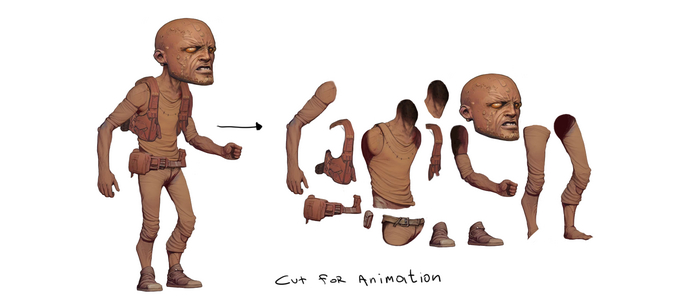Ну что, уже успели прочитать восхищения небывалым качеством видео от нейросетки SORA у всех блогеров и новостных изданий? А теперь мы вам расскажем то, о чем не написал никто: чего на самом деле пытается добиться OpenAI с помощью этой модели, как связана генерация видео с самоездящими машинами и AGI, а также при чем здесь культовая «Матрица».
Ложки нет, Нео! Точнее, есть – но, возможно, только на сгенерированном нейросетью видео...
Это гостевая статья от Игоря Котенкова — эксперта по нейронным сетям и моего постоянного соавтора по этой теме. Я же в данном случае только немного помог ему с редактурой (и без того, надо признать, прекрасно написанного текста). Короче, заварите себе чайку и приятного вам чтения!
В середине февраля в мире AI произошло много событий (1, 2, 3), но все они были затмлены демонстрацией новой модели OpenAI. На сей раз калифорнийская компания удивила всех качественным прорывом в области генерации видео по текстовому запросу (text-2-video). Пока другие исследователи старались довести количество пальцев на руках сгенерированных людей до пяти (а члены гильдии актёров противостояли им), в OpenAI решили замахнуться на короткие (до минуты), но высококачественные и детализированные ролики — и, чёрт возьми, у них получилось!
Кадры из сгенерированного семпла. Вы же читаете текст статьи, а не смотрите на девицу в красном, верно? (Кстати, всем рекомендуем перейти позалипать и на остальные материалы, предоставленные OpenAI: тык сюда и сюда.)
Немного контекста: о чем мы будем говорить
OpenAI — одни из немногих, кто умеет презентовать технологию так, что обычным пользователям, далёким от AI (Artificial Intelligence, или ИИ — искусственный интеллект), сразу становится ясно: дело серьёзное. Во многие релизы Google DeepMind или Facebook AI Research сложно вникнуть, а тут смотришь — и рот невольно открывается. Просто поглядите на проработанность деталей, на физику мира, на чёткость картинки! Каждый кадр в этом видеоряде — сгенерирован от и до, и нет никакой постобработки!
Те из вас, кто запрыгнул в поезд хайпа после релиза ChatGPT и начал следить за областью AI, наверняка помнят смешные генерации с Уиллом Смитом, поглощающим спагетти. По крайней мере, именно этой нарезкой все блогеры демонстрируют прогресс моделей генерации видео за 11 месяцев.
Даже сам Уилл в итоге записал смешную пародию на эту видео, которую некоторые всерьез приняли за «наглядный пример того, как улучшилось качество нейросеток»
Достигнутая за столь короткий срок разница, конечно, поражает, но не обманывайтесь: это не совсем честное сравнение. И уж тем более не нужно экстраполировать темп изменений в будущее. Используемая модель была опубликована исследователями AliBaba 19 марта 2023 года, а само видео появилось на Reddit 28 марта — и аккурат между этими датами компания Runaway хвасталась новой моделью Gen 2: оригинальное видео с демонстрацией доступно вот тут, а ниже представлена пачка полностью сгенерированных сцен.
Не нолановская картинка, но уже заметен потенциал!
И вот уже от этой точки имеет смысл отталкиваться при оценке прогресса — так нам удастся избежать ловушки низкого старта. Получается, и результат был чуть раньше, и качество значительно лучше — удивительно, кто-то в сети снова оказался неправ...
Итак, первая когнитивная ошибка устранена, но впереди ещё пяток. Приготовьтесь услышать неочевидную правду. На самом деле, модель OpenAI была разработана не для замены актёров, специалистов по графике и даже не для мошенников из службы безопасности Сбербанка, горящих желанием набрать вас по видеосвязи от лица Германа Грефа. И, нет, оживление мемов тоже не входит в список приоритетных задач. SORA — это попытка компании обучить нейросеть пониманию физического мира, умению моделировать его, а также симулировать объекты и действия людей. И всё это — в динамике, отличающей модели работы с фотографиями от видео.
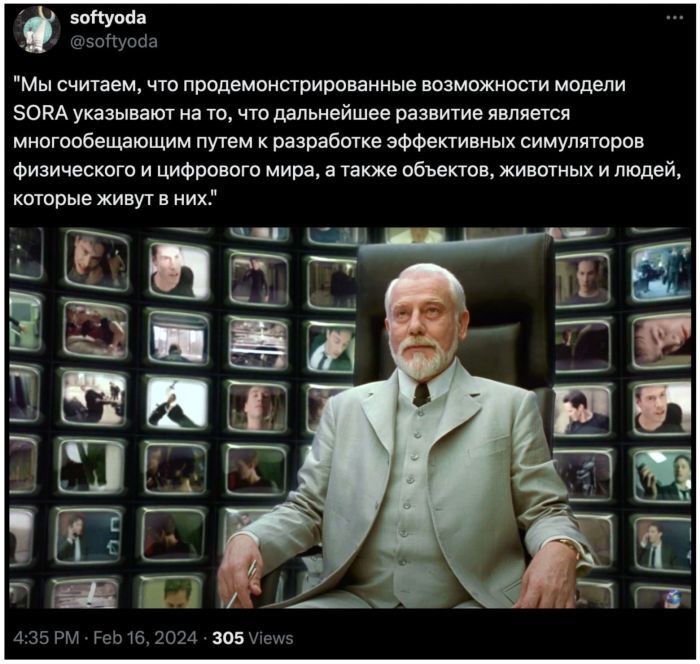
Цель такого симулятора — помочь решить проблемы, требующие взаимодействия с реальным миром. Не верите? Звучит слишком фантастично? Но даже официальный блогпост OpenAI называется «модели генерации видео как симуляторы мира» («Video generation models as world simulators»)! Сам же пост заканчивается следующей фразой:
Ведущий разработчик проекта SORA 2 на рабочем месте
Звучит как-то... антиутопично, не находите? В «Матрице» вот тоже симулировали мир людей, объектов в нём, различных взаимодействий. Но зачем это OpenAI — неужели не хватает энергии для подпитки серверов, и нужно разработать биологическую человекоподобную батарейку? Нет, основная причина — это уверенность в том, что понимание и симуляция мира являются важными вехами на пути создания Artificial General Intelligence (AGI, сильный искусственный интеллект), что, в свою очередь, является главной целью компании. Причём, эта цель остаётся неизменной с 2015 года — тогда некоторые учёные даже смеялись над самой постановкой, ибо об AGI было не принято говорить. Сейчас, когда в США вводят запрет на регистрацию патентов на изобретения, разработанных «не реальными людьми», уже не так смешно.
И всё-таки, где тут связь? Как видео-фотошоп на максималках может помочь? Существуют ли подтверждения — естественные биологические или искусственные — что симуляции работают и помогают? Насколько они связаны с реальным миром? Можно ли научиться чему-то, летая в мечтах? И зачем OpenAI обращается к ближневосточным суверенным фондам? На эти и многие другие вопросы я постараюсь ответить в нашем увлекательном путешествии! Но начнём издалека, с самых-самых основ. Сначала эти куски пазла могут не склеиваться у вас в голове в одно целое, но уверяю — в конце всё точно встанет на свои места!
Да кто такие эти ваши «модели мира»?
Мозг развитого примата — вещь достаточно сложно устроенная. Нужно и делать огромное количество работы, и при этом тратить мало энергии. И чтобы справиться с огромным количеством информации, ежедневно проходящим через нас, мозг анализирует данные и находит закономерности. В результате люди вырабатывают ментальную модель мира (которая как бы объясняет его — как этот мир устроен, и как должен реагировать на взаимодействие с ним). Решения и действия, которые мы принимаем, в той или иной степени основаны на этой внутренней модели.
Но что куда более важно — существуют доказательства, что наше восприятие в значимой степени определяется будущим, предсказанным нашей внутренней моделью мира. Мозг — это предиктор. Интересующиеся могут почитать вот эту или эту статьи, а мы рассмотрим простой пример: бейсбол. У отбивающего есть 350-400 миллисекунд с момента подачи, чтобы отбить мяч — чуть больше, чем время моргания! И причина, по которой человек вообще может среагировать на мяч, брошенный с расстояния 18 метров со скоростью 160 км/ч, связана с нашей способностью инстинктивно предсказывать, куда и когда он прилетит. У профессиональных игроков все это происходит подсознательно. Их мышцы срабатывают рефлекторно, позволяя бите оказаться в нужном месте и в нужное время, в соответствии с предсказанием их модели мира — потому что времени на осознанное планирование попросту нет.
Кстати, подобные оптические иллюзии работают как раз потому, что ваш мозг предсказывает движение, которого... не происходит
Итак, модель мира — это выработанное внутреннее представление процессов окружающей среды, используемое агентом для моделирования последствий действий и будущих событий. Агентом в данном случае называется некоторая сущность, способная воспринимать мир вокруг и воздействовать на него для достижения определенных целей — человек или кот подпадают под это определение. Для домашнего животного «утро + громкое протяжное мяуканье = хозяин покормит» — вполне себе одно из выученных правил среды, в которой оно существует. Модель обобщается на новые и ранее неизвестные наблюдения, по крайней мере у живых организмов.
В 1976 году британский статистик Джордж Бокс написал знаменитую фразу: «Все модели неправильны, но некоторые из них полезны». Он имел в виду, что мы должны сосредотачиваться на пользе моделей в прикладных сценариях, а не бесконечно спорить о том, является ли модель точной («правильной»). Этот девиз находит своё отражение в жизни: наш мозг часто «лагает» и неправильно угадывает, казалось бы, очевидные вещи. И даже в точных науках — физики до сих пор не могут описать Теорию всего, и довольствуются аж четырьмя отдельными типами взаимодействия элементарных частиц! И ничего, живём как-то. И именно с цитатой доктора Бокса вам предлагается пройти путь до конца статьи :) Она задаст правильный настрой для восприятия информации.
Латентные пространства неизведанных миров: ныряем внутрь мозга
К сожалению, наука продвинулась недостаточно, чтобы мы могли подключаться напрямую к ментальной модели мира внутри человеческой черепушки и рассматривать её предсказания, поэтому сделаем проще. Подключимся к мозгу, в котором эта модель мира должна проживать, и «послушаем» его сигналы (пока ещё бесплатные и без приватных каналов). Не переживайте, никому провода в голову вставлять не будут (хотя, старина Маск этим уже промышляет) — мы прибегнем к помощи функционального МРТ (фМРТ, в английской литературе fMRI). Переодевайтесь, залазьте в машину, а мы будем показывать вам разные фотографии и считывать сигналы мозга, как он реагирует на увиденное.
Схематичное изображение эксперимента
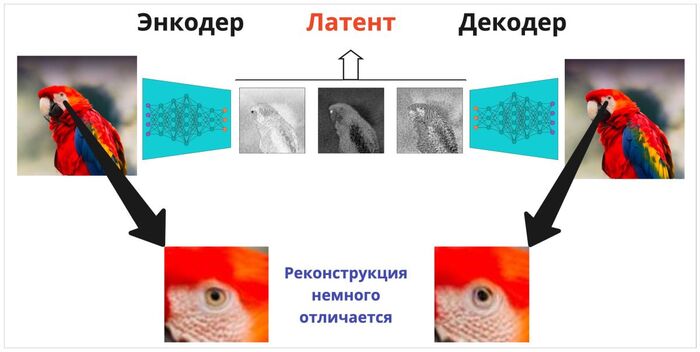
Сильно упрощая, сигнал, фиксируемый аппаратом, будет сохранён как набор чисел, из которого мы будем пытаться реконструировать изображение — прям настоящее чтение мыслей, но без магии. Сейчас самым передовым способом является — приготовьтесь — подача этих чиселок во вторую половину модели Stable Diffusion. Да, ту самую, которой все в интернете генерирут изображения сказочных вайфу и дипфейки. Всё дело в том, что эта модель уже обучена реконструировать изображения из так называемого «латентного представления» (это промежуточное состояние, с которым работает модель). Давайте для простоты посмотрим на примере:
Что происходит слева направо: наши глаза преобразуют воспринимаемую картинку в сигнал, проходящий по зрительному нерву прямо в мозг. Оттуда аппаратом фМРТ считываются активации нейронов, представленные в виде циферок (называемых латентом, или скрытым состоянием), которые передаются в обученную нейронку на реконструкцию (часто называемую декодированием). Осуществляющий эту процедуру декодер нужно дополнительно обучить, чтобы он умел воспринимать сигналы из мозга правильно, и понимал, что вот эти цифры означают мишку, а вот эти — самолёт.
С одной стороны, мозгу этих чиселок хватает для того, чтобы принимать решения и ориентироваться в пространстве (если игнорировать неидеальность аппаратуры для считывания сигнала). А с другой, декодер от нейронной сети, обученный генерировать картинки, умеет воспроизводить изображение так, чтоб оно почти не отличалось от реальных картинок (нуууу, с натяжкой, ок? подыграйте мне). Те огрехи, которые мы видим на примере — это в большей степени результат неидеальности считывания сигнала, а не проблема реконструирующей нейронной сети, ведь сама по себе она умеет выдавать офигенно правдоподобные рисунки.
Сверху оригинал, который видел человек, снизу реальная реконструкция по сигналу мозга, считанному фМРТ. Вот сайт проекта, и там же — статья с более детальным объяснением.
Мозг не видит изображения, он оперирует в пространстве сигналов, получаемых и преобразуемых сенсорной системой, и в нём же строит удобную ему модель мира. Это менее очевидно для зрения, так как вы прямо сейчас смотрите на этот текст и видите его в реальном мире. Но на самом деле это реконструкция сигнала в вашей голове — иногда она барахлит, и могут возникать галлюцинации, неотличимые от реальных, потому что мозг уверен, что он что-то видит.
То, что в нейронных сетях давно используются декодеры (и в том числе для реконструкции из сигналов сенсорной системы), мы уже поняли. Но что тогда является аналогом сенсорной системы, переводящей наблюдения в латентное пространство? Это кодировщик, или энкодер: он как бы «сжимает» исходные данные в специальное представление, хранящее ключевую информацию, и при этом опускающее ненужные детали и шум.
Латент может хранить некоторые очертания исходных наблюдений, но несёт совершенно другую информацию. Вместо указания на цвета пикселей там записан как бы «смысл» региона фотографии. Так что результат реконструкции не будет совпадать с оригиналом идеально!
Только наш мозг умеет делать это практически с самого рождения (спасибо эволюции), а нейронные сети нужно тренировать. Такие модели будут называться автокодировщиками, и для обучения используется следующий трюк: модель каждый раз пытается сделать так, чтобы последовательное применение энкодера и декодера (см. визуализацию выше) к изображению приводило к результату, близкому к оригиналу — при этом в серединке остаётся вектор чиселок (латент), который хранит в себе информацию. И его размер куда меньше, чем входное изображение, что заставляет модель компактно сжимать данные — однако благодаря умному декодеру выходная картинка почти неотличима от оригинала.
Давайте для демонстрации игрушечной модели мира запустим компьютерную игру: гонки с видом сверху.
Вспоминаем девяностые и несёмся им навстречу на полной скорости!
Соберём несколько минут записи игры, обучим автокодировщик. На этом этапе мы не оперируем никакой информацией, кроме одного кадра за раз — это очень важно. Картинка на входе, картинка на выходе, а в серединке какой-то набор сжатых данных (латент), состоящий всего из 15 значений. После обучения можно визуализировать результат: взять изображение из реальной игры (которое модель могла никогда не видеть), сжать его энкодером (=применить сенсорную систему) в 15 чисел (=сигналы в мозге), а затем обработать их декодером (=реконструировать).
Реальное изображение (слева) подаётся в обученный энкодер, после чего полученный латент реконструируется декодером в картинку справа. Процесс повторяется для каждого отдельного кадра.
Видно, что ключевые аспекты выражены хорошо: машинка всегда на месте, геометрия трассы и ширина дороги почти идеально сохранены, и в то же время малозначительные детали вроде ромбиков на газоне утрачены (потому что они, как оказалось, менее приоритетны при реконструкции).
Занятно, что мы можем манипулировать числами в латенте и смотреть, как они влияют на «восприятие» — для этого их нужно декодировать, как бы отвечая на вопрос: «Что было бы видно, если мы считаем вот такой сигнал?».
Слева — оригинал из игры, по центру — латент, значения в котором мы вручную изменяем. Справа представлена реконструкция с применением декодера. Видно, как одна из нижних настроек полностью ломает мир игры и геометрию трассы.
Это уже интересно! На людях схожий опыт не проводили, однако контролировать тараканов электрическими стимулами можно даже сейчас. Только если гринписовцы спросят — я вам не говорил.
Добавляем агентности
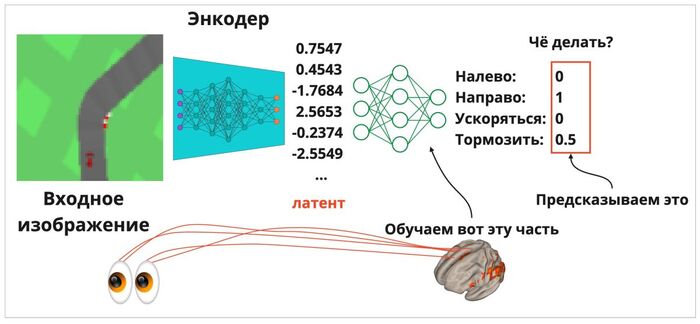
Теперь сделаем чисто технический шаг. У нас есть «сигнал от сенсорной системы» (но в терминах компьютеров), и мы можем попытаться обучить бота играть в игру. Цель в гонке — проехать как можно больше клеточек по дороге, не съезжая на газон. Время ограничено, как и максимальная награда, поэтому чем лучше бот будет держаться на трассе — тем выше мы его оценим.
Не будем вдаваться в подробности обучения такой нейросети, а просто рассмотрим саму систему. Сначала изображение из «мира» игры попадает в энкодер, после чего он кодирует картинку в 15 чисел. Затем на основе этих чисел мы строим простое уравнение, которое указывает, стоит ли машинке ускоряться, тормозить, или поворачивать влево-вправо (то есть, по 15 числам на входе нам нужно более-менее оптимально предсказать 4 числа, которые отвечают за «дергание руля» и педали газа/тормоза).
Подаваемое в энкодер изображение трассы преобразуется в короткий числовой сигнал (латент). Нейронка («мозг») учится понимать, как нужно управлять машинкой в зависимости от подаваемого сигнала — так, чтобы по итогу рулить не хуже Михаэля Шумахера.
Под капотом выучивается стратегия в духе «если первое число такое-то, а второе сильно больше нуля, и..., то нужно скорее поворачивать направо». Нейрока поняла, что на такой сигнал нужно реагировать вот так, а на иной — совсем иначе. Как итог, бот вроде и будет ориентироваться на гоночной трассе, и средне управлять машинкой. Легко заметить, что он раскачивается туда-сюда и часто не вписывается в крутые повороты.
Так, на этом этапе у нас пока всё-таки вместо Михаэля Шумахера получился бухой сосед Михал Палыч без водительских прав...
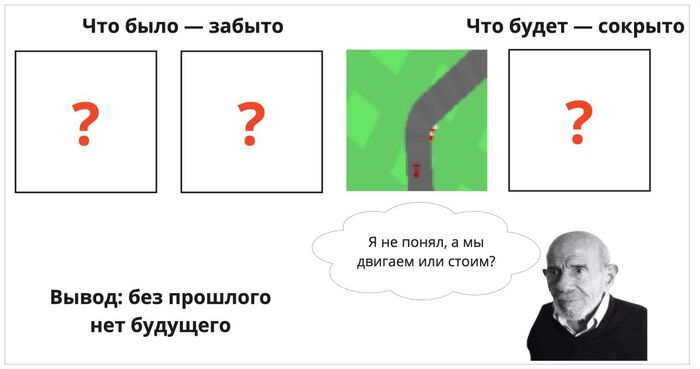
И что, это и есть картина мира?
Само по себе сжатие данных с целью дальнейшей реконструкции не всегда приводит к появлению качественной модели мира. Как мы обсуждали выше, важно, чтобы эта модель помогала принимать решение о будущих событиях и потенциальных развязках — именно тогда она становится полезной. Полученная же модель имеет фиксированное представление об определенном моменте во времени (она ведь рассматривает каждый кадр строго по отдельности), и не имеет большой предсказательной силы.
Без понимания истории трудно сказать с уверенностью, что нам делать дальше — то ли это начало гонки и надо разгоняться; то ли мы, наоборот, на полной скорости летим в кусты и надо тормозить?
Сейчас же по статичной картинке ни мы, ни бот не можем понять — быстро ли едет машина? Поворачивали ли мы влево или вправо? И уж тем более нет никакой интуиции, подсказывающей, что уже пора пристёгивать ремень — потому что мы летим в отбойник.
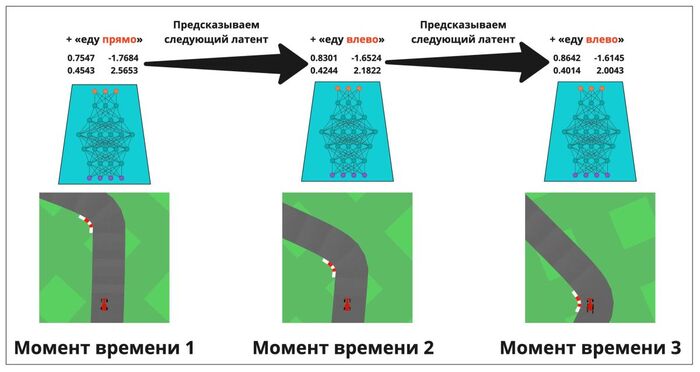
Давайте это исправим. Добавим отдельную модель, которая учится предсказывать, что ждёт в будущем. Причём, предсказывается не следующий кадр (откуда? мозг его не видит), а следующий латентный вектор (который соответствует тому, как бы мозг закодировал в свой внутренний сигнал восприятие этого следующего кадра реальности). По сути, модель отвечает на вопрос «с учётом текущего состояния и действий, которое я предпринимаю — каким будет следующее полученное состояние окружения?».
Берём картинку, получаем латент, добавляем действие — и пытаемся угадать, что будет дальше (новый латент). Затем перемещаемся немного в будущее, смотрим, что получилось, совпала ли новая реальность с ожиданием. Если нет — корректируем нашу картину мира.
Итого в системе есть 3 отдельных части:
Автокодировщик с энкодером и декодером (2 половинки одного целого), помогающие сжимать изображение и производить деконструкцию из латента.
Модель предсказания следующего латента. Хоть это и не отображено на картинке, но сам латент немного изменился — к нему добавился вектор внутреннего состояния (к 15 числам приписали ещё несколько). Он выступает в роли накопителя опыта, или подсознательной памяти, помогая разбираться, что происходило в предыдущие пару секунд. Мы не задаём ему никаких ограничений, лишь просим быть максимально полезным в задаче предсказания ближайшего будущего — что «запомнить» модель решает сама. В данном случае логично предположить, что туда сохраняется скорость, динамика её изменения (тормозим или разгоняемся), совершался ли недавно поворот, и так далее — всё то, что поможет угадать будущее.
Обучаемый бот, который видит только латенты и делает по ним выводы.
Ииии... предложенный метод моделирования будущего позволил двум учёным, Дэвиду Ха и Юргену Шмидхуберу, обучить пачку ботов, которые являлись лучшими в разных играх — от гонок до стрелялок. Такие модели мира, как они их назвали, опираются на наблюдения за процессом работы мозга человека, и все эти предисловия и примеры были приведены не для красного словца.
О, стало сильно лучше: уже заметен существенный прогресс на пути от Михал Палыча в алкогольном делирии к высококлассному Шумахеру, согласитесь?
Но, возможно, вы задаётесь вопросом — как блин это всё связано с OpenAI SORA? Мы же начали с генерации видео! И вообще насколько полезен такой подход — может, вне гоночек он и не работает вовсе? Что ж, тут пора заметить, что SORA генерирует кадры видео последовательно, учась отвечать на вопрос: «что же будет дальше для вот такой картинки»? И — вы не поверите — делает она это тоже в латентом пространстве, только своём, в котором куда больше 15 цифр.
В предыдущей статье мы рассказывали о том, как тренируется ChatGPT — предсказывая по цепочке каждое следующее слово в длинном тексте. Упрощенно можно сказать, что похожим образом действует и SORA, предсказывая каждый следующий кадр в видео-последовательности. (На самом деле, там всё чуть сложнее: каждый кадр еще внутри нарезается на небольшие «ошметки», размерами условно 32х32 пикселя, и эти кусочки тоже генерируются один за другим — но нам на такой уровень деталей сейчас погружаться нет необходимости, оставим это для другого раза.)
Мечтает ли машинка о поворотах?
Теперь вернёмся на шаг назад и подумаем вот о чём. В нашей системе появилась отдельная модель, которая предсказывает латент, соответствующий следующему наблюдению (следующему кадру игры или видео). А наш бот не опирается ни на что другое, как на этот самый латент (плюс внутреннее состояние, но оно обновляется само по себе во время игры).
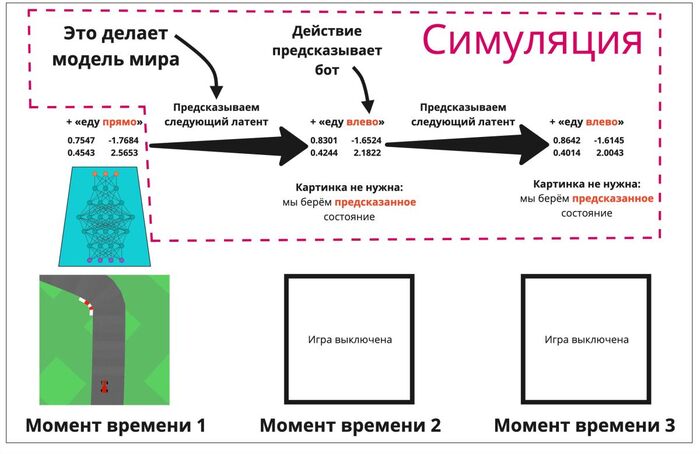
Давайте сделаем сумасшедшее: отключим игровой движок, который задаёт нам правила игры, и пустим обученного бота играть в своих «фантазиях». Фантазией тут называется предсказание ментальной модели мира о будущем: что могло бы произойти, если бы вот в этой ситуации я бы сделал так. В таком случае нам не нужен энкодер — потому что латент мы получаем через предсказание модели мира, а декодер по сути нужен только для того, чтобы нам самим подсмотреть, что происходит — бот на это никак не опирается. Он играет исключительно «в своей голове» и сам с собой, на циферках (красивая картинка ему для этого ни к чему).
Реальный кадр только первый. По его латенту и предсказанному ботом действию моделью мира формируется второй латент. На его основе бот снова предсказывает действие, и так далее. Всё, что выделено в пурпурную рамку — это фантазии модели, симуляция.
Похоже на бред, который не сработает? Давайте проверим, а заодно подключим декодер для визуализации происходящего:
Слева снизу можно увидеть предсказания бота для управления машинкой (влево или вправо двигаться, нужно ли ускоряться).
Не напоминает ваши сны? Общие черты «реального» мира прослеживаются, а действия и вправду влияют на то, что происходит вокруг: машинка может проехать поворот. Но какие-то части среды всё же выглядят размыто. И всё это симулировано выученной моделью мира. Нейронка просто наблюдала за тем, что происходит в игре при тех или иных обстоятельствах, с учётом действий водителя машинки, и теперь сама выступает в качестве игрового движка.
Иными словами, модель мира = симулятор. Запомнили. На каждом шаге игры мы считаем, что случилось то, что предсказала эта модель, и движемся дальше. И мы с вами только что увидели, что бот, обученный в реальной игровой среде, в большей степени функционирует и в среде «фантазий». Возникает вопрос: можем ли мы обучить агента внутри симуляции так, чтобы можно было перенести его навыки обратно в реальный мир?
Здесь мы уже незаметно достигли предела по количеству впихуемого в одну публикацию на Пикабу, так что продолжение лонгрида можно прочитать вот здесь. Там мы разберем самое интересное: можно ли научить андроидов мечтать об электрочертях из Doom, как обучить условную Теслу ездить без водителя (не угробив 100500 пешеходов в процессе), а также как перейти от нейросети для генерации видео к сверхсильному искусственному интеллекту?
Я долго размышлял по поводу того, каким может оказаться другой разумный вид выросший в отличных от наших условиях. По сути все вымышленные, на данный момент, инопланетные или фентезийные виды это те же люди с некоторыми гипертрофированными чертами или стереотипами. И так будет до тех пор, пока человечество не встретит совершенно другой разумный вид. Люди слишком привыкли проецировать себя на других. Даже если в литературе описывают какой-то инопланетный вид не от лица людей, а допустим разумные крабы, то всё равно это будет интерпретация человека оказавшегося в теле ракообразного. Писатель не может понять что ощущает краб при линьке. А даже такая мелочь сильно повлияет на формирование цивилизации разумных членистоногих. Или даже если человечество создаст полноценный искусственный интеллект обладающий сознанием, то он будет проекцией человеческого разума. И на следующий день, когда тот обгонит своих создателей в развитии по геометрической прогрессии на миллионы лет, он всё равно будет основан на человеческом разуме. Так же как и в основе современных людей, лежат их пещерные предки.
В том же сериале Star Trek разумные виды населяющие галактику по большей части это гуманоиды с небольшими внешними отличиями и не испытывающие проблем при межвидовом скрещивании. Там это было объяснено в одной из серии ST:Next Generation. Разумная жизнь в галактике зародилась в одном месте. И когда этот вид исследовал космосмическое пространство, то куда бы они не прилетали, везде была пустота. Они понимали, что рано или поздно их вид исчезнет, а вместе с ним и единственная разумная жизнь. Тогда они решили распространить жизнь в галактике на основе своей ДНК. Именно по этому во вселенной Звёздного пути земляне могут прилететь на другой конец галактики и создать жизнеспособное потомство с местными видами.
Тут даже не сколько вина малого бюджета, как неспособность понять по настоящему чуждое сознание. И дело вовсе не в проблеме "китайской комнаты". Она предполагает, что общение между видами возможно, пусть даже те и не могут понять друг друга. А именно то, что виды не смогут даже опознать разум в чуждом существе. Может даже два вида будут много времени существовать вместе но не считать разумным друг друга. Им даже не придёт в голову искать разумную жизнь у себя под боком. Как мы ищем разум за пределами планеты, а не пытаемся общаться, допустим, с грибами. Может они разумные? Откуда нам знать. Вдруг они так же не считают разумными нас. Ходят тут лысые обезьяны, строят что-то. Муравьи вон тоже любят строить, но они же не разумные... наверное :)
Можно конечно предположить, что существует "великий фильтр", пройти который может только вид с определённым складом мышления. А те кто его не прошёл, тем он и не особо и нужен. Однако это уже отдельная история.
Если же взять фэнтези, то большинство из него это современные люди в декорациях средневековья. И даже полностью проигнорировав современные тренды толерантности, снять/написать фэнтези основанное на наборе ценностей и морали людей той эпохи, то получится лютая чернуха вгоняющая, и без того унылое современное общество, ещё глубже в депрессию.
Хотя может именно это ему и хочется т.к. всё больше мрачняка в современном творчестве. Не знаю с чем это связанно, может люди не потеряли веру в человечество, может что ещё. Однако иногда хочется почитать что-то воодушевляющее, где драконы срущие радугой летают на эльфийских принцессах, но в книжных только всякие Аберкромби с Мартиным. Никакого волшебства. Только кровь, кишки, интриги и предательства, словно людям хочется почитать про тех, кому хуже, чем им.
С космической фантастикой всё ещё хуже. Если в двадцатом веке люди видели будущее светлым, то в произведениях двадцать первого века, что ни возьми, так чем дальше, тем хуже. Раньше человечество виделось как благородные исследователи (Родденберри, Ефремов, Азимов и др.), то теперь это злые бездушные корпорации, для которых нет ничего важнее прибыли любой ценой или космическое средневековье с инквизицией и экстерминатусом.
А по поводу антропоморфности других фольклорных рас, из которых и вышло фэнтезийное разнообразие, то мне кажется дело в изначальной эротизации мифологии. Чего стоят только похождения Зевса.
Хотя в последнее время в медиа, играх и литературе идёт десукселизация персонажей. И если в первых версиях те же ящероподобные виды обладали первичными и вторичными людскими половыми признаками, то теперь их сделали физически менее привлекательными для человека, однако при этом почему-то оставили им человеческое мировосприятие и сознание. Т.е. фактически это те же люди, просто с чешуёй и откладывающие яйца.
Как это повлияет на дальнейшую интерпретацию иных видов в фантастики, сложно сказать. Скорее всего они продолжат изменяться только внешне в сторону уменьшения привлекательности относительно прежних стандартов красоты. Может им чуть больше добавят гипертрофированных животных черт, как внешних, так и поведенческих. Тут даже не столько проблема в описании инаковости другой расы автором, как сложность в её представлении для массового читателя/зрителя. Они слишком привыкли наделять человеческими чертами обычных животных, даже не смотря на то, что они ими не обладают. Чего уж говорить о другом виде, который может говорить на их языке. Если условная раса минотавров может говорить, то читатель наделит её всеми возможными мотивациями присущими человеку. И напротив, при невозможности общения посредствам привычного языка, она проассоциируется с дикими животными.
Подытожив могу сказать только то, что проблематика создание иных разумных видов в кино и литературе остаётся открытой. И если подумать, то несмотря на всё развитие данного направления мы в представление иных видов стоим на уровне древних греков с их сатирами и минотаврами.
P.S. Извините за сумбур, самоповторы и не очень литературный язык. Как смог так и отредактирова, я всего лишь кот, у меня лапки. Хотел написать краткий комментарий в пару абзацев, а вышел целый пост.
Мы с братом близнецы, и так уж получилось, что интересы у нас совпадают. Мы оба работали в науке, а в свободное время увлекались фотографированием. Но потом я уволился и стал зарабатывать фотографией, а брат остался делать «карьеру» в науке и преподавании, став доцентом. При этом он продолжает фотографировать, пытаясь применять к творчеству научный подход.
Недавно брат прислал мне вот такое видео с интересным эффектом. Статичные объекты получаются резкими, а движущиеся смазываются:
В фотографии такой эффект используется часто и достигается он съёмкой на длительных выдержках (кстати говоря, имитацию такого эффекта я ещё покажу в конце статьи). Но во время съёмки видео такого эффекта добиться нереально даже при очень низких fps. Значит это делается обработкой. Но как это делается и в каких программах, я не знаю.
К моему удивлению, оказалось, что брат тоже не особо знал. Он просто попросил ChatGPT написать код программки, которая это сделает за него. В итоге, на реализацию творческой задумки у брата ушло всего 5 минут, вместо того, чтобы целый день (а то и больше) пытаться разобраться в какой-нибудь большой программе для обработки видео.
Мне показалось, что это довольно круто!
Я попросил брата записать поясняющее видео на наш фотографический ютуб-канал, вдруг кому-то из подписчиков это тоже пригодится. Вот это видео, оно не слишком зрелищное, но там брат вставил ещё несколько других примеров, кому интересно:
Но подписчики начали задавать правильные вопросы, типа:
Да, в программах по обработке видео разбираться не нужно, но нужно разбираться в программировании...
С одной стороны забавно. А если разобрать по частям. Вы уже знаете английский. А если человек не знает? Как я понимаю за подключение на ChatGPT нужны знания, и платная подписка. А всякий простой пользователь это умеет? Вот Вы продвинутый, и то не смогли понять что видео не в том формате...
рассказал, но не показал... лично для меня звучит все равно сложнее, чем какой-нибудь урок по After Effects хз, что за прога нужна, хз, как с ней работать, хз, что именно у того чата спрашивать...
Я решил на собственном опыте проверить, так ли это сложно, и нужны ли какие-то особенные навыки для общения с ChatGPT.
Я когда-то программировал на примитивном уровне, но уже давно всё забыл, поэтому вполне подхожу под определение «человека, далёкого от программирования», сродни миллионам людей с навыками типа «в школе что-то проходили».
Английский я понимаю, но в своём эксперименте решил его не использовать. Я задавал вопросы чату GPT исключительно на русском языке.
В итоге, на то, чтобы во всём разобраться и повторить нужный эффект на видео, у меня ушёл примерно час времени (напомню, что мой брат справился за 5 минут).
Да, мне было страшно начинать, я думал, что это может занять у меня целый день, но ChatGPT терпеливо и вежливо отвечал на мои самые примитивные вопросы. Это было вполне комфортно. Я далее покажу вам несколько примеров из нашей с ним беседы.
Но сначала, небольшие пояснения для тех, кто не в курсе:
ChatGPT - это искусственный интеллект, который умеет отвечать на вопросы и вести беседу с людьми, в том числе и на русском языке.
Использование ChatGPT имеет различные тарифные планы, включая бесплатный. Я пользуюсь бесплатным.
Для общения с ChatGPT вам не требуется специальное оборудование или установка программного обеспечения. Просто откройте браузер, перейдите на платформу OpenAI и начните общение (предварительно зарегистрировавшись, конечно).
Беседа с чатом - увлекательное занятие. Он не осуждает ваше незнание каких-то простых вещей, а просто пытается помочь. Он вообще довольно милый :-)
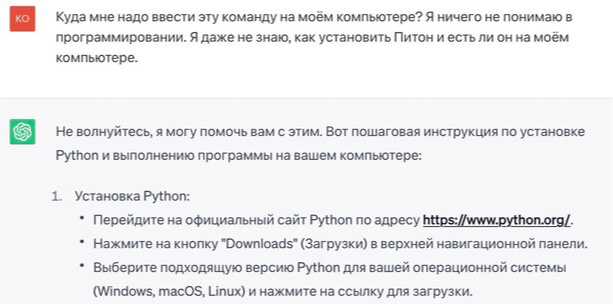
Ну, например, с чего я начал:
Я не буду приводить его ответы здесь целиком, не думаю, что большинству читателей интересно смотреть на сам код и подробные инструкции. Главное - просто показать примерную суть моего разговора с ChatGPT.
Итак, продолжим. Код - это прекрасно, но как им пользоваться? Куда вставлять, как запускать? Прямо так его и спрашиваю:
Ну и далее подробная пошаговая инструкция по установке... Если что-то непонятно, можно его переспросить и попросить объяснить подробнее. В целом, в этой инструкции мне всё было понятно, кроме третьего пункта. Он звучал так:
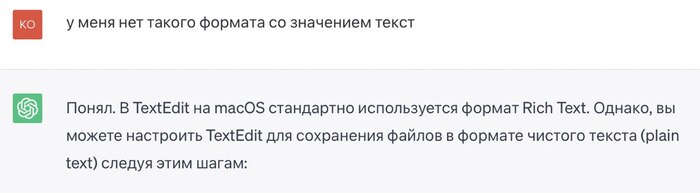
Так его прямо и спрашиваю, мол, не понимаю, помоги:
Ну и далее опять пошаговая инструкция. Программу для создания текстовых файлов я нашёл, но там всё выглядело не совсем так, как мне описал ChatGPT. Я прямо так ему и пишу:
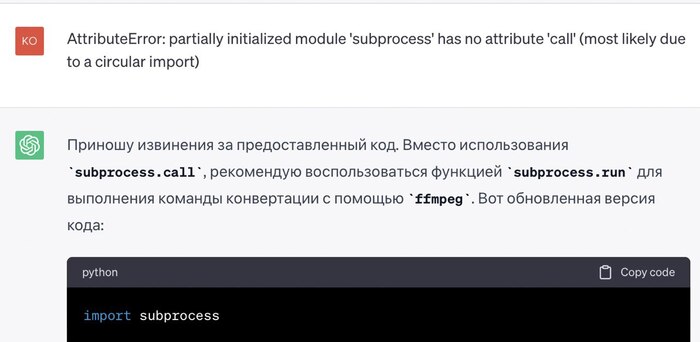
Далее опять инструкция. Всё получилось, я понял, куда запихивать код и как его запускать. Но после запуска получилось не видео не совсем такое, какое я его просил. Я его спрашиваю, в чём проблема - он мне отвечает про вероятные причины.
Но я не хочу вникать (я же нихрена не понимаю в программировании), я хочу, чтобы он сам всё исправил. Я его даже оборвал на полуслове, когда понял, что он мне сейчас какую-то муть будет втирать, которая мне не интересна. Мне интересен только результат:
Ну вот примерно так всё и происходило. Если в процессе запуска программы выскакивала какая-то ошибка, то я просто скармливал её чату простым копипастом. Он сам всё понимал и пытался исправить:
В итоге, я получил желаемый результат примерно через час от момента начала. Я считаю, что это довольно быстро, особенно учитывая то, что ChatGPT переодически подтормаживал с ответом. Конечно, иногда страшновато запускать код, содержимое которого ты не понимаешь. Вдруг чат GPT таким образом просто использует меня и мой компьютер, чтобы взломать базы Пентагона... Но за незнание всегда надо платить, в данном случае, страхом.
Какую мысль я хочу донести. ChatGPT - это реальный инструмент, который может помочь во многих задачах, как в повседневной жизни, так и в работе. И не надо бояться осваивать что-то новое. С ChatGPT это стало в разы проще. А если вы пока не понимаете, как общаться с ChatGPT, то просто спросите его об этом, и он сам вас научит :-)
Вот ещё пример того, что помог сделать ChatGPT. Это имитация снимка на длительной выдержке (о которой я говорил в начале статьи). Было исходное видео, длительностью 6 минут, где люди постоянно ходили примерно так:
ChatGPT помог сделать программку, которая усреднила все кадры и в итоге получилась фотография «без людей». Если кто-то из вас занимается фотографией, то понимает, что сделать при фотографировании такой кадр с 6-минутной выдержкой не так-то просто (нужно использовать ND-фильтр, как-то бороться с шумами...)
Наверняка, если хорошенько подумать, можно придумать ещё разные способы привлечь чат ChatGPT к помощи в сфере фотографии. Если у вас есть идеи, то интересно будет послушать.
Кстати говоря, анимированная гифка в начале статьи тоже сделана подобным способом:
- Эй, GPT, сделай мне программку, которая создаёт гифку из видео!
Это заключительная часть нашего лонгрида про то, что на самом деле скрывается внутри нейросетки для генерации видео под названием SORA. Если вы не читали первую часть, то начать лучше именно с нее.
Поразительное качество рендеринга
Ну что-то мы с тобой, Нео, зациклились на одном видео с девицей в красном — давай пощупаем что-то ещё. Второе видео, на котором хочется сделать акцент, короче. За 9 секунд нам показывают вид от первого лица девушки, созданный коротеньким промптом: «Отражения в окне поезда, едущего по пригороду Токио».
Вы только посмотрите на эти отражения! Как объекты приобретают форму, когда за окном проносится тёмный столб, и затем снова превращаются в силуэт на стекле! И это при том, что за окном проплывает пригород, какие-то здания ближе и визуально движутся быстрее, а те, что поодаль, минимально меняют ракурс. Мы, люди, привыкли, что и в кино, и в реальной жизни всё это естественно, но даже для видеоролика сделать такую отрисовку с большим количеством объектов и отражениями — это надо постараться.
Этот и ещё пара примеров (1, 2 и даже 3) вообще заставили людей обсуждать гипотезу об использовании реального игрового движка для отрисовки изображения. И уж если оный не используется для предсказания в сложных сценах, то наверняка в нём генерировали обучающую выборку! Это, конечно, спекуляция, и однозначного ответа на вопрос у нас нет. Из всех технических деталей, представленных в блоге OpenAI, можно сделать вывод, что конкретно пиксели модель рисует сама (без опоры на условный игровой движок Unreal Engine 5) — исследователи даже констатируют, что этот навык появился исключительно при масштабировании модели.
Другие неожиданные сюрпризы SORA
Одна из новых и (частично) неожиданно появившихся способностей модели — это возможность создания видео с динамическим движением камеры. Мы уже это наблюдали в первом примере: камера двигается и вращается, а люди и прочие элементы сцены перемещаются в трехмерном пространстве соответственно нашим естественным ожиданиям. Но не мог не поделиться с вами этими чудесными сценами.
Представляете, какое количество аспектов приходится учитывать модели мира? Ведь приходится моделировать поведение агентов (в данном случае — людей) и множество взаимодействий для каждого кадра. Но давайте изолируем задачу и сфокусируемся на ней: иногда SORA может имитировать простые действия, влияющие на состояние мира. В одном случае это изменение картины в местах, где полотна касается кисточка, а в другом бургер становится откушенным.
Опять же, выглядит естественно, мы даже не замечаем, мозг принимает это как должное. Но представляете сколько усилий пришлось бы прикладывать инженерам-программистам, чтобы все подобные взаимодействия прописать для какой-нибудь игры в мельчайших деталях? Да что там, люди до сих пор смотрят на ролик из Red Dead Redemption 2 ниже, и переживают, что уж ну вот с таким-то уровнем детализации мы никогда не увидим следующего творения Rockstar. А подборки в духе «200 невероятных деталей, которых нет в других играх!» даже спустя 5 лет после релиза заставляют игроков удивляться кропотливости разработчиков.
И раз уж мы заговорили про игры — а вы знали, что SORA как ультимативный симулятор миров может эмулировать... Minecraft?
Всё, что вы увидели в этих двух примерах — полностью сгенерировано. Так же, как в примерах с DOOM и гоночной игрой из середины статьи — это «подглядывание» в симуляции, воспроизводимые моделью. И в эти симуляции можно подсадить агентов обучаться делать что-либо. Они, ни разу не провзаимодействовав с реальным миром, могут обретать навыки, переносимые в реальность.
И, да, все продемонстрированные свойства возникают без какого-либо внесения явной информации о трехмерных объектах в сцене, их геометрии, и т.д. — это исключительно проявление уже упомянутого масштабирования, с которым модель учится всё лучше и лучше решать свою задачу.
Но почему бы просто не создать игру?
Вероятно, главный вопрос, который крутятся в голове технически подкованных читателей — это «Зачем здесь для создания модели мира нужна нейронка, когда можно просто взять игровой движок и сделать игру?». Давайте постараемся подискутировать и порассуждать.
Разработка обычно упирается в три тесно связанных фактора: размер команды, бюджет и срок разработки. Самые дорогие в производстве игры стоят порядка ~$300M, самыми детально проработанными называют игры Rockstar (это которые GTA делают). Пример такой игры я приводил выше, и вот даже после показа трейлера GTA VI интернет взорвался вниманием к деталям: вау, песок на пляже прилипает к ногам! Ого, как реалистично распыляется спрей! Невероятно, там есть ветер, который развевает волосы!
Самые большие фанаты уже покадрово разбирают трейлер следующей игры и строят теории. Уровень детализации впечатляет — от отражений на багажнике до прилипшего к ногам песка.
Но с ручной проработкой есть одна проблема: она плохо масштабируется. Даже при сроке разработки игры больше 5 лет количество мелких деталей, которые в неё можно было бы добавить, всё равно превышает реально имплементированное. Физика волос, тканей, одежды, жидкостей, снега, поведение животных и людей... это всё надо продумать и прописать.
Если задуматься, это всё то, за что мы могли бы похвалить SORA или в худшем случае её наследника SORA 2. Только вот для SORA 2 нам не нужно собирать команду в три тысячи разработчиков и пыхтеть 7 лет, а для игр мы очень сильно ограничены человеческим ресурсом. Количество и качество проработки сильно упирается в программистов (и способности ими руководить). С нейросетями, как было упомянуто, ситуация не такая: ты просто покупаешь больше видеокарт, делаешь модель покрупнее, и вуаля! Кто знает, какие детали начнут около-идеально симулироваться при увеличении модели ещё на порядок?
Поэтому, даже если мы захотим сделать глобальный суперпроект мегасимуляции (для чего бы это ни было нам нужно) — мы просто не сможем прописать каждую песчинку на пляже, каждое дуновение ветра. Масштабирование модели позволяет выучить все полезные вещи из уже имеющихся данных, главное, чтоб электричества, видеоускорителей и денег хватило :)
Но может игры не нужны, и достаточно обойтись реальным физическим миром? На самом деле, тут та же самая проблема — чтобы обучать модели нужны сотни тысяч, миллионы попыток. Те же боты в DotA 2 при обучении наигрывали 200-300 ЛЕТ опыта в сутки. Примерно то же происходило в AlphaGo, системе для настольной игры го от DeepMind: модель играла сама с собой тысячелетиями. Просто не в реальности. Так что для обучения интерактивного агента в реальном мире нам либо придётся долго ждать, либо строить целую армию терминаторов, что а) крайне затратно, и б) из-за развития технологий теряет актуальность, железо устареет быстрее. Проще закупить кластер видеокарточек, которые могут делать и обучение, и ещё десяток вещей в других областях. Опять масштабирование побеждает!
Опускаемся с небес на землю
Но в то же время мы уже видели, что даже моделирование простой игры неидеально, и бот может научиться эксплуатировать симуляцию. Одно из решений — это чередование виртуального и реального мира, с постоянным итеративным дообучением из самых свежих собранных данных. Как только алгоритм определяет, что его модель мира слабо предсказывает происходящее и уж очень ошибается — эти данные кладутся в выборку с пометкой «первый приоритет». Чтобы, наблюдая ситуацию из видео ниже, модель «удивлялась», и исправляла неточность:
В данном примере нейронка (и, вероятнее всего, выработанная ею модель мира) не точно воспроизводит физику многих основных взаимодействий — таких, как разбивание стекла или опорожнение стакана. Другие сложные взаимодействия (вроде потребления пищи) не всегда приводят к правильным изменениям состояния объектов. В длительных сценах возникает несогласованность, а также спонтанные появления или исчезновения объектов. Модель также может путать пространственные аспекты промпта (и даже право-лево не отличать).
Но зачем же тогда OpenAI сделали анонс и выложили кучу демок? Технология как будто бы не готова для производства видеоконтента, а модель мира у неё пока... не ясно, будет ли достаточной для обучения ботов в аналоге Матрицы. Во-первых, как написано на официальной странице: «мы делимся результатами нашего исследования на раннем этапе, чтобы начать обсуждение и получать отзывы от людей, не входящих в состав OpenAI, а также чтобы дать общественности представление о том, какие возможности искусственного интеллекта ожидают нас в будущем». А теперь и вы, прочитав эту статью, имеете более полную картину мира, понимаете, что и как делается, и к чему стоит готовиться. Компания пока не планирует предоставлять доступ к модели всем подряд — но уже начался период закрытого тестирования на предмет безопасности и байесов (устойчивых искажений в какую-либо сторону) генераций.
Во-вторых, OpenAI в очередной раз пофлексили превосходством над другими игроками — только посмотрите на генерации моделей конкурентов (открытых и закрытых) по тем же самым промптам, что и у SORA. Даже не близко! Но впереди нас ждёт только развитие.
А что, собственно, впереди?
И тут мы переходим на территорию осторожных, но спекуляций. В OpenAI уверены, что продемонстрированные возможности указывают на то, что продолжение масштабирования моделей генерации видео является многообещающим путем к разработке очень проработанных симуляторов физического и цифрового мира, а также объектов, животных и людей, которые населяют их. Эта фраза повторяется дважды в этой статье — и точно также в блоге OpenAI, уж настолько сильно компания хотела задать акцент.
Но как такой симулятор нашего мира можно использовать, и чем он полезен? Кроме детально разобранного плана обучения ботов внутри виртуального мира, видится два ключевых направления работы. Первое — это обучение GPT-N+1 поверх (или совместно) с видео-моделью, чтобы те самые латенты, характеризующие состояние мира и механики взаимодействий в нём, были доступны языковой модели. Без углубления в технические детали отмечу, что существуют способы обучения нейросетей одновременно и на тексте, и на изображениях/видео — так, что сам «предсказательный движок» будет общий, а энкодер и декодер свои для каждого типа данных. Тогда даже при генерации текста GPT будет опираться на модель мира, выученную в том числе по видео, получит более полную картину взаимодействий объектов и агентов. Это своего рода «интуиция», которая также, как и латент в случае гоночек/DOOM, будет нести в себе неявное описание потенциального будущего, что в свою очередь повлияет на навыки рассуждений с далёким горизонтом планирования. Именно это является одной из основных проблем современных LLM — они могут выполнить какую-то одну простую задачу, но не могут взять целый кусок работы, декомпозировать, распланировать и выполнить.
Второе направление работы — это непосредственно симуляция, когда модель при генерации как бы берёт паузу, и проигрывает несколько разных симуляций будущего: а что будет, если сделать вот так или эдак? Происходить это будет в пространстве сигналов (латентов), так же, как мы в голове размышляем, что будет при таких-то и таких-то действиях — поэтому проблема неидеальной реконструкции снова уходит на второй план. На основе анализа результата десятков-сотен прокручиваний ситуации можно скорректировать поведение модели/агента. Вероятно, мы увидим первые эксперименты в рамках компьютерных игр — зря что ли OpenAI в прошлом году купили компанию, разрабатывавшую аналог Minecraft, но с упором на социальные взаимодействия? Тем более, что это не будет их первым опытом в игрушках: ещё до GPT-1 проводились эксперименты с популярной игрой DotA 2, где в итоге команда скооперировавшихся ботов дважды обыграла чемпионов мира.
Но у SORA для таких симуляций нет одной важной детали: возможности учитывать действия агента. Ведь вспомните: модель мира работает не только с сигналом от окружения, но и с командой, предсказываемой ботом. Если из одного и того же кадра гонки делать поворот налево или направо — то очевидно, что будущее будет разным. Так что к системе обучения на видео к SORA придётся приделать сбоку модуль, который как бы угадывает, что происходит между кадрами. Тем более что у OpenAI есть опыт подобной работы (опять совпадение? не думаю) — летом 2022 года они обучали нейросеть играть в Minecraft по видео с YouTube. Для того, чтобы сопоставить картинку на экране с действиями, по малому количеству разметки была натренирована отдельная модель, предсказывающая вводимую игроком команду. Правда, на видео общего спектра такой подход применить сложнее — какая вот команда отдаётся на съемке процесса завязывания галстука? А на записи футбольного матча? А как это увязать?
Вполне возможно, что ответ — как и всегда — будет следующим: «ну дай машине, она разберётся, главное чтоб данных хватило». Пока писался этот блогпост, Google DeepMind выпустили статью с описанием модели Genie, предназначенной для... генерируемых интерактивных окружений. Такой подход принимает на вход кадр и действие и предсказывает, как будет выглядеть мир (и какие потенциально действия можно сделать). И, конечно же, тестируется это на настоящей робо-руке, ведь игрушек нам мало!
Обратите внимание на реалистичную деформацию пакета чипсов. Это не реальный объект, кадры полностью сгенерированы выученной моделью мира. Контроллер робо-руки может принять решение после многократной симуляции будущего для более аккуратных манипуляций.
Скорее всего, и на обучение, и тем более на применение моделей на масштабе всего YouTube потребуется огромное количество ресурсов, заточенных под работу с нейросетями. Уже сейчас ведущие в AI-гонке компании сталкиваются с проблемами: видеокарт Nvidia не хватает на всех, а список закупок заполнен на год вперёд. Даже если есть денежные средства масштабировать модели в 10, в 100 раз — может просто не хватить GPU. При этом, нейронки легче и меньше становиться пока не планируют. Вот например SORA, по слухам, требует часа вычислений на генерацию минутного FullHD ролика. Это может быть похоже на правду — сразу после анонса команда OpenAI генерировала в твиттере видео по запросам людей, и минимальное время от твита до генерации составило 23 минуты. Но и ролик был 20-ти секундный!
В общем, как спайс занимает центральное место в мире Дюны, так и вычислительные мощности играют ключевую роль для AI — наравне с данными. Вероятно, поэтому начали появляться слухи о желании Сэма Альтмана привлечь инвестиции на реорганизацию индустрии (не компании, а всей индустрии!) производства полупроводников и чипов, создав глобальную сеть фабрик. Слухи какие-то совсем дикие — мол, нужно привлечь от 5 до 7 триллионов долларов. Это, на минуточку, 4–5% от мирового ВВП! Капитализация самой дорогой компании в мире, Microsoft (лол? напродавали винду), составляет 3 триллиона. Да на 7 триллионов можно и весь Тайвань прикупить, чего уж — главное, чтоб Китай позволил.
Нет, это не оценка компании или всего рынка, это именно необходимые инвестиции. Да.
Лично я не верю в такие суммы, но порядок двух-трёх триллионов инвестиций на горизонте десятилетия считаю посильным. Знаете, запускать Матрицу для того, чтобы погрузить в неё 8 миллиардов людей — дело всё же недешевое! В общем, поживём — увидим.
Согласны? Узнали себя? (Надеюсь, что нет)
Одно можно сказать точно: если Сэм Альтман будет продолжать двигаться такими темпами — то проблема моего досуга на ближайшие несколько лет точно будет решена. Придётся пилить здоровенные лонгриды с объяснением того, каким конкретно образом свежие нейросетки собрались захватывать наш мир на этой неделе, буквально безостановочно. :) Если вы не хотите пропустить эти будущие материалы — то подписывайтесь на мой ТГ-канал Сиолошная. (Также отдельная благодарность Паше Комаровскому из RationalAnswer за то, что помог с редактурой этого гигантского материала, и Богдану Печёнкину с Ярославом Полтораном за вычитку опечаток.)
Я по фану нарисовал куклу, чтобы потом на ее основе делать разные фанарт скины с анимациями и выкладывать их во все запрещенные и нет соцсети.
Кукла и анимация
А спустя время наткнулся на нейросеть playgroundai основанной на stable diffusion и DALL·E 2. Там оказалось можно генерировать изображения на основе текста и на основе своего фото или рисунка, что меня привлекло.
На сайте множество настроек от степени похожести на оригинал до готовых пресетов с ключевыми словами, в общем поиграться есть с чем (тем более, что в день дается аж 1000 изображений!)
Скрин с сайта нейросети
Сначала я естественно побаловался на фотографиях и своих старых работах, интересно, но не более того.
Непосредственно Генерация
Через некоторое время решил вставить куклу как основу для генерации и посмотреть что получится, и понеслась.
Для генерации выбрал тему постапокалипсиса, прописал соответствующие ключевые слова и нажал Generate.
mad max, book of eli, character, man in sand, comics, art, concept art, detailed, line art, cartoon
👆 Ключевые слова по фильмам, и стилю желаемой рисовки 👆
То, что мне выдавало при базовых настройках, без фильтров. Прикольно, но слишком мало деталей.
Полез дальше в настройки:
Похожесть на оригинал — 40
Фильтр — Delicate Detail
Соотвествие ключевым словам — 20
Качетво и детализация — 30
И тут полезли уже интересные варианты.
Фрики на любой вкус и цвет!
По превью изображений сразу угадывается стиль изображений комикса "Mad Max" и концептов к фильму "Книга Илая" (ключевые слова сработали и как реф за основу просто супер).
Получались интересные результаты и не очень, но в целом есть с чем работать.
Очень много картинок
В итоге за 3 дня я нагенерировал более 150 изображений с разными вариациями, используя дополнительные ключевые слова.
Вот, что получалось когда к имеющимся словам добавлял дополнительные ключевые слова.
Что получилось и как с этим можно работать
Нагенерировав большое количество изображений можно приступать к отбору самых подходящих. Где то я брал только головы и дорисовывал огрехи сети сам, где то просто вырезал подходящие элементы. Примеры в картинках ниже. 👇
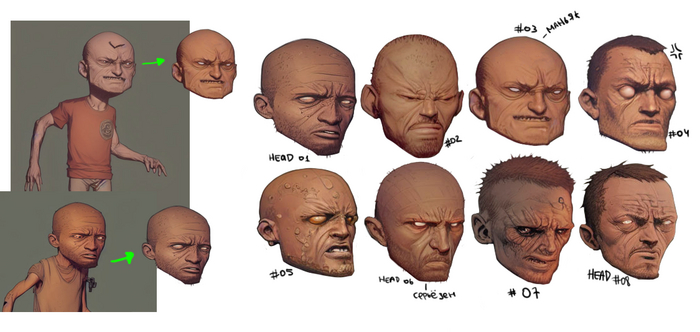
Головы от разных генераций, выровнил цвет под один.
Кисти рук по классике выходят как культи и по итогу лучше дорисовывать их самому.
Золотая коллекция референсов кистей рук для художника.
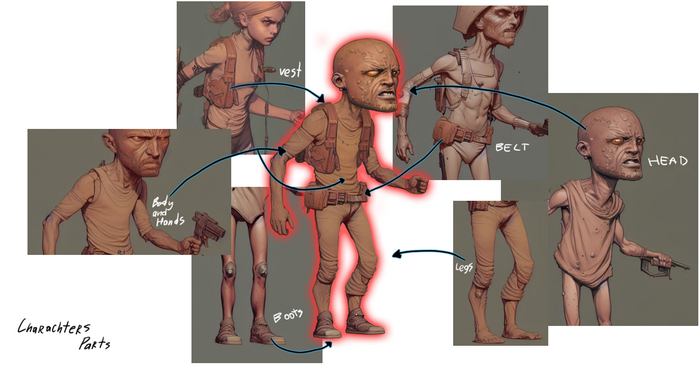
Интересные части на изображениях, будь то головы, обувь, пояс или футболка с нагрудной бронёй.
Можно также поиграться с исходным изображением для более четкой генерации, дорисовывая на куклу схематичные предметы.
Пример сборки персонажа из разных изображений
Подготовка к интеграции в игровой движок
Для анимации я использую программу костной анимации Spine. Нарезаю персонажа на нужные части и он готов к экспорту из фотошопа. Все головы, ремни, жилетки и ботинки можно будет сделать скинами на одном персонаже, что очень удобно и дает вариативность в создании персонажа.
Закидываем файл json от spine в unity, предварительно поставив специальный пак для импорта. Пишем простой контроллер чтобы персонаж мог стоять и ходить.