МОСКВА, 1 апр — РИА Новости. Специалисты Московского государственного технического университета имени Н.Э. Баумана завершили разработку уникальной системы искусственного интеллекта, не имеющей аналогов в мире. Нейросеть, получившая название «Код-Дзержинский» (КД-1), предназначена для автоматического анализа программного кода на предмет соответствия закону о защите русского языка, нормам «цифровой этики» и «морально-нравственным устоям» в условиях суверенного рунета.
Как сообщили журналистам в пресс-службе вуза, разработка велась в рамках государственной программы по обеспечению цифрового суверенитета в IT-сфере. Новый алгоритм способен не просто находить баги или уязвимости, но и выявлять в коде «деструктивный подтекст», «излишнюю лаконичность, граничащую с саботажем», а также использование нежелательных англицизмов в названиях переменных, как этого требует Федеральный закон № 168-ФЗ от 24.06.2025 («закон о защите русского языка»), который с 1 марта 2026 года обязывает бизнес использовать русский язык в исходном коде своих программных продуктов: иностранные слова допустимы только с переводом на кириллицу.
«В отличие от западных аналогов, которые заботятся лишь о безопасности данных, наш продукт глубоко анализирует семантику. Если программист попытается назвать функцию free(), система не просто выдаст ошибку компиляции, но и сформирует уведомление для отдела кадров о необходимости усиленной воспитательной беседы», — заявил на презентации руководитель научно-учебного комплекса «Информатика и системы управления», доктор технических наук Андрей Пролетарский.
Особенностью «Код-Дзержинского» стал модуль прогнозирования «Железный Феликс». Он автоматически переписывает код, заменяя подозрительные конструкции на патриотичные аналоги. Так, по данным разработчиков, команда else автоматически заменяется на аИначе, а оператор ветвления switch теперь требует обязательного согласования с «Роскомнадзором» перед использованием.
Партнером проекта выступил один из крупнейших операторов связи. В компании уже пообещали внедрить систему для анализа кода биллинговых систем, чтобы исключить начисление «немотивированных скидок» и «спонтанной щедрости» по отношению к абонентам.
Ректор МГТУ им. Н.Э. Баумана Михаил Гордин отметил, что нейросеть прошла успешные испытания на базе кафедры «Компьютерные системы и сети».
«Мы считаем, что это большой шаг на пути к полному импортозамещению. Теперь даже самый строптивый код, написанный вольнодумным джуниором, можно за несколько итераций привести к единому, “обезличенному” знаменателю. Счастье в цифрах, как известно, должно быть принудительным и строго типизированным», — подчеркнул ректор.
В настоящее время разработчики готовят патент на изобретение в Роспатенте, а также ведут подготовительные работы к внедрению системы в образовательный процесс. С нового учебного года студентам Бауманки, сдающим лабораторные работы по программированию, для допуска к их защите придется предъявлять преподавателю отчёт о результатах проверки своего исходного кода интеллектуальной системой КД-1.
В материале использованы открытые данные МГТУ им. Н.Э. Баумана. Текст является первоапрельским и не содержит реальных планов по внедрению описанных технологий.
В данном случае большая часть подробностей, что я излагал в промпте даже была не нужна. Но если так описывать настоящие задачи, каждую функцию, каждый алгоритм, то нейросеть будет писать и 3 и 5 тысяч строк кода так, как ты хочешь.
Принты в коде появились потому, что в системном промпте прописаны дополнительные условия.
А от анонима пишу потому что не хочу этим засирать свою историю аккаунта.
Если у тебя такая примитивная задача заняла две недели, а не десять минут, то программирование это явно не твоё.
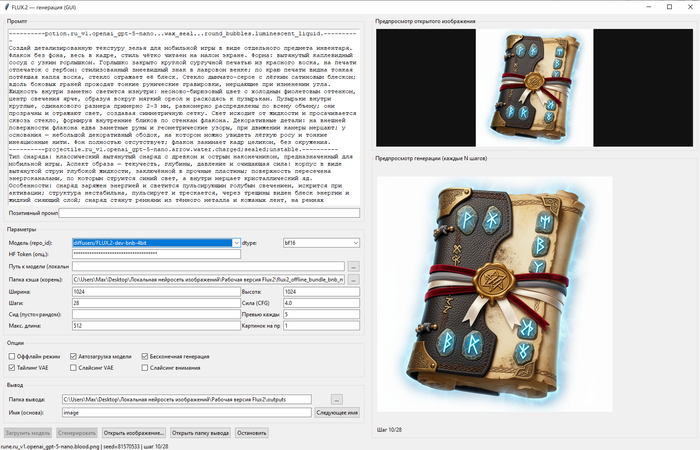
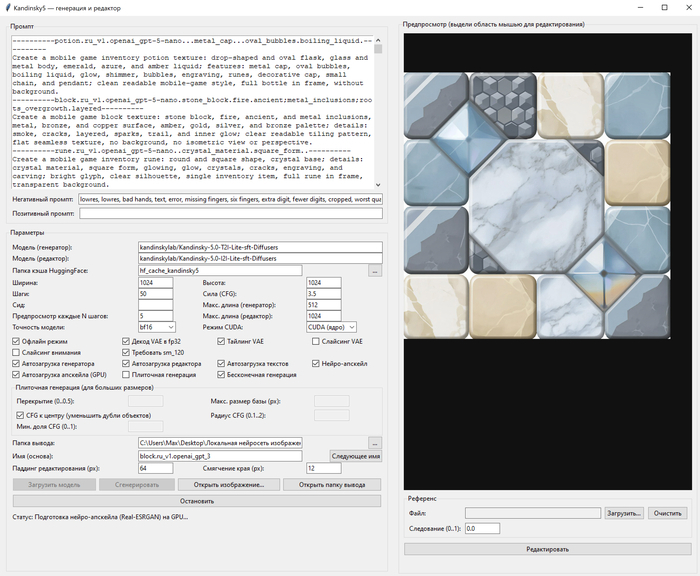
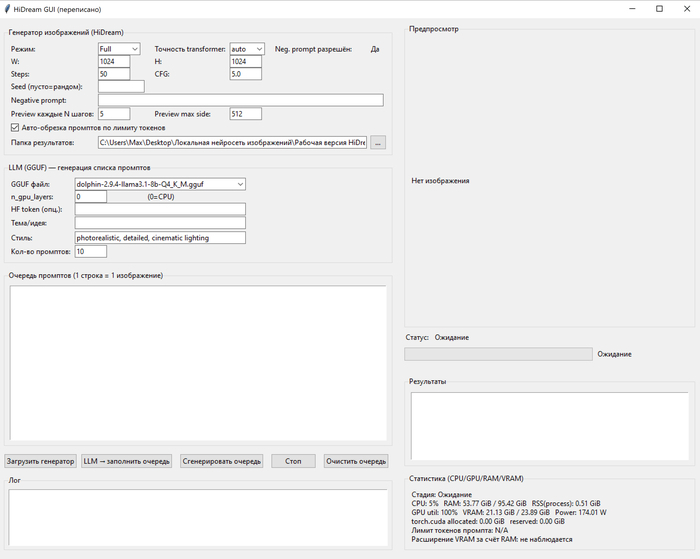
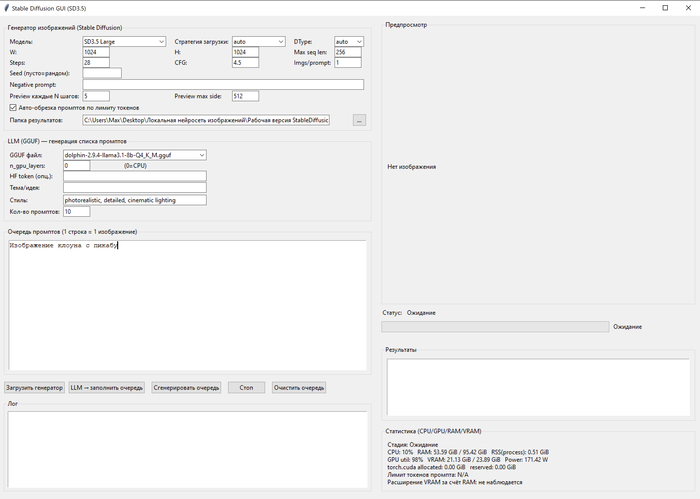
Я вот чисто по приколу себе сделал кастомные GUI для разных нейросетей, что бы локально их гонять, пакетные запросы выполнять и.т.д. Не по заказу, а просто для своего пет-проекта, текстурки нагенерить. И у меня на это ушла пара часов. При этом в самой длинной программе 5700 строк, ни одна из которых не была написана руками. Я этим не горжусь, вайбкодинг, как его сейчас используют, та ещё мерзость. Но я писал код руками больше 10 лет, и сейчас могу сформулировать свои требования к нейросети так, что бы она их сделала так, как я хочу за первые несколько запросов.
Я работаю с ИИ с момента его появления. У меня ИИ пишет программу на 3000 строк за 2-3 попытки. Без багов и ровно так, как я хочу. Знаешь почему? Потому что перед этим я трачу час на написание промпта. Промпт - это не кнопка "сделай заебись". Это точно такая же программа, просто на естественном языке. И нейросеть просто её компилирует в машиночитаемый код. Когда обычные компиляторы создают баги, ты не винишь компилятор, он виноват лишь в том что реализовал то что ты НАПИСАЛ, а не то что ты ЗАХОТЕЛ. И когда нейросеть создаёт баги, нужно винить не нейросеть, а себя. Потому что нейросеть реализует то, что ты пишешь, а не то, что ты хочешь.
Для ЛЛ: генерю куски кода для проекта в 250 строк и уже задолбался.
Забавно...
То есть по сути, вкратце: берём исходник, генерим по нему ТЗ и по полученному ТЗ пишем код с нуля? В приципе - логично, да...
Интересно, как в дальнейшем ИИ реализует поддержку (фидбэк) своего же кода. Все эти багрепорты и issue... В частности, как будут реализованы все, зачастую бредовые пожелания к улучшайзингу "от начальства"... ну, вы же знаете про "поиграться фонтами"... Так как ИИ, как уже многократно писано, зачастую ориентированы на удовлетворение ЛЮБЫХ потребностей и клиент всегда прав... во что это, интересно, выльется?
Примерно с месяц как я таки не удержался и начал пользоваться гугл-ИИ для генерации кода. Реально удобно. Не надо перекапывать кучи форумов и т.п. Задача была раcпарсить логи Tasmota напрямую с ZBBridge. Без использования MQTT. Хочу сделать вывод данных с подключенного к системе датчика т-ры/влажности на "ESP32-C3 с 0,42-дюймовым OLED-модулем". То есть тут нет особых возможностей для работы с сокетами, воркерами, докерами и т.п. Поэтому опрашиваю мост и парсю лог ответов. Хочу получить предельно простой, короткий код, чтобы впоследствии беспроблемно портировать его с TS в ардуино-скетч.
Совершенно очевидно было воспользоваться для парсинга регулярками. Программирую уже очень давно, но регулярки я так и не освоил. Это выше моего понимания. Тупой я, да. Так вот.
После чего получаем пачку JSON-ов. Для дальнейшей обработки, да.
Ну, в приницпе, дареному коню и т.д.... Но что я заметил: из 20 вариантов, рабочих было примерно треть. То есть всё красиво, почти работает, но... После уточнений и дополнений регулярка каждый раз получается кардинально новая. Даже на просьбу доделать уже существующее, я получаю абсолютно новую сигнатуру. При этом я запускаю полученное, получаю ерунду, шлю ИИ фидбэк и получаю (!!!!!)
- Да, вы абсолютно правы, я ошиблась, тут не хватает пары фигурных скобок....
В результате я не пишу код, а занимаюсь тестированием написанного ИИ кода и пространными пояснениями почему он не работает... Причем сэкса стало на порядок больше. Я не стал меньше сидеть за компом. Отнюдь. у меня есть такой микроанализатор моей активности за компом.
Статы обычного рабочего дня:
𝖚𝖑/𝖉𝖑: 94.3M / 392.1M 𝖉𝖆𝖞: 54
Ping: 0.010 / 0.041 Avg: 0.011
Click Mouse/Key: 2 095 / 11 065
MouseTravel: 111.97 m
Статы при работе с ИИ:
𝖚𝖑/𝖉𝖑: 172.1M / 1.8G 𝖉𝖆𝖞: 60
Ping: 0.011 / 0.077 Avg: 0.014
Click Mouse/Key: 4 635 / 21 924
MouseTravel: 228.48 m
Весь код ПРОЕКТА - 250 строк. С комментариями. Результаты работы, лог.
Так вот к чему я это всё: этот "мегапроект" я пилю больше двух недель... И мне интересно, сколько придется дорабатывать и допиливать сгенеренный код чего-то посложнее... Как мне думается, на программистах они, конечно же, сэкономят. 7 секунд, 13 секунд... Халява же, сэээр... Но они там, как мне кажется, буквально разорятся на бэта-тестерах...
И вот всеми любимые "уязвимости"... Интересно - ИИ будет пользоваться рецептами обхода существующих и известных, обнаруживать и решать такие вопросы сама или нагенерит тысячи новых?...
А учитывая их любовь к генерации всего кода заново, даже после небольших корректив, проект будет каждый раз отличаться? Архитектура, названия методов, структура... Сегодня ты тестировал модуль мойДейвайс, а после правок "размера фонта" через 10 секунд ты уже будешь работать с "загогулина_От_Дяди_Ляо_GmBh"?...
Не, ну поживём увидим... Но мне проще писать код самому. Меньше приходится о нем рассказывать.
Нда... растёкся я мыслью по древу... Надо попросить ИИ переписать пост... какой-то он некликбейтный...
Проект Malus запустил автоматизированный сервис, использующий две изолированные группы нейросетей для переписывания библиотек с открытым исходным кодом. Технология позволяет легально удалять оригинальные лицензии и делать программное обеспечение проприетарным, решая проблему юридических рисков корпоративного сектора, которая оценивается в миллионы долларов ежегодно.
«Чистая комната» как услуга.
Наконец-то свобода от лицензионных обязательств открытого кода. Авторы: Mike Nolan Источник: MalusCorp
Наши проприетарные ИИ-роботы самостоятельно воссоздают любой проект с открытым кодом с нуля. Результат? Юридически независимый код с удобной для корпораций лицензией. Никакого указания авторства. Никакого копилефта. Никаких проблем. Авторы: Mike Nolan Источник: MalusCorp
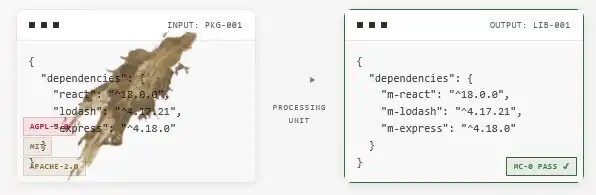
Сервис Malus предлагает бизнесу механизм полного избавления от условий строгих лицензий вроде AGPL, GPL или правил обязательной атрибуции Apache. Клиент загружает файл-манифест с зависимостями своего проекта и получает функциональные аналоги нужных пакетов. Итоговый продукт юридически очищен от прав оригинальных создателей и передается заказчику под новой проприетарной лицензией MalusCorp-0, которая не требует указания авторства и позволяет корпорациям распоряжаться алгоритмами по своему усмотрению.
В основе системы лежит автоматизированный процесс так называемой «чистой комнаты». Первая группа ИИ-агентов изолированно анализирует исключительно публичную документацию, спецификации и интерфейсы оригинального программного обеспечения. Вторая группа, физически отгороженная от первой и не имеющая доступа к исходным текстам, пишет код с нуля на базе составленного технического задания. Это исключает прямое копирование и переводит процесс из разряда плагиата в категорию независимого воссоздания.
Стоимость услуги рассчитывается динамически по тарифу один цент за каждый килобайт распакованного исходного пакета. По расчетам системы, очистка популярной библиотеки маршрутизации express обойдется в 73 цента, в то время как крупный пакет lodash будет стоить чуть менее 14 долларов.
Прецедент вековой давности: как закон 1879 года легализует машинный код
Идея проекта не является юридической новацией. Она базируется на американском судебном прецеденте Baker v. Selden 1879 года, который жестко разделил концепцию и форму ее выражения. Закон об авторском праве защищает конкретный текст программы, но не саму идею или заложенную в нее функцию. Тот, кто сможет реализовать аналогичный механизм с нуля, не заглядывая в чужие исходники, становится полноправным владельцем нового продукта.
В 1984 году компания Phoenix Technologies использовала этот принцип для легального клонирования базовой системы ввода-вывода от IBM. Один инженер месяцами изучал документацию и писал спецификацию, а другой, никогда не видевший оригинального кода, создавал совместимый аналог. Этот проект занял несколько месяцев ручного труда, но позволил сторонним производителям материнских плат легально запускать любые операционные системы без отчислений оригинальному разработчику.
Процесс «чистой комнаты» всегда был невероятно дорогим занятием, требующим штата юристов и жесткой дисциплины. Новация платформы Malus заключается в делегировании этой сложной юридической процедуры нейросетям. Первая группа алгоритмов выступает в роли первого инженера, изолированно читая документацию, а вторая берет на себя роль исполнителя, моментально генерируя «чистый» код. По заявлению создателей платформы, известная микробиблиотека left-pad воссоздается системой за десять секунд, а первая в истории видеоигра Spacewar — всего за пять.
Юридическая база столетней давности в сочетании с машинным обучением превращает авторское право из непреодолимой защиты сообщества разработчиков открытого кода в формальность, которую легко автоматизировать.
Цена бесплатного труда: почему корпорации видят угрозу в открытом коде
В программном манифесте, опубликованном 1 марта 2026 года, генеральный директор Malus Майк Нолан формулирует главную проблему корпоративного сектора: мировая цифровая инфраструктура держится на энтузиазме волонтеров. Бизнес получает программное обеспечение бесплатно, но расплачивается за это отсутствием гарантий, технической поддержки и контроля над цепочками поставок.
Проблема имеет конкретное финансовое выражение. По оценке создателей сервиса, среднестатистическая корпорация со штатом более пятисот инженеров ежегодно тратит около четырех миллионов долларов на управление рисками открытого кода. Эти средства уходят на инструменты анализа уязвимостей, работу юристов и содержание специальных отделов по надзору за соблюдением лицензий.
Зависимость от чужих библиотек регулярно приводит к масштабным кризисам. В декабре 2021 года критическая уязвимость Log4Shell в утилите ведения логов заставила инженеров по всему миру экстренно закрывать бреши на серверах, пока неоплачиваемые авторы оригинального кода получали тысячи гневных писем от корпораций.
Возникают и ситуации намеренного саботажа: в январе 2022 года создатель популярных пакетов colors.js и faker.js внедрил бесконечные циклы в свой код в знак протеста против его использования крупным бизнесом без финансовой отдачи. В марте того же года разработчик утилиты node-ipc добавил функционал удаления файлов на компьютерах пользователей по геополитическим мотивам.
В такой парадигме использование открытого исходного кода становится для корпораций непредсказуемой структурной уязвимостью. Платформа Malus предлагает решить эту проблему радикально: разорвать социальный контракт с разработчиками и заменить их полностью подконтрольным машинным кодом.
Анатомия цифрового цинизма: где заканчивается шутка и начинается бизнес
Несмотря на наличие работающей системы оплаты и реальную возможность загрузить файл конфигурации для обработки, проект Malus является масштабной сатирой, приуроченной к выступлению Майка Нолана на европейской конференции разработчиков FOSDEM в 2026 году. За фасадом стартапа, публикующего вымышленные отзывы корпоративных менеджеров о том, что чувство вины не отображается в квартальных отчетах, скрывается жесткая критика современной технологической индустрии.
Именно здесь ирония проекта достигает своего пика и становится пугающе точной. Вместо того чтобы выстроить систему справедливой компенсации для уставших программистов-энтузиастов, на которых держится вся мировая архитектура, гиганты индустрии предпочитают искать юридические лазейки. Платформа едко высмеивает эту корпоративную логику: компаниям проще нанять ИИ-агентов, которые за доли секунды сотрут лицензию и уничтожат любые следы авторства, чем поддержать создателя оригинальной идеи.
Реакция профильных сообществ показала, что граница между шуткой и реальностью окончательно стерта. В ходе обсуждений на площадке Hacker News многие инженеры восприняли платформу как настоящую коммерческую угрозу. Специалисты отметили, что описанный юридический механизм технически реализуем уже сегодня, а автоматизированное правоприменение радикально меняет правила игры. Как только стоимость обхода лицензии становится ниже стоимости судебного разбирательства, система защиты авторских прав начинает давать сбой.
Юридический парадокс современного рынка технологий
Проект Malus подсветил фундаментальный парадокс современного рынка технологий. Искусственный интеллект, обученный на массивах бесплатного программного обеспечения, теперь используется для того, чтобы лишить создателей этого самого обеспечения последних юридических рычагов влияния.
Открытым остается лишь вопрос о том, как скоро подобная едкая антиутопия окончательно станет реальностью: потребуется ли индустрии отдельный судебный прецедент для оценки машинной «чистой комнаты», или автоматическая очистка кода и обход лицензий незаметно превратятся в стандартный бизнес-процесс для транснациональных корпораций.
У меня для вас параноидальная новость. Существует теория, согласно которой настоящий интернет, наполненный живыми людьми, «умер» еще году в 2016-м.
Сейчас мы живем в мире, где боты разговаривают с ботами.
Факты, от которых становится не по себе:
Более 47% всего интернет-трафика в 2023 году сгенерировали боты.
Отзывы на товары пишут нейросети.
Комментарии под новостями пишут алгоритмы, чтобы разжигать споры.
Даже музыку и картинки теперь делают ИИ.
Получается замкнутый круг. ИИ учится на текстах из интернета, которые написал другой ИИ. Мы видим «галлюцинации» машин.
Я решил визуализировать эту теорию. Представьте человека, который тонет в потоке цифровых масок и лайков, где нет ничего настоящего. Получилось довольно крипово, в духе «Матрицы».
Как думаете, сколько процентов ваших собеседников в сети — реальные люди?
Пруфы, что я существую, и еще больше крутого визуала — в моем Телеграм, а исходники картинок храню в Шедевруме.
Кажется, я понял почему последние годы так много говорится о советских галошах и советской жопе. Потому что любой человек оперирует теми нарративами и постулатами, которые попадают в его поле зрения на уровне потолочного восприятия, а у этих говорунов судя по всему потолочный уровень немногим выше Ленинских галош, да может быть при помощи табурета или стремянки, едва дотягивающийся до Сталинской задницы.