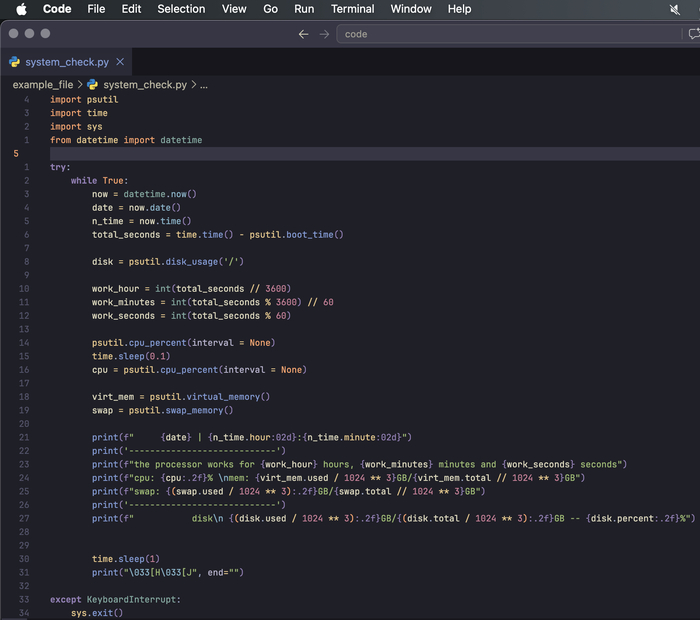
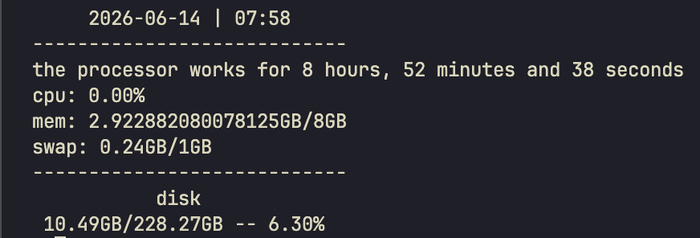
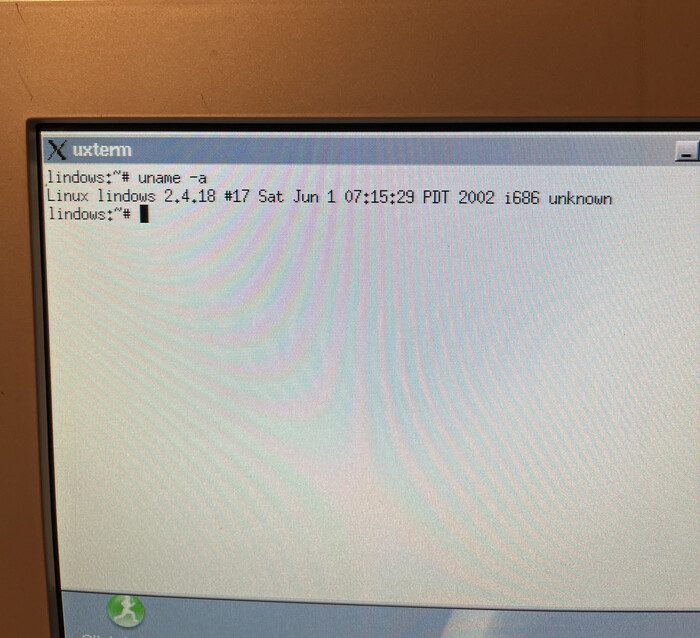
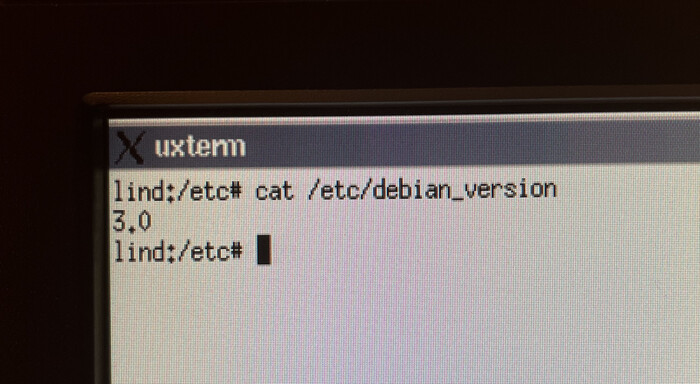
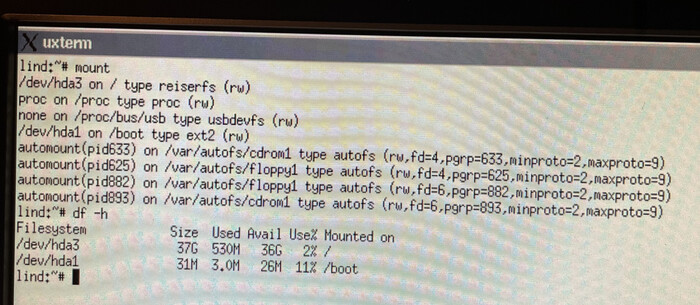
Был серьёзный перерыв, потеря мотивации и всё такое, с момента последнего поста углубился в работу с консолью, поставил две виртуалки дебиан, одну кде, другую hyprland, обе снёс из за того что надоел весь этот сахар, сегодня более или мненее разобрался с psutils, написал что то типа мини утилиты для бекапа системы, не на что не претендую, писал не для использования а для освежения навыков и изучения библиотеки, вот код и вывод:
Привет, Пикабу! Я отвечаю за ИТ и цифровую трансформацию (CDTO/CIO) на крупном промышленном предприятии. Если вы работаете в энтерпрайзе, то наверняка знаете эту боль: бизнес приходит и говорит «Хотим свой ChatGPT, чтобы он читал наши чертежи и оптимизировал производство!». А следом приходит служба информационной безопасности (ИБ) и молча кладет на стол регламенты.
В нашей реальности облачные LLM (будь то зарубежные или отечественные по API) мертвы по определению. Коммерческая тайна, строгая регуляторика, жестко изолированный контур (air-gapped сети) и гетерогенный парк на базе Astra Linux диктуют свои правила. Нам нужен локальный, полностью суверенный ИИ.
Важная оговорка: всё, о чем пойдет речь ниже — это результаты моего независимого исследования. Я собрал локальный стенд на собственном оборудовании, сфокусировавшись на типовых проблемах промышленности, но без использования служебных данных и корпоративной инфраструктуры. В этой статье я расскажу, как уйти от игрушечного «промт-инжиниринга» к распределенным мультиагентным системам, как математически обосновать закупку GPU-кластера и как заставить локальные модели работать быстро, не выжигая железо. Будет много технического мяса.
1. Иллюзия монолитных запросов и переход к мультиагентности
Если попытаться развернуть большую локальную модель (70B+) и «скормить» ей в контекст гигабайты нормативки, результат предсказуем: модель либо захлебывается (out of memory), либо начинает галлюцинировать, придумывая несуществующие пункты регламентов. Монолитные LLM хороши для генерации писем, но для сложных промышленных задач они непригодны.
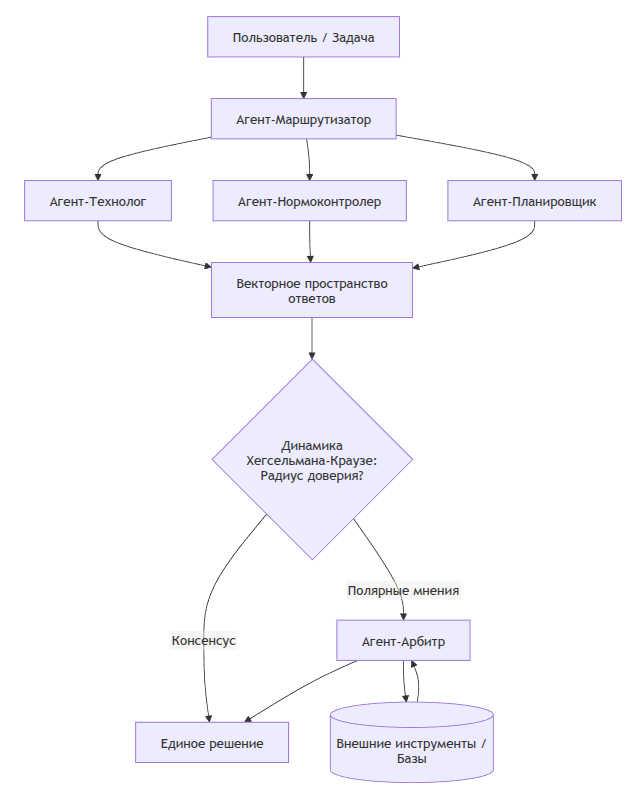
Я спроектировал архитектуру на основе мультиагентных систем (MAS). Вместо одного «всезнающего» ИИ работает рой небольших специализированных моделей (14B-32B).
Как заставить их договариваться?
Чтобы агенты (например, «Агент-Технолог», «Агент-Нормоконтролер» и «Агент-Планировщик») не спорили бесконечно, их координация формализуется как децентрализованный частично наблюдаемый марковский процесс принятия решений (Dec-POMDP). Каждый агент видит только свою часть производственной задачи, но максимизирует общую функцию полезности.
Для согласования ответов экспертных агентов я применил математический аппарат нелинейной динамики Хегсельмана-Краузе (Hegselmann-Krause). В классической модели Х-К мнения агентов сходятся, если они находятся в пределах «радиуса доверия». Для LLM это выглядит так: если эмбеддинги ответов агентов находятся близко в векторном пространстве, они сливаются в единое решение (консенсус); если мнения полярны — запускается арбитражный агент, который вызывает внешние инструменты проверки.
Пример из практики: мы используем открытые веса эффективных моделей семейства Qwen (например, Qwen 2.5 на 14B-32B параметров). При проверке легальности, нормативного соответствия или подборе сложных кодов (технологических или таможенных) один Агент-Эксперт генерирует гипотезу, а другой, Агент-Нормоконтролер, жестко сверяет ее по RAG-базе локальных ГОСТов. Динамика Х-К позволяет им достичь консенсуса, исключая галлюцинации: если первый придумывает несуществующий пункт, второй не принимает этот токен (их мнения полярны), и арбитр запрашивает перегенерацию с прямой выдержкой из PDF.
Безопасность и верификация графа
В промышленности цена ошибки ИИ — это остановка линии или брак партии. Поэтому необходим жесткий контроль пайплайнов с помощью раскрашенных сетей Петри (Colored Petri Nets, CPN).
CPN позволяет статически верифицировать граф исполнения агентов до его запуска. «Фишки» (токены) в сети несут в себе типизированные данные (json-объекты с контекстом), и мы математически гарантируем, что агент не сможет передать секретный чертеж агенту, у которого нет нужного уровня допуска (аналог мандатного доступа Astra Linux), а также то, что процесс не уйдет в бесконечный цикл (deadlock).
2. Выживание на одной RTX 3090: как впихнуть невпихуемое
Давайте без иллюзий. Когда мы говорим «ИИ для энтерпрайза», многие представляют себе стойки с H100. Но в реальности тестирование гипотез, RAG-конвейеров и парсинга нормативки (для моих pet-проектов) происходило у меня дома, на одной-единственной десктопной RTX 3090 с 24 ГБ VRAM.
В 24 ГБ VRAM физически не влезает неквантованная модель на 32B, не говоря уже про контекст в 100k-200k токенов (а приказы и ГОСТы, которые я загружал в прототипы, легко съедают этот объем). Оптимизация инференса здесь — вопрос выживания, а не красивых графиков.
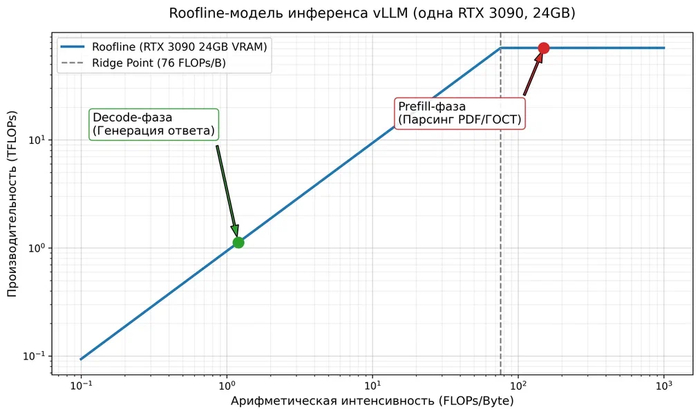
Я профилировал работу моделей через двухфазную модель Roofline:
Prefill-фаза (когда модель «проглатывает» промт с кучей документации): мы упираемся в вычислительную мощность (compute-bound).
Decode-фаза (когда модель отвечает): мы упираемся в пропускную способность памяти (memory bandwidth-bound).
Самой большой болью стал KV-кэш. При потоковой обработке документов в `vLLM` с окном контекста в 128k–262k токенов кэш мгновенно выедал всю оставшуюся видеопамять (OOM).
Мой стек оптимизации для RTX 3090:
Квантование: Я перешел с тяжелых весов на GGUF и AWQ (FP8). Это позволило уместить веса хорошей модели семейства Qwen в ~12-14 ГБ VRAM, оставив место под контекст.
Heavy Hitter Oracle (H2O): Для сжатия KV-кэша. В механизме внимания не все токены одинаково полезны. H2O динамически оценивает «важность» токенов в кэше и безжалостно отбрасывает (evict) лишние, оставляя только Heavy Hitters (токены, на которые опирается смысл) и небольшое окно свежих токенов.
Разделение нагрузок: В проектах я вынес генерацию векторов (эмбеддингов) и задачи OCR в ONNX-рантайм (только CPU/RAM), чтобы полностью отдать дефицитную видеопамять под `vLLM` сервер.
Именно эти суровые "домашние" ограничения научили меня делать по-настоящему эффективные локальные архитектуры, которые на заводах смогут работать не на суперкомпьютерах, а на обычных серверах с бытовыми или полупрофессиональными GPU.
3. FinOps: Как защитить бюджет на GPU-кластер
Финдиректору плевать на H2O и сети Петри. Ему нужны цифры. Инвестиции в локальные GPU — это тяжелый CapEx.
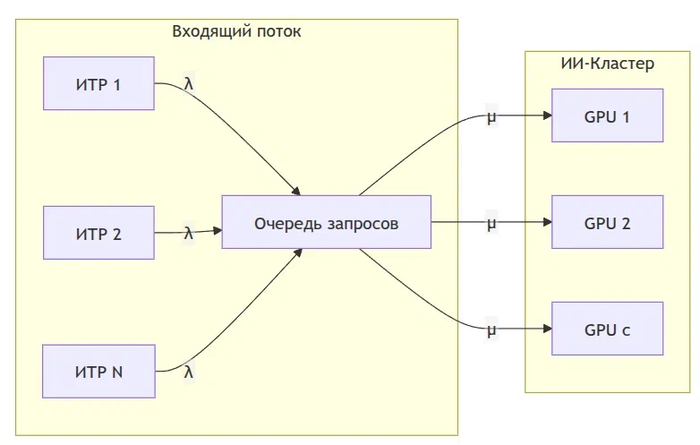
Чтобы обосновать размер кластера, я предлагаю использовать теорию массового обслуживания (СМО). Локальный API моделируется как система типа M/M/c, где:
пуассоновский входной поток заявок (λ) — это запросы от ИТР (инженерно-технических работников);
экспоненциальное время обслуживания (μ) — это время инференса;
c — количество параллельно работающих GPU/инстансов моделей.
Построив график вероятности ожидания в очереди P(W>0) в зависимости от количества видеокарт, можно найти точку экстремума, где добавление новых GPU уже не дает существенного прироста утилизации (закон убывающей отдачи). Это дает точное понимание, сколько железа брать в первую очередь, не переплачивая за простаивающие мощности.
Далее это упаковывается в финансовую модель:
Считается ROI (Return on Investment) и NPV (Net Present Value) проекта на горизонте 3 лет.
В графу доходов закладывается не мифическая «инновационность», а конкретные FTE (Full-Time Equivalent): сколько человеко-часов высокооплачиваемых инженеров высвобождается от рутинного поиска по документации и формирования отчетов.
Учитывается стоимость рисков: штрафы за утечку коммерческой тайны (если бы мы пошли в публичное облако) и экономия на штрафах от надзорных органов благодаря снижению ошибок в проектной документации.
При грамотном расчете NPV выходит положительным, и проект окупается.
4. Практика: что ИИ реально может делать на заводе?
На базе моих тестов и прототипов можно выделить следующие сценарии применения в air-gapped контуре:
Парсинг и аудит техзаданий по ГОСТ 34 и ГОСТ 19
Инженеры загружают в систему сырые требования заказчика. Агенты автоматически разбивают их на атомарные пункты, проверяют на противоречия (через динамику Хегсельмана-Краузе) и генерируют драфты ТЗ, спецификаций и программ испытаний, строго форматированные по ГОСТам. То, на что уходили недели рутины, может делаться за часы.
Анализ нормативной документации (RAG-система)
Сборка локальной базы векторного поиска по внутренним СТО, регламентам и инструкциям. Технолог спрашивает: «Какой допуск по шероховатости для детали Х при обработке на станке Y согласно регламенту от 2023 года?». Модель выдает точный ответ с прямой ссылкой на абзац в PDF.
Анализ исторических логов АСУ ТП и журналов дефектов. ИИ (в связке с классическим ML) может анализировать текстовые записи операторов и телеметрию, выявляя скрытые паттерны, предшествующие поломке оборудования.
Оперативное планирование
Планировщик в цехе общается с ИИ-агентом на естественном языке, чтобы перестроить маршрутные карты при внезапной поломке станка. ИИ опрашивает ERP-систему (через API по строгому графу CPN), анализирует свободные мощности и предлагает варианты перестроения плана.
Заключение
Проектирование локального ИИ для сурового энтерпрайза — это не про то, как написать красивый промт. Это про математику, инженерию (сжатие кэшей, расчет СМО), информационную безопасность на уровне мандатного доступа и архитектуру агентов, которые не имеют права на галлюцинации.
Облака — это здорово и удобно. Но когда речь заходит о ядре промышленности, суверенитет и безопасность данных не имеют цены. И, как показывают мои исследования, архитектура локальных ИИ-кластеров сегодня уже способна решать тяжелые производственные задачи, математически обосновывая свою окупаемость.
А как вы решаете проблему ИИ в закрытых контурах? Пытаетесь пробить файрвол к облакам или собираете свои локальные кластеры? Делитесь в комментариях!
Знакомая ситуация? Скопировал на телефоне код из СМС - надо вставить в терминал на ноуте. Скопировал ссылку на компе - хочешь открыть на телефоне. И каждый раз одно и то же: отправляешь сам себе в Telegram, в «Избранное».
У меня этих «Избранных» сообщений уже на пару тысяч накопилось. Свалка из ссылок, кодов, кусков текста и паролей.
Вот на слове «паролей» я и притормозил.
Неприятная мысль
Сначала я пошёл искать готовое решение - таких сервисов хватает. Поставил один, попользовался неделю. А потом поймал себя на мысли: я только что прогнал через этот буфер пароль от рабочей базы. И он улетел на чей-то чужой сервер.
Полез читать, как эти штуки устроены. И почти везде одно и то же: ваш буфер обмена уезжает на сервер компании, там лежит, оттуда раздаётся на другие ваши устройства. Шифрование «по дороге» есть почти у всех - но на самом сервере данные лежат как есть. Открытым текстом.
То есть весь вопрос «читает ли кто-то мой буфер» сводится к «доверяю ли я этой компании». А я не хотел доверять на слово. Даже самому себе.
Что я в итоге сделал
Сел и написал свой сервис. Называется Copy Sync. Идея в одной фразе:
Сервер устроен так, что ему физически нечего у вас украсть.
Это не «мы обещаем не смотреть». Это «мы технически не можем посмотреть, даже если очень захотим». Разница примерно как между «сосед обещал не читать ваши письма» и «письмо вообще не попадает соседу в руки».
Как это работает на человеческом языке:
Ваш текст шифруется прямо на вашем устройстве, ещё до отправки.
На сервер уезжает уже не текст, а зашифрованная каша. Ключа от неё у сервера нет - ключ остаётся у вас.
Получатель (другое ваше устройство) расшифровывает кашу обратно у себя.
Сервер в этой схеме - просто труба. Он передаёт мешок, не зная, что внутри. Сами данные не хранятся - улетели и удалились.
Если кто-то завтра украдёт мой сервер целиком и заглянет в базу - он увидит столбец со случайным шумом. Ни паролей, ни ссылок, ни ключей. Их там нет не потому, что я их спрятал. Их там нет по конструкции.
Почему рассказываю, а не просто пользуюсь молча
Потому что «доверьтесь мне, я честный» - это ровно то, от чего я бежал. Поэтому весь код открыт. Любой, кто умеет читать программу, может проверить.
И честно про минусы, без маркетинга: проект ещё сырой. Пока работает веб-версия, расширение для браузера и приложения на телефон - в планах. Пара важных штук по безопасности ещё не доделана. Это пет-проект одного человека, а не продукт корпорации.
В ядре Linux нашли уязвимость CVE-2026-46333, которая звучит особенно неприятно для администраторов: обычный локальный пользователь на уязвимой машине может прочитать файлы, доступные только root, включая приватные SSH-ключи хоста и /etc/shadow с хешами паролей. Проблема получила название ssh-keysign-pwn, а публичный демонстрационный эксплойт уже появился в открытом доступе.
Исправление вошло в ядро 14 мая 2026 года через коммит 31e62c2ebbfd
Как обычно, миллион миллион красных глаз за все время существования ядра смотрел куда угодно, но только не в код. Непонятно куда смотрели и все органы сертификации, с их "безопасным линуксом".
Все по новой классике
Если речь об уязвимостях, то линукс это только ядро, софт отношения к нему не имеет. Уязвимости софта – это не проблема линукса.
Уязвимость в драйверах, входящих в ядро, тоже не считается, потому что раз драйверы сами по себе (если рассматривать их в вакууме) – не ядро, то они сразу же никакого отношения к ядру не имеют, а линукс – это ведь только ядро. Архитектура ядра линукса неуязвима, поэтому если софт, скачанный из магазина приложений в андроиде, тихо ворует персональные данные, то это неправильный софт, кривой пользователь, но архитектура ядра линукса неуязвима.
Все эти CVE последнего месяца - результат реальное применение нейронок, а не только котиков рисовать.
И, на сладкое. Есть в США такая фирма, National Security Agency. Они эксплуатируют нейронки где-то с года 2010-2015. Наиболее известен Utah Data Center (UDC), запущенный в 2014 году, всего за 1.5 миллиарда тогдашних долларов. Наиболее известен продукт EternalBlue, получивший мировую известность в 2017 году. При том, что продукт был разработан в 2012.
The NSA did not alert Microsoft about the vulnerabilities, and held on to it for more than five years before the breach forced its hand
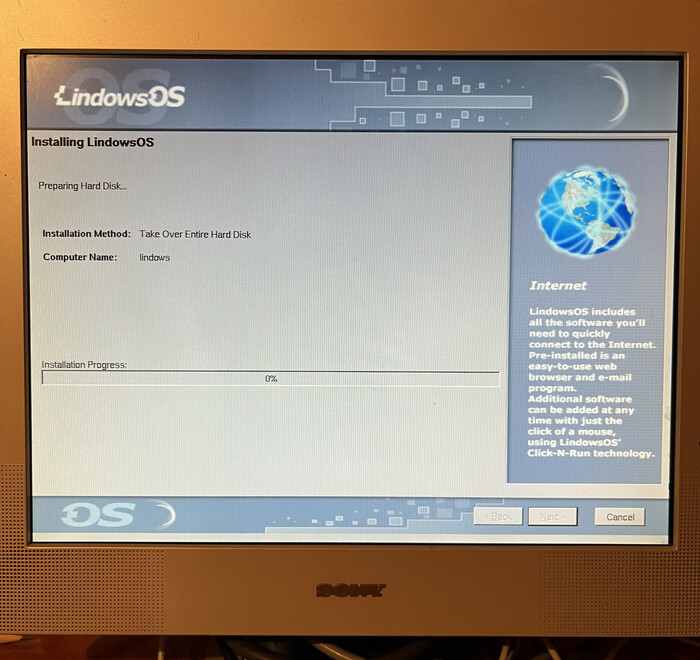
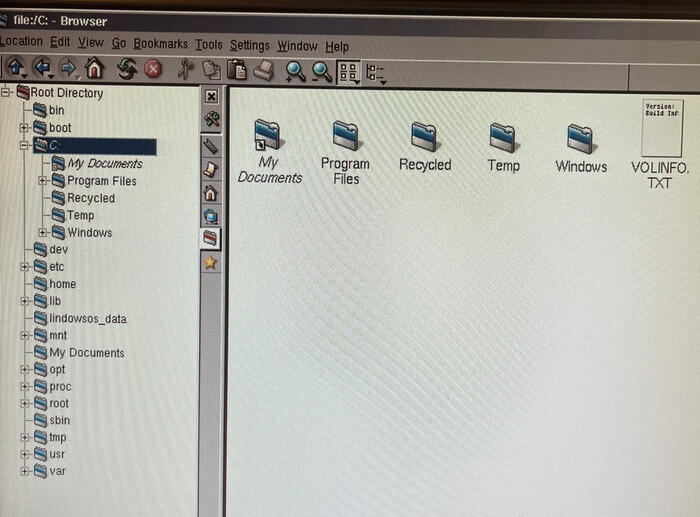
Итак, что обещали потребителю? Lindows заменит две операционные системы. Зачем держать две системы? Когда я приобретал этот диск, я думал так же. Но обо всём по порядку.
Поехали. CD-диск (загрузочный) выглядит так:
Установка весьма проста — загружаемся с компакт-диска. Всего четыре простых шага.
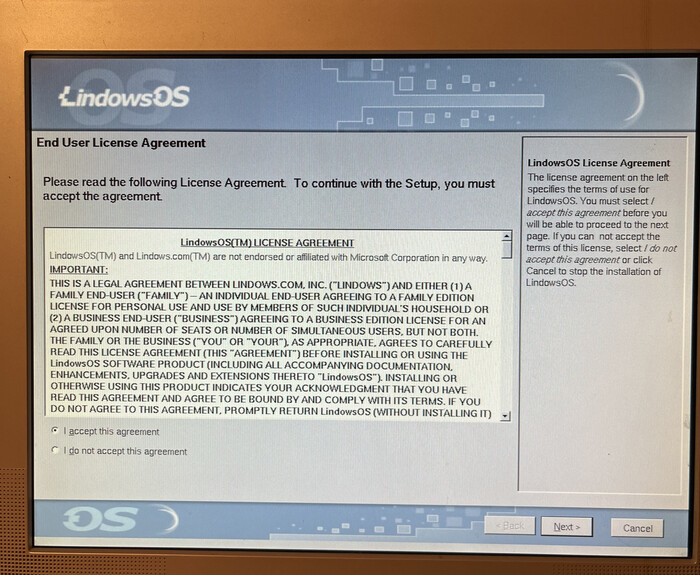
Пользовательское соглашение
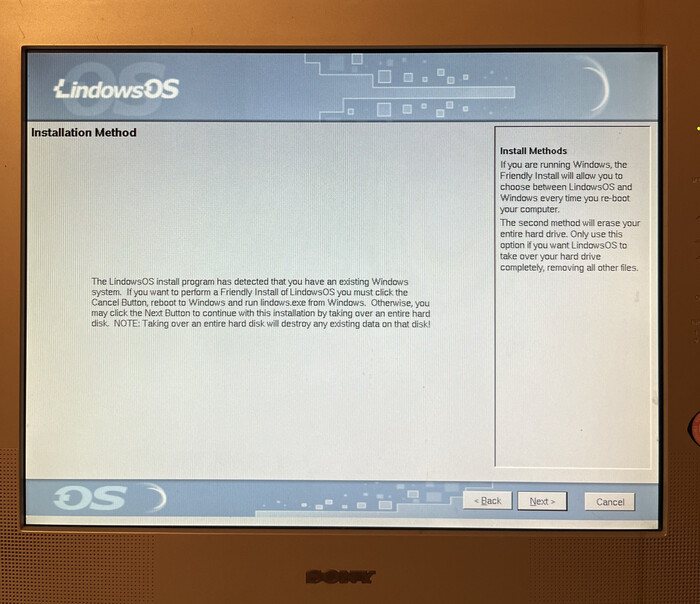
Определение наличия уже установленной системы
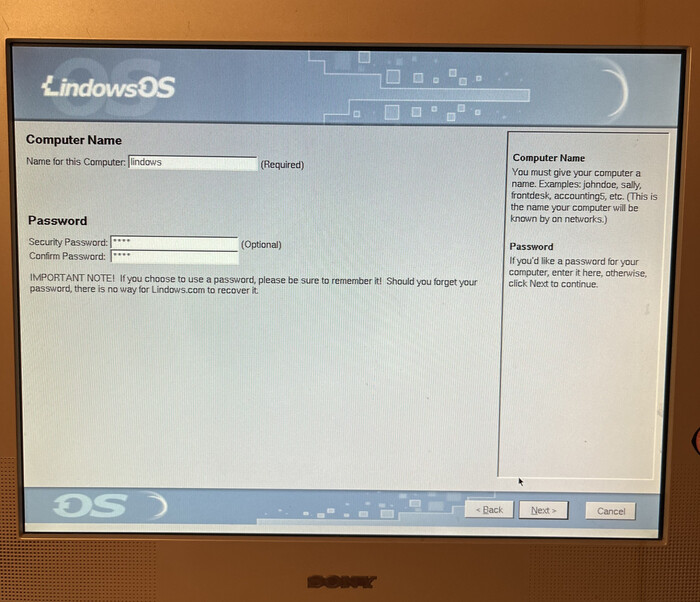
Присвоение имени компьютера и пароля
И установка на жесткий диск без его разбиения и реструктуризации
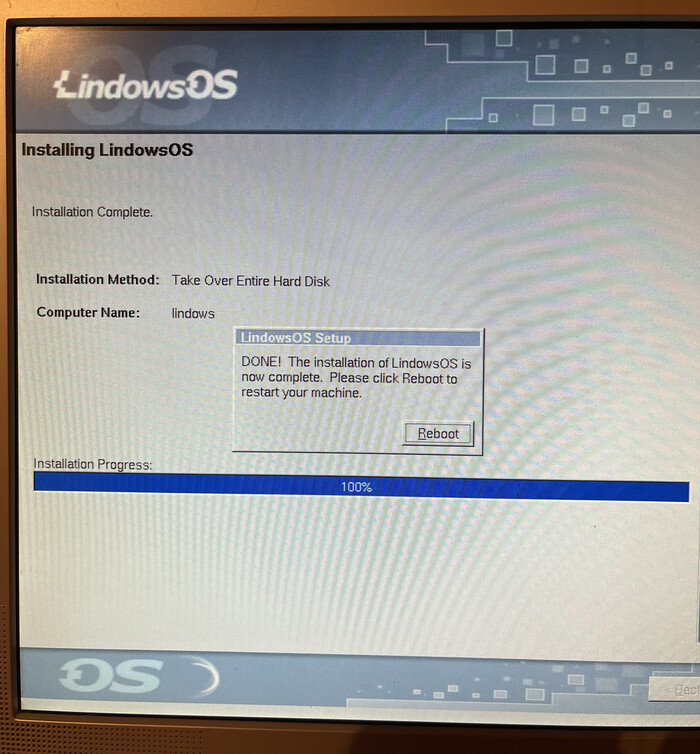
Инсталляция операционной системы завершается следующим сообщением и предложением перезагрузить компьютер.
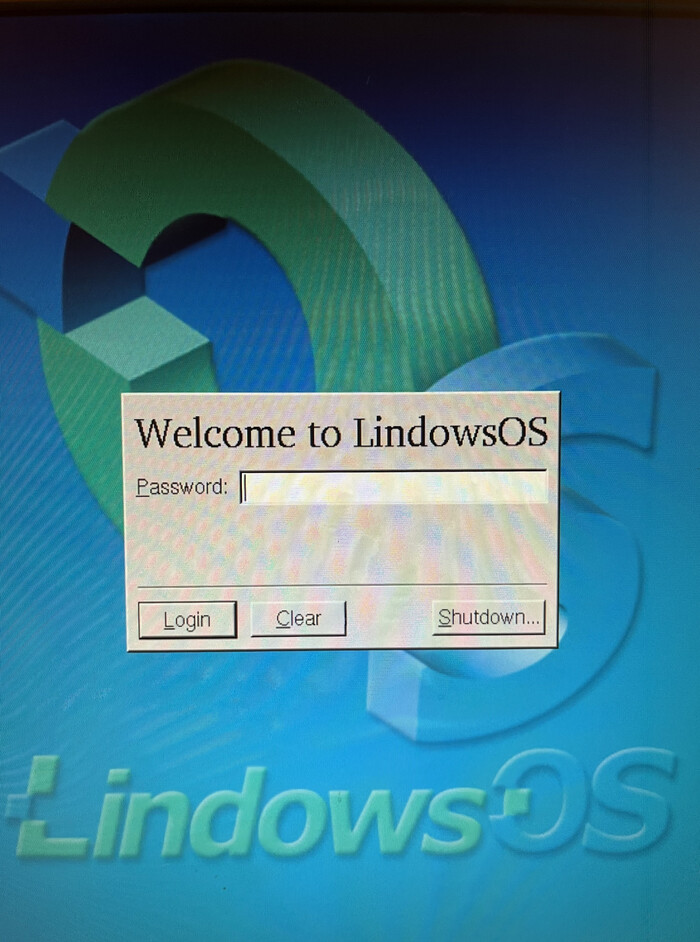
После перезагрузки мы видим окно авторизации пользователя.
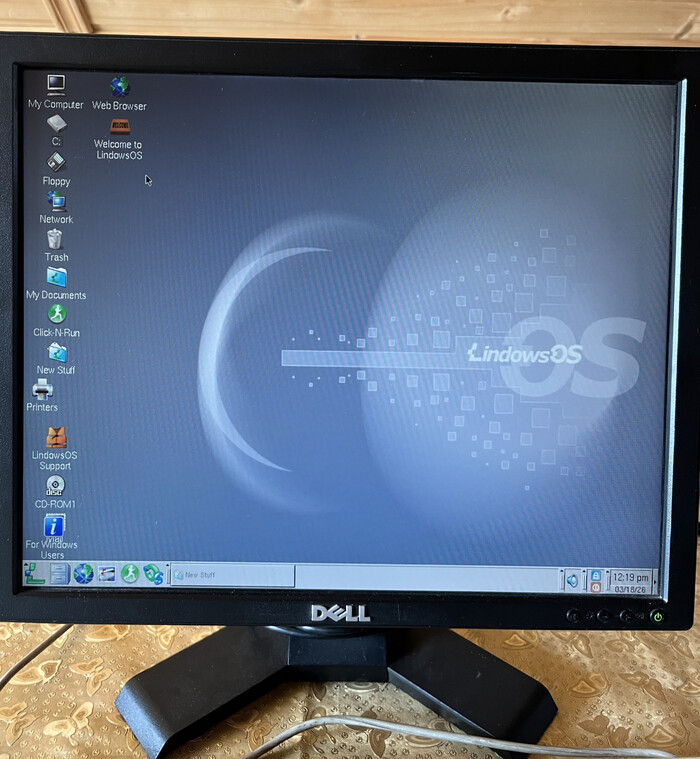
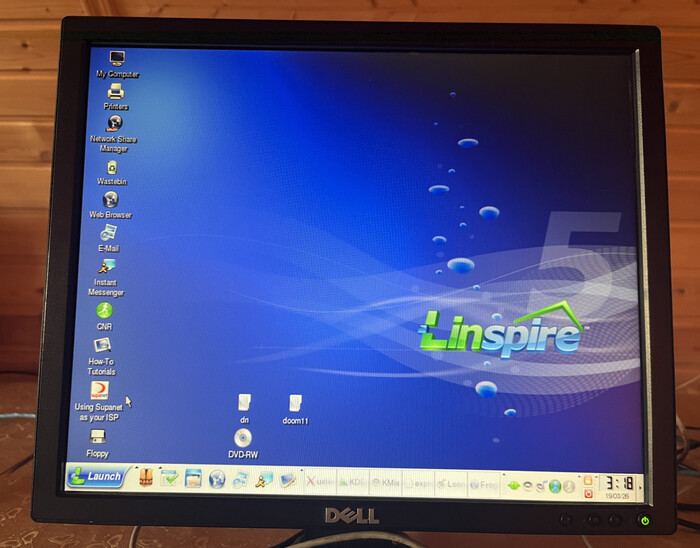
Заходим на рабочий стол и видим интерфейс в стиле Windows 95. По мере написания статьи монитор, отображающий целевую операционную систему, менялся.
Теперь определимся, что за окружение перед нами и куда мы попали.
Кто у нас пользователь по умолчанию? Ни много ни мало, а сам root. А в чём вишенка на торте? В том, что root — священная корова Unix-like систем — по умолчанию вообще без пароля. Найдёте ещё такую систему? Примечательно, ничего не скажешь. Две громадные дыры в безопасности.
Посмотрим версию Debian. Кодовое название версии 3.0 — Woody.
Woody
Графическая среда KDE 3.0.
Файловая система, на которую установилась Lindows — ReiserFS.
Любопытно выглядит файловая структура Windows в корне ReiserFS.
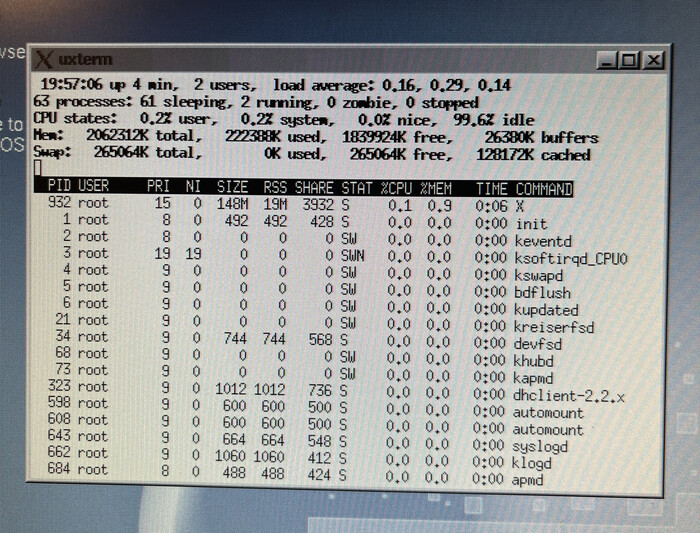
Процессы запущенные после установки.
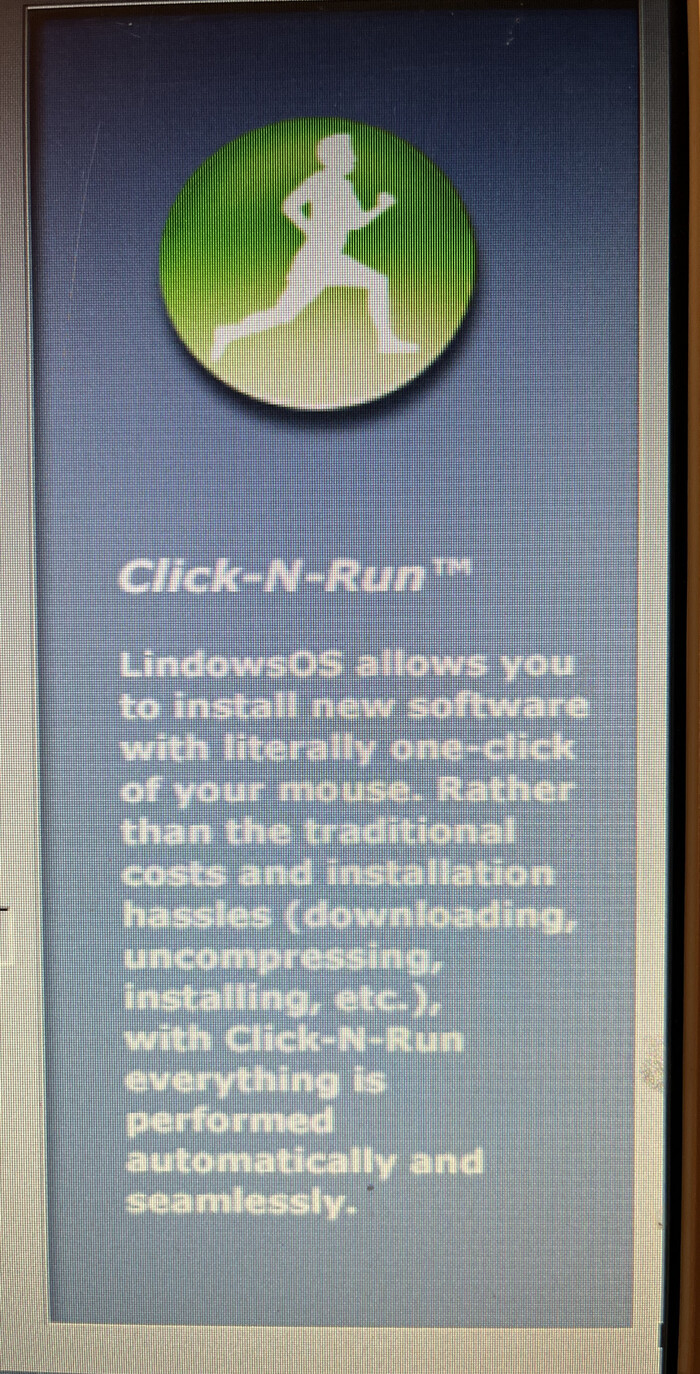
Мы определились с внешностью Lindows, а теперь самое главное — в процессе инсталляции на экране было описание технологии Click-n-Run Warehause (далее CNR).
По сути, технология CNR — это инструмент запуска приложений из собственного магазина компании. Упор сделан на запуск программного обеспечения с открытым программным кодом, но не бесплатно. Подписка, позволяющая осуществить запуск из магазина приложений, оценивалась в $49,95 в год. Данная цифра — плата за удобство запуска Linux-приложений одним щелчком мыши. Да, кстати, не только Linux, но и Windows-приложений. Но обо всём по порядку.
После установки Lindows установленная операционная система почти чиста. Она содержит лишь пустые ярлычки, ведущие на приложения, которые можно загрузить с сайта компании, предварительно оплатив подписку. Приведу короткий видеообзор, навигацию по меню — так будет нагляднее.
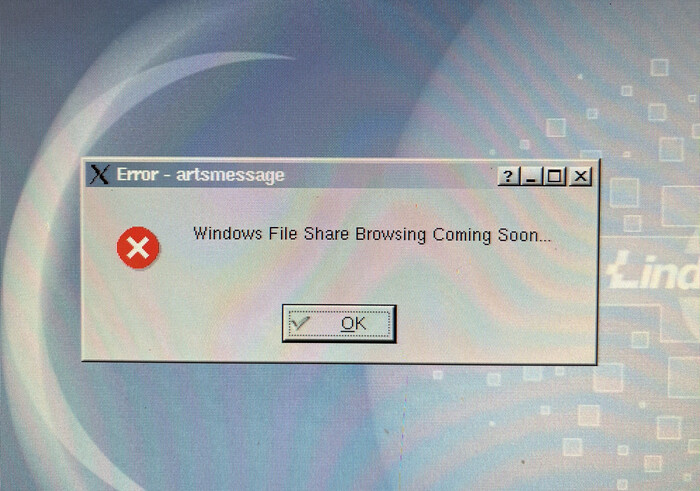
Вот так выглядит запуск «Сетевого окружения». Думаю, планировался недоинтегрированный SAMBA-механизм при помощи SMB/CIFS-протокола работы в сети, включающей в себя Windows-машины.
Ожидается...
Мы видим операционную систему без наполнения. На текущий момент времени крутое доменное имя «Lindows.com» продаётся. Для нас это означает, что воспользоваться штатным механизмом запуска приложений, предназначенным создателями, невозможно.
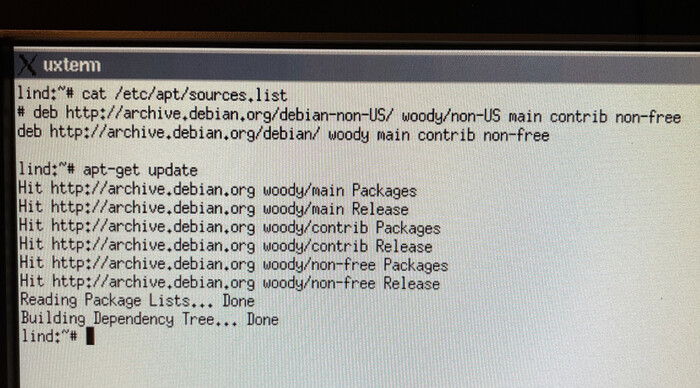
Поэтому мы вспоминаем, на чем построена наша система и пробуем воспользоваться давно устаревшим репозиторием.
Прописываем действующий архивный репозиторий и обновляем его.
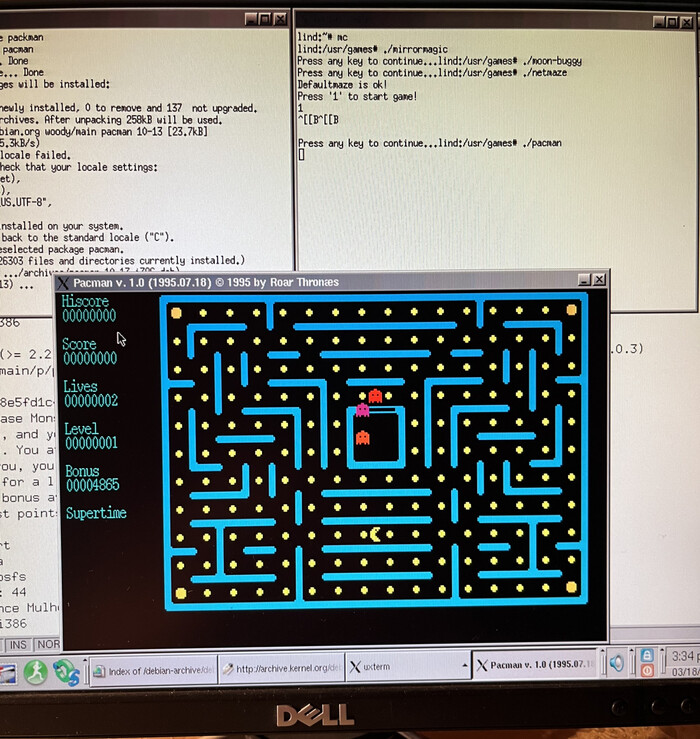
Поставим несколько игрушек, чтобы убедиться, что все ставится и работает. Вот Pacman.
Pacman
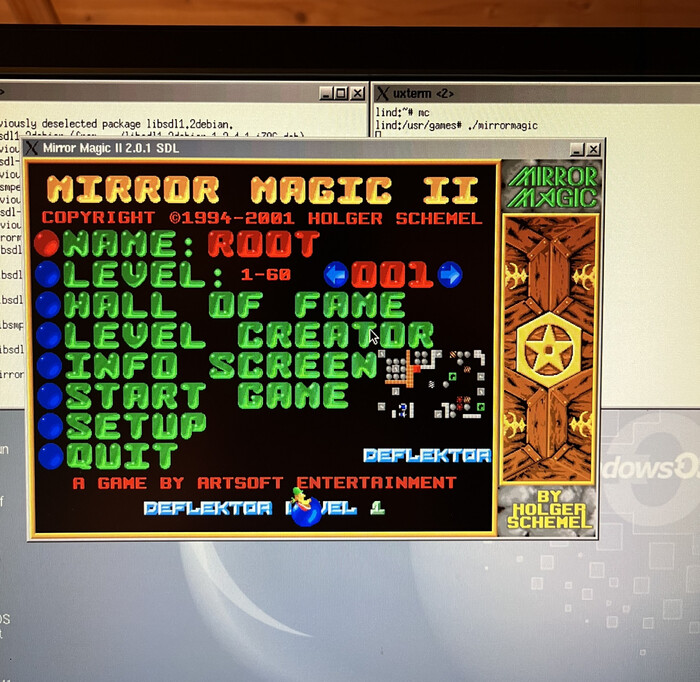
А вот Mirror magic 2.
Запустим Sabre — самолётик, но только криво он у меня запустился. Экран раздвоило, ну да пусть. Смысл в факте запуска, а играть я не собирался. С другой стороны, это говорит о качестве всего: ну не должно такого быть, чтобы так разнесло экран.
Остаётся открытым вопрос: а что же с самым интересным — запуском Windows-приложений? Механизм данного запуска планировался при помощи Wine. Wine — это акроним «Wine Is Not an Emulator», как подчёркивают авторы проекта. Пройдя поиском по всей системе, я не обнаружил и следов Wine. Вот незадача…
Какой напрашивается вывод? В чём основная «фишка» операционной системы? Мне, пользователю, хотелось бы одним щелчком мыши запустить Windows-приложение или хотя бы MS-DOS-программу. Получается, прежде всего я должен установить инструментарий, позволяющий это сделать? А как же обещанное «из коробки»? В чём тогда отличие от других дистрибутивов Linux, так громко не заявляющих о полноценной совместимости? Везде можно установить Wine и быть довольным результатом.
Вот тут-то и пришло прозрение, что гениальность этой операционной системы — только в названии. Предполагаю, что истинная цель — это успешная попытка использовать уже раскрученное имя Windows с небольшим изменением. Как мы видим, обернулось всё это выгодной продажей проекта. Так действуют киберсквоттеры — пираты в сфере доменных имён. Несмотря на очевидное созвучие с оригинальной Windows, такая корпорация, как Microsoft, не смогла справиться простым судебным решением. Здесь был размах глобальнее, и оно сработало: просуществовало как-никак 7 лет, правда сменив имя на LinspireOS.
Упомянув LinspireOS, предлагаю вкратце глянуть на скрины этой операционной системы.
Так выглядит рабочий стол.
Браузер открывает http-ресурсы.
С русским языком всё в порядке — «квакозяблы» отсутствуют. Совсем неплохо.
Напоследок — неразлучная пара канонических любимых игр, подтверждающих, что рассмотренные операционные системы вполне пригодны и не бесполезны. Куда без него, без DOOM'а разумеется?
Ну и достойный крутой последователь — Quake2
В конечном итоге Microsoft приняла гениальное решение «в лоб» — покупка наименования LindowsOS, впоследствии ставшего LinspireOS. Проблема решена навсегда.
Здесь неплохая детальная хронология разбирательств и судебных тяжб.
А здесь подобная информация по вышеописанной тематике.
Что скажете? Цель создания данной операционной системы для производителя, на мой взгляд, вполне достигнута. Среди уважаемых читателей есть тот, кто успел попользоваться сервисом этой операционной системы? Как оно вам? Любопытно услышать мнение. Пишите, пожалуйста, что считаете по этому вопросу!
Наверняка многие из вас, кто изучал в университете «Архитектуру ЭВМ» или системное программирование, сталкивались с архитектурой PDP-11. Эта машина стала настоящей классикой: её элегантная система команд и ортогональные методы адресации стали основой для обучения целых поколений программистов.
Однако софта для эмуляции PDP-11, который был бы удобным, современным и работал "из коробки" на современных ОС, критически не хватает. Часто это консольные утилиты из 90-х или софт, требующий бубнов при установке.
Поэтому я решил написать свой собственный эмулятор PDP-11 — с графическим интерфейсом, интерактивной памятью, виртуальной периферией и встроенным справочником.
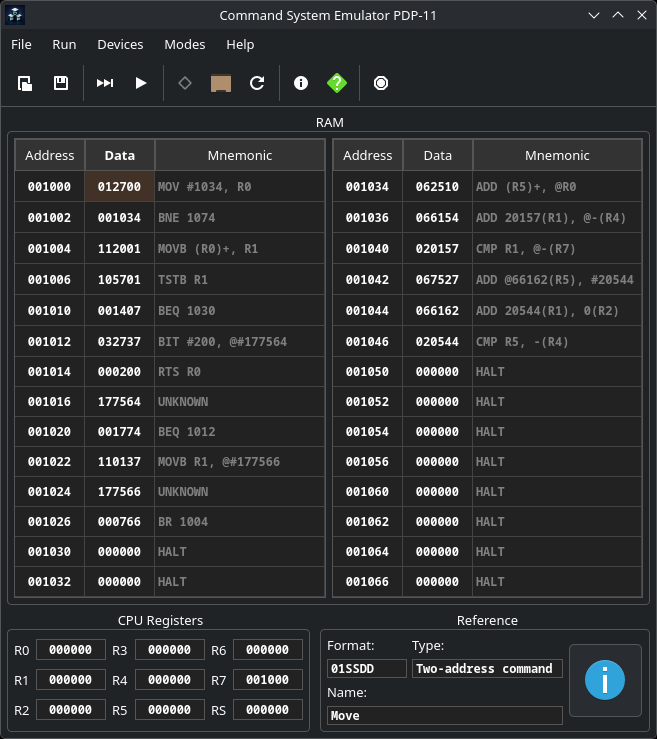
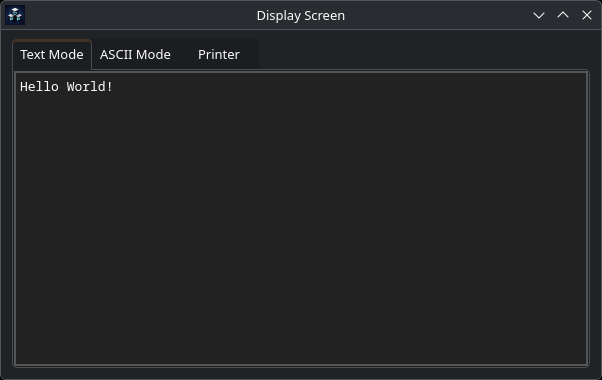
Главное окно эмулятора: таблица оперативной памяти с мгновенным дизассемблером (загружена программа Hello World), панель регистров процессора и интерактивный контекстный справочник.
Что под капотом?
Эмулятор написан на C++17 с использованием фреймворка Qt6. Я ставил перед собой цель сделать не просто «выполнялку» кода, а именно наглядный инструмент для студентов и энтузиастов, чтобы каждый такт процессора был понятен.
Что умеет эмулятор на данный момент:
Интерактивная память и дизассемблер "на лету" Сердце интерфейса — таблица оперативной памяти. Как только вы вводите восьмеричный код в ячейку (например, 005203), эмулятор мгновенно дизассемблирует его и показывает мнемонику — INC R3. И наоборот, ошиблись цифрой — увидите UNKNOWN или другую команду. Это невероятно ускоряет процесс понимания машинного кода.
Полный набор регистров и флаги PSW Внизу окна всегда видны состояния регистров R0-R7 и слово состояния процессора (PSW). При пошаговом выполнении (Step Mode) можно наблюдать, как меняются флаги N, Z, V, C в зависимости от результатов арифметики.
Memory-Mapped I/O (Внешние устройства) Какая же ЭВМ без периферии? Я реализовал виртуальные устройства, отображаемые на память по классическим адресам PDP-11:
Дисплей терминала (регистры TPS 177564 и TPB 177566)
Клавиатура (регистры TKS 177560 и TKB 177562)
Принтер (регистры 177514 и 177516)
Виртуальный терминал, работающий через классический Memory-Mapped I/O. Процессор посимвольно вывел строку в регистр данных дисплея по адресу 177566.
Аппаратные прерывания и таймер
Отдельная гордость — это честная реализация работы с прерываниями. Это не просто скрипт, который выполняет команды по списку. Процессор умеет:
Обрабатывать команду WAIT (переход в режим энергосбережения).
Генерировать аппаратные прерывания. Например, встроенный таймер дергает вектор 100(8) каждые 100 мс.
В комплекте с эмулятором идет программа «Stopwatch» (Секундомер). Она показывает, как можно отсчитывать реальные секунды в регистре R0, перехватывая тики таймера и отправляя процессор в спячку (WAIT) между ними. Всё как в настоящем железе!
Сборка и DevOps (чтобы работало у всех)
Как разработчик, я ненавижу, когда для запуска опенсорс-проекта нужно потратить полдня на настройку окружения. Поэтому я заморочился с инфраструктурой:
Для Windows: Написан "умный" скрипт compile.bat. Вы просто запускаете его на чистой Windows. Скрипт сам скачает MSYS2, установит нужный GCC toolchain, подтянет статическую версию Qt6 и соберет независимый PDP11.exe весом в пару десятков мегабайт (без необходимости таскать за собой гору .dll).
Для Linux (Arch/Manjaro): Написан скрипт setup_package.sh, который на лету генерирует PKGBUILD, ресайзит иконки через ImageMagick, создает .desktop файл и устанавливает эмулятор как полноценный нативный пакет в систему.
Кросс-компиляция: Поддерживается сборка Windows .exe файла прямо из-под Linux через MinGW.
Примеры программ
Чтобы пользователям не пришлось начинать с чистого листа, я подготовил библиотеку дампов .pdp, которые идут в комплекте:
Hello World — классика с циклом и проверкой флага готовности дисплея.
Keyboard — программа эхо-ввода (выводит на экран то, что набирается на клавиатуре).
16-bit Integer Calculator — полноценный калькулятор (+, -, *, /) с программной реализацией алгоритмов умножения и деления (которых нет в базовой архитектуре PDP-11) и конвертацией бинарного результата в ASCII-строку для вывода на экран.
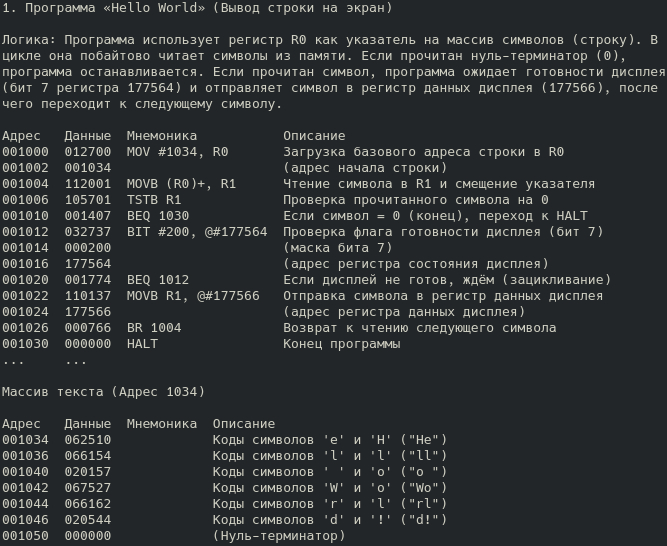
Но просто выложить код — это полдела. Поскольку проект задумывался как образовательный, я уделил огромное внимание документации. Каждая программа из примеров разобрана буквально по строчкам: с указанием адресов, машинных кодов, мнемоник и подробным описанием логики.
Фрагмент документации: пошаговый разбор логики работы и дамп памяти для программы «Hello World».
Кроме того, в репозиторий вшита подробнейшая документация по самой архитектуре PDP-11. Я перевел классические справочники из старых PDF-файлов в современный, аккуратно сверстанный Markdown (с поддержкой Obsidian-ссылок).
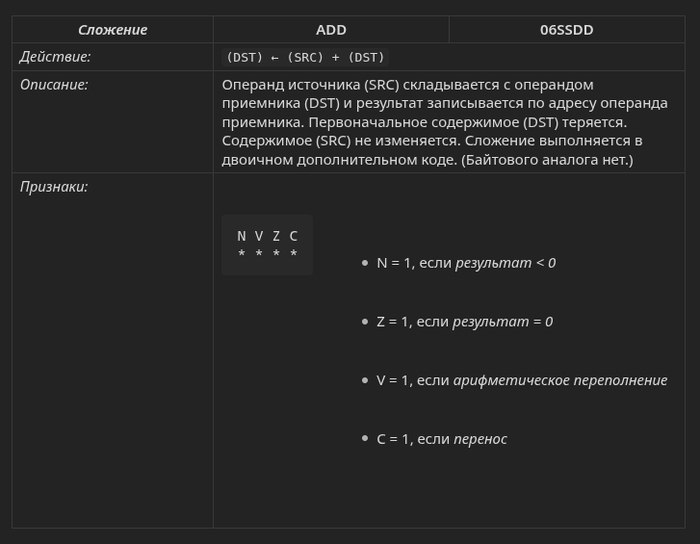
В нем расписана работа каждой машинной инструкции, особенности адресации и, самое главное для написания эмуляторов — точное влияние каждой команды на флаги регистра состояния (N V Z C).
Пример страницы из справочника: описание работы команды сложения и её влияния на регистр состояния процессора (PSW).
Итоги и планы
Проект полностью открытый, распространяется под свободной лицензией MIT и доступен на GitHub. Если вы преподаете архитектуру ЭВМ или просто хотите поностальгировать по временам, когда программы писались на машинном коде — заходите, пробуйте, делитесь идеями!
Что можно улучшить в будущем:
Внедрить поддержку макроассемблера (чтобы можно было писать код текстом, а не только вводить восьмеричные числа).
Puppet - мой основной рабочий инструмент. Сейчас он обслуживает нашу офисную и торговую сеть, а это более 9000 хостов на Linux под самые разные нужды. На русском языке актуальных материалов по нему практически нет, поэтому я взялся за англоязычную «Puppet 8 for DevOps Engineers». Читалось не быстро, но, как говорится, дорогу осилит идущий.
И книга оказалась просто 10 из 10.
Больше всего понравилось, что это не просто сборник синтаксиса и примеров, а разбор Puppet как полноценного инженерного инструмента.
Что внутри:
Сначала автор рассказывает историю создания Puppet и задачи, ради которых он создавался. Потом переходит к философии: почему он устроен именно так, как работает декларативный подход, зачем нужна идемпотентность и почему это важно для управления инфраструктурой.
Большой блок посвящён коду. Код описан через примеры и советы, но так же описаны типовые ошибки, подводные камни и наследие старых версий, которое всё ещё можно встретить в живых инфраструктурах, но лучше заменить.
Отдельно понравилось, что есть главы про архитектуру использования Puppet, серверную часть, конфигурирование, тонкую настройку, логирование, мониторинг и эксплуатацию. То есть это не только книга для тех, кто пишет Puppet-код, но и для тех, кто потом будет держать всю эту систему в работоспособном состоянии.
Последняя небольшая часть посвящена сравнению с платной версией. Автор честно говорит, что многие возможности можно собрать и в бесплатной версии, если готовы вложить время и поддерживать всё самостоятельно.
Так же в этих главах становится понятно что автор не просто пользуется Puppet, а является частью его команды разработки. Отсюда и такой уровень погружения в разные аспекты инструмента.
По итогу:
Книга оказалась полезной со всех сторон: и для написания нормального Puppet-кода, и для понимания архитектуры, и для эксплуатации серверов Puppet в реальной инфраструктуре.
Хочется, чтобы по другим DevOps-инструментам чаще попадались книги такого уровня.
Есть, правда, грустный контекст: Puppet 8 стал последней open source-веткой. После изменений со стороны Perforce новые пакеты и бинарные сборки Puppet начали уходить в закрытую модель распространения. Сообщество в ответ развивает форк OpenVox. По командам, структуре и общей логике он во многом продолжает привычный Puppet-подход, так что история инструмента, похоже, не закончилась.
О видео обычно говорят просто: "ну подключили камеры, и все". На практике именно видео чаще всего и начинает ломаться первым, когда система сталкивается с реальной нагрузкой.
С видеонаблюдением часто повторяется одна и та же история: на первом запуске или «на показе» всё красиво, а под реальной нагрузкой начинаются «черные плитки», таймауты, реконнекты и странные просадки.
У меня это тоже было — и это нормально: под нагрузкой впервые видно, где слабые места. Дальше текст не «из методички»: конспект того, что уже раз пришлось пройти руками — смотреть `top`, логи трансляции, поменять одну вещь и снова проверить, ушёл ли симптом.
Локальный стенд: VirtualBox и «всё сразу»
Домашний стенд на ПК — VirtualBox.
Сервер в рабочей сети — через него идёт работа с датчиками, камерами и остальным нужным оборудованием. У меня он тоже стоял в VirtualBox: 6 виртуальных ядер, 6 ГБ оперативной памяти, под систему и приложения 25 ГБ диска, отдельно 50 ГБ под видеоархив.
Одновременно все камеры в полном качестве, постоянная запись архива, движение и просмотр по архиву и много окон live для такой конфигурации — слишком плотный пакет: процессор и диск быстро упираются в потолок, отклик «плавает», кажется, что «сломалось всё». На стенде в «жаркие» минуты служба трансляции (go2rtc) в `top` доходила примерно до ~250–350% CPU — это сумма по ядрам, не «одна строка = одно ядро»; при таких цифрах на VM с шестью ядрами сразу видно, почему «всё и сразу» без компромиссов не взлетит.
По отдельности обычно спокойнее: одна камера крупно, или только сетка с облегчёнными превью, или только архив. Выделение отдельного физического сервера на объекте пока не удалось согласовать с руководством — поэтому остаётся тестовая VM с жёсткими лимитами. На нормальном серверном железе ту же схему разумно ожидать заметно ровнее, с большим запасом под «всё сразу».
Что перебирали, пока остановились на текущем варианте
Ниже не «история коммитов», а смысл: сколько разных рычагов пришлось пощупать, пока картинка и нагрузка не сошлись в рабочий баланс. Порядок в жизни мог быть любой — важнее, что почти никогда не хватало одной правки.
Полноценный поток на каждую плитку в сетке — слишком тяжело для сервера и сети при одновременном открытии; пришлось уйти к более лёгкому потоку в сетке, а «как в мониторе» — только для одной выбранной камеры (крупный просмотр).
Несколько тяжёлых вариантов встраивания видео в браузере сразу — давали всплеск нагрузки и на клиенте, и на сервере; схему показа и запасные режимы пришлось упростить.
Запасной кадр, если с камеры временно ничего не приходит — чтобы оператор не смотрел в пустой чёрный прямоугольник (в том числе на стенде без настроенной трансляции).
Нестабильные камеры — перевод на запасной канал с меньшей нагрузкой (типичный субпоток с регистратора), подбор параметров «картинка vs стабильность» на проблемных точках.
Повторные подключения из‑за обрывов по сети — убирал лишние «хвосты» подписок, следил, чтобы не копились фоновые процессы записи после перезапуска сервера.
Баланс по ядрам — когда сеть и трансляция грузят систему, без нормального распределения прерываний узел может «косить» под одним ядром сильнее остальных. Сервер на объекте у меня тоже на VM — не домашний ноутбук, но всё равно виртуалка, не выделенное железо в стойке. После включения балансировки IRQ (`irqbalance` в Ubuntu) в одном спокойном срезе простой CPU вырос примерно с ~41% до ~76%: не волшебство, просто меньше «залипаний» и перекоса, системе легче дышать.
В сумме это много мелких шагов с проверкой «до / после», а не одна правка. Итог — компромисс: не «идеальная картинка на каждой плитке всегда», а устойчивый просмотр в реальных условиях.
Что чаще всего ломает картинку
В работе чаще всего всплывали такие причины:
нестабильный сигнал с отдельных камер или регистратора;
частые переподключения;
перегруз сервера службой трансляции, когда много окон смотрят одновременно;
сеть и очереди пакетов (на узле с ограниченными ресурсами это особенно заметно).
Поэтому искать «один баг» почти всегда промах: чаще это связка камеры, сети, сервера и того, сколько окон открыто одновременно.
Как это чинили
Не «перезагрузил вкладку — и авось», а по делу:
проверка потоков по камерам;
уборка устаревших настроек трансляции;
запасные варианты для слабых мест;
контроль фоновых задач, которые держат нагрузку;
повторные замеры после каждой правки.
Именно так постепенно получилось убрать самые болезненные сценарии. Параллельно неплохо держать в порядке список потоков, запасные варианты для проблемных камер, зависшие просмотры и метрики до/после — иначе легко перепутать «кажется лучше» с реальным улучшением.
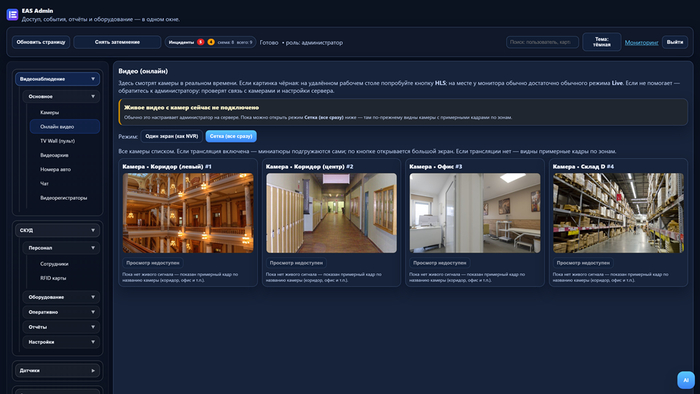
Онлайн видео: режим «Сетка (все сразу)»
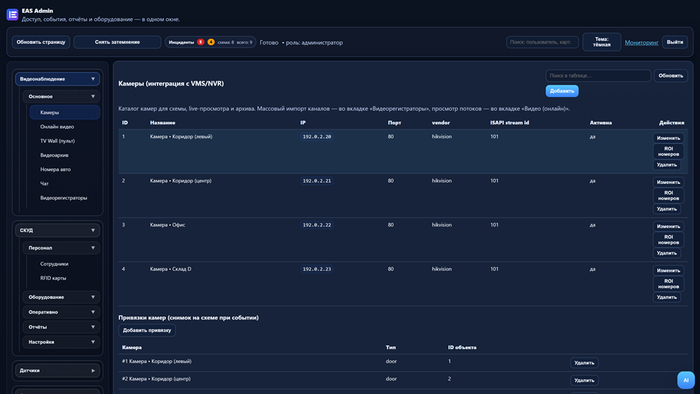
Каталог камер (IP, поток, запись в архив — через «Изменить») открывается отдельно — «Камеры» в том же разделе меню:
Каталог камер (настройка)
Список камер и кнопки «Изменить» / «Удалить»; живой просмотр — только во вкладке «Онлайн видео».
Ещё есть вкладка «Видеорегистраторы». Она нужна, чтобы не заводить каждую камеру отдельно по IP: подключаешь к EAS уже стоящий в сети регистратор и подтягиваешь с него каналы в каталог камер — так проще, когда камер много и они уже сидят на NVR. Но по опыту важно знать другое: когда сигнал идёт через регистратор, тот часто отдаёт не «полный» поток, а облегчённый (типичный субпоток для веба или телефона) — на экране это обычно выглядит заметно хуже, чем при прямой схеме «камера → сервер». Удобство массового импорта и качество картинки здесь часто меняются местами: адресов меньше, а «картинка как в кино» ждать не стоит, пока на стороне регистратора не настроят нормальный канал.
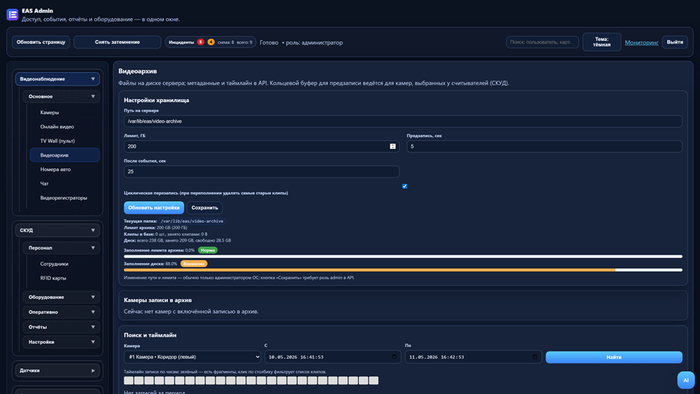
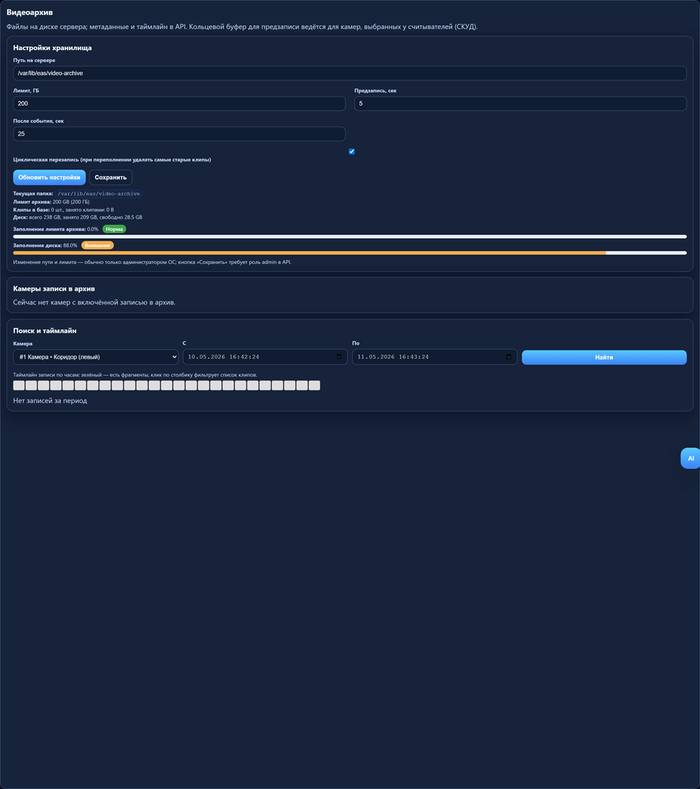
Видеоархив: поиск и таймлайн
Вкладка «Видеоархив»: выбор камеры и интервала, таймлайн и список клипов; что реально попало в архив, зависит от галочки «Записывать в архив» и режима записи по каждой камере.
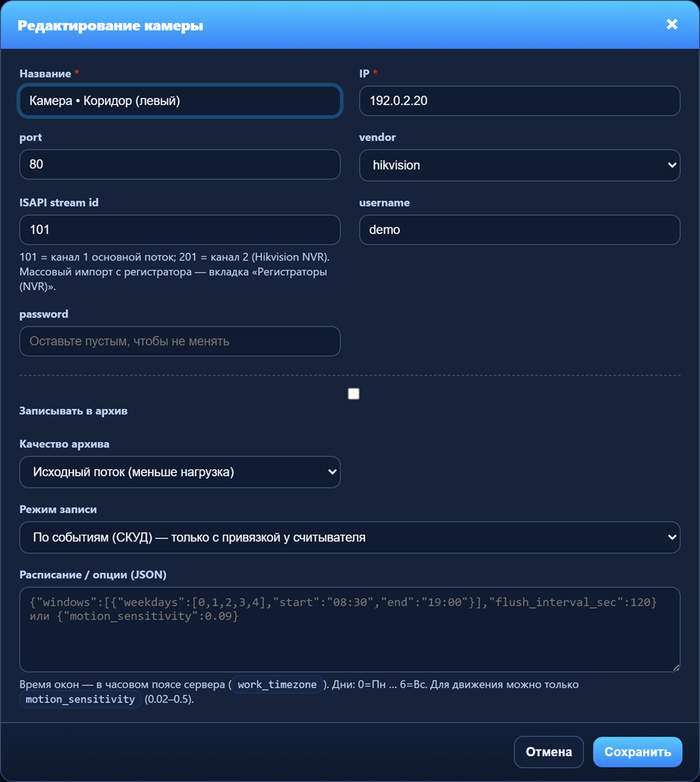
Какие камеры пишут в архив и куда складываются файлы
Писать не обязательно все камеры сразу — у каждой записи в каталоге (Админка → Камеры, кнопка «Изменить») есть галочка «Записывать в архив». Включил её только там, где запись реально нужна — остальные не грузят диск и CPU «про запас». Ниже по той же форме задаётся режим (по событиям СКУД, по расписанию, непрерывно и т.д.) и качество — это уже про баланс «сколько крутим ffmpeg» против «сколько храним».
Камера: «Записывать в архив» и режим записи
Форма редактирования камеры: запись в архив включается отдельно для каждой камеры.
Каталог, куда складываются клипы, задаётся во вкладке «Видеоархив», блок «Настройки хранилища» — поле «Путь на сервере». Это любой каталог, который видит Linux на машине EAS: можно взять локальный диск или каталог на отдельном томе, а можно указать путь к уже смонтированной сетевой шаре (SMB/CIFS, NFS и т.п.) — если администратор ОС смонтировал ресурс, например, в `/mnt/video-archive`, то в поле пишем именно его
Лимит, ГБ — сколько места отводим под архив по сумме клипов в учёте. Циклическая перезапись: если включена, при переполнении лимита система удаляет самые старые записи, пока объём снова не укладывается в квоту — диск не раздувается бесконечно. Если цикл выключить и лимит исчерпан, новые фрагменты могут не записаться (в логах будет предупреждение) — тогда либо поднимают лимит, либо чистят архив вручную. «Предзапись» и «После события, сек» — сколько секунд «до» и «после» тянуть вокруг срабатывания СКУД по считывателям, чтобы в клип попал нужный хвост, а не одна секунда события.
Видеоархив: путь хранилища и квота
На скрине: путь на сервере, лимит в гигабайтах, предзапись/хвост после события, циклическая перезапись.
Почему "все камеры сразу" - это испытание
Когда в сетке много камер, растут нагрузка на обработку потоков, сеть и параллельные просмотры. Слабое место всплывёт: дёргается картинка, тёмные плитки, задержка, рост нагрузки на сервер. Тут помогает не «ещё одна вкладка», а замерить, урезать лишнее или разнести нагрузку — иначе снова те же цифры в `top`.
Архив и расследование
Видеоархив в EAS — не «просто склад»: по нему возвращают момент события, сверяют время и подтверждают выводы после инцидента; вместе со схемой и событиями он помогает снять спор («когда это было», «что повторяется»). Удобно, когда архив открывается из того же экрана, где вы уже смотрите проблему — не нужно «перескакивать» в другую вселенную.
Видео на объекте: нагрузка и проверки
Камера может быть «вроде рабочая», а при нескольких потоках или полной сетке давать задержки и обрывы. Смотрю не на разовый «успешный показ», а на устойчивость в повторяемом режиме. Проверка у меня простая: симптомы → одно понятное действие → снова те же условия — иначе шаг за успех не считаю.
В двух словах
Если совсем коротко: стабильное live — это не галочка в настройках, а привычка смотреть нагрузку и не обманываться. Мониторинг, сетка потоков, запасные сценарии, проверка после каждой правки — и учёт реальных ресурсов (например VM на тесте: 6 CPU, 6 ГБ ОЗУ, 25 ГБ под систему и приложения, 50 ГБ под архив). «Всё сразу» от узла, который уже честно показал сотни процентов CPU в `top`, лучше не ждать — тогда картинка перестаёт «сыпаться», а архив остаётся рабочим инструментом разбора.
Далее — датчики: как сделать так, чтобы они не просто «рисовали цифры», а помогали видеть риск и принимать решение вовремя.