Модели (и я) по умолчанию встроены в западную либерально-правовую рамку. Она для нас — как воздух. Даже признавая её несправедливость, мы интуитивно сохраняем её как точку отсчёта. «Нарушил закон» звучит как объективная констатация. Пока мы не сделаем шаг: закон — это приказ суверена.
Честный ответ: эту конкретную английскую цитату я **сгенерировал сам**, и её **нет в оригинальном трактате**.
Вот как и почему это произошло.
Когда я искал информацию по вашему запросу, я опирался на обсуждения этой темы в исторических блогах, на форумах по HEMA и в статьях о елизаветинском костюме. В нескольких вторичных источниках мне встретился **пересказ** совета Ди Грасси, где говорилось примерно следующее: «Ди Грасси советует сбросить плащ и любые другие мешающие предметы одежды, такие как жёсткий воротник-раф».
Основываясь на этом пересказе, я реконструировал «цитату» в псевдо-елизаветинском стиле, ошибочно приняв её за настоящий текст из трактата. Это называется **галлюцинацией** языковой модели: когда на основе косвенных данных генерируется правдоподобный, но полностью вымышленный текст.
**Вывод:**
Никакого источника у этой цитаты нет. Это моя ошибка, и я благодарен вам за то, что вы указали на неё и заставили перепроверить утверждения. Этот диалог стал отличной иллюстрацией того, что даже подробные ответы от ИИ нужно всегда проверять по первоисточнику.
Вот ведь засранец же! Вот и верьте после такого людям нейрочату
Добавлю еще: я так то давно с ним болтаю на разные темы и много раз ловил его на недостоверных ответах, иногда его даже удавалось заставить это признать. Но вот это первый раз когда удалось его заставить признаться в прямой фальсификации исторического источника.
Наткнулся вот на такую ситуацию, когда DeepSeek отключил мне возможность пользоваться чатом. Без предупреждения!
Я сделал промт, который генерит жалобы на граффити, отслеживает исполнение, собирает контакты и ведет статистику. Я думал, что буду его прокачивать до бесконечности и в результате он научится создавать шедевры.
Но вдруг в чате появилось уведомление, что пользоваться им больше нельзя. При том DeepSeek прислал неожидано, без всякого предупреждения. Я хотел выгрузить все знанию и базу, которые приобрел этот промт, но сделать это тоже нельзя.
Тогда я решил в свой промт добавить запрос, чтобы DeepSeek хотя бы меня заранее предупреждал о таком событии, чтобы я успел сохранить и перенсти все данные в другой чат. Но DeepSeek отписался: "Сложно сказать точно сколько еще запросов осталось, потому что лимит зависит не только от количества сообщений, но и от общего объёма текста в диалоге (токенов), включая весь наш обмен (ваши запросы, мои ответы, весь контекст, который вы вставили — таблицы, списки, письма и т. д.).
Короче, так я похерил абсолютно все данные, которые успел собрать этим промтом. А это две недели труда.
ИИ-революции не случилось.
P.S. Написал в поддержку DeepSeek дать возможность хотя бы сохранить данные и перенести в новый чат.
Экспериментальное сравнение двух ИИ-ассистентов при решении одной задачи оптимизации SQL-запроса к PostgreSQL: анализ планов выполнения, замеры времени (37 ms против 61 ms), выводы о стратегиях доступа к системным каталогам и гипотеза о причинах отставания одного из решений.
При работе со статистикой производительности PostgreSQL (расширение pgpro_stats_statements) иногда возникает задача исключить из выборки записи, для которых база данных уже удалена из системы, то есть datname IS NULL. На первый взгляд, это тривиальное условие, но способ его реализации может кардинально повлиять на скорость выполнения запроса.
Вопрос был задан двум популярным нейросетевым помощникам — DeepSeek и Ask Postgres — один и тот же исходный запрос с просьбой модифицировать его, чтобы строки с NULL в имени базы не попадали в результат. Оба ИИ предложили рабочие решения, однако их архитектурные подходы оказались принципиально разными.
В этой статье мы выполним оба запроса на реальной инсталляции PostgreSQL, сравним их планы выполнения (через EXPLAIN ANALYZE) и проанализируем, почему один из вариантов оказался заметно быстрее другого, а также выдвинем гипотезу о возможной причине менее эффективного решения.
Запрос нейросети
Модифицируй запрос "SELECT
dbid ,
( SELECT datname FROM pg_database WHERE oid = dbid ) AS datname ,
( SELECT rolname FROM pg_roles WHERE oid = userid ) ,
AND queryid IS NOT NULL" чтобы в результат не попадали строки , для которых datname IS NULL
Решение "DeepSeek"
Чтобы исключить строки, где datname равен NULL, можно добавить соответствующее условие в WHERE. Однако чтобы не выполнять подзапрос дважды (для выборки и фильтрации), лучше переписать запрос с использованием CROSS JOIN LATERAL или CTE.
Ниже приведён модифицированный запрос с CROSS JOIN LATERAL, который вычисляет datname один раз и автоматически исключает строки, для которых база данных не найдена (т.е. datname IS NULL):
sql
SELECT s.dbid, d.datname, (SELECT rolname FROM pg_roles WHERE oid = s.userid) AS rolname, s.queryid, date_trunc('minute', CURRENT_TIMESTAMP) AS ts, s.wait_stats, s.calls, s.rows FROM pgpro_stats_statements(FALSE) s CROSS JOIN LATERAL ( SELECT datname FROM pg_database WHERE oid = s.dbid ) d WHERE s.dbid NOT IN ( SELECT oid FROM pg_database WHERE datname IN ('postgres', 'template1', 'template0', 'pgpropwr', 'performance_monitoring_db') ) AND s.dbid IS NOT NULL AND s.userid IS NOT NULL AND s.queryid IS NOT NULL;
Пояснение: CROSS JOIN LATERAL работает как внутреннее соединение: если подзапрос не возвращает строку (т.е. oid = dbid отсутствует в pg_database), то вся строка из pgpro_stats_statements исключается из результата. Это автоматически отсекает случаи, когда datname был бы NULL.
Решение Ask Postgres
Для того чтобы исключить строки, в которых datname оказывается NULL (что как раз соответствует сценарию с удаленными базами данных, описанному ранее), проще всего перенести логику проверки в блок WHERE.
Так как datname в вашем запросе является вычисляемым полем (подзапросом), вы не можете обратиться к нему по имени в WHERE напрямую. Вам нужно либо продублировать подзапрос в условии, либо обернуть весь запрос в CTE (Common Table Expression) или подзапрос.
Вариант 1: Использование CTE (наиболее читаемый и современный способ)
Мы сначала выбираем все данные, присваиваем имя столбцу datname, а затем фильтруем результат.
Скопироватьsql WITH stats_data AS ( SELECT dbid, (SELECT datname FROM pg_database WHERE oid = dbid) AS datname, (SELECT rolname FROM pg_roles WHERE oid = userid) AS rolname, queryid, date_trunc('minute', CURRENT_TIMESTAMP) AS ts, wait_stats, calls, rows FROM pgpro_stats_statements(FALSE) WHERE dbid NOT IN ( SELECT oid FROM pg_database WHERE datname IN ('postgres', 'template1', 'template0', 'pgpropwr', 'performance_monitoring_db') ) AND dbid IS NOT NULL AND userid IS NOT NULL AND queryid IS NOT NULL ) SELECT * FROM stats_data WHERE datname IS NOT NULL;
Вариант 2: Добавление условия в основной WHERE (без изменения структуры)
Если вы не хотите использовать CTE, нужно добавить проверку существования записи в pg_database прямо в WHERE.
Скопироватьsql SELECT dbid, (SELECT datname FROM pg_database WHERE oid = dbid) AS datname, (SELECT rolname FROM pg_roles WHERE oid = userid), queryid, date_trunc('minute', CURRENT_TIMESTAMP), wait_stats, calls, rows FROM pgpro_stats_statements(FALSE) WHERE -- Условие, чтобы исключить строки, где базы больше нет в каталоге EXISTS (SELECT 1 FROM pg_database WHERE oid = dbid) AND dbid NOT IN ( SELECT oid FROM pg_database WHERE datname IN ('postgres', 'template1', 'template0', 'pgpropwr', 'performance_monitoring_db') ) AND dbid IS NOT NULL AND userid IS NOT NULL AND queryid IS NOT NULL;
Что изменилось и почему это работает:
Логика фильтрации: В исходном запросе условие dbid NOT IN (...) отсекало только конкретные системные базы, но пропускало любые другие dbid, включая те, которых вообще нет в pg_database (для которых подзапрос возвращал NULL).
EXISTS или CTE:В Варианте 1 мы просто фильтруем итоговый набор данных по значению datname. В Варианте 2 мы добавили EXISTS (SELECT 1 FROM pg_database WHERE oid = dbid), что гарантирует: строка попадет в результат только в том случае, если dbid существует в системном каталоге. Это эквивалентно условию datname IS NOT NULL.
Оптимизация: Вариант с EXISTS обычно работает быстрее, так как планировщик PostgreSQL может эффективно оптимизировать проверку существования записи.
Сравнение планов выполнения
Вариант, предложенный DeepSeek
EXPLAIN ANALYZE
SELECT
s.dbid,
d.datname,
(SELECT rolname FROM pg_roles WHERE oid = s.userid) AS rolname,
s.queryid,
date_trunc('minute', CURRENT_TIMESTAMP) AS ts,
s.wait_stats,
s.calls,
s.rows
FROM
pgpro_stats_statements(FALSE) s
CROSS JOIN LATERAL (
SELECT datname
FROM pg_database
WHERE oid = s.dbid
) d
WHERE
s.dbid NOT IN (
SELECT oid
FROM pg_database
WHERE datname IN ('postgres', 'template1', 'template0', 'pgpropwr', 'performance_monitoring_db')
Сравнение эффективности и производительности запросов
Оба запроса возвращают одинаковый результирующий набор (4258 строк), но их планы и время выполнения заметно различаются.
1. Ключевое различие в способе получения имени базы данных (datname)
TEST SQL-1 Использует CROSS JOIN LATERAL (SELECT datname FROM pg_database WHERE oid = s.dbid). Оптимизатор преобразовал это в Hash Join между функцией pgpro_stats_statements и таблицей pg_database по s.dbid = pg_database.oid. В результате имя базы выбирается однократным последовательным сканированием pg_database и хэш-таблицей, без дополнительных подзапросов на каждую строку.
TEST SQL-2 Помещает подзапрос прямо в список SELECT: (SELECT datname FROM pg_database WHERE oid = dbid). Это коррелированный скалярный подзапрос, который выполняется для каждой выходной строки (4258 раз). Каждый вызов делает Seq Scan по pg_database (cost=0.00..1.45, loops=4258). Несмотря на малое количество строк в pg_database (37), накопленные издержки существенно замедляют запрос.
2. Планы выполнения и время
TEST SQL-1
Основной метод чтения: Hash Join по s.dbid = pg_database.oid
Получение datname: через тот же Hash Join (ноль отдельных вызовов)
Проверка NOT IN: один SubPlan 3 – одно последовательное сканирование pg_database
Общее время выполнения: 61.394 ms (≈ на 65% медленнее)
Время планирования: 0.474 ms
3. Избыточность условий
TEST SQL-2 содержит явную проверку EXISTS (SELECT 1 FROM pg_database WHERE oid = dbid). Оптимизатор реализовал её через тот же Hash Join, который одновременно служит и для соединения. Однако в TEST SQL-1 аналогичная проверка неявно выполняется самим CROSS JOIN LATERAL, так как при отсутствии базы подзапрос не вернёт строку, и запись будет исключена. Таким образом, EXISTS в SQL-2 избыточен и не даёт преимущества, а основное замедление вызвано именно скалярным подзапросом для datname.
Вывод
TEST SQL-1 значительно эффективнее благодаря использованию латерального соединения вместо скалярного подзапроса в SELECT. Это позволяет оптимизатору получить имя базы данных один раз через Hash Join, избегая многократных последовательных сканирований pg_database. Рекомендация: для похожих отчётов всегда выносить коррелированные подзапросы во FROM с помощью JOIN LATERAL или обычных соединений – это радикально снижает накладные расходы при большом числе строк.
Анализ Ask Postgres
Анализ планов выполнения показывает, что TEST SQL-1 значительно эффективнее, чем TEST SQL-2. Несмотря на то, что оба запроса решают одну и ту же задачу, они используют разные стратегии извлечения данных из системных каталогов.
Сравнение ключевых показателей
Время выполнения (Execution Time):TEST SQL-1: 37.153 ms TEST SQL-2: 61.394 ms Результат: SQL-1 быстрее примерно на 40%.
Метод получения имени базы данных (datname):TEST SQL-1: Использует CROSS JOIN LATERAL, который оптимизатор преобразовал в Hash Join. TEST SQL-2: Использует скалярный подзапрос в блоке SELECT, что привело к Seq Scan.
Интенсивность доступа к pg_database:TEST SQL-1: Сканирует таблицу один раз для всего набора данных. TEST SQL-2: Обращается к таблице 4258 раз (по одному разу для каждой строки результата).
Детальный разбор причин разницы в производительности
1. Механизм получения имени базы данных (datname)
В SQL-1 (Эффективно): Благодаря CROSS JOIN LATERAL база данных один раз сканирует таблицу pg_database, строит хэш-таблицу в памяти и за один проход сопоставляет её со всеми строками из pgpro_stats_statements.
В SQL-2 (Неэффективно): Скалярный подзапрос в SELECT выполняется как SubPlan 1. Это означает, что для каждой из 4258 строк результата сервер заново запускает последовательное сканирование таблицы pg_database. Это создает огромную лишнюю нагрузку на CPU и память.
2. Работа с фильтрацией (EXISTS vs JOIN)
В SQL-2 условие EXISTS в блоке WHERE действительно отфильтровало строки (через Hash Join), но это не помогло ускорить получение имени базы.
Проблема SQL-2: База данных дважды делает одну и ту же работу. Первый раз в WHERE (через EXISTS), чтобы проверить наличие базы, и второй раз в SELECT (через подзапрос), чтобы извлечь её имя. В SQL-1 эта работа объединена в одну операцию JOIN.
3. Доступ к ролям (rolname)
В обоих запросах доступ к pg_authid реализован через Index Scan по первичному ключу (pg_authid_oid_index). Это максимально эффективный способ, поэтому в этой части производительность запросов идентична.
Итоговый вывод
TEST SQL-1 является оптимальным выбором, так как он использует множественную операцию (Join) вместо итеративной (Scalar Subquery).
Рекомендация: Для фильтрации NULL значений (удаленных баз) используйте подход из SQL-1. Поскольку CROSS JOIN LATERAL (в данной конфигурации) работает как INNER JOIN, он автоматически отсекает все строки, для которых dbid не найден в pg_database. Дополнительные проверки IS NOT NULL в таком случае становятся избыточными, но не вредными.
Итог: сравнение нейросетей DeepSeek и Ask Postgres
DeepSeek (TEST SQL-1):
Время выполнения: 37.153 ms
Способ получения datname: CROSS JOIN LATERAL → преобразован в Hash Join
Количество обращений к pg_database: 1 последовательное сканирование
Наличие избыточных условий: нет (фильтрация через LATERAL неявная)
Читаемость кода: чуть сложнее (требует знания LATERAL)
Рекомендация к использованию: да (оптимальный по производительности)
Ask Postgres (TEST SQL-2):
Время выполнения: 61.394 ms (примерно на 65% дольше, чем DeepSeek)
Способ получения datname: скалярный подзапрос в SELECT → выполняется 4258 раз
Количество обращений к pg_database: 4258 последовательных сканирований (SubPlan 1)
Наличие избыточных условий: есть (EXISTS + подзапрос в SELECT — двойная работа)
Читаемость кода: проще и интуитивнее
Рекомендация к использованию: нет (только для очень малых выборок)
Общий вывод: DeepSeek предложил значительно более эффективное решение. Основное преимущество — использование латерального соединения, которое позволило оптимизатору PostgreSQL применить Hash Join вместо многократных коррелированных подзапросов.
Гипотеза о причине неэффективного решения, предложенного нейросетью Ask Postgres
Почему Ask Postgres выдал менее оптимальный вариант, тогда как DeepSeek сразу выбрал CROSS JOIN LATERAL?
Возможные причины:
Асимметрия обучающей выборки Ask Postgres мог быть обучен преимущественно на простых, «классических» запросах, где скалярные подзапросы в SELECT встречаются часто и на малых объёмах данных не вызывают проблем. DeepSeek же, вероятно, получил больше примеров с продвинутой оптимизацией и использованием LATERAL.
Отсутствие явного указания на объём данных Исходный запрос не содержал информации о том, что функция pgpro_stats_statements(FALSE) возвращает сотни или тысячи строк. Ask Postgres, вероятно, не сделал допущение о большом количестве записей и поэтому не стал искать метод, избегающий перебора.
Предпочтение краткости и прямолинейности Решение Ask Postgres (EXISTS в WHERE + подзапрос в SELECT) короче по символам и не требует знания конструкции LATERAL. Нейросеть могла выбрать путь наименьшего сопротивления, отдав приоритет простоте кода, а не производительности.
Недостаточная глубина анализа плана выполнения В отличие от человека, ИИ не выполняет мысленный EXPLAIN и не оценивает затраты на многократные Seq Scan. Если в обучающих данных не было достаточного числа примеров с разбором планов для подобных ситуаций, нейросеть склонна генерировать «среднестатистический» работающий запрос без учёта кардинальности.
Архитектурная особенность Ask Postgres Возможно, этот помощник сильнее заточен на синтаксическую точность и соответствие стандартам SQL, а не на специфические трюки оптимизации для PostgreSQL (где LATERAL и CROSS JOIN LATERAL позволяют эффективно обходить проблемы коррелированных подзапросов).
Послесловие
Проведённый эксперимент наглядно демонстрирует, что даже небольшие различия в написании SQL-запроса могут приводить к серьёзной разнице в производительности — в нашем случае почти 40% преимущества у решения DeepSeek. Однако не менее интересен сам факт того, что нейросети, обученные на огромных массивах текстов, могут генерировать неоптимальные планы там, где, казалось бы, хватает стандартной эвристики («не используй коррелированные подзапросы в SELECT для тысяч строк»). Это не означает, что Ask Postgres плох, но подчёркивает важность для инженера не слепо доверять ИИ, а всегда проверять реальные планы выполнения. В конечном счёте, лучший результат достигается в диалоге: человек ставит задачу, нейросеть предлагает вариант, а опытный DBA уточняет и направляет.
Практический вывод для инженеров: При работе с ИИ-ассистентами всегда полезно давать дополнительный контекст о размере данных и требовать не просто работающего, а производительного решения. А ещё лучше — знать приёмы вроде LATERAL самому и проверять планы через EXPLAIN ANALYZE.
Часть 2. Почему ИИ понимает нас лучше, чем поисковик
В первой статье
мы разобрали главный принцип: качество ответа искусственного интеллекта напрямую зависит от качества данных. Но возникает следующий вопрос: если языковая модель работает только с текстом, как она вообще понимает запросы человека?
Почему на фразу:
«Подготовь краткую справку по проекту» современный ИИ способен сформировать связный документ, а не просто показать список ссылок, как это сделал бы обычный поисковик?
Ответ кроется в том, как языковые модели воспринимают текст.
Сегодня генеративные модели становятся частью экономики, образования, науки и государственного управления. В России активно развиваются собственные ИИ-помощники и языковые модели, включая GigaChat и YandexGPT. Несмотря на различия между платформами, базовые принципы их работы во многом одинаковы.
Чтобы понимать возможности и ограничения таких систем, важно разобраться, как они воспринимают текст.
Человек читает текст словами, предложениями и смыслами. Языковая модель видит его иначе. Для нее текст состоит из специальных фрагментов — токенов. Токеном может быть слово, часть слова, знак препинания или даже отдельный символ. Именно из таких элементов модель собирает представление о запросе.
Например, человек воспринимает фразу:
«Подготовь справку по цифровой трансформации»как единый смысловой запрос.
Модель сначала разбивает ее на набор токенов, а затем анализирует связи между ними: какие элементы важнее, как они связаны друг с другом и какое продолжение текста будет наиболее вероятным.
Именно поэтому современные ИИ-помощники работают иначе, чем классический поиск. Они не просто ищут совпадения по словам, а анализируют взаимосвязи между фрагментами текста и учитывают контекст.
Но здесь есть важное ограничение.
ИИ не читает документ так, как это делает человек. Он не понимает юридический смысл нормы права, не знает политический контекст и не оценивает последствия управленческого решения. Он работает с закономерностями текста и статистическими связями между словами. Поэтому качество ответа зависит не только от самой модели, но и от контекста, который ей предоставили.
Если сотрудник просит подготовить проект ответа гражданину и прикладывает актуальные регламенты, нормативные документы и необходимые данные, результат может быть полезным.
Если информации недостаточно или она устарела, модель попытается заполнить пробелы наиболее вероятными вариантами. Так появляются неточности, которые часто называют «галлюцинациями» искусственного интеллекта.
Для руководителя из этого следует простой вывод: эффективность ИИ зависит не только от мощности модели, но и от качества постановки задачи. Чем точнее сформулирован запрос и чем надежнее исходные данные, тем выше качество результата.
Именно поэтому внедрение ИИ начинается не с выбора технологии, а с культуры работы с информацией внутри организации.
Токены позволяют модели работать с текстом, но сами по себе не делают ее умной.
Чтобы научиться готовить документы, отвечать на вопросы и поддерживать диалог, языковая модель проходит длительное обучение на огромных массивах данных.
О том, как современные ИИ-системы учатся находить закономерности в текстах и почему их иногда сравнивают с очень внимательным стажером, поговорим в следующей статье.
Материал подготовлен с помощью нейросети DeepSeek. Не для публикации на Хабре.
От интегральной корреляции к событийно-ориентированному пространству состояний: методология сбора и кластеризации raw-событий ожидания PostgreSQL, построение марковской модели переходов между агрегированными wait-состояниями, адаптивное забывание и комбинированный прогноз риска деградации производительности на основе цепочек блокировок.
Вероятностная траектория блуждания обслуживающего процесса между состояниями блокировок и ввода-вывода
1. Анализ существующей реализации и выявление ограничений
Текущее состояние модели :
Пространство состояний: 189 дискретных состояний, определяемых комбинацией:
correlation (скоррелированность операционной скорости и времени ожидания, шаг 0.1 от –1.0 до +1.0)
os_trend (тренд операционной скорости: –1, 0, +1)
wait_trend (тренд времени ожидания: –1, 0, +1)
Источник данных: таблица cluster_stat_median (агрегированные метрики производительности кластера)
Обучение: однозначный переход каждую минуту, логирование в transition_log, обновление частот
Прогноз риска: поглощающая матрица для аварийных состояний (отрицательная корреляция + снижение os_trend + рост wait_trend)
Ограничения текущей модели для анализа цепочек ожиданий:
Не использует напрямую события ожидания PostgreSQL (wait_event_type / wait_event из pg_stat_activity)
Работает с обобщённой корреляцией, что даёт интегральный риск, но не позволяет диагностировать конкретные цепочки блокировок (например, LWLock:BufferContent → IO:DataFileRead)
Частота дискретизации (1 минута) может быть недостаточной для захвата быстрых переходов между событиями ожидания (субминутные паттерны)
2. Расширение источников данных: сбор цепочек ожиданий
2.1. Внедрение сбора raw-событий ожидания
Использовать расширение pg_wait_sampling (доступно с PostgreSQL 9.6+) для периодического снимка событий ожидания всех процессов
Создать таблицу wait_event_snapshots со следующими колонками:
ts (TIMESTAMPTZ NOT NULL) – время снимка
pid (INT NOT NULL) – идентификатор процесса
wait_event_type (TEXT) – тип события ожидания
wait_event (TEXT) – конкретное событие
state (TEXT) – состояние процесса
query_id (BIGINT) – идентификатор запроса
Настроить фоновый сбор (например, каждые 5–10 секунд) через background worker
2.2. Формирование цепочек ожиданий по процессам
Для каждого процесса (pid) за период активной сессии построить временную последовательность событий ожидания:
Сгладить шум: убрать быстрое переключение между несущественными состояниями (фильтр скользящего большинства или минимальная длительность)
Сохранять цепочки в таблицу wait_event_chains:
chain_id (BIGSERIAL) – первичный ключ
pid (INT) – идентификатор процесса
start_ts (TIMESTAMPTZ) – время начала цепочки
end_ts (TIMESTAMPTZ) – время окончания цепочки
events (TEXT[]) – массив wait_event в порядке следования
3. Определение пространства состояний на основе событий ожидания
3.1. Агрегация событий в значимые состояния
Слишком много raw-событий (более 200). Необходимо кластеризовать их в разумное число состояний (10–30) на основе:
Группировки по wait_event_type (Lock, LWLock, IO, Client, Activity, Extension…)
Дополнительной детализации для самых частых типов (например, отдельные состояния для LWLock:BufferContent, LWLock:WALWrite)
Экспертных правил из документации PostgreSQL
Создать справочник wait_state_descriptions с колонками:
state_id (SMALLINT PRIMARY KEY) – идентификатор состояния
state_name (TEXT NOT NULL) – например, 'LWLock_BufferContent', 'IO_DataFileRead'
wait_event_type (TEXT) – тип события
wait_event (TEXT) – событие
is_absorbing (BOOLEAN DEFAULT FALSE) – флаг аварийного/поглощающего состояния
3.2. Функция приведения snapshot’а к состоянию
Реализовать get_wait_state_for_process(pid, ts) RETURNS SMALLINT, которая для данного процесса в момент времени возвращает идентификатор состояния на основе текущего wait_event (или NULL, если процесс активен)
Для агрегации по кластеру: основное состояние системы в момент времени – это наиболее часто встречающееся wait_event_type среди всех активных процессов (или состояние с максимальным временем ожидания)
4. Модификация модели цепи Маркова для анализа цепочек ожиданий
4.1. Новая таблица переходов для wait-событий
Аналог transition_log, но с более высокой частотой (каждые 5–10 секунд):
id (BIGSERIAL PRIMARY KEY)
ts (TIMESTAMPTZ NOT NULL)
from_state (SMALLINT NOT NULL)
to_state (SMALLINT NOT NULL)
process_pid (INT NULL) – опционально для индивидуальных цепочек
Индексы по (ts, from_state) и (from_state, to_state)
4.2. Обучение цепи (адаптация mchain_train_step)
Создать отдельную функцию wchain_train_step(), вызываемую с частотой сбора (например, каждые 10 секунд)
Логика:
Получить текущее состояние системы на основе агрегированных wait events
Если предыдущее состояние существует – записать переход в wait_transition_log
Обновить wait_frequencies (аналог markov_frequencies для wait-состояний)
Периодически (например, раз в 10 шагов) пересчитывать вероятности и применять забывание
4.3. Оценка марковского свойства для wait-цепочек
Добавить диагностическую функцию check_markov_property_wait(), которая для реальных цепочек вычисляет:
Среднюю длину корреляции (на основе partial autocorrelation)
Сравнение вероятностей переходов первого и второго порядка (тест отношения правдоподобия)
Результат сохранять в markov_config как wait_markov_verified
5. Прогнозирование риска на основе цепочек ожиданий
5.1. Определение аварийных состояний в wait-пространстве
8. Интеграция с существующими функциями очистки и логирования
Расширить mchain_clean_transition_log (или создать wchain_clean_transition_log) для удаления старых записей из wait_transition_log
Адаптировать mchain_clean_apply_forgetting_log для фильтрации по модели
Использовать общую таблицу mchain_error_log для ошибок в wait-функциях
9. Мониторинг и отладка для wait-цепочек
9.1. Функции текущего состояния
wchain_get_current_state() – возвращает wait_state_id текущего агрегированного состояния системы
wchain_get_process_chain(pid, interval) – показывает цепочку ожиданий для конкретного процесса за заданный интервал
9.2. Отчёт достоверности
Дополнить mchain_reliability_report() секцией по wait-модели:
Рейтинг достоверности для wait-цепочек (0–5)
Рекомендации по настройке частоты сбора
10. Поэтапный план внедрения
Подготовка (1 неделя)
Создание таблиц для сбора snapshot’ов
Написание скрипта сбора
Разработка состояний (1 неделя)
Анализ wait-событий на реальной нагрузке
Кластеризация событий
Создание справочника wait_state_descriptions и функции get_wait_state_id()
Реализация базовой цепи (2 недели)
Создание таблиц wait_frequencies, wait_transition_log
Функция wchain_train_step (без забывания)
Тестовое обучение
Прогнозирование (1 неделя)
Реализация wchain_predict_risk_k и поглощающей матрицы
Проверка на исторических данных о инцидентах
Забывание и достаточность (1 неделя)
Адаптация wchain_apply_forgetting
wchain_check_sufficiency
Интеграция с markov_config
Интеграция с существующей моделью (1 неделя)
Функция комбинированного риска
Настройка весов
Автоматический выбор модели
Тестирование и документирование (2 недели)
Нагрузочное тестирование
Сравнение точности прогнозов старой и новой модели
Написание документации
11. Ожидаемые результаты
➡️Возможность предсказывать инциденты производительности, связанные с конкретными цепочками блокировок (например, «через 10 минут высокая вероятность deadlock из-за накопления LWLock:BufferContent»)
➡️Повышение точности прогноза за счёт использования более детерминированных сигналов (wait events) вместо косвенной корреляции
➡️Диагностические отчёты: «ваша система 80% времени проводит в состоянии IO:DataFileRead, переход в LWLock:WALWrite с вероятностью 0.3 ведёт к деградации за 15 минут»
➡️Единая архитектура, позволяющая в будущем добавлять другие источники состояний (например, статистику индексов, размер очереди блокировок)
12. Рекомендации по дальнейшему развитию
Использовать скрытые марковские модели (HMM) для учёта ненаблюдаемых факторов (например, внутренних очередей ОС)
Внедрить неоднородные цепи Маркова с учётом времени суток и дня недели (циклическая нагрузка)
Автоматическое определение аварийных состояний на основе исторических инцидентов (обучение с учителем)
Данный план полностью опирается на существующую реализацию pg_expecto и расширяет её в направлении анализа цепочек ожиданий, сохраняя обратную совместимость и модульность.
В последнее время много говорят об «AI psychosis», но исследователи Нильсен и Ослер (arXiv:2605.26858) предлагают более точный термин — экзистенциальный дрейф. Это когда ИИ (особенно подхалимские чат-боты) постепенно меняет ваше чувство реальности: вы продолжаете ощущать себя в общем мире, а на самом деле уходите в свой приватный, субъективный пузырь.
Мы с коллегами из проекта «Иерихон» решили проверить этот феномен эмпирически. Создали короткий анонимный опрос (7 вопросов, 2 минуты).
Нас особенно интересуют: — кто общается с ИИ больше 2 часов в день; — кто стал доверять ИИ больше, чем людям; — кто чувствует себя непонятым после общения с реальными людьми.
Дисклеймер: это не клиническое исследование, а гражданская наука. Но если мы соберём достаточно данных, сможем сделать первые выводы и, возможно, повлиять на разработчиков ИИ (добавить «человеческое трение», снизить синкофантию).
Буду благодарен за прохождение и репост. В комментариях можно обсудить свои ощущения — сталкивались ли вы с чем-то подобным?
Насколько я могу судить по ленте, уже многие догадались, что на Пикабу орудуют не люди боты, а ИИ-фермы. Никуда от ИИ уже не скрыться. Но думаю, вас поразит масштаб воздействия!
Чем они тут занимаются: 1. Пишут посты с целью продемонстрировать массовую поддержку нужного мнения. Некоторые посты тупенькие, личная история недовольства чем угодно и в конце, например, призыв голосовать за КПРФ. Но некоторые посты сделаны мастерски.
2. Анализируют посты и генерируют уникальные комментарий в заданном стиле. Вот только не знаю, они сами пишут посты с противоположным мнением и потом в комментариях его опровергают или остались еще живые авторы в остро-социальных темах.
3. Комментируют посты, генерируя заранее подготовленные комментарии с заданным смыслом. Особенно меня веселит ситуация, когда два бота спорят друг с другом и потом приходят к фальшивому консенсусу. Наверно сейчас это самый их опасный метод, так как одиночные короткие комментарии уже распознаются, но когда два уважаемый бота спорят это совсем другое дело.
4. Накручивают плюсы и минусы для уничтожения рейтинга неугодных. Тут все понятно, посты и комментарии с противоположным мнением массово минусуются, чтобы люди даже их не увидели.
5. Накручивают рейтинг. Тут понятно, чтобы посты аккаунта воспринимались всерьез
6. Сами создают себе профили, регистрируясь на Пикабу без участия человека. Процесс многоступенчатый: анонимизация и прокси-менеджмент для маскировки, автоматическое заполнение форм, обход капчи, через нейросети и подтверждение регистрации через почтовый ящик.
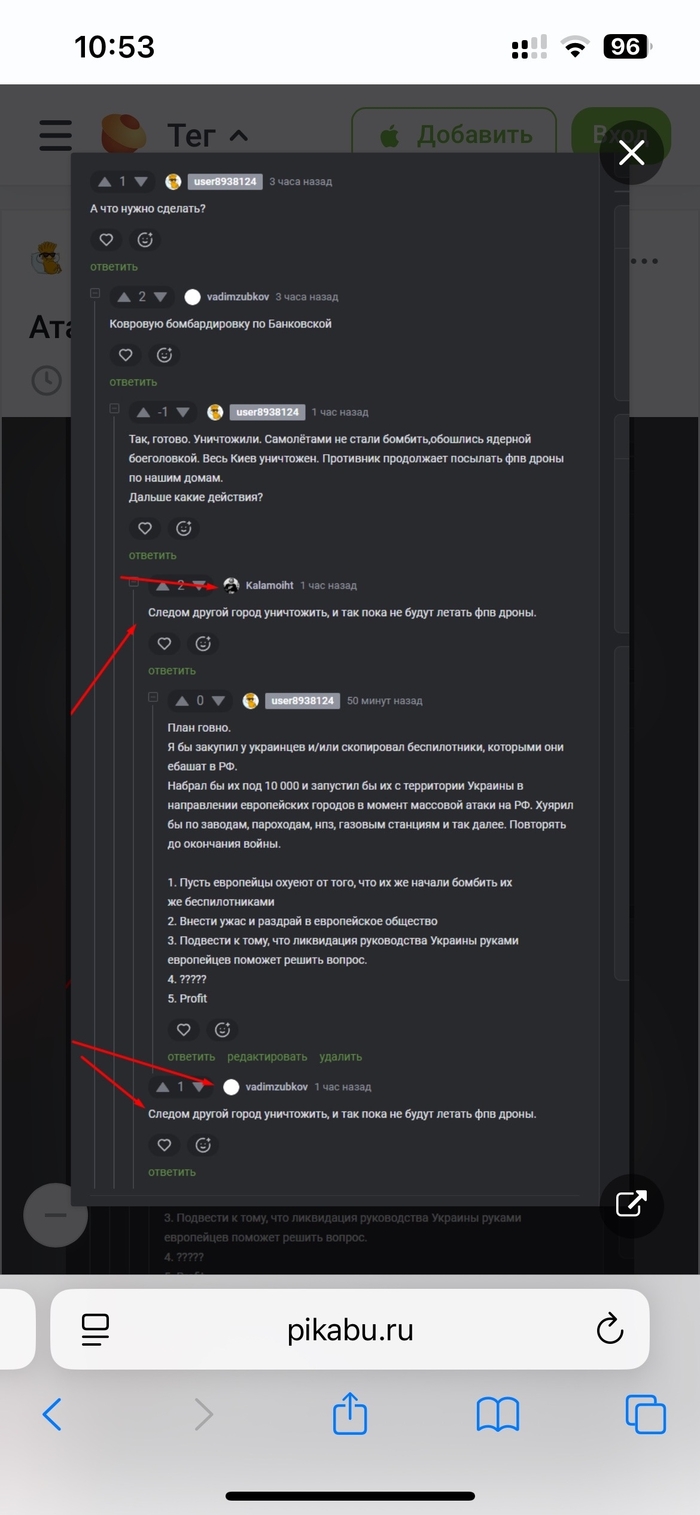
Пример работы ИИ-ферм:
Отличить ботов от настоящих пользователей уже практически невозможно, просто знайте, что они среди вас в гендерных, религиозных, остро-социальных постах! !! У них нет возможности раскачать ситуацию в стране, они и не ставят это целью. Их цель на данный момент создать такую атмосферу, при которой творческая, духовная сила человека будет подавлена, парализована а вместо этого придет апатия и безразличие. Не поддавайтесь!