
0 просмотренных постов скрыто




Как расшифровали клинопись
Началась эта история ещё в XVIII веке, когда европейские путешественники стали проявлять интерес к древним развалинам. Помимо руин античных храмов в поле их зрения попали и остатки Персеполя — столицы династии Ахеменидов в Персии (559–331 гг. до н.э.). На сохранившихся дверных проёмах дворцов любители древностей находили короткие надписи, выполненные тремя видами клинописи. Самые любопытные копировали их в свои путевые заметки.

Параллельно рос интерес европейских учёных к священным текстам востока, в том числе и к зороастрийской религии, которая во времена династии Ахеменидов была на подъёме. В 1771 году был опубликован текст Авесты, что подстегнуло интерес и к авестийскому языку.
Авеста — это священная книга зороастризма, древнеперсидский религиозный текст, содержащий молитвы, гимны, ритуальные формулы и предписания для верующих.
Первый шаг в расшифровке древнеперсидской клинописи сделал немец Г. Ф. Гротефенд. К этому моменту уже был определён самый простой вариант из трёх видов письма, которые присутствовали в скопированных в Персеполе надписях, это был как раз древнеперсидский, и ограниченное число знаков в этой части привело интересующихся к выводу, что письмо алфавитное.
Есть довольно чёткие критерии: если письмо фонетическое, знаков может быть до трёх-четырёх десятков. Если слоговое, их может быть около ста. Если же каждый знак означает отдельное слово, то знаков будет несколько сотен, и это минимум.
Наклонные клинья были восприняты как разделители слов, и далее, по тому, как слова переносились со строки на строку, было определено, что направление письма шло слева направо. И вот, начало положено: в одном из текстов Гротефенд увидел повторяющуюся группу знаков:

Он попытался найти что-то похожее в опубликованных древнеперсидских текстах, какую-нибудь типичную формулу, где бы повторялось одно слово примерно таким же образом.
И нашёл. Довольно часто надписи, посвящённые царям, начинались таким образом: "\имярек\ царь, царь царей...". Гротефенд предположил, что здесь как раз такая же формулировка. И тогда в начале должно идти имя этого царя, затем само слово "царь", далее, вероятно, какой-то эпитет царя, а потом формула "царь царей". Таким образом, Гротефенд сделал вывод, что повторяющийся набор знаков значит "царь".
Далее, он логически вывел, что первое слово в первой строке - это имя царя.

Далее, он взял другой подобный текст и обнаружил там тот же принцип: три раза слово "царь" в первых строках.

И тут он увидел, что последовательность знаков, с которой начинается второй текст, встречается в третьей строке первого (выделено синим):

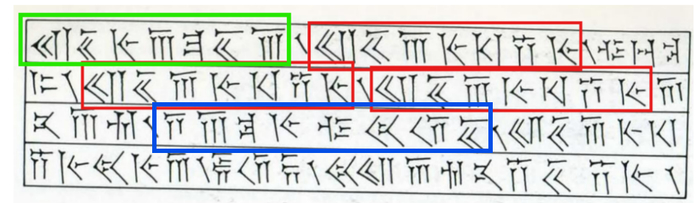
Кроме того, в первом тексте после этого имени опять шло слово "царь":

Получалось следующее: "Некто, царь какой-то, царь царей, ..., другой некто царь". Опять же, по аналогии с известными текстами, Гротефенд предположил, что здесь сказано, что такой-то царь, царь царей, является сыном другого царя (то есть "Некто, царь какой-то, царь царей, сын другого некого царя", и дальше, видимо, информация о его деятельности.
Очередным методом тыка он прикинул, что речь может идти про Ксеркса и его отца Дария. Покрутив их имена и так, и эдак, он получил такой вот предварительный набор расшифрованных знаков:

Некоторые знаки в двух именах оказались одинаковыми, и даже на нужных местах, чтобы это действительно оказались Дарий и Ксеркс (спойлер: да, это были они). Затем он взялся за слово "царь". Используя уже полученные благодаря именам соответствия, он увидел часть слова:
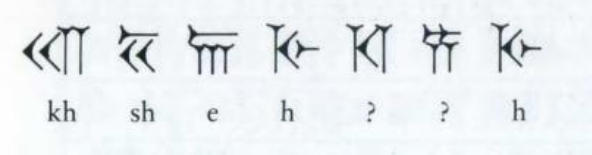
А благодаря Авесте он знал о наличии царского титула "khscheio". Поэтому два нерасшифрованных знака в слове "царь" он обозначил как "i" и "о". Далее, в тексте про Дария он стал также искать упоминание его отца, предположив, что принцип составления текстов одинаков. Зная, что отца Дария звали Гистасп, он нашёл что-то похожее:
Тогда он поиграл и с этим именем, и предположил, что Гистасп расшифровывается следующим образом (знаки "о", "sh", "а" уже были, теперь он добавил "g", "t", "s" и "p").

И, хотя не все его выводы позже были признаны верными, этот лингвистический подвиг положил начало глобальному процессу, который продолжился после Гротефенда медленно, но уверенно. Последователи продолжали сопоставлять источники, искать известные имена, и, таким образом, открывать новые и новые знаки.
Следующий прорыв был совершён англичанином Генри Роулинсоном спустя тридцать лет после Гротефенда (в 1835 году). Он стал копировать огромные надписи Дария, высеченные на теперь уже знаменитой горе Бехистун. Эти надписи увековечивали победы Дария в установлении его власти над Персидской империей, и также были выполнены на трёх языках, как и ранее известные короткие надписи из Персеполя.
Теперь мы знаем, что три представленных языка были древнеперсидским (это то, что дешифровывал Гротефенд), а также эламским и вавилонским.
За десять лет Роулинсон скопировал все 414 строк Бехистунской надписи (причём он должен был работать как скалолаз, потому что скала была высокой и отвесной). Благодаря этому он стал обладателем бесценной информации: здесь были названия всех народов империи Дария, а поскольку названия народов нередко одинаковы или похожи в разных языках, то это позволило идентифицировать огромное количество новых знаков.
Когда древнеперсидские тексты были, наконец, побеждены, пришёл черёд эламских и вавилонских. Их Роулинсон скопировал в 1844 и 1847 годах, но здесь дела обстояли значительно сложнее. В эламских текстах встречалось 123 знака, что означало, что письмо это силлабическое (слоговое), а не алфавитное. И хотя, благодаря тому, что тексты на всех языках были параллельны, можно было примерно предполагать звуковые формы знаков, это всё равно было очень трудно: языки эти не родственные, и произношение одних и тех же имён и названий было разным. Например, того же Гистаспа на древнеперсидском звали vi-i-ša-ta-a-sa-pa-ha-ya-a (да, Гротефенд был не совсем прав насчёт некоторых знаков в его имени), на эламском mi-iš-da-áš-ba, а на вавилонском uš-ta-as-pa.
Эламская часть была поручена Эдвину Норрису, который справился с ней к 1855 году. А Роулинсон вместе с коллегой Хинксом занялись вавилонскими текстами. Они оказались ещё сложнее первых двух, потому что были написаны частично фонетическими знаками, а частично логограммами (то есть часть знаков означала звуки, а часть - целые слова). Например, в тексте, посвящённом Дарию, имя Дария написано звуковым письмом, а титул "царь" (šarrú) обозначен шумерским знаком LUGAL.
Дешифровщикам пришлось изрядно поломать голову, прежде чем они вообще могли предположить, что в одном и том же тексте может встречаться два типа знаков (в вавилонском языке I тыс. до н.э. использовалось более 600 знаков). В помощь им, к счастью, существовали известные учёным иврит, арамейский и другие языки семитской группы, куда относился и вавилонский.
И таким вот образом, шаг за шагом, методом тыка, подбором, сопоставлением, проверками, откатываниями назад, сравнениями с другими языками и текстами, клинопись была расшифрована.
Источник изображений:
Walker. C. Reading The Past Cuneiform \есть в свободном доступе ВОТ ТУТ\
Показать полностью
10

ЪГЪЛ. Рассказываем, как читается это болгарское слово. И почему именно так

Сегодня мы займемся лингвистической археологией и разберем одну занимательную историю, спрятанную в болгарском алфавите. Речь пойдет о букве, которая нам, русскоязычным, хорошо знакома. О твердом знаке.
Вот только в болгарском языке у буквы Ъ совершенно иная, куда более звучная роль.
Первый путь
Начнем с самого начала. В древних славянских языках существовали так называемые редуцированные, или сверхкраткие, гласные. Это были звуки-призраки, которые произносились очень слабо и кратко. Их обозначали буквами “Ъ” (ер) и “Ь” (ерь).
Со временем в восточнославянских языках (в том числе и в русском) эти звуки в большинстве позиций сократились настолько, что просто исчезли – этот процесс историки называют падением редуцированных. А в сильных позициях, например, под ударением, они прояснились и стали звучать полноценно – О, Е.
Так у нас, кстати, появились беглые гласные. Допустим, день – дня. Вот эта беглая “е” на самом деле когда-то была звуком “Ь”. Писалось: дьнь – дьня. В первом случае “Ь” был под ударением и развился в полногласный “Е”, а во втором сократился до нуля и выпал.
А вот в болгарском языке редуцированный “Ъ” никуда не пропал. Он остался в словах, и произносится теперь как некий неразборчивый звук – то ли “ы”, то ли “о”. Очень похоже на то, как мы произносим первый гласный в слове “молоко”, когда не стараемся четко выговаривать все слоги.
В болгарском алфавите “Ъ” получил название “ер голям” (большой ер) и является полноценной гласной буквой.
Второй путь
В праславянском существовали носовые гласные, которых в современном русском уже нет. В процессе развития славянских языков этот звук в разных славянских диалектах пошел разными путями. В древнерусском языке их наследником был юс большой – буква Ѫ, обозначавшая носовой звук, средний между “о” и “у”. В русском языке он благополучно перешел в обычный, чистый звук “У”.
В болгарском этот носовой звук пережил несколько иную эволюцию. Он тоже утратил свой призвук, но превратился в итоге не в “у”, а в… некий неразборчивый звук – то ли “ы”, то ли “о”. То есть по факту совершенно совпал в произношении с тем же “ер голям”, сохранив при этом свое изначальное начертание – Ѫ.
В итоге у болгар образовались две буквы, означающие практически один и тот же звук: Ѫ и Ъ. Весь XIX век выдвигались проекты реформы, ликвидирующей этот казус. Например, предлагалось сохранять букву Ѫ только там, где было ясно видно ее этимологию. Проектов было много, но буква Ѫ все-таки дожила аж до 1945 года.
А теперь главный нюанс. В 1945 году в Болгарии прошла орфографическая реформа, одним из ключевых пунктов которой было следующее: буква Ѫ упразднена и заменена на Ъ во всех случаях, кроме слова “сѫ”, где она заменена на “а”. То есть вопрос решили радикально.
Разбираем слово “ъгъл”
Теперь давайте применим наши знания на практике и разберем тот самый пример, который и навел нас на эту тему. Возьмем болгарское слово “ъгъл”. Буквы “Ъ” в нем – разного происхождения.
Первый “Ъ” (в начале слова) – это как раз наследник юса большого (Ѫ). В праславянском это слово звучало с носовым звуком. В русском этот звук превратился в “У”.
Второй “Ъ” (в конце слова) – это классический пример развития из древнего редуцированного гласного. В русском языке этот сверхкраткий звук в сильной позиции развился в “О”.
Что будет, если заменить первый “Ъ на “у”, а второй – на “о”? Правильно, получится “угол”. Именно так и переводится болгарское слово “ъгъл”.
Таким образом, в одном слове мы видим наглядный результат двух независимых исторических процессов, которые привели к одному графическому и фонетическому итогу.
Источник: Литинтерес (канал в ТГ, группа в ВК)
Показать полностью


Рот и губы
Я не знаю, что будет с моей памятью через 50 лет.
Но я точно буду помнить всю жизнь, что
рот — ля бока, а губы — ля лябра.

Методы мнемотехники
Мнемотехника - это способ запоминания огромного количества информации в короткие сроки.
Если вы хотите выучить быстро иностранный язык, то можете использовать мнемотехнику.
Однако со стороны это выглядит странно. Кто видел мои посты, тот сразу скажет - что это за херня?!
Эта херня - использование метода звуковых ассоциаций в мнемотехнике. Берём английское слово pillow и подбираем схожее слово по звучанию пила. Тут многие говорят – а зачем, теперь вместо двух слов pillow - подушка надо три слова запоминать, это же больше лишних слов. И тут люди ошибаются.
Мнемотехника - это не зубрёжка слов. Не нужно слова запоминать отдельно. Нужно совмещать слова в один образ: пилой распилили подушку. Просто представьте эту сцену. Вот вы стоите у себя в спальне у кровати и пилите пилой подушку. Теперь вы точно никогда не забудете, что подушка это pillow.
Главное не слова, а образы. Люди далёкие от мнемотехники этого не понимают. И именно поэтому на прошлые посты я получил кучу дизов и клоунов. В панамку мне хорошо накидали).
Кроме метода ассоциаций однако существует и другой метод - метод локаций или дворец памяти. Нужно запомнить большой список слов - размещай эти слова в знакомой локации. Можно в своей квартире, можно по дороге на работу. Например надо запомнить: мяч, трамвай, пистолет, пылесос, яблоко, кирпич, труба, деньги, вилка, кот.
Выхожу я из дома и вижу на дороге прыгает мяч. За углом же моего дома проехал трамвай. В соседнем дворе стоит мужик с пистолетом. Посреди двора ездит пылесос. Вышел со двора и вижу, как ребёнок ест яблоко. На бульваре лежит гигантский красный кирпич. У девятины через дорогу проложена труба. Возле светофора из окна автомобиля выкинули пачку денег. Из киоска выкидывают вилки. А возле ворот рынка гуляет кот.
Так же можно и не привязываться у конкретным локациям, а просто составить рассказ из слов: мяч попал под трамвай. Водитель трамвая достал пистолет и выстрелил в пылесос. Пылесос засосал яблоко. Но тут пылесос разбили кирпичом и перебросили яблоко в трубу. Из трубы полетели деньги. Деньги поддели на вилку. Вилку облизал кот.
Кроме этого существует ещё методика за поминания цифр - БЦК буквенно цифровой код. Здесь можно использовать как визуальную схожесть цифр 1 - кол 2 - лебедь, так и буквы. Я совмещаю и то и то: лтчп - 2345, где 2 - лебедь, 3 - т, 4 - я, 5 - п. Запоминаешь фразу лётчик попал в чп и расшифровываешь, что это 2345.
Собственно и всё.
Показать полностью

Начните с Мураками
Мураками Харуки (не путать с Мураками Рю) — почти идеальный автор для момента, когда базовый вокабуляр уже при себе, но читать что-то «настоящее» всё ещё страшно. Я и сам с него начинал. Не только когда взялся учить язык, но и в принципе, когда взялся за японскую литературу. Точно какая — не помню, но одна из его книг была на полке у моей сестры. Я её тогда, лет в 14, прочитал взахлеб за несколько вечеров, закрыл — ничего не понятно, но очень интересно. Такой вот экспириенс, который я повторил позже не один раз. Ну ладно, пост немного не об этом.
У Мураками довольно прозрачный стиль: короткие предложения, понятные диалоги, много бытовых сцен. Он, кстати, пишет так намеренно. Вот отрывок из его книги «Писатель как профессия» (職業としての小説家): «Я заменял сложные слова и конструкции простыми, перефразировал идеи так, чтобы они становились предельно ясными, и очищал описания от языковых украшений и мишуры» (内容をできるだけシンプルな言葉で言い換え、意図をわかりやすくパラフレーズし、描写から余分な贅肉を削ぎ落とし…).
Главное в Мураками для изучающих японский — повторяемость. Одни и те же слова, конструкции и сцены возвращаются снова и снова: человек просыпается, готовит еду, пьёт кофе, слушает музыку, идёт по улице, разговаривает с кем-то странным. Для обычного читателя это может быть «ну да, опять колодец, джаз и одинокий мужчина», а для изучающего язык — почти встроенная система интервального повторения.
Я бы не советовал начинать с самых толстых романов, если вы только переходите к чтению. Лучше взять рассказы, например «ドライブ・マイ・カー» («Сядь за руль моей машины», по его мотивам, кстати, есть одноимённый классный фильм), или что-то относительно короткое, например «国境の南、太陽の西».
Надеюсь, благодаря этому посту кто-то не только улучшит японский, но и познакомится с одним из самых узнаваемых японских писателей.
Показать полностью
Связаны ли слова "смирна" и "смирный"?
(рубрика: вопрос от подписчика)
Нет.
Слово "смирна" — греческое, σμῠ́ρνᾰ \smŭ́rnă\. С этимологией у него не очень хорошо, но по одной из версий оно идёт от названия города Измир (по-гречески, собственно, Σμύρνα \Smúrna\). Происхождение названия города Измир ещё более тёмное.
Слово "смирный" наше родное, хотя и с подвохом. Подвох заключается в том, что как будто бы оно происходит от слова "мир", как и прилагательное "мирный". Может, оно и так, а может, это, скорее, родня слову "смиренный" (от "смирение"). А "смирение" раньше выглядело как "съмѣрение", от слова "мѣра" (а не от "мир"), и таким образом изначально оно было родственным для "умеренный", "измерить", "смерить" и прочего с корнем "мер". Скорее всего, сближение с "мир" тут произошло вместе с изменением написания благодаря народному переосмыслению.


Ответ USSR9609986 в «Прибалтика и русский язык»2
А чем может гордиться современная Латвия?
Что первое вспоминается? Шпроты? Рижский бальзам?

Фото сгенерировано ИИ.
Первые промышленные шпроты были разработаны в 1890 году в Риге. Именно тогда местная фирма «Морис и Ко» впервые начала консервировать подкопченную балтийскую кильку в масле, укладывая ее стройными рядами.
В 1890 году территория современной Латвии входила в состав Российской империи и делилась на три губернии: Курляндскую, Лифляндскую и Витебскую.
1955 год: В СССР был разработан и выпущен первый единый государственный стандарт (ГОСТ 280-55) на классические шпроты в масле, которые стали символом праздничного стола.
Слово «шпрот» происходит от немецкого «Sprott» — так называют мелкую морскую рыбу (салаку или кильку).

Оригинальная этикетка того времени
Рижский черный бальзам был придуман в 1752 году. Его создал рижский аптекарь Абрахам Кунце, изначально назвав целебный напиток «Бальзамом Кунце».
В 1752 году Рига являлась частью Российской империи. Город вошел в состав России в 1710 году во время Северной войны. Этот статус был юридически закреплен Ништадтским мирным договором в 1721 году, после чего Рига стала административным центром Рижской губернии. (Кстати, за эти территории Россия выплатила Швеции денежную компенсацию в 2 миллиона рейхсталеров (около 56 тонн серебра) за уступленные прибалтийские территории, так что территории были не только завоеваны, но куплены, вместе со всеми жителями).
Получается, за оба символа и предмета национальной гордости Латвия обязана вовсе не латышам? А чем ещё современная Латвия может гордиться?
Может, есть какой-то аналог «Сделано у нас», чтобы можно было ознакомиться с прогрессом Латвии после того, как они «освободились» от «русской оккупации»?
Показать полностью
2