигурации online_analyze=on и jit=on показатели не улучшатся, гипотеза о ключевой роли этих параметров отвергается.
Недостающие данные (критичны для углублённого анализа):
Точные значения shared_buffers, effective_cache_size, work_mem – для оценки адекватности буферного пула.
Размеры и статистика обращения к основным таблицам и индексам (pg_stat_user_tables, pg_statio_user_tables).
Планы запросов в обоих периодах (хотя бы выборка по медленным запросам).
Метрики ожиданий (pg_stat_wait_events) для выявления конкуренции за блокировки или IO.
Действительный характер нагрузки (репликация, ETL, batch-процедуры) – чтобы проверить допущение о неизменности.
*Уровень-3:Предположение/ устаревшее –* без этих данных окончательный вывод о причине падения производительности невозможен. Гипотеза остаётся правдоподобной, но требует проверки.
4. Анализ SQL запросов по разделу "Top SQL by I/O wait time": analyze-Top_SQL.txt
Сравнительный анализ планов выполнения (plan‑3.txt и plan‑4.txt)
Сопоставление выполнено по Query ID из файла queryid‑2.txt. Сравниваются три запроса, для которых установлено текстовое совпадение между периодами «отчет‑5635_5636» (PG 15.14, старые настройки) и «отчет‑93‑94» (PG 17.7, новые настройки).
INSERT INTO _InfoRg16813
Первый период (Query ID 7f58891f6efcac66): план – Insert on public._inforg16813 -> Result.
Второй период (Query ID 11882bc12ecb7128): план идентичен первому периоду.
Вывод: изменений нет. (Подтверждено)
INSERT INTO BinaryData
Первый период (Query ID ece33a053752847): план – Insert on public.binarydata -> Result.
Второй период (Query ID 74fb45dc12c18919): план идентичен.
Вывод: изменений нет. (Подтверждено)
SELECT … FROM _InfoRg12488 … ORDER BY … LIMIT $5
Первый период (Query ID b932f4ddf25919b4): зафиксированы два плана: План 1: Limit -> Sort -> Index Scan using _inforg12488_1 (с условием по _fld12490rref = $1 и дополнительными фильтрами). План 2: Limit -> Sort -> Bitmap Heap Scan -> Bitmap Index Scan on _inforg12488_1 (Recheck Cond по тому же полю).
Второй период (Query ID 12e2db113ff929b0): зафиксированы три плана: План 1: Limit -> Sort -> Seq Scan on _inforg12488 (последовательное сканирование с фильтром). План 2: Limit -> Sort -> Bitmap Heap Scan -> Bitmap Index Scan on _inforg12488_1 (как в первом периоде). План 3: Limit -> Sort -> Index Scan using _inforg12488_1 (как в первом периоде).
Вывод: во втором периоде появился вариант плана с Seq Scan, отсутствовавший в первом периоде. Одновременно увеличилось общее число вариантов плана для этого запроса (с 2 до 3). (Подтверждено)
Обобщение по планам Для двух INSERT-операторов планы не изменились. Для единственного SELECT-оператора, по которому возможно сравнение, во втором периоде планировщик дополнительно рассматривает (и, следовательно, может выбирать) последовательное сканирование, тогда как в первом периоде использовались только методы доступа по индексу. Это прямое свидетельство сдвига в поведении оптимизатора при новых настройках.
Дополнение гипотезы о влиянии конфигурационных параметров на показатели Load Distribution
Исходная гипотеза (analyze.txt, раздел 3) связывала падение hit ratio, рост физических чтений и времени ввода-вывода с изменением планов запросов в пользу менее селективных методов доступа (seq scan).
Анализ планов выполнения подкрепляет эту гипотезу конкретным примером: для запроса, который в первом периоде всегда использовал индекс, во втором периоде стал доступен план с последовательным сканированием таблицы. Вероятно, этот случай не единичен, и подобные изменения затронули значительную часть нагрузки, что и вызвало наблюдаемый рост shared blocks read и падение hit ratio.
Уточнённая последовательность рассуждений и тезисов
Количество выполненных запросов в DB‑4 практически не изменилось (+0.7%), однако общее время выполнения выросло в 3.3 раза, а время ввода-вывода – в 13.4 раза. Основной вклад в деградацию дали возросшие физические чтения. (Подтверждено)
Cache hit ratio снизился с 93.5% до 81.8% при стабильном объёме разделяемой памяти. Это исключает уменьшение буферного пула как причину и указывает на изменение паттернов доступа к данным. (Подтверждено)
Для одного из немногих доступных для сравнения запросов зафиксировано появление в новом периоде плана с Seq Scan, которого не было ранее. (Подтверждено)
Аналогичные изменения могли произойти и для других запросов, составляющих основную нагрузку, что объясняет кратный рост физических чтений и падение hit ratio. (Вероятно)
Сдвиг в планах согласуется с отключением online_analyze (устаревание статистики), снижением generic_plan_fuzz_factor (уменьшение штрафа для обобщённых планов), выключением JIT, а также с переходом на новую версию PG с иной моделью стоимости. (Вероятно)
Сокращение использования временных блоков при одновременном росте чтений может указывать на замену операций с записью на диск (например, хеш-соединений) на операции с активным чтением данных (сортировка или merge join), что согласуется с общим ростом физических чтений. (Вероятно)
Рост объёма WAL на 73% при неизменном количестве запросов частично объясняется увеличением фоновой записи «грязных» страниц, вытесняемых из-за возросшего потока чтений, но также может свидетельствовать о реальном увеличении объёма изменяемых данных, что требует отдельной проверки. (Вероятно)
Таким образом, основная гипотеза не изменилась, но получила прямое подтверждение на уровне конкретного плана запроса. Вероятность гипотезы повышается.
Дополнение способов подтверждения и опровержения гипотезы
С учётом данных о планах выполнения добавляются следующие пункты (к уже перечисленным в analyze.txt):
Для подтверждения:
Проанализировать распределение реально использовавшихся планов во втором периоде. Если через pg_stat_statements или расширенные отчёты pgpro_pwr доступна статистика по каждому planid (например, calls, total_time, shared_blks_read), можно установить долю запросов, выполненных с Seq Scan, и сравнить её с первым периодом. Значительный рост этой доли напрямую подтвердит гипотезу. (Предположение)
Для запроса SELECT … FROM _InfoRg12488 (Query ID 12e2db113ff929b0) оценить фактическую селективность условия _fld12490rref = $1. Если она высока (т.е. возвращается мало строк), выбор Seq Scan однозначно неоптимален и является прямым следствием ошибки планировщика при новых параметрах — это будет сильным подтверждением гипотезы. (Предположение)
Временно вернуть параметры online_analyze = on и generic_plan_fuzz_factor = 1 и проверить, исчезнет ли Seq Scan-план для этого запроса и восстановятся ли общие показатели hit ratio и I/O time (A/B-тестирование). (Предположение)
Для опровержения:
Если статистика использования планов покажет, что Seq Scan-план для данного запроса практически не выбирается (calls близко к нулю), то его появление в списке планов не повлияло на нагрузку, и гипотеза о массовом переходе на Seq Scan теряет основание. Потребуется искать иные причины роста физических чтений. (Предположение)
Если auto_explain (уже включён) зафиксирует, что в большинстве медленных запросов второго периода используются индексные доступы, а рост чтений вызван, например, обработкой существенно большего объёма данных (изменившийся характер нагрузки), то гипотеза о влиянии параметров планирования будет опровергнута. (Предположение)
Если значение enable_seqscan в первом периоде было off (или иным образом ограничено), а во втором — on, то различие в планах объясняется тривиальной настройкой, а не сложным влиянием online_analyze и generic_plan_fuzz_factor. (Неизвестно — значение enable_seqscan в отчётах не зафиксировано, требуется проверка.) (Предположение)
Недостающие данные, критичные для углублённого анализа (дополнительно к разделу 4 analyze.txt):
Значения enable_seqscan, enable_indexscan, enable_bitmapscan в обоих периодах.
Статистика использования отдельных планов (planid) для ключевых запросов: количество вызовов, общее время, прочитанные блоки.
Оценка селективности предикатов для проблемного запроса (значения параметров $1, $6 и т.д.) и распределение данных в таблице _InfoRg12488.
Полный список запросов с наибольшим вкладом в total_time и shared blocks read в обоих периодах и их планы, чтобы оценить масштаб явления.
Общий технический итог
Установлено, что при практически неизменном количестве выполненных запросов (рост на 0,7%) общее время выполнения увеличилось в 3,3 раза, а время ввода-вывода – в 13,4 раза, что сопровождалось падением коэффициента попаданий в буферный кеш с 93,5% до 81,8%. Сравнительный анализ планов выполнения для трёх текстуально совпадающих запросов выявил появление во втором периоде варианта с последовательным сканированием таблицы для SELECT-оператора, при том что в первом периоде использовались только индексные методы доступа. Данный факт, согласующийся с изменениями конфигурации (online_analyze.enable = off, generic_plan_fuzz_factor = 0,9, jit = off), подтверждает гипотезу о смещении выбора планов в сторону менее селективных сканирований как основной причине роста физических чтений и деградации производительности. Рост объёма WAL на 73% при стабильной частоте запросов требует дополнительной проверки, но может быть следствием усиленной фоновой записи грязных страниц при вытеснении из буферного пула.
Послесловие
Полученные результаты демонстрируют принципиальную применимость методики, основанной на последовательном применении промптов к отчётам pgpro_pwr, для выявления тонких эффектов изменения параметров планировщика и версии СУБД. Однако надёжность выводов ограничена отсутствием в исходных данных точных значений shared_buffers, work_mem, статистики pg_stat_user_tables и метрик ожиданий (pg_stat_wait_events). Для окончательной верификации гипотезы необходима постановка контролируемого А/В-эксперимента с возвратом ключевых параметров (online_analyze, generic_plan_fuzz_factor, jit) к исходным значениям на целевой системе, а также анализ распределения фактически используемых планов по planid через pg_stat_statements. Предложенный подход может быть масштабирован на задачи регрессионного анализа производительности при миграциях PostgreSQL с использованием нейросетевых моделей в качестве ассистирующего инструмента.
Апрель 2026 принёс разработчикам больше гибкости: помощник кода доступен при корректной настройке среды и оплате через международные инструменты. Многие команды уже закрывают рутинные задачи генерацией функций и тестов, а одиночные специалисты ускоряют ревью и прототипирование. Ниже собраны рабочие способы подключения, варианты оплаты без зарубежного счёта и практики использования в популярных IDE, включая VS Code и решения от JetBrains.
Что такое GitHub Copilot и зачем он нужен разработчикам
Это ассистент программирования, который предлагает строки и целые фрагменты на основе контекста файла. Подскажите намерение комментариями, и он допишет функцию или тест к модулю. Инструмент ускоряет типовые операции: генерацию шаблонов, конверсию между API, наброски SQL, миграции и фиксы по диффу. Пользователь видит подсказки в редакторе, управляет частотой предложений, журналом телеметрии и политиками конфиденциальности внутри настроек.
Работает ли GitHub Copilot в России: ограничения, статус и требования
Нужен ли VPN для GitHub Copilot из России
Многие разработчики подключают VPN, чтобы пройти авторизацию расширения и беспрепятственно открывать промо-страницы подписки. Стабильный туннель снижает ошибки сети при обращении к API. Проверьте маску региона, скорость не ниже 20 Мбит/с и отсутствие компрессии трафика. Для надёжности добавьте исключения в клиенте, а DNS переключите на публичные резолверы вроде comss.one dns для корректного разрешения доменов.
Влияет ли регион аккаунта и IP-адрес на работу Copilot
Сервис сверяет страну биллинга карточки и адрес плательщика, поэтому платежи с локальных реквизитов часто не проходят. На доступ к расширению влияет IP: некоторые узлы блокируют вызовы API. Проверьте страницу Billing → Subscriptions, затем сравните адрес в Payment method с реквизитами карты. При расхождении индекс и страна должны соответствовать стране эмитента платёжного инструмента.
Будет ли Copilot работать после смены VPN
После успешной авторизации расширение сохраняет токен до истечения сессии. Смена маршрута иногда роняет запросы, особенно при жёстком DPI у провайдера. Удерживайте один провайдер туннеля на время работы IDE, а для долгих сессий включите автопереподключение. При обрыве перезайдите через команду “Sign in to GitHub” внутри IDE и обновите маркер доступа в браузере.
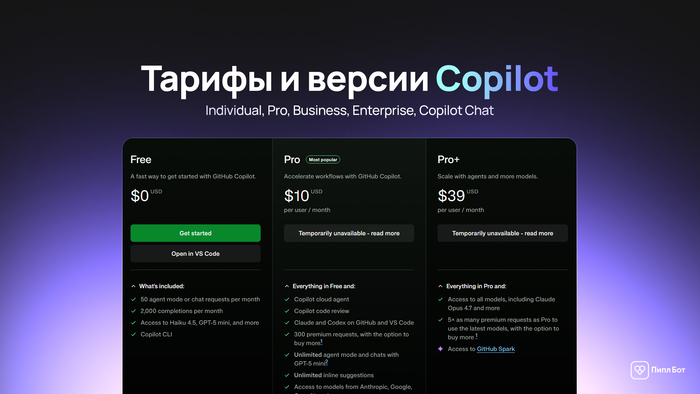
Тарифы и версии Copilot: Individual, Pro, Business, Enterprise, Copilot Chat
Линейка покрывает личное использование и корпоративные процессы. Individual подойдёт фрилансеру или студенту, а Business добавляет параметры управления для команд через организацию: политики, телеметрия, ограничения. Enterprise ориентирован на крупные компании с централизованным соответствием, журналами и границами данных. Copilot Chat дополняет кодогенерацию диалогом внутри редактора, полезен при отладке и объяснении фрагментов.
Лицензирование для команд и организаций: Pro для нескольких разработчиков vs Business
Небольшие группы часто начинают с Individual на каждого участника, но централизованный контроль удобнее через Business. Там проще управлять доступом, аудитом и оплатой одним счётом через Billing для организации. Если используете Pro-аккаунты как основу экосистемы, сверьте названия и состав опций на актуальной странице тарифов, затем зафиксируйте единый цикл продления в Subscriptions.
Как купить и оплатить GitHub Copilot из России и Беларуси в 2026
Что требуется для оплаты из России
Понадобится платёжный инструмент с иностранной страной биллинга и поддержкой 3‑D Secure. Подготовьте адрес плательщика, индекс и телефон в формате страны эмитента. Откройте GitHub → Settings → Billing → Subscriptions и добавьте способ оплаты. Проверьте лимит на онлайн-платежи в мобильном банке посредника, а затем активируйте автопродление, если планируете ежемесячное списание.
Способы оплаты без зарубежного счета
Сценарий рабочий через цифровые платёжные решения от партнёров. ПиплБот помогает получить доступ к международным продуктам: цифровые карты, пополнения и коды, которые подходят для оплаты глобальных подписок. Оформите нужный номинал, затем введите реквизиты в Billing. Включите 3‑D Secure, проверьте лимит. Если банк запрашивает SMS, держите подключённый номер и запасной e‑mail для прохождения KYC.
Оплата GitHub Copilot Pro из России
Для уровня Pro используйте тот же подход: цифровая карта иностранного банка-партнёра и корректный биллинг. Добавьте карту в разделе Payment methods, затем подтвердите мелкое списание. Сверьте страну в адресе, индекс и формат телефона. При отказе повторите через альтернативный платёжный канал, который ПиплБот предоставляет как цифровой продукт с поддержкой 3‑D Secure и лимитами под подписки.
Оплата в Республике Беларусь
Пользователи из Минска и других городов применяют международные карточные решения по той же схеме. Укажите страну выпуска в Billing, затем проверьте, проходит ли код 3‑D Secure через местного оператора связи. При ошибке 05 поднимите лимит на онлайн-платежи, а для повторной попытки очистите кэш браузера, перезайдите и вновь откройте Subscriptions для подтверждения.
Нужно ли менять регион GitHub-аккаунта
Обычно достаточно совпадения страны платёжного инструмента и адреса в Billing. Менять страну профиля не требуется, если оплата проходит. Важнее корректно заполнить почтовый код и город на латинице. Изменения делайте через Settings → Account и дублируйте адрес в Payment method. После сохранения повторите оплату и проверьте раздел Invoices.
Бесплатно: тестовый период, GitHub Education и программы для open‑source
Доступен trial, который активируется без мгновенного списания при успешной привязке метода оплаты. Обучающиеся со статусом Education получают льготы, подтверждая e‑mail учебного заведения. Для мейнтейнеров open‑source возможны бесплатные квоты через профильные программы. Проверьте Eligibility на странице условий и храните подтверждения статуса, чтобы продлить льготу после верификации.
Что будет с подпиской, если реквизиты посредника истекут
При недоступной карте авторизация платежа падает, а сервис ставит состояние Past due. Зайдите в Billing → Payment methods, добавьте новый инструмент и нажмите Retry charge возле последнего счёта. Смена носителя не влияет на настройки IDE. После успешного списания статус вернётся в Active, а расширение продолжит предлагать подсказки без повторной установки.
Как подключить и активировать GitHub Copilot
Регистрация и оформление подписки
Создайте аккаунт через браузер, подтвердите почту и включите 2FA в Security. Перейдите в Settings → Billing, выберите план и завершите оформление. Проверьте, что включено автопродление, если нужно сохранить непрерывный доступ. Сразу откройте раздел Copilot в настройках профиля, чтобы включить генерацию предложений и дополнительные параметры конфиденциальности телеметрии.
Активация в аккаунте GitHub
Зайдите в Settings → GitHub Copilot и включите переключатели для “Suggestions” и “Chat”. Если используете организацию, администратор разрешает доступ через Policies. Сохраните изменения, затем откройте IDE и авторизуйтесь. Страница Subscriptions должна показывать активный план, а в списке устройств появится ваш редактор после первого входа.
Установка расширений и авторизация
Откройте каталог расширений редактора и найдите модуль по официальному названию. Установите, затем нажмите “Sign in” в всплывающем уведомлении. Авторизация идёт через браузерный OAuth; подтвердите запрос и вернитесь назад. Проверьте, что строка статуса сообщает о готовности, а в палитре команд доступна команда для запроса подсказок и открытия чата.
Установка и настройка GitHub Copilot в IDE
Visual Studio Code (VS Code) — установка, настройка и горячие клавиши
В VS Code откройте Extensions и установите модуль, затем включите “Inline Suggest” в Settings. Приём подсказки по умолчанию — клавиша Tab, альтернативы меняются через Keyboard Shortcuts. Для диалога используйте командную палитру и запрос “Copilot Chat: Open”. Если подсказки слишком частые, снизьте интенсивность в Editor → Suggestions и отключите автопоявление для больших файлов.
Visual Studio — подключение и особенности
В полнофункциональной IDE установка идёт через Extensions Manager. После входа через браузер проверьте Tools → Options → IntelliCode, чтобы согласовать поведение с подсказками ассистента. В крупных решениях включайте подсказки только для активного файла, чтобы не перегружать подсистему анализа. Горячие клавиши меняются в Options → Keyboard с поиском по названию команды.
JetBrains IDE (IntelliJ IDEA, PyCharm и др.) — подключение и настройки
Откройте Settings → Plugins и найдите расширение, затем авторизуйтесь через OAuth. Управляйте частотой появления предложений в Editor → Code Completion, а для чата добавьте панельный инструмент. При конфликтах с Live Templates временно выключите автогенерацию в больших проектах. Для Python, Java и JavaScript полезно включить режим объяснения фрагмента по выделению.
GitHub Copilot Chat на русском языке: локализация и подсказки
Диалог понимает запросы на русском и обрабатывает комментарии в коде. Формулируйте намерение кратко, добавляйте ограничения по версиям библиотек и указывайте формат результата. Для многоязычных проектов сообщайте целевой фреймворк, чтобы повысить точность. Если ответ не попал, сужайте контекст: файл, диапазон строк и ожидаемый прототип функции.
Как эффективно пользоваться Copilot: практики и сценарии
Поддерживаемые языки программирования и фреймворки
Инструмент уверенно помогает в Python, JavaScript и Java, а также вполне полезен для YAML, Dockerfile и SQL. Добавьте версии фреймворков в комментарий: “FastAPI 0.110, Python 3.11” или “React 18 без классовых компонентов”. Тогда генерация ближе к ожиданиям. Для инфраструктуры указывайте Terraform-провайдера и версию, чтобы предложения соответствовали нужным блокам.
Работа на нескольких устройствах и синхронизация
Подписка привязана к аккаунту, поэтому используйте её и дома, и на рабочем ноутбуке. Включите Settings Sync в IDE, чтобы переносить расклад горячих клавиш и предпочтения. При смене машины не забудьте переавторизоваться, а токены очистить на старой через браузер. История диалогов хранится у поставщика, удаление делайте в настройках профиля.
Влияние Copilot на производительность IDE
Подсказки требуют сетевых вызовов, поэтому слабая сеть добавляет задержку. На крупных монорепозиториях включайте подсказки в активном файле и отключайте для бинарников. Мониторьте загрузку CPU и память в диспетчере задач, а затем корректируйте частоту предложений. Если IDE подтормаживает, сократите глубину анализа проекта и выключите лишние плагины.
Безопасность и конфиденциальность: что отправляется и хранится на серверах
Фрагменты кода и метаданные запроса уходят на сервер для генерации ответа. В корпоративной среде ограничьте отправку конфиденциальных строк через политики организации. Изучите Settings → Privacy, отключите телеметрию, если это разрешено политикой. Для закрытых модулей используйте минимальные контекстные куски и избегайте персональных данных в промптах.
Поддержка русского языка: комментарии в коде и промпты
Подсказки корректно реагируют на комментарии на русском, но иногда полезно добавить англоязычные ключевые слова API. Используйте чёткую структуру: “Сгенерируй функцию, которая…” и укажите параметры. Для многошаговых задач разбивайте на пункты. Чем явнее контекст и формат вывода, тем надёжнее итог, особенно при генерации тестов и миграций.
Решение проблем: Copilot в России не работает — что делать
Проблемы с авторизацией и платежами
Если окно OAuth не открывается, выключите блокировщики и почистите кеш. При отказе оплаты проверьте страну в Billing, лимит по карте и 3‑D Secure. Попробуйте вторую попытку через другой платёжный канал, который предлагает ПиплБот, затем перезапустите IDE. В Invoices проверьте статус, а квитанцию отправьте в бухгалтерию при необходимости.
Ошибки подключения: сеть, VPN и прокси
Тестируйте маршрут через ping и traceroute до API-узлов, а DNS переводите на публичные резолверы. В VPN отключите компрессию, настройте протокол WireGuard или IKEv2 и зафиксируйте один шлюз. Если используете корпоративный прокси, добавьте исключения для доменов поставщика. После стабилизации канала перезайдите в расширение и обновите токен.
Как отменить подписку и вернуть средства
Откройте Billing → Subscriptions и нажмите Cancel. Доступ сохранится до конца оплаченного периода. Возвраты зависят от политики поставщика: создайте тикет через Support и приложите номер инвойса. После закрытия подписки удалите способ оплаты, а в IDE выключите модуль через менеджер расширений, чтобы прекратить сетевые вызовы.
Альтернативы GitHub Copilot, доступные в России
Часть специалистов комбинирует ассистент кода с внешними чат‑системами и локальными подключениями. Например, Claude используют для пояснений алгоритмов и генерации комментариев, а IDE‑расширения дают подсказки построчно. Такой дуэт помогает балансировать приватность и качество выдачи. Сервисы оплаты цифровых инструментов удобно оформлять через ПиплБот, чтобы не держать зарубежный счёт.
Перспективы: GitHub Copilot в России в 2024–2026
За два года помощники кода продвинулись от шаблонов к осознанной навигации по проектам. Виден тренд на организационные политики, прозрачность телеметрии и управление контент‑фильтрами. Оплата через цифровые каналы стала рутиной: пользователи подключают подписку, синхронизируют IDE и шлифуют практики промптинга. Ожидаем усиление чата и глубинной интеграции в пайплайны CI.
Итоги: стоит ли подключать Copilot сейчас
Да, если вы хотите ускорить выпуск фич и типовых задач без потери качества. Инструмент закрывает шаблонный код и подсказки по API, а человек держит архитектуру и ревью. Подключите через рабочую схему оплаты и настройте IDE так, чтобы подсказки не мешали. ПиплБот помогает решить вопрос с оплатой цифровых сервисов без филиала за рубежом.
Чек-лист: подключение и оплата
Подготовьте платёжный инструмент с 3‑D Secure и адресом страны эмитента.
Включите стабильный VPN и публичный DNS; проверьте скорость от 20 Мбит/с.
Зайдите в GitHub → Settings → Billing → Subscriptions и добавьте карту.
Активируйте Copilot в настройках аккаунта; включите Suggestions и Chat.
Установите расширение в IDE; пройдите OAuth через браузер.
Настройте горячие клавиши и частоту подсказок в редакторе.
FAQ — Частые вопросы о GitHub Copilot в России
Copilot заменит программистов?
Нет. Ассистент ускоряет рутину и помогает с набросками, но архитектуру, контроль качества, безопасность и финальные решения держит инженер. Лучшая практика — поручать генерацию шаблонов, тестов и однотипных преобразований, а ключевую логику проектировать вручную.
Используете GitHub copilot в работе?
Большинство команд подключает инструмент в IDE для автодополнения и чата при отладке. Типичный сценарий: комментарий с намерением, затем генерация функции и доработка под гайдлайны проекта. Результат проходит обычный код‑ревью через pull request и линтеры.
Почему я должен тратить время на написание кода, который я уже знаю и который писал в прошлом?
Не нужно. Делегируйте шаблонные блоки ассистенту и сосредоточьтесь на архитектуре, интеграциях и сложных частях. Снижайте технический долг, автоматизируйте тесты и покрытие. Инструмент помогает быстрее пройти повторяющиеся участки пути.
Нужен ли VPN для оплаты и работы расширения?
Часто да. VPN помогает пройти авторизацию и стабилизировать сетевые вызовы расширения. Для платежа важнее страна биллинга карты и корректный адрес в Billing; без совпадения оплата может падать даже при активном туннеле.
Как оплатить подписку без зарубежного счёта?
Используйте цифровые платёжные решения партнёров. Через ПиплБот удобно приобрести подходящий инструмент с поддержкой 3‑D Secure, затем ввести реквизиты в разделе Subscriptions. Проверьте лимит на онлайн‑платежи и страну биллинга перед подтверждением.
Где изменить частоту подсказок и горячие клавиши?
Внутри IDE: в VS Code — Settings и Keyboard Shortcuts, в средах JetBrains — Settings → Keymap и Code Completion. Снизьте навязчивость, если предложения мешают, и включите чат по команде, а не автоматически.