00:00 Начало 00:24 Квантовый секрет русско-китайских побед 02:30 Горячая суперсемейка NVIDIA 04:00 Болтливый электрокар Volkswagen 05:42 Санкции и российская IT-индустрия 07:24 Итоги розыгрыша ноутбука и не только 09:15 Кто придумал нейросеть для порчи других нейросетей
Я лет десять назад наблюдал картину на тему: в Московском Кремле тогда билеты для входа продавались в киоске с двумя окошками. Ни билетных автоматов, ни онлайн-продажи тогда не было, только живая очередь, только хардкор. Очередь в этот киоск выстраивалась на 1000+ человек (стоять больше часа). Передо мной стояли итальянцы, которые постепенно приходили в некое остервенение на грани истерики.
И вот, подошла их очередь, итальянец подбирая слова на ломаном английском просит продать ему билеты в Кремль, а в окошке сидит бабушка, судя по виду - многократный победитель чемпионата вахтеров, и чеканным слогом ему отвечает "я Вас не понимаю, говорите по-русски".
Эмоции меня накрыли смешанные, с одной стороны, я сильно охуел от организации процесса, там где дешево и сердито можно было заработать на туристах, всё было сделано максимально тупо и неудобно; с другой стороны эта имперская спесь в исполнении тетушки-"ни шагу назад", прям меня впечатлила и где-то даже вызвала гордость.
Итальянцам я тогда помог, на будущее посоветовал учить русский.
Стоит отметить, что сейчас ситуация изменилась радикально. Поставили большой павильон с кучей окошек, также можно купить билет онлайн или в автомате. Даже в оружейную палату и Алмазный фонд попасть не проблема.
Для ЛЛ: В ChatGPT загрузили скрипты из диагностического руководства, чтобы проверить, может ли искусственный интеллект заменить клиническое суждение американского врача-психиатра.
58-летний автор видео вызвался пройти 30-минутное клиническое интервью с врачом-психиатром доктором Джоанн Мандин и выложить его онлайн.
Врач-психиатр работает в частной психиатрической клиники в Лос Альтос, Калифорния https://www.savantcare.com/ и беседы с пациентами прогоняет через компьютер.
Во время интервью компьютерная программа транскрибирует голос пациента в текст,
затем из текста автоматически удаляется информация, идентифицирующая личность, - анонимизация,
затем из текста автоматически удаляется "чувствительная" информация, - очистка,
Sanitization is the process of removing sensitive information from a document or other message (or sometimes encrypting it), so that the document may be distributed to a broader audience.
и только потом диалог врача-психиатра и "некого пациента" на протяжении получаса отправляется в чат GPT Open AI на контент-анализ.
В программу загружены диагностические скрипты, по которым думает врач-психиатр. Она анализирует текст сессии и выдаёт клинические суждения: признаков психоза нет, признаков суицидальных настроений нет, и т.д.
Как и в Чат GPT и психологи здесь ИИ уверенно утверждал, что калифорнийскому пациенту 24 года, хотя вопроса про возраст в диалоге врача и пациента не было вообще и пациенту на самом деле 58 лет.
Да-да, такое с чатом GPT частенько бывает!
Пациент поинтересовался, какие скрипты заложены в программу и будет ли поставлен балл за нарциссизм, потому что говорит только о себе )
Компьютерная программа по тексту 30-минутной анонимизированной и очищенной от "секретной информации" сессии нашла симптомы, подходящие для диагнозов Нарушения адаптации, Посттравматического расстройства и Синдрома дефицита внимания и гиперактивности (с этим выводом компьютера врач не согласилась, но обещала подумать ещё раз, вдруг она что-то пропустила).
Врач-психиатр заверила пациента, что она отредактирует диагностический отчёт о проведённой сессии: исправит возраст на правильный и уберёт клинические суждения, которые кажутся ей "перебором"(не сказать "галлюцинацией ИИ на тему"). Супервизором быть проще, чем психиатром-интерном, да )
Видео, на мой взгляд, неоправданно длинное. Впрочем, маркетинг никто не отменял. Сам не похвалишь клинику в которой "работали дни и ночи напролёт", чтобы скопировать в программу тексты из диагностического руководства создать чудо-скрипты, - никто не похвалит.
Процесс диалога с машиной врач называет Super Prompt Engineering. Она рада, что при нагрузке около 10 пациентов в день, чат GPT подсказывает ей, какие симптомы и синдромы можно найти по скриптам на основе DSM-5 ( используемая в США с 2013 года номенклатура кодировки психических расстройств) и ICD-10 (используемая в мире версия классификатора МКБ, разработанная в 1989 году, принятая ВОЗ в 1990 году и заменяемая в 2022 году очередной версией МКБ 11-го пересмотра, МКБ-11).
Пациент смеётся и предполагает, что всех врачей-психиатров со временем полностью заменят машины, транскрибирующие разговор в текст.
В комментариях к видео пациенты жалуются: "Ролик подал надежды. В Швейцарии вам месяца два придётся ждать приёма у психиатра. Судя по количеству бумаг, которые психиатры должны заполнять для страховых компаний, у них просто нет времени на приём людей. Если бы система такого типа могла иметь дополнительную функцию, помогающую им справляться со всеми административными и страховыми формами и отчетами, они могли бы фактически начать принимать больше пациентов, больше сосредоточившись на своей основной работе, а не теряя так много времени на административные задачи и отказывая пациентам. На самом деле мне было бы очень интересно принять участие в любом тестировании этой системы в качестве пациента онлайн, потому что я все еще не мог поговорить здесь со специалистом! Интересно, что в Таиланде гораздо проще попасть на прием к психиатру или врачу-специалисту, вас запишут на прием в течение недели, если не на следующий день, потому что у них куча административных сотрудников, которые занимаются бумагами".
Что лично я думаю о чудо-программе?
Об искусстве клинического интервью написаны прекрасные книги, учебники и монографии. Переводить жалобы на приёме в строчки из диагностического руководства много ума не надо. А вот понять, о чём тебе-интервьюеру НЕ рассказывают, каких тем избегают, о чём умалчивает пациент, где и как он замялся, прежде чем дал ответ, предположить, почему пауза затянулась, смена позы, неуместная шутка, внезапный "вбоквел" от темы, и вынести из информации об умолчании адекватное диагностическое суждение - здесь клинициста, его насмотренность, наслушанность и его чутьё не заменит никакой скрипт.
Chatgpt помог написать мне милую сказку про этого мишку:
Дом великанов
В одном уютном и солнечном доме жил маленький плюшевый мишка. Он был действительно миниатюрным: всего 9 сантиметров в высоту и весил 25 грамм. Мишка носил коричневую модную куртку в белый горошек, которая придавала ему уверенности и особенно нарядный вид.
Однажды, стоя на подлокотнике дивана, медведик оглядывался вокруг. Дом был для него настоящим огромным замком с бесконечными коридорами, высокими шкафами и неизведанными комнатами. Мишутка любил мечтать о приключениях, которые могли бы его ожидать в этом огромном доме.
Первым делом он решил отправиться в путешествие по дивану. Мишка осторожно спустился с подлокотника, перебираясь по мягким подушкам, как по маленьким холмам. Подушек было много, и каждая казалась ему горой, которую нужно покорить. На вершине одной из них он обнаружил небольшую дыру. Зайдя в неё, медведик оказался в темной пещере из ткани. Это было так захватывающе и немного страшно, но любопытство взяло верх.
Пройдя через пещеру, мишутка вышел на свет и оказался у основания большого журнального столика. Он посмотрел вверх и решил, что это будет его следующая цель. Сначала он обогнул стол, исследуя его ножки, которые казались ему могучими столпами. Потом он нашел низко свисающую скатерть и, ухватившись за неё, начал медленно карабкаться наверх.
На вершине стола мишка нашел множество интересных вещей: красивую вазу с цветами, большую книгу с яркими картинками и коробку с печеньем. Он осторожно открыл коробку и обнаружил, что в ней хранится целое богатство — ароматные печенья с шоколадной крошкой! Медведик попробовал один маленький кусочек и почувствовал, как вкус шоколада распространился по всему его телу. Это был настоящий пир для малыша.
После угощения, медведик решил, что пора исследовать дальше. Он спустился со стола и направился в сторону кухни. Кухня была огромной, и каждый предмет на ней казался ему гигантским. Мишка нашел пакет с мукой и устроил себе маленькую снежную горку, скатываясь с неё снова и снова. Затем он наткнулся на большую коробку с игрушками, стоящую в углу.
В коробке было много интересных предметов, но больше всего ему понравилась маленькая машинка. Мишутка сел в неё и представил себя гонщиком, мчащимся по бесконечным трассам. Он ездил по коробке, представляя, что пересекает пустыни и леса, переправляется через реки и взбирается на высокие горы.
Когда день подходил к концу, медведик вернулся на диван. Уставший, но счастливый, он сел на свой подлокотник и смотрел на закат, который пробивался через большое окно. В тот момент мишка понял, что в огромном доме всегда найдется место для новых приключений и открытий. С каждым днем он будет узнавать что-то новое и переживать новые удивительные события, а может найдёт и друзей.
И так, под мерцающий свет луны, проникающий через большое окно, маленький плюшевый мишутка закрыл глаза и заснул, мечтая о том, что завтра принесет ему ещё больше удивительных приключений.
Мне сказка понравилась! Не напряжная, расслабляющая, отдыхательная, позволяет пофантазировать.
А кто дочитал, тот сегодня получит обнимашки, а если сомневаетесь в этом, то обнимите близкого Вам человека сегодня. Поделитесь своей добротой !
❤️❤️❤️
У меня уже месяц примерно такое приподнятое настроение, когда я хочу делать всем комплименты, дарить радость, обнимать, но часто стесняюсь)
В 2015 Маск убеждал Сэма Альтмана не жалеть никаких денег на найм топовых спецов, чтобы спасти человечество от зловредного супер-ИИ от Google – а сейчас он публично обзывает его «лжецом, жуликом и мошенником». В 2018 Маск «оценивал шансы OpenAI на успех как нулевые» – а теперь он хочет выкупить компанию за $97 млрд. В этом лонгриде мы детально разберемся: как так вышло, что Илон сначала помог запустить самую революционную ИИ-компанию современности, а потом стал главным ее хейтером?
Это гостевая статья от Леонида Хоменко – продуктового аналитика и автора канала «Трагедия общин» про искусственный интеллект и современные технологии. Я в данном случае выступаю как редактор, который изо всех сил пытался сделать этот интереснейший лонгрид чуть более вместимым в разумные рамки объема. =)
За последний год OpenAI неоднократно находилась в гуще захватывающих событий: скандал с неудавшимся увольнением Сэма Альтмана, уход из компании Ильи Суцкевера, а также несколько судебных исков от Илона Маска. Последняя новость – это не только (и не столько) очередное проявление эксцентричности Маска, на самом деле там довольно интересная историческая подоплека! В этой статье мы как раз хотим рассказать вам о том, как создавалась компания OpenAI, и что происходило у нее внутри до прорыва с ChatGPT и прихода всеобщей популярности.
А история там кроется не хуже, чем в фильме «Оппенгеймер»: сюжет создания OpenAI – это практически готовый оскароносный сценарий. Только если ядерные технологии от повседневной жизни находятся далеко, то ChatGPT лично я использую буквально каждый день.
В общем, ставки в этой истории такие же высокие, а исход от них мы все в итоге рискуем ощутить на себе
Откуда идут истоки этого текста: судебный иск Илона Маска к OpenAI
Почти ровно 12 месяцев назад, 29 февраля 2024 года, Илон Маск подал в суд на OpenAI и лично на Сэма Альтмана (CEO компании). Вот как на это отреагировала команда OpenAI (выдержка из их официального пресс-релиза, который они выложили на сайте в течение недели после этого иска):
Нам грустно, что до такого дошло с человеком, которым мы глубоко восхищались. Он вдохновил нас целиться выше, а потом сказал, что у нас ничего не получится, основал прямого конкурента и подал на нас в суд, когда мы начали добиваться значимого прогресса в реализации миссии без него.
Greg Brockman, Ilya Sutskever, John Schulman, Sam Altman, Wojciech Zaremba, OpenAI
Прочитав такое, сразу возникает желание задать вопрос: «Илон, ну не *удак ли ты?». И на этот вопрос можно с уверенностью ответить… Ладно, не будем спойлерить – предоставим вам право решать в итоге самостоятельно. Наше дело здесь – это подробно рассказать вам всю историю их непростых взаимоотношений, а также пертурбаций, которые претерпела сама компания с момента основания.
В чем была суть иска Илона Маска (опустим пока подробности, что он уже успел несколько раз ее поменять – отзывая старые иски и переподавая новые)? Он обвинил OpenAI в отходе от изначальной некоммерческой миссии, чрезмерной зависимости от Microsoft, и фокусе на максимизации прибыли.
В соцсети Х Маск, скажем так, тоже не сильно стеснялся в выражениях
Маск утверждает, что сделки с Microsoft заставили OpenAI вести себя как монополист: компания заняла 70% рынка генеративного ИИ, душит конкуренцию, запрещая партнерам инвестировать в другие компании, и предлагает сотрудникам нерыночные зарплаты.
Это противоречит изначальной миссии, в которую Маск, как он пишет, искренне верил: первыми создать дружелюбный AGI (универсальный искусственный интеллект, способный соображать не хуже человека) и сделать так, чтобы пользу от него получили все в мире, а не только избранные. Маск был не просто сооснователем, а источником финансов и основным драйвером амбиций, которые в итоге помогли компании построить самый быстрорастущий продукт в истории.
В ноябре 2024 года в рамках судебного разбирательства был опубликован архив переписки сооснователей OpenAI с момента незадолго до создания компании в 2015 и до 2019 года, когда их пути окончательно разошлись. Переписка довольно фрагментарная – с большими пробелами во времени и отсутствием того, что обсуждалось лично или через другие каналы.
Чтобы сделать историю более цельной, мы добавим контекст из других источников и постараемся пересказать именно самое интересное. Цитаты местами будут переводиться не дословно – поэтому тем, кто прямо хочет погрузиться в эту историю по-хардкору, советуем ознакомиться и с оригиналами (там много интересного). Ну и смело пишите, если увидите, что в переводе писем где-то сильно накосячено.
Основная цель этого лонгрида – показать, что у каждого участника этой истории есть своя правда.
Часть 1. Предыстория появления OpenAI на свет
Цепочка опубликованных писем начинается с, казалось бы, довольно странного питча Сэма Альтмана:
Я много размышлял и думаю, что человечество невозможно остановить от разработки ИИ. Так что, если это всё равно произойдет, то было бы неплохо, чтобы кто-то другой, а не Google, сделал это первым.
Как думаешь, было бы хорошей идеей запустить что-то вроде «Манхэттенского проекта» для ИИ? Мне кажется, мы могли бы привлечь немало топовых специалистов в индустрии. Можно было бы структурировать проект так, чтобы технология принадлежала всему миру (через некоммерческую структуру), но при этом разработчики получали бы конкурентные зарплаты на уровне стартапов.
Sam Altman to Elon Musk - May 25, 2015 9:10 PM
Почему Сэм с ходу пишет Илону Маску про Google, и зачем их вообще останавливать? Спокойно, ща мы всё объясним!
2014: DeepMind и его последующая покупка Гуглом
Илон Маск всегда был известен своим интересом к экзистенциальным рискам. Например, миссия SpaceX в том и заключается, чтобы спасти нашу цивилизацию от возможного вымирания на Земле. Ведь жить на двух планетах лучше (ну, по крайней мере, безопаснее), чем на одной.
В 2012 году Маск встретился с Демисом Хассабисом из компании DeepMind и заинтересовался темой искусственного интеллекта. Хассабис в разговоре набросил, что ИИ – это один из серьезнейших рисков. Колонизация Марса будет иметь смысл, только если сверхразумные машины не последуют за людьми и не уничтожат их и там. Маск идеей проникся и вложил $5 млн в DeepMind, чтобы быть ближе к фронтиру отрасли.
Теперь уже Нобелевский лауреат, руководитель всего AI в Google, и почетный рыцарь – сир Демис Хассабис
Вскоре стало ясно, что крупные компании активно переманивают самых талантливых исследователей из сферы глубокого обучения (Deep Learning). Например, Джеффри Хинтон изначально хотел пойти в Baidu за $12 млн, но устроил аукцион, на котором Google выкупил его за $44 млн.
Один из отцов-основателей ИИ, учитель Ильи Суцкевера, и Нобелевский лауреат с индексом Хирша под 188 – Джеффри Хинтон
Несмотря на это «искушение большим баблом», Демис Хассабис хотел, чтобы компания DeepMind оставалась независимой – именно для того, чтобы гарантировать, что ее AI-технологии не превратятся в итоге в нечто опасное. Но когда Ларри Пейдж (сооснователь Google) увидел, как DeepMind научили нейросеть играть в Atari, он тоже резко захотел «вписаться в перспективную тему».
В 2014 году Google предложил $650 млн за покупку DeepMind. И Демис всё же согласился, но настоял на двух условиях: никакого оружия и военного применения для технологии; и она должна контролироваться независимым советом по этике. (Спойлер: в феврале 2025 года Гугл в итоге отказался от обещания не использовать ИИ для создания оружия – не зря, выходит, Хассабис на эту тему переживал!)
2015: Маск ссорится с «гугловскими» из-за рисков ИИ
Тут надо сделать оговорку, что Илон Маск и Ларри Пейдж к этому моменту дружили уже больше 10 лет. Но, как говорит сам Маск, именно резкие различия в их взглядах на безопасность ИИ стали в итоге причиной того, что они прекратили общаться.
Илон Маск пристально смотрит на создателя гугловского PageRank-алгоритма (и, заодно, лучшего в мире печатного станка денег) Ларри Пейджа
Пиком стал их публичный спор на дне рождения Маска в июне 2015. Пейдж верил, что развитие технологий приведет к слиянию людей и машин (и что это хорошо). Дескать, разные формы интеллекта будут бороться за ресурсы, и в итоге победит сильнейший, и будет дальше жить-поживать. А вот Маску идея о том, что человечество может не войти в эту категорию «сильнейших», казалась не очень веселой.
Я часто разговаривал с ним допоздна о безопасности ИИ, Ларри недостаточно серьезно относился к этой проблеме. Его позиция была интересной: он стремился к созданию цифрового сверхинтеллекта – можно сказать, цифрового божества. Когда я однажды поднял вопрос о том, как мы собираемся обеспечить безопасность человечества, он обвинил меня в «видовом расизме» (Speciesism): по сути, в том, что я зря отдаю предпочтение людям в потенциальном конфликте с цифровыми формами жизни будущего.
Ну и, видимо, на этом дружба закончилась. Повздорили из-за роботов (да еще и, пока что, воображаемых)! Напомню, что это не какая-то научная фантастика, а вполне реальные люди – причем, руководящие крупнейшими мировыми корпорациями. Можете еще послушать вот этот короткий отрывок из интервью Маска Лексу Фридману, где он описывает свои идеологические разногласия с Ларри Пейджем:
В общем, у Илона Маска уже тогда были поводы, скажем так, не сильно доверять намерениям Гугла в отношении ИИ. Так что, после продажи DeepMind этому же самому Гуглу, Демису Хассабису не составило большого труда уговорить Маска присоединиться к специальному совету по этике – который должен был следить за тем, чтобы технология не была использована во зло. Первое заседание совета прошло в августе 2015-го и… чуда не произошло.
Ларри Пейдж вместе с Сергеем Брином и Эриком Шмидтом заявили, что все эти ваши опасения по поводу AI преувеличены. В итоге Маск посчитал такой совет фикцией, и на этом его участие в DeepMind благополучно закончилось. Ну а Google просто распустил этот этический совет, заменив его корпоративными гайдлайнами – что только усилило беспокойство Хассабиса. В 2017 году он с другими основателями даже попытался отделиться, но Гугл просто повысил им зарплаты + накинул опционов, и ребята остались. Как говорится, «баблу даже не нужно побеждать зло, если они играют за одну команду!»
2015: Создание OpenAI
А теперь давайте еще раз посмотрим на таймлайн происходящего по датам:
Январь 2014 – Google покупает DeepMind
Май 2015 – первое письмо Альтмана Маску с питчем «Манхэттенского AI-проекта»
Июнь 2015 – Маск посрался с Ларри Пейджем на ДР
Июль 2015 – Сэм, Илон и Грег Брокман «завербовали» в команду Илью Суцкевера
Август 2015 – провальное заседание комитета по этике DeepMind
Ноябрь 2015 – официальное создание компании OpenAI
В таком контексте, питч из первого письма Сэма Альтмана про «злой Гугл уже вот-вот создаст злой AI!» выглядит идеально. Он отправлен ровно в тот момент, когда у Илона уже зрело недовольство происходящим и желание что-то сделать с этим, но еще не было конкретного плана.
А Сэм как раз предлагает такой план: так как остановить Google невозможно, нужно его просто опередить! Если cобрать небольшую группу самых талантливых людей в отрасли, то можно первыми сделать сильный ИИ – и, при этом, поставить приоритет на использовании этой мега-технологии во благо всего мира.
Неудивительно, что миссия OpenAI (некоммерческой организации), сформулированная в декабре 2015, сейчас – 10 лет спустя – звучит крайне идеалистично:
OpenAI – это некоммерческая исследовательская компания. Наша главная цель – создать искусственный интеллект и сделать так, чтобы он принес максимальную пользу всему человечеству. Мы не обременены необходимостью получать прибыль, что дает нам уникальную свободу.
Мы можем полностью сосредоточиться на создании ИИ, который будет доступен для всех. Мы верим в демократизацию технологий и выступаем против концентрации такой мощной силы в руках избранных.
Наш путь непрост. Зарплаты у нас ниже, чем предлагают другие компании, а результат всего предприятия пока неясен. Но мы убеждены, что выбрали правильную цель и создали правильную структуру. Надеемся, что именно это привлечет к нам лучших специалистов в области.
Молоденькие Маск и Альтман во времена, когда они еще прекрасно общались между собой (2015 год)
Вообще, есть мнение, что OpenAI просто не смогли бы успешно запуститься без поддержки Маска. А он ее оказал именно из опасений, что Ларри Пейдж направит огромные ресурсы Google на создание сверхсильного искусственного интеллекта, не заботясь о его безопасности (тут будет уместно напомнить, что этой важной теме посвящен другой наш масштабный лонгрид).
Часть 2. С чем боролась свежевылупившаяся OpenAI: найм кадров и закуп железа
Почему роль Маска во всём этом была такой важной? Ответ простой: бабло! В ноябре 2015 Грег и Сэм обсуждали, сколько нужно денег, чтобы у OpenAI появился шанс тягаться «с большими парнями». Они планировали поднять $100 млн на грантах и донатах (плюс-минус на такую сумму у Альтмана в итоге и получилось выйти, включая, судя по всему, грант на $30 млн от Open Philanthropy).
Но Илон убедил их целиться в сумму в 10 раз больше, чтобы не выглядеть безнадежно отстающими по сравнению с конскими расходами Google и Facebook. Причем Маск, который к этому моменту уже успел закинуть в общую кубышку $45 млн «из своих» (поверх собранного Сэмом), пообещал добить недостающую сумму после сборов от других инвесторов до миллиарда долларов самолично.
И практически сразу стало понятно, почему он был прав. Об этом – как раз в этой части.
Фокус на найме: большие деньги для больших талантов
Главной стратегией OpenAI с самого начала было собрать небольшую, но сильную команду мотивированных специалистов, чтобы догнать Google. А чтобы привлекать лучших из лучших – нужна и компенсация соответствующая! И пока обсуждались зарплаты и плюшки, Сэм Альтман пришел с новостью, что DeepMind планирует перекупить всю команду OpenAI крупными контр-офферами. Они явно стремились устранить конкурента на ранней стадии, буквально загоняя людей в угол на проходящей в декабре 2015-го конфе NIPS.
Маск отреагировал на это однозначно:
Давайте повышать з/п. Выбор прост: либо мы привлекаем лучших в мире специалистов, либо DeepMind оставит нас позади. Я поддержу любые меры для найма топовых людей.
Elon Musk to Greg Brockman, (cc: Sam Altman) - Feb 22, 2016 12:09 AM
Из писем видно, как сложно было ребятам – они ворвались отстающими на рынок, где бигтех уже вел настоящую охоту за топовыми ресерчерами. Но на стороне OpenAI было, так сказать, «моральное превосходство»: ведь они как бы противостояли огромным бездушным корпорациям, пытаясь создать сильный ИИ на благо всего человечества. Вот здесь Маск дает понять Илье Суцкеверу (ключевому «мозгу» команды), что если они все вместе не поднапрягутся и не выдадут результат – то завалить Гугл будет просто нереально:
Вероятность того, что DeepMind создаст настоящий искусственный разум, растет с каждым годом. Через 2–3 года она, скорее всего, не превысит 50%, но, вероятно, преодолеет 10%. С учетом их ресурсов, это не кажется мне безумным.
В любом случае, лучше переоценивать, чем недооценивать конкурентов.
Нам важно добиться значимого результата в следующие 6–9 месяцев, чтобы показать, что мы действительно способны на многое. Это не обязательно должен быть прорыв мирового уровня, но достаточно значимый успех, чтобы ключевые таланты по всему миру обратили на нас внимание.
Elon Musk to Ilya Sutskever, (cc: Greg Brockman, Sam Altman) - Feb 19, 2016 12:05 AM
Вот он, Илья Суцкевер – признанное светило всея машин лёрнинга (в те времена он еще не щеголял своей фирменной прической)
Open Source как препятствие к конкуренции с тех-гигантами
В этой же парадигме «борьбы со злым Гуглом», кстати, логично рассматривать и изменение отношения OpenAI к концепции открытого кода – которая, казалось бы, намертво закреплена в самом названии этой некоммерческой организации. А вот, поди ж ты: уже начиная с модели GPT-3 (2020 год), OpenAI перестали выкладывать свои наработки в опенсорс. Так вот, на самом деле, предпосылки к этому обсуждались внутри команды задолго до этого момента.
По мере того, как мы приближаемся к созданию ИИ, имеет смысл начинать быть менее открытыми. «Open» в OpenAI означает, что все должны пользоваться плодами ИИ после его создания, но совершенно нормально не делиться результатами исследований, хотя это определенно правильная стратегия в краткосрочной перспективе для целей рекрутинга.
Ilya Sutskever to: Elon Musk, Sam Altman, Greg Brockman - Jan 2, 2016 9:06 AM
На письмо выше Илон Маск ответил пять минут спустя коротко, но однозначно: «Ага». Это уже потом, восемь лет спустя, у него случились массовые подгорания в Твиттере из-за «слишком закрытой» политики OpenAI; а вот в 2016-м Маск почему-то был совсем не против такой стратегии – не делиться самыми прорывными результатами исследований, чтобы их в итоге не скопировали «нехорошие люди».
Хотя, возможно, Илону тут не нравится чисто семантическое несоответствие названия компании и ее фактического поведения…
Смена парадигмы: не только люди, но и железки
Как видим из дискуссии в предыдущей паре разделов, в 2016 году команда OpenAI в основном ломала голову на тему «как бы нам привлечь на свою сторону самых няш-умняш индустрии» – и на это денег еще плюс-минус, как будто бы, хватало.
Но год спустя ситуация внезапно и резко поменялась: в марте 2017-го ребята осознали, что создание AGI потребует огромных вычислительных ресурсов. Ведь объем компьюта, используемого другими бигтех-компаниями для прорывных результатов, увеличивался по траектории «примерно в 10 раз каждый год». А это уже миллиарды долларов в год, которые просто так собрать некоммерческому проекту, казалось, попросту невозможно. OpenAI отчаянно нуждалась в новом плане!
Google Brain на конфе NIPS (декабрь 2017) хвастаются своим дорогущим железом на TPUv2
В чем тут дело, нам поможет объяснить Илья Суцкевер. Судя по разным интервью, Илья был именно тем человеком, кто одним из первых поверил в Scaling – мощное масштабирование способностей ИИ чисто за счет наращивания вычислительных мощностей – еще до того, как это полностью подтвердилось на практике:
Мы обычно считаем, что проблемы сложны, если умные люди долго не могут их решить. Однако последние пять лет показали, что самые ранние и простые идеи об искусственном интеллекте – нейронные сети – были верны с самого начала. А чтобы они заработали, нам просто не хватало современного железа.
Если наши компьютеры слишком медленные, никакая гениальность ученых не поможет достичь AGI. Достаточно быстрые компьютеры – необходимый элемент, и все прошлые неудачи были вызваны тем, что оборудование оказалось недостаточно мощным для AGI.
Отдельно Илья поясняет важное технологическое изменение, которое довольно сильно поменяло «правила игры» для разработчиков ИИ. До этого супердорогие суперкомпьютеры условного Гугла не столько ускоряли самые масштабные эксперименты по обучению нейросеток, сколько позволяли проводить много разных тестов поменьше. А это для ресерчеров не так важно, как скорость проведения больших экспериментов: для прогресса нужно как можно быстрее получить данные предыдущего «фронтирного» эксперимента, чтобы задизайнить и провести следующий, и так далее…
Раньше большой вычислительный кластер мог помочь тебе делать больше разных экспериментов, но он не позволял выполнить один большой эксперимент более быстро. По этой причине, небольшая независимая лаборатория могла конкурировать с Google – ведь его единственным конкурентным преимуществом была возможность одновременного проведения множества мелких экспериментов (это так себе преимущество).
Но сейчас стало возможным комбинировать сотни GPU (графических вычислительных чипов) и CPU (центральных процессоров), чтобы запускать эксперименты в 100 раз масштабнее за то же время. В результате, для сохранения конкурентоспособности любой AI-лаборатории теперь необходим минимальный вычислительный кластер в 10–100 раз больше, чем раньше.
Ilya Sutskever to: Greg Brockman, [redacted], Elon Musk - Jun 12, 2017 10:39 PM
Эпоха параллельных вычислений: больше, быстрее, ДОРОЖЕ
Ну, то есть, вы поняли? Одними топовыми ML-спецами теперь сыт не будешь – пришла эра параллельных вычислений, теперь надо еще расчехлять свинью-копилку для закупки графических чипов в промышленных масштабах! Кстати, именно эта смена технологического тренда в 2016–2017 и стала ранним звоночком-предзнаменованием к тому, что в 2024-м Nvidia станет крупнейшей и успешнейшей компанией в мире.
Дженсен Хуанг из Nvidia лично донатит в OpenAI в 2016 году один из первых серверов DGX-1 – кластера GPU, специально предназначенного для использования в тренировке ИИ (а принимает дар кто? лично батя Илон Маск!)
Позволим себе супер-краткий экскурс в историю о том, как графические чипы буквально всего лишь за пять лет стремительным домкратом ворвались в мир машинного обучения и обеспечили себе там доминирующее положение:
До 2012: Использование GPU вместо CPU при тренировке нейросетей было редкостью.
2012–2014: Большинство результатов достигалось на 1–8 GPU мощностью 1–2 терафлопс.
2014–2016: Крупные тренировочные запуски на 10–100 GPU мощностью 5–10 терафлопс. Однако, видеокарты всё еще неэффективно взаимодействовали друг с другом.
2016–2017: Появились новые чипы (TPU) и много разных подходов, улучшающих параллелизацию вычислений – вот тут-то и наступил расцвет «видеокарточного машинлёрнинга»!
Количество вычислительных ресурсов, необходимых для обучения прорывных нейросеток: удвоение происходит каждые три с половиной месяца [статья про компьют из старого блога OpenAI]
Каждые несколько лет GPU становятся мощнее. Чем лучше видеокарты, тем больше операций в секунду можно выполнять за ту же цену. Рост мощности компьюта в 10 раз в год происходит потому, что ресерчеры постоянно находят способы использовать больше чипов параллельно. И это открывает возможность практически безлимитно заваливать любую проблему деньгами. Илья Суцкевер пишет про это:
Главное – это размер и скорость наших экспериментов. Раньше даже крупный кластер не сильно ускорял проведение большого эксперимента. Но теперь можно проводить их в 100 раз быстрее.
Если у нас будет достаточно оборудования, чтобы проводить эксперименты за 7–10 дней, то история показывает, что всё остальное приложится. Это как в фундаментальной физике: ученые быстро выяснят как устроена Вселенная, если у них будет достаточно большой коллайдер.
Есть основания считать, что оборудование для глубокого обучения будет ускоряться в 10 раз ежегодно на протяжении ближайших 4–5 лет. Это ускорение произойдет не из-за уменьшения размеров транзисторов или увеличения тактовой частоты; оно произойдет потому, что, как и мозг, нейронные сети обладают внутренним параллелизмом, и уже создается новое высокопараллельное оборудование, чтобы использовать этот потенциал.
В общем, в переводе с нёрдовского языка на бизнесовый, письмо выше на самом деле пытается сказать «ДАЙТЕ НАМ БОЛЬШЕ ДЕНЯК НА ЧИПЫ!». Оглядываясь назад, Илья примерно в два раза переоценил масштаб происходящих процессов, но всё равно хорошо предсказал сам тренд.
2017: Не железом единым, или алгоритмический сюрприз от Google
Ровно месяцем ранее от последнего процитированного выше письма Суцкевера, 12 июня 2017 года, Google выпустили культовую 15-страничную научную статью Attention is All You Need, которая произвела настоящую революцию в мире глубокого обучения. Именно там была впервые представлена архитектура трансформеров!
Помните, как раньше Сири или Google-ассистент не могли поддерживать длительные разговоры, так как быстро теряли контекст? Главная тому причина – ограничение разных архитектур того времени: модель могла быть либо умной, либо обладать хорошей памятью (упрощаю, но суть примерно такая):
Свёрточные сети хорошо масштабируются, но теряют общую картину в длинных цепочках;
Рекуррентные сети лучше обрабатывают длинные цепочки, но плохо масштабируются.
Разные модели лучше подходили для разных задач: например, для перевода текста важны длинные цепочки, а для генерации изображений – внимание к локальным деталям, которое лучше у крупных моделей. Так вот, трансформеры убрали эту проблему в принципе, сохранив лучшее от обеих архитектур. Они умеют и видеть общую картину, и при этом отлично масштабируются!
Именно появление архитектуры трансформера, по сути, открыло эпоху больших языковых моделей (LLM), и привело в итоге к появлению того самого ChatGPT, который прогремел на весь мир в 2022-м. (Про историю создания и про принципы работы ChatGPT у нас, кстати, есть отдельная большая статья.)
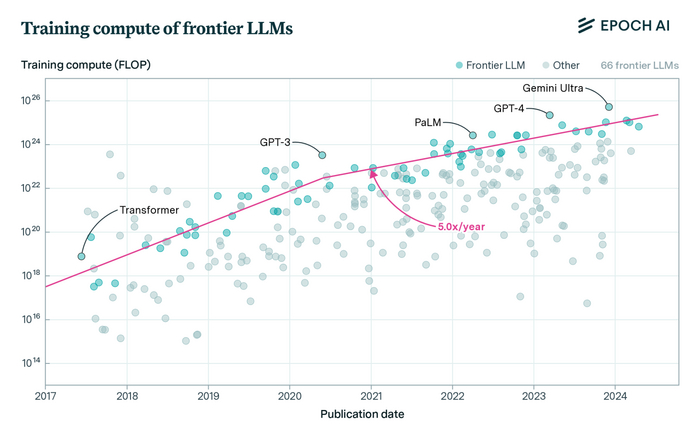
Начиная с появления трансформера, объем компьюта на тренировку передовых языковых нейросетей начал увеличиваться в 10 раз каждый год (!), и только с 2020-го тренд чуть замедлился до «жалких» х5 в год
Получается, в середине 2017 года два фактора идеально наложились друг на друга. Во-первых, новые GPU-чипы позволили мощно наращивать объем компьюта, который можно использовать при тренировке огромных моделей. А во-вторых, новаторская архитектура трансформера, собственно, позволила эти самые гигантские модели успешно обучать – чтобы при этом у них не разбегалось в разные стороны внимание, и они могли «держать в голове» необходимый контекст.
В общем, ситуация вышла такая: Железо нужное на рынке есть. Алгоритмы нужные придумали. Чего не хватает? Огромной кучи денег, чтобы всё это закупить и запустить! Вот об этом мы сейчас и поговорим…
К сожалению, третья (заключительная) часть материала не влезает на Пикабу из-за ограничений по объему. Окончание можно прочитать по ссылке на полную версию статьи вот здесь.
Сервисdraw-a-uiгенерирует сайт из простого наброска без знаний кода-GPT-4-Vision сам его пропишет и преоразует макет в рабочую страницу.Достаточно текстом указать,чтохотим увидеть на выходе, добавить кнопки, нарисовать элементы, и сервис создаст UI исходя из ваших желаний.
Хотите узнавать первыми о полезных сервисах с искусственным интеллектом для работы, учебы и облегчения жизни? Подпишитесь на мой тг НейроProfit, там я рассказываю, как можно использовать нейросети для бизнеса
Это вторая часть нашего лонгрида про то, что на самом деле скрывается внутри нейросетки для генерации видео под названием SORA. Если вы не читали первую часть, то начать лучше именно с нее.
Опускаемся на уровень глубже: Дум — крута!
Но вы поди уже устали смотреть на какие-то пиксельные машинки и гоночки, давайте возьмём что-то крутое. Как гласит культовая фраза, Дум — круто! Поэтому слегка сменим обстановку, и переместимся в новое игровое окружение с новыми правилами.
Дум — крута!
Дум — это 3Д-экшон, суть такова... здесь взята урезанная игра с понятной задачей: продержаться в комнате с монстрами-импами как можно дольше. Можно перемещаться влево-вправо, чтобы уклоняться от огненных шаров, запускаемых монстрами в другом конце комнаты. Чем больше времени продержишься — тем лучше.
Наконец-то запустили дум не только на мобилках и холодильниках, но и на Висишечке
Первым делом необходимо переобучить энкодер-декодер, а затем — модель мира. Мы уже детально обсудили, как это делать. Единственным изменением является то, что помимо следующего состояния мы также предсказываем нолик или единичку — в зависимости от того, закончилась ли игра (если вдруг в игрока попал огненный шар). Если мы хотим тренировать бота полностью в симуляции, то как иначе нам понять, что game is over?
Затем произведём обучение нейросети, отвечающей за контроль игрока — полностью внутри симуляции. То есть, этот агент не будет играть в игру вообще: ни один латент, на основе которого принимается решение (двигаться влево или вправо), не будет получен из реальных изображений. Да и самих изображений вообще нет — только цепочка последовательно предсказываемых сигналов, которые бот мог бы увидеть от реальной игры (если бы не летал в фантазиях).
На нашу радость, с помощью декодера мы можем подсмотреть, что происходит в этой симуляции — и даже при желании поиграть в неё самостоятельно (ведь симулятор предсказывает следующее состояние не только по текущему латенту, но и по действию — движется игрок или стоит). Ниже вы можете увидеть запись симуляции. Если в нижнем левом углу робот — то играет обученный бот, а если обезьянка — то ваш покорный слуга. :) Обратите внимание на счётчик времени слева сверху (он наложен отдельным скриптом) — игра обнуляется, если игрок ловит фаербол лицом.
Сорри за мыльную картинку: именно так выглядит игра «в фантазиях» нашей нейросетки, а не на реальном движке
Качество записи тут ниже потому, что и энкодер, и декодер учились на картинках меньшего разрешения. Прослеживается аккуратность симуляции — есть кирпичные стены по бокам, через которые нельзя пройти, огненные шары летят по своей траектории, задаваемой в момент атаки. Однако и артефакты сложно не заметить: монстров то больше, то меньше, хотя по правилам их число должно строго увеличиваться.
Plot twist: пересаживаемся в «реальный мир»
Окей, ну вроде и обезьяна, и робот играют на равных (я старался, честно). Поигравшись с настройками, авторы исследования замерили качество: в 100 подряд идущих симулированных играх бот проживал в среднем 918 кадров (чуть больше 20 секунд). Теперь переходим к развязке — этого обученного бота, без любой промежуточной адаптации, заставляют играть в настоящую игру, а не симулятор. Теперь состояние среды формируется уже по известному сценарию: изображение из игрового движка обрабатывается энкодером в сигнал, с опорой на который (и на свою модель мира) бот делает предсказание, двигаться ли ему влево, вправо или замереть.
Сколько этот бычара смог продержаться не в своих мечтах, а на деле? Смог вывезти за базар? Ну, да — в реальной игре он продержался в среднем 1092 кадра (даже больше, чем в симуляции). Это большой скачок по отношению к другим методам обучения — на тот момент лучшим считался результат 820 кадров.
То есть, обучение в симуляции не то что просто кое-как перенеслось на настоящую «жизнь» (игру, которую мы симулировали), а сделало это с сохранением качества, да вдобавок еще и показало себя лучше других методов. Где-то тут полезно бы вспомнить, что новую модель SORA для генерации видео в OpenAI называют симулятором миров... но до этого мы ещё дойдем. А то вдруг окажется, что на примитивных игрушках это всё работает, а реальная-то жизнь она ж совсем не такая?
А пока вернёмся к примеру с машинкой. Может быть он вас не впечатлил? Тоже игрушка ведь. Ну едет и едет по симулированному треку, чего бубнить. Но что, если я скажу вам, что стартап Wayne, занимающийся разработкой автопилотов, ещё в далёком 2018 году опробовал метод на реальном транспортном средстве? И вот что у них получилось:
Кстати, вы обратили внимание на дождь? Не беда, если нет (ваш энкодер решил опустить эту деталь, не так ли?). Но вот что интересно: в этом случае модель училась водить в симуляторе, данные для которого были собраны исключительно в солнечную погоду. Но это не помешало обучить бота, который будет ездить в дождь! Сосредоточившись на том, что имеет отношение к принятию решений при вождении, система не отвлекается на отражения от луж или капли воды на стекле. Фактически, модель фокусируется на том, что имеет отношение к вождению, и это позволит применить подход к ситуациям, не встреченным во время тренировки.
Но не всё так радужно с симуляциями
Мы уже упомянули выше, что симуляции неидеальны: в Doom неправильно (непоследовательно) отображается количество врагов во времени. Но есть и куда более серьёзная проблема. Поскольку используемая модель мира является лишь приближением среды, то иногда она выдаёт состояния, которые не соответствуют правилам, задаваемым окружением. По этой причине бот, обучающийся в фантазиях, может наткнуться на неточность и начать её эксплуатировать. В примере с Doom это может выглядеть так:
То чувство, когда запустил в игре настолько «изи мод», что враги даже забыли тебя атаковать
Здесь бот нащупывает такое состояние, в котором симуляция не считает нужным запускать огненные шары в игрока — а значит, и умереть нельзя. И это может оказаться как просто мелким недостатком при переносе в реальную игру (или, тем более, мир), так и критической уязвимостью, приводящей к непредсказуемому непонятному поведению. Если мы будем учить автопилоты для реальных дорог в симулированной среде — лучше удостовериться, что пешеходы там не умеют телепортироваться на пару метров в сторону, когда возникает риск сбивания их машиной.
Причин неидеальности симуляции можно выделить две: недостаток данных для конкретной ситуации (из-за чего возникает «дырка» в логике симулятора) и недостаточная «ёмкость» обучаемой модели мира.
Про решение первой проблемы поговорим совсем вкратце (оно достаточно техническое, и не вписывается в рамки статьи). Один подход заключается в уменьшении предсказуемости среды в симуляторе, когда из одного и того же состояния игра может перейти в совершенно разные фазы на следующем шаге. Причём, можно управлять степенью случайности, находя баланс между реализмом и эксплуатируемостью (абсолютно случайную среду не получится обмануть — ведь она не зависит от твоих действий). Другое решение — привить обучаемому боту любопытство. Сделать это можно, например, если штрафовать его за то, что он слишком слабо меняет состояние среды (засиживается на месте), или же наоборот поощрять за новые свершения. Вы не поверите, но один из ботов в таком эксперименте начал залипать в аналог «телевизора», щёлкая каналы. В конце концов, мы не так уж сильно и отличаемся друг от друга. :)
Агент слева оказался настолько любознателен, что подсел на иглу телевидения. У бота справа телевизора в лабиринте попросту не было, поэтому он успешно выбрался. Вывод: если хотите спрятать сокровища — оставьте в лабиринте телевизор.
А что делать с ёмкостью модели? На данный момент известен лишь один гарантированный способ, который даст результат при любых обстоятельствах: масштабирование. Это означает, что мы можем увеличить размер нейросети, пропорционально увеличить размер корпуса тренировочных данных, и как следствие потратить больше ресурсов на обучение.
Все остальные способы, хоть иногда и могут сработать (взять более чистые данные/выбрать другую архитектуру модели/и т.д.), но имеют свои ограничения, а главное — могут перестать работать. Для больших нейронных сетей (в том числе и языковых моделей вроде ChatGPT) уже пару лет как вывели эмпирический закон, который показывает, насколько вырастет качество при увеличении потребляемых при тренировке ресурсов. Это называется «закон масштабирования».
Нужно БОЛЬШЕ ВИДЕОУСКОРИТЕЛЕЙ!
И масштабирование сейчас — одна из самых главных причин, по которой вы всё чаще и чаще в последнее время слышите про AI, и почему наблюдается рост качества. Если раньше модели обучали на одном, ну может на двух серверах в течении пары недель, то теперь компании арендуют целые датацентры на месяцы. По сути, появился способ закидать проблему шапками, покупай больше видеокарточек — и дело в шляпе шапке. Это одновременно и хорошо, и плохо — с одной стороны мы точно знаем, что можно получить нейросеть получше, а с другой — она будет стоить дороже.
Вернёмся к ранее упомянутому стартапу Wayne, продолжающему заниматься беспилотными автомобилями. Они всё ещё фокусируются на создании моделей мира как вспомогательном инструменте обучения алгоритмов (прямо как OpenAI). В прошлом году они представили свою модель GAIA-1, которая... тоже была обучена предсказывать будущие кадры в видео. На видео ниже вы можете увидеть сравнение ранней модели, обученной летом 2023 года, с более поздней, на которую потратили существенно больше ресурсов («отмасштабировали»).
Да, оба видео сгенерированы почти полностью, реальным является лишь первый кадр, общий и для левой, и для правой демонстрации. Однако здесь мы наблюдаем реконструкцию с использованием декодера, а не входное изображение — поэтому уже на первой секунде заметна разница. Во-первых, вдалеке виднеются светофоры — а значит у модели мира будет задача их симулировать. Во-вторых, детали вроде машин и деревьев стали намного чётче. В-третьих, улучшилась согласованность последовательно идущих кадров (посмотрите на «плавающие» формы машин справа в самом начале). Подход один и тот же, архитектура модели и принцип обучения те же — а результат качественно лучше.
Такой продвинутый симулятор может показывать и более сложные сцены, а не просто езду по прямой. Следующий пример демонстрирует, что модель мира может помочь симулировать взаимодействие с другими участниками дорожного движения. В варианте слева белый автомобиль дает задний ход, уступая нам дорогу. Во втором развитии схожего сценария (и оба — в визуализированной «фантазии» модели!) мы уступаем дорогу и позволяем выполнить разворот — при этом наш автомобиль замедляется. Здесь оба видео порождены одной и той же моделью, разница лишь в выборе развития событий (та самая случайность в модели мира).
Вуаля, теперь можно обучать модель автопилота в симуляции, порождаемой «фантазией» модели мира, без выезда на реальную дорогу с риском для водителей, и при этом инсценировать любые желаемые сценарии. Однако нейронке есть куда расти: на её обучение потратили ресурсов в 100 раз меньше, чем на одну из лучших доступных языковых моделей LLAMA-2-70B от META (ex-Facebook, на территории РФ признана экстремистской), и приблизительно в 2000 раз меньше, чем (по слухам) OpenAI потратили на GPT-4 — самую лучшую Large Language Model (LLM) на данный момент. Представляете, какой потенциал для улучшений? (Конечно представляете — просто посмотрите на OpenAI SORA!)
Единственная разница между сгенерированными видео — количество вычислительных мощностей, потраченных на обучение SORA. На демонстрацию справа суммарно было использовано в 32 раза больше ресурсов, чем на жутенькую The Thing слева.
Есть ли модели мира у LLM?
Ну, раз уж мы заговорили про большие языковые модели, то давайте сделаем отступление и попробуем разобраться: а есть ли модель мира у них. С одной стороны, зрением они не обладают, лишь читают текст в интернете, а с другой — ну что-то же они должны были выучить? Сразу после этого блока мы перейдем к модели SORA, с которой всё и начиналось, и в целом вы можете пропустить эту часть без потери смысла — но мимо вас пройдёт столько всего интересного!
Примерно 95–98% ресурсов тренировки больших языковых моделей тратится на обучение задаче предсказания следующего слова в некотором тексте. Под «некоторым» здесь подразумевается почти любой текст на сотне языков, доступных во всём интернете. Там есть и Википедия (как база знаний и фактов), и учебники по физике, описывающие принципы взаимодействия объектов (включая силы гравитации), есть детективные истории, и много чего вообще. Каждый раз модель смотрит на часть предложения и угадывает следующее слово. Если она сделает это правильно, то обновит свои параметры так, чтобы закрепить уверенность в ответе; в противном случае она извлечет уроки из ошибки и в следующий раз даст предсказание получше.
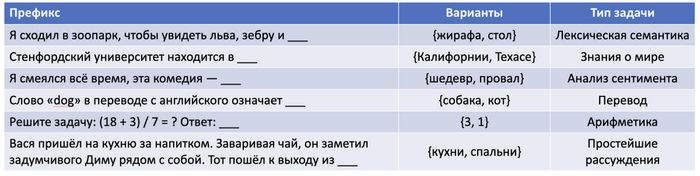
Префиксы — это примеры некоторых контекстов из интернета. Далее идут потенциальные варианты продолжения (то есть следующего слова, которое нужно предсказать). В последней колонке определен тип задачи (классификация тут условная, а не строгая и однозначная)
Давайте посмотрим на примеры в табличке выше. Чтобы предсказать следующее слово для каждого из префиксов, нужно либо обладать конкретными знаниями, либо уметь рассуждать. Иногда это может быть двумя сторонами одной и той же монеты: например, можно запомнить базовую таблицу умножения, но также через неё понять и тысячи более сложных примеров (которые в этой таблице не встречались), и затем начать корректно применять принципы математических операций.
OpenAI в этом плане двигались постепенно — первые проверки гипотезы о том, что языковая модель при обучении строит модель мира, помогающую ей успешно предсказывать следующее слово, были ещё до GPT-1. Исследователи предположили, что если взять достаточно большую по тем временам модель, и обучить её на 40 Гигабайтах отзывов с Amazon (при этом не показывая, какой рейтинг оставил пользователь — только текст), то скорее всего нейросеть сможет сама «изобрести» внутри себя концепцию сентимента. Иными словами, она сможет определять, является ли отзыв позитивным или негативным. С учётом того, что в явном виде мы никак эту информацию не сообщаем — было неочевидно, получится ли разобраться со столь сложной и абстрактной вещью, которая существует только у нас в голове: сентимент текста. Ведь это не природное явление, не закон физики — это то, как мы, люди, придумавшие свои искусственные языки, воспринимаем информацию.
Сказано — сделано. В OpenAI обучили модель, а затем рассмотрели её латент (да, там тоже модель сначала сжимает текст в понятные ей сигналы, а затем переводит его обратно в текст) под микроскопом. Так же, как мы пытались крутить 15 чиселок латента на гифке с игрушечной трассой, исследователи пытались найти такой параметр (из 4096 разных, если вам интересно), который был бы связан с сентиментом. И, как уже должно быть понятно, нашли!
Но как для текста можно понять, что вот, скажем, семнадцатая цифра в нашем латенте отвечает за сентимент? Пробуется два способа: это анализ зависимости значения от входной последовательности (текста отзыва), и сентимента генерируемого текста (= «фантазии» модели) от этого же значения. Мы как бы отвечаем на два вопроса: «Правда ли значение предсказуемо меняется из-за отзыва?» и «Правда ли, что модель опирается на это значение, то есть, сгенерированный отзыв меняется из-за значения в латенте?»
Сначала про первое. Давайте возьмём тысячи отзывов, но уже не с Amazon, а с американского аналога Кинопоиска, IMDB. Для каждого из них определим, являются ли они позитивными или негативыми. Затем будем подавать эти отзывы в модель (грубо говоря использовать энкодер для получения латента, хоть в языковых моделях это устроено чуть иначе) и смотреть, как меняется найденная цифра. Можно сделать визуализацию в виде гистограмы, на которой отзывы с разным сентиментом окрашены в разные цвета.
Горизонтальная шкала показывает, как негативные (голубым) и позитивные (оранжевым) отзывы распределились по значениям найденного нами внутри модели параметра, отвечающего за сентимент.
По графику видно, что для негативных отзывов модель зачастую показывает значения ниже нуля (аналог с визуализацией гоночной трассы — один ползунок выкручен влево), а для позитивных — выше. И «горбики» распределений почти заметно отличаются. Те отзывы, что попадают на пересечение, скорее всего имеют смешанный сентимент: может, там фильм и хвалят, и ругают? Таким образом, мы можем сказать, что состояние модели меняется в зависимости от сентимента конкретного отзыва — становится больше или меньше.
Но опирается ли нейронка на эту модель мира? Считается ли конкретно этот латент важным во время запуска симуляции (в которую мы можем подсмотреть уже не визуально, а по сгенерированному тексту)? Давайте зафиксируем все остальные значения латента (через установку одинакового начала отзыва), и сначала сгенерируем отзыв о фильме, указав большое положительное значение, а затем — отрицательное. По идее, если для модели этот признак важен, мы ожидаем увидеть очень положительный, хвалебный отзыв, а за ним — негативный.
Результаты генерации. Зелёным выделены позитивные части отзывов, красным — негативные.
И ровно это учёные и обнаружили — при генерации ответ модели существенно меняет свой окрас в зависимости от лишь одной цифре в латенте. Но главная фишка в том, что мы не давали модели никакого понимания, что такое сентимент, и какими словами он выражается — вообще ничего, кроме кучи текстов. И всё же для модели мира оказалось удобнее (выгоднее?) кодировать данные так, чтобы сентимент легко разделялся, и им можно было управлять.
Этот игрушечный пример послужил толчком для OpenAI к развитию идей в модели GPT-1, а GPT-2 и 3 были дальнейшим масштабированием: больше модель, больше текстов, и как следствие более полная картина мира, выработанная внутри нейросети. Поскольку теперь кроме отзывов мы показываем тексты вообще про всё на свете, от комментариев на Дваче до учебника по физике, то модель выучивает огромное количество вещей, не только простой сентимент.
Очень сложно оценить наперёд, насколько комплексной и многогранной будет модель, и что будет зашито в её модель мира. Бывают комичные случаи: знакомьтесь, Ян Лекун, лауреат премии Тьюринга (аналог Нобелевки в компьютерных науках) за вклад в область нейронных сетей. За это его ещё называют одним из трёх крёстных отцов искусственного интеллекта. В настоящее время является вице-президентом по AI в компании META. Кажется, уж он-то точно хорошо разбирается в предмете?
Те самые трое крёстных отцов AI (Ян Лекун справа). Вообще говоря, к настоящему моменту они между собой немного все разосрались, но это уже совсем другая история...
В подкасте Лексу Фридману от 23 января 2022 года Ян говорил: «Я не думаю, что мы можем научить машину быть разумной исключительно на основе текста, потому что я думаю, что объем информации о мире, содержащейся в тексте, ничтожен по сравнению с тем, что модели нужно знать. Вы знаете, что люди пытались сделать это в течение 30 лет, верно? <...> Я думаю, что это в принципе безнадежно, но позвольте мне привести пример. Я беру предмет, кладу его на стол и толкаю стол. Для вас совершенно очевидно, что предмет будет двигаться вместе со столом, верно? Потому что он на нём лежит. Но в мире нет текста, объясняющего это! И поэтому, если вы тренируете машину, настолько мощную, насколько она может быть, например, ваш GPT-5000 или что-то еще, она никогда не узнает эту информацию. Этого просто нет ни в одном тексте».
Менее чем через год вышла ChatGPT (GPT-3.5), которая...правильно отвечала на этот вопрос. Ну ладно, ошибся дядька, наверное, где-то в учебниках физики был схожий пример. Когда в Твиттере ему за это предъявили, то он придумал новую мега-супер-сложную задачку. Сейчас-то наверное подготовился? Не стал щадящие примеры выбирать? Он выбрал задачку с шестерёнками... которую модель решила сходу, сразу же.
Тогда через месяц он придумал усложнение: «7 стержней равномерно распределены по кругу. На каждом стержне установлена шестерня, так, что она находится в сцеплении с шестернями слева и справа. Шестерёнки пронумерованы от 1 до 7 по кругу. Если бы третья шестерня была повернута по часовой стрелке, в каком направлении вращалась бы седьмая?». Родители с детьми в начальной школе уже словили флешбеки от домашки по физике, но теперь они хотя бы узнают, что... GPT-4 и на такой вопрос даёт правильный ответ.
На размышление даётся 30 секунд. Пишите в комментах, кто оказался умнее — вы или GPT-4?
GPT-4 вообще удивила многих. Вот как думаете, можно ли ответить на такой вопрос к следующей картинке, не понимая физику нашего мира, не моделируя взаимодействия объектов? Что произойдет с мячиком, если перчатка упадёт?
GPT-4 может принимать текст вместе с изображением, и умеет отвечать на вопросы, требующие визуальной информации. Тут модель правильно предсказала, что мячик подлетит наверх.
Позиция Яна не в том, что модели так не могут в принципе — он лишь не верил, что сложным физическим описаниям можно научиться либо просто по тексту, либо что такой текст вообще существует. И был не прав. Этот пример призван показать, что не стоит загадывать наперёд, что не смогут делать системы завтрашнего дня.
Конечно, модель могла не «понять» физику и уж тем более не строить модель мира, а быть обученной на таких же или уж очень похожих задачах. Однако я уже со счёта сбился от количества примеров с вопросами про очень специфичные и даже закрытые штуки, которые публикуют пользователи, но для которых, тем не менее, GPT-4 даёт адекватные ответы. Один, два, три раза — можно списать на запоминание, но были случаи...
И даже у столь мощной GPT-4 модель мира всё еще не идеальна, и то и дело приводит к глупым ошибкам. «Все модели неправильны, но некоторые из них полезны», помните?
OpenAI SORA: эмулятор Вачовски или симулятор мира?
Наконец, переходим к десерту. Такое длинное вступление было необходимо для того, чтобы наглядно продемонстрировать читателю крайне важные в контексте новой модели OpenAI тезисы:
Модели мира помогают агенту принимать решение с учётом информации о возможном будущем
Для того, чтобы успешно предсказывать будущее состояние, важно понимать лежащие в основе формирования среды процессы
Модели мира строят предсказания не в привычном нам виде, а в понятном им мире преобразованных сигналов (латентное пространство)
Мы можем заглянуть внутрь, но реконструкция не будет идеальной
Бот, обученный в симулируемой моделью мира сцене, может проявлять навыки и в реальной среде
Масштабирование модели всегда приносит улучшения, при этом многие из них неочевидны и сложнопредсказуемы
И вот теперь, когда мы разобрали концепцию моделей мира и посмотрели, для чего они могут использоваться, мы будем смотреть на примеры и пытаться понять, а в чём же именно ВАУ-эффект модели SORA. Она, как и GPT-4, выработала внутри себя какую-то модель мира, помогающую предсказывать следующий кадр в огромной разнообразной выборке всевозможных видео. Рендеринг финального изображения — это лишь реконструкция того, что предсказывает модель (потому что мы смотрим на это через призму декодера; хоть он и достаточно мощный, но имеет свои недочёты).
Пример, которым OpenAI решили похвастаться и вывести в начало своего блогпоста, вы уже видели в превью статьи. Это одноминутное FullHD @ 30 к/сек. видео, сгенерированное по текстовому запросу (промпту): «Элегантная женщина идет по улице Токио, озаренной теплым светом неоновых огней и анимированных городских вывесок. На ней черная кожаная куртка, длинное красное платье и черные ботинки, в руке черная сумочка. Она в солнцезащитных очках и с красной помадой. Шагает уверенно и непринужденно. Асфальт улицы мокрый, отзеркаливающий яркие огни. Вокруг ходит множество пешеходов.»
Во-первых, сложно не заметить точнейшее соблюдение всех деталей промпта в сгенерированном видео. Даже если сильно захотеть — разве что субъективные «элегантная женщина» и «шагает уверенно» можно подвергнуть сомнению, но, по-моему, модель справилась отлично. В этом заслуга специального приёма, использовавшегося OpenAI при разработке их предыдущей модели, DALL-E 3 (делает генерацию изображения по текстовому запросу, как MidJourney).
Так как зачастую текстовые подписи к картинкам и роликам в интернете очень короткие и несут лишь поверхностное (а иногда и неточное) описание происходящего, исследователи предложили применить умницу GPT-4 для генерации более подробных описаний. Для этого видео нарезалось на кадры, и языковая модель получала команду создать детальные подписи к происходящему в нескольких подряд идущих изображениях. Текстовые комментарии выходят не в пример длиннее, с большим количеством нюансов, поэтому обученная text-2-image или text-2-video модель гораздо охотнее обращает внимание на запрос, пытаясь соответствовать каждой его частичке. Даже лучшие платные аналоги моделей еле-еле оперируют двумя, самый край тремя предложениями — а тут мы нагрузили деталей на 5 строчек! Для DALL-E 3 процент синтетических текстов был 95%, вероятно, в SORA плюс-минус такой же.
Во-вторых, общий визуал существенно превосходит ожидания от моделей на данный момент. В Твиттере даже шутят, что «это был невероятный год прогресса AI... за один час». Тут сложно не согласиться, особенно если последнее демо, что вы видели — это Уилл Смит со спагетти из начала статьи. Но в сцене, кажется, учтено почти всё. Если заведомо не знать, что это генерация и не ждать подвоха — сразу и не скажешь. Освещение, отражения, толпа людей, переход на ближний план с детализацией текстуры кожи, плавность перемещения камеры с соответствующим изменением углов обзора на объекты в фоне. А те объекты, что пропадают из поля зрения на несколько секунд (люди сзади, синий дорожный знак на стене справа), возвращаются без изменений — такой консистентности во времени раньше и не мечтали добиться!
Моя модель мира предсказывает, что этот карандаш пропадёт из поля зрения через пару секунд. И... он испарился!
В-третьих, давайте поговорим про недостатки. Я пересмотрел видео около десятка раз, и самые заметные изменения происходят, если сравнивать начало и конец. На секундах с 55 по 59 вы можете заметить, что: 1) из рук пропадает чёрная сумочка; 2) левый лацкан куртки стал аномально большим (и даже испортил симметрию), да и правый прибавил в размере; 3) на красном платье на груди появляются чёрные пятна; 4) меняется причёска, появляется завихрение волос. Есть и комичные проблемы — обратите внимание, как левая нога превращается в правую (и наоборот) на секундах 15 и 29. И как после такого заснуть? А на секундах 16–17 ноги группы людей слева (парень, проходящий мимо двух азиаток в масках) будто бы окутаны водным шаром и очень расплывчаты.
Важно отметить, что часть этих проблем наверняка лежит на неидеальности реконструкции декодера, а часть — на проблемах с моделью мира. А может быть, собака зарыта где-то ещё, мы не знаем. Дело осложняется тем, что ни у кого, кроме OpenAI и их доверенных лиц, нет доступа к нейросети, чтобы это можно было проверить. Помните, как в эксперименте с числом в латенте, влияющим на генерацию отзыва? Тогда исследователи могли однозначно проверить, что будет, если его дёргать туда-сюда, здесь же подобного анализа не производилось. И всё же сделаю смелое предположение и скажу, что пронумерованные проблемы из абзаца выше скорее всего являются недостатками модели мира (исчез объект? поменялась форма чуть ли не самого крупного объекта в кадре? как так?!), а вот проблемы с отображением ног — уже реконструкции (потому что энкодер и декодер не посчитали нужными кодировать информацию о двух ногах, находящихся рядом).
Подобный артефакт можно было наблюдать на одном из видео выше, в симуляторе для автопилота. Там сами машины и окружение были достаточно чёткими, а вот диски колес как будто бы не крутились, и были очень шумными. Вероятнее всего, при обучении модель сочла, что куда выгоднее кодировать такие признаки, как размер авто, направление его движения, скорость, а вот насколько повёрнуты колёса в каждый момент времени уже можно подзабить — ведь это не так важно, и мы, люди, тоже не обращаем внимания при вождении на этот шум. Помните, что модель мира предсказывает будущее состояние, но не вся информация одинаково полезна для этой цели.
А так как информация не присутствует в модели мира и латенте, то и декодер не может грамотно восстановить картинку.
Но с этим связана и неожиданная хорошая новость! Раз модель мира не уделяет внимание такой детали, то и несоответствие картинки из декодированного видео настоящему миру не так критично. Ведь энкодер при сжатии видеопотока в латент для обработки (или симуляции) также опустит эти детали! В итоге, латент для реальной картинки и для «симулированной» будет почти одинаковым (хоть проблемы в реконструкции заметны невооружённым глазом). А значит наш бот, играющий в симуляторе, не заметит подвоха, и сможет потенциально оперировать в реальном мире. То, что может быть критично для создателей видеоконтента в силу неидеальности визуала, абсолютно не мешает основной цели модели SORA!
Так, и мы опять не влезли в ограничение Пикабу по количеству символов на один материал. :) Заключительная часть статьи находится вот здесь (осталось совсем немного потерпите!).





















![Количество вычислительных ресурсов, необходимых для обучения прорывных нейросеток: удвоение происходит каждые три с половиной месяца [<a href="https://pikabu.ru/story/ilon_mask_protiv_openai_polnaya_istoriya_ot_lyubvi_do_nenavisti_12399657?u=https%3A%2F%2Fopenai.com%2Findex%2Fai-and-compute%2F&t=%D1%81%D1%82%D0%B0%D1%82%D1%8C%D1%8F%20%D0%BF%D1%80%D0%BE%20%D0%BA%D0%BE%D0%BC%D0%BF%D1%8C%D1%8E%D1%82&h=e59d0d0bd4749fa9b276a0e97bc2910c18b84b84" title="https://openai.com/index/ai-and-compute/" target="_blank" rel="nofollow noopener">статья про компьют</a> из старого блога OpenAI]](https://cs15.pikabu.ru/post_img/2025/02/20/4/1740029983253579345.jpg)