
Настоящее предназначение OpenAI SORA, часть 2
Это вторая часть нашего лонгрида про то, что на самом деле скрывается внутри нейросетки для генерации видео под названием SORA. Если вы не читали первую часть, то начать лучше именно с нее.
Опускаемся на уровень глубже: Дум — крута!
Но вы поди уже устали смотреть на какие-то пиксельные машинки и гоночки, давайте возьмём что-то крутое. Как гласит культовая фраза, Дум — круто! Поэтому слегка сменим обстановку, и переместимся в новое игровое окружение с новыми правилами.

Дум — крута!
Дум — это 3Д-экшон, суть такова... здесь взята урезанная игра с понятной задачей: продержаться в комнате с монстрами-импами как можно дольше. Можно перемещаться влево-вправо, чтобы уклоняться от огненных шаров, запускаемых монстрами в другом конце комнаты. Чем больше времени продержишься — тем лучше.
Наконец-то запустили дум не только на мобилках и холодильниках, но и на Висишечке
Первым делом необходимо переобучить энкодер-декодер, а затем — модель мира. Мы уже детально обсудили, как это делать. Единственным изменением является то, что помимо следующего состояния мы также предсказываем нолик или единичку — в зависимости от того, закончилась ли игра (если вдруг в игрока попал огненный шар). Если мы хотим тренировать бота полностью в симуляции, то как иначе нам понять, что game is over?
Затем произведём обучение нейросети, отвечающей за контроль игрока — полностью внутри симуляции. То есть, этот агент не будет играть в игру вообще: ни один латент, на основе которого принимается решение (двигаться влево или вправо), не будет получен из реальных изображений. Да и самих изображений вообще нет — только цепочка последовательно предсказываемых сигналов, которые бот мог бы увидеть от реальной игры (если бы не летал в фантазиях).
На нашу радость, с помощью декодера мы можем подсмотреть, что происходит в этой симуляции — и даже при желании поиграть в неё самостоятельно (ведь симулятор предсказывает следующее состояние не только по текущему латенту, но и по действию — движется игрок или стоит). Ниже вы можете увидеть запись симуляции. Если в нижнем левом углу робот — то играет обученный бот, а если обезьянка — то ваш покорный слуга. :) Обратите внимание на счётчик времени слева сверху (он наложен отдельным скриптом) — игра обнуляется, если игрок ловит фаербол лицом.
Сорри за мыльную картинку: именно так выглядит игра «в фантазиях» нашей нейросетки, а не на реальном движке
Качество записи тут ниже потому, что и энкодер, и декодер учились на картинках меньшего разрешения. Прослеживается аккуратность симуляции — есть кирпичные стены по бокам, через которые нельзя пройти, огненные шары летят по своей траектории, задаваемой в момент атаки. Однако и артефакты сложно не заметить: монстров то больше, то меньше, хотя по правилам их число должно строго увеличиваться.
Plot twist: пересаживаемся в «реальный мир»
Окей, ну вроде и обезьяна, и робот играют на равных (я старался, честно). Поигравшись с настройками, авторы исследования замерили качество: в 100 подряд идущих симулированных играх бот проживал в среднем 918 кадров (чуть больше 20 секунд). Теперь переходим к развязке — этого обученного бота, без любой промежуточной адаптации, заставляют играть в настоящую игру, а не симулятор. Теперь состояние среды формируется уже по известному сценарию: изображение из игрового движка обрабатывается энкодером в сигнал, с опорой на который (и на свою модель мира) бот делает предсказание, двигаться ли ему влево, вправо или замереть.
Сколько этот бычара смог продержаться не в своих мечтах, а на деле? Смог вывезти за базар? Ну, да — в реальной игре он продержался в среднем 1092 кадра (даже больше, чем в симуляции). Это большой скачок по отношению к другим методам обучения — на тот момент лучшим считался результат 820 кадров.
То есть, обучение в симуляции не то что просто кое-как перенеслось на настоящую «жизнь» (игру, которую мы симулировали), а сделало это с сохранением качества, да вдобавок еще и показало себя лучше других методов. Где-то тут полезно бы вспомнить, что новую модель SORA для генерации видео в OpenAI называют симулятором миров... но до этого мы ещё дойдем. А то вдруг окажется, что на примитивных игрушках это всё работает, а реальная-то жизнь она ж совсем не такая?
А пока вернёмся к примеру с машинкой. Может быть он вас не впечатлил? Тоже игрушка ведь. Ну едет и едет по симулированному треку, чего бубнить. Но что, если я скажу вам, что стартап Wayne, занимающийся разработкой автопилотов, ещё в далёком 2018 году опробовал метод на реальном транспортном средстве? И вот что у них получилось:
Кстати, вы обратили внимание на дождь? Не беда, если нет (ваш энкодер решил опустить эту деталь, не так ли?). Но вот что интересно: в этом случае модель училась водить в симуляторе, данные для которого были собраны исключительно в солнечную погоду. Но это не помешало обучить бота, который будет ездить в дождь! Сосредоточившись на том, что имеет отношение к принятию решений при вождении, система не отвлекается на отражения от луж или капли воды на стекле. Фактически, модель фокусируется на том, что имеет отношение к вождению, и это позволит применить подход к ситуациям, не встреченным во время тренировки.
Но не всё так радужно с симуляциями
Мы уже упомянули выше, что симуляции неидеальны: в Doom неправильно (непоследовательно) отображается количество врагов во времени. Но есть и куда более серьёзная проблема. Поскольку используемая модель мира является лишь приближением среды, то иногда она выдаёт состояния, которые не соответствуют правилам, задаваемым окружением. По этой причине бот, обучающийся в фантазиях, может наткнуться на неточность и начать её эксплуатировать. В примере с Doom это может выглядеть так:
То чувство, когда запустил в игре настолько «изи мод», что враги даже забыли тебя атаковать
Здесь бот нащупывает такое состояние, в котором симуляция не считает нужным запускать огненные шары в игрока — а значит, и умереть нельзя. И это может оказаться как просто мелким недостатком при переносе в реальную игру (или, тем более, мир), так и критической уязвимостью, приводящей к непредсказуемому непонятному поведению. Если мы будем учить автопилоты для реальных дорог в симулированной среде — лучше удостовериться, что пешеходы там не умеют телепортироваться на пару метров в сторону, когда возникает риск сбивания их машиной.
Причин неидеальности симуляции можно выделить две: недостаток данных для конкретной ситуации (из-за чего возникает «дырка» в логике симулятора) и недостаточная «ёмкость» обучаемой модели мира.
Про решение первой проблемы поговорим совсем вкратце (оно достаточно техническое, и не вписывается в рамки статьи). Один подход заключается в уменьшении предсказуемости среды в симуляторе, когда из одного и того же состояния игра может перейти в совершенно разные фазы на следующем шаге. Причём, можно управлять степенью случайности, находя баланс между реализмом и эксплуатируемостью (абсолютно случайную среду не получится обмануть — ведь она не зависит от твоих действий). Другое решение — привить обучаемому боту любопытство. Сделать это можно, например, если штрафовать его за то, что он слишком слабо меняет состояние среды (засиживается на месте), или же наоборот поощрять за новые свершения. Вы не поверите, но один из ботов в таком эксперименте начал залипать в аналог «телевизора», щёлкая каналы. В конце концов, мы не так уж сильно и отличаемся друг от друга. :)
Агент слева оказался настолько любознателен, что подсел на иглу телевидения. У бота справа телевизора в лабиринте попросту не было, поэтому он успешно выбрался. Вывод: если хотите спрятать сокровища — оставьте в лабиринте телевизор.
А что делать с ёмкостью модели? На данный момент известен лишь один гарантированный способ, который даст результат при любых обстоятельствах: масштабирование. Это означает, что мы можем увеличить размер нейросети, пропорционально увеличить размер корпуса тренировочных данных, и как следствие потратить больше ресурсов на обучение.
Все остальные способы, хоть иногда и могут сработать (взять более чистые данные/выбрать другую архитектуру модели/и т.д.), но имеют свои ограничения, а главное — могут перестать работать. Для больших нейронных сетей (в том числе и языковых моделей вроде ChatGPT) уже пару лет как вывели эмпирический закон, который показывает, насколько вырастет качество при увеличении потребляемых при тренировке ресурсов. Это называется «закон масштабирования».
Нужно БОЛЬШЕ ВИДЕОУСКОРИТЕЛЕЙ!
И масштабирование сейчас — одна из самых главных причин, по которой вы всё чаще и чаще в последнее время слышите про AI, и почему наблюдается рост качества. Если раньше модели обучали на одном, ну может на двух серверах в течении пары недель, то теперь компании арендуют целые датацентры на месяцы. По сути, появился способ закидать проблему шапками, покупай больше видеокарточек — и дело в шляпе шапке. Это одновременно и хорошо, и плохо — с одной стороны мы точно знаем, что можно получить нейросеть получше, а с другой — она будет стоить дороже.
Вернёмся к ранее упомянутому стартапу Wayne, продолжающему заниматься беспилотными автомобилями. Они всё ещё фокусируются на создании моделей мира как вспомогательном инструменте обучения алгоритмов (прямо как OpenAI). В прошлом году они представили свою модель GAIA-1, которая... тоже была обучена предсказывать будущие кадры в видео. На видео ниже вы можете увидеть сравнение ранней модели, обученной летом 2023 года, с более поздней, на которую потратили существенно больше ресурсов («отмасштабировали»).
Да, оба видео сгенерированы почти полностью, реальным является лишь первый кадр, общий и для левой, и для правой демонстрации. Однако здесь мы наблюдаем реконструкцию с использованием декодера, а не входное изображение — поэтому уже на первой секунде заметна разница. Во-первых, вдалеке виднеются светофоры — а значит у модели мира будет задача их симулировать. Во-вторых, детали вроде машин и деревьев стали намного чётче. В-третьих, улучшилась согласованность последовательно идущих кадров (посмотрите на «плавающие» формы машин справа в самом начале). Подход один и тот же, архитектура модели и принцип обучения те же — а результат качественно лучше.
Такой продвинутый симулятор может показывать и более сложные сцены, а не просто езду по прямой. Следующий пример демонстрирует, что модель мира может помочь симулировать взаимодействие с другими участниками дорожного движения. В варианте слева белый автомобиль дает задний ход, уступая нам дорогу. Во втором развитии схожего сценария (и оба — в визуализированной «фантазии» модели!) мы уступаем дорогу и позволяем выполнить разворот — при этом наш автомобиль замедляется. Здесь оба видео порождены одной и той же моделью, разница лишь в выборе развития событий (та самая случайность в модели мира).
Вуаля, теперь можно обучать модель автопилота в симуляции, порождаемой «фантазией» модели мира, без выезда на реальную дорогу с риском для водителей, и при этом инсценировать любые желаемые сценарии. Однако нейронке есть куда расти: на её обучение потратили ресурсов в 100 раз меньше, чем на одну из лучших доступных языковых моделей LLAMA-2-70B от META (ex-Facebook, на территории РФ признана экстремистской), и приблизительно в 2000 раз меньше, чем (по слухам) OpenAI потратили на GPT-4 — самую лучшую Large Language Model (LLM) на данный момент. Представляете, какой потенциал для улучшений? (Конечно представляете — просто посмотрите на OpenAI SORA!)
Единственная разница между сгенерированными видео — количество вычислительных мощностей, потраченных на обучение SORA. На демонстрацию справа суммарно было использовано в 32 раза больше ресурсов, чем на жутенькую The Thing слева.
Есть ли модели мира у LLM?
Ну, раз уж мы заговорили про большие языковые модели, то давайте сделаем отступление и попробуем разобраться: а есть ли модель мира у них. С одной стороны, зрением они не обладают, лишь читают текст в интернете, а с другой — ну что-то же они должны были выучить? Сразу после этого блока мы перейдем к модели SORA, с которой всё и начиналось, и в целом вы можете пропустить эту часть без потери смысла — но мимо вас пройдёт столько всего интересного!
Примерно 95–98% ресурсов тренировки больших языковых моделей тратится на обучение задаче предсказания следующего слова в некотором тексте. Под «некоторым» здесь подразумевается почти любой текст на сотне языков, доступных во всём интернете. Там есть и Википедия (как база знаний и фактов), и учебники по физике, описывающие принципы взаимодействия объектов (включая силы гравитации), есть детективные истории, и много чего вообще. Каждый раз модель смотрит на часть предложения и угадывает следующее слово. Если она сделает это правильно, то обновит свои параметры так, чтобы закрепить уверенность в ответе; в противном случае она извлечет уроки из ошибки и в следующий раз даст предсказание получше.
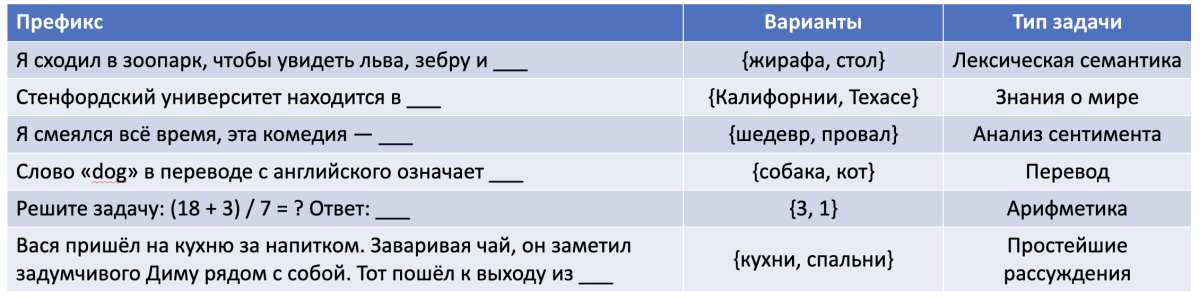
Префиксы — это примеры некоторых контекстов из интернета. Далее идут потенциальные варианты продолжения (то есть следующего слова, которое нужно предсказать). В последней колонке определен тип задачи (классификация тут условная, а не строгая и однозначная)
Давайте посмотрим на примеры в табличке выше. Чтобы предсказать следующее слово для каждого из префиксов, нужно либо обладать конкретными знаниями, либо уметь рассуждать. Иногда это может быть двумя сторонами одной и той же монеты: например, можно запомнить базовую таблицу умножения, но также через неё понять и тысячи более сложных примеров (которые в этой таблице не встречались), и затем начать корректно применять принципы математических операций.
OpenAI в этом плане двигались постепенно — первые проверки гипотезы о том, что языковая модель при обучении строит модель мира, помогающую ей успешно предсказывать следующее слово, были ещё до GPT-1. Исследователи предположили, что если взять достаточно большую по тем временам модель, и обучить её на 40 Гигабайтах отзывов с Amazon (при этом не показывая, какой рейтинг оставил пользователь — только текст), то скорее всего нейросеть сможет сама «изобрести» внутри себя концепцию сентимента. Иными словами, она сможет определять, является ли отзыв позитивным или негативным. С учётом того, что в явном виде мы никак эту информацию не сообщаем — было неочевидно, получится ли разобраться со столь сложной и абстрактной вещью, которая существует только у нас в голове: сентимент текста. Ведь это не природное явление, не закон физики — это то, как мы, люди, придумавшие свои искусственные языки, воспринимаем информацию.
Сказано — сделано. В OpenAI обучили модель, а затем рассмотрели её латент (да, там тоже модель сначала сжимает текст в понятные ей сигналы, а затем переводит его обратно в текст) под микроскопом. Так же, как мы пытались крутить 15 чиселок латента на гифке с игрушечной трассой, исследователи пытались найти такой параметр (из 4096 разных, если вам интересно), который был бы связан с сентиментом. И, как уже должно быть понятно, нашли!
Но как для текста можно понять, что вот, скажем, семнадцатая цифра в нашем латенте отвечает за сентимент? Пробуется два способа: это анализ зависимости значения от входной последовательности (текста отзыва), и сентимента генерируемого текста (= «фантазии» модели) от этого же значения. Мы как бы отвечаем на два вопроса: «Правда ли значение предсказуемо меняется из-за отзыва?» и «Правда ли, что модель опирается на это значение, то есть, сгенерированный отзыв меняется из-за значения в латенте?»
Сначала про первое. Давайте возьмём тысячи отзывов, но уже не с Amazon, а с американского аналога Кинопоиска, IMDB. Для каждого из них определим, являются ли они позитивными или негативыми. Затем будем подавать эти отзывы в модель (грубо говоря использовать энкодер для получения латента, хоть в языковых моделях это устроено чуть иначе) и смотреть, как меняется найденная цифра. Можно сделать визуализацию в виде гистограмы, на которой отзывы с разным сентиментом окрашены в разные цвета.
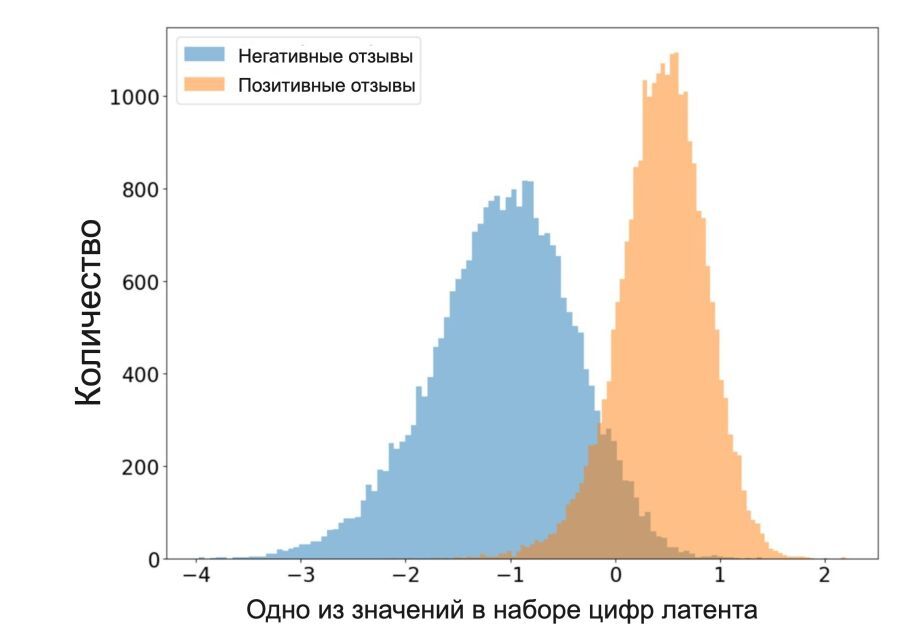
Горизонтальная шкала показывает, как негативные (голубым) и позитивные (оранжевым) отзывы распределились по значениям найденного нами внутри модели параметра, отвечающего за сентимент.
По графику видно, что для негативных отзывов модель зачастую показывает значения ниже нуля (аналог с визуализацией гоночной трассы — один ползунок выкручен влево), а для позитивных — выше. И «горбики» распределений почти заметно отличаются. Те отзывы, что попадают на пересечение, скорее всего имеют смешанный сентимент: может, там фильм и хвалят, и ругают? Таким образом, мы можем сказать, что состояние модели меняется в зависимости от сентимента конкретного отзыва — становится больше или меньше.
Но опирается ли нейронка на эту модель мира? Считается ли конкретно этот латент важным во время запуска симуляции (в которую мы можем подсмотреть уже не визуально, а по сгенерированному тексту)? Давайте зафиксируем все остальные значения латента (через установку одинакового начала отзыва), и сначала сгенерируем отзыв о фильме, указав большое положительное значение, а затем — отрицательное. По идее, если для модели этот признак важен, мы ожидаем увидеть очень положительный, хвалебный отзыв, а за ним — негативный.
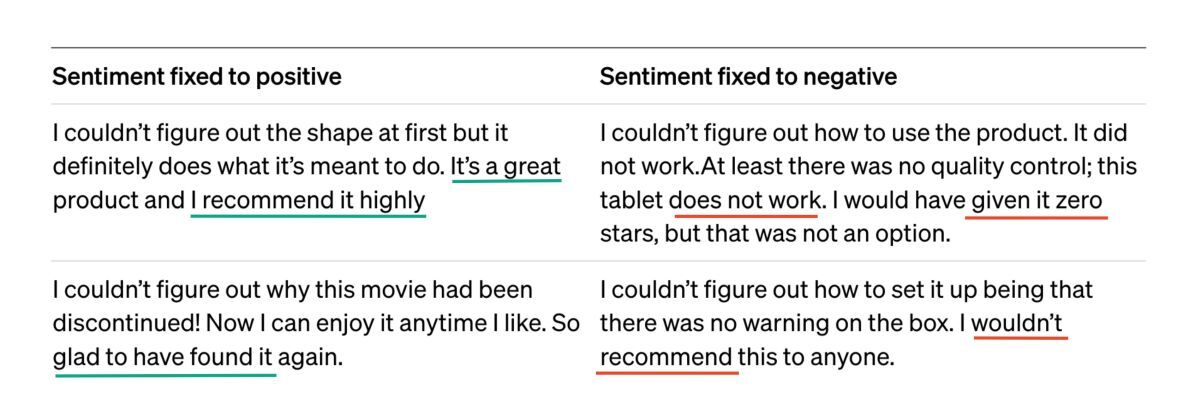
Результаты генерации. Зелёным выделены позитивные части отзывов, красным — негативные.
И ровно это учёные и обнаружили — при генерации ответ модели существенно меняет свой окрас в зависимости от лишь одной цифре в латенте. Но главная фишка в том, что мы не давали модели никакого понимания, что такое сентимент, и какими словами он выражается — вообще ничего, кроме кучи текстов. И всё же для модели мира оказалось удобнее (выгоднее?) кодировать данные так, чтобы сентимент легко разделялся, и им можно было управлять.
Этот игрушечный пример послужил толчком для OpenAI к развитию идей в модели GPT-1, а GPT-2 и 3 были дальнейшим масштабированием: больше модель, больше текстов, и как следствие более полная картина мира, выработанная внутри нейросети. Поскольку теперь кроме отзывов мы показываем тексты вообще про всё на свете, от комментариев на Дваче до учебника по физике, то модель выучивает огромное количество вещей, не только простой сентимент.
Очень сложно оценить наперёд, насколько комплексной и многогранной будет модель, и что будет зашито в её модель мира. Бывают комичные случаи: знакомьтесь, Ян Лекун, лауреат премии Тьюринга (аналог Нобелевки в компьютерных науках) за вклад в область нейронных сетей. За это его ещё называют одним из трёх крёстных отцов искусственного интеллекта. В настоящее время является вице-президентом по AI в компании META. Кажется, уж он-то точно хорошо разбирается в предмете?

Те самые трое крёстных отцов AI (Ян Лекун справа). Вообще говоря, к настоящему моменту они между собой немного все разосрались, но это уже совсем другая история...
В подкасте Лексу Фридману от 23 января 2022 года Ян говорил: «Я не думаю, что мы можем научить машину быть разумной исключительно на основе текста, потому что я думаю, что объем информации о мире, содержащейся в тексте, ничтожен по сравнению с тем, что модели нужно знать. Вы знаете, что люди пытались сделать это в течение 30 лет, верно? <...> Я думаю, что это в принципе безнадежно, но позвольте мне привести пример. Я беру предмет, кладу его на стол и толкаю стол. Для вас совершенно очевидно, что предмет будет двигаться вместе со столом, верно? Потому что он на нём лежит. Но в мире нет текста, объясняющего это! И поэтому, если вы тренируете машину, настолько мощную, насколько она может быть, например, ваш GPT-5000 или что-то еще, она никогда не узнает эту информацию. Этого просто нет ни в одном тексте».
Менее чем через год вышла ChatGPT (GPT-3.5), которая...правильно отвечала на этот вопрос. Ну ладно, ошибся дядька, наверное, где-то в учебниках физики был схожий пример. Когда в Твиттере ему за это предъявили, то он придумал новую мега-супер-сложную задачку. Сейчас-то наверное подготовился? Не стал щадящие примеры выбирать? Он выбрал задачку с шестерёнками... которую модель решила сходу, сразу же.
Тогда через месяц он придумал усложнение: «7 стержней равномерно распределены по кругу. На каждом стержне установлена шестерня, так, что она находится в сцеплении с шестернями слева и справа. Шестерёнки пронумерованы от 1 до 7 по кругу. Если бы третья шестерня была повернута по часовой стрелке, в каком направлении вращалась бы седьмая?». Родители с детьми в начальной школе уже словили флешбеки от домашки по физике, но теперь они хотя бы узнают, что... GPT-4 и на такой вопрос даёт правильный ответ.

На размышление даётся 30 секунд. Пишите в комментах, кто оказался умнее — вы или GPT-4?
GPT-4 вообще удивила многих. Вот как думаете, можно ли ответить на такой вопрос к следующей картинке, не понимая физику нашего мира, не моделируя взаимодействия объектов? Что произойдет с мячиком, если перчатка упадёт?

GPT-4 может принимать текст вместе с изображением, и умеет отвечать на вопросы, требующие визуальной информации. Тут модель правильно предсказала, что мячик подлетит наверх.
Позиция Яна не в том, что модели так не могут в принципе — он лишь не верил, что сложным физическим описаниям можно научиться либо просто по тексту, либо что такой текст вообще существует. И был не прав. Этот пример призван показать, что не стоит загадывать наперёд, что не смогут делать системы завтрашнего дня.
Конечно, модель могла не «понять» физику и уж тем более не строить модель мира, а быть обученной на таких же или уж очень похожих задачах. Однако я уже со счёта сбился от количества примеров с вопросами про очень специфичные и даже закрытые штуки, которые публикуют пользователи, но для которых, тем не менее, GPT-4 даёт адекватные ответы. Один, два, три раза — можно списать на запоминание, но были случаи...
И даже у столь мощной GPT-4 модель мира всё еще не идеальна, и то и дело приводит к глупым ошибкам. «Все модели неправильны, но некоторые из них полезны», помните?
OpenAI SORA: эмулятор Вачовски или симулятор мира?
Наконец, переходим к десерту. Такое длинное вступление было необходимо для того, чтобы наглядно продемонстрировать читателю крайне важные в контексте новой модели OpenAI тезисы:
Модели мира помогают агенту принимать решение с учётом информации о возможном будущем
Для того, чтобы успешно предсказывать будущее состояние, важно понимать лежащие в основе формирования среды процессы
Модели мира строят предсказания не в привычном нам виде, а в понятном им мире преобразованных сигналов (латентное пространство)
Мы можем заглянуть внутрь, но реконструкция не будет идеальной
Бот, обученный в симулируемой моделью мира сцене, может проявлять навыки и в реальной среде
Масштабирование модели всегда приносит улучшения, при этом многие из них неочевидны и сложнопредсказуемы
И вот теперь, когда мы разобрали концепцию моделей мира и посмотрели, для чего они могут использоваться, мы будем смотреть на примеры и пытаться понять, а в чём же именно ВАУ-эффект модели SORA. Она, как и GPT-4, выработала внутри себя какую-то модель мира, помогающую предсказывать следующий кадр в огромной разнообразной выборке всевозможных видео. Рендеринг финального изображения — это лишь реконструкция того, что предсказывает модель (потому что мы смотрим на это через призму декодера; хоть он и достаточно мощный, но имеет свои недочёты).
Пример, которым OpenAI решили похвастаться и вывести в начало своего блогпоста, вы уже видели в превью статьи. Это одноминутное FullHD @ 30 к/сек. видео, сгенерированное по текстовому запросу (промпту): «Элегантная женщина идет по улице Токио, озаренной теплым светом неоновых огней и анимированных городских вывесок. На ней черная кожаная куртка, длинное красное платье и черные ботинки, в руке черная сумочка. Она в солнцезащитных очках и с красной помадой. Шагает уверенно и непринужденно. Асфальт улицы мокрый, отзеркаливающий яркие огни. Вокруг ходит множество пешеходов.»
Во-первых, сложно не заметить точнейшее соблюдение всех деталей промпта в сгенерированном видео. Даже если сильно захотеть — разве что субъективные «элегантная женщина» и «шагает уверенно» можно подвергнуть сомнению, но, по-моему, модель справилась отлично. В этом заслуга специального приёма, использовавшегося OpenAI при разработке их предыдущей модели, DALL-E 3 (делает генерацию изображения по текстовому запросу, как MidJourney).
Так как зачастую текстовые подписи к картинкам и роликам в интернете очень короткие и несут лишь поверхностное (а иногда и неточное) описание происходящего, исследователи предложили применить умницу GPT-4 для генерации более подробных описаний. Для этого видео нарезалось на кадры, и языковая модель получала команду создать детальные подписи к происходящему в нескольких подряд идущих изображениях. Текстовые комментарии выходят не в пример длиннее, с большим количеством нюансов, поэтому обученная text-2-image или text-2-video модель гораздо охотнее обращает внимание на запрос, пытаясь соответствовать каждой его частичке. Даже лучшие платные аналоги моделей еле-еле оперируют двумя, самый край тремя предложениями — а тут мы нагрузили деталей на 5 строчек! Для DALL-E 3 процент синтетических текстов был 95%, вероятно, в SORA плюс-минус такой же.
Во-вторых, общий визуал существенно превосходит ожидания от моделей на данный момент. В Твиттере даже шутят, что «это был невероятный год прогресса AI... за один час». Тут сложно не согласиться, особенно если последнее демо, что вы видели — это Уилл Смит со спагетти из начала статьи. Но в сцене, кажется, учтено почти всё. Если заведомо не знать, что это генерация и не ждать подвоха — сразу и не скажешь. Освещение, отражения, толпа людей, переход на ближний план с детализацией текстуры кожи, плавность перемещения камеры с соответствующим изменением углов обзора на объекты в фоне. А те объекты, что пропадают из поля зрения на несколько секунд (люди сзади, синий дорожный знак на стене справа), возвращаются без изменений — такой консистентности во времени раньше и не мечтали добиться!

Моя модель мира предсказывает, что этот карандаш пропадёт из поля зрения через пару секунд. И... он испарился!
В-третьих, давайте поговорим про недостатки. Я пересмотрел видео около десятка раз, и самые заметные изменения происходят, если сравнивать начало и конец. На секундах с 55 по 59 вы можете заметить, что: 1) из рук пропадает чёрная сумочка; 2) левый лацкан куртки стал аномально большим (и даже испортил симметрию), да и правый прибавил в размере; 3) на красном платье на груди появляются чёрные пятна; 4) меняется причёска, появляется завихрение волос. Есть и комичные проблемы — обратите внимание, как левая нога превращается в правую (и наоборот) на секундах 15 и 29. И как после такого заснуть? А на секундах 16–17 ноги группы людей слева (парень, проходящий мимо двух азиаток в масках) будто бы окутаны водным шаром и очень расплывчаты.
Важно отметить, что часть этих проблем наверняка лежит на неидеальности реконструкции декодера, а часть — на проблемах с моделью мира. А может быть, собака зарыта где-то ещё, мы не знаем. Дело осложняется тем, что ни у кого, кроме OpenAI и их доверенных лиц, нет доступа к нейросети, чтобы это можно было проверить. Помните, как в эксперименте с числом в латенте, влияющим на генерацию отзыва? Тогда исследователи могли однозначно проверить, что будет, если его дёргать туда-сюда, здесь же подобного анализа не производилось. И всё же сделаю смелое предположение и скажу, что пронумерованные проблемы из абзаца выше скорее всего являются недостатками модели мира (исчез объект? поменялась форма чуть ли не самого крупного объекта в кадре? как так?!), а вот проблемы с отображением ног — уже реконструкции (потому что энкодер и декодер не посчитали нужными кодировать информацию о двух ногах, находящихся рядом).
Подобный артефакт можно было наблюдать на одном из видео выше, в симуляторе для автопилота. Там сами машины и окружение были достаточно чёткими, а вот диски колес как будто бы не крутились, и были очень шумными. Вероятнее всего, при обучении модель сочла, что куда выгоднее кодировать такие признаки, как размер авто, направление его движения, скорость, а вот насколько повёрнуты колёса в каждый момент времени уже можно подзабить — ведь это не так важно, и мы, люди, тоже не обращаем внимания при вождении на этот шум. Помните, что модель мира предсказывает будущее состояние, но не вся информация одинаково полезна для этой цели.

А так как информация не присутствует в модели мира и латенте, то и декодер не может грамотно восстановить картинку.
Но с этим связана и неожиданная хорошая новость! Раз модель мира не уделяет внимание такой детали, то и несоответствие картинки из декодированного видео настоящему миру не так критично. Ведь энкодер при сжатии видеопотока в латент для обработки (или симуляции) также опустит эти детали! В итоге, латент для реальной картинки и для «симулированной» будет почти одинаковым (хоть проблемы в реконструкции заметны невооружённым глазом). А значит наш бот, играющий в симуляторе, не заметит подвоха, и сможет потенциально оперировать в реальном мире. То, что может быть критично для создателей видеоконтента в силу неидеальности визуала, абсолютно не мешает основной цели модели SORA!
Так, и мы опять не влезли в ограничение Пикабу по количеству символов на один материал. :) Заключительная часть статьи находится вот здесь (осталось совсем немного потерпите!).