Полгода назад я пришёл в новую организацию, и мне достался парк машин. Десяток на Windows, несколько маков, пачка линуксовых ноутов у разработчиков. Невыносимым было другое. Навешанные до меня политики и блокировки со стороны ИБ связывали руки так, что здраво администрировать домен было попросту нельзя: любое рутинное действие упиралось в чужие ограничения. Тогда я и полез искать решение, которое помогло бы мне нормально админить этот парк.
Готового, что легло бы на мою ситуацию, я так и не нашёл — и в итоге сел писать своё. Ниже — разбор инженерных решений, которые по дороге пришлось принять, и карта того, где у этой конструкции проходит настоящая граница безопасности. Последнее для меня важнее всей остальной механики: MDM по определению даёт слишком много власти над чужими машинами, и делать вид, что это не так, я не стал. Поэтому архитектуру ниже я описываю как ответ на вопрос «где это ломается».
Откуда взялась задача
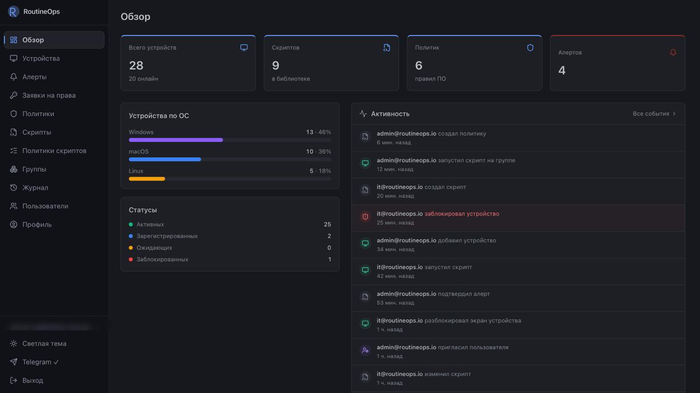
Требований у меня было немного, но именно они всё и отсеяли: сервер должен стоять у меня, телеметрия парка не утекать на сторону, и всё это работать на смешанном парке сразу. Self-hosted-вариантов под такое оказалось немного, и те, что были, спотыкались об одно и то же: либо только маки, либо платные и при этом недоступны в России, либо разваливались на простом вопросе — а что с устройством, если агент две недели просидел офлайн. Ближе всего в этом поиске подобрался Fleet — серьёзный открытый проект, к нему я ещё вернусь ниже. Но развернуть его у себя оказалось тем ещё квестом: я в России, а fleetdm на российский IP не але, так что и сервер, и сборку агентов приходилось поднимать через VPN. Вдобавок агент на macOS в моём случае вставал через раз, а то и вовсе не ставился. Инструмент, который в итоге получился, я назвал RoutineOps; дальше по тексту буду говорить «агент», «сервер» и «панель».
Ещё одно соображение, которое я держал в голове: базовую защиту управляющего канала — mTLS, аудит, вменяемую политику паролей, подпись обновлений — я считаю БАЗОЙ, и держать её за пейволлом мне казалось неправильным. Это моё мнение, не претензия к рынку. Проект в итоге открыт под Apache-2.0; платный уровень существует, но вся базовая защита — в открытой части, и это не тема статьи.
Почему постоянный gRPC/mTLS-канал, а не опрос через VPN
Вечная головная боль: как дотянуться до ноутбука, который сейчас сидит в кафе за чужим NAT. Классических ответов два, и оба мне не понравились. Загнать всех в VPN — это лишняя инфраструктура и ещё одна точка отказа. Сделать агент, который раз в N минут дёргает HTTP-эндпоинт «не прилетело ли чего», — это шторм пустых запросов, а задержка команд упирается в период опроса.
Я пошёл третьим путём. Агент — Go-бинарь, который держит постоянный gRPC-стрим поверх mTLS наружу, по обычному интернету. Соединение инициирует сам агент: оно исходящее, а значит дружит с NAT. По этому же двунаправленному стриму сервер в любой момент проталкивает команду — запусти скрипт, заблокируй экран. Задержка доставки тут — это задержка сети, а не интервал, на который выставлен опрос.
Стек намеренно скучный — скучное не будит меня в три ночи.
Агент и сервер — Go, сервер монолитом, без зоопарка микросервисов.
Связь — gRPC + Protocol Buffers поверх mTLS: TLS 1.3, приватный CA с пиннингом на всём канале агентов.
База — PostgreSQL 16, источник правды.
Очередь задач — Redis + Asynq, с ретраями.
Веб-интерфейс — React + TypeScript (Vite), раздаётся nginx-контейнером.
Развёртывание — Docker Compose.
Порты минимальны: 443 — веб-интерфейс, REST API, enroll, отдача бинарей; 50051 — постоянный gRPC-канал агентов. Postgres и Redis наружу не торчат вообще. На парк до 50 устройств хватает 1 vCPU / 2 GB RAM / 20 GB SSD — и это стартовая планка. Heartbeat дешёвый, инвентарь редкий, поэтому один узел спокойно тянет тысячи устройств: предел задаёт железо машины, не архитектура.
Сертификат — это идентичность, и всё
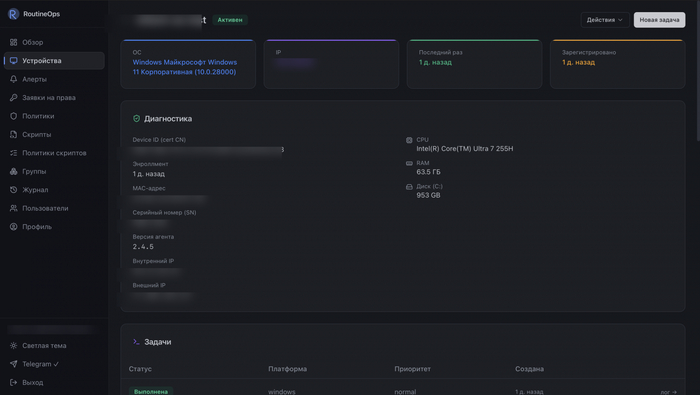
Самый важный архитектурный вопрос: как агент доказывает, что он именно то устройство, за которое себя выдаёт. Ответ короткий. device_id — это CN клиентского сертификата, и только он. Идентификаторам в теле сообщений сервер не верит вообще. Прилетел heartbeat, а внутри указан чужой device_id? Игнорируется. Значение имеет одно — чем подписан TLS-хендшейк.
Отсюда и enrollment, устроенный так, чтобы приватный ключ устройства никогда не покидал устройство:
Админ в панели заводит устройство и получает одноразовый токен: TTL 24 часа, single-use, гонка при погашении закрыта на уровне БД.
Агент локально генерирует пару ключей и отправляет CSR на POST /api/v1/enroll.
Сервер подписывает сертификат своим приватным CA и сам проставляет CN. Повлиять на свой CN агент не может.
Подделать чужое устройство без его ключа не выйдет — и не потому, что «мы проверяем поля», а потому, что проверять тут в принципе нечего. Криптография здесь вырезает целый класс авторизационной логики. Решение нравится мне тем, что после него кода становится меньше.
Heartbeat и инвентаризация разведены нарочно
Наивно было бы слить всё в один поток: раз в минуту слать полный отчёт о железе и заодно сообщать, что жив. На парке это дорого и бессмысленно — список установленного софта не меняется каждые тридцать секунд. Поэтому потока два, независимых.
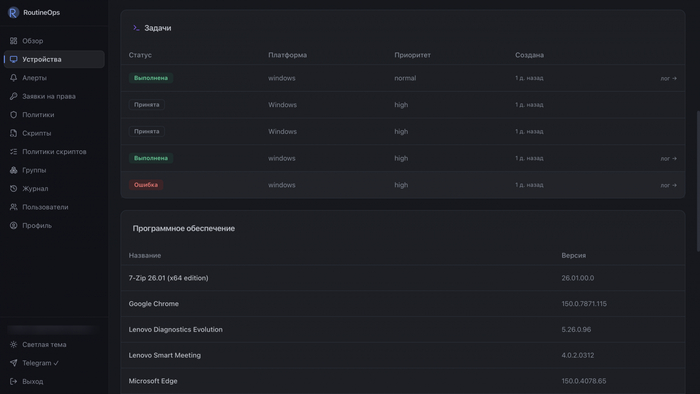
Heartbeat — лёгкий и частый, примерно раз в 30 секунд, по постоянному стриму; по нему же едут задачи. Дёшево, потому что данных в нём кот наплакал. Инвентаризация — тяжёлая и редкая, примерно раз в 5 минут: ОС, железо, серийник, установленное ПО (на Linux — из dpkg/rpm/pacman/apk), версия агента.
Такое разделение держит постоянный канал дешёвым при любом размере парка. Если устройство пропало с радаров и heartbeat не приходит дольше порога (порог настраивается через AGENT_UNREACHABLE_MINUTES) — поднимается алерт agent_unreachable, с подавлением дребезга от сна и modern standby, иначе каждый закрытый на ночь ноут спамил бы в Telegram Max :).
Результаты скриптов идемпотентны. У каждого запуска есть run_id, и повторная доставка дедуплицируется на сервере. Связь рвётся, ack теряется, агент шлёт результат заново — без этой механики ловил бы дубли, а на неидемпотентных командах ещё и двойное исполнение.
Агенту не нужна постоянная связь
Постоянный канал удобен, но агент не должен превращаться в кирпич, стоит серверу отвалиться. Cron-скрипт-политики крутит локальный планировщик прямо на устройстве: сервер лёг на обновление — политики по расписанию всё равно отработают.
Сложнее всего с блокировкой экрана. В офлайне полноэкранный overlay держится, а разблокировка идёт по локально хранимому bcrypt-хешу пароля — ходить за ней к серверу не нужно. Это осознанный компромисс: если бы разблокировка требовала сервер, любой обрыв связи превращал бы блокировку в невозможность войти в систему — а это уже хуже самой угрозы. Результаты и события тем временем копятся локально и досылаются, когда связь вернётся.
Временные админ-права — без поездки к машине
Бытовой, но постоянный сценарий: пользователю нужно поставить программу, которая требует прав администратора. Раньше это значило либо дойти до машины ногами, либо подключиться к ней удалённо и вбить админский пароль руками — и так на каждую установку.
Теперь пользователь запрашивает временные локальные админ-права прямо из трея агента, я одобряю заявку в панели — и он ставит нужное сам, а по истечении срока повышение снимается. Ни подходить к машине, ни поднимать удалённую сессию ради одной инсталляции не надо. Мелочь на фоне остальной механики, но именно из таких мелочей и складывалось то самое «здраво администрировать парк», ради которого всё и затевалось.
Fail-closed self-update и миграции
Самообновление — самый опасный канал из всех. Тот, кто им рулит, кладёт свой бинарь на все устройства как root. Поэтому здесь всё fail-closed. Примерно раз в 6 часов агент тянет манифест и проверяет sha256 и ed25519-подпись по полному манифесту: версия, ОС, архитектура, хеш подписаны одним набором сразу. Так нельзя подсунуть валидный бинарь под чужую версию или платформу. Дальше агент атомарно заменяет себя и перезапускается. Даунгрейд невозможен — есть anti-rollback floor: битый релиз чинится только версией вперёд, назад дороги нет. Приватный ключ подписи уникален для конкретной инсталляции; потеря не катастрофа — новый раздаётся через переэнролл.
На сервере тот же принцип. Схему накатывает отдельный migrate-сервис — до старта сервера. Не прошла миграция — сервер просто не поднимется на несовместимой схеме. Down-миграций нет, и это намеренно: откат — только из бэкапа, причём бэкап БД update.shснимает сам перед каждым обновлением. Пережить факап из снапшота я предпочту тому, чтобы полагаться на корректность down-скрипта, накатываемого поверх наполовину применённого состояния.
Модель доверия: god-mode by design
А вот тут льстить не буду — и это, пожалуй, самая важная часть текста. MDM по своей природе — это god-mode над парком. Скрипт-канал исполняет произвольный bash -c / powershell -Command как root/SYSTEM на каждом устройстве. Это не дыра, которую я забыл заткнуть. Это и есть продукт: весь смысл MDM в том, чтобы раскатать одну команду на сотню машин разом. А такой инструмент по определению — санкционированный RCE.
Подписи на скрипт-канале нет. И не будет. Ed25519-подпись защищает только канал самообновления — анти-тампер и анти-даунгрейд бинаря. Она никак не ограничивает то, что вы запускаете на устройствах. Тезис «скомпрометированный сервер не сможет выполнить код на парке» — неверное прочтение. Ещё как сможет: выполнение произвольного кода на парке — это его штатная функция.
JWT_SECRET (симметричный HS256) — единственный корень доверия панели. Кто прочитал этот секрет, тот печатает себе сколько угодно валидных admin-токенов. Не «подобрать пароль», не «обойти MFA» — просто сгенерировать подписанный токен и зайти админом.
Отсюда единственный вывод: реальный периметр безопасности — это хост, на котором крутится сервер. Не TLS, не RBAC, не аудит. Они важны, но вторичны. Увели сервер — увели весь парк.
Харденинг этого хоста — работа оператора, и в SECURITY.md под неё лежит чеклист: SSH только по ключам, наружу открыты только два порта, Postgres и Redis — на localhost, JWT_SECRET генерируется через openssl rand -base64 48 и лежит в режиме 600, панель — за VPN или IP-allowlist, аудит-лог — в append-only хранилище с алертом на появление новых админов.
Я специально не прячу этот раздел в мелкий шрифт. Любой MDM устроен ровно так же — просто не каждый проговаривает это вслух. Мне важно, чтобы человек ставил такой инструмент с открытыми глазами: в безопасности честность — это техническое свойство, а не тон голоса.
Что закрыто по умолчанию
Периметр — на операторе. Но всё, что можно закрыть кодом, закрыто по умолчанию, без единой галочки:
Не стартует на слабом секрете. Требует JWT_SECRET от 32 байт и минимум 16 различных байт. Случайно уехать в прод на changeme не получится.
Admin-JWT живёт 8 часов. Logout реально ревокирует токен через jti-блоклист. Смена или сброс пароля обнуляет все ранее выданные токены пользователя разом — через token-epoch.
Lockout по IP и по аккаунту, bcrypt cost 12. Форма входа не выдаёт, какие аккаунты вообще существуют.
Политика сложности пароля — для всех, включая seed-админа: от 8 символов, минимум 3 класса символов из 4. Даже первый администратор не заведётся с admin/admin.
RBAC на две роли — it_admin (всё) и viewer (только чтение), с проверкой на сервере. Viewer, дёрнувший мутирующий эндпоинт прямо из DevTools, упрётся в 403 ещё на сервере.
Плюс одноразовые enroll-токены, журнал аудита на каждое привилегированное действие (retention по умолчанию 365 дней), security-заголовки (HSTS/CSP/X-Frame-Options/nosniff), rate-limit и cap на размер запроса.
Ни одна из этих механик не спасёт скомпрометированный хост — см. раздел про модель доверия. Они закрывают то, что реально можно закрыть на уровне приложения, и не притворяются, что закрывают больше.
Честные ограничения
Раз обещал честность — вот граница, без прикрас.
Один узел — одна точка отказа. Для парка в режиме «поставил и работает» этого достаточно, но иллюзий про отказоустойчивость держать не стоит.
Нет SSO и MFA. Вход по паролю плюс RBAC. Пока разумно держать панель за VPN или allowlist.
macOS .pkg не подписан Apple. По двойному клику встретит Gatekeeper — ставится через installer из терминала.
Скрипт-канал — это RCE by design. Подробно — в разделе про модель доверия выше.
Про Fleet
Ближайший открытый аналог, который я смотрел, — Fleet, тоже open source, ядро под MIT. Инструмент серьёзный и зрелый, и во многом он сильнее моего: настоящий нативный MDM с профилями конфигурации и zero-touch-энроллментом, live-запросы osquery по всему парку, расчёт на масштаб в сотни тысяч машин. Построен вокруг osquery, инфраструктура — MySQL плюс Redis за балансировщиком, под горизонтальное масштабирование.
Под мой случай он просто не сошёлся по устройству. Чтобы реально управлять маками, Fleet опирается на нативный Apple MDM — а это APNs-сертификат от Apple с ежегодным продлением плюс Apple Business Manager для zero-touch. Мне не нужна была SQL-аналитика по всему парку; нужен был лёгкий агент, офлайн-лок без APNs, инвентарь и скрипты. А поверх этого архитектурного несовпадения легли те самые бытовые проблемы с развёртыванием из России и капризным macOS-агентом, о которых я писал в начале.
Чему это меня научило
Самое неожиданное в проекте — что львиная доля инженерных решений оказалась не про «как добавить», а про «как убрать». Идентичность через CN вырезала целый класс серверной авторизации; fail-closed на миграциях и обновлениях — ветки «а что если накатилось наполовину». Разведённые heartbeat и инвентарь сняли лишний трафик. А карта модели доверия избавила меня самого от иллюзии, будто TLS и RBAC — это и есть безопасность. Настоящий периметр оказался в одном месте — на хосте сервера.
Исходники я открыл под Apache-2.0; прямую ссылку на репозиторий оставлю тут :). Если вам будет интересно я бы с радостью пообщался по замечаниям именно по модели доверия — по местам, где приложение должно что-то enforce-ить, но не делает.