

Программирование
5 постов
5 постов
4 поста

Сидишь вечером и смотришь на то, как ChatGPT за несколько секунд пишет полнофункциональное CRUD-приложение. Пялишься на экран и спрашиваешь себя
Заменит ли меня эта штука или нет?
Ты не один, кто задается таким вопросом – и нет, твоя карьера, к счастью, ещё не закончилась.
ИИ уже вошёл в индустрию – инструменты как ChatGPT, Copilot, и Claude заметно повышают скорость разработки. Ещё в 2022, когда ChatGPT только появился, никто не мог себе такого представить.
Что ИИ делает хорошо?
Хорошо справляется с боилерплейтом, например, при написании кода для работы с базами данных
Не помню, когда в последний раз писал регулярное выражение без ChatGPT
ИИ действительно удобно использовать для дебага, так как он видит мелкие ошибки, которые человеку сложно заметить
Написание сообщений для коммитов
В чём ИИ плох?
Создание проектов, отличающихся от чего-то среднестатистического, что и так уже есть
Переписывание легаси кода со старой версии фреймворка/библиотеки на новую, так как языковые модели обновляются нечасто
Не может принимать ответственные решения, например, выбор архитектуры
Ошибки, которые допустил ИИ, очень сложно находить даже самим нейросетям
Иногда создаёт артефакты наподобие passwords.txt :}
При появлении каждого нового “убийцы”, программистам наоборот становилось легче, а не сложнее. Так что, нейросети не заменят нас, а лишь помогут делать продукты ещё лучше.
Год | “Убийца программистов” | Что случилось?
2000 | WYSIWYG редакторы | Веб набрал ещё больше оборотов
2010 | No-code платформы | Ещё больше разработчиков были наняты
2020 | Low-code решения | Зарплаты стали ещё больше
2025 | Вайб кодинг и прочее | Программировать стало легче
Предлагаю поизучать ИИ-тему, чтобы оставаться в курсе последних моделей, событий и так далее, чтобы в случае необходимости быстро адаптироваться к новым условиям. Даже если ИИ заглохнет вы немного потеряете.
Надеюсь статья вам понравилась! Оригинал на английском находится здесь. У меня кстати есть телеграм канал https://t.me/thegblog)
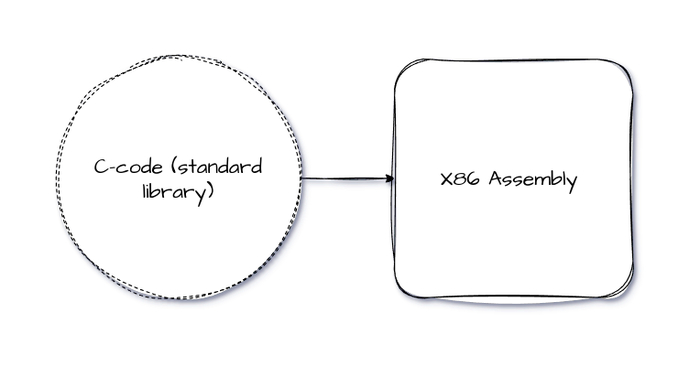
Разрабатывая стандартную библиотеку для своего языка, столкнулся с проблемой: как связывать код написанный на C с ассембли. Первый подход – компиляция C в ассембли и ручное копирование кода – оказался не самым удобным. Две проблемы этого способа это несовместимость синтаксиса GCC и Nasm и постоянное дублирование кода при малейших изменениях.
Теперь расскажу о способе, который является оптимальным – линковке объектных файлов.
Приведу пример из моего языка программирования – функция для печати целых чисел.
debug.c
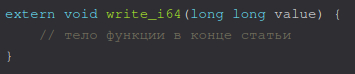
Важно, что функция объявлена с модификатором extern, то есть доступна глобально.
Также, в него нужно включить заголовочный файл, в котором будут объявлены все сигнатуры функций.
debug.c
debug.h
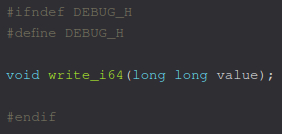
Теперь, создаём объектный файл.
gcc -nostdlib -no-pie -fno-stack-protector -c debug.c -o debug.o
Флаги -no-pie и -fno-stack-protector нужны для совместимости с ассембли.
main.asm
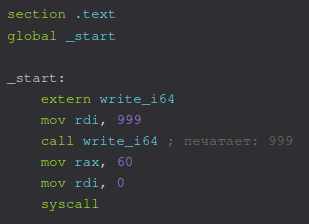
Компилируем и компонуем с объектным файлом стандартной библиотеки
nasm -f elf64 main.asm -o main.o
gcc -nostdlib -no-pie main.o debug.o -o main
Получаем одиночный бинарный файл, в котором включены и стандартная библиотека и главный файл.
Если вам хочется узнать больше о языках программирования, переходите в мой телеграм канал.
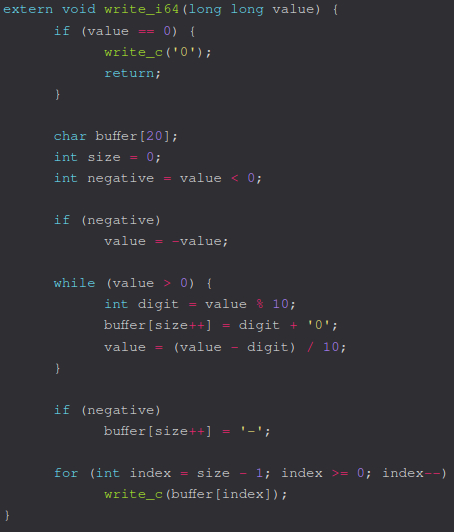
P.S: Тело функции
Как же исходный код превращается в бинарный файл, который потом исполняется на компьютере? Не нашёл ни одной статьи, которая описывала бы полный процесс от начала до конца, поэтому я написал данный материал.
Как оказалось, не всё так трудно, как мне изначально казалось. Я понимаю, что в настоящих больших компиляторах всё гораздо сложнее, но это не меняет принципа по которым они строятся и работают.
На этом этапе исходный код в виде строки разделяется на отдельные части, то есть токены. Этот этап – самый простой во всём процессе компиляции.
Вход
let a = 10 + 2
if a > 8 then
debug "A больше 8"
else
debug "А либо меньше, либо равно 8"
end
Выход
[
Let, Identifier("a"), Equal, Integer(10), Plus, Integer(2),
If, Identifier("a"), Greater, Integer(8), Then,
Debug, String("A больше 8"),
Else,
Debug, String("А либо меньше, либо равно 8"),
End,
]
Здесь поток токенов объединяется в AST или абстрактное синтаксическое дерево. В этом дереве содержится вся информация об исходном коде в структурированном виде, удобным для обработки и анализа. Например, с его помощью можно проверять корректность типов переменных.
[
Let {
identifier: "a",
value: Binary(Add, Integer(10), Integer(2)),
},
If {
condition: Binary(Greater, Identifier("a"), Integer(8)),
then: [Debug(String("A больше 8"))],
else_: [Debug(String("А либо меньше, либо равно 8"))],
},
]
AST преобразуется в низкоуровневые инструкции, которые не зависят от конкретной архитектуры. Это удобно, так как упрощает поддержку большого количества архитектур и процессоров.
В компиляторах Rust и Clang в качестве промежуточного представления используется LLVM IR, так как его экосистема берёт на себя многие оптимизации, и компилирование в ассемблерный код для разных платформ как X86, ARM и так далее.
Сначала, для того, чтобы избавится от условных конструкций как if и match, мы разделяем входное дерево на отдельные блоки, которые не содержат в себе условий, и дальше связываем их, описывая переходы между ними.
Блоки, не содержащие условий
{
0: [
Let {
identifier: "a",
value: Binary(Add, Integer(10), Integer(2)),
},
],
1: [Debug(String("A больше 8"))],
2: [Debug(String("А либо меньше, либо равно 8"))],
3: Empty,
}
Блок Empty – это пустой блок, который не содержит в себе инструкций, и служит только для удобства построения CFG.
И условные переходы между блоками
{
0: Branch { # переход с условием
condition: Binary(Greater, Identifier("a"), Integer(8)),
true_: 1,
false_: 2,
},
1: Direct(3), # прямой переход без условия
2: Direct(3),
}
Состоит из низкоуровневых инструкций максимально приближенных к нативному ассембли-коду.
Первый блок
[
Label(0),
LoadInteger { to: 0, value: 10 },
LoadInteger { to: 1, value: 2 },
Add { to: 2, left: 0, right: 1 },
Set { identifier: "a", from: 2 },
Get { to: 3, from: "a" },
LoadInteger { to: 4, value: 8 },
Greater { to: 5, left: 3, right: 4 },
JumpIf { condition: 5, label: 1 },
Jump(2),
Второй
Label(1),
LoadString { to: 6, value: "A больше 8" },
Debug { value: 6 },
Get { to: 7, from: "a" },
LoadInteger { to: 8, value: 8 },
Greater { to: 9, left: 7, right: 8 },
JumpIf { condition: 9, label: 3 },
Jump(2),
Третий
Label(2),
LoadString { to: 10, value: "А либо меньше, либо равно 8" },
Debug { value: 10 },
И последний, пустой блок
Label(3),
]
Или в виде псевдо-кода
@0:
#0 = 10
#1 = 2
#2 = add #0 #1
$a = #2
#3 = $a
#4 = 8
#5 = gt #3 #4
jump @1 if #5
jump @2
@1:
#6 = "A больше 8"
debug #6
#7 = $a
#8 = 8
#9 = gt #7 #8
jump @3 if #9
jump @2
@2:
#10 = "А либо меньше, либо равно 8"
debug #10
@3:
Далее, каждая 3AC инструкция конвертируется в одну или несколько ассемблерных инструкций, которые уже напрямую выполняются на процессоре без какой-либо прослойки.
section .data
str_0: db "A больше 8", 0
str_1: db "А либо меньше, либо равно 8", 0
Строки будут записаны вместе с файлом как его часть, то есть они не будут аллоцированны динамически во время выполнения.
section .bss
a: resq 1
Мы будем хранить переменную в секции .bss, так как в нашей программе одна зона видимости. В настоящих компиляторах переменные обычно хранятся на стеке, или вовсе в регистрах в зависимости от степени оптимизации.
section .text
global _start
_start:
Делаем _start глобально видимым для того, чтобы линкер смог собрать бинарный файл.
L0:
mov rax, 10
mov rbx, 2
mov rcx, rax
add rcx, rbx
mov [a], rcx
a = rcx = rax + rbx = 10 + 2 = 12.
mov rax, [a]
mov rbx, 8
cmp rax, rbx
mov rcx, 0
setg cl
rcx = rax > rbx = a > 8 = 1 то есть true.
cmp rcx, 1
je L1
jmp L2
Если rcx = 1, то есть true, то переходим в L1, иначе – в L2.
L1:
mov rax, str_0
call debug
debug – это какая-то функция, которая печатает строки в консоль. В целях соблюдения компактности, я не стал её включать в код. Регистр rax – первый аргумент.
mov rax, [a]
mov rbx, 8
cmp rax, rbx
setg rcx
cmp rcx, 1
je L3
jmp L2
L2:
mov rax, str_1
call debug
L2 – начало блока else.
L3:
mov rax, 60
mov rdi, 0
syscall
Выходим из программы, производя системный вызов (syscall). В rax находится номер вызова – 60, то есть выход (SYS_exit). А в rdi лежит статус завершения программы, в данном случае 0, то есть успешное завершение.
Надеюсь вам понравилась эта статья! Она написана на основе моего хобби-компилятора, поэтому если у вас есть желание внести свою лепту в проект – отправляйте пул-реквест в репозиторий!

Эта статья – краткий обзор первой половины книги Чистый код.
Разберём ключевые принципы именования переменных, проектирования функций и других аспектов, чтобы писать код, который будет понятен вам и вашей команде спустя годы.
Основные тезисы для тех, кто не хочет читать эту прекрасную статью целиком.
Думайте над именами
Не делайте код слишком чистым
Следуйте стандартам языка или вашей команды
Программист не должен заниматься форматированием
Чистый код легко читается, изменятся и поддерживается. Это тот код, с которым легко работать и вносить новый функционал.
Грязный код затормаживает разработку новых фич из-за того, что программистам тяжело с ним работать.
Призваны помочь борьбе с грязным кодом, делая жизнь программистов легче.

Для того чтобы выбрать название, задайте себе вопрос: “что делает эта функция?” или “что обозначает эта переменная?”. Если вы не можете ответить на вопрос – займитесь рефакторингом.
Самое сложная вещь в программировании – это нейминг.
Поэтому стоит подумать хотя бы минуту, прежде чем давать имя чему-либо.
Если вы понимаете, что делает функция, которую вы написали месяц назад – поздравляю, у вас получилось подобрать хорошее название.
Как правило, в современных языках программирования существуют модули, которые разделяют кодовую базу на части. Следовательно, каждое название находится только в своей зоне видимости и не требует дополнительного уточнения его принадлежности.
Кодирование признаков в именах бесполезно – IDE и так даёт всю нужную информацию о переменной. Также, оно ухудшает удобочитаемость кода и затрудняет автодополнение при вводе.
Каждая концепция должна обозначаться одним и тем же словом – иначе придётся разбираться чем одно отличается от другого.
Функции – как хорошие шутки: короткие и по делу.
– DeepSeek
Функции выступают основными строительными блоками программы. Поэтому, важно писать их так, чтобы было понятно, что происходит в коде.
Функция должна выполнять только одну операцию. Она должна выполнять её хорошо, и ничего другого она делать не должна.
– Роберт Мартин
Если название функции намекает на то, что она выполняет несколько действий, разбейте её тело на две новые функции. Таким образом, теперь она выполняет только одну задачу – объединение двух новых функций.
Первое правило: функции должны быть компактными. Второе правило: функции должны быть еще компактнее.
– Роберт Мартин
Чем компактнее функция, тем лучше. Но как и с любой вещью важно не переусердствовать – если функция легко читается, то зачем её разделять?
Чем меньше аргументов, тем лучше. Три или четыре – уже много. Для уменьшения их количества можно объединять в структуры, разделяя по группам.
Программист не должен заниматься форматированием.
В каждом языке программирования есть программы для форматирования кода. Их преимущество в том, что они работают быстро и соблюдают все стандарты языка.
Также, их можно настраивать, чтобы соблюдать особые правила выработанные в команде.
Важный аспект чистого кода это соблюдение стандартов. Они есть почти во всех языках программирования.
Python – PEP 8
Rust – The Rust Style Guide
C++ – Google C++ Style Guide
Просто следуйте им. Это снизит когнитивную нагрузку на мозг в спорных ситуациях, так как можно сделать так, как прописано в стандарте.

Одна для написания кода, а другая для рефакторинга.
Фокусируйтесь только на написании функционала. Не заморачивайтесь о длине функций, названиях переменных и т.д. Главная задача этой шапки – получить работающий код.
Приводите написанный код в читаемое состояние. Если вдруг стало нужно написать какой-то функционал – меняйте шапку.
Хороший комментарий должен описывать подробности, которые не могут быть выражены кодом. Например, примеры каких-то значений.
Не комментируйте то, что и так очевидно. Это не принесёт пользу, а наоборот навредит читаемости.
Удаляйте комментарии, которые перестали быть актуальными после изменений кода, так как они описывают уже не тот функционал, который был раньше.
Занимаясь бесконечным рефакторингом, вы перестаёте писать функционал. Доводите код до состояния достаточно чисто, а не до идеала – иначе вы никогда ничего не напишете.
Пожалуй это главное, чего стоит придерживаться, когда пытаешься писать чистый код.
Надеюсь, статья была полезной. Другие статьи можно найти в моём блоге.


Have you seen that man?
Часто при изучении английского многие сталкиваются с такой проблемой, как неправильное использование артиклей. Даже те, кто изучают английский долгое время, ошибаются в этом.
В этой статье разберём несколько правил для того, чтобы писать грамотно и не выдавать своё русское происхождение в англоязычных чатах.
Артикль a используется в тех случаях, когда говорится о каком-то общем понятии или когда что-то упоминается впервые.
Тут всё просто – a используется в тех случаях, когда слово начинается на согласный звук, а an – в тех, когда слово начинается на гласный звук.
a cat
Начинается на c, то есть на согласный.
an eagle
Начинается на e, то есть на гласный.
Так как во внимание берётся именно звук, пример
an hour
тоже правильный, так как h не произносится.
Артикль the ставится тогда, когда говорится о чём-то конкретном или о том, что уже упоминалось в разговоре.
Также он используется, когда говорится об уникальных объектах в единичном экземпляре.
the sun
Пишется с артиклем, потому что существует только одно солнце.
Как правило, сначала используется артикль a, а уже потом the.
I found a coin in the park. The coin turned out to be ancient.
Сначала говорится о какой-то монетке, которая была найдена в парке, а во втором предложении – уже именно о той самой монетке.
Чаще всего пишутся без артикля, кроме стран, названия которых состоят из нескольких слов.
Без артикля
Russia
С артиклем
the United States of America
Названия во множественном числе всегда пишутся с артиклем.
the Netherlands
Названия рек, морей и океанов пишутся с артиклем the, а названия озёр – без артикля.
Пишутся с артиклем the.
the North
или
the West
Это такие местоимения, как
my
her
their
its
и другие, которые обозначают принадлежность чего-то к чему-то.
Если перед словом стоит такое местоимение, ставить артикль не требуется.
Its tail is too long.
Не требуется ставить the, потому как its уже даёт необходимую конкретизацию.
Используются для указания на что-то.
This используется для указания на объект, находящийся близко, а that – для объектов, находящихся далеко.
This is my car.
Говорится о машине, которая стоит прямо здесь, то есть человек как бы указывает на неё словами.
На заметку: множественные формы this и that – these и those.
Также this используется для обозначения чего-то текущего и актуального.
This day was great!
Говорится о сегодняшнем, то есть текущем, дне.
This month wasn’t very hot.
Говорится о текущем месяце.
Надеюсь, статья была полезна 🤗. Другие статьи про английский вы можете найти в моём блоге или прямо тут на Пикабу.

Neovim <3
Расскажу о том, почему я использую Neovim как основной текстовый редактор, а также о том, как я им пользуюсь.
По сравнению с VS Code и другими IDE, Neovim очень минималистичный и простой. Единственное, что нужно знать – это то, какие клавиши за что отвечают.
После того как вы привыкаете к способу управления, появляется второе преимущество – удобство. После этого вам будет не хватать vim-раскладки в обычных редакторах.
Хоть vim-раскладка увеличивает скорость печати, это не главное, так как при 10 часах дебага она вам не поможет. Дело тут именно в удобстве.
Команда Действие
Esc – перейти в NORMAL режим
hjkl – перемещение
Ctrl-d/u – пол страницы вверх/вниз
gg/G – вверх/низ файла
yy/p – скопировать/вставить строчку
o/O – вставить пустую строчку снизу/сверху
I/A – переход в начало/конец строки
:w(q) – сохранить (и выйти)
:q! – выйти без сохранения
По настройке Neovim очень много статей, инструкций и т.д. Я опишу только свою конфигурацию.
Как я уже сказал, я люблю минимализм.
Из плагинов использую Telescope для навигации по проекту, Treesitter для подсветки синтаксиса и LSP для автодополнения и аннотаций. В качестве темы использую Gruvbox.
Моя конфигурация
GitHub с конфигурацией если вам интересно.
Единственная сложность при знакомстве с Neovim – vim-раскладка.
В Neovim есть 5 режимов. Каждый из них нужен для выполнения какой-то отдельной задачи.
Основной режим. Для перехода в него нажмите либо Esc, либо Ctrl-c.
h – влево
j – вниз
k – вверх
l – вправо
Ctrl-d – пол страницы вниз
Ctrl-u – пол страницы вверх
I – в начало строки
A – в конце строки
gg – в начало файла
G – в низ файла
Экран можно разделить на несколько частей. Для того чтобы разделить экран вертикально, напишите :vs, а для горизонтального разделения – :sp.
Разделение экрана
Для перемещения между окнами у меня настроены эти клавиши.
wh – перейти в окно слева
wj – перейти в окно снизу
wk – перейти в окно сверху
wl – перейти в окно справа
o – вставить пустую линию под текущей
O – вставить пустую линию над текущей
dd – удалить линию
yy – скопировать линию в буфер обмена
p – вставить скопированное
При удалении чего-либо, удаленный текст копируется в буфер обмена.
Позволяет выделять текст и манипулировать им.
Для того чтобы выделить текст, нажмите v в режиме NORMAL. Также, можно выделить всю линию, для этого нажмите V.
После выделения можно приступить к его редактированию.
d – удалить
u – перевести в нижний регистр
U – перевести в верхний регистр
y – скопировать в буфер обмена
p – вставить текст из буфера вместо выделенного текста.
Обычный режим для набора текста. Тоже что и в других редакторах.
Чтобы вернутся в NORMAL, нужно нажать Esc.
Перейти в него можно нажав : в NORMAL режиме. После каждой команды для выполнения нужно нажимать Enter.
:w – сохранить файл
:wq – сохранить и выйти
:q! – выйти без сохранения
Находясь в VISUAL режиме, напечатайте :s/, впишите текст или регулярное выражение которое хотите заменить, потом / и текст на который хотите изменить.
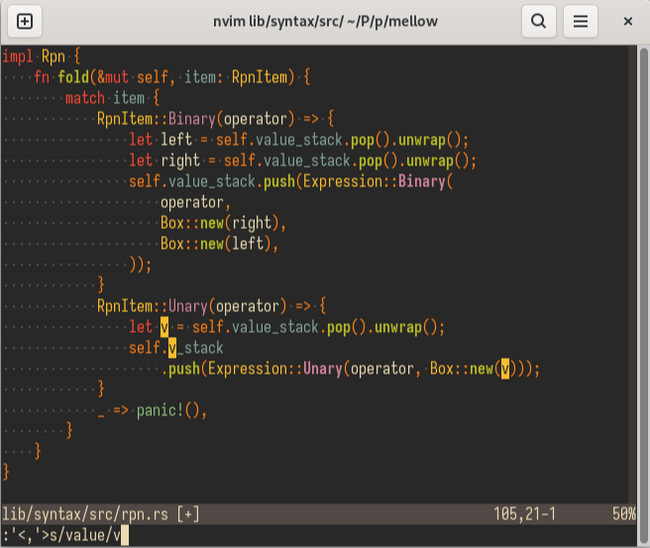
Замена текста в выделенной области
Нажмите / и впишите то, что хотите найти. После этого нажмите Enter и перемещайтесь по найденным результатам с помощью n.
Помогает искать файлы по названию. Я долгое время использовал Nvimtree, но после того как установил Telescope нужда в нём пропала.
Live Grep – плагин, дополняющий Telescope, который помогает искать код по всей кодовой базе с молниеносной скоростью.
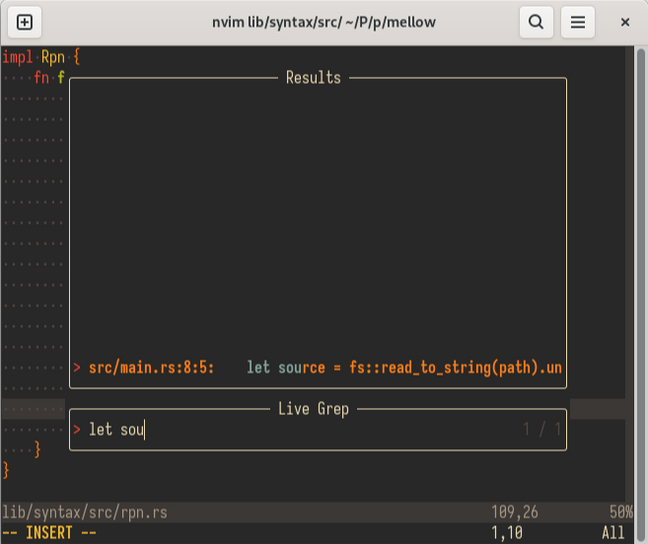
Поиск по кодовой базе
Для вызова напишите :te. В этом же окне откроется терминал, с возможностью использования vim-раскладки.
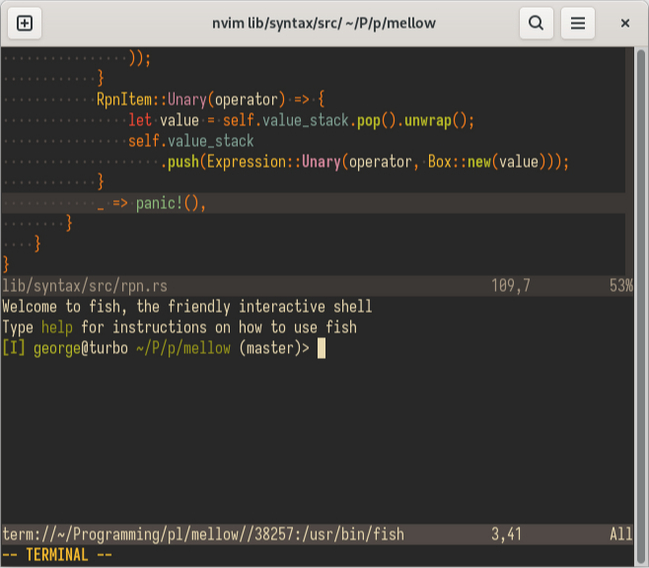
Встроенный терминал в отдельном окне
При открытии больших файлов редактор можно запускать в чистом виде без плагинов, затормаживающих открытие и редактирование.
nvim --clean
Иногда использую GUI версию Neovim под названием Neovide. Люблю его из-за очень красивой анимации перемещения курсора и того что он написан на Rust.
Если вам нужно выйти из редактора, просто наберите :q!.
Надеюсь статья была полезной. Больше статей в моём блоге.
Наглядная иллюстрация того, что может случиться с C++ программистами.
В Rust необычная схема управления памятью. Он не использует сборщик мусора, как в Java и Go, что делает его быстрым. Скорость Rust сопоставима со скоростью C.
Однако и у этой схемы есть минусы. Для того чтобы их решить, были введены умные указатели, которые дают возможность оперировать памятью на низком уровне с тем же удобством.
В статье специально использованы простейшие примеры, чтобы понять их было легче.
Нужен для хранения объектов в куче, а не на стеке.
Обычно используется для рекурсивных типов, где размер объекта неизвестен во время компиляции.
Пример кода, который не будет работать.
struct Expression {
operator: Operator,
left: Expression, // Ошибка: recursive type has infinite size
right: Expression, // Ошибка: recursive type has infinite size
}
Чинится обертыванием left и right в Box.
struct Expression {
operator: Operator,
left: Box<Expression>,
right: Box<Expression>,
}
Позволяет нескольким переменным владеть одним объектом размещенным в куче.
Не работающий код.
let a = "Hello, World!".to_string();
let b = a;
let c = a; // Ошибка: use of moved value
Чтобы он заработал, добавим Rc.
let a = Rc::new("Hello, World!".to_string());
let b = Rc::clone(&a);
let c = Rc::clone(&a);
Код также будет работать если мы скопируем объект.
let a = "Hello, World!".to_string();
let b = a.clone();
let c = a;
Но прямое копирование может серьезно повредить производительности. Преимущество Rc в том, что при присваивании не создаётся новый объект, а даётся ссылка на уже существующий.
То же что и Rc, но безопасное для использования в многопоточных приложениях. Это значит, что его можно использовать из разных потоков, не боясь гонок данных.
let a = Arc::new(1);
let b = Arc::clone(&a);
let c = Arc::clone(&a);
Дороже с точки зрения производительности из-за способа подсчёта ссылок.
Позволяет изменять данные внутри себя даже если объявлен как неизменяемый.
let a = RefCell::new(1);
*a.borrow_mut() += 1;
dbg!(a); // 2
RefCell часто комбинируют с Rc в виде Rc<RefCell<T>>. Это позволяет каждому владельцу ссылки изменять общий объект.
let a = Rc::new(RefCell::new(1));
let b = Rc::clone(&a);
let c = Rc::clone(&a);
*b.borrow_mut() += 1;
dbg!(&a); // 2
dbg!(&c); // Тоже 2
*c.borrow_mut() += 1;
dbg!(&a); // 3
dbg!(&b); // Тоже 3
Главное преимущество умных указателей – избегание ошибок типа segfault и выстрелов в ногу, характерных для C и C++, сохраняя при этом удобство использования.
Если статья была полезной, вас могут заинтересовать и другие статьи в моём телеграм-канале.




